W tym wpisie na blogu przeanalizujemy 6 różnych scenariuszy awarii w produkcyjnych systemach baz danych, od problemów z jednym serwerem po plany przełączania awaryjnego obejmujące wiele centrów danych. Przeprowadzimy Cię przez procedury odzyskiwania i przełączania awaryjnego dla odpowiedniego scenariusza. Mamy nadzieję, że pozwoli to dobrze zrozumieć ryzyko, z którym możesz się zmierzyć, i rzeczy, które należy wziąć pod uwagę podczas projektowania infrastruktury.
Schemat bazy danych uszkodzony
Zacznijmy od instalacji na jednym węźle - konfiguracji bazy danych w najprostszej formie. Łatwy do wdrożenia przy najniższych kosztach. W tym scenariuszu uruchamiasz wiele aplikacji na jednym serwerze, na którym każdy ze schematów bazy danych należy do innej aplikacji. Podejście do odzyskania pojedynczego schematu zależałoby od kilku czynników.
- Czy mam kopię zapasową?
- Czy mam kopię zapasową i jak szybko mogę ją przywrócić?
- Jaki rodzaj silnika pamięci jest używany?
- Czy mam kopię zapasową zgodną z PITR (odzyskiwanie punktu w czasie)?
Uszkodzenie danych można zidentyfikować za pomocą mysqlcheck.
mysqlcheck -uroot -p <DATABASE>Zastąp DATABASE nazwą bazy danych, a TABLE nazwą tabeli, którą chcesz sprawdzić:
mysqlcheck -uroot -p <DATABASE> <TABLE>Mysqlcheck sprawdza określoną bazę danych i tabele. Jeśli tabela przejdzie pomyślnie sprawdzenie, mysqlcheck wyświetli OK dla tabeli. W poniższym przykładzie widzimy, że tabela pensje wymaga odzyskania.
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OKW przypadku instalacji jednowęzłowej bez dodatkowych serwerów DR, podstawowym podejściem byłoby przywrócenie danych z kopii zapasowej. Ale to nie jedyna rzecz, którą musisz wziąć pod uwagę. Posiadanie wielu schematów bazy danych w tej samej instancji powoduje problem, gdy trzeba wyłączyć serwer w celu przywrócenia danych. Innym pytaniem jest, czy możesz sobie pozwolić na przywrócenie wszystkich baz danych do ostatniej kopii zapasowej. W większości przypadków nie byłoby to możliwe.
Jest tu kilka wyjątków. Możliwe jest przywrócenie pojedynczej tabeli lub bazy danych z ostatniej kopii zapasowej, gdy odzyskiwanie do określonego momentu nie jest potrzebne. Taki proces jest bardziej skomplikowany. Jeśli masz mysqldump, możesz wyodrębnić z niego swoją bazę danych. Jeśli uruchamiasz binarne kopie zapasowe za pomocą xtradbackup lub mariabackup i masz włączoną tabelę dla pliku, jest to możliwe.
Oto jak sprawdzić, czy masz włączoną opcję tabeli na plik.
mysql> SET GLOBAL innodb_file_per_table=1; Po włączeniu innodb_file_per_table można przechowywać tabele InnoDB w pliku nazwa_tabeli .ibd. W przeciwieństwie do mechanizmu pamięci masowej MyISAM, z osobnymi plikami nazwa_tabeli .MYD i nazwa_tabeli .MYI dla indeksów i danych, InnoDB przechowuje dane i indeksy razem w jednym pliku .ibd. Aby sprawdzić silnik pamięci masowej, musisz uruchomić:
mysql> select table_name,engine from information_schema.tables where table_name='table_name' and table_schema='database_name';lub bezpośrednio z konsoli:
[example@sqldat.com ~]# mysql -u<username> -p -D<database_name> -e "show table status\G"
Enter password:
*************************** 1. row ***************************
Name: test1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 12
Avg_row_length: 1365
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2018-05-24 17:54:33
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment: Aby przywrócić tabele z xtradbackup, musisz przejść przez proces eksportu. Kopia zapasowa musi być przygotowana, zanim będzie można ją przywrócić. Eksport odbywa się na etapie przygotowania. Po utworzeniu pełnej kopii zapasowej uruchom standardową procedurę przygotowania z dodatkową flagą --export :
innobackupex --apply-log --export /u01/backupSpowoduje to utworzenie dodatkowych plików eksportu, których będziesz używać później w fazie importu. Aby zaimportować tabelę na inny serwer, najpierw utwórz nową tabelę o takiej samej strukturze, jak ta, która zostanie zaimportowana na tym serwerze:
mysql> CREATE TABLE corrupted_table (...) ENGINE=InnoDB;odrzuć przestrzeń tabel:
mysql> ALTER TABLE mydatabase.mytable DISCARD TABLESPACE;Następnie skopiuj pliki mytable.ibd i mytable.exp do głównej bazy danych i zaimportuj jej obszar tabel:
mysql> ALTER TABLE mydatabase.mytable IMPORT TABLESPACE;Jednak aby zrobić to w bardziej kontrolowany sposób, zaleca się przywrócenie kopii zapasowej bazy danych na innej instancji/serwerze i skopiowanie tego, co jest potrzebne, z powrotem do systemu głównego. Aby to zrobić, musisz uruchomić instalację instancji mysql. Można to zrobić na tym samym komputerze – ale wymaga więcej wysiłku, aby skonfigurować w taki sposób, aby obie instancje mogły działać na tym samym komputerze – na przykład wymagałoby to różnych ustawień komunikacji.
