Schemat bazy danych nie jest czymś wyrytym w kamieniu. Jest przeznaczony do konkretnej aplikacji, ale wtedy wymagania mogą i zwykle ulegają zmianie. Do aplikacji dodawane są nowe moduły i funkcjonalności, gromadzone jest więcej danych, wykonywana jest refaktoryzacja kodu i modelu danych. W związku z tym konieczność modyfikacji schematu bazy danych w celu dostosowania do tych zmian; dodawanie lub modyfikowanie kolumn, tworzenie nowych tabel lub partycjonowanie dużych. Zapytania również się zmieniają, ponieważ programiści dodają nowe sposoby interakcji użytkowników z danymi – nowe zapytania mogą wykorzystywać nowe, wydajniejsze indeksy, więc spieszymy się z ich tworzeniem, aby zapewnić aplikacji najlepszą wydajność bazy danych.
Jak więc najlepiej podejść do zmiany schematu? Jakie narzędzia są przydatne? Jak zminimalizować wpływ na produkcyjną bazę danych? Jakie są najczęstsze problemy z projektowaniem schematów? Jakie narzędzia mogą pomóc Ci pozostać na szczycie schematu? W tym poście na blogu przedstawimy krótki przegląd zmian w schemacie w MySQL i MariaDB. Należy pamiętać, że nie będziemy omawiać zmian w schemacie w kontekście Galera Cluster. W poprzednich wpisach na blogu omówiliśmy już całkowitą izolację zamówień, aktualizacje schematu kroczącego i wskazówki, jak zminimalizować wpływ RSU. Omówimy również wskazówki i triki związane z projektowaniem schematu oraz sposób, w jaki ClusterControl może pomóc Ci być na bieżąco ze wszystkimi zmianami schematu.
Rodzaje zmian schematów
Najpierw najważniejsze. Zanim zagłębimy się w temat, musimy zrozumieć, w jaki sposób MySQL i MariaDB wykonują zmiany w schemacie. Widzisz, jedna zmiana schematu nie jest równa innej zmianie schematu.
Być może słyszeliście o zmianach w Internecie, zmianach natychmiastowych lub zmianach na miejscu. Wszystko to jest efektem prowadzonych prac nad zminimalizowaniem wpływu zmian schematu na produkcyjną bazę danych. Historycznie prawie wszystkie zmiany w schemacie były blokowane. Jeśli wykonałeś zmianę schematu, wszystkie zapytania zaczną się nawarstwiać, czekając na zakończenie ALTER. Oczywiście stanowiło to poważne problemy w przypadku wdrożeń produkcyjnych. Jasne, ludzie natychmiast zaczynają szukać obejścia i omówimy je w dalszej części tego bloga, ponieważ nawet dzisiaj są one nadal aktualne. Ale także rozpoczęto prace nad poprawą zdolności MySQL do uruchamiania DDL (języka definicji danych) bez większego wpływu na inne zapytania.
Natychmiastowe zmiany
Czasami nie trzeba dotykać żadnych danych w przestrzeni tabel, ponieważ wystarczy zmienić metadane. Przykładem będzie upuszczenie indeksu lub zmiana nazwy kolumny. Takie operacje są szybkie i wydajne. Zazwyczaj ich wpływ jest ograniczony. Nie pozostaje to jednak bez wpływu. Czasami zmiana metadanych zajmuje kilka sekund i taka zmiana wymaga uzyskania blokady metadanych. Ta blokada jest na podstawie tabeli i może blokować inne operacje, które mają być wykonane na tej tabeli. Zobaczysz to jako wpisy „Oczekiwanie na blokadę metadanych tabeli” na liście procesów.
Przykładem takiej zmiany może być natychmiastowa ADD COLUMN, wprowadzona w MariaDB 10.3 i MySQL 8.0. Daje to możliwość wykonania tej dość popularnej zmiany schematu bez żadnych opóźnień. Zarówno MariaDB, jak i Oracle zdecydowały się na dołączenie kodu z Tencent Game, który pozwala błyskawicznie dodać nową kolumnę do tabeli. Dzieje się tak pod pewnymi określonymi warunkami; kolumna musi być dodana jako ostatnia, indeksy pełnotekstowe nie mogą istnieć w tabeli, format wiersza nie może być skompresowany - więcej informacji o tym, jak działa natychmiastowe dodawanie kolumny, znajdziesz w dokumentacji MariaDB. W przypadku MySQL jedyne oficjalne odniesienie można znaleźć na blogu mysqlserverteam.com, chociaż istnieje błąd w celu aktualizacji oficjalnej dokumentacji.
