Docelowy czas odzyskiwania (RTO) to czas, w którym usługa musi zostać przywrócona, aby uniknąć niedopuszczalnych konsekwencji. Obliczając, ile czasu może potrwać odzyskiwanie po awarii bazy danych, możemy wiedzieć, jaki jest wymagany poziom przygotowania. Jeśli RTO trwa kilka minut, wymagana jest znaczna inwestycja w przełączanie awaryjne. RTO wynoszący 36 godzin wymaga znacznie mniejszej inwestycji. I tu pojawia się automatyzacja przełączania awaryjnego.
W naszych poprzednich blogach omawialiśmy przełączanie awaryjne dla MongoDB, MySQL/MariaDB/Percona, PostgreSQL lub TimeScaleDB. Podsumowując, „Przełączenie awaryjne „ to zdolność systemu do kontynuowania działania nawet w przypadku wystąpienia jakiejś awarii. Sugeruje to, że funkcje systemu są przejmowane przez elementy drugorzędne, jeśli elementy podstawowe ulegną awarii. Przełączanie awaryjne jest naturalną częścią każdego systemu o wysokiej dostępności, a w niektórych przypadkach , musi być nawet zautomatyzowane. Ręczne przełączanie awaryjne trwa zbyt długo, ale zdarzają się przypadki, w których automatyzacja nie działa dobrze – na przykład w przypadku podzielonego mózgu, w którym replikacja bazy danych jest uszkodzona, a dwie „połówki” nadal otrzymują aktualizacje, skutecznie co prowadzi do rozbieżnych zestawów danych i niespójności.
Wcześniej pisaliśmy o zasadach przewodnich procedur automatycznego przełączania awaryjnego ClusterControl. Tam, gdzie to możliwe, automatyczne przełączanie awaryjne zapewnia wydajność, ponieważ umożliwia szybkie przywrócenie sprawności po awariach. W tym blogu przyjrzymy się, jak osiągnąć automatyczne przełączanie awaryjne w konfiguracji replikacji master-slave (lub podstawowej gotowości) przy użyciu ClusterControl.
Wymagania dotyczące stosu technologii
Stos można złożyć z komponentów oprogramowania Open Source i dostępnych jest wiele opcji — niektóre bardziej odpowiednie niż inne, w zależności od charakterystyki przełączania awaryjnego, a także poziomu wiedzy dostępnej w zakresie zarządzania i konserwacji rozwiązania. Sprzęt i sieć to również ważne aspekty.
Oprogramowanie
W ekosystemie open source dostępnych jest wiele opcji, których można użyć do wdrożenia przełączania awaryjnego. W przypadku MySQL możesz skorzystać z MHA, MMM, Maxscale/MRM, mysqlfailover lub Orchestrator. Ten poprzedni blog porównuje MaxScale do MHA z Maxscale/MRM. PostgreSQL ma repmgr, Patroni, PostgreSQL Automatic Failover (PAF), pglookout, pgPool-II lub stolon. Te różne opcje wysokiej dostępności zostały omówione wcześniej. MongoDB ma zestawy replik z obsługą automatycznego przełączania awaryjnego.
ClusterControl zapewnia automatyczną funkcję przełączania awaryjnego dla MySQL, MariaDB, PostgreSQL i MongoDB, którą omówimy w dalszej części. Warto zauważyć, że ma również funkcję automatycznego odzyskiwania uszkodzonych węzłów lub klastrów.
Sprzęt
Automatyczne przełączanie awaryjne jest zwykle wykonywane przez oddzielny serwer demonów, który jest skonfigurowany na własnym sprzęcie — niezależnie od węzłów bazy danych. Monitoruje stan baz danych i wykorzystuje informacje do podejmowania decyzji, jak zareagować w przypadku awarii.
Serwery Commodity mogą działać dobrze, chyba że serwer monitoruje ogromną liczbę instancji. Zazwyczaj kontrole systemu i analiza kondycji są lekkie pod względem przetwarzania. Jednakże, jeśli masz dużą liczbę węzłów do sprawdzenia, duży procesor i pamięć są koniecznością, zwłaszcza gdy kontrole muszą być ustawione w kolejce, gdy próbuje pingować i gromadzić informacje z serwerów. Monitorowane i nadzorowane węzły mogą czasami utknąć z powodu problemów z siecią, dużego obciążenia lub, w gorszym przypadku, mogą być wyłączone z powodu awarii sprzętu lub uszkodzenia hosta maszyny wirtualnej. Tak więc serwer, który przeprowadza kontrole stanu i systemu, powinien wytrzymać takie przestoje, ponieważ istnieje prawdopodobieństwo, że przetwarzanie kolejek może wzrosnąć, ponieważ odpowiedzi na każdy z monitorowanych węzłów może zająć trochę czasu, zanim zostanie zweryfikowane, że nie jest już dostępny lub upłynął limit czasu. został osiągnięty.