Możesz połączyć zarówno przywracanie zadań, jak i instalację za pomocą ClusterControl.
ClusterControl przeprowadzi Cię przez dostępne kopie zapasowe lokalnie lub w chmurze, pozwoli Ci wybrać dokładny czas przywracania lub dokładną pozycję dziennika oraz w razie potrzeby zainstalować nową instancję bazy danych.
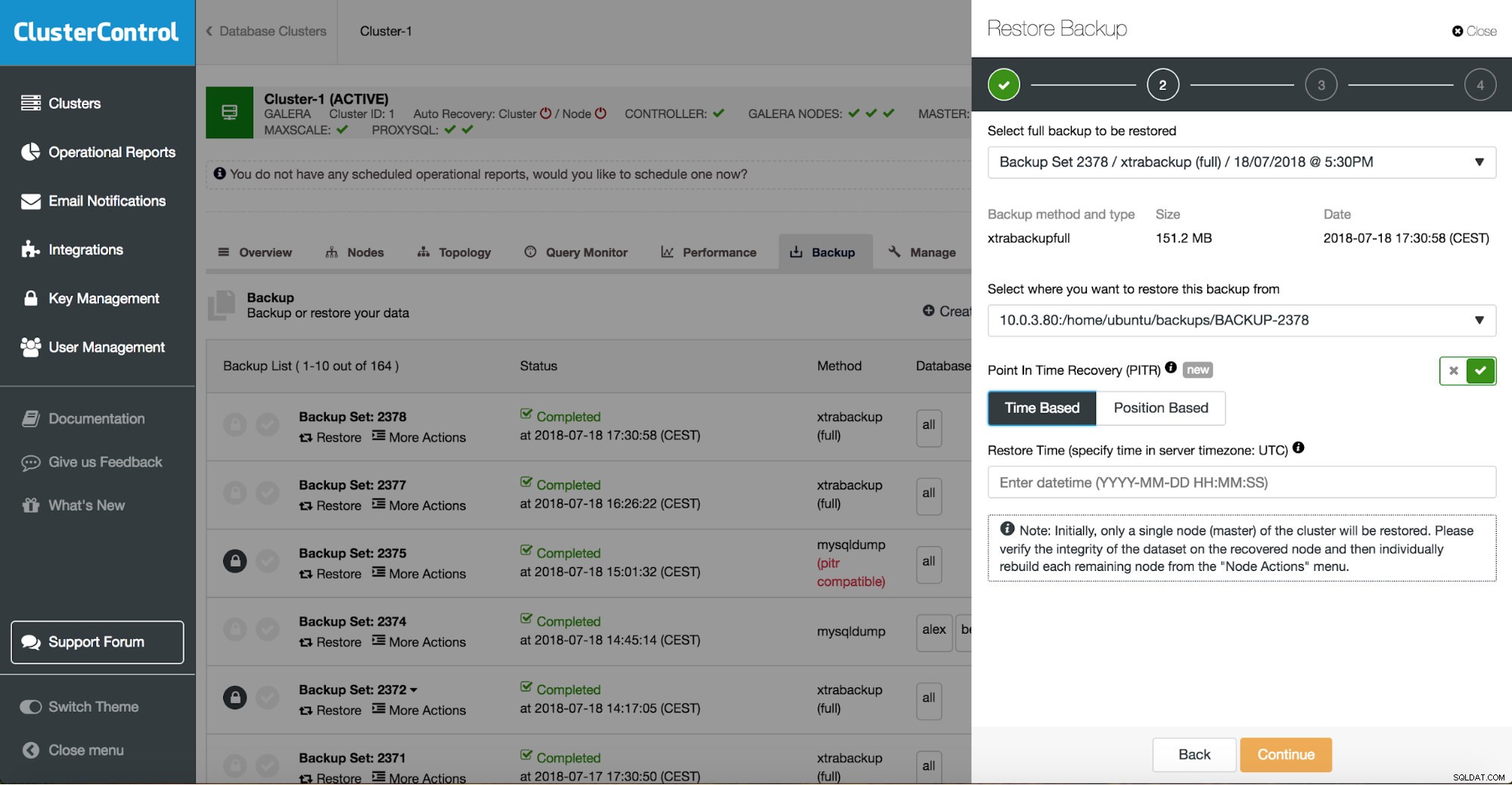 Przywracanie punktu w czasie ClusterControl
Przywracanie punktu w czasie ClusterControl 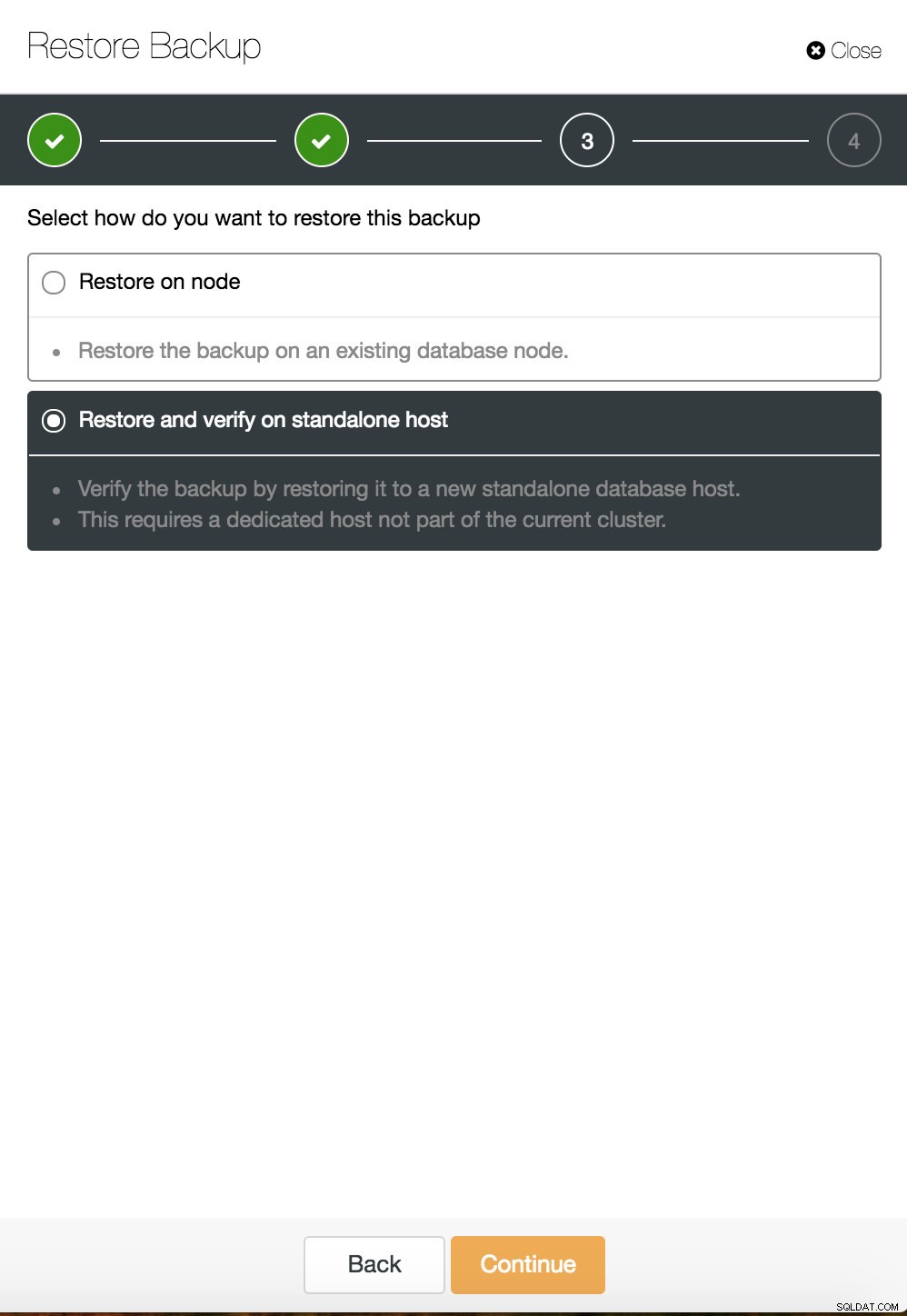 ClusterControl przywracanie i weryfikacja na samodzielnym hoście
ClusterControl przywracanie i weryfikacja na samodzielnym hoście 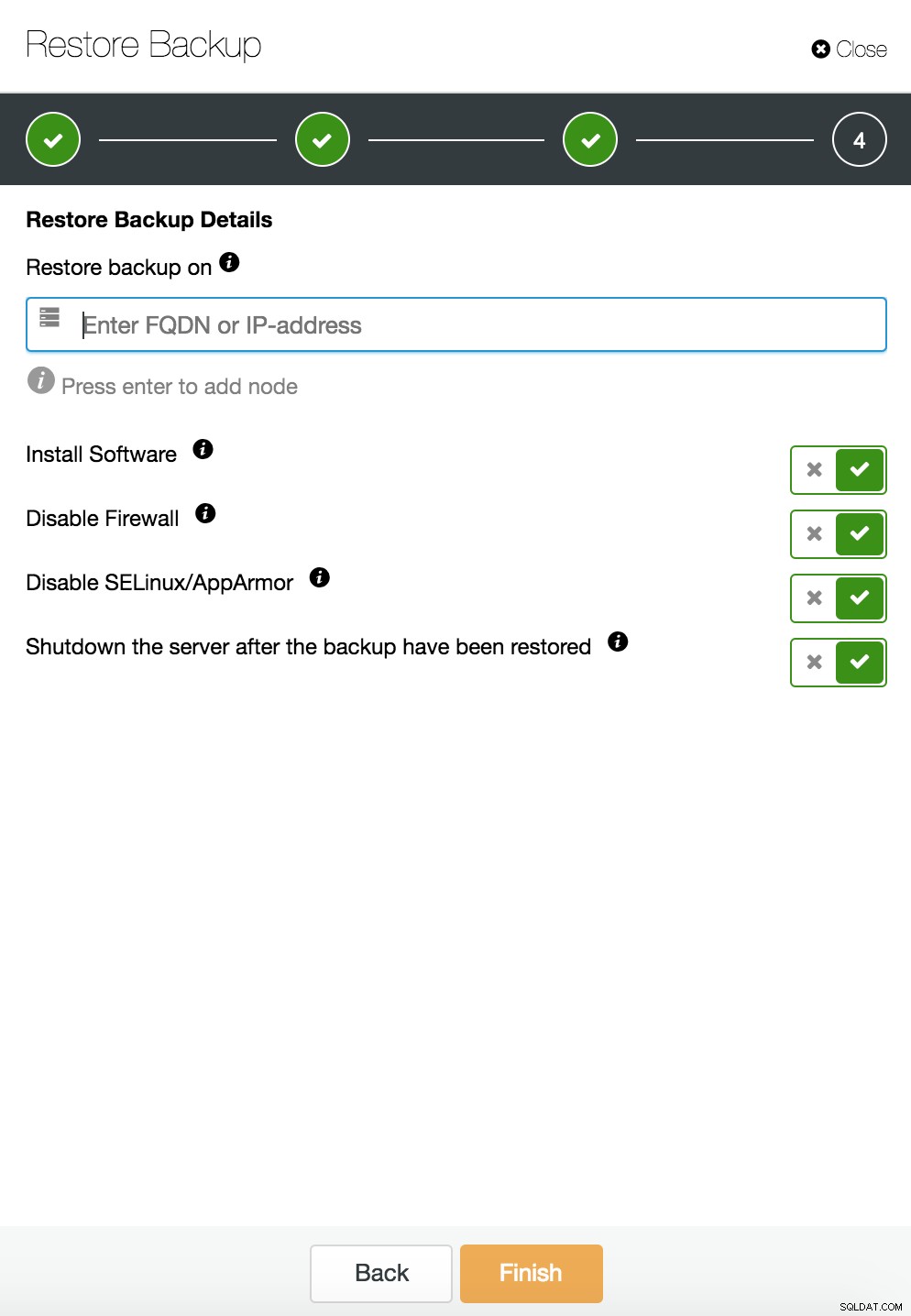 Przywracanie i weryfikacja CusterControl na samodzielnym hoście. Opcje instalacji.
Przywracanie i weryfikacja CusterControl na samodzielnym hoście. Opcje instalacji. Więcej informacji na temat odzyskiwania danych znajdziesz na blogu My MySQL Database is Corrupted... Co mam teraz zrobić?
Uszkodzona instancja bazy danych na serwerze dedykowanym
