Migracja z bazy danych Oracle do open source może przynieść szereg korzyści. Niższy koszt posiadania jest kuszący i skłania wiele firm do migracji. Jednocześnie DevOps, SysOps lub DBA muszą utrzymać ścisłe umowy SLA w celu zaspokojenia potrzeb biznesowych.
Jednym z kluczowych problemów podczas planowania migracji danych do innej bazy danych, zwłaszcza open source, jest sposób uniknięcia utraty danych. Nie jest zbyt daleko idące, że ktoś przypadkowo usunął część bazy danych, ktoś zapomniał zawrzeć klauzulę WHERE w zapytaniu DELETE lub przypadkowo uruchomić DROP TABLE. Pytanie brzmi, jak wyjść z takich sytuacji.
Takie rzeczy mogą się zdarzyć i będą się zdarzać, jest to nieuniknione, ale skutki mogą być katastrofalne. Jak ktoś powiedział:„To wszystko jest zabawne i gry, dopóki tworzenie kopii zapasowej się nie powiedzie”. Najcenniejszy zasób nie może zostać naruszony. Okres.
Strach przed nieznanym jest naturalny, jeśli nie znasz nowych technologii. W rzeczywistości wiedza na temat rozwiązań bazodanowych Oracle, niezawodności i wspaniałych funkcji oferowanych przez Oracle Recovery Manager (RMAN) może zniechęcić Ciebie lub Twój zespół do migracji do nowego systemu bazodanowego. Lubimy korzystać z rzeczy, które znamy, więc po co migrować, gdy nasze obecne rozwiązanie działa. Kto wie, ile projektów zostało wstrzymanych, ponieważ zespół lub osoba nie była przekonana do nowej technologii?
Logiczne kopie zapasowe (exp/imp, expdp/impdb)
Zgodnie z dokumentacją MySQL, logiczna kopia zapasowa to „kopia zapasowa, która odtwarza strukturę tabeli i dane, bez kopiowania rzeczywistych plików danych”. Ta definicja może dotyczyć zarówno świata MySQL, jak i Oracle. To samo dotyczy „dlaczego” i „kiedy” użyjesz kopii logicznej.
Logiczne kopie zapasowe są dobrym rozwiązaniem, gdy wiemy, jakie dane zostaną zmodyfikowane, dzięki czemu możesz wykonać kopię zapasową tylko tej części, której potrzebujesz. Upraszcza potencjalne przywracanie pod względem czasu i złożoności. Jest to również bardzo przydatne, jeśli musimy przenieść część małego/średniego zestawu danych i skopiować z powrotem do innego systemu (często w innej wersji bazy danych). Oracle używa narzędzi eksportu, takich jak exp i expdp, do odczytywania danych z bazy danych, a następnie eksportowania ich do pliku na poziomie systemu operacyjnego. Następnie możesz zaimportować dane z powrotem do bazy danych za pomocą narzędzi importu imp lub impdp.
Oracle Export Utilities daje nam wiele opcji wyboru danych do wyeksportowania. Na pewno nie znajdziesz takiej samej liczby funkcji w mysql, ale większość potrzeb jest zaspokojona, a resztę można wykonać za pomocą dodatkowych skryptów lub narzędzi zewnętrznych (sprawdź mydumper).
MySQL jest dostarczany z pakietem narzędzi oferujących bardzo podstawową funkcjonalność. Są to mysqldump, mysqlpump (nowoczesna wersja mysqldump, która ma natywną obsługę równoległości) i klient MySQL, który można wykorzystać do wyodrębnienia danych do zwykłego pliku.
Poniżej znajdziesz kilka przykładów ich użycia:
Kopia zapasowa tylko struktury bazy danych
mysqldump --no-data -h localhost -u root -ppassword mydatabase > mydatabase_backup.sqlZapasowa struktura tabeli
mysqldump --no-data --single- transaction -h localhost -u root -ppassword mydatabase table1 table2 > mydatabase_backup.sqlUtwórz kopię zapasową określonych wierszy
mysqldump -h localhost --single- transaction -u root -ppassword mydatabase table_name --where="date_created='2019-05-07'" > table_with_specific_rows_dump.sqlImportowanie tabeli
mysql -u username -p -D dbname < tableName.sqlPowyższe polecenie zatrzyma ładowanie, jeśli wystąpi błąd.
