Jest to druga część serii poświęconej rozwiązaniom wyzwania generatora szeregów liczbowych. W zeszłym miesiącu omówiłem rozwiązania, które generują wiersze w locie za pomocą konstruktora wartości tabeli z wierszami opartymi na stałych. W tych rozwiązaniach nie było żadnych operacji we/wy. W tym miesiącu skoncentruję się na rozwiązaniach, które odpytują fizyczną tabelę podstawową, którą wstępnie wypełniasz wierszami. Z tego powodu, poza raportowaniem profilu czasowego rozwiązań, tak jak zrobiłem to w zeszłym miesiącu, będę również raportował profil I/O nowych rozwiązań. Jeszcze raz dziękujemy Alanowi Bursteinowi, Joe Obbishowi, Adamowi Machanicowi, Christopherowi Fordowi, Jeffowi Modenowi, Charliemu, NoamGrowi, Kamilowi Kosno, Dave'owi Masonowi, Johnowi Nelsonowi #2 i Edowi Wagnerowi za podzielenie się swoimi pomysłami i komentarzami.
Najszybsze rozwiązanie do tej pory
Najpierw, dla szybkiego przypomnienia, przejrzyjmy najszybsze rozwiązanie z artykułu z zeszłego miesiąca, zaimplementowane jako wbudowany TVF o nazwie dbo.GetNumsAlanCharlieItzikBatch.
Wykonam testy w tempdb, włączając statystyki IO i TIME:
SET NOCOUNT ON; USE tempdb; SET STATISTICS IO, TIME ON;
Najszybsze rozwiązanie z ostatniego miesiąca stosuje sprzężenie z fikcyjną tabelą, która ma indeks magazynu kolumn, aby uzyskać przetwarzanie wsadowe. Oto kod do utworzenia fikcyjnej tabeli:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
A oto kod z definicją funkcji dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO W zeszłym miesiącu użyłem następującego kodu do przetestowania wydajności funkcji ze 100 mln wierszy, po włączeniu opcji Odrzuć wyniki po wykonaniu w SSMS, aby pominąć zwracanie wierszy wyjściowych:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Oto statystyki czasu, które otrzymałem dla tego wykonania:
Czas procesora =16031 ms, upływ czasu =17172 ms.Joe Obbish słusznie zauważył, że ten test może nie odzwierciedlać niektórych rzeczywistych scenariuszy, w tym sensie, że duża część czasu wykonywania jest spowodowana asynchronicznymi oczekiwaniami we/wy sieci (typ oczekiwania ASYNC_NETWORK_IO). Możesz zaobserwować najwyższe oczekiwania, przeglądając stronę właściwości węzła głównego rzeczywistego planu zapytania lub uruchamiając rozszerzoną sesję zdarzeń z informacjami o oczekiwaniu. Fakt, że włączysz opcję Odrzuć wyniki po wykonaniu w SSMS, nie uniemożliwia SQL Serverowi wysyłania wierszy wyników do SSMS; po prostu zapobiega ich drukowaniu przez SSMS. Pytanie brzmi, jakie jest prawdopodobieństwo, że zwrócisz klientowi duże zestawy wyników w rzeczywistych scenariuszach, nawet jeśli używasz tej funkcji do utworzenia dużej serii liczbowej? Być może częściej zapisujesz wyniki zapytania w tabeli lub używasz wyniku funkcji jako części zapytania, które ostatecznie generuje mały zestaw wyników. Musisz to rozgryźć. Możesz zapisać zestaw wyników do tabeli tymczasowej za pomocą instrukcji SELECT INTO lub możesz użyć sztuczki Alana Bursteina z instrukcją SELECT przypisania, która przypisuje wartość kolumny wyników do zmiennej.
Oto jak zmienić ostatni test, aby używał opcji przypisywania zmiennych:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Oto statystyki czasu, które otrzymałem podczas tego testu:
Czas procesora =8641 ms, upływ czasu =8645 ms.Tym razem informacja o oczekiwaniu nie zawiera żadnych asynchronicznych operacji wejścia/wyjścia sieci i można zauważyć znaczny spadek czasu wykonywania.
