Galera Cluster zawiera wiele godnych uwagi funkcji, które nie są dostępne w standardowej replikacji MySQL (lub replikacji grupowej); automatyczne przydzielanie węzłów, prawdziwy multi-master z rozwiązywaniem konfliktów i automatycznym przełączaniem awaryjnym. Istnieje również szereg ograniczeń, które mogą potencjalnie wpłynąć na wydajność klastra. Na szczęście, jeśli nie jesteś tego świadomy, istnieją obejścia. A jeśli zrobisz to dobrze, możesz zminimalizować wpływ tych ograniczeń i poprawić ogólną wydajność.
Wcześniej omówiliśmy wiele wskazówek i trików związanych z Galera Cluster, w tym uruchamianie Galera w AWS Cloud. Ten wpis na blogu wyraźnie omawia aspekty wydajności, z przykładami, jak najlepiej wykorzystać Galera.
Ładunek replikacji
Małe wprowadzenie — Galera replikuje zestawy zapisu na etapie zatwierdzania, synchronicznie przesyłając zestawy zapisu z węzła nadawcy do węzłów odbiorczych za pośrednictwem wtyczki replikacji wsrep. Ta wtyczka będzie również certyfikować zestawy zapisu w węzłach odbiorczych. Jeśli proces certyfikacji zakończy się pomyślnie, zwraca klientowi OK w węźle nadawczym i zostanie zastosowany w węzłach odbiorczych w późniejszym czasie asynchronicznie. W przeciwnym razie transakcja zostanie wycofana w węźle nadawczym (zwracając błąd do klienta), a zestawy zapisu, które zostały przesłane do węzłów odbiorczych, zostaną odrzucone.
Zestaw zapisów składa się z operacji zapisu wewnątrz transakcji, która zmienia stan bazy danych. W klastrze Galera autocommit jest domyślnie 1 (włączone). Dosłownie, każda instrukcja SQL wykonana w Galera Cluster zostanie ujęta jako transakcja, chyba że jawnie zaczniesz od BEGIN, START TRANSACTION lub SET autocommit=0. Poniższy diagram ilustruje enkapsulację pojedynczej instrukcji DML w zbiorze zapisów:
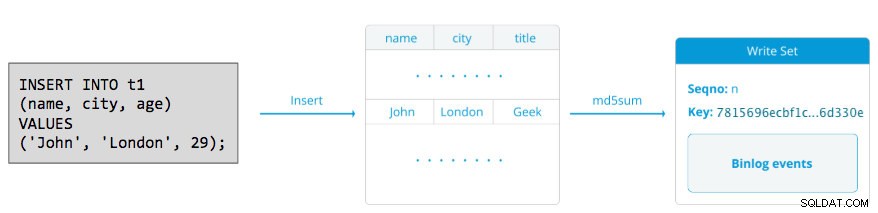
W przypadku DML (INSERT, UPDATE, DELETE...) ładunek zestawu zapisu składa się ze zdarzeń dziennika binarnego dla określonej transakcji, podczas gdy w przypadku DDL (ALTER, GRANT, CREATE...) ładunek zestawu zapisu jest samą instrukcją DDL. W przypadku DML zestaw zapisów będzie musiał być certyfikowany pod kątem konfliktów w węźle odbiorczym, podczas gdy w przypadku DDL (w zależności od wsrep_osu_method , domyślnie TOI), klaster klastra uruchamia instrukcję DDL we wszystkich węzłach w tej samej kolejności całkowitej, blokując inne transakcje przed zatwierdzaniem, gdy DDL jest w toku (zobacz także RSU). Krótko mówiąc, Galera Cluster obsługuje replikację DDL i DML w inny sposób.
Czas podróży w obie strony
Ogólnie rzecz biorąc, następujące czynniki określają, jak szybko Galera może replikować zbiór zapisów z węzła nadawcy do wszystkich węzłów odbiorczych:
- Czas podróży w obie strony (RTT) do najdalszego węzła w klastrze od węzła nadawcy.