Wady platformy bazowej są często przyczyną uszkodzenia bazy danych. Twoja instancja MySQL opiera się na wielu elementach do przechowywania i pobierania danych - podsystemie dysku, kontrolerach, kanałach komunikacji, sterownikach i oprogramowaniu układowym. Awaria może wpłynąć na części danych, pliki binarne mysql, a nawet pliki kopii zapasowych, które przechowujesz w systemie. Aby oddzielić różne aplikacje, możesz umieścić je na dedykowanych serwerach.
Różne schematy aplikacji na osobnych systemach to dobry pomysł, jeśli możesz sobie na nie pozwolić. Można powiedzieć, że jest to marnotrawstwo zasobów, ale jest szansa, że wpływ na biznes będzie mniejszy, jeśli tylko jeden z nich ulegnie uszkodzeniu. Ale nawet wtedy musisz chronić swoją bazę danych przed utratą danych. Przechowywanie kopii zapasowej na tym samym serwerze nie jest złym pomysłem, o ile masz kopię w innym miejscu. Obecnie przechowywanie w chmurze jest doskonałą alternatywą dla kopii zapasowych na taśmach.
ClusterControl umożliwia przechowywanie kopii kopii zapasowej w chmurze. Obsługuje przesyłanie do 3 największych dostawców chmury — Amazon AWS, Google Cloud i Microsoft Azure.
Po przywróceniu pełnej kopii zapasowej możesz przywrócić ją do określonego momentu. Odzyskiwanie do określonego momentu spowoduje zaktualizowanie serwera do czasu nowszego niż w momencie wykonania pełnej kopii zapasowej. Aby to zrobić, musisz mieć włączone logi binarne. Możesz sprawdzić dostępne logi binarne za pomocą:
mysql> SHOW BINARY LOGS;I aktualny plik dziennika z:
SHOW MASTER STATUS;Następnie możesz przechwytywać dane przyrostowe, przekazując logi binarne do pliku sql. Brakujące operacje można następnie wykonać ponownie.
mysqlbinlog --start-position='14231131' --verbose /var/lib/mysql/binlog.000010 /var/lib/mysql/binlog.000011 /var/lib/mysql/binlog.000012 /var/lib/mysql/binlog.000013 /var/lib/mysql/binlog.000015 > binlog.outTo samo można zrobić w ClusterControl.