W przypadku środowisk opartych na chmurze istnieją usługi oferujące automatyczne przełączanie awaryjne. Na przykład Amazon RDS używa DRBD do replikacji pamięci masowej do węzła rezerwowego. Lub jeśli przechowujesz swoje woluminy w EBS, są one replikowane w wielu strefach.
Sieć
Oprogramowanie do zautomatyzowanego przełączania awaryjnego często opiera się na agentach skonfigurowanych w węzłach bazy danych. Agent zbiera informacje lokalnie z instancji bazy danych i wysyła je na serwer na żądanie.
Jeśli chodzi o wymagania sieciowe, upewnij się, że masz dobrą przepustowość i stabilne połączenie sieciowe. Kontrole należy przeprowadzać często, a pominięte bicie serca z powodu niestabilnej sieci może prowadzić do tego, że oprogramowanie do przełączania awaryjnego (błędnie) wywnioskuje, że węzeł nie działa.
ClusterControl nie wymaga żadnego agenta zainstalowanego na węzłach bazy danych, ponieważ będzie on SSH w każdym węźle bazy danych w regularnych odstępach czasu i wykonał szereg kontroli.
Automatyczne przełączanie awaryjne z ClusterControl
ClusterControl oferuje możliwość ręcznego i automatycznego przełączania awaryjnego. Zobaczmy, jak można to zrobić.
Przełączanie awaryjne w ClusterControl można skonfigurować tak, aby było automatyczne lub nie. Jeśli wolisz ręcznie zająć się przełączaniem awaryjnym, możesz wyłączyć automatyczne odzyskiwanie klastra. Podczas ręcznego przełączania awaryjnego możesz przejść do Klaster → Topologia w ClusterControl. Zobacz zrzut ekranu poniżej:
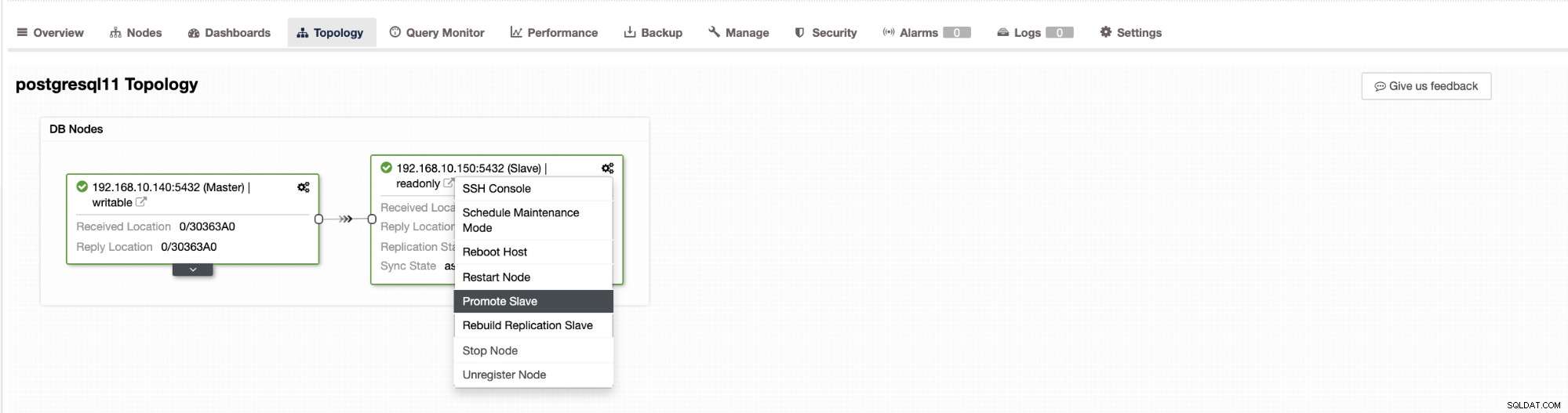
Domyślnie odzyskiwanie klastra jest włączone i używane jest automatyczne przełączanie awaryjne. Po wprowadzeniu zmian w interfejsie użytkownika zmienia się konfiguracja środowiska wykonawczego. Jeśli chcesz, aby ustawienie przetrwało ponowne uruchomienie kontrolera, upewnij się, że wprowadziłeś również zmianę w konfiguracji cmon, tj. /etc/cmon.d/cmon_

Na serwerze MySQL/MariaDB/Percona automatyczne przełączanie awaryjne jest inicjowane przez ClusterControl, gdy wykryje, że nie ma hosta z opcją tylko do odczytu flaga wyłączona. Może się to zdarzyć, ponieważ master (który ma tylko do odczytu ustawiony na 0) nie jest dostępny lub może zostać wyzwolony przez użytkownika lub oprogramowanie zewnętrzne, które zmieniło tę flagę na urządzeniu głównym. Jeśli ręcznie wprowadzasz zmiany w węzłach bazy danych lub masz oprogramowanie, które może mieć problemy z ustawieniami tylko do odczytu, powinieneś wyłączyć automatyczne przełączanie awaryjne. Automatyczne przełączanie awaryjne ClusterControl jest podejmowane tylko raz, dlatego po nieudanym przełączeniu awaryjnym nie nastąpi kolejne przełączenie awaryjne - dopiero po ponownym uruchomieniu cmon.
