Głównym celem tworzenia kopii zapasowych danych jest oczywiście możliwość przywrócenia danych i uzyskania dostępu do archiwów w przypadku awarii sprzętu. Aby dziś prowadzić biznes, potrzebujesz pewności, że w przypadku katastrofy Twoje dane będą chronione i dostępne. Będziesz musiał przechowywać kopie zapasowe poza siedzibą firmy, na wypadek gdyby centrum danych spłonęło.
Ochrona danych pozostaje wyzwaniem dla małych i średnich przedsiębiorstw. Małe i średnie firmy wolą archiwizować dane swojej firmy przy użyciu pamięci masowej podłączanej bezpośrednio, a większość firm planuje wykonywanie kopii zapasowych poza siedzibą firmy. Podejście do lokalnego przechowywania może prowadzić do jednego z najpoważniejszych dylematów, przed jakimi może stanąć współczesna firma - utraty danych w przypadku katastrofy.
Przy podejmowaniu decyzji o tym, czy zezwolić na przeniesienie bazy danych o znaczeniu krytycznym dla firmy poza siedzibą firmy, oraz przy wyborze odpowiedniego dostawcy należy rozważyć wiele czynników. Tradycyjne metody, takie jak zapisywanie na taśmie i wysyłanie do zdalnej lokalizacji, mogą być skomplikowanym procesem, który wymaga specjalnego sprzętu, odpowiednio przeszkolonego personelu i procedur zapewniających regularne tworzenie kopii zapasowych, ochronę i weryfikację integralności zawartych w nich informacji. Małe firmy zwykle mają niewielkie budżety na IT. Często nie mogą sobie pozwolić na dodatkowe centrum danych, nawet jeśli mają dedykowane centrum danych. Niemniej jednak nadal ważne jest przechowywanie kopii plików kopii zapasowej poza siedzibą firmy. Katastrofy, takie jak huragan, powódź, pożar lub kradzież, mogą zniszczyć serwery i pamięć masową. Przechowywanie kopii zapasowych danych w oddzielnym centrum danych zapewnia bezpieczeństwo danych, niezależnie od tego, co dzieje się w głównym centrum danych. Przechowywanie w chmurze to świetny sposób na rozwiązanie tego problemu.
W przypadku tworzenia kopii zapasowych w chmurze należy wziąć pod uwagę wiele czynników. Oto niektóre z pytań:
- Czy dane w kopii zapasowej są zabezpieczone w spoczynku w zewnętrznym centrum danych?
- Czy transfer do lub z zewnętrznego centrum danych przez publiczną sieć internetową jest bezpieczny?
- Czy ma to wpływ na RTO (Cel czasu odzyskiwania)?
- Czy proces tworzenia kopii zapasowych i odzyskiwania jest wystarczająco łatwy dla naszego personelu IT?
- Czy są wymagane jakieś zmiany w istniejących procesach?
- Czy potrzebne są narzędzia do tworzenia kopii zapasowych innych firm?
- Jakie są dodatkowe koszty związane z wymaganym oprogramowaniem lub transferem danych?
- Jakie są koszty przechowywania?
Funkcje tworzenia kopii zapasowych podczas tworzenia kopii zapasowej w chmurze
Jeśli serwer MySQL lub miejsce docelowe kopii zapasowej znajduje się w ujawnionej infrastrukturze, takiej jak chmura publiczna, dostawca usług hostingowych lub jest połączony przez niezaufaną sieć WAN, musisz pomyśleć o dodatkowych działaniach w zasadach tworzenia kopii zapasowych. Istnieje kilka różnych sposobów wykonywania kopii zapasowych bazy danych dla MySQL, a w zależności od typu kopii zapasowej, czas odzyskiwania, rozmiar i opcje infrastruktury będą się różnić. Ponieważ wiele rozwiązań do przechowywania w chmurze to po prostu pamięć masowa z różnymi interfejsami API, każde rozwiązanie do tworzenia kopii zapasowych można wykonać za pomocą odrobiny skryptów. Więc jakie mamy opcje, aby proces był płynny i bezpieczny?