- Rozmiar zbioru zapisu do przesłania i certyfikacji pod kątem konfliktu w węźle odbiorczym.
Na przykład, jeśli mamy klaster Galera składający się z trzech węzłów, a jeden z węzłów jest oddalony o 10 milisekund (0,01 sekundy), jest bardzo mało prawdopodobne, że będziesz w stanie zapisać więcej niż 100 razy na sekundę w tym samym wierszu bez konfliktów. Istnieje popularny cytat Marka Callaghana, który dość dobrze opisuje to zachowanie:
„[W klastrze Galera] danego wiersza nie można modyfikować więcej niż raz na RTT”
Aby zmierzyć wartość RTT, po prostu wykonaj polecenie ping na węźle inicjującym do najdalszego węzła w klastrze:
$ ping 192.168.55.173 # the farthest nodePoczekaj kilka sekund (lub minut) i zakończ polecenie. Ostatni wiersz sekcji statystyk ping jest tym, czego szukamy:
--- 192.168.55.172 ping statistics ---
65 packets transmitted, 65 received, 0% packet loss, time 64019ms
rtt min/avg/max/mdev = 0.111/0.431/1.340/0.240 msmaks wartość wynosi 1,340 ms (0,00134 s) i powinniśmy przyjąć tę wartość podczas szacowania minimum transakcji na sekundę (tps) dla tego klastra. średnia wartość wynosi 0,431ms (0,000431s) i możemy użyć do oszacowania średniej Tps podczas min wartość wynosi 0,111ms (0,000111s), której możemy użyć do oszacowania maksimum pok. mdev oznacza rozkład próbek RTT na podstawie średniej. Niższa wartość oznacza bardziej stabilny RTT.
Stąd transakcje na sekundę można oszacować, dzieląc RTT (w sekundach) na 1 sekundę:

Wynik,
- Minimalny tps:1 / 0,00134 (maks. RTT) =746,26 ~ 746 tps
- Średnia liczba punktów na sekundę:1 / 0,000431 (średni czas RTT) =2320,19 ~ 2320 punktów na sekundę
- Maksymalna liczba tps:1 / 0,000111 (min. RTT) =9009.01 ~ 9009 t/s
Zauważ, że jest to tylko szacunkowa ocena wydajności replikacji. Niewiele możemy zrobić, aby to ulepszyć po stronie bazy danych, gdy już wszystko zostanie wdrożone i uruchomione. Z wyjątkiem sytuacji, gdy przenosisz lub migrujesz serwery bazy danych bliżej siebie, aby poprawić RTT między węzłami lub zaktualizować sieciowe urządzenia peryferyjne lub infrastrukturę. Wymagałoby to czasu na konserwację i odpowiedniego planowania.
Podziel duże transakcje
Kolejnym czynnikiem jest wielkość transakcji. Po przekazaniu zapisu nastąpi proces certyfikacji. Certyfikacja to proces mający na celu określenie, czy węzeł może zastosować zestaw zapisów. Galera generuje pseudoklucze MD5 z sumą kontrolną z każdego pełnego wiersza. Koszt certyfikacji zależy od wielkości zbioru zapisów, co przekłada się na szereg unikalnych wyszukiwań kluczy w indeksie certyfikacji (tabela haszująca). Jeśli zaktualizujesz 500 000 wierszy w jednej transakcji, na przykład:
# a 500,000 rows table
mysql> UPDATE mydb.settings SET success = 1;Powyższe wygeneruje pojedynczy zestaw zapisów z 500 000 zdarzeń w dzienniku binarnym. Ten ogromny zbiór nie przekracza wsrep_max_ws_size (domyślnie 2 GB), więc zostanie przeniesiony przez wtyczkę replikacji Galera do wszystkich węzłów w klastrze, poświadczając te 500 000 wierszy w węzłach odbiorczych pod kątem wszelkich konfliktowych transakcji, które nadal znajdują się w kolejce podrzędnej. Na koniec status certyfikacji jest zwracany do wtyczki replikacji grupowej. Im większy rozmiar transakcji, tym większe ryzyko, że będzie ona kolidować z innymi transakcjami pochodzącymi od innego mastera. Konfliktowe transakcje marnują zasoby serwera, a także powodują ogromne wycofanie do węzła nadawcy. Zwróć uwagę, że operacja wycofywania w MySQL jest znacznie wolniejsza i mniej zoptymalizowana niż operacja zatwierdzania.
