Ktoś przypadkowo usunął część bazy danych. Ktoś zapomniał umieścić klauzulę WHERE w zapytaniu DELETE lub usunął niewłaściwą tabelę. Takie rzeczy mogą i będą się zdarzać, jest to nieuniknione i ludzkie. Ale wpływ może być katastrofalny. Co możesz zrobić, aby zabezpieczyć się przed takimi sytuacjami i jak możesz odzyskać swoje dane? W tym poście na blogu omówimy niektóre z najbardziej typowych przypadków utraty danych oraz sposoby przygotowania się do ich odzyskania.
Przygotowania
Są rzeczy, które powinieneś zrobić, aby zapewnić płynną regenerację. Przejrzyjmy je. Pamiętaj, że nie jest to sytuacja „wybierz jedną” – najlepiej, jeśli zastosujesz wszystkie środki, które omówimy poniżej.
Kopia zapasowa
Trzeba mieć kopię zapasową, nie da się od niej uciec. Powinieneś przetestować swoje pliki kopii zapasowych - jeśli nie przetestujesz swoich kopii zapasowych, nie możesz być pewien, czy są one dobre i czy kiedykolwiek będziesz w stanie je przywrócić. W przypadku odzyskiwania danych po awarii należy przechowywać kopię kopii zapasowej poza centrum danych — na wypadek, gdyby całe centrum danych stało się niedostępne. Aby przyspieszyć odzyskiwanie, bardzo przydatne jest przechowywanie kopii zapasowej również w węzłach bazy danych. Jeśli zestaw danych jest duży, skopiowanie go przez sieć z serwera kopii zapasowej do węzła bazy danych, który chcesz przywrócić, może zająć dużo czasu. Przechowywanie najnowszej kopii zapasowej lokalnie może znacznie skrócić czas przywracania.
Logiczna kopia zapasowa
Twoja pierwsza kopia zapasowa najprawdopodobniej będzie fizyczną kopią zapasową. W przypadku MySQL lub MariaDB będzie to coś w rodzaju xtrabackup lub jakiś rodzaj migawki systemu plików. Takie kopie zapasowe świetnie nadają się do przywracania całego zestawu danych lub udostępniania nowych węzłów. Jednak w przypadku usunięcia podzbioru danych obciążają je znaczne koszty. Przede wszystkim nie jesteś w stanie przywrócić wszystkich danych, w przeciwnym razie nadpiszesz wszystkie zmiany, które nastąpiły po utworzeniu kopii zapasowej. To, czego szukasz, to możliwość przywrócenia tylko podzbioru danych, tylko wierszy, które zostały przypadkowo usunięte. Aby to zrobić z fizyczną kopią zapasową, musiałbyś przywrócić ją na osobnym hoście, zlokalizować usunięte wiersze, zrzucić je, a następnie przywrócić w klastrze produkcyjnym. Kopiowanie i przywracanie setek gigabajtów danych tylko w celu odzyskania kilku wierszy to coś, co z pewnością nazwalibyśmy znacznym obciążeniem. Aby tego uniknąć można wykorzystać kopie logiczne - zamiast przechowywania danych fizycznych, takie kopie przechowują dane w formacie tekstowym. Ułatwia to zlokalizowanie dokładnych danych, które zostały usunięte, które można następnie przywrócić bezpośrednio w klastrze produkcyjnym. Aby było to jeszcze łatwiejsze, możesz również podzielić taką logiczną kopię zapasową na części i wykonać kopię zapasową każdej tabeli w osobnym pliku. Jeśli Twój zbiór danych jest duży, sensowne będzie podzielenie jednego dużego pliku tekstowego na tyle, na ile to możliwe. Spowoduje to, że kopia zapasowa będzie niespójna, ale w większości przypadków nie stanowi to problemu - jeśli będziesz musiał przywrócić cały zestaw danych do spójnego stanu, użyjesz fizycznej kopii zapasowej, która jest pod tym względem znacznie szybsza. Jeśli chcesz przywrócić tylko podzbiór danych, wymagania dotyczące spójności są mniej rygorystyczne.
Odzyskiwanie do określonego momentu
Backup to dopiero początek - będziesz mógł przywrócić dane do punktu, w którym wykonano kopię zapasową, ale najprawdopodobniej dane zostały usunięte po tym czasie. Samo przywrócenie brakujących danych z ostatniej kopii zapasowej może spowodować utratę wszelkich danych, które zostały zmienione po utworzeniu kopii zapasowej. Aby tego uniknąć, należy wdrożyć odzyskiwanie do określonego punktu w czasie. W przypadku MySQL oznacza to w zasadzie, że będziesz musiał użyć dzienników binarnych, aby odtworzyć wszystkie zmiany, które nastąpiły między momentem utworzenia kopii zapasowej a zdarzeniem utraty danych. Poniższy zrzut ekranu pokazuje, jak ClusterControl może w tym pomóc.