Szyfrowanie
Zawsze dobrze jest wymusić szyfrowanie w celu zwiększenia bezpieczeństwa danych kopii zapasowej. Prostym przypadkiem użycia szyfrowania jest sytuacja, w której chcesz przesłać kopię zapasową do zewnętrznego magazynu kopii zapasowej znajdującego się w chmurze publicznej.
Podczas tworzenia zaszyfrowanej kopii zapasowej należy pamiętać, że jej odzyskanie zwykle zajmuje więcej czasu. Kopia zapasowa musi zostać odszyfrowana przed podjęciem jakichkolwiek działań związanych z odzyskiwaniem. W przypadku dużego zestawu danych może to spowodować pewne opóźnienia w RTO.
Z drugiej strony, jeśli używasz klucza prywatnego do szyfrowania, upewnij się, że przechowujesz klucz w bezpiecznym miejscu. Jeśli brakuje klucza prywatnego, kopia zapasowa będzie bezużyteczna i niemożliwa do odzyskania. Jeśli klucz zostanie skradziony, wszystkie utworzone kopie zapasowe używające tego samego klucza zostaną naruszone, ponieważ nie będą już zabezpieczone. Możesz użyć popularnego GnuPG lub OpenSSL do wygenerowania kluczy prywatnych lub publicznych.
Aby wykonać szyfrowanie mysqldump za pomocą GnuPG, wygeneruj klucz prywatny i postępuj zgodnie z instrukcjami kreatora:
$ gpg --gen-keyUtwórz zwykłą kopię zapasową mysqldump jak zwykle:
$ mysqldump --routines --events --triggers --single-transaction db1 | gzip > db1.tar.gzZaszyfruj plik zrzutu i usuń starszą zwykłą kopię zapasową:
$ gpg --encrypt -r ‘example@sqldat.com’ db1.tar.gz
$ rm -f db1.tar.gz
GnuPG automatycznie doda rozszerzenie .gpg do zaszyfrowanego pliku. Aby odszyfrować,
po prostu uruchom polecenie gpg z flagą --decrypt:
$ gpg --output db1.tar.gz --decrypt db1.tar.gz.gpg
Aby utworzyć zaszyfrowany mysqldump przy użyciu OpenSSL, należy wygenerować klucz prywatny i klucz publiczny:
OpenSSL req -x509 -nodes -newkey rsa:2048 -keyout dump.priv.pem -out dump.pub.pem
Ten klucz prywatny (dump.priv.pem) należy przechowywać w bezpiecznym miejscu do późniejszego odszyfrowania. W przypadku mysqldump można utworzyć zaszyfrowaną kopię zapasową, na przykład przesyłając zawartość do openssl
mysqldump --routines --events --triggers --single-transaction database | openssl smime -encrypt -binary -text -aes256
-out database.sql.enc -outform DER dump.pub.pem
Aby odszyfrować, po prostu użyj klucza prywatnego (dump.priv.pem) obok flagi -decrypt:
openssl smime -decrypt -in database.sql.enc -binary -inform
DEM -inkey dump.priv.pem -out database.sqlPercona XtraBackup może służyć do szyfrowania lub odszyfrowywania lokalnych lub strumieniowych kopii zapasowych z opcją xbstream, aby dodać kolejną warstwę ochrony do kopii zapasowych. Szyfrowanie odbywa się za pomocą biblioteki libgcrypt. Do określenia klucza szyfrowania można użyć zarówno opcji --encrypt-key, jak i opcji --encryptkey-file. Klucze szyfrujące można generować za pomocą poleceń takich jak
$ openssl rand -base64 24
$ bWuYY6FxIPp3Vg5EDWAxoXlmEFqxUqz1Ta wartość może być następnie użyta jako klucz szyfrowania. Przykład polecenia innobackupex przy użyciu --encrypt-key:
$ innobackupex --encrypt=AES256 --encrypt-key=”bWuYY6FxIPp3Vg5EDWAxoXlmEFqxUqz1” /storage/backups/encryptedDane wyjściowe powyższego polecenia OpenSSL można również przekierować do pliku i traktować jako plik klucza:
openssl rand -base64 24 > /etc/keys/pxb.keyUżyj go z opcją --encrypt-key-file:
innobackupex --encrypt=AES256 --encrypt-key-file=/etc/keys/pxb.key /storage/backups/encryptedAby odszyfrować, po prostu użyj opcji --decrypt z odpowiednim --encrypt-key lub --encrypt-key-file:
$ innobackupex --decrypt=AES256 --encrypt-key=”bWuYY6FxIPp3Vg5EDWAxoXlmEFqxUqz1”
/storage/backups/encrypted/2018-11-18_11-10-09/Aby uzyskać więcej informacji na temat szyfrowania MySQL i MariaDB, zapoznaj się z naszym innym wpisem na blogu.