Przetestuj funkcję ponownie, tym razem dodając kolejność:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Otrzymałem następujące statystyki wydajności dla tego wykonania:
Czas procesora =9360 ms, upływ czasu =9551 ms.Przypomnij sobie, że nie ma potrzeby stosowania operatora sortowania w planie dla tego zapytania, ponieważ kolumna n jest oparta na wyrażeniu, które zachowuje kolejność w odniesieniu do kolumny rownum. To dzięki ciągłej sztuczce Charli do składania, którą omówiłem w zeszłym miesiącu. Plany dla obu zapytań — tego bez zamówienia i tego z zamówieniem są takie same, więc wydajność jest zwykle podobna.
Rysunek 1 podsumowuje wyniki, które otrzymałem dla rozwiązań z zeszłego miesiąca, tylko tym razem używając przypisania zmiennych w testach zamiast odrzucania wyników po wykonaniu.
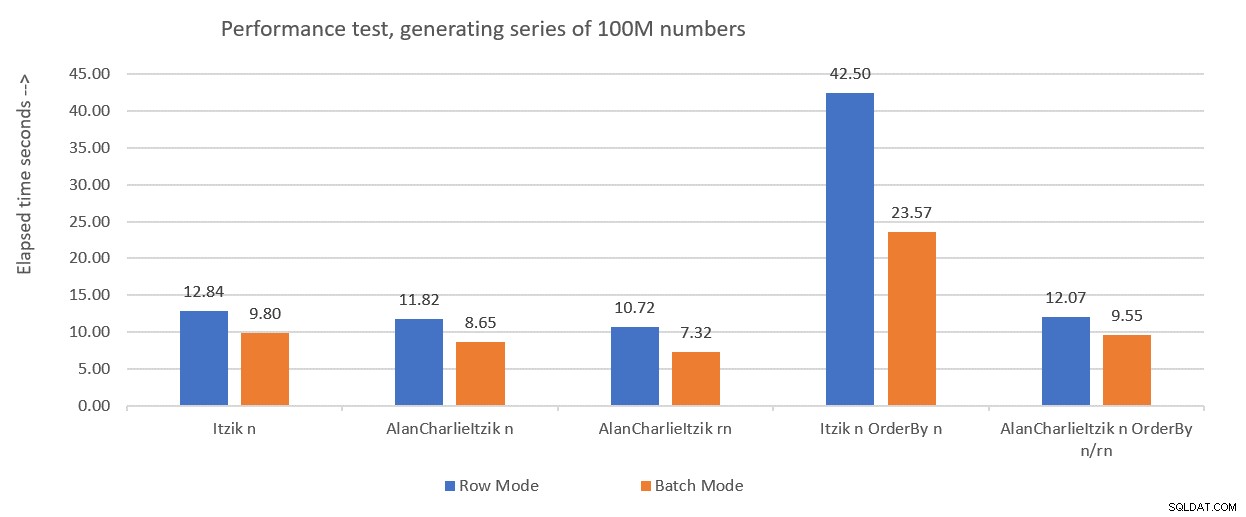 Rysunek 1:Podsumowanie dotychczasowych wyników z przypisaniem zmiennych
Rysunek 1:Podsumowanie dotychczasowych wyników z przypisaniem zmiennych
Wykorzystam technikę przypisywania zmiennych do testowania pozostałych rozwiązań, które przedstawię w tym artykule. Upewnij się, że dostosowujesz swoje testy, aby jak najlepiej odzwierciedlały Twoją rzeczywistą sytuację, używając przypisywania zmiennych, WYBIERZ DO, Odrzuć wyniki po wykonaniu lub jakiejkolwiek innej techniki.
Wskazówka dotycząca wymuszania planów szeregowych bez MAXDOP 1
Zanim przedstawię nowe rozwiązania, chciałem tylko zakryć małą wskazówkę. Przypomnij sobie, że niektóre rozwiązania najlepiej sprawdzają się w przypadku korzystania z planu szeregowego. Oczywistym sposobem na wymuszenie tego jest wskazówka dotycząca zapytania MAXDOP 1. I to jest właściwa droga, jeśli czasami chcesz włączyć równoległość, a czasami nie. Co jednak, jeśli zawsze chcesz wymusić plan szeregowy podczas korzystania z funkcji, chociaż jest to mniej prawdopodobny scenariusz?