Zmiany na miejscu
Niektóre zmiany wymagają modyfikacji danych w przestrzeni tabel. Takie modyfikacje można wykonać na samych danych i nie ma potrzeby tworzenia tymczasowej tabeli z nową strukturą danych. Takie zmiany zazwyczaj (choć nie zawsze) umożliwiają wykonywanie innych zapytań dotykających tabelę podczas zmiany schematu. Przykładem takiej operacji jest dodanie do tabeli nowego indeksu pomocniczego. Ta operacja zajmie trochę czasu, ale pozwoli na wykonanie DML.
Przebudowa tabeli
Jeśli nie można dokonać zmiany w miejscu, InnoDB utworzy tymczasową tabelę o nowej, pożądanej strukturze. Następnie skopiuje istniejące dane do nowej tabeli. Ta operacja jest najdroższa i prawdopodobnie (choć nie zawsze tak się dzieje) blokuje DML. W rezultacie taka zmiana schematu jest bardzo trudna do wykonania na dużej tabeli na samodzielnym serwerze, bez pomocy zewnętrznych narzędzi - zazwyczaj nie możesz sobie pozwolić na blokowanie bazy danych na długie minuty, a nawet godziny. Przykładem takiej operacji może być zmiana typu danych kolumny, np. z INT na VARCHAR.
Zmiany schematu i replikacja
Ok, więc wiemy, że InnoDB zezwala na zmiany w schemacie online i jeśli zajrzymy do dokumentacji MySQL, zobaczymy, że większość zmian w schemacie (przynajmniej te najczęstsze) można wykonać online. Jaki jest powód poświęcania godzin rozwoju na tworzenie narzędzi do zmiany schematów online, takich jak gh-ost? Możemy zaakceptować, że zmiana schematu pt-online jest pozostałością starych, złych czasów, ale gh-ost to nowe oprogramowanie.
Odpowiedź jest złożona. Istnieją dwa główne problemy.
Po pierwsze, po rozpoczęciu zmiany schematu nie masz nad nią kontroli. Możesz go przerwać, ale nie możesz go wstrzymać. Nie możesz tego dławić. Jak możesz sobie wyobrazić, przebudowanie tabeli jest kosztowną operacją i nawet jeśli InnoDB pozwala na wykonanie DML, dodatkowe obciążenie I/O z DDL wpływa na wszystkie inne zapytania i nie ma możliwości ograniczenia tego wpływu do poziomu, który jest akceptowalny dla aplikacji.
Drugim, jeszcze poważniejszym problemem, jest replikacja. Jeśli wykonasz operację bez blokowania, która wymaga przebudowy tabeli, rzeczywiście nie zablokuje DML, ale dotyczy to tylko mastera. Załóżmy, że wykonanie takiego DDL zajęło 30 minut — prędkość ALTER zależy od sprzętu, ale dość często zdarza się, że takie czasy wykonania występują na tabelach o rozmiarze 20 GB. Jest on następnie replikowany na wszystkie urządzenia podrzędne i od momentu uruchomienia DDL na tych urządzeniach podrzędnych replikacja będzie czekać na jej zakończenie. Nie ma znaczenia, czy używasz MySQL czy MariaDB, czy masz replikację wielowątkową. Niewolnicy będą lagować - będą czekać te 30 minut na zakończenie DDL, zanim zaczną stosować pozostałe zdarzenia binlogu. Jak można sobie wyobrazić, 30 minut lagów (czasem nawet 30 sekund będzie niedopuszczalne - wszystko zależy od aplikacji) jest czymś, co uniemożliwia wykorzystanie tych niewolników do skalowania. Oczywiście istnieją obejścia — możesz dokonywać zmian schematu od dołu do góry łańcucha replikacji, ale to poważnie ogranicza twoje możliwości. Zwłaszcza w przypadku korzystania z replikacji opartej na wierszach w ten sposób można wykonywać tylko zgodne zmiany schematu. Kilka przykładów ograniczeń replikacji opartej na wierszach; nie możesz usunąć żadnej kolumny, która nie jest ostatnią, nie możesz dodać kolumny na pozycję inną niż ostatnia. Nie możesz również zmienić typu kolumny (na przykład INT -> VARCHAR).
Jak widać, replikacja zwiększa złożoność sposobu przeprowadzania zmian w schemacie. Operacje, które nie są blokowane na samodzielnym hoście, stają się blokowane podczas wykonywania na urządzeniach podrzędnych. Rzućmy okiem na kilka metod, których możesz użyć, aby zminimalizować wpływ zmian w schemacie.