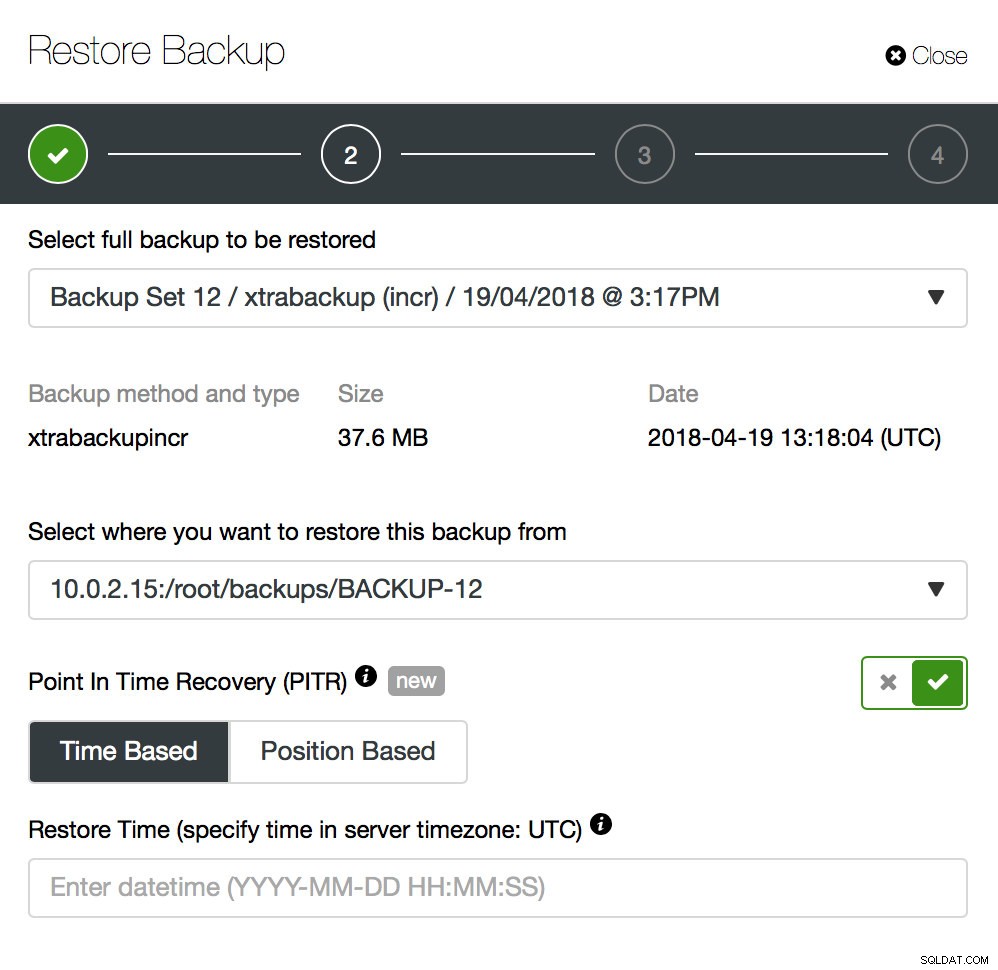
Musisz przywrócić tę kopię zapasową do momentu tuż przed utratą danych. Będziesz musiał przywrócić go na osobnym hoście, aby nie wprowadzać zmian w klastrze produkcyjnym. Po przywróceniu kopii zapasowej możesz zalogować się do tego hosta, znaleźć brakujące dane, zrzucić je i przywrócić w klastrze produkcyjnym.
Opóźniony niewolnik
Wszystkie metody, które omówiliśmy powyżej, mają jeden wspólny problem — przywrócenie danych wymaga czasu. Może to potrwać dłużej, jeśli przywrócisz wszystkie dane, a następnie spróbujesz zrzucić tylko interesującą część. Może to zająć mniej czasu, jeśli masz logiczną kopię zapasową i możesz szybko przejść do danych, które chcesz przywrócić, ale w żadnym wypadku nie jest to szybkie zadanie. Nadal musisz znaleźć kilka wierszy w dużym pliku tekstowym. Im jest większy, tym bardziej skomplikowane staje się zadanie - czasami sam rozmiar pliku spowalnia wszystkie działania. Jedną z metod uniknięcia tych problemów jest posiadanie opóźnionego niewolnika. Niewolnicy zazwyczaj starają się być na bieżąco z mistrzem, ale istnieje również możliwość skonfigurowania ich tak, aby trzymali się z dala od swojego mistrza. Na poniższym zrzucie ekranu możesz zobaczyć, jak użyć ClusterControl do wdrożenia takiego urządzenia podrzędnego:
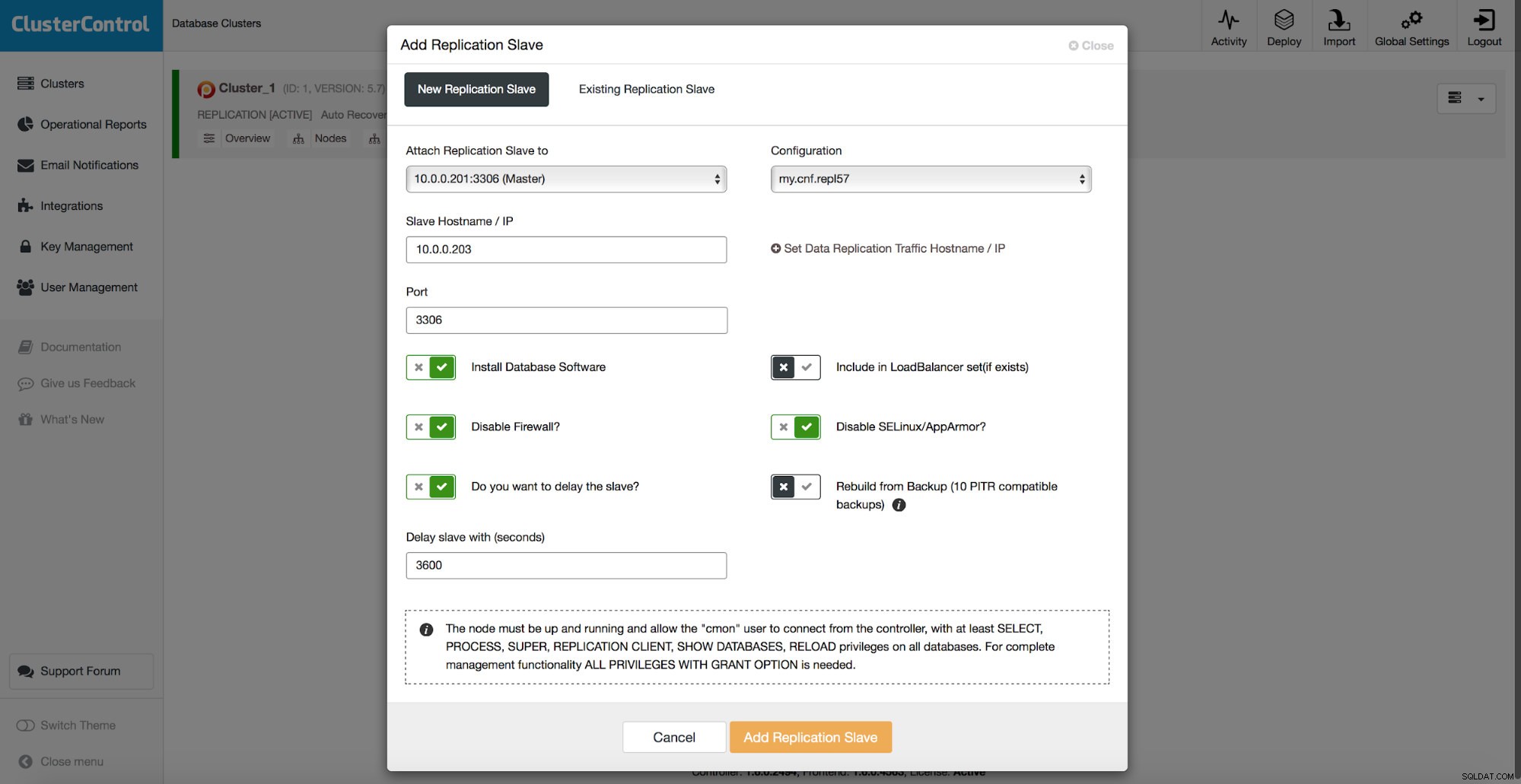
