Klaster Galera wymusza silną spójność danych, w której wszystkie węzły w klastrze są ściśle powiązane. Chociaż segmentacja sieci jest obsługiwana, wydajność replikacji jest nadal ograniczona przez dwa czynniki:
-
Czas podróży w obie strony (RTT) do najdalszego węzła w klastrze od węzła nadawcy.
-
Rozmiar zbioru zapisu, który ma być przesłany i certyfikowany pod kątem konfliktu w węźle odbiorczym.
Chociaż istnieją sposoby na zwiększenie wydajności Galery, nie można obejść tych dwóch ograniczających czynników.
Na szczęście Galera Cluster został zbudowany na bazie MySQL, która ma również wbudowaną funkcję replikacji (duh!). Zarówno replikacja Galera, jak i replikacja MySQL istnieją niezależnie w tym samym oprogramowaniu serwerowym. Możemy wykorzystać te technologie do współpracy, gdzie cała replikacja w centrum danych będzie się odbywać na Galera, podczas gdy replikacja między centrami danych będzie się odbywać na standardowej replikacji MySQL. Witryna podrzędna może działać jako witryna gorącej gotowości, gotowa do obsługi danych po przekierowaniu aplikacji do witryny kopii zapasowej. Omówiliśmy to w poprzednim blogu na temat architektur MySQL do odzyskiwania po awarii.
Replikacja klastrów do klastrów została wprowadzona w ClusterControl w wersji 1.7.4. W tym poście na blogu pokażemy, jak proste jest skonfigurowanie replikacji między dwoma klastrami Galera (PXC 8.0). Następnie przyjrzymy się trudniejszej części:obsłudze awarii zarówno na poziomie węzła, jak i klastra za pomocą ClusterControl; operacje przełączania awaryjnego i powrotu po awarii są kluczowe dla zachowania integralności danych w całym systemie.
Wdrażanie klastra