Narzędzia zmiany schematu online
Jak wspomnieliśmy wcześniej, istnieją narzędzia, których zadaniem jest dokonywanie zmian w schemacie. Najpopularniejsze z nich to pt-online-schema-change stworzony przez Perconę i gh-ost, stworzony przez GitHub. W serii wpisów na blogu porównaliśmy je i omówiliśmy, w jaki sposób można użyć gh-ost do wprowadzania zmian w schemacie oraz w jaki sposób można ograniczyć i ponownie skonfigurować trwającą migrację. Tutaj nie będziemy wchodzić w szczegóły, ale nadal chcielibyśmy wspomnieć o niektórych najważniejszych aspektach korzystania z tych narzędzi. Na początek zmiana schematu wykonana za pomocą pt-osc lub gh-ost nastąpi na wszystkich węzłach bazy danych jednocześnie. Nie ma żadnego opóźnienia, jeśli chodzi o to, kiedy zmiana zostanie zastosowana. Dzięki temu można używać tych narzędzi nawet w przypadku zmian schematu, które są niezgodne z replikacją opartą na wierszach. Dokładne mechanizmy tego, jak te narzędzia śledzą zmiany w tabeli, są różne (wyzwalacze w pt-osc vs. binlog parsing w gh-ost), ale główna idea jest taka sama - tworzona jest nowa tabela z pożądanym schematem, a istniejące dane są skopiowane ze starej tabeli. W międzyczasie DML są śledzone (w jedną lub drugą stronę) i stosowane do nowej tabeli. Po migracji wszystkich danych nazwy tabel są zmieniane, a nowa tabela zastępuje starą. Jest to operacja atomowa, więc nie jest widoczna dla aplikacji. Oba narzędzia mają opcję dławienia obciążenia i wstrzymywania operacji. Gh-ost może zatrzymać całą aktywność, pt-osc tylko może zatrzymać proces kopiowania danych między starą a nową tabelą - wyzwalacze pozostaną aktywne i będą nadal duplikować dane, co zwiększa obciążenie. Ze względu na tabelę zmiany nazwy, oba narzędzia mają pewne ograniczenia dotyczące kluczy obcych - nieobsługiwane przez gh-ost, częściowo obsługiwane przez pt-osc albo przez zwykłą ALTER, co może powodować opóźnienia w replikacji (niewykonalne, jeśli tablica podrzędna jest duża) lub przez porzucenie starej tabeli przed zmianą nazwy nowej - jest to niebezpieczne, ponieważ nie ma możliwości wycofania, jeśli z jakiegoś powodu dane nie zostały poprawnie skopiowane do nowej tabeli. Wyzwalacze są również trudne do obsługi.
Nie są obsługiwane w gh-ost, pt-osc w MySQL 5.7 i nowszych mają ograniczoną obsługę tabel z istniejącymi wyzwalaczami. Innymi ważnymi ograniczeniami narzędzi zmiany schematu online jest to, że w tabeli musi istnieć klucz unikalny lub klucz podstawowy. Służy do identyfikowania wierszy do skopiowania między starymi a nowymi tabelami. Te narzędzia są również znacznie wolniejsze niż bezpośrednie ALTER - zmiana, która zajmuje godziny podczas działania ALTER, może zająć kilka dni, jeśli jest wykonywana za pomocą pt-osc lub gh-ost.
Z drugiej strony, jak wspomnieliśmy, o ile wymagania są spełnione, a ograniczenia nie wchodzą w grę, wszystkie zmiany schematu można uruchamiać za pomocą jednego z narzędzi. Wszystko będzie się działo w tym samym czasie na wszystkich hostach, dzięki czemu nie musisz się martwić o kompatybilność. Masz również pewien poziom kontroli nad sposobem wykonywania procesu (mniej w pt-osc, znacznie więcej w gh-ost).
Możesz zmniejszyć wpływ zmiany schematu, możesz je wstrzymać i pozwolić im działać tylko pod nadzorem, możesz przetestować zmianę przed jej faktycznym wykonaniem. Możesz nakazać im śledzenie opóźnienia replikacji i wstrzymanie w przypadku wykrycia wpływu. To sprawia, że te narzędzia są naprawdę świetnym dodatkiem do arsenału DBA podczas pracy z replikacją MySQL.