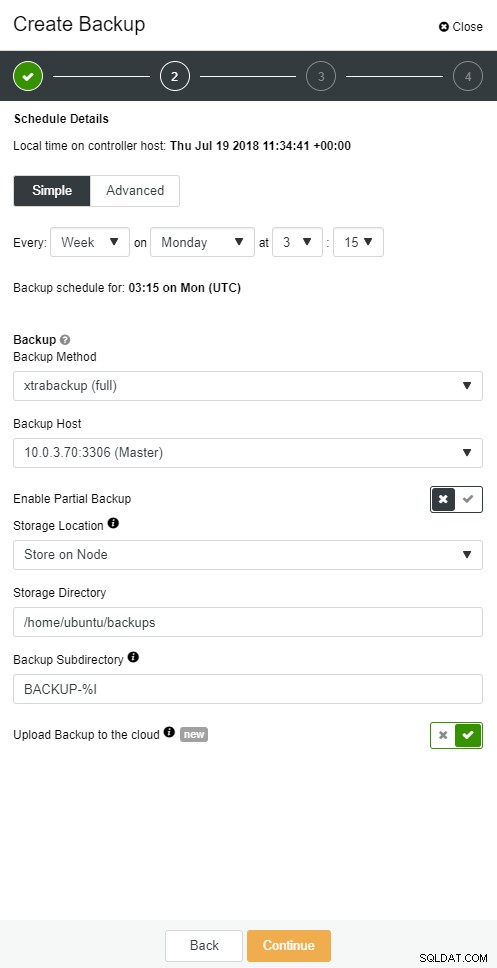 Kopia zapasowa w chmurze ClusterControl
Kopia zapasowa w chmurze ClusterControl  Kopia zapasowa w chmurze ClusterControl
Kopia zapasowa w chmurze ClusterControl Podrzędna baza danych przestaje działać
Ok, więc masz swoją bazę danych działającą na serwerze dedykowanym. Utworzyłeś zaawansowany harmonogram tworzenia kopii zapasowych z kombinacją pełnych i przyrostowych kopii zapasowych, prześlij je do chmury i przechowuj najnowsze kopie zapasowe na dyskach lokalnych w celu szybkiego odzyskiwania. Masz różne zasady przechowywania kopii zapasowych — krótsze dla kopii zapasowych przechowywanych na dyskach lokalnych i rozszerzone dla kopii zapasowych w chmurze.
Wygląda na to, że jesteś dobrze przygotowany na scenariusz katastrofy. Ale jeśli chodzi o czas przywracania, może on nie spełniać Twoich potrzeb biznesowych.
Potrzebujesz funkcji szybkiego przełączania awaryjnego. Serwer, który będzie działał, stosując logi binarne z mastera, na którym ma miejsce zapis. Replikacja Master/Slave rozpoczyna nowy rozdział w scenariuszu pracy awaryjnej. Jest to szybka metoda na przywrócenie aplikacji do życia, jeśli opanowanie spadnie.
Ale w scenariuszu przełączania awaryjnego należy wziąć pod uwagę kilka rzeczy. Jednym z nich jest skonfigurowanie niewolnika replikacji z opóźnieniem, dzięki czemu można reagować na polecenia grubego palca, które zostały wyzwolone na serwerze głównym. Serwer podrzędny może pozostawać w tyle za serwerem głównym przynajmniej o określoną ilość czasu. Domyślne opóźnienie to 0 sekund. Użyj opcji MASTER_DELAY opcji CHANGE MASTER TO, aby ustawić opóźnienie na N sekund:
CHANGE MASTER TO MASTER_DELAY = N;Drugim jest włączenie automatycznego przełączania awaryjnego. Na rynku dostępnych jest wiele zautomatyzowanych rozwiązań do przełączania awaryjnego. Możesz skonfigurować automatyczne przełączanie awaryjne za pomocą narzędzi wiersza poleceń, takich jak MHA, MRM, mysqlfailover lub GUI Orchestrator i ClusterControl. Prawidłowo skonfigurowany może znacznie zmniejszyć przestoje.
ClusterControl obsługuje automatyczne przełączanie awaryjne dla replikacji MySQL, PostgreSQL i MongoDB, a także rozwiązania klastrowe z wieloma wzorcami Galera i NDB.