Na potrzeby naszego przykładu będziemy potrzebować co najmniej dwóch klastrów i dwóch lokacji – jednej dla głównego i drugiego dla drugorzędnego. Działa podobnie do tradycyjnej replikacji typu master-slave MySQL, ale na większą skalę z trzema węzłami bazy danych w każdej lokacji. Dzięki ClusterControl można to osiągnąć, wdrażając klaster podstawowy, a następnie wdrożony klaster pomocniczy w lokalizacji odzyskiwania po awarii jako klaster replik, replikowany przez dwukierunkową replikację asynchroniczną.
Poniższy diagram ilustruje naszą ostateczną architekturę:

W sumie mamy sześć węzłów bazy danych, trzy w witrynie głównej i jeden trzy w witrynie odzyskiwania po awarii. Aby uprościć reprezentację węzła, użyjemy następujących notacji:
-
Strona główna:
-
galera1-P - 192.168.11.171 (master)
-
galera2-P - 192.168.11.172
-
galera3-P - 192.168.11.173
-
-
Strona odzyskiwania po awarii:
-
galera1-DR - 192.168.11.181 (slave)
-
galera2-DR - 192.168.11.182
-
galera3-DR - 192.168.11.183
-
Najpierw po prostu wdroż pierwszy klaster i nazywamy go PXC-Primary. Otwórz ClusterControl UI → Wdróż → MySQL Galera i wprowadź wszystkie wymagane szczegóły:
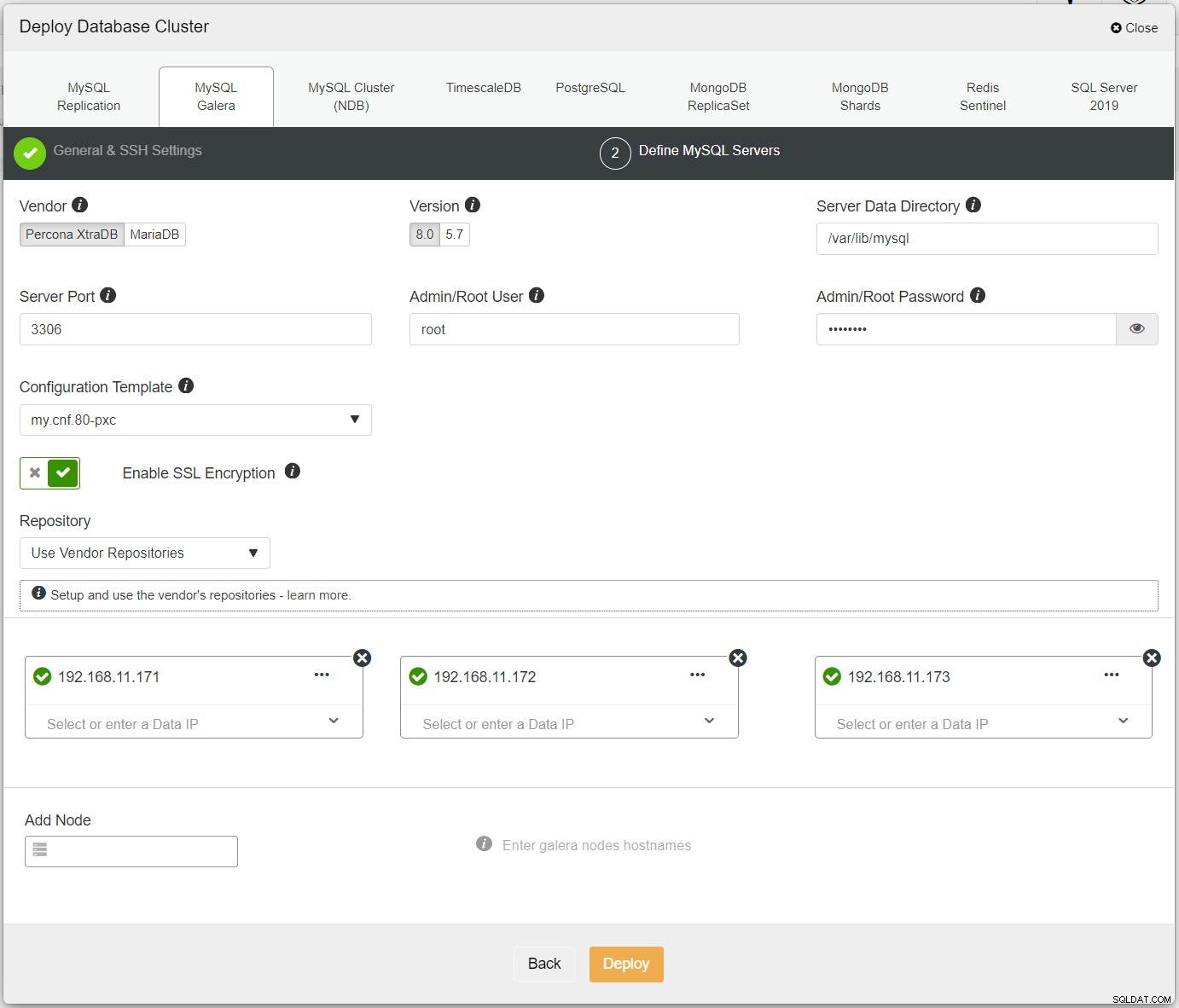
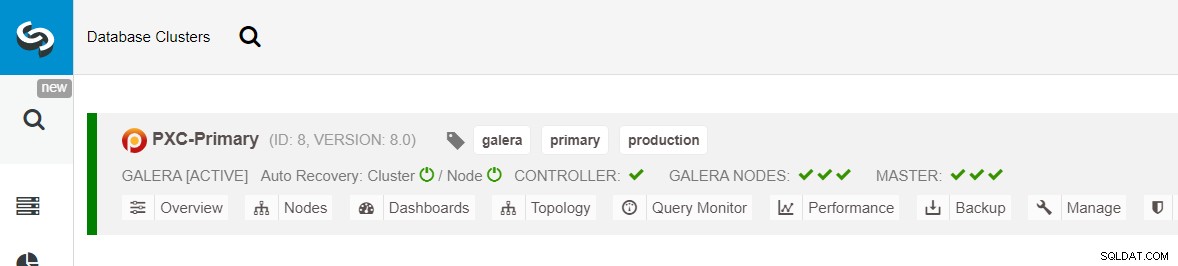
Upewnij się, że obok każdego określonego węzła znajduje się zielony znacznik wskazujący, że ClusterControl może łączyć się z hostem przez SSH bez hasła. Kliknij Wdróż i poczekaj na zakończenie wdrażania. Po zakończeniu powinieneś zobaczyć następujący klaster wymieniony na stronie pulpitu klastra:
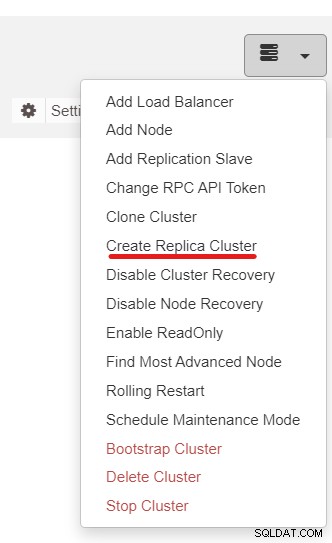
Następnie użyjemy funkcji ClusterControl o nazwie Create Replica Cluster, dostępnej z menu rozwijane Akcja klastra:
Zostanie wyświetlone następujące wyskakujące okienko paska bocznego:
Wybraliśmy opcję „Streaming from Master”, w której ClusterControl użyje wybrany master do synchronizacji klastra replik i skonfigurowania replikacji. Zwróć uwagę na opcję replikacji dwukierunkowej. Jeśli ta opcja jest włączona, ClusterControl skonfiguruje replikację dwukierunkową między obiema lokacjami (replikacja cykliczna). Wybrany master będzie replikowany z pierwszego mastera zdefiniowanego dla klastra replik i na odwrót. Ta konfiguracja zminimalizuje czas przemieszczania wymagany podczas odzyskiwania po przełączeniu awaryjnym lub powrocie po awarii. Kliknij „Create Replica Cluster”, gdzie ClusterControl otworzy nowy kreator wdrażania dla klastra replik, jak pokazano poniżej:
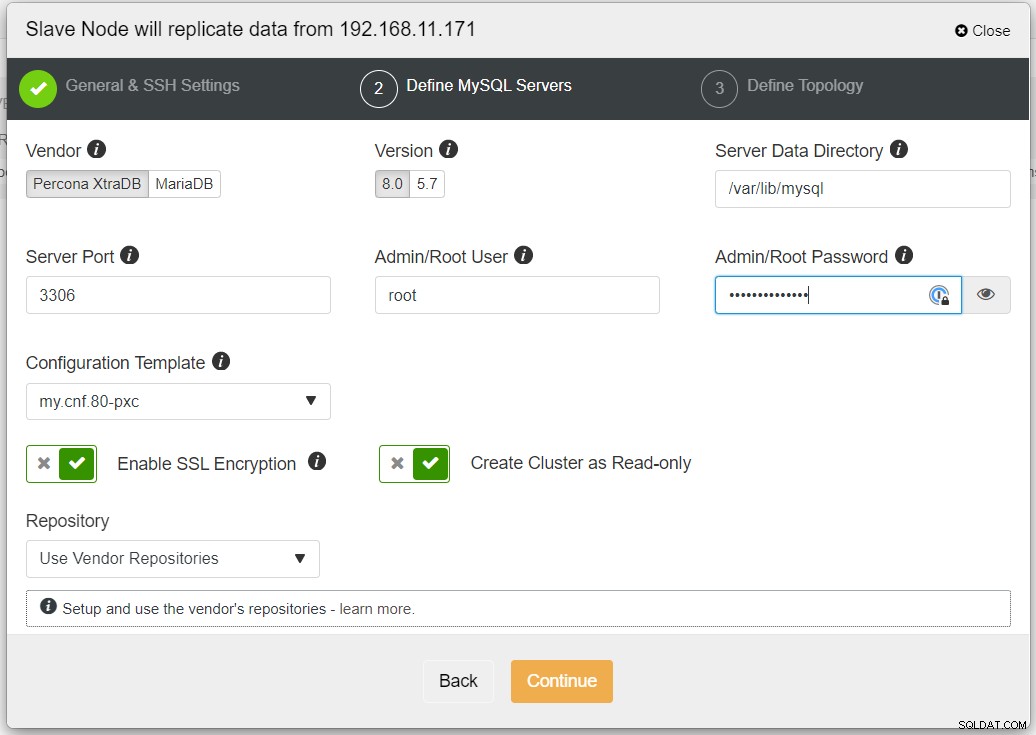
Zaleca się włączenie szyfrowania SSL, jeśli replikacja obejmuje niezaufane sieci, takie jak WAN, sieci nietunelowane lub Internet. Upewnij się również, że opcja „Utwórz klaster jako tylko do odczytu” jest włączona; jest to ochrona przed przypadkowym zapisem i dobry wskaźnik do łatwego odróżnienia klastra aktywnego (odczyt-zapis) od klastra pasywnego (tylko do odczytu).
Podczas wypełniania wszystkich niezbędnych informacji należy przejść do następującego etapu w celu zdefiniowania topologii klastra replik:
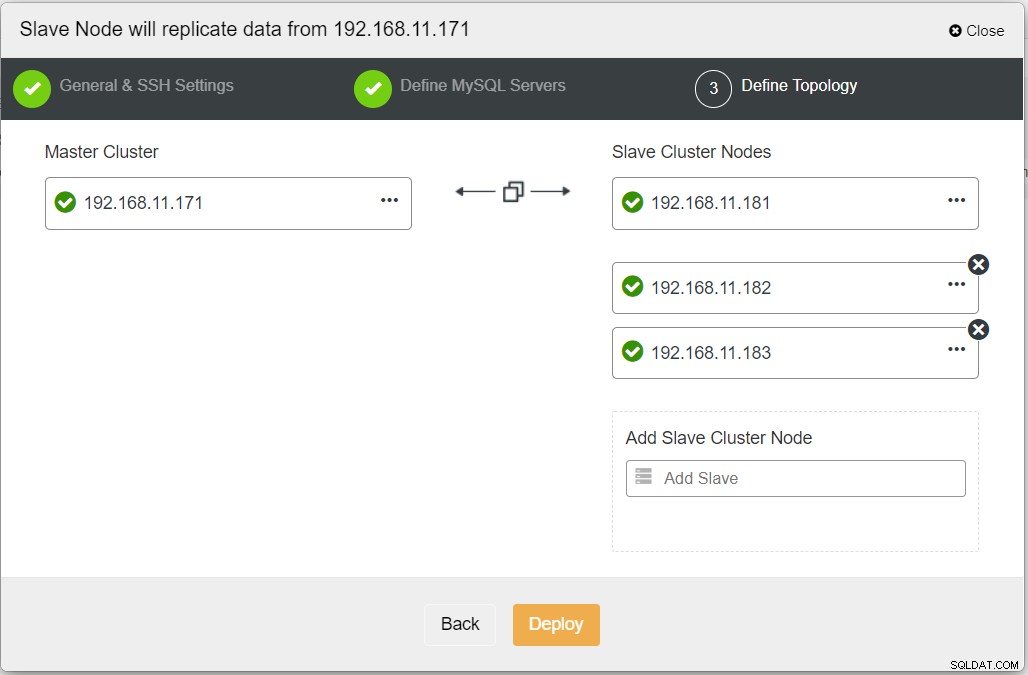
W panelu ClusterControl po zakończeniu wdrażania powinien zostać wyświetlony Witryna DR ma dwukierunkową strzałkę połączoną z witryną główną:
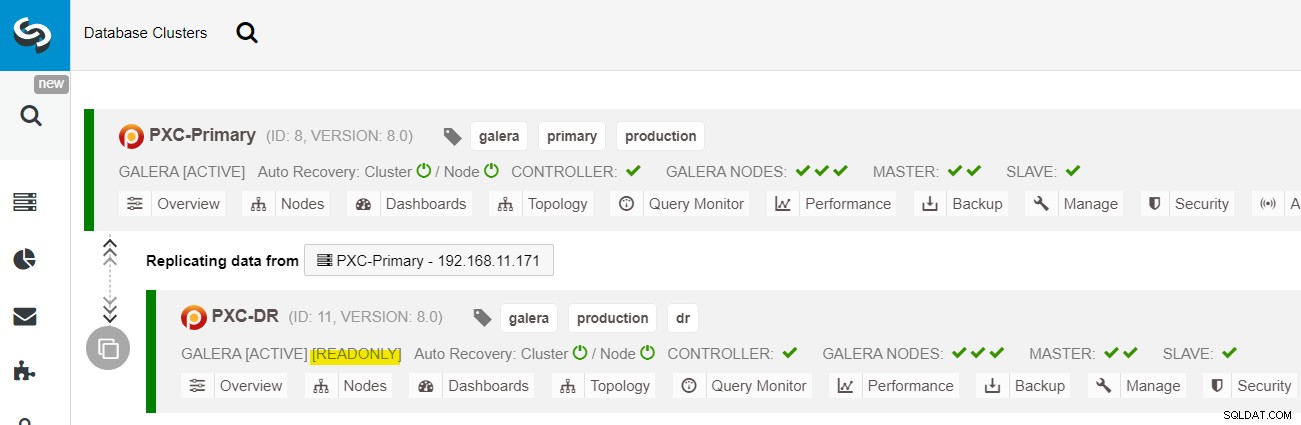
Wdrożenie zostało zakończone. Aplikacje powinny wysyłać zapisy tylko do lokacji głównej, ponieważ jest to lokacja aktywna, a lokacja DR jest skonfigurowana tylko do odczytu (podświetlona na żółto). Odczyty mogą być wysyłane do obu lokacji, chociaż lokacja DR może pozostawać w tyle z powodu asynchronicznej natury replikacji. Taka konfiguracja sprawi, że główna i po awarii lokacja odzyskiwania będzie od siebie niezależna i będzie luźno połączona z replikacją asynchroniczną. Jeden z węzłów Galera w lokacji DR będzie serwerem podrzędnym, który replikuje się z jednego z węzłów Galera (głównego) w lokacji głównej.