Krótko mówiąc, mamy tutaj opcję dodania urządzenia podrzędnego replikacji do konfiguracji bazy danych i skonfigurowania go tak, aby był opóźniony. Na powyższym zrzucie ekranu niewolnik zostanie opóźniony o 3600 sekund, czyli o godzinę. Pozwala to na użycie tego urządzenia podrzędnego do odzyskania usuniętych danych do godziny od usunięcia danych. Nie będziesz musiał przywracać kopii zapasowej, wystarczy uruchomić mysqldump lub SELECT ... INTO OUTFILE dla brakujących danych, a otrzymasz dane do przywrócenia w swoim klastrze produkcyjnym.
Przywracanie danych
W tej sekcji omówimy kilka przykładów przypadkowego usunięcia danych i sposobów ich odzyskania. Przejdziemy przez odzyskiwanie z pełnej utraty danych, pokażemy również, jak odzyskać częściową utratę danych podczas korzystania z fizycznych i logicznych kopii zapasowych. W końcu pokażemy Ci, jak przywrócić przypadkowo usunięte wiersze, jeśli masz w konfiguracji opóźnione urządzenie podrzędne.
Pełna utrata danych
Przypadkowe „rm -rf” lub „DROP SCHEMA myonlyschema”; został wykonany i skończyło się na braku danych. Jeśli zdarzyło Ci się również usunąć pliki inne niż z katalogu danych MySQL, może być konieczne ponowne udostępnienie hosta. Aby uprościć sprawę, założymy, że wpłynęło to tylko na MySQL. Rozważmy dwa przypadki, z opóźnionym niewolnikiem i bez jednego.