Stałe zmiany schematu
Zazwyczaj administrator baz danych używa jednego z narzędzi zmiany schematu online. Ale jak omówiliśmy wcześniej, w pewnych okolicznościach nie można ich użyć, a bezpośrednia zmiana jest jedyną realną opcją. Jeśli mówimy o samodzielnym MySQL, nie masz wyboru - jeśli zmiana jest nieblokująca, to dobrze. Jeśli tak nie jest, cóż, nic nie możesz na to poradzić. Ale przecież nie tak wiele osób uruchamia MySQL jako pojedyncze instancje, prawda? Co powiesz na replikację? Jak omówiliśmy wcześniej, bezpośrednia zmiana na urządzeniu głównym nie jest możliwa – w większości przypadków spowoduje to opóźnienie w urządzeniu podrzędnym, co może być nie do przyjęcia. Można jednak dokonać zmiany w sposób kroczący. Możesz zacząć od niewolników, a gdy zmiana zostanie zastosowana na wszystkich z nich, wypromować jednego z niewolników jako nowego mistrza, zdegradować starego mistrza do niewolnika i wprowadzić na nim zmianę. Jasne, zmiana musi być zgodna, ale prawdę mówiąc, najczęstszymi przypadkami, w których nie można użyć zmian schematu online, jest brak klucza podstawowego lub unikalnego. We wszystkich innych przypadkach istnieje pewne obejście, zwłaszcza w przypadku zmiany schematu pt-online, ponieważ gh-ost ma bardziej twarde ograniczenia. Jest to obejście, które nazwałbyś „takie” lub „dalekie od ideału”, ale sprawdzi się, jeśli nie masz innej opcji do wyboru. Co ważne, większości ograniczeń można ominąć, monitorując schemat i wyłapując problemy, zanim tabela się powiększy. Nawet jeśli ktoś utworzy tabelę bez klucza podstawowego, nie jest problemem uruchomienie bezpośredniej zmiany, która zajmuje pół sekundy lub mniej, ponieważ tabela jest prawie pusta.
Jeśli się rozwinie, stanie się to poważnym problemem, ale to DBA będzie musiał wyłapać tego rodzaju problemy, zanim faktycznie zaczną stwarzać problemy. Omówimy kilka wskazówek i wskazówek, jak upewnić się, że wykryjesz takie problemy na czas. Udostępnimy również ogólne wskazówki dotyczące projektowania schematów.
Wskazówki i wskazówki
Projektowanie schematu
Jak pokazaliśmy w tym poście, narzędzia do zmiany schematu online są bardzo ważne podczas pracy z konfiguracją replikacji, dlatego ważne jest, aby upewnić się, że schemat jest zaprojektowany w taki sposób, aby nie ograniczał możliwości dokonywania zmian schematu. Istnieją trzy ważne aspekty. Po pierwsze, klucz podstawowy lub unikalny musi istnieć - musisz upewnić się, że w Twojej bazie danych nie ma tabel bez klucza podstawowego. Powinieneś to regularnie monitorować, w przeciwnym razie może to stać się poważnym problemem w przyszłości. Po drugie, powinieneś poważnie rozważyć, czy używanie kluczy obcych jest dobrym pomysłem. Jasne, mają swoje zastosowania, ale zwiększają również obciążenie bazy danych i mogą sprawić, że korzystanie z narzędzi zmiany schematu online będzie problematyczne. Aplikacja może wymusić relacje. Nawet jeśli oznacza to więcej pracy, nadal może być lepszym pomysłem niż zacząć używać kluczy obcych i poważnie ograniczać się do tego, jakie rodzaje zmian schematu można wykonać. Po trzecie, wyzwalacze. Ta sama historia, co w przypadku kluczy obcych. Są fajną funkcją, ale mogą stać się ciężarem. Musisz poważnie zastanowić się, czy korzyści z ich używania przeważają nad ograniczeniami, jakie stwarzają.
Śledzenie zmian w schemacie
Zarządzanie zmianą schematu to nie tylko uruchamianie zmian schematu. Musisz także pozostać na szczycie swojej struktury schematu, zwłaszcza jeśli nie jesteś jedyną osobą dokonującą zmian.