Mamy teraz system, w którym awaria klastra w lokacji głównej nie wpłynie na lokację zapasową. Pod względem wydajności opóźnienie WAN nie wpłynie na aktualizacje w aktywnym klastrze. Są one wysyłane asynchronicznie do witryny kopii zapasowej.
Na marginesie, możliwe jest również posiadanie dedykowanej instancji slave jako przekaźnika replikacji zamiast używania jednego z węzłów Galera jako slave.
Procedura przełączania awaryjnego węzła Galera
W przypadku awarii bieżącego urządzenia głównego (galera1-P), a pozostałe węzły w lokalizacji głównej nadal działają, urządzenie podrzędne w witrynie odzyskiwania po awarii (galera1-DR) powinno zostać skierowane do wszystkich dostępnych urządzeń głównych w lokalizacji głównej, jak pokazano na poniższym diagramie:
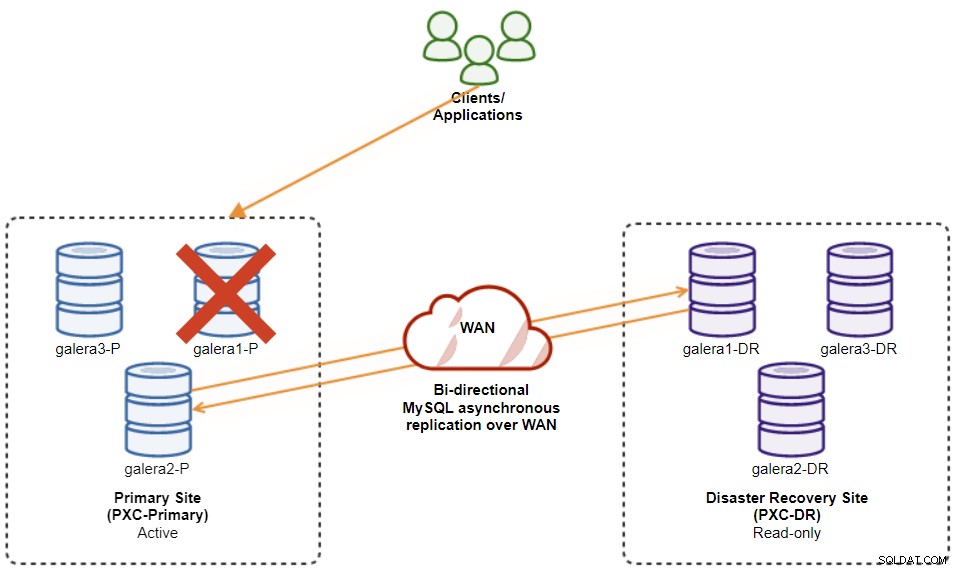
Z listy klastrów ClusterControl widać, że stan klastra jest zdegradowany , a jeśli najedziesz kursorem na ikonę wykrzyknika, zobaczysz błąd dla tego konkretnego węzła (galera1-P):