Powyższa instrukcja SQL może zostać przepisana w bardziej przyjazną dla Galera instrukcję za pomocą prostej pętli, jak w poniższym przykładzie:
(bash)$ for i in {1..500}; do \
mysql -uuser -ppassword -e "UPDATE mydb.settings SET success = 1 WHERE success != 1 LIMIT 1000"; \
sleep 2; \
donePowyższe polecenie powłoki aktualizuje 1000 wierszy na transakcję 500 razy i czeka 2 sekundy między wykonaniami. Możesz również użyć procedury składowanej lub innych środków, aby osiągnąć podobny wynik. Jeśli przepisanie zapytania SQL nie wchodzi w grę, po prostu poinstruuj aplikację, aby wykonała dużą transakcję podczas okresu konserwacji, aby zmniejszyć ryzyko konfliktów.
W przypadku usuwania dużych ilości danych rozważ użycie narzędzia pt-archiver z zestawu Percona Toolkit — zadania o niewielkim wpływie, przeznaczonego tylko do przesyłania dalej, do wycinania starych danych z tabeli bez znacznego wpływu na zapytania OLTP.
Równoległe wątki podrzędne
W Galerze aplikacja jest procesem wielowątkowym. Applier to wątek działający w Galera w celu zastosowania przychodzących zestawów zapisu z innego węzła. Oznacza to, że wszyscy odbiorcy mogą jednocześnie wykonywać wiele operacji DML, które pochodzą bezpośrednio z węzła nadawcy (nadrzędnego). Replikacja równoległa Galera jest stosowana do transakcji tylko wtedy, gdy jest to bezpieczne. Zwiększa prawdopodobieństwo synchronizacji węzła z węzłem nadawcy. Jednak prędkość replikacji jest nadal ograniczona do czasu RTT i rozmiaru zestawu zapisu.
Aby jak najlepiej to wykorzystać, musimy wiedzieć dwie rzeczy:
- Liczba rdzeni serwera.
- Wartość wsrep_cert_deps_distance status.
Stan wsrep_cert_deps_distance mówi nam potencjalny stopień zrównoleglenia. Jest to wartość średniej odległości między najwyższą i najniższą wartością seqno, którą można ewentualnie zastosować równolegle. Możesz użyć wsrep_cert_deps_distance zmienna statusu określająca maksymalną możliwą liczbę wątków podrzędnych. Zwróć uwagę, że jest to średnia wartość w czasie. Dlatego, aby uzyskać dobrą wartość, musisz trafić do klastra z operacjami zapisu przez obciążenie testowe lub test porównawczy, aż zobaczysz stabilną wartość.