Kompresja
W świecie tworzenia kopii zapasowych baz danych w chmurze kompresja jest jednym z Twoich najlepszych przyjaciół. Może nie tylko zaoszczędzić miejsce na dysku, ale także znacznie skrócić czas potrzebny na pobieranie/przesyłanie danych.
Dostępnych jest wiele narzędzi do kompresji, a mianowicie gzip, bzip2, zip, rar i 7z.
Zwykle mysqldump może mieć najlepsze współczynniki kompresji, ponieważ jest to płaski plik tekstowy. W zależności od narzędzia i współczynnika kompresji, skompresowany mysqldump może być do 6 razy mniejszy niż oryginalny rozmiar kopii zapasowej. Aby skompresować kopię zapasową, możesz przesłać dane wyjściowe mysqldump do narzędzia do kompresji i przekierować je do pliku docelowego. Możesz także pominąć kilka rzeczy, takich jak komentarze, instrukcja blokady tabel (jeśli InnoDB), pominięcie oczyszczonego identyfikatora GTID i wyzwalaczy:
mysqldump --single-transaction --skip-comments --skip-triggers --skip-lock-tables --set-gtid-purged OFF --all-databases | gzip > /storage/backups/all-databases.sql.gzDzięki Percona Xtrabackup możesz korzystać z trybu strumieniowego (innobackupex), który przesyła kopię zapasową na STDOUT w specjalnym formacie tar lub xbstream zamiast kopiowania plików do katalogu kopii zapasowych. Posiadanie skompresowanej kopii zapasowej może zaoszczędzić do 50% oryginalnego rozmiaru kopii zapasowej, w zależności od zestawu danych. Dołącz opcję --compress do polecenia kopii zapasowej. Używając xbstream w kopiach strumieniowych, możesz przyspieszyć proces kompresji, używając opcji --compress-threads. Ta opcja określa liczbę wątków tworzonych przez xtrabackup do równoległej kompresji danych. Domyślna wartość tej opcji to 1. Aby użyć tej funkcji, dodaj opcję do lokalnej kopii zapasowej. Przykładowa kopia zapasowa z kompresją:
innobackupex --stream=xbstream --compress --compress-threads=4 > /storage/backups/backup.xbstream
Przed zastosowaniem logów na etapie przygotowania, skompresowane pliki będą musiały zostać
rozpakowane przy użyciu xbstream:
Następnie użyj qpress, aby rozpakować każdy plik kończący się na .qp w odpowiednim katalogu przed
uruchomieniem -- polecenie apply-log, aby przygotować dane MySQL.
$ xbstream -x < /storage/backups/backup.xbstreamOgranicz przepustowość sieci
Świetną opcją dla kopii zapasowych w chmurze jest ograniczenie przepustowości sieci (Mb/s) podczas tworzenia kopii zapasowej. Możesz to osiągnąć za pomocą narzędzia pv. Narzędzie pv jest dostarczane z opcjami modyfikatorów danych -L RATE, --rate-limit RATE, które ograniczają transfer do maksymalnie RATE bajtów na sekundę. Poniższy przykład ograniczy to do 2MB/s.