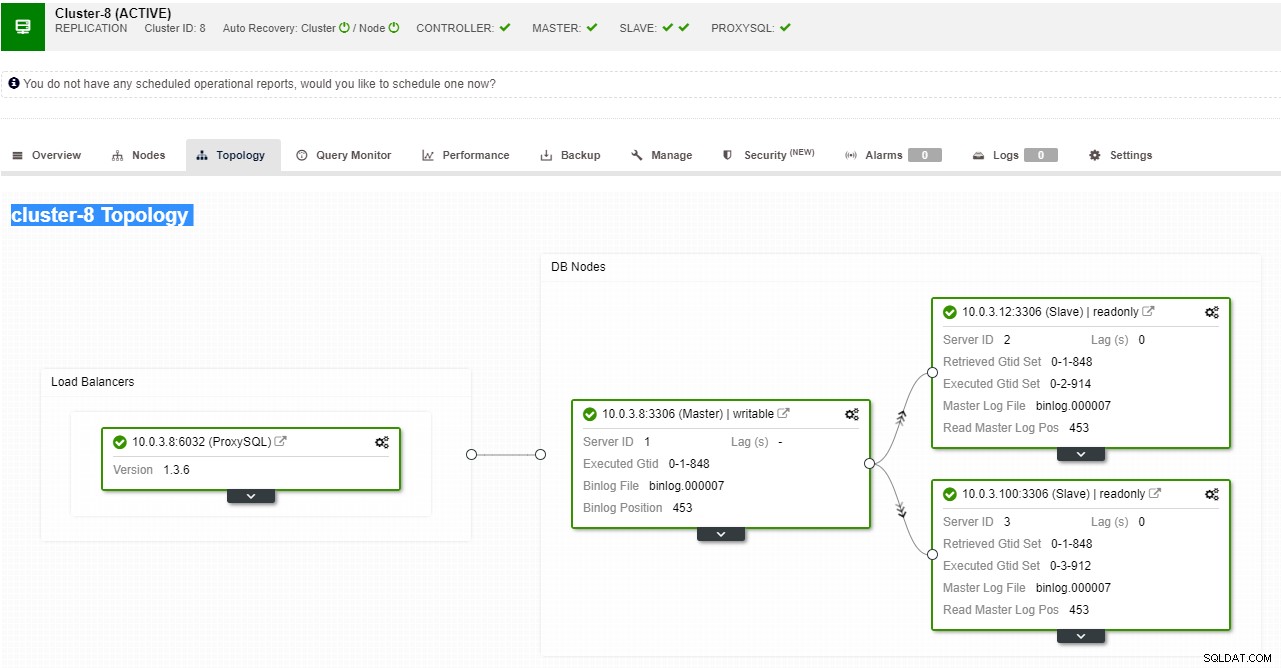 Widok topologii replikacji ClusterControl
Widok topologii replikacji ClusterControl Kiedy węzeł podrzędny ulegnie awarii, a serwer zostanie poważnie opóźniony, możesz chcieć odbudować swój serwer podrzędny. Proces odbudowy urządzenia podrzędnego jest podobny do przywracania z kopii zapasowej.
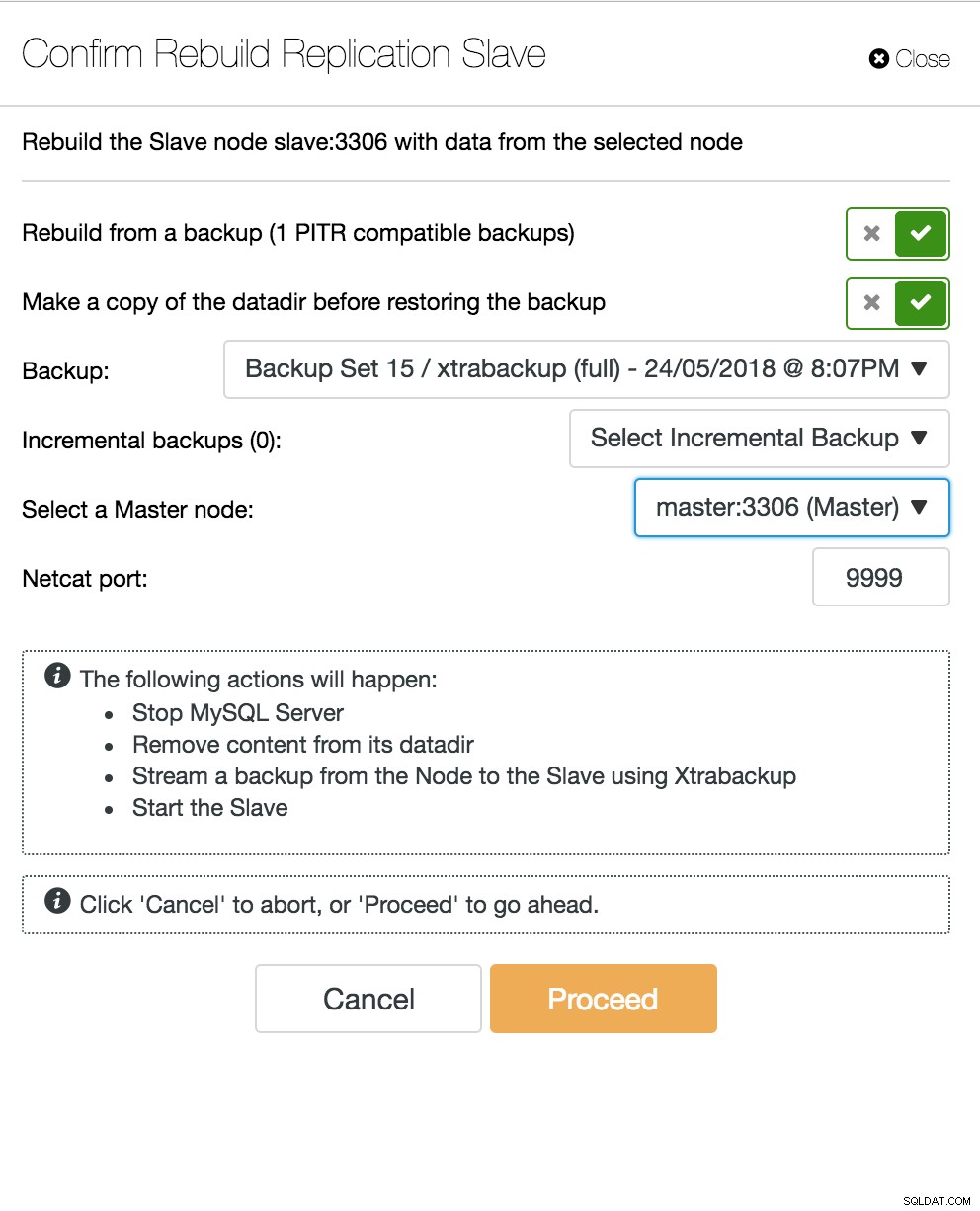 ClusterControl odbudowując urządzenie podrzędne
ClusterControl odbudowując urządzenie podrzędne Awaria serwera baz danych Multi-Master
Teraz, gdy masz serwer podrzędny działający jako węzeł DR, a proces przełączania awaryjnego jest dobrze zautomatyzowany i przetestowany, twoje życie DBA staje się wygodniejsze. To prawda, ale do rozwiązania jest jeszcze kilka zagadek. Moc obliczeniowa nie jest bezpłatna, a Twój zespół biznesowy może poprosić Cię o lepsze wykorzystanie sprzętu, możesz chcieć używać serwera podrzędnego nie tylko jako serwera pasywnego, ale także do obsługi operacji zapisu.
Możesz wtedy zbadać rozwiązanie replikacji z wieloma wzorcami. Galera Cluster stał się popularną opcją dla wysokiej dostępności MySQL i MariaDB. I chociaż obecnie jest znany jako wiarygodny zamiennik tradycyjnych architektur typu master-slave MySQL, nie jest to zamiennik typu drop-in.
Klaster Galera ma architekturę niczego współdzielonego. Zamiast dysków współdzielonych Galera wykorzystuje replikację opartą na certyfikacji z komunikacją grupową i porządkowaniem transakcji w celu uzyskania replikacji synchronicznej. Klaster bazy danych powinien być w stanie przetrwać utratę węzła, chociaż osiąga się to na różne sposoby. W przypadku Galery krytycznym aspektem jest liczba węzłów. Galera wymaga kworum, aby funkcjonować. Klaster z trzema węzłami może przetrwać awarię jednego węzła. Dzięki większej liczbie węzłów w klastrze możesz przetrwać więcej awarii.
Proces odzyskiwania jest zautomatyzowany, więc nie musisz wykonywać żadnych operacji przełączania awaryjnego. Jednak dobrą praktyką byłoby zabijanie węzłów i sprawdzanie, jak szybko można je przywrócić. Aby ta operacja była bardziej wydajna, możesz zmodyfikować rozmiar pamięci podręcznej Galera. Jeśli rozmiar pamięci podręcznej Galera nie jest odpowiednio zaplanowany, następny węzeł rozruchowy będzie musiał wykonać pełną kopię zapasową, a nie tylko brakujące zestawy zapisu w pamięci podręcznej.