W przypadku PostgreSQL ClusterControl wybierze najbardziej zaawansowany slave, wykorzystując w tym celu pg_current_xlog_location (PostgreSQL 9+) lub pg_current_wal_lsn (PostgreSQL 10+) w zależności od wersji naszej bazy danych. ClusterControl wykonuje również kilka kontroli procesu przełączania awaryjnego, aby uniknąć niektórych typowych błędów. Jednym z przykładów jest to, że jeśli uda nam się odzyskać naszego starego, nieudanego mastera, „nie” zostanie automatycznie ponownie wprowadzony do klastra, ani jako nadrzędny, ani jako podrzędny. Musimy to zrobić ręcznie. Pozwoli to uniknąć możliwości utraty danych lub niespójności w przypadku, gdy nasz podrzędny (którego promowaliśmy) był opóźniony w tym czasie awarii. Możemy również szczegółowo przeanalizować problem przed ponownym wprowadzeniem go do konfiguracji replikacji, aby zachować informacje diagnostyczne.
Ponadto, jeśli przełączanie awaryjne nie powiedzie się, nie są podejmowane żadne dalsze próby (dotyczy to zarówno klastrów opartych na PostgreSQL, jak i MySQL), konieczna jest ręczna interwencja w celu przeanalizowania problemu i wykonania odpowiednich działań. Ma to na celu uniknięcie sytuacji, w której ClusterControl, który obsługuje automatyczne przełączanie awaryjne, próbuje promować następne urządzenie podrzędne i następne. Może wystąpić problem i nie chcemy pogarszać sytuacji, próbując wielu przełączeń awaryjnych.
ClusterControl oferuje białą i czarną listę zestawu serwerów, które chcesz wziąć udział w przełączaniu awaryjnym lub wykluczyć jako kandydata.
W przypadku klastrów typu MySQL, ClusterControl buduje listę urządzeń podrzędnych, które można promować do stanu master. W większości przypadków będzie zawierał wszystkie urządzenia podrzędne w topologii, ale użytkownik ma nad nimi dodatkową kontrolę. W konfiguracji cmon można ustawić dwie zmienne:
replication_failover_whitelisti
replication_failover_blacklistW przypadku zmiennej konfiguracyjnej replication_failover_whitelist zawiera ona listę adresów IP lub nazw hostów urządzeń podrzędnych, które powinny być używane jako potencjalni kandydaci na mastera. Jeśli ta zmienna jest ustawiona, tylko te hosty będą brane pod uwagę. W przypadku zmiennej replication_failover_blacklist zawiera ona listę hostów, które nigdy nie będą uznawane za głównego kandydata. Możesz go użyć do wylistowania urządzeń podrzędnych, które są używane do tworzenia kopii zapasowych lub zapytań analitycznych. Jeśli sprzęt różni się w zależności od urządzenia podrzędnego, możesz umieścić tutaj urządzenia podrzędne, które używają wolniejszego sprzętu.
replication_failover_whitelist ma pierwszeństwo, co oznacza, że replication_failover_blacklist jest ignorowana, jeśli ustawiono replication_failover_whitelist.