$ pv -q -L 2mW poniższym przykładzie możesz zobaczyć xtrabackup z równoległym gzipem, szyfrowaniem
/usr/bin/innobackupex --defaults-file=/etc/mysql/my.cnf --galera-info --parallel 4 --stream=xbstream --no-timestamp . | pv -q -L 2m | pigz -9 - | openssl enc -aes-256-cbc -pass file:/var/tmp/cmon-008688-19992-72450efc3b6e9e4f.tmp > /home/ubuntu/backups/BACKUP-3445/backup-full-2018-11-28_213540.xbstream.gz.aes256 ) 2>&1.Przenieś kopię zapasową do chmury
Teraz, gdy kopia zapasowa jest skompresowana i zaszyfrowana, jest gotowa do przesłania.
Chmura Google
Narzędzie wiersza poleceń gsutil służy do zarządzania zasobnikami na dane w Google Cloud Storage, ich monitorowania i korzystania z nich. Jeśli już zainstalowałeś narzędzie gcloud, masz już zainstalowany gsutil. W przeciwnym razie postępuj zgodnie z instrukcjami dla swojej dystrybucji Linuksa tutaj.
Aby zainstalować gcloud CLI, wykonaj poniższą procedurę:
curl https://sdk.cloud.google.com | bashUruchom ponownie powłokę:
exec -l $SHELLUruchom gcloud init, aby zainicjować środowisko gcloud:
gcloud initPo zainstalowaniu i uwierzytelnieniu narzędzia wiersza poleceń gsutil utwórz regionalny zasobnik pamięci o nazwie mysql-backups-storage w bieżącym projekcie.
gsutil mb -c regional -l europe-west1 gs://severalnines-storage/
Creating gs://mysql-backups-storage/Amazonka S3
Jeśli nie używasz RDS do obsługi baz danych, jest bardzo prawdopodobne, że tworzysz własne kopie zapasowe. Platforma AWS firmy Amazon, S3 (Amazon Simple Storage Service) to usługa przechowywania danych, której można używać do przechowywania kopii zapasowych baz danych lub innych krytycznych plików biznesowych. Niezależnie od tego, czy jest to instancja Amazon EC2, czy środowisko lokalne, możesz użyć tej usługi do zabezpieczenia swoich danych.
Podczas gdy kopie zapasowe można przesyłać za pośrednictwem interfejsu internetowego, dedykowany interfejs wiersza poleceń s3 może być używany do robienia tego z wiersza poleceń i za pomocą skryptów automatyzacji tworzenia kopii zapasowych. Jeśli kopie zapasowe mają być przechowywane przez bardzo długi czas, a czas odzyskiwania nie stanowi problemu, kopie zapasowe można przenieść do usługi Amazon Glacier, która zapewnia znacznie tańsze długoterminowe przechowywanie. Pliki (obiekty amazon) są logicznie przechowywane w ogromnym płaskim kontenerze o nazwie bucket. S3 przedstawia interfejs REST swoim wnętrzom. Możesz użyć tego interfejsu API do wykonywania operacji CRUD na zasobnikach i obiektach, a także do zmiany uprawnień i konfiguracji w obu.
Podstawową metodą dystrybucji AWS CLI w systemach Linux, Windows i macOS jest pip, menedżer pakietów dla Pythona. Instrukcję można znaleźć tutaj.
aws s3 cp severalnines.sql s3://severalnine-sbucket/mysql_backupsDomyślnie S3 zapewnia 11-sekundową trwałość obiektu. Oznacza to, że jeśli przechowujesz w nim 1.000.000.000 (1 miliard) obiektów, możesz spodziewać się utraty 1 obiektu średnio co 10 lat. Sposób, w jaki S3 osiąga tę imponującą liczbę dziewiątek, polega na automatycznej replikacji obiektu w wielu strefach dostępności, o czym powiemy w innym poście. Amazon ma regionalne centra danych na całym świecie.