Jest pewien trik, aby to osiągnąć. Użycie nieliniowego skalarnego UDF w zapytaniu jest inhibitorem równoległości. Jednym ze skalarnych inhibitorów inline UDF jest wywołanie funkcji wewnętrznej, która jest zależna od czasu, na przykład SYSDATETIME. Oto przykład nieliniowego skalarnego UDF:
CREATE OR ALTER FUNCTION dbo.MySYSDATETIME() RETURNS DATETIME2 AS BEGIN RETURN SYSDATETIME(); END; GO
Inną opcją jest zdefiniowanie UDF z pewną stałą jako wartością zwracaną i użycie opcji INLINE =OFF w jego nagłówku. Ale ta opcja jest dostępna dopiero od SQL Server 2019, w którym wprowadzono skalarne wstawianie UDF. Za pomocą powyższej sugerowanej funkcji możesz utworzyć ją tak, jak w przypadku starszych wersji SQL Server.
Następnie zmień definicję funkcji dbo.GetNumsAlanCharlieItzikBatch, aby wywołać fikcyjną funkcję dbo.MySYSDATETIME (zdefiniuj opartą na niej kolumnę, ale nie odwołuj się do kolumny w zwróconym zapytaniu), na przykład:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT
ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum,
dbo.MySYSDATETIME() AS dontinline
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Możesz teraz ponownie uruchomić test wydajności bez określania MAXDOP 1 i nadal uzyskać plan szeregowy:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n;
Należy jednak podkreślić, że każde zapytanie korzystające z tej funkcji otrzyma teraz plan szeregowy. Jeśli istnieje jakakolwiek szansa, że funkcja będzie używana w zapytaniach, które skorzystają z planów równoległych, lepiej nie używaj tej sztuczki, a gdy potrzebujesz planu szeregowego, po prostu użyj MAXDOP 1.
Rozwiązanie Joe Obbisha
Rozwiązanie Joe jest dość kreatywne. Oto jego własny opis rozwiązania:
„Zdecydowałem się na utworzenie klastrowego indeksu magazynu kolumn (CCI) z 134 217 728 wierszami kolejnych liczb całkowitych. Funkcja odwołuje się do tabeli do 32 razy, aby uzyskać wszystkie wiersze potrzebne do zestawu wyników. Wybrałem CCI, ponieważ dane będą się dobrze skompresować (mniej niż 3 bajty na wiersz), tryb wsadowy zostanie udostępniony „za darmo”, a wcześniejsze doświadczenia sugerują, że odczytywanie numerów sekwencyjnych z CCI będzie szybsze niż generowanie ich inną metodą. ”Jak wspomniano wcześniej, Joe zauważył również, że moje oryginalne testy wydajności były znacznie wypaczone ze względu na asynchroniczne oczekiwania we/wy sieci generowane przez przesyłanie wierszy do SSMS. Tak więc wszystkie testy, które tutaj przeprowadzę, będą wykorzystywały pomysł Alana z przypisaniem zmiennej. Pamiętaj, aby dostosować swoje testy w oparciu o to, co najbardziej odzwierciedla Twoją rzeczywistą sytuację.
Oto kod, którego Joe użył do utworzenia tabeli dbo.GetNumsObbishTable i wypełnienia jej 134 217 728 wierszami:
DROP TABLE IF EXISTS dbo.GetNumsObbishTable; CREATE TABLE dbo.GetNumsObbishTable (ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE); GO SET NOCOUNT ON; DECLARE @c INT = 0; WHILE @c < 128 BEGIN INSERT INTO dbo.GetNumsObbishTable SELECT TOP (1048576) @c * 1048576 - 1 + ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1); SET @c = @c + 1; END; GO
Ukończenie tego kodu na moim komputerze zajęło 1:04 minuty.
Możesz sprawdzić wykorzystanie miejsca w tej tabeli, uruchamiając następujący kod:
EXEC sys.sp_spaceused @objname = N'dbo.GetNumsObbishTable';
Zajęło mi około 350 MB miejsca. W porównaniu z innymi rozwiązaniami, które przedstawię w tym artykule, to zajmuje znacznie więcej miejsca.
W architekturze magazynu kolumn SQL Server grupa wierszy jest ograniczona do 2^20 =1 048 576 wierszy. Możesz sprawdzić, ile grup wierszy zostało utworzonych dla tej tabeli za pomocą następującego kodu:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.GetNumsObbishTable'); Mam 128 grup wierszy.