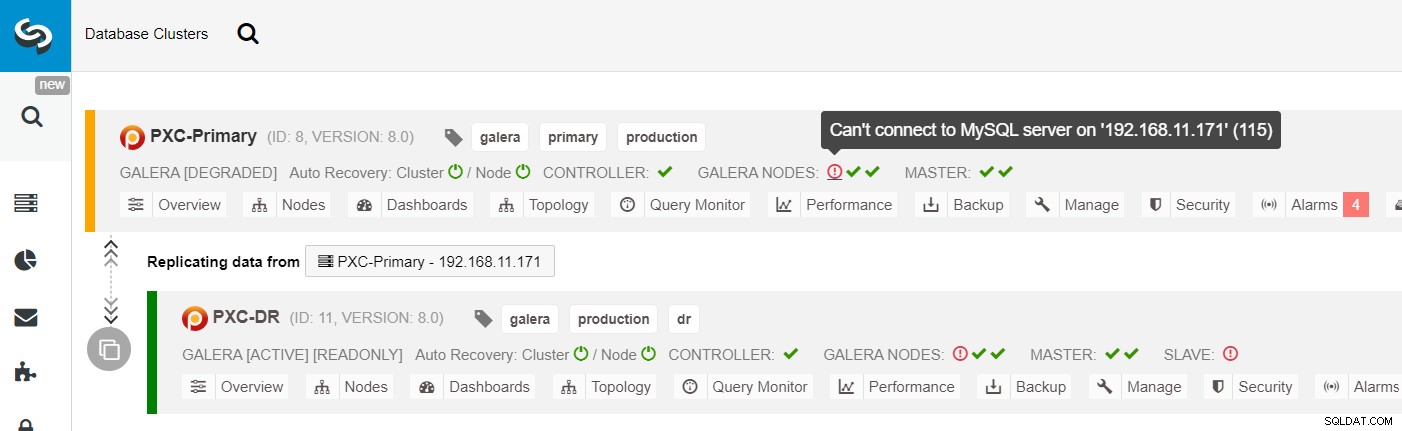
Korzystając z ClusterControl, możesz po prostu przejść do klastra PXC-DR → Węzły → wybrać galera1-DR → Akcje węzła → Odbuduj urządzenie podrzędne replikacji, a zostanie wyświetlone następujące okno dialogowe konfiguracji:
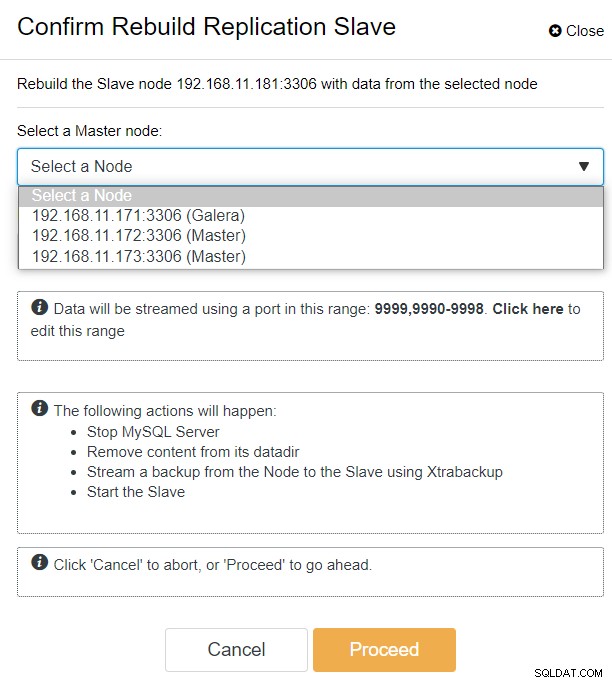
Widać wszystkie węzły Galera w lokalizacji głównej (192.168.11.17x ) z listy rozwijanej. Wybierz węzeł dodatkowy, 192.168.11.172 (galera2-P) i kliknij Kontynuuj. ClusterControl następnie skonfiguruje topologię replikacji tak, jak powinna, konfigurując replikację dwukierunkową z galera2-P do galera1-DR. Możesz to potwierdzić na stronie pulpitu nawigacyjnego klastra (zaznaczonej na żółto):
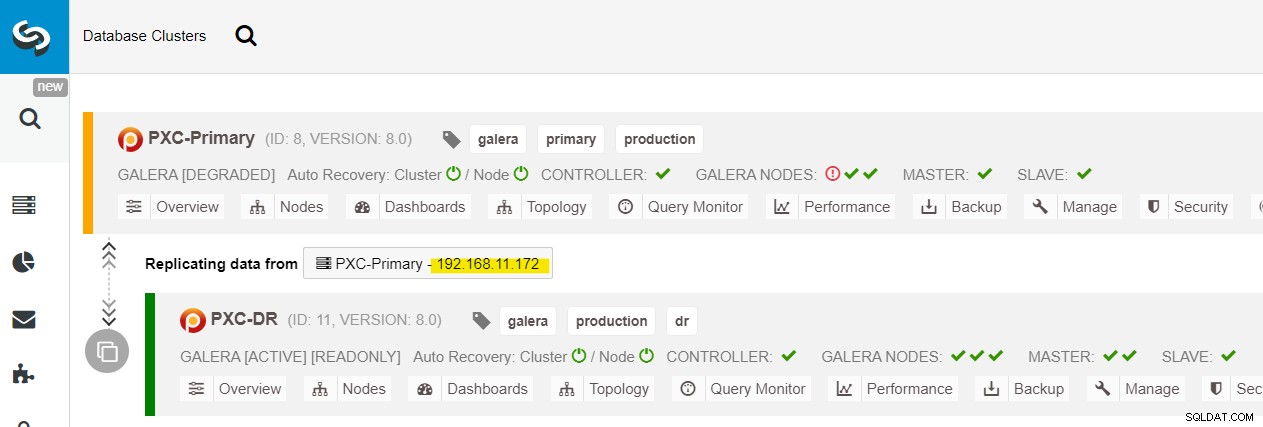
W tym momencie klaster podstawowy (PXC-Primary) nadal działa jako aktywny klaster dla tej topologii. Nie powinno to wpływać na czas działania usługi bazy danych w podstawowym klastrze.