Brak opóźnionego urządzenia podrzędnego
W takim przypadku jedyne, co możemy zrobić, to przywrócić ostatnią fizyczną kopię zapasową. Ponieważ wszystkie nasze dane zostały usunięte, nie musimy się martwić o aktywność, która miała miejsce po utracie danych, ponieważ bez danych nie ma aktywności. Powinniśmy się martwić o aktywność, która miała miejsce po wykonaniu backupu. Oznacza to, że musimy wykonać przywracanie do punktu w czasie. Oczywiście zajmie to więcej czasu niż samo przywrócenie danych z kopii zapasowej. Jeśli szybkie uruchomienie bazy danych jest ważniejsze niż przywrócenie wszystkich danych, równie dobrze możesz po prostu przywrócić kopię zapasową i być z nią w porządku.
Po pierwsze, jeśli nadal masz dostęp do logów binarnych na serwerze, który chcesz przywrócić, możesz ich użyć do PITR. Najpierw chcemy przekonwertować odpowiednią część dzienników binarnych do pliku tekstowego w celu dalszego zbadania. Wiemy, że utrata danych nastąpiła po godzinie 13:00. Najpierw sprawdźmy, który plik binlogu powinniśmy zbadać:
example@sqldat.com:~# ls -alh /var/lib/mysql/binlog.*
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:32 /var/lib/mysql/binlog.000001
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:33 /var/lib/mysql/binlog.000002
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:35 /var/lib/mysql/binlog.000003
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:38 /var/lib/mysql/binlog.000004
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:39 /var/lib/mysql/binlog.000005
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:41 /var/lib/mysql/binlog.000006
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:43 /var/lib/mysql/binlog.000007
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:45 /var/lib/mysql/binlog.000008
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:47 /var/lib/mysql/binlog.000009
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:49 /var/lib/mysql/binlog.000010
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:51 /var/lib/mysql/binlog.000011
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:53 /var/lib/mysql/binlog.000012
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:55 /var/lib/mysql/binlog.000013
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:57 /var/lib/mysql/binlog.000014
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:59 /var/lib/mysql/binlog.000015
-rw-r----- 1 mysql mysql 306M Apr 23 13:18 /var/lib/mysql/binlog.000016Jak widać, interesuje nas ostatni plik binlog.
example@sqldat.com:~# mysqlbinlog --start-datetime='2018-04-23 13:00:00' --verbose /var/lib/mysql/binlog.000016 > sql.outPo zakończeniu rzućmy okiem na zawartość tego pliku. Będziemy szukać ‘drop schema’ w vim. Oto odpowiednia część pliku:
# at 320358785
#180423 13:18:58 server id 1 end_log_pos 320358850 CRC32 0x0893ac86 GTID last_committed=307804 sequence_number=307805 rbr_only=no
SET @@SESSION.GTID_NEXT= '52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415'/*!*/;
# at 320358850
#180423 13:18:58 server id 1 end_log_pos 320358946 CRC32 0x487ab38e Query thread_id=55 exec_time=1 error_code=0
SET TIMESTAMP=1524489538/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
drop schema sbtest
/*!*/;Jak widać, chcemy przywrócić do pozycji 320358785. Możemy przekazać te dane do interfejsu użytkownika ClusterControl:
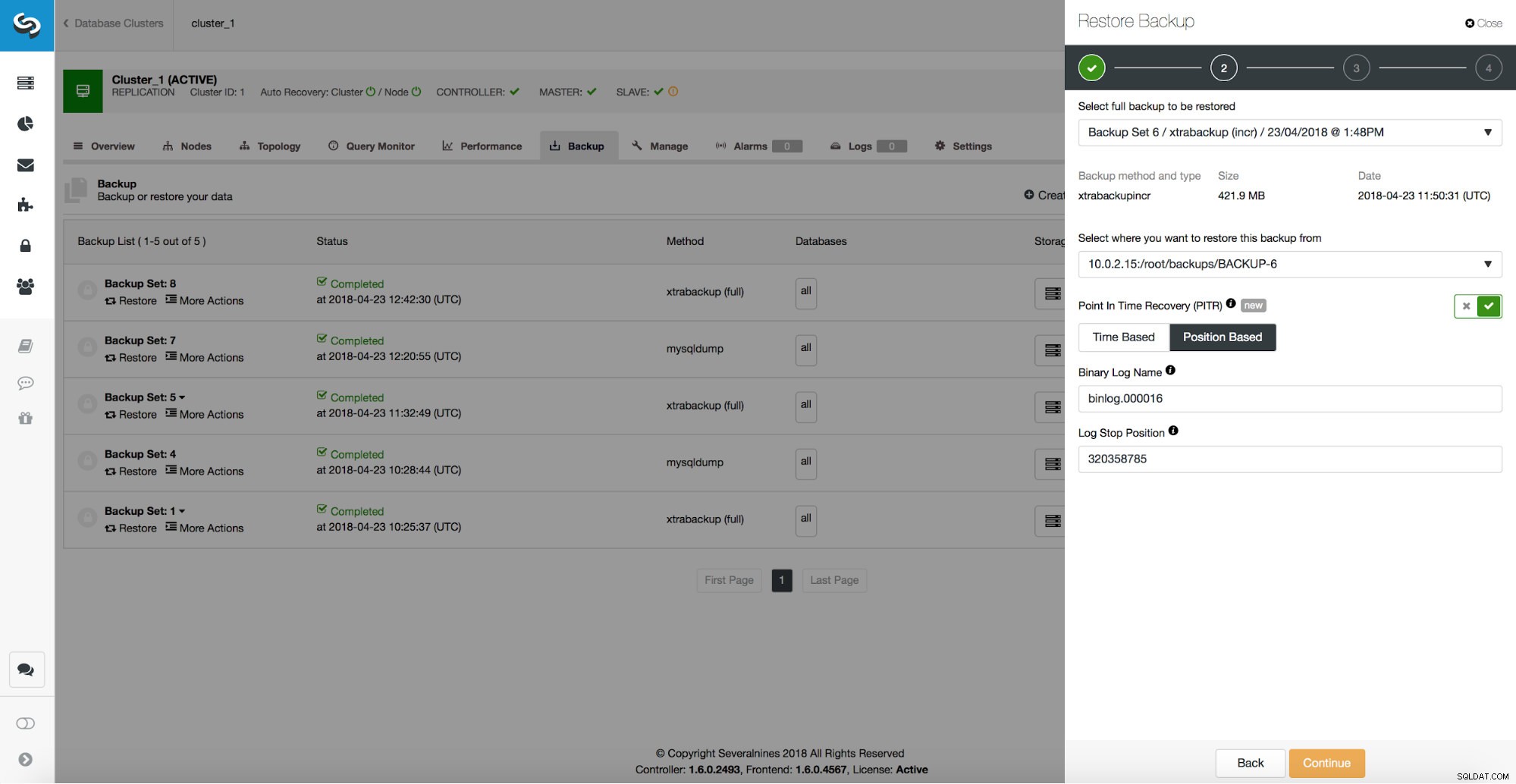
Opóźniony niewolnik
Jeśli mamy opóźnionego slave'a i ten host wystarczy do obsłużenia całego ruchu, możemy go użyć i awansować na mastera. Najpierw jednak musimy upewnić się, że dogonił starego mistrza aż do utraty danych. Użyjemy tutaj trochę CLI, aby tak się stało. Najpierw musimy dowiedzieć się, na której pozycji doszło do utraty danych. Następnie zatrzymamy urządzenie podrzędne i pozwolimy mu dobiegać do zdarzenia utraty danych. W poprzednim rozdziale pokazaliśmy, jak uzyskać prawidłową pozycję - badając logi binarne. Możemy użyć tej pozycji (binlog.000016, pozycja 320358785) lub, jeśli używamy wielowątkowego slave'a, powinniśmy użyć GTID zdarzenia utraty danych (52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415) i odtworzyć zapytania do ten numer GTID.
Najpierw zatrzymajmy urządzenie podrzędne i wyłączmy opóźnienie:
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.01 sec)
mysql> CHANGE MASTER TO MASTER_DELAY = 0;
Query OK, 0 rows affected (0.02 sec)Następnie możemy uruchomić go do podanej pozycji logu binarnego.
mysql> START SLAVE UNTIL MASTER_LOG_FILE='binlog.000016', MASTER_LOG_POS=320358785;
Query OK, 0 rows affected (0.01 sec)Jeśli chcemy użyć GTID, polecenie będzie wyglądało inaczej:
mysql> START SLAVE UNTIL SQL_BEFORE_GTIDS = ‘52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415’;
Query OK, 0 rows affected (0.01 sec)Po zatrzymaniu replikacji (co oznacza, że wszystkie zdarzenia, o które prosiliśmy, zostały wykonane), powinniśmy sprawdzić, czy host zawiera brakujące dane. Jeśli tak, możesz awansować go na mastera, a następnie przebudować inne hosty, używając nowego mastera jako źródła danych.
Nie zawsze jest to najlepsza opcja. Wszystko zależy od tego, jak opóźniony jest twój niewolnik - jeśli jest opóźniony o kilka godzin, może nie ma sensu czekać, aż nadrobi zaległości, zwłaszcza jeśli w twoim środowisku jest duży ruch związany z zapisami. W takim przypadku najprawdopodobniej szybciej odbudować hosty przy użyciu fizycznej kopii zapasowej. Z drugiej strony, jeśli masz dość mały ruch, może to być dobry sposób na szybkie naprawienie problemu, wypromowanie nowego mastera i kontynuowanie obsługi ruchu, podczas gdy reszta węzłów jest przebudowywana w tle .