Jeśli ładujesz dane bezpośrednio z klienta mysql, błędy zostaną zignorowane, a klient będzie kontynuował
mysql> source tableName.sqlAby zapisać dane wyjściowe, musisz użyć
mysql> tee import_tableName.logWszystkie flagi wyjaśnione pod poniższymi linkami:
- https://dev.mysql.com/doc/refman/8.0/en/mysqldump.html
- https://dev.mysql.com/doc/refman/8.0/en/mysqlimport.html
- https://dev.mysql.com/doc/refman/8.0/en/mysql.html
Jeśli planujesz używać logicznej kopii zapasowej w różnych wersjach baz danych, upewnij się, że masz odpowiednią konfigurację sortowania. Poniższej instrukcji można użyć do sprawdzenia domyślnego zestawu znaków i sortowania dla danej bazy danych:
USE mydatabase;
SELECT @@character_set_database, @@collation_database;Innym sposobem pobrania zmiennej systemowej collation_database jest użycie polecenia POKAŻ ZMIENNE.
SHOW VARIABLES LIKE 'collation%';Ze względu na ograniczenia zrzutu mysql często musimy modyfikować dane wyjściowe. Przykładem takiej modyfikacji może być konieczność usunięcia niektórych linii. Na szczęście mamy możliwość przeglądania i modyfikowania danych wyjściowych za pomocą standardowych narzędzi tekstowych przed przywróceniem. Narzędzia takie jak awk, grep, sed mogą stać się twoim przyjacielem. Poniżej znajduje się prosty przykład, jak usunąć trzecią linię z pliku zrzutu.
sed -i '1,3d' file.txtMożliwości są nieskończone. To jest coś, czego nie znajdziemy w Oracle, ponieważ dane są zapisywane w formacie binarnym.
Jest kilka rzeczy, które musisz wziąć pod uwagę podczas uruchamiania logicznego mysql. Jednym z głównych ograniczeń jest czysta obsługa równoległości i blokowania obiektów.
Zagadnienia dotyczące tworzenia kopii logicznych
Po wykonaniu takiej kopii zapasowej zostaną wykonane następujące kroki.
- Tabela BLOKADA TABELI.
- POKAŻ tabelę CREATE TABLE.
- WYBIERZ * Z tabeli DO pliku tymczasowego OUTFILE.
- Zapisz zawartość pliku tymczasowego na końcu pliku zrzutu.
- ODBLOKUJ STOŁY
Domyślnie mysqldump nie uwzględnia w swoich danych wyjściowych procedur i zdarzeń — musisz jawnie ustawić flagi --routines i --events.
Inną ważną kwestią jest silnik, którego używasz do przechowywania danych. Mam nadzieję, że w dzisiejszych czasach większość systemów produkcyjnych używa silnika zgodnego z ACID o nazwie InnoDB. Starszy silnik MyISAM musiał blokować wszystkie tabele, aby zapewnić spójność. To jest, gdy wykonywano FLUSH TABLES WITH READ LOCK. Niestety, jest to jedyny sposób, aby zagwarantować spójną migawkę tabel MyISAM podczas działania serwera MySQL. To sprawi, że serwer MySQL stanie się tylko do odczytu do momentu wykonania UNLOCK TABLES.
W przypadku tabel w silniku przechowywania InnoDB zaleca się użycie opcji --single- transaction. MySQL tworzy następnie punkt kontrolny, który umożliwia zrzutowi przechwycenie wszystkich danych przed punktem kontrolnym podczas odbierania nadchodzących zmian.
Opcja --single-transaction mysqldump nie wykonuje funkcji FLUSH TABLES WITH READ LOCK. Powoduje to, że mysqldump ustawia POWTARZALNĄ transakcję ODCZYTU dla wszystkich zrzucanych tabel.
Kopia zapasowa mysqldump jest znacznie wolniejsza niż narzędzia Oracle exp, expdp. Mysqldump jest narzędziem jednowątkowym i jest to jego najważniejsza wada - wydajność jest dobra dla małych baz danych, ale szybko staje się nie do zaakceptowania, jeśli zestaw danych rozrasta się do dziesiątek gigabajtów.
- ROZPOCZNIJ TRANSAKCJĘ ZE SPÓJNYM MIGAWEM.
- Dla każdego schematu i tabeli bazy danych zrzut wykonuje następujące kroki:
- POKAŻ tabelę CREATE TABLE.
- WYBIERZ * Z tabeli DO pliku tymczasowego OUTFILE.
- Zapisz zawartość pliku tymczasowego na końcu pliku zrzutu.
- POTWIERDZENIE.