Microsoft Azure Storage
Platforma chmury publicznej firmy Microsoft, Azure, oferuje opcje przechowywania z interfejsem linii kontrolnej. Informacje można znaleźć tutaj. Wieloplatformowy interfejs wiersza polecenia platformy Azure typu open source udostępnia zestaw poleceń do pracy z platformą Azure. Zapewnia wiele funkcji widocznych w portalu Azure, w tym bogaty dostęp do danych.
Instalacja Azure CLI jest dość prosta, instrukcje znajdziesz tutaj. Poniżej możesz dowiedzieć się, jak przenieść kopię zapasową do pamięci Microsoft.
az storage blob upload --container-name severalnines --file severalnines.sql --name severalnines_backupHybrydowa pamięć masowa dla kopii zapasowych MySQL i MariaDB
Wraz z rozwijającą się branżą pamięci masowej w chmurze publicznej i prywatnej, mamy nową kategorię zwaną pamięcią masową hybrydową. Ta technologia umożliwia przechowywanie plików lokalnie, a zmiany są automatycznie synchronizowane ze zdalnym dostępem w chmurze. Takie podejście wynika z potrzeby posiadania ostatnich kopii zapasowych przechowywanych lokalnie w celu szybkiego przywracania (niższe RTO), a także z celów ciągłości biznesowej.