Częściowa utrata danych — fizyczna kopia zapasowa
W przypadku częściowej utraty danych fizyczne kopie zapasowe mogą być nieefektywne, ale ponieważ są to najczęstsze rodzaje kopii zapasowych, bardzo ważne jest, aby wiedzieć, jak z nich korzystać do częściowego przywracania. Pierwszym krokiem będzie zawsze przywrócenie kopii zapasowej do punktu w czasie przed zdarzeniem utraty danych. Bardzo ważne jest również przywrócenie go na osobnym hoście. ClusterControl używa xtrabackup do fizycznych kopii zapasowych, więc pokażemy, jak z niego korzystać. Załóżmy, że uruchomiliśmy następujące nieprawidłowe zapytanie:
DELETE FROM sbtest1 WHERE id < 23146;
Chcieliśmy usunąć tylko jeden wiersz („=” w klauzuli WHERE), zamiast tego usunęliśmy ich kilka (
Teraz spójrzmy na plik wyjściowy i zobaczmy, co możemy tam znaleźć. Używamy replikacji opartej na wierszach, dlatego nie zobaczymy dokładnie wykonanego kodu SQL. Zamiast tego (o ile użyjemy flagi --verbose do mysqlbinlog) zobaczymy zdarzenia jak poniżej:
Jak widać, MySQL identyfikuje wiersze do usunięcia przy użyciu bardzo precyzyjnego warunku WHERE. Tajemnicze znaki w czytelnym dla człowieka komentarzu „@1”, „@2” oznaczają „pierwszą kolumnę”, „druga kolumna”. Wiemy, że pierwsza kolumna to „id”, co nas interesuje. Musimy znaleźć duże zdarzenie DELETE na tabeli „sbtest1”. W komentarzach, które nastąpią, należy wymienić id 1, potem id „2”, potem „3” i tak dalej – aż do id „23145”. Wszystko powinno być wykonane w jednej transakcji (pojedyncze zdarzenie w logu binarnym). Po przeanalizowaniu danych wyjściowych za pomocą „mniej”, znaleźliśmy:
Wydarzenie, do którego dołączone są te komentarze, rozpoczęło się o:
Dlatego chcemy przywrócić kopię zapasową do poprzedniego zatwierdzenia w pozycji 29600687. Zróbmy to teraz. Wykorzystamy do tego zewnętrzny serwer. Przywrócimy kopię zapasową do tej pozycji i utrzymamy działanie serwera przywracania, abyśmy mogli później wyodrębnić brakujące dane.
Po zakończeniu przywracania upewnijmy się, że nasze dane zostały odzyskane:
Wygląda dobrze. Teraz możemy wyodrębnić te dane do pliku, który wczytamy z powrotem do urządzenia głównego.
Coś jest nie tak – dzieje się tak, ponieważ serwer jest skonfigurowany tak, aby mógł zapisywać pliki tylko w określonej lokalizacji – chodzi o bezpieczeństwo, nie chcemy pozwalać użytkownikom na zapisywanie treści w dowolnym miejscu. Sprawdźmy, gdzie możemy zapisać nasz plik:
Ok, spróbujmy jeszcze raz:
Teraz wygląda znacznie lepiej. Skopiujmy dane do mastera:
Teraz nadszedł czas, aby załadować brakujące wiersze do urządzenia głównego i sprawdzić, czy się udało:
To wszystko, przywróciliśmy nasze brakujące dane.
W poprzedniej sekcji przywróciliśmy utracone dane za pomocą fizycznej kopii zapasowej i zewnętrznego serwera. Co by było, gdybyśmy mieli utworzoną logiczną kopię zapasową? Spójrzmy. Najpierw sprawdźmy, czy mamy logiczną kopię zapasową:
Tak, jest. Teraz nadszedł czas na dekompresję.
Gdy zajrzysz do niego, zobaczysz, że dane są przechowywane w wielowartościowym formacie INSERT. Na przykład:
Wszystko, co musimy teraz zrobić, to wskazać, gdzie znajduje się nasza tabela, a następnie gdzie przechowywane są interesujące nas wiersze. Po pierwsze, znając wzorce mysqldump (upuść tabelę, utwórz nową, wyłącz indeksy, wstaw dane) zastanówmy się, który wiersz zawiera instrukcję CREATE TABLE dla tabeli „sbtest1”:
Teraz, używając metody prób i błędów, musimy dowiedzieć się, gdzie szukać naszych wierszy. Pokażemy Ci ostatnie polecenie, które wymyśliliśmy. Cała sztuczka polega na tym, aby spróbować wydrukować różne zakresy linii za pomocą sed, a następnie sprawdzić, czy ostatnia linia zawiera wiersze bliskie, ale późniejsze niż to, czego szukamy. W poniższym poleceniu szukamy wierszy między 971 (CREATE TABLE) a 993. Prosimy również sed o zakończenie, gdy osiągnie wiersz 994, ponieważ reszta pliku nie jest dla nas interesująca:
Wynik wygląda jak poniżej:
Oznacza to, że nasz zakres wierszy (do wiersza o identyfikatorze 23145) jest bliski. Następnie chodzi o ręczne czyszczenie pliku. Chcemy, aby zaczynał się od pierwszego wiersza, który musimy przywrócić:
I skończ z ostatnim wierszem do przywrócenia:
Musieliśmy przyciąć niektóre niepotrzebne dane (jest to wielowierszowe wstawianie), ale po tym wszystkim mamy plik, który możemy załadować z powrotem do mastera.