Fizyczne kopie zapasowe (RMAN)
Na szczęście większość ograniczeń logicznego tworzenia kopii zapasowych można rozwiązać za pomocą narzędzia Percona Xtrabackup. Percona XtraBackup to najpopularniejsze oprogramowanie do tworzenia kopii zapasowych typu open source MySQL/MariaDB, które wykonuje nieblokujące kopie zapasowe baz danych InnoDB i XtraDB. Należy do kategorii fizycznej kopii zapasowej, która składa się z dokładnych kopii katalogu danych MySQL i znajdujących się pod nim plików.
To ta sama kategoria narzędzi, co Oracle RMAN. RMAN jest częścią oprogramowania bazodanowego, XtraBackup należy pobrać osobno. Xtrabackup jest dostępny jako pakiet rpm i deb i obsługuje tylko platformy Linux. Instalacja jest bardzo prosta:
$ wget https://www.percona.com/downloads/XtraBackup/Percona-XtraBackup-8.0.4/binary/redhat/7/x86_64/percona-XtraBackup-80-8.0.4-1.el7.x86_64.rpm
$ yum localinstall percona-XtraBackup-80-8.0.4-1.el7.x86_64.rpmXtraBackup nie blokuje bazy danych podczas procesu tworzenia kopii zapasowej. W przypadku dużych baz danych (100+ GB) zapewnia znacznie lepszy czas przywracania w porównaniu do mysqldump. Proces przywracania obejmuje przygotowanie danych MySQL z plików kopii zapasowej, przed zastąpieniem ich lub zamianą na bieżący katalog danych w węźle docelowym.
Percona XtraBackup działa poprzez zapamiętywanie numeru sekwencyjnego dziennika (LSN) podczas uruchamiania, a następnie kopiowanie plików danych do innej lokalizacji. Kopiowanie danych zajmuje trochę czasu, a jeśli pliki się zmieniają, odzwierciedlają stan bazy danych w różnych momentach. Jednocześnie XtraBackup uruchamia proces w tle, który kontroluje pliki dziennika transakcji (tzw. redo log) i kopiuje z niego zmiany. Należy to robić w sposób ciągły, ponieważ dzienniki transakcji są zapisywane w sposób okrężny i po pewnym czasie można je ponownie wykorzystać. XtraBackup potrzebuje zapisów dziennika transakcji dla każdej zmiany w plikach danych od momentu rozpoczęcia wykonywania.
Po zainstalowaniu XtraBackup możesz wreszcie wykonać swoje pierwsze fizyczne kopie zapasowe.
xtrabackup --user=root --password=PASSWORD --backup --target-dir=/u01/backups/Inną przydatną opcją, którą robią administratorzy MySQL, jest przesyłanie kopii zapasowej na inny serwer. Strumień taki można wykonać za pomocą narzędzia xbstream, jak na poniższym przykładzie:
Uruchom słuchacz na zewnętrznym serwerze na preferowanym porcie (w tym przykładzie 1984)
nc -l 1984 | pigz -cd - | pv | xbstream -x -C /u01/backupsUruchom kopię zapasową i przenieś do zewnętrznego hosta
innobackupex --user=root --password=PASSWORD --stream=xbstream /var/tmp | pigz | pv | nc external_host.com 1984Jak można zauważyć proces przywracania jest podzielony na dwa główne etapy (podobnie jak w Oracle). Kroki są przywracane (kopiowanie z powrotem) i odzyskiwanie (zastosowanie dziennika).
XtraBackup --copy-back --target-dir=/var/lib/data
innobackupex --apply-log --use-memory=[values in MB or GB] /var/lib/dataRóżnica polega na tym, że możemy wykonać odzyskiwanie tylko do punktu, w którym wykonano kopię zapasową. Aby zastosować zmiany po utworzeniu kopii zapasowej, musimy to zrobić ręcznie.
Przywracanie punktu w czasie (odzyskiwanie RMAN)
W Oracle RMAN wykonuje wszystkie kroki, gdy wykonujemy odzyskiwanie bazy danych. Można to zrobić według SCN, czasu lub na podstawie zestawu danych kopii zapasowej.
RMAN> run
{
allocate channel dev1 type disk;
set until time "to_date('2019-05-07:00:00:00', 'yyyy-mm-dd:hh24:mi:ss')";
restore database;
recover database; }W mysql potrzebujemy innego narzędzia do wydobycia danych z logów binarnych (podobnie jak w archiwach Oracle) mysqlbinlog. mysqlbinlog może odczytywać logi binarne i konwertować je na pliki. Co musimy zrobić, to
Podstawowa procedura to
- Przywróć pełną kopię zapasową
- Przywróć przyrostowe kopie zapasowe
- Aby określić czas rozpoczęcia i zakończenia odzyskiwania (może to być koniec tworzenia kopii zapasowej i numer pozycji przed niestety upuszczeniem tabeli).