Aby uzyskać liczbę rdzeni, możesz po prostu użyć następującego polecenia:
$ grep -c processor /proc/cpuinfo
4Idealnie, 2, 3 lub 4 wątki aplikacji slave na rdzeń procesora to dobry początek. Dlatego minimalna wartość wątków podrzędnych powinna wynosić 4 x liczba rdzeni procesora i nie może przekraczać wsrep_cert_deps_distance wartość:
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cert_deps_distance';
+--------------------------+----------+
| Variable_name | Value |
+--------------------------+----------+
| wsrep_cert_deps_distance | 48.16667 |
+--------------------------+----------+Możesz kontrolować liczbę wątków aplikacji podrzędnych za pomocą wsrep_slave_thread zmienny. Mimo że jest to zmienna dynamiczna, tylko zwiększenie liczby miałoby natychmiastowy efekt. Jeśli zmniejszysz wartość dynamicznie, zajmie to trochę czasu, zanim wątek aplikatora zakończy pracę po zakończeniu stosowania. Zalecana wartość wynosi od 16 do 48:
mysql> SET GLOBAL wsrep_slave_threads = 48;Zwróć uwagę, że aby działały równoległe wątki podrzędne, należy ustawić następujące elementy (co jest zwykle wstępnie skonfigurowane dla Galera Cluster):
innodb_autoinc_lock_mode=2Pamięć podręczna Galery (gcache)
Galera używa wstępnie przydzielonego pliku o określonym rozmiarze o nazwie gcache, w którym węzeł Galera przechowuje kopię zestawów zapisu w stylu bufora kołowego. Domyślnie jego rozmiar to 128 MB, co jest dość małe. Incremental State Transfer (IST) to metoda przygotowania łącznika poprzez wysłanie tylko brakujących zbiorów zapisów dostępnych w gcache dawcy. IST jest szybszy niż transfer migawki stanu (SST), nie blokuje i nie ma znaczącego wpływu na wydajność dawcy. Powinna być preferowaną opcją, gdy tylko jest to możliwe.
IST można osiągnąć tylko wtedy, gdy wszystkie zmiany pominięte przez dołączającego nadal znajdują się w pliku gcache dawcy. Zalecanym ustawieniem jest to, aby był tak duży, jak cały zbiór danych MySQL. Jeśli miejsce na dysku jest ograniczone lub kosztowne, określenie odpowiedniego rozmiaru pamięci podręcznej gcache ma kluczowe znaczenie, ponieważ może to wpłynąć na wydajność synchronizacji danych między węzłami Galera.
Poniższe zestawienie da nam wyobrażenie o ilości danych replikowanych przez Galerę. Uruchom następującą instrukcję na jednym z węzłów Galera w godzinach szczytu (testowane na MariaDB>10.0 i PXC>5.6, galera>3.x):
mysql> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;
+--------+---------+-----------------+-----------------------+
| MB/min | MB/hour | gcache Size(MB) | Time to full(minutes) |
+--------+---------+-----------------+-----------------------+
| 7.95 | 477.00 | 128 | 16.10 |
+--------+---------+-----------------+-----------------------+
Możemy oszacować, że węzeł Galera może mieć około 16 minut przestoju, bez konieczności dołączania SST (chyba że Galera nie może określić stanu dołączenia). Jeśli to za mało i masz wystarczająco dużo miejsca na dysku na swoich węzłach, możesz zmienić wsrep_provider_options="gcache.size=
Zaleca się również użycie gcache.recover=yes w wsrep_provider_options (Galera> 3.19), gdzie Galera spróbuje przywrócić plik gcache do stanu używalności podczas uruchamiania, zamiast go usunąć, zachowując w ten sposób możliwość posiadania IST i unikając SST w jak największym stopniu. Codership i Percona szczegółowo opisali to na swoich blogach. IST jest zawsze najlepszą metodą synchronizacji po ponownym dołączeniu węzła do klastra. Jest o 50% szybszy niż xtrabackup lub mariabackup i 5x szybszy niż mysqldump.
Asynchroniczne urządzenie podrzędne
Węzły Galera są ściśle powiązane, a wydajność replikacji jest tak wysoka, jak w przypadku najwolniejszego węzła. Galera używa mechanizmu kontroli przepływu, aby kontrolować przepływ replikacji między członkami i eliminować wszelkie opóźnienia. Replikacja może przebiegać szybko lub wolno na każdym węźle i jest dostosowywana automatycznie przez Galerę. Jeśli chcesz wiedzieć o kontroli przepływu, przeczytaj ten wpis na blogu autorstwa Jaya Janssena z Percony.