Na koniec ostatnia kontrola:
Wszystko w porządku, dane zostały przywrócone.
W takim przypadku nie przejdziemy przez cały proces. Opisaliśmy już, jak zidentyfikować pozycję zdarzenia utraty danych w dziennikach binarnych. Opisaliśmy również, jak zatrzymać opóźnione urządzenie podrzędne i ponownie uruchomić replikację, aż do momentu przed zdarzeniem utraty danych. Wyjaśniliśmy również, jak używać SELECT INTO OUTFILE i LOAD DATA INFILE do eksportowania danych z zewnętrznego serwera i ładowania ich na master. To wszystko, czego potrzebujesz. Dopóki dane nadal znajdują się na opóźnionym urządzeniu podrzędnym, musisz go zatrzymać. Następnie musisz zlokalizować pozycję przed zdarzeniem utraty danych, uruchomić urządzenie podrzędne do tego momentu, a gdy to zrobisz, użyj opóźnionego urządzenia podrzędnego, aby wyodrębnić dane, które zostały usunięte, skopiuj plik do mastera i załaduj go, aby przywrócić dane .
Przywracanie utraconych danych nie jest zabawne, ale jeśli wykonasz kroki, które przeszliśmy na tym blogu, będziesz miał duże szanse na odzyskanie utraconych danych.mysqlbinlog --verbose /var/lib/mysql/binlog.000003 > bin.out### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=999296
### @2=1009782
### @3='96260841950-70557543083-97211136584-70982238821-52320653831-03705501677-77169427072-31113899105-45148058587-70555151875'
### @4='84527471555-75554439500-82168020167-12926542460-82869925404'### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=1
### @2=1006036
### @3='123'
### @4='43683718329-48150560094-43449649167-51455516141-06448225399'
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=2
### @2=1008980
### @3='123'
### @4='05603373460-16140454933-50476449060-04937808333-32421752305'#180427 8:09:21 server id 1 end_log_pos 29600687 CRC32 0x8cfdd6ae Xid = 307686
COMMIT/*!*/;
# at 29600687
#180427 8:09:21 server id 1 end_log_pos 29600752 CRC32 0xb5aa18ba GTID last_committed=42844 sequence_number=42845 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= '0c695e13-4931-11e8-9f2f-080027e8bf1b:55893'/*!*/;
# at 29600752
#180427 8:09:21 server id 1 end_log_pos 29600826 CRC32 0xc7b71da5 Query thread_id=44 exec_time=0 error_code=0
SET TIMESTAMP=1524816561/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
BEGIN
/*!*/;
# at 29600826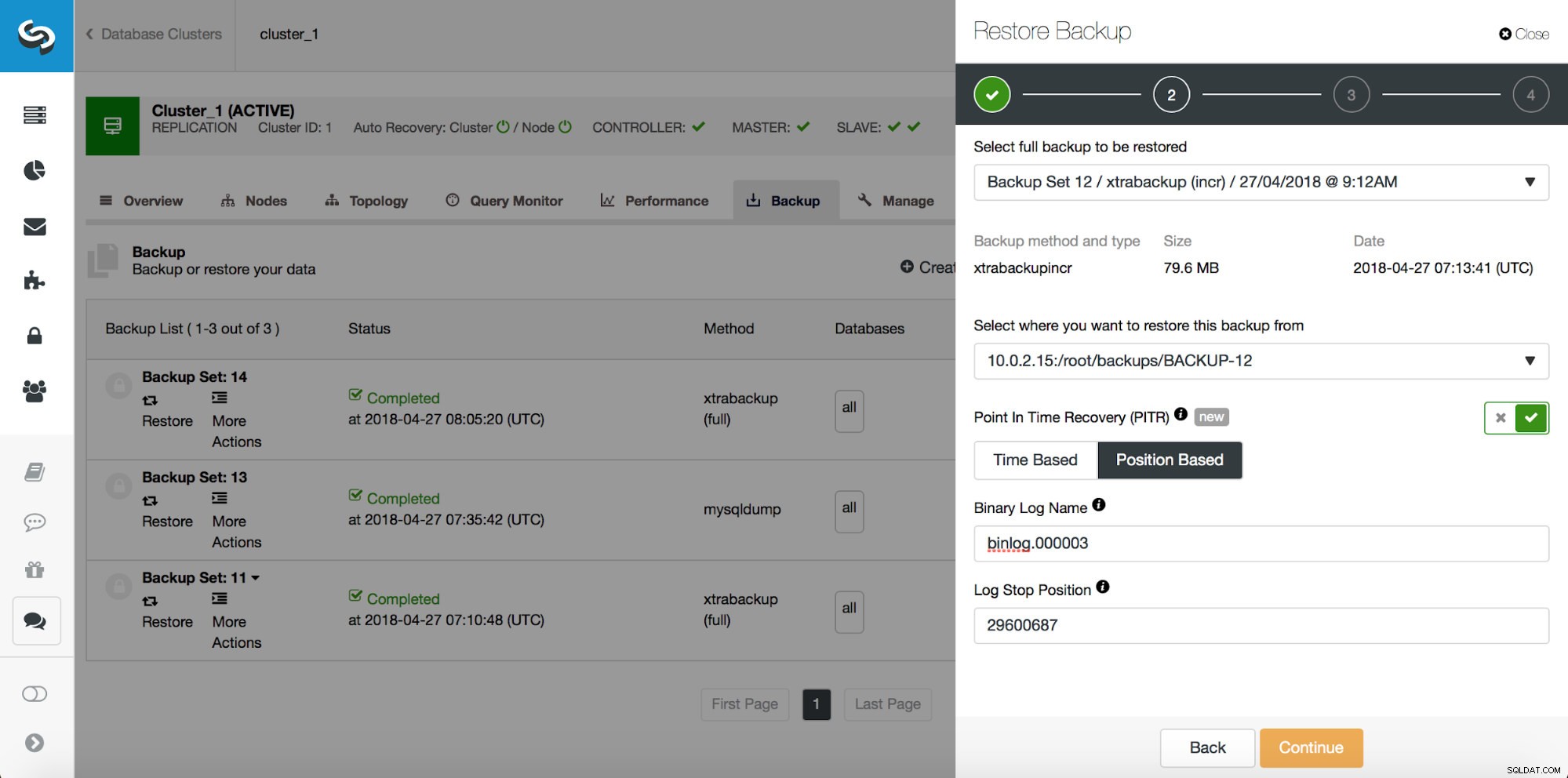
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.03 sec)mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE 'missing.sql';
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statementmysql> SHOW VARIABLES LIKE "secure_file_priv";