- Przekonwertuj niezbędne logi Bingloga na SQL i zastosuj nowo utworzone pliki SQL w odpowiedniej kolejności — upewnij się, że uruchamiasz jedno polecenie mysqlbinlog.
> mysqlbinlog binlog.000001 binlog.000002 | mysql -u root -p
Szyfruj kopie zapasowe (portfel Oracle)
Percona XtraBackup może służyć do szyfrowania lub odszyfrowywania lokalnych lub strumieniowych kopii zapasowych z opcją xbstream, aby dodać kolejną warstwę ochrony do kopii zapasowych. Do określenia klucza szyfrowania można użyć zarówno opcji --encrypt-key, jak i opcji --encryptkey-file. Klucze szyfrujące można generować za pomocą poleceń takich jak
$ openssl rand -base64 24
$ bWuYY6FxIPp3Vg5EDWAxoXlmEFqxUqz1Ta wartość może być następnie użyta jako klucz szyfrowania. Przykład polecenia innobackupex przy użyciu --encrypt-key:
$ innobackupex --encrypt=AES256 --encrypt-key=”bWuYY6FxIPp3Vg5EDWAxoXlmEFqxUqz1” /storage/backups/encryptedAby odszyfrować, po prostu użyj opcji --decrypt z odpowiednim --encrypt-key:
$ innobackupex --decrypt=AES256 --encrypt-key=”bWuYY6FxIPp3Vg5EDWAxoXlmEFqxUqz1”
/storage/backups/encrypted/2019-05-08_11-10-09/Zasady tworzenia kopii zapasowych
Nie ma wbudowanej funkcjonalności polityki tworzenia kopii zapasowych ani w MySQL/MariaDB, ani nawet w narzędziu Percony. Jeśli chcesz zarządzać swoimi logicznymi lub fizycznymi kopiami zapasowymi MySQL, możesz użyć do tego ClusterControl.
ClusterControl to kompleksowy system zarządzania bazami danych typu open source dla użytkowników w środowiskach mieszanych. Zapewnia zaawansowaną funkcję zarządzania kopiami zapasowymi dla MySQL lub MariaDB.
Dzięki ClusterControl możesz:
- Tworzenie zasad tworzenia kopii zapasowych
- Monitoruj stan kopii zapasowych, wykonania i serwery bez kopii zapasowych
- Wykonywanie kopii zapasowych i przywracanie (w tym odzyskiwanie do określonego momentu)
- Kontroluj przechowywanie kopii zapasowych
- Zapisuj kopie zapasowe w chmurze