W większości przypadków nieuniknione są ciężkie operacje, takie jak długotrwała analityka (intensywna odczyt) i kopie zapasowe (intensywne odczytywanie, blokowanie), co może potencjalnie obniżyć wydajność klastra. Najlepszym sposobem na wykonanie tego typu zapytań jest wysłanie ich do luźno powiązanego serwera replik, na przykład asynchronicznego urządzenia podrzędnego.
Asynchroniczne urządzenie podrzędne replikuje się z węzła Galera przy użyciu standardowego protokołu replikacji asynchronicznej MySQL. Nie ma ograniczeń co do liczby urządzeń podrzędnych, które można podłączyć do jednego węzła Galera, możliwe jest również połączenie go z pośrednim masterem. Operacje MySQL wykonywane na tym serwerze nie wpłyną na wydajność klastra, z wyjątkiem początkowej fazy synchronizacji, w której należy wykonać pełną kopię zapasową w węźle Galera w celu przygotowania urządzenia podrzędnego przed ustanowieniem łącza replikacji (chociaż ClusterControl pozwala na zbudowanie asynchronicznej najpierw podrzędny z istniejącej kopii zapasowej, przed podłączeniem go do klastra).
GTID (Global Transaction Identifier) zapewnia lepsze mapowanie transakcji między węzłami i jest obsługiwany w MySQL 5.6 i MariaDB 10.0. Dzięki GTID operacja przełączania awaryjnego z urządzenia podrzędnego na inny węzeł nadrzędny (inny węzeł Galera) jest uproszczona, bez konieczności określania dokładnego pliku dziennika i pozycji. Galera ma również własną implementację GTID, ale te dwa są od siebie niezależne.
Skalowanie asynchronicznego urządzenia podrzędnego to jedno kliknięcie, jeśli używasz funkcji ClusterControl -> Dodaj funkcję podrzędną replikacji:
Zwróć uwagę, że logi binarne muszą być włączone na urządzeniu głównym (wybranym węźle Galera), zanim będziemy mogli kontynuować tę konfigurację. W poprzednim poście omówiliśmy również sposób ręczny.