Scenariusz pracy awaryjnej jest prosty i polega na uruchomieniu instancji. Na podstawie danych w pamięci podręcznej Galera, węzeł rozruchowy wykona SST (przywracanie z pełnej kopii zapasowej) lub IST (zastosowanie brakujących zestawów zapisu). Jednak często wiąże się to z interwencją człowieka. Jeśli chcesz zautomatyzować cały proces przełączania awaryjnego, możesz użyć funkcji automatycznego odzyskiwania ClusterControl (na poziomie węzła i klastra).
 Autoodzyskiwanie klastra ClusterControl
Autoodzyskiwanie klastra ClusterControl Oszacuj rozmiar pamięci podręcznej Galera:
MariaDB [(none)]> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;Aby zapewnić bardziej spójne przełączanie awaryjne, należy włączyć gcache.recover=yes w mycnf. Ta opcja ożywi galera-cache po ponownym uruchomieniu. Oznacza to, że węzeł może działać jako DONOR i usługa, której brakuje zestawów zapisu (ułatwiając IST, zamiast używać SST).
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 2,
members = 2/3 (joined/total),
act_id = 12810,
last_appl. = 0,
protocols = 0/7/3 (gcs/repl/appl),
group UUID = 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Trying to continue unpaused monitor
2018-07-20 8:59:44 139657311033088 [Note] WSREP: New cluster view: global state: 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69:12810, view# 3: Primary, number of nodes: 3, my index: 1, protocol version 3Węzeł Proxy SQL przestaje działać
Jeśli masz konfigurację wirtualnego adresu IP, wszystko, co musisz zrobić, to wskazać aplikacji na wirtualny adres IP i wszystko powinno być poprawne pod względem połączenia. Nie wystarczy mieć instancje bazy danych w wielu centrach danych, nadal potrzebujesz aplikacji, aby uzyskać do nich dostęp. Załóżmy, że skalowałeś liczbę replik do odczytu, możesz chcieć zaimplementować wirtualne adresy IP dla każdej z tych replik do odczytu ze względu na konserwację lub dostępność. Może stać się niewygodną pulą wirtualnych adresów IP, którymi musisz zarządzać. Jeśli jedna z tych replik do odczytu napotka awarię, musisz ponownie przypisać wirtualny adres IP do innego hosta, w przeciwnym razie aplikacja połączy się z hostem, który nie działa, lub w najgorszym przypadku z opóźnionym serwerem ze starymi danymi.