Oto kod z definicją funkcji dbo.GetNumsObbish:
CREATE OR ALTER FUNCTION dbo.GetNumsObbish(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE AS RETURN SELECT @low + ID AS n FROM dbo.GetNumsObbishTable WHERE ID <= @high - @low UNION ALL SELECT @low + ID + CAST(134217728 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(134217728 AS BIGINT) AND ID <= @high - @low - CAST(134217728 AS BIGINT) UNION ALL SELECT @low + ID + CAST(268435456 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(268435456 AS BIGINT) AND ID <= @high - @low - CAST(268435456 AS BIGINT) UNION ALL SELECT @low + ID + CAST(402653184 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(402653184 AS BIGINT) AND ID <= @high - @low - CAST(402653184 AS BIGINT) UNION ALL SELECT @low + ID + CAST(536870912 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(536870912 AS BIGINT) AND ID <= @high - @low - CAST(536870912 AS BIGINT) UNION ALL SELECT @low + ID + CAST(671088640 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(671088640 AS BIGINT) AND ID <= @high - @low - CAST(671088640 AS BIGINT) UNION ALL SELECT @low + ID + CAST(805306368 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(805306368 AS BIGINT) AND ID <= @high - @low - CAST(805306368 AS BIGINT) UNION ALL SELECT @low + ID + CAST(939524096 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(939524096 AS BIGINT) AND ID <= @high - @low - CAST(939524096 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1073741824 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1073741824 AS BIGINT) AND ID <= @high - @low - CAST(1073741824 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1207959552 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1207959552 AS BIGINT) AND ID <= @high - @low - CAST(1207959552 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1342177280 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1342177280 AS BIGINT) AND ID <= @high - @low - CAST(1342177280 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1476395008 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1476395008 AS BIGINT) AND ID <= @high - @low - CAST(1476395008 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1610612736 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1610612736 AS BIGINT) AND ID <= @high - @low - CAST(1610612736 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1744830464 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1744830464 AS BIGINT) AND ID <= @high - @low - CAST(1744830464 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1879048192 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1879048192 AS BIGINT) AND ID <= @high - @low - CAST(1879048192 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2013265920 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2013265920 AS BIGINT) AND ID <= @high - @low - CAST(2013265920 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2147483648 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2147483648 AS BIGINT) AND ID <= @high - @low - CAST(2147483648 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2281701376 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2281701376 AS BIGINT) AND ID <= @high - @low - CAST(2281701376 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2415919104 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2415919104 AS BIGINT) AND ID <= @high - @low - CAST(2415919104 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2550136832 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2550136832 AS BIGINT) AND ID <= @high - @low - CAST(2550136832 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2684354560 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2684354560 AS BIGINT) AND ID <= @high - @low - CAST(2684354560 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2818572288 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2818572288 AS BIGINT) AND ID <= @high - @low - CAST(2818572288 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2952790016 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2952790016 AS BIGINT) AND ID <= @high - @low - CAST(2952790016 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3087007744 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3087007744 AS BIGINT) AND ID <= @high - @low - CAST(3087007744 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3221225472 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3221225472 AS BIGINT) AND ID <= @high - @low - CAST(3221225472 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3355443200 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3355443200 AS BIGINT) AND ID <= @high - @low - CAST(3355443200 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3489660928 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3489660928 AS BIGINT) AND ID <= @high - @low - CAST(3489660928 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3623878656 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3623878656 AS BIGINT) AND ID <= @high - @low - CAST(3623878656 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3758096384 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3758096384 AS BIGINT) AND ID <= @high - @low - CAST(3758096384 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3892314112 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3892314112 AS BIGINT) AND ID <= @high - @low - CAST(3892314112 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4026531840 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4026531840 AS BIGINT) AND ID <= @high - @low - CAST(4026531840 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4160749568 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4160749568 AS BIGINT) AND ID <= @high - @low - CAST(4160749568 AS BIGINT); GO
32 indywidualne zapytania generują rozłączne podzakresy 134 217 728 liczb całkowitych, które po ujednoliceniu dają pełny nieprzerwany zakres od 1 do 4 294 967 296. To, co jest naprawdę mądre w tym rozwiązaniu, to filtr WHERE, który określa predyktory, z których korzystają poszczególne zapytania. Przypomnijmy, że gdy SQL Server przetwarza wbudowany TVF, najpierw stosuje osadzanie parametrów, zastępując parametry stałymi wejściowymi. SQL Server może następnie zoptymalizować zapytania, które tworzą podzakresy, które nie przecinają się z zakresem wejściowym. Na przykład, gdy żądasz zakresu wejściowego od 1 do 100 000 000, istotne jest tylko pierwsze zapytanie, a cała reszta zostaje zoptymalizowana. W takim przypadku plan będzie zawierał odniesienie tylko do jednego wystąpienia tabeli. To całkiem genialne!