Poniższy zrzut ekranu z ClusterControl przedstawia topologię klastra, ilustruje on naszą architekturę Galera Cluster z asynchronicznym urządzeniem podrzędnym:
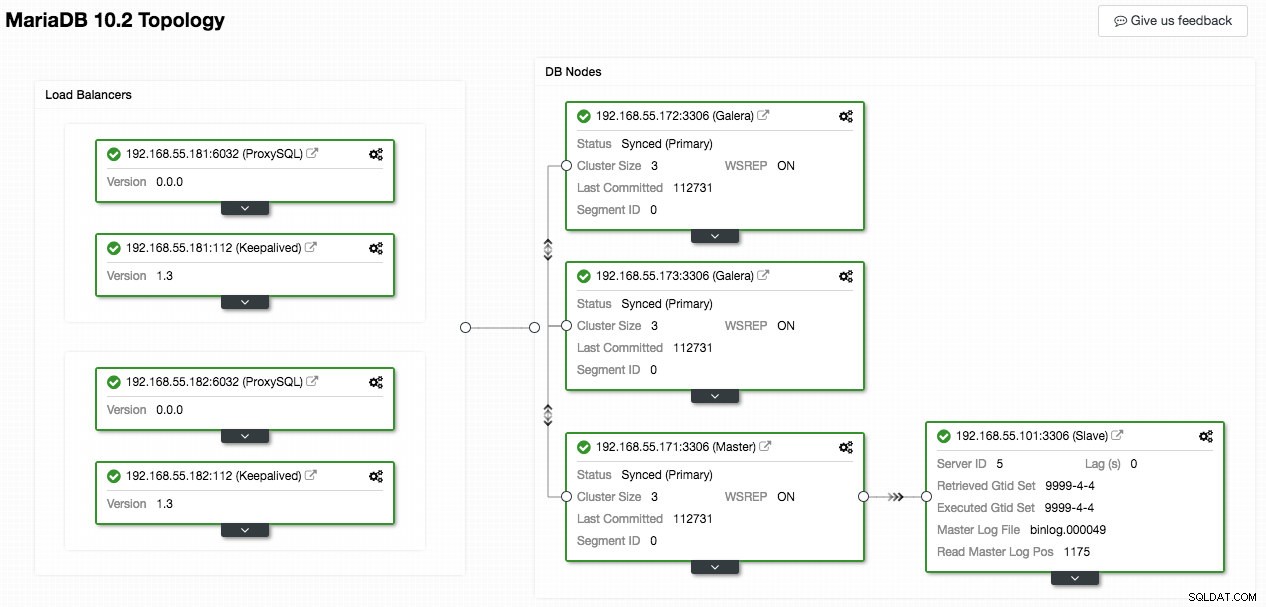
ClusterControl automatycznie wykrywa topologię i generuje super fajny diagram, jak powyżej. Możesz także wykonywać zadania administracyjne bezpośrednio z tej strony, klikając ikonę koła zębatego w prawym górnym rogu każdego pola.
Zwrotny serwer proxy obsługujący SQL
ProxySQL i MariaDB MaxScale to inteligentne odwrotne serwery proxy, które rozumieją protokół MySQL i mogą działać jako brama, router, system równoważenia obciążenia i zapora sieciowa przed węzłami Galera. Z pomocą dostawcy wirtualnego adresu IP, takiego jak LVS lub Keepalived, i łącząc to z technologią replikacji multi-master Galera, możemy uzyskać wysoce dostępną usługę bazy danych, eliminując wszystkie możliwe pojedyncze punkty awarii (SPOF) z punktu aplikacji widzenia. To z pewnością poprawi dostępność i niezawodność całej architektury.
Kolejną zaletą tego podejścia jest możliwość monitorowania, przepisywania lub przekierowywania przychodzących zapytań SQL w oparciu o zestaw reguł, zanim dotrą do rzeczywistego serwera bazy danych, minimalizując zmiany po stronie aplikacji lub klienta i kierując zapytania do bardziej odpowiedni węzeł dla optymalnej wydajności. Ryzykownym zapytaniom Galera, takim jak LOCK TABLES i FLUSH TABLES WITH READ LOCK, można zapobiegać z wyprzedzeniem, zanim spowodują spustoszenie w systemie, podczas gdy wpływają na zapytania, takie jak zapytania „hotspot” (wiersz, do którego różne zapytania chcą uzyskać dostęp w tym samym czasie). zostać przepisany lub przekierowany do pojedynczego węzła Galera, aby zmniejszyć ryzyko konfliktów transakcji. W przypadku ciężkich zapytań tylko do odczytu, takich jak OLAP lub kopia zapasowa, możesz skierować je do asynchronicznego urządzenia podrzędnego, jeśli takie masz.