Gdy lista urządzeń podrzędnych, które można awansować na nadrzędne, jest gotowa, ClusterControl zaczyna porównywać ich stan w poszukiwaniu najbardziej aktualnego urządzenia podrzędnego. Tutaj różni się obsługa konfiguracji opartych na MariaDB i MySQL. W przypadku konfiguracji MariaDB ClusterControl wybiera urządzenie podrzędne, które ma najniższe opóźnienie replikacji ze wszystkich dostępnych urządzeń podrzędnych. W przypadku konfiguracji MySQL ClusterControl wybiera również takie urządzenie podrzędne, ale następnie sprawdza dodatkowe, brakujące transakcje, które mogły zostać wykonane na niektórych pozostałych urządzeniach podrzędnych. Jeśli taka transakcja zostanie znaleziona, ClusterControl podporządkowuje głównego kandydata od tego hosta w celu pobrania wszystkich brakujących transakcji. Możesz pominąć ten proces i po prostu użyć najbardziej zaawansowanego urządzenia podrzędnego, ustawiając zmienną replication_skip_apply_missing_txs w konfiguracji CMON:
np.
replication_skip_apply_missing_txs=1Sprawdź naszą dokumentację tutaj, aby uzyskać więcej informacji o zmiennych.
Zastrzeżenie polega na tym, że musisz to ustawić tylko wtedy, gdy wiesz, co robisz, ponieważ mogą wystąpić błędne transakcje. Może to spowodować przerwanie replikacji, a także niespójność danych w klastrze. Jeśli błędna transakcja miała miejsce w przeszłości, może nie być już dostępna w dziennikach binarnych. W takim przypadku replikacja zostanie przerwana, ponieważ jednostki podrzędne nie będą w stanie odzyskać brakujących danych. Dlatego ClusterControl domyślnie sprawdza, czy nie ma błędnych transakcji, zanim promuje kandydata na mistrza na mistrza. Jeśli taki problem zostanie wykryty, wyłącznik główny zostanie przerwany, a ClusterControl umożliwi użytkownikowi ręczne rozwiązanie problemu.
Jeśli chcesz mieć 100% pewność, że ClusterControl będzie promować nowego mastera, nawet jeśli zostaną wykryte pewne problemy, możesz to zrobić za pomocą zmiennej replication_stop_on_error. Zobacz poniżej:
np.
replication_stop_on_error=0Ustaw tę zmienną w pliku konfiguracyjnym cmon. Jak wspomniano wcześniej, może to prowadzić do problemów z replikacją, ponieważ urządzenia podrzędne mogą zacząć prosić o zdarzenie dziennika binarnego, które nie jest już dostępne. Aby poradzić sobie z takimi przypadkami, dodaliśmy eksperymentalne wsparcie dla odbudowy niewolników. Jeśli ustawisz zmienną
replication_auto_rebuild_slave=1w konfiguracji cmon i jeśli twój slave jest oznaczony jako wyłączony z następującym błędem w MySQL:
Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'ClusterControl podejmie próbę odbudowania urządzenia podrzędnego przy użyciu danych z urządzenia nadrzędnego. Takie ustawienie może nie zawsze być odpowiednie, ponieważ proces odbudowy spowoduje zwiększone obciążenie urządzenia głównego. Może się również zdarzyć, że Twój zbiór danych jest bardzo duży i regularna przebudowa nie jest opcją - dlatego to zachowanie jest domyślnie wyłączone.
Gdy już upewnimy się, że nie ma żadnych błędnych transakcji i możemy już iść, jest jeszcze jeden problem, z którym musimy sobie jakoś poradzić - może się zdarzyć, że wszyscy niewolnicy pozostaną w tyle za mistrzem.
Jak zapewne wiesz, replikacja w MySQL działa w dość prosty sposób. Master przechowuje zapisuje w dziennikach binarnych. Wątek we/wy urządzenia podrzędnego łączy się z urządzeniem nadrzędnym i pobiera wszystkie brakujące zdarzenia z dziennika binarnego. Następnie przechowuje je w postaci dzienników przekaźników. Wątek SQL analizuje je i stosuje zdarzenia. Slave lag to stan, w którym wątek SQL (lub wątki) nie radzi sobie z liczbą zdarzeń i nie jest w stanie ich zastosować, gdy tylko zostaną one wyciągnięte z mastera przez wątek we/wy. Taka sytuacja może się zdarzyć bez względu na rodzaj używanej replikacji. Nawet jeśli używasz replikacji częściowo zsynchronizowanej, może ona zagwarantować jedynie, że wszystkie zdarzenia z urządzenia nadrzędnego będą przechowywane na jednym z urządzeń podrzędnych w dzienniku przekaźnika. Nie mówi nic o zastosowaniu tych wydarzeń do niewolnika.