ClusterControl zapewnia użytkownikom narzędzia do śledzenia niektórych z najczęstszych problemów związanych z projektowaniem schematów. Może pomóc w śledzeniu tabel, które nie mają kluczy podstawowych:
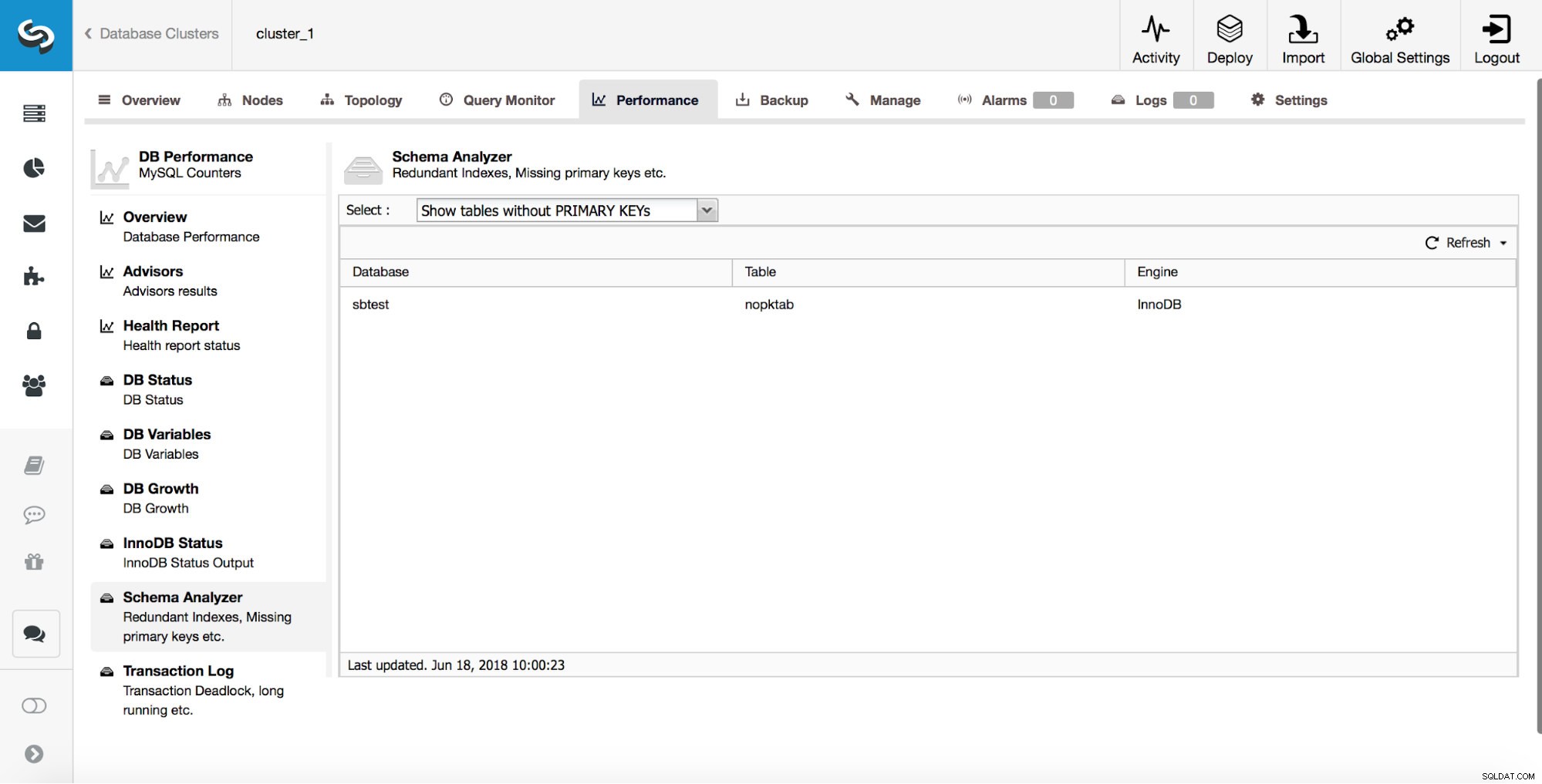
Jak wspomnieliśmy wcześniej, wczesne przechwycenie takich tabel jest bardzo ważne, ponieważ klucze podstawowe muszą być dodawane za pomocą funkcji direct alter.
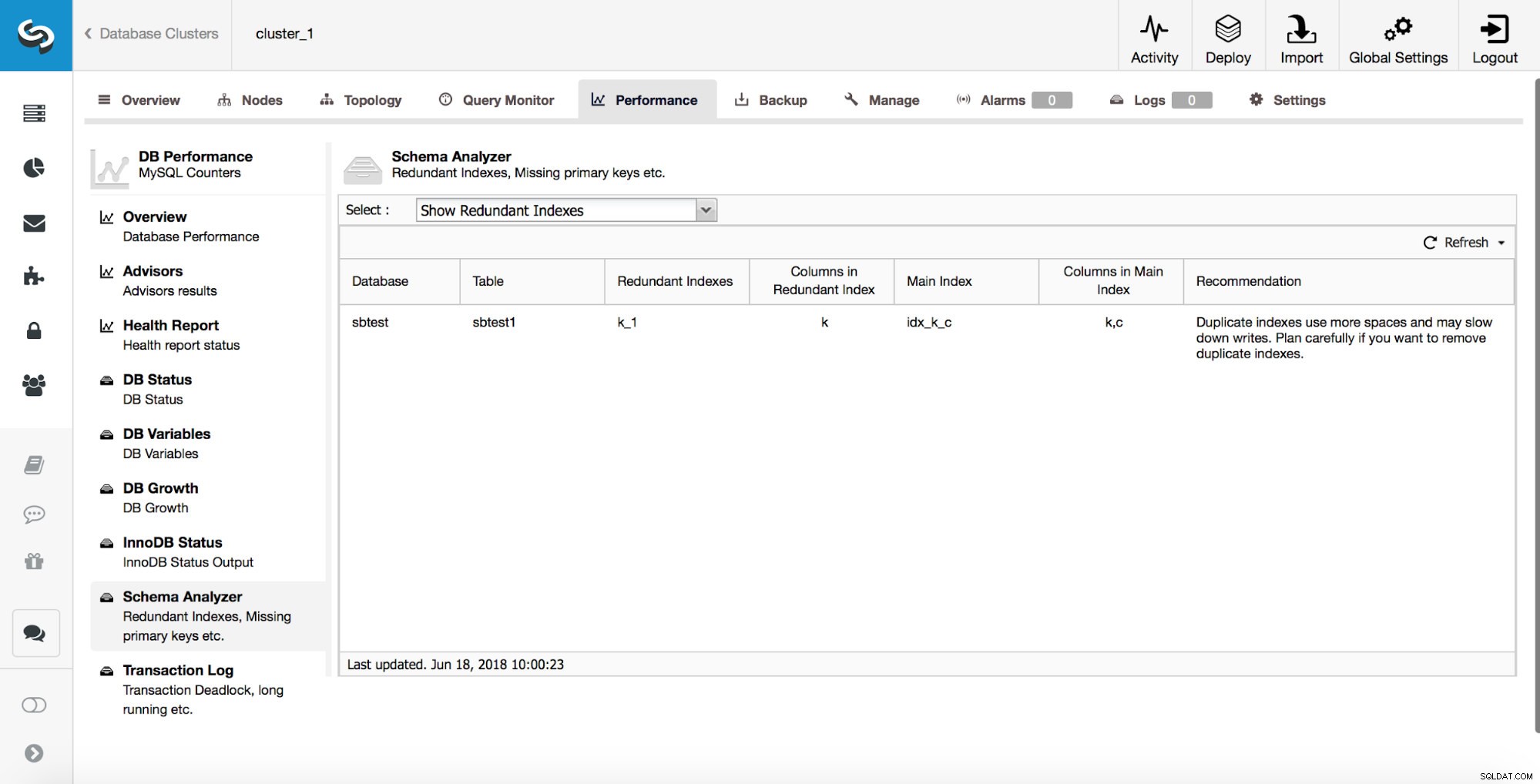
ClusterControl może również pomóc w śledzeniu zduplikowanych indeksów. Zazwyczaj nie chcesz mieć wielu zbędnych indeksów. W powyższym przykładzie widać, że jest indeks na (k, c) i jest też indeks na (k). Każde zapytanie, które może używać indeksu utworzonego na kolumnie „k”, może również używać indeksu złożonego utworzonego na kolumnach (k, c). Są przypadki, w których korzystne jest zachowanie zbędnych indeksów, ale trzeba do tego podchodzić indywidualnie. Począwszy od MySQL 8.0, możliwe jest szybkie sprawdzenie, czy indeks jest naprawdę potrzebny, czy nie. Możesz sprawić, że zbędny indeks będzie „niewidoczny”, uruchamiając:
ALTER TABLE sbtest.sbtest1 ALTER INDEX k_1 INVISIBLE;Spowoduje to, że MySQL zignoruje ten indeks, a dzięki monitoringowi możesz sprawdzić, czy nie miało to negatywnego wpływu na wydajność bazy danych. Jeśli przez jakiś czas wszystko działa zgodnie z planem (kilka dni lub nawet tygodni), możesz zaplanować usunięcie zbędnego indeksu. W przypadku wykrycia, że coś jest nie tak, zawsze możesz ponownie włączyć ten indeks, uruchamiając:
ALTER TABLE sbtest.sbtest1 ALTER INDEX k_1 VISIBLE;Operacje te są natychmiastowe, a indeks jest cały czas obecny i nadal jest utrzymywany - tylko, że nie będzie brany pod uwagę przez optymalizator. Dzięki tej opcji usuwanie indeksów w MySQL 8.0 będzie znacznie bezpieczniejszym działaniem. W poprzednich wersjach ponowne dodanie błędnie usuniętego indeksu przy dużych tabelach mogło zająć godziny, jeśli nie dni.
ClusterControl może również poinformować Cię o tabelach MyISAM.