Procedura przełączania awaryjnego klastra Galera
Jeśli klaster podstawowy ulegnie awarii, ulegnie awarii lub po prostu utraci łączność z punktu widzenia aplikacji, aplikacja może zostać niemal natychmiast przekierowana do witryny DR. SysAdmin musi po prostu wyłączyć tryb tylko do odczytu we wszystkich węzłach Galera w witrynie odzyskiwania po awarii, używając następującej instrukcji:
mysql> SET GLOBAL read_only = 0; -- repeat on galera1-DR, galera2-DR, galera3-DRDla użytkowników ClusterControl, możesz użyć ClusterControl UI → Węzły → wybierz węzeł DB → Akcje węzła → Wyłącz tylko do odczytu. ClusterControl CLI jest również dostępny po wykonaniu następujących poleceń w węźle ClusterControl:
$ s9s node --nodes="192.168.11.181" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.182" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.183" --cluster-id=11 --set-read-writePrzełączanie awaryjne do witryny DR jest teraz zakończone i aplikacje mogą zacząć wysyłać zapisy do klastra PXC-DR. W interfejsie użytkownika ClusterControl powinieneś zobaczyć coś takiego:
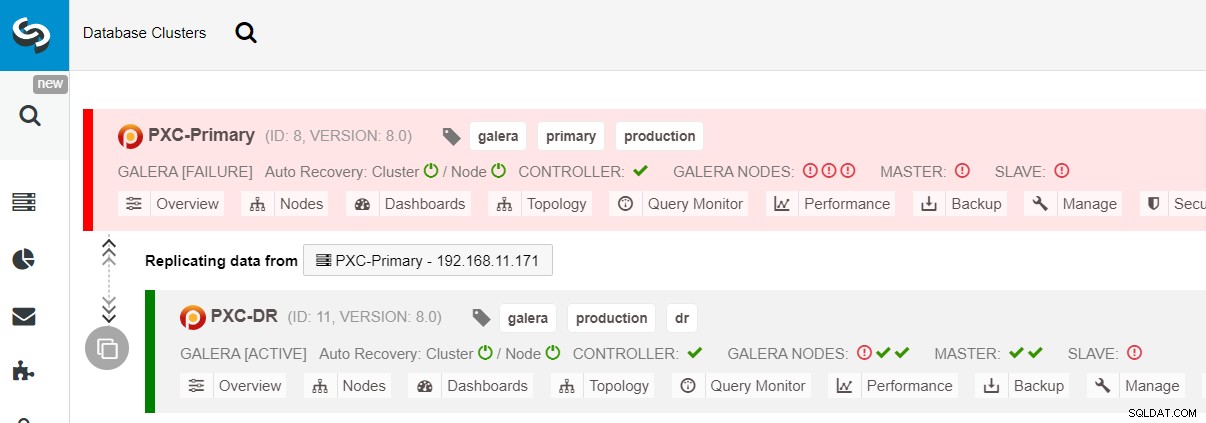
Poniższy diagram przedstawia naszą architekturę po awarii aplikacji w witrynie DR :
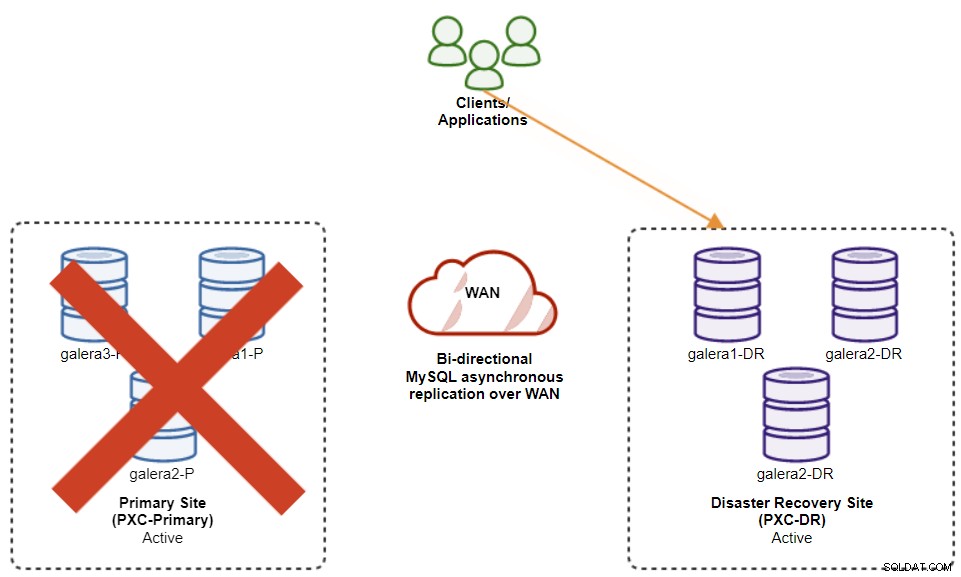
Zakładając, że witryna główna nadal nie działa, w tym momencie nie ma replikacja między lokacjami do czasu przywrócenia lokacji głównej.