+------------------+-----------------------+
| Variable_name | Value |
+------------------+-----------------------+
| secure_file_priv | /var/lib/mysql-files/ |
+------------------+-----------------------+
1 row in set (0.13 sec)mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE '/var/lib/mysql-files/missing.sql';
Query OK, 23145 rows affected (0.05 sec)example@sqldat.com:~# scp /var/lib/mysql-files/missing.sql 10.0.0.101:/var/lib/mysql-files/
missing.sql 100% 1744KB 1.7MB/s 00:00mysql> LOAD DATA INFILE '/var/lib/mysql-files/missing.sql' INTO TABLE sbtest.sbtest1;
Query OK, 23145 rows affected (2.22 sec)
Records: 23145 Deleted: 0 Skipped: 0 Warnings: 0
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Częściowa utrata danych — logiczna kopia zapasowa
example@sqldat.com:~# ls -alh /root/backups/BACKUP-13/
total 5.8G
drwx------ 2 root root 4.0K Apr 27 07:35 .
drwxr-x--- 5 root root 4.0K Apr 27 07:14 ..
-rw-r--r-- 1 root root 2.4K Apr 27 07:35 cmon_backup.metadata
-rw------- 1 root root 5.8G Apr 27 07:35 mysqldump_2018-04-27_071434_complete.sql.gzexample@sqldat.com:~# mkdir /root/restore
example@sqldat.com:~# zcat /root/backups/BACKUP-13/mysqldump_2018-04-27_071434_complete.sql.gz > /root/restore/backup.sqlINSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399'),(2,1008980,'69708345057-48265944193-91002879830-11554672482-35576538285-03657113365-90301319612-18462263634-56608104414-27254248188','05603373460-16140454933-50476449060-04937808333-32421752305')example@sqldat.com:~/restore# grep -n "CREATE TABLE \`sbtest1\`" backup.sql > out
example@sqldat.com:~/restore# cat out
971:CREATE TABLE `sbtest1` (example@sqldat.com:~/restore# sed -n '971,993p; 994q' backup.sql > 1.sql
example@sqldat.com:~/restore# tail -n 1 1.sql | lessINSERT INTO `sbtest1` VALUES (31351,1007187,'23938390896-69688180281-37975364313-05234865797-89299459691-74476188805-03642252162-40036598389-45190639324-97494758464','60596247401-06173974673-08009930825-94560626453-54686757363'),INSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399')(23145,1001595,'37250617862-83193638873-99290491872-89366212365-12327992016-32030298805-08821519929-92162259650-88126148247-75122945670','60801103752-29862888956-47063830789-71811451101-27773551230');example@sqldat.com:~/restore# cat 1.sql | mysql -usbtest -psbtest -h10.0.0.101 sbtest
mysql: [Warning] Using a password on the command line interface can be insecure.mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Częściowa utrata danych, opóźnione urządzenie podrzędne
Wniosek