Przetestujmy wydajność funkcji w zakresie od 1 do 100 000 000:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000);
Plan dla tego zapytania pokazano na rysunku 2.
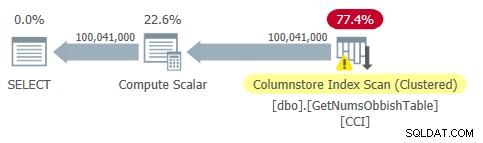 Rysunek 2:Plan dla dbo.GetNumsObbish, 100 mln wierszy, nieuporządkowane
Rysunek 2:Plan dla dbo.GetNumsObbish, 100 mln wierszy, nieuporządkowane
Zauważ, że rzeczywiście w tym planie potrzebne jest tylko jedno odniesienie do CCI tabeli.
Otrzymałem następujące statystyki czasu dla tego wykonania:
To imponujące i zdecydowanie szybsze niż cokolwiek innego, co testowałem.
Oto statystyki I/O, które otrzymałem dla tego wykonania:
Tabela „GetNumsObbishTable”. Liczba skanów 1, odczyty logiczne 0, odczyty fizyczne 0, odczyty serwera strony 0, odczyty z wyprzedzeniem 0, odczyty z wyprzedzeniem serwera strony 0, logiczne odczyty LOB 32928 , fizyczne odczyty lobu 0, serwer strony lob odczytuje 0, odczyt z wyprzedzeniem odczytuje 0, odczyt z wyprzedzeniem serwera strony lob wynosi 0.Tabela „GetNumsObbishTable”. Segment odczytuje 96 , pominięto segment 32.
Profil we/wy tego rozwiązania jest jedną z jego wad w porównaniu z innymi, powodując ponad 30 000 odczytów logicznych lob dla tego wykonania.
Aby zobaczyć, że po przekroczeniu wielu podzakresów 134 217 728 liczb całkowitych plan będzie zawierał wiele odwołań do tabeli, zapytaj funkcję z zakresem od 1 do 400 000 000, na przykład:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 400000000);
Plan tego wykonania pokazano na rysunku 3.
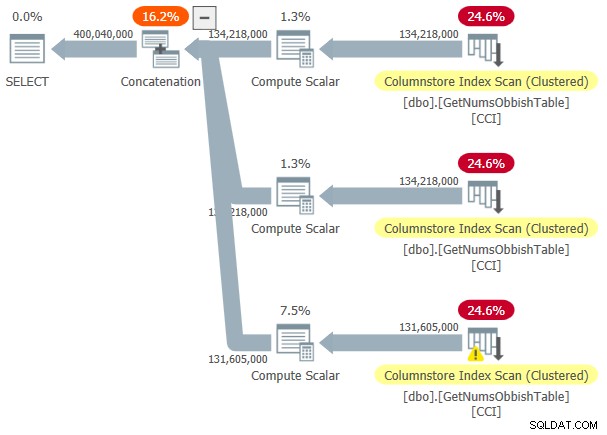 Rysunek 3:Plan dla dbo.GetNumsObbish, 400 mln wierszy, nieuporządkowane
Rysunek 3:Plan dla dbo.GetNumsObbish, 400 mln wierszy, nieuporządkowane
Żądany zakres przekroczył trzy podzakresy 134 217 728 liczb całkowitych, stąd plan pokazuje trzy odniesienia do CCI tabeli.
Oto statystyki czasu, które otrzymałem dla tego wykonania:
Czas procesora =20610 ms, upływ czasu =20628 ms.A oto statystyki I/O:
Tabela „GetNumsObbishTable”. Liczba skanów 3, odczyty logiczne 0, odczyty fizyczne 0, odczyty serwera strony 0, odczyty z wyprzedzeniem 0, odczyty serwera strony odczyty z wyprzedzeniem 0, logiczne odczyty lob 131026 , fizyczne odczyty lobu 0, serwer strony lob odczytuje 0, odczyt z wyprzedzeniem odczytuje 0, odczyt z wyprzedzeniem serwera strony lob wynosi 0.Tabela „GetNumsObbishTable”. Segment odczytuje 382 , segment pominięty 2.
Tym razem wykonanie zapytania spowodowało ponad 130 000 odczytów logicznych lob.