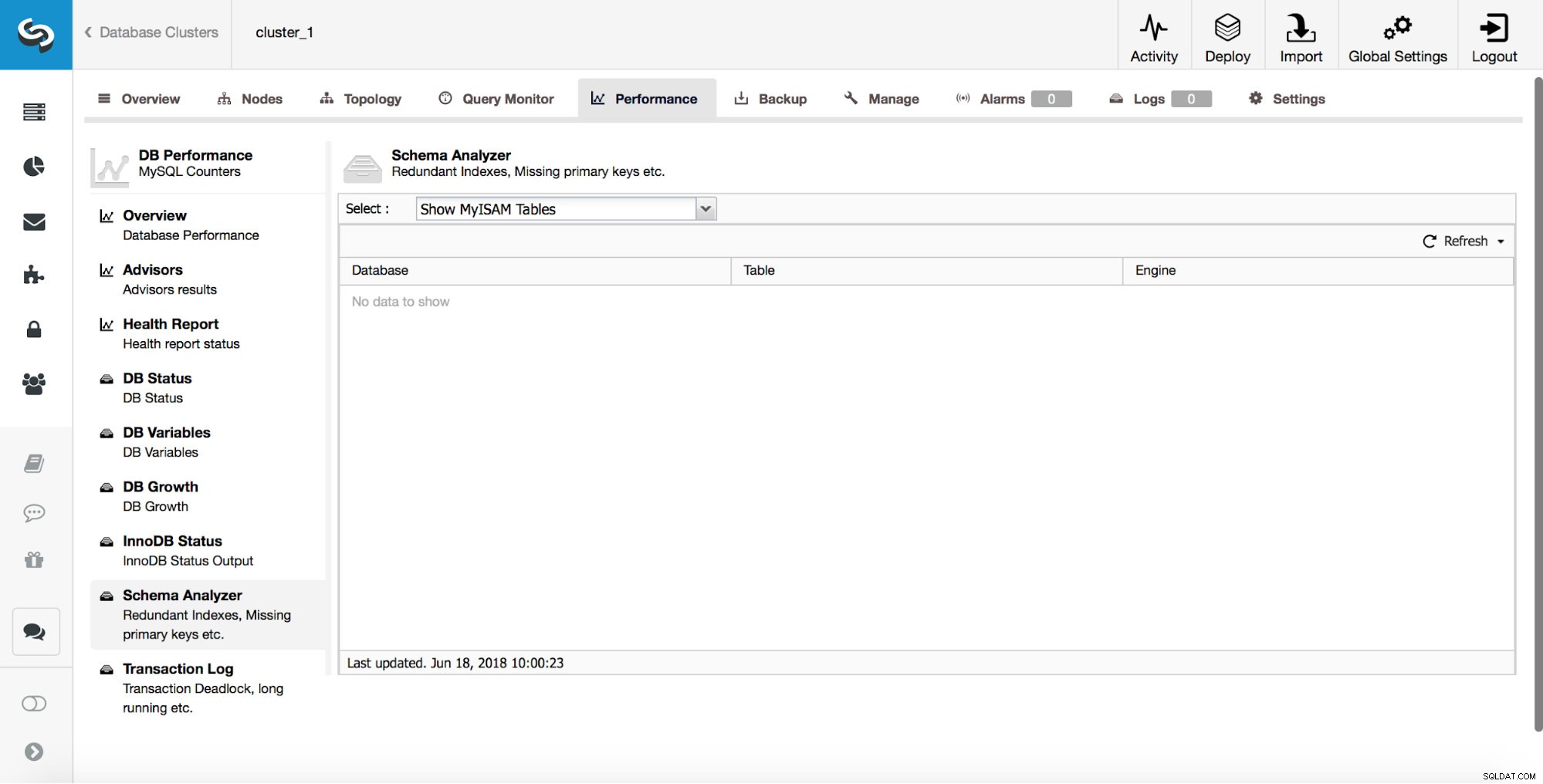
Chociaż MyISAM nadal może mieć swoje zastosowania, musisz pamiętać, że nie jest to silnik pamięci transakcyjnej. W związku z tym może łatwo wprowadzić niespójność danych między węzłami w konfiguracji replikacji.
Inną bardzo przydatną funkcją ClusterControl jest jeden z raportów operacyjnych - raport zmiany schematu.
W idealnym świecie administrator baz danych przegląda, zatwierdza i wdraża wszystkie zmiany schematu. Niestety, nie zawsze tak jest. Taki proces przeglądu po prostu nie pasuje do zwinnego rozwoju. Ponadto stosunek programistów do administratorów baz danych jest zazwyczaj dość wysoki, co może również stanowić problem, ponieważ administratorzy baz danych mieliby trudności, aby nie stać się wąskim gardłem. Dlatego często zdarza się, że zmiany schematu są wykonywane poza wiedzą DBA. Jednak DBA jest zwykle odpowiedzialny za wydajność i stabilność bazy danych. Dzięki raportowi o zmianie schematu mogą teraz śledzić zmiany schematu.