- Weryfikuj kopie zapasowe (pełny test z przywracaniem na samodzielnym serwerze)
- Zaszyfruj kopie zapasowe
- Kompresuj kopie zapasowe
- I wiele innych
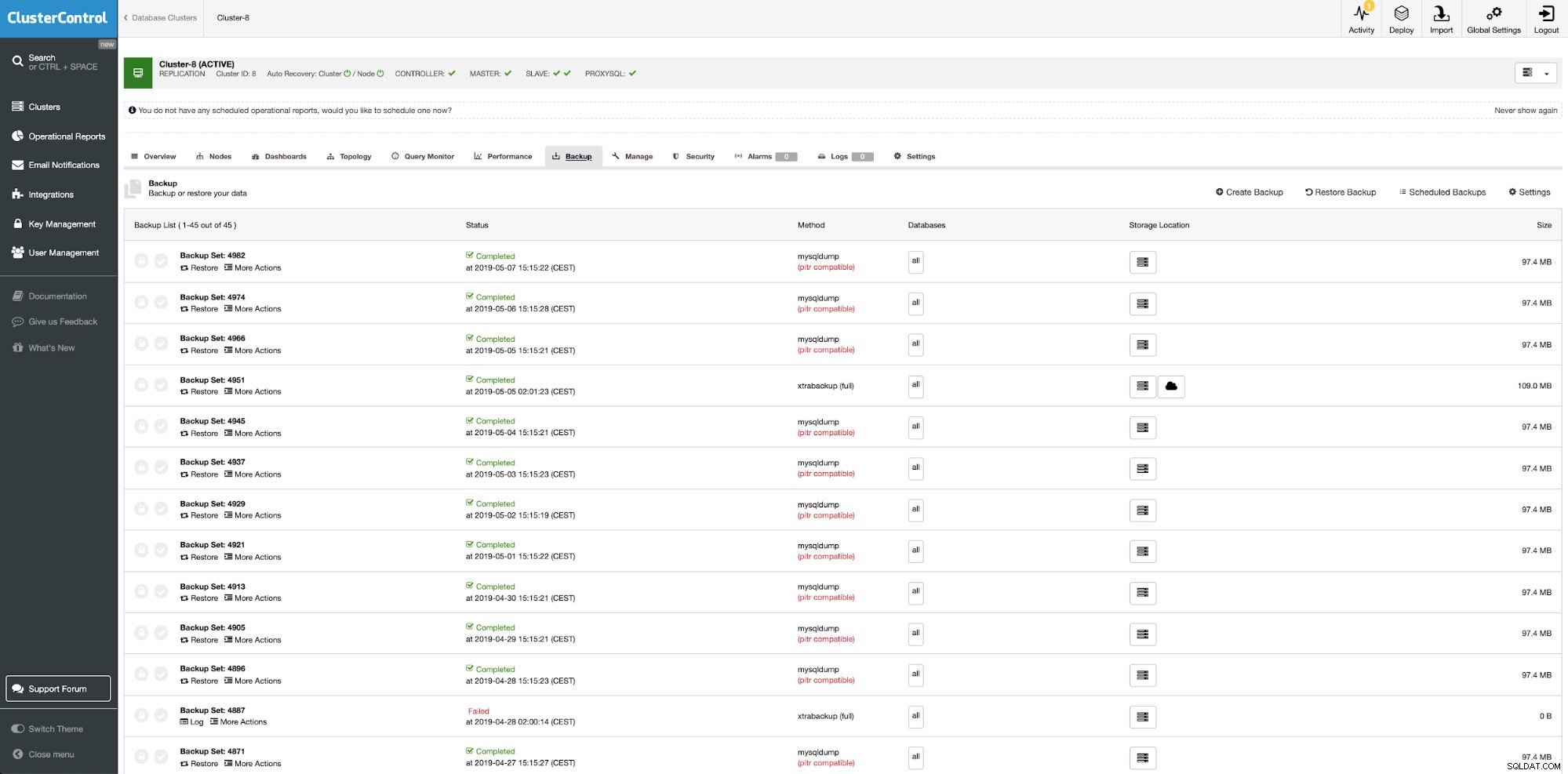 ClusterControl:zarządzanie kopiami zapasowymi
ClusterControl:zarządzanie kopiami zapasowymi Trzymaj kopie zapasowe w chmurze
Organizacje od dawna wdrażały rozwiązania do tworzenia kopii zapasowych na taśmach jako środek ochrony
danych przed awariami. Jednak pojawienie się publicznej chmury obliczeniowej umożliwiło również stworzenie nowych modeli o niższym całkowitym koszcie posiadania niż te, które były tradycyjnie dostępne. Nie ma sensu biznesowego wyodrębnianie kosztu rozwiązania DR od jego projektu, więc organizacje muszą wdrożyć odpowiedni poziom ochrony przy możliwie najniższych kosztach.
Chmura zmieniła branżę tworzenia kopii zapasowych danych. Ze względu na przystępną cenę mniejsze firmy mają rozwiązanie poza siedzibą firmy, które tworzy kopie zapasowe wszystkich ich danych (i tak, upewnij się, że są szyfrowane). Zarówno Oracle, jak i MySQL nie oferują wbudowanych rozwiązań do przechowywania w chmurze. Zamiast tego możesz skorzystać z narzędzi dostarczanych przez dostawców chmury. Przykładem może być s3.
aws s3 cp severalnines.sql s3://severalnine-sbucket/mysql_backupsWniosek

Istnieje wiele sposobów tworzenia kopii zapasowych bazy danych, ale ważne jest, aby przeanalizować potrzeby biznesowe przed podjęciem decyzji o strategii tworzenia kopii zapasowych. Jak widać, istnieje wiele podobieństw między kopiami zapasowymi MySQL i Oracle, które, miejmy nadzieję, mogą spełnić Twoje SLA.
Zawsze upewnij się, że ćwiczysz te polecenia. Nie tylko wtedy, gdy jesteś nowy w tej technologii, ale gdy DBMS staje się bezużyteczny, więc wiesz, co robić.
Jeśli chcesz dowiedzieć się więcej o MySQL, zapoznaj się z naszym oficjalnym dokumentem The DevOps Guide to Database Backup for MySQL and MariaDB.