Jeśli możesz pogodzić się z kosztami I/O i nie musisz przetwarzać serii numerów w uporządkowany sposób, jest to świetne rozwiązanie. Jeśli jednak musisz przetworzyć serię w kolejności, to rozwiązanie spowoduje, że w planie pojawi się operator sortowania. Oto test żądający zamówionego wyniku:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000) ORDER BY n;
Plan tego wykonania pokazano na rysunku 4.
 Rysunek 4:Plan dla dbo.GetNumsObbish, 100 mln wierszy, uporządkowane
Rysunek 4:Plan dla dbo.GetNumsObbish, 100 mln wierszy, uporządkowane
Oto statystyki czasu, które otrzymałem dla tego wykonania:
Czas procesora =44516 ms, upływ czasu =34836 ms.Jak widać, wydajność znacznie spadła wraz ze wzrostem czasu działania o rząd wielkości z powodu jawnego sortowania.
Oto statystyki I/O, które otrzymałem dla tego wykonania:
Tabela „GetNumsObbishTable”. Liczba skanów 4, odczyty logiczne 0, odczyty fizyczne 0, odczyty serwera strony 0, odczyty z wyprzedzeniem 0, odczyty serwera strony odczyty z wyprzedzeniem 0, logiczne odczyty LOB 32928 , fizyczne odczyty lobu 0, serwer strony lob odczytuje 0, odczyt z wyprzedzeniem odczytuje 0, odczyt z wyprzedzeniem serwera strony lob wynosi 0.Tabela „GetNumsObbishTable”. Segment odczytuje 96 , segment pominięty 32.
Stół „Stół roboczy”. Liczba skanów 0, odczyty logiczne 0, odczyty fizyczne 0, odczyty serwera strony 0, odczyty z wyprzedzeniem 0, odczyty z wyprzedzeniem serwera stron 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty serwera strony lobu 0, odczyty naprzód odczytuje 0, serwer stron lob odczyt z wyprzedzeniem odczytuje 0.
Zauważ, że Worktable pojawił się na wyjściu STATISTICS IO. Dzieje się tak, ponieważ sort może potencjalnie rozlać się do tempdb, w którym to przypadku użyje stołu roboczego. Ta egzekucja się nie rozlała, dlatego wszystkie liczby w tym wpisie są zerami.
Rozwiązanie autorstwa Johna Nelsona #2, Dave, Joe, Alan, Charlie, Itzik
John Nelson #2 opublikował rozwiązanie, które jest po prostu piękne w swojej prostocie. Dodatkowo zawiera pomysły i sugestie z innych rozwiązań Dave'a, Joe, Alana, Charliego i mnie.
Podobnie jak w przypadku rozwiązania Joe, John zdecydował się użyć CCI, aby uzyskać wysoki poziom kompresji i „darmowe” przetwarzanie wsadowe. Tylko John zdecydował się wypełnić tabelę 4B wierszami jakimś fikcyjnym znacznikiem NULL w kolumnie bitowej, a funkcja ROW_NUMBER wygeneruje liczby. Ponieważ przechowywane wartości są takie same, przy kompresji powtarzających się wartości potrzeba znacznie mniej miejsca, co skutkuje znacznie mniejszą liczbą operacji we/wy w porównaniu z rozwiązaniem Joe. Kompresja magazynu kolumn bardzo dobrze radzi sobie z powtarzającymi się wartościami, ponieważ może reprezentować każdą taką kolejną sekcję w segmencie kolumn grupy wierszy tylko raz wraz z liczbą kolejnych powtarzających się wystąpień. Ponieważ wszystkie wiersze mają tę samą wartość (znacznik NULL), teoretycznie wystarczy jedno wystąpienie na grupę wierszy. W przypadku wierszy 4B powinieneś otrzymać 4096 grup wierszy. Każdy powinien mieć pojedynczy segment kolumn, przy bardzo małym zapotrzebowaniu na miejsce.
Oto kod do tworzenia i wypełniania tabeli, zaimplementowany jako CCI z kompresją archiwalną:
DROP TABLE IF EXISTS dbo.NullBits4B;
CREATE TABLE dbo.NullBits4B
(
b BIT NULL,
INDEX cc_NullBits4B CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B),
nulls(b) AS (SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B)
INSERT INTO dbo.NullBits4B WITH (TABLOCK) (b)
SELECT b FROM nulls;
GO Główną wadą tego rozwiązania jest czas potrzebny na wypełnienie tej tabeli. Ukończenie tego kodu na moim komputerze zajęło 12:32 minut, gdy zezwalałem na równoległość, i 15:17 minut, gdy wymuszano plan szeregowy.