Na początku potrzebna jest pewna konfiguracja. W pliku konfiguracyjnym dla danego klastra (/etc/cmon.d/cmon_X.cnf) musisz zdefiniować, na którym hoście ClusterControl powinien śledzić zmiany i które schematy powinny być sprawdzane.
schema_change_detection_address=10.0.0.126
schema_change_detection_databases=sbtestGdy to zrobisz, możesz zaplanować regularne wykonywanie raportu. Przykładowe wyjście może wyglądać jak poniżej:
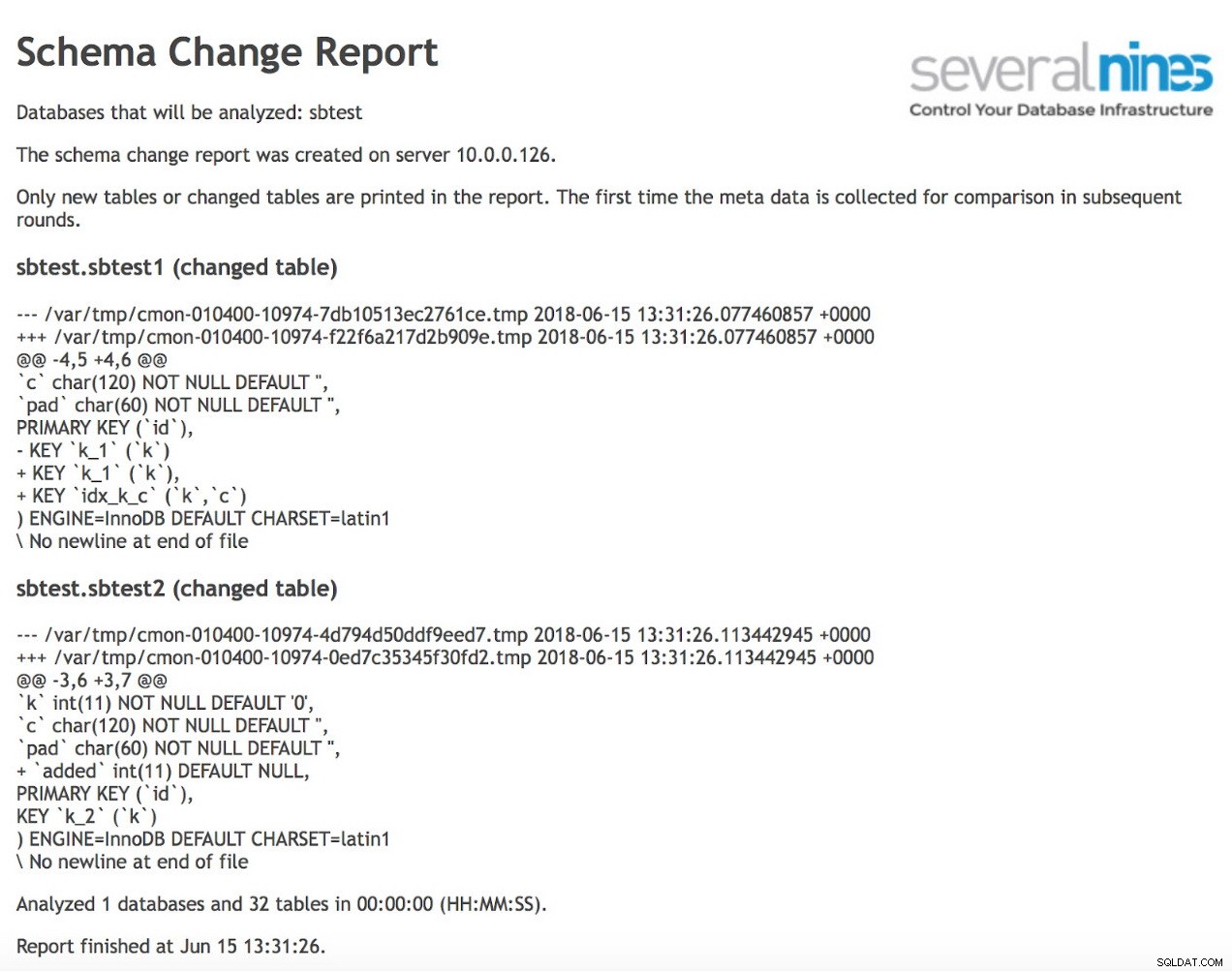
Jak widać, od poprzedniego uruchomienia raportu zmieniły się dwie tabele. W pierwszym utworzono nowy indeks złożony na kolumnach (k, c). W drugiej tabeli dodano kolumnę.
W kolejnym przebiegu otrzymaliśmy informację o nowej tabeli, która została utworzona bez żadnego indeksu ani klucza podstawowego. Korzystając z tego rodzaju informacji, możemy z łatwością działać, gdy jest to potrzebne i rozwiązywać problemy, zanim faktycznie zaczną stać się blokerami.