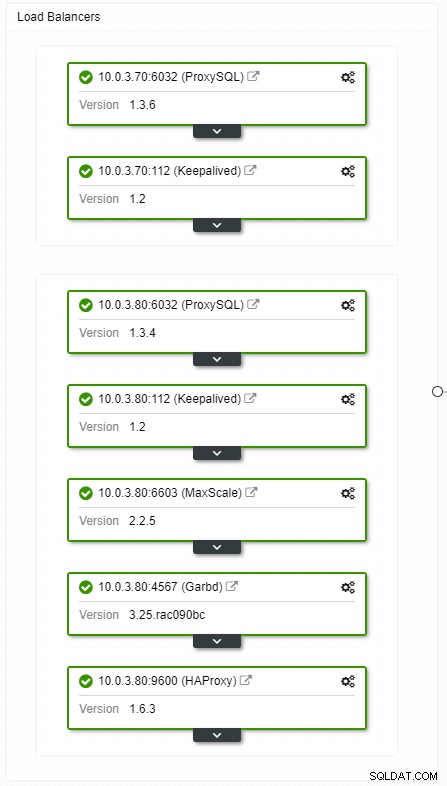 Widok topologii systemów równoważenia obciążenia ClusterControl HA
Widok topologii systemów równoważenia obciążenia ClusterControl HA Awarie nie są częste, ale bardziej prawdopodobne niż awarie serwerów. Jeśli z jakiegoś powodu slave ulegnie awarii, coś takiego jak ProxySQL przekieruje cały ruch do mastera, z ryzykiem jego przeciążenia. Gdy urządzenie podrzędne odzyska sprawność, ruch zostanie do niego przekierowany. Zazwyczaj taki przestój nie powinien zająć więcej niż kilka minut, więc ogólna dotkliwość jest średnia, nawet jeśli prawdopodobieństwo jest również średnie.
Aby mieć nadmiarowe komponenty systemu równoważenia obciążenia, możesz użyć funkcji keepalive.
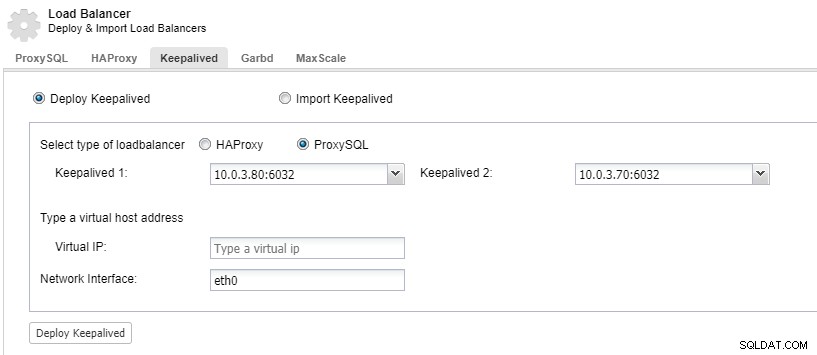 ClusterControl:Wdrażanie utrzymywania aktywności dla systemu równoważenia obciążenia ProxySQL
ClusterControl:Wdrażanie utrzymywania aktywności dla systemu równoważenia obciążenia ProxySQL Centrum danych upada
Główny problem z replikacją polega na tym, że nie ma mechanizmu większościowego do wykrywania awarii centrum danych i obsługi nowego mastera. Jednym z rozwiązań jest użycie Orchestrator/Raft. Orchestrator to nadzorca topologii, który może kontrolować przełączanie awaryjne. W połączeniu z Raftem, Orchestrator stanie się świadomy kworum. Jedna z instancji Orchestrator jest wybierana na lidera i wykonuje zadania odzyskiwania. Połączenie między węzłem programu Orchestrator nie jest skorelowane z zatwierdzeniami transakcyjnej bazy danych i jest rzadkie.
Orchestrator/Raft może korzystać z dodatkowych instancji monitorujących topologię. W przypadku partycjonowania sieciowego partycjonowane instancje Orchestrator nie podejmą żadnych działań. Część klastra Orchestrator, która posiada kworum, wybierze nowego mastera i wprowadzi niezbędne zmiany topologii.
ClusterControl służy do zarządzania, skalowania i, co najważniejsze, odzyskiwania węzłów — Orchestrator obsługuje przełączanie awaryjne, ale jeśli urządzenie podrzędne ulegnie awarii, ClusterControl upewni się, że zostanie odzyskane. Orchestrator i ClusterControl będą znajdować się w tej samej strefie dostępności, oddzielonej od węzłów MySQL, aby mieć pewność, że na ich aktywność nie będą miały wpływu podziały sieci między strefami dostępności w centrum danych.