Ważnym aspektem efektywnego wykorzystania zasobów jest posiadanie oddzielnych retencji kopii zapasowych. Dane przechowywane lokalnie, na nadmiarowych dyskach twardych byłyby przechowywane krócej, podczas gdy przechowywanie kopii zapasowych w chmurze byłoby przechowywane przez dłuższy czas. Wielokrotnie wymóg dłuższego przechowywania kopii zapasowych wynika z obowiązków prawnych dla różnych branż (takich jak telekomy, które muszą przechowywać metadane połączeń). Dostawcy chmury, tacy jak Google Cloud Services, Microsoft Azure i Amazon S3, oferują praktycznie nieograniczoną przestrzeń dyskową, zmniejszając lokalne zapotrzebowanie na przestrzeń. Pozwala to na dłuższe przechowywanie plików kopii zapasowej, tak długo, jak chcesz i nie ma obaw związanych z lokalną przestrzenią dyskową.
 Zarządzanie kopiami zapasowymi ClusterControl — hybrydowa pamięć masowa
Zarządzanie kopiami zapasowymi ClusterControl — hybrydowa pamięć masowa Podczas planowania tworzenia kopii zapasowej za pomocą ClusterControl, każda z metod tworzenia kopii zapasowych jest konfigurowalna z zestawem opcji dotyczących sposobu wykonywania kopii zapasowej. Najważniejsze dla hybrydowego przechowywania w chmurze to:
- Ograniczanie przepustowości sieci
- Szyfrowanie z wbudowanym zarządzaniem kluczami
- Kompresja
- Okres przechowywania lokalnych kopii zapasowych