Pamiętaj, że możesz popracować nad optymalizacją ładowania danych. Na przykład John przetestował rozwiązanie, które ładowało wiersze przy użyciu 32 jednoczesnych połączeń z OSTRESS.EXE, z których każda uruchamia 128 rund wstawiania 2 ^ 20 wierszy (maksymalny rozmiar grupy wierszy). To rozwiązanie skróciło czas ładowania Johna do jednej trzeciej. Oto kod, którego użył Jan:
ostress -S(local)\YourSQLInstance -E -dtempdb -n32 -r128 -Q"With L0 AS (SELECT CAST(NULL AS BIT) AS b FROM (VALUES(1),(1),(1),(1) ,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1) AS D(b)), L1 AS (WYBIERZ A.b Z L0 JAKO POŁĄCZENIE KRZYŻOWE L0 JAKO B), L2 AS (WYBIERZ A.b Z L1 JAKO POŁĄCZENIE KRZYŻOWE L1 JAKO B), nulls(b) AS (WYBIERZ A.b Z L2 JAKO A) CROSS JOIN L2 AS B) INSERT INTO dbo.NullBits4B(b) SELECT TOP (1048576) b FROM nulls OPTION(MAXDOP 1);"Mimo to czas ładowania jest w minutach. Dobrą wiadomością jest to, że dane ładowanie danych należy wykonać tylko raz.
Świetną wiadomością jest niewielka ilość miejsca potrzebnego na stół. Użyj następującego kodu, aby sprawdzić wykorzystanie miejsca:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits4B';
Mam 1,64 MB. To niesamowite, biorąc pod uwagę fakt, że tabela ma 4B wierszy!
Użyj poniższego kodu, aby sprawdzić, ile grup wierszy zostało utworzonych:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits4B'); Zgodnie z oczekiwaniami liczba grup wierszy wynosi 4096.
Definicja funkcji dbo.GetNumsJohn2DaveObbishAlanCharlieItzik staje się wtedy całkiem prosta:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits4B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO
Jak widać, proste zapytanie względem tabeli używa funkcji ROW_NUMBER do obliczenia podstawowych numerów wierszy (kolumna rownum), a następnie zapytanie zewnętrzne używa tych samych wyrażeń, co w dbo.GetNumsAlanCharlieItzikBatch do obliczenia rn, op i n. Również tutaj, zarówno rn, jak i n, zachowują kolejność względem rownum.
Przetestujmy wydajność funkcji:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000);
Mam plan pokazany na Rysunku 5 dla tego wykonania.
 Rysunek 5:Plan dla dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Rysunek 5:Plan dla dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Oto statystyki czasu, które otrzymałem podczas tego testu:
Czas procesora =7593 ms, upływ czasu =7590 ms.
Jak widać, czas wykonania nie jest tak szybki jak w przypadku rozwiązania Joe, ale nadal jest szybszy niż wszystkie inne rozwiązania, które testowałem.
Oto statystyki I/O, które otrzymałem w tym teście:
Tabela „NullBits4B”. Segment odczytuje 96 , segment pominięty 0
Zwróć uwagę, że wymagania we/wy są znacznie niższe niż w przypadku rozwiązania Joe.
Kolejną zaletą tego rozwiązania jest to, że gdy musisz przetworzyć zamówione serie numerów, nie płacisz żadnych dodatkowych opłat. Dzieje się tak, ponieważ nie spowoduje to jawnej operacji sortowania w planie, niezależnie od tego, czy uporządkujesz wynik według rn, czy n.
Oto test, który to pokazuje:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000) ORDER BY n;
Otrzymujesz taki sam plan, jak pokazano wcześniej na rysunku 5.
Oto statystyki czasu, które otrzymałem podczas tego testu;
Czas procesora =7578 ms, upływ czasu =7582 ms.A oto statystyki I/O:
Tabela „NullBits4B”. Liczba skanów 1, odczyty logiczne 0, odczyty fizyczne 0, odczyty serwera strony 0, odczyty z wyprzedzeniem 0, odczyty serwera strony odczyty z wyprzedzeniem 0, logiczne odczyty lob 194 , fizyczne odczyty lobu 0, serwer strony lob odczytuje 0, odczyt z wyprzedzeniem odczytuje 0, odczyt z wyprzedzeniem serwera strony lob wynosi 0.Tabela „NullBits4B”. Segment odczytuje 96 , segment pominięty 0.