Problem polega na tym, że jeśli slave zostanie awansowany na mastera, logi przekaźników zostaną wymazane. Jeśli urządzenie podrzędne jest opóźnione i nie zastosowało wszystkich transakcji, utraci dane - zdarzenia, które nie zostały jeszcze zastosowane z dzienników przekaźników, zostaną utracone na zawsze.
Nie ma jednego uniwersalnego sposobu rozwiązania tej sytuacji. ClusterControl daje użytkownikom kontrolę nad tym, jak należy to zrobić, zachowując bezpieczne ustawienia domyślne. Odbywa się to w konfiguracji cmon przy użyciu następującego ustawienia:
replication_failover_wait_to_apply_timeout=-1Domyślnie przyjmuje wartość „-1”, co oznacza, że przełączenie awaryjne nie nastąpi natychmiast, jeśli główny kandydat jest opóźniony, więc jest ustawiony na oczekiwanie w nieskończoność, chyba że kandydat nadrobi zaległości. ClusterControl będzie czekał w nieskończoność, aż zastosuje wszystkie brakujące transakcje z jego dzienników przekazywania. Jest to bezpieczne, ale jeśli z jakiegoś powodu najbardziej aktualny serwer podrzędny ma duże opóźnienia, przełączenie awaryjne może zająć godziny. Z drugiej strony spektrum ustawia go na „0” – oznacza to, że przełączenie awaryjne następuje natychmiast, bez względu na to, czy główny kandydat jest opóźniony, czy nie. Możesz także przejść na środek i ustawić go na pewną wartość. To ustawi czas w sekundach, na przykład 30 sekund, więc ustaw zmienną na,
replication_failover_wait_to_apply_timeout=30Po ustawieniu na> 0, ClusterControl będzie czekał, aż główny kandydat zastosuje brakujące transakcje ze swoich dzienników przekaźnikowych, aż zostanie osiągnięta wartość (co w przykładzie wynosi 30 sekund). Przełączanie awaryjne następuje po określonym czasie lub gdy główny kandydat nadrobi zaległości w replikacji, w zależności od tego, co nastąpi wcześniej. Może to być dobry wybór, jeśli Twoja aplikacja ma określone wymagania dotyczące przestojów i musisz w krótkim czasie wybrać nowego mastera.
Więcej informacji o tym, jak ClusterControl współpracuje z automatycznym przełączaniem awaryjnym w PostgreSQL i MySQL, znajdziesz w naszych poprzednich blogach zatytułowanych „Failover for PostgreSQL Replication 101” i „Automatic failover of MySQL Replication – Nowość w ClusterControl 1.4”.
Wniosek
Automatyczne przełączanie awaryjne to cenna funkcja, szczególnie dla firm, które wymagają działania w trybie 24/7 przy minimalnych przestojach. Firma musi określić, jak dużą kontrolę oddaje proces automatyzacji podczas nieplanowanych przestojów. Rozwiązanie o wysokiej dostępności, takie jak ClusterControl, oferuje konfigurowalny poziom interakcji w przetwarzaniu awaryjnym. W przypadku niektórych organizacji automatyczne przełączanie awaryjne może nie być opcją, mimo że interakcja użytkownika podczas przełączania awaryjnego może pochłaniać czas i wpływać na RTO. Zakłada się, że jest to zbyt ryzykowne w przypadku, gdy automatyczne przełączanie awaryjne nie działa poprawnie lub, co gorsza, powoduje bałagan i częściowy brak danych (chociaż można by argumentować, że człowiek może również popełnić katastrofalne błędy prowadzące do podobnych konsekwencji). Ci, którzy wolą zachować ścisłą kontrolę nad swoją bazą danych, mogą pominąć automatyczne przełączanie awaryjne i zamiast tego użyć procesu ręcznego. Taki proces zajmuje więcej czasu, ale pozwala doświadczonemu administratorowi ocenić stan systemu i podjąć działania naprawcze w oparciu o to, co się stało.