Procedura powrotu po awarii klastra Galera
Po pojawieniu się lokacji głównej należy pamiętać, że klaster podstawowy musi być ustawiony na tryb tylko do odczytu, więc wiemy, że aktywnym klastrem jest ten w lokacji odzyskiwania po awarii. W ClusterControl przejdź do menu rozwijanego klastra i wybierz opcję „Włącz tylko do odczytu”, co spowoduje włączenie trybu tylko do odczytu na wszystkich węzłach w klastrze podstawowym i podsumowanie bieżącej topologii, jak poniżej:
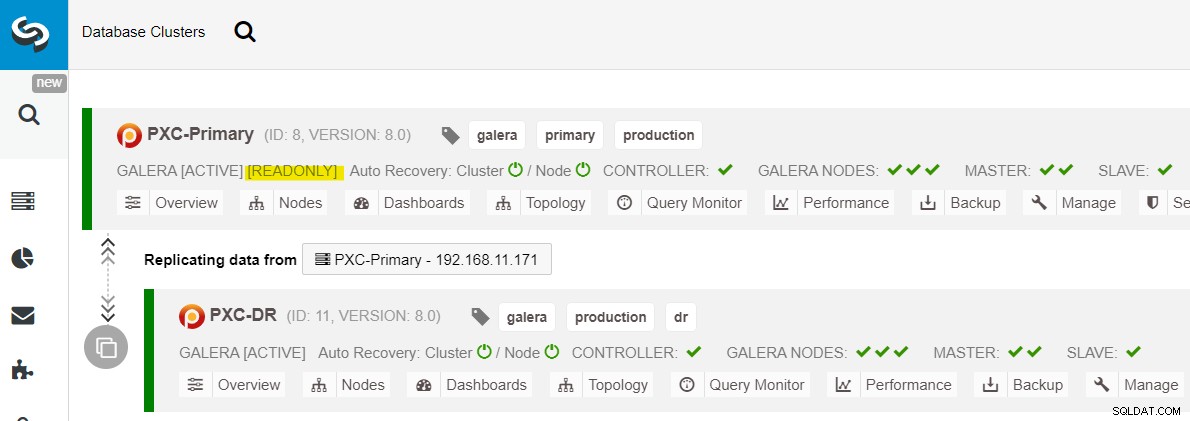
Przed planowaniem uruchomienia procedury powrotu po awarii klastra upewnij się, że wszystko jest zielone oznacza, że wszystkie węzły działają i są ze sobą zsynchronizowane). Jeśli na przykład istnieje węzeł w stanie pogorszenia, węzeł replikujący nadal pozostaje w tyle lub tylko niektóre węzły w klastrze podstawowym były osiągalne, poczekaj, aż klaster zostanie w pełni odzyskany, albo przez oczekiwanie na automatyczne procedury odzyskiwania ClusterControl do zakończenia lub ręczna interwencja.
W tym momencie klaster aktywny jest nadal klastrem DR, a klaster główny działa jako klaster drugorzędny. Poniższy diagram ilustruje obecną architekturę:
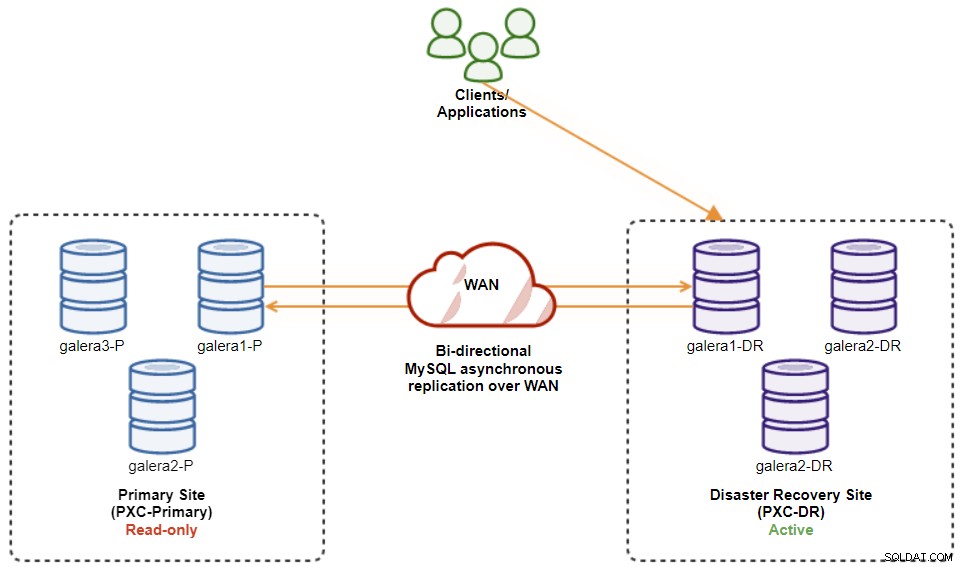
Najbezpieczniejszym sposobem powrotu po awarii do witryny głównej jest ustawienie tylko do odczytu w klastrze DR, a następnie wyłączenie trybu tylko do odczytu w lokacji głównej. Przejdź do ClusterControl UI → PXC-DR (menu rozwijane) → Włącz tylko do odczytu. Spowoduje to, że zadanie ustawi tylko do odczytu na wszystkich węzłach w klastrze DR. Następnie przejdź do ClusterControl UI → PXC-Primary → Nodes i wyłącz tylko do odczytu we wszystkich węzłach bazy danych w głównym klastrze.
Można również uprościć powyższe procedury za pomocą ClusterControl CLI. Alternatywnie wykonaj następujące polecenia na hoście ClusterControl:
$ s9s cluster --cluster-id=11 --set-read-only # enable cluster-wide read-only
$ s9s node --nodes="192.168.11.171" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.172" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.173" --cluster-id=8 --set-read-writePo zakończeniu kierunek replikacji powrócił do pierwotnej konfiguracji, gdzie PXC-Primary jest klastrem aktywnym, a PXC-DR jest klastrem rezerwowym. Poniższy diagram ilustruje ostateczną architekturę po operacji powrotu po awarii klastra:
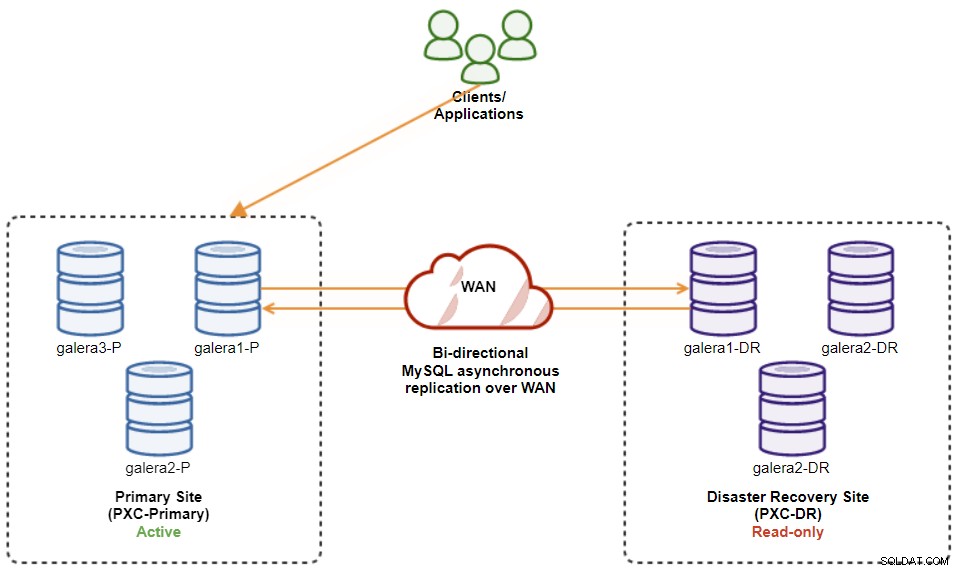
W tym momencie można bezpiecznie przekierować aplikacje do pisania główna siedziba.