Odwrotny serwer proxy monitoruje również stan bazy danych, zapytania i zmienne, aby zrozumieć zmiany topologii i podjąć dokładną decyzję o routingu do serwerów zaplecza. Pośrednio centralizuje monitorowanie węzłów i przegląd klastrów bez konieczności regularnego sprawdzania każdego węzła Galera. Poniższy zrzut ekranu przedstawia panel monitorowania ProxySQL w ClusterControl:
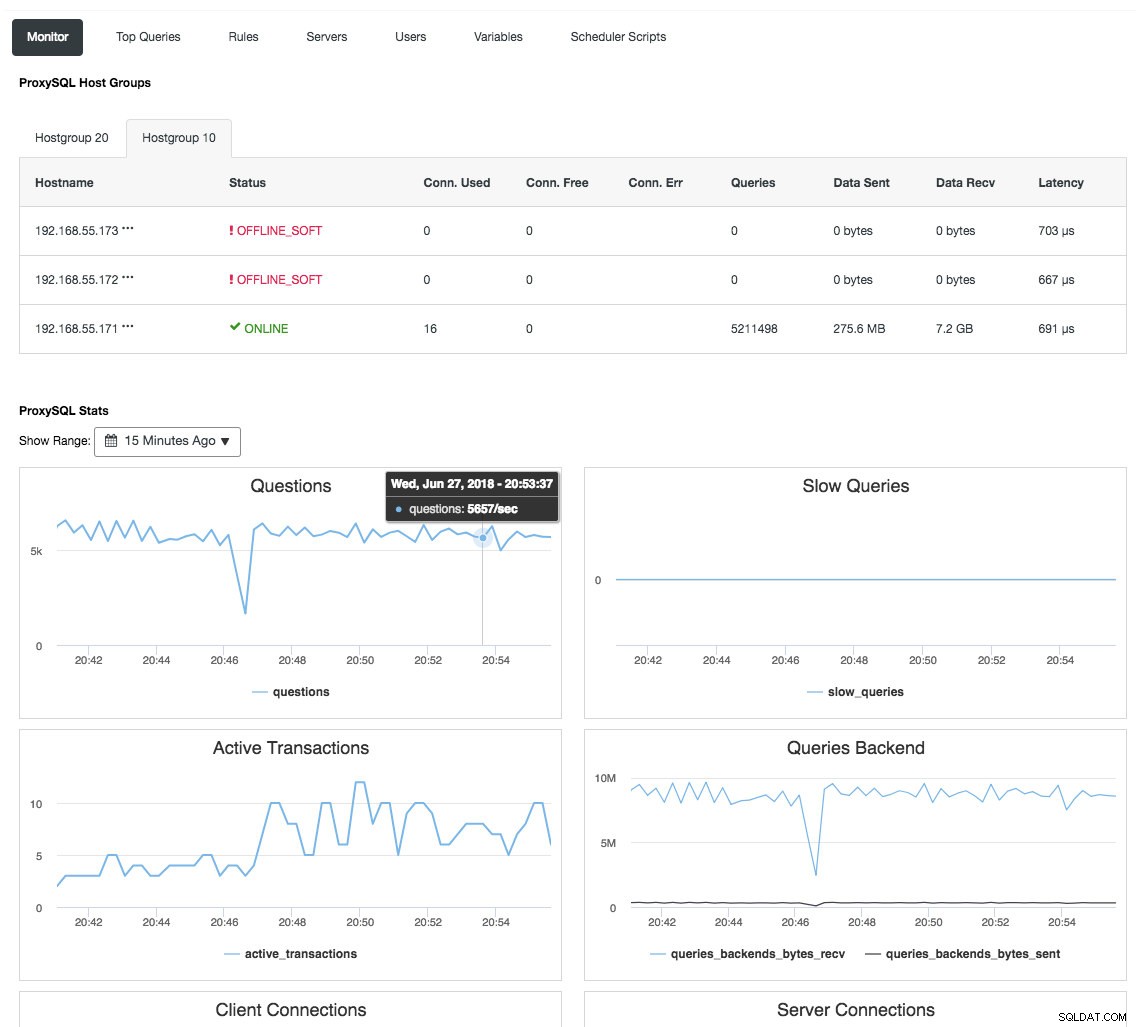
Istnieje również wiele innych korzyści, które system równoważenia obciążenia może przynieść, aby znacząco ulepszyć Galera Cluster, jak szczegółowo omówiono w tym poście na blogu, Zostań administratorem ClusterControl:tworzenie wysokiej jakości komponentów bazy danych za pomocą systemów równoważenia obciążenia.
Ostateczne myśli
Dzięki dobremu zrozumieniu wewnętrznego działania Galera Cluster możemy obejść niektóre ograniczenia i ulepszyć usługę bazy danych. Miłego klastrowania!