- Okres przechowywania kopii zapasowych w chmurze
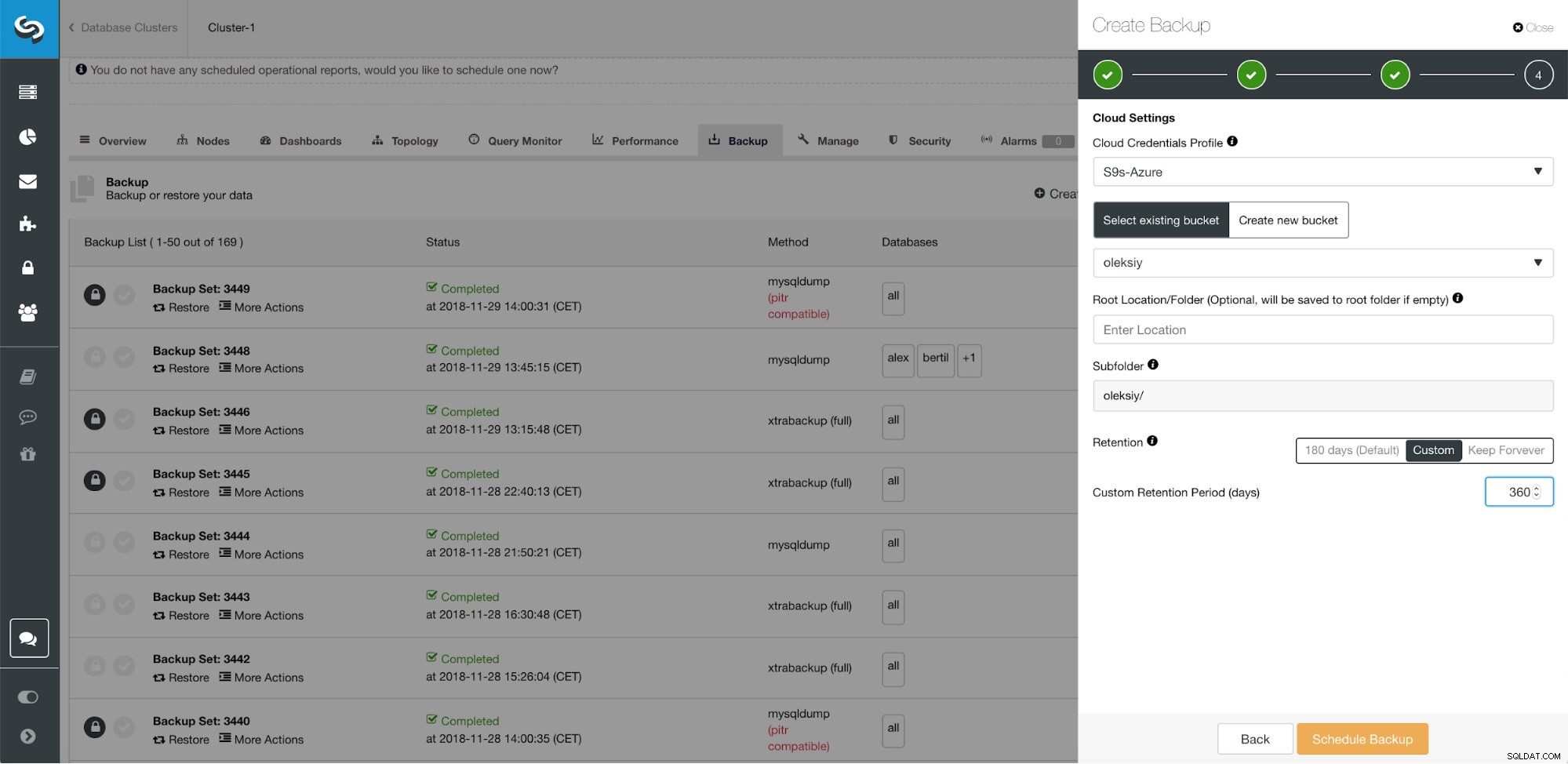 ClusterControl podwójna retencja kopii zapasowych
ClusterControl podwójna retencja kopii zapasowych 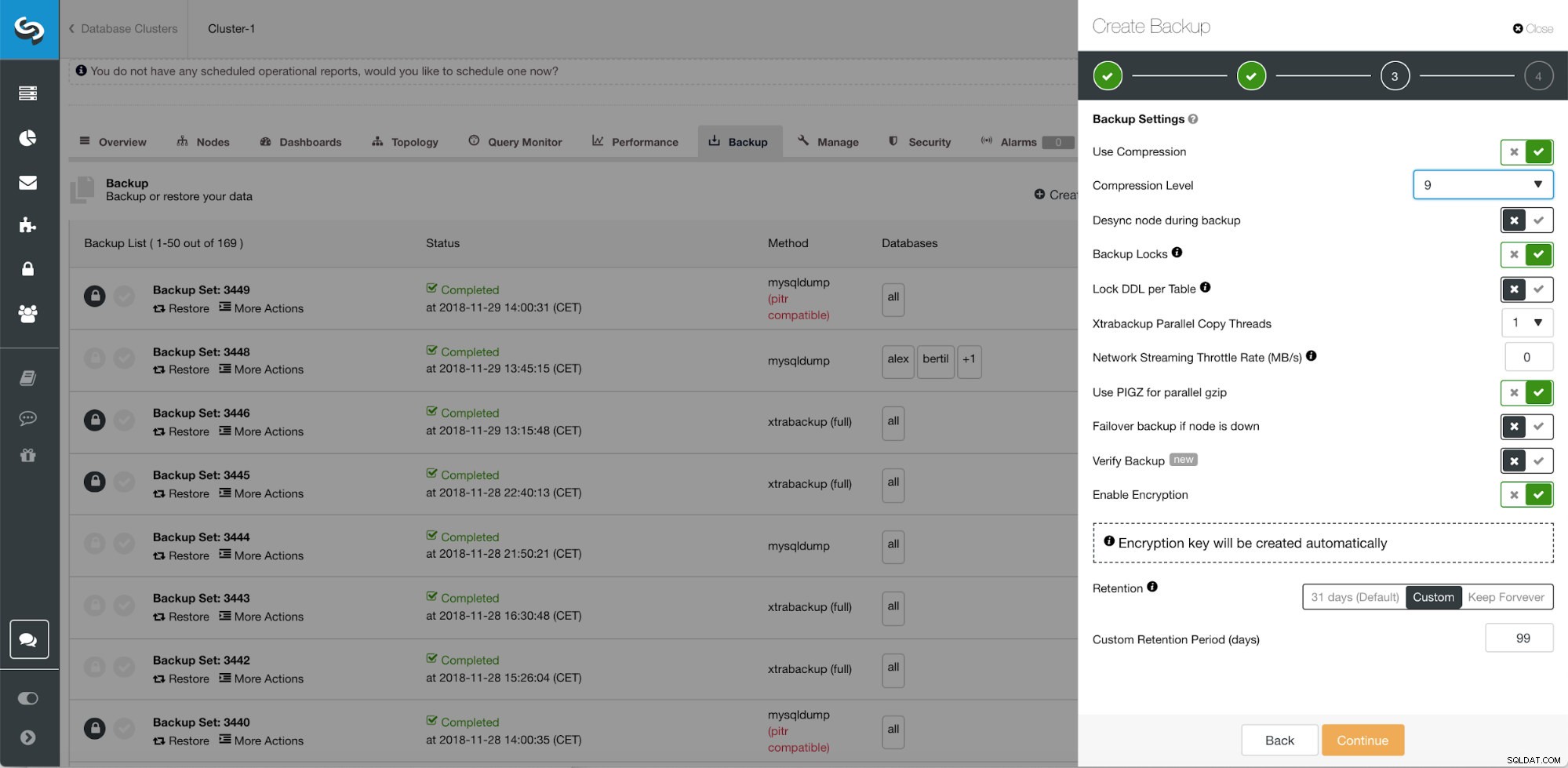 Zaawansowane funkcje tworzenia kopii zapasowych ClusterControl dla chmury, kompresji równoległej, limitu przepustowości sieci, szyfrowania itp...
Zaawansowane funkcje tworzenia kopii zapasowych ClusterControl dla chmury, kompresji równoległej, limitu przepustowości sieci, szyfrowania itp... Wniosek
Chmura zmieniła branżę tworzenia kopii zapasowych danych. Ze względu na przystępną cenę mniejsze firmy mają rozwiązanie poza siedzibą firmy, które tworzy kopie zapasowe wszystkich ich danych.
Twoja firma może skorzystać ze skalowalności chmury i opłat zgodnie z rzeczywistym użyciem, aby zaspokoić rosnące potrzeby w zakresie pamięci masowej. Możesz zaprojektować strategię tworzenia kopii zapasowych, aby zapewnić zarówno lokalne kopie w centrum danych w celu natychmiastowego przywrócenia, jak i bezproblemową bramę do usług przechowywania w chmurze od AWS, Google i Azure.
Zaawansowane 256-bitowe funkcje szyfrowania i kompresji TLS i AES obsługują bezpieczne kopie zapasowe, które zajmują znacznie mniej miejsca w chmurze.