Zalety asynchronicznej replikacji między klastrami
Korzystanie z klastra z asynchroniczną replikacją ma wiele zalet:
-
Minimalny czas przestoju podczas operacji przełączania awaryjnego bazy danych. Zasadniczo, możesz przekierować zapis niemal natychmiast do strony podrzędnej, tylko jeśli możesz zabezpieczyć zapisy przed dotarciem do strony głównej (ponieważ te zapisy nie zostaną zreplikowane i prawdopodobnie zostaną nadpisane podczas ponownej synchronizacji z witryny DR).
-
Brak wpływu na wydajność w witrynie głównej, ponieważ jest ona niezależna od witryny kopii zapasowej (DR). Replikacja z mastera na slave jest wykonywana asynchronicznie. Witryna nadrzędna generuje logi binarne, witryna podrzędna replikuje zdarzenia i stosuje je w późniejszym czasie.
-
Witryny odzyskiwania po awarii mogą być używane do innych celów, na przykład tworzenia kopii zapasowych baz danych, tworzenia kopii zapasowych dzienników binarnych i raportowania, lub ciężkich zapytań analitycznych (OLAP). Obie strony mogą być używane jednocześnie, z wyjątkiem opóźnienia replikacji i operacji tylko do odczytu po stronie podrzędnej.
-
Klaster DR może potencjalnie działać na mniejszych instancjach w środowisku chmury publicznej, o ile mogą nadążyć z klastrem podstawowym. W razie potrzeby możesz uaktualnić instancje. W niektórych sytuacjach może to zaoszczędzić trochę kosztów.
-
Do odzyskiwania po awarii potrzebujesz tylko jednej dodatkowej witryny w porównaniu z konfiguracją aktywnej-aktywnej replikacji wielostanowiskowej Galera, która wymaga co najmniej trzech aktywnych witryn do prawidłowego działania.
Wady asynchronicznej replikacji między klastrami
Istnieją również wady tej konfiguracji, w zależności od tego, czy używasz replikacji dwukierunkowej, czy jednokierunkowej:
-
Istnieje szansa pominięcia niektórych danych podczas przełączania awaryjnego, jeśli urządzenie podrzędne było w tyle, ponieważ replikacja jest asynchroniczna. Można to poprawić za pomocą półsynchronicznej i wielowątkowej replikacji niewolników, aczkolwiek będzie czekał inny zestaw wyzwań (narzut sieciowy, luka replikacji itp.).
-
W replikacji jednokierunkowej, mimo że procedury przełączania awaryjnego są dość proste, procedury powrotu po awarii mogą być trudne i podatne na błąd. Wymaga pewnej wiedzy na temat przełączania roli master/slave z powrotem do lokacji głównej. Zaleca się, aby dokumentować procedury, regularnie przeprowadzać próby przełączenia awaryjnego/powrotu poawaryjnego oraz używać dokładnych narzędzi do raportowania i monitorowania.
-
To może być dość kosztowne, ponieważ musisz skonfigurować podobną liczbę węzłów w witrynie odzyskiwania po awarii . To nie jest czarno-białe, ponieważ uzasadnienie kosztów zwykle wynika z wymagań Twojej firmy. Przy pewnym planowaniu możliwe jest zmaksymalizowanie wykorzystania zasobów bazy danych w obu lokalizacjach, niezależnie od ról bazy danych.
Zawijanie
Konfigurowanie replikacji asynchronicznej dla klastrów MySQL Galera może być stosunkowo prostym procesem — o ile rozumiesz, jak prawidłowo radzić sobie z awariami zarówno na poziomie węzła, jak i klastra. Ostatecznie, operacje przełączania awaryjnego i powrotu po awarii mają kluczowe znaczenie dla zapewnienia integralności danych.
Więcej wskazówek dotyczących projektowania klastrów Galera z uwzględnieniem strategii przełączania awaryjnego i powrotu po awarii można znaleźć w tym poście poświęconym architekturze MySQL do odzyskiwania po awarii. Jeśli szukasz pomocy w automatyzacji tych operacji, przetestuj ClusterControl bezpłatnie przez 30 dni i postępuj zgodnie z krokami opisanymi w tym poście.
Nie zapomnij śledzić nas na Twitterze lub LinkedIn i zasubskrybuj nasz biuletyn bądź na bieżąco z najnowszymi wiadomościami i najlepszymi praktykami w zakresie zarządzania infrastrukturą baz danych typu open source.