Zasadniczo są takie same jak w teście bez zamówienia.
Rozwiązanie 2 autorstwa Johna Nelsona #2, Dave Masona, Joe Obbisha, Alana, Charliego, Itzika
Rozwiązanie Johna jest szybkie i proste. To fantastycznie. Jedynym minusem jest czas ładowania. Czasami nie będzie to problemem, ponieważ ładowanie odbywa się tylko raz. Ale jeśli jest to problem, możesz wypełnić tabelę 102 400 wierszami zamiast 4B i użyć połączenia krzyżowego między dwoma wystąpieniami tabeli i filtru TOP, aby wygenerować żądaną maksymalną liczbę 4B wierszy. Zauważ, że aby uzyskać 4B wierszy, wystarczyłoby wypełnić tabelę 65 536 wierszami, a następnie zastosować sprzężenie krzyżowe; Jednak w celu natychmiastowego skompresowania danych — w przeciwieństwie do ładowania do magazynu różnicowego opartego na magazynie wierszy — należy załadować tabelę z co najmniej 102 400 wierszami.
Oto kod do tworzenia i wypełniania tabeli:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO Czas ładowania jest znikomy — 43 ms na moim komputerze.
Sprawdź rozmiar tabeli na dysku:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits102400';
Potrzebuję 56 KB miejsca na dane.
Sprawdź liczbę grup wierszy, ich stan (skompresowany lub otwarty) i ich rozmiar:
SELECT state_description, total_rows, size_in_bytes
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits102400'); Otrzymałem następujący wynik:
state_description total_rows size_in_bytes ------------------ ----------- -------------- COMPRESSED 102400 293
Tutaj potrzebna jest tylko jedna grupa wierszy; jest skompresowany, a jego rozmiar to pomijalne 293 bajty.
Jeśli wypełnisz tabelę o jeden wiersz mniej (102 399), uzyskasz nieskompresowany magazyn różnicowy oparty na magazynie wierszy. W takim przypadku sp_spaceused zgłasza rozmiar danych na dysku przekraczający 1 MB, a sys.column_store_row_groups zgłasza następujące informacje:
state_description total_rows size_in_bytes ------------------ ----------- -------------- OPEN 102399 1499136
Upewnij się więc, że wypełniłeś tabelę 102 400 wierszami!
Oto definicja funkcji dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Let’s test the function's performance:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
I got the plan shown in Figure 6 for this execution.
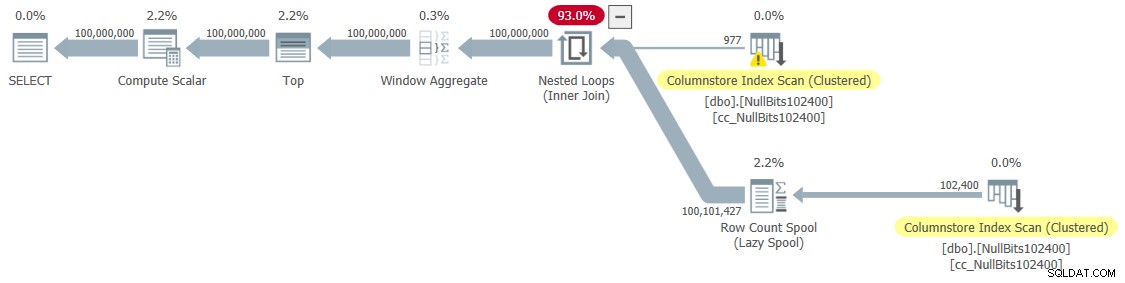 Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
I got the following time statistics for this test:
CPU time =9188 ms, elapsed time =9188 ms.As you can see, the execution time increased by ~ 26%. It’s still pretty fast, but not as fast as the single-table solution. So that’s a tradeoff that you’ll need to evaluate.
I got the following I/O stats for this test:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
The I/O profile of this solution is excellent.
Let’s add order to the test:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
You get the same plan as shown earlier in Figure 6 since there’s no explicit sorting needed.
I got the following time statistics for this test:
CPU time =9140 ms, elapsed time =9237 ms.And the following I/O stats:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
Again, the numbers are very similar to the test without the ordering.
Performance summary
Figure 7 has a summary of the time statistics for the different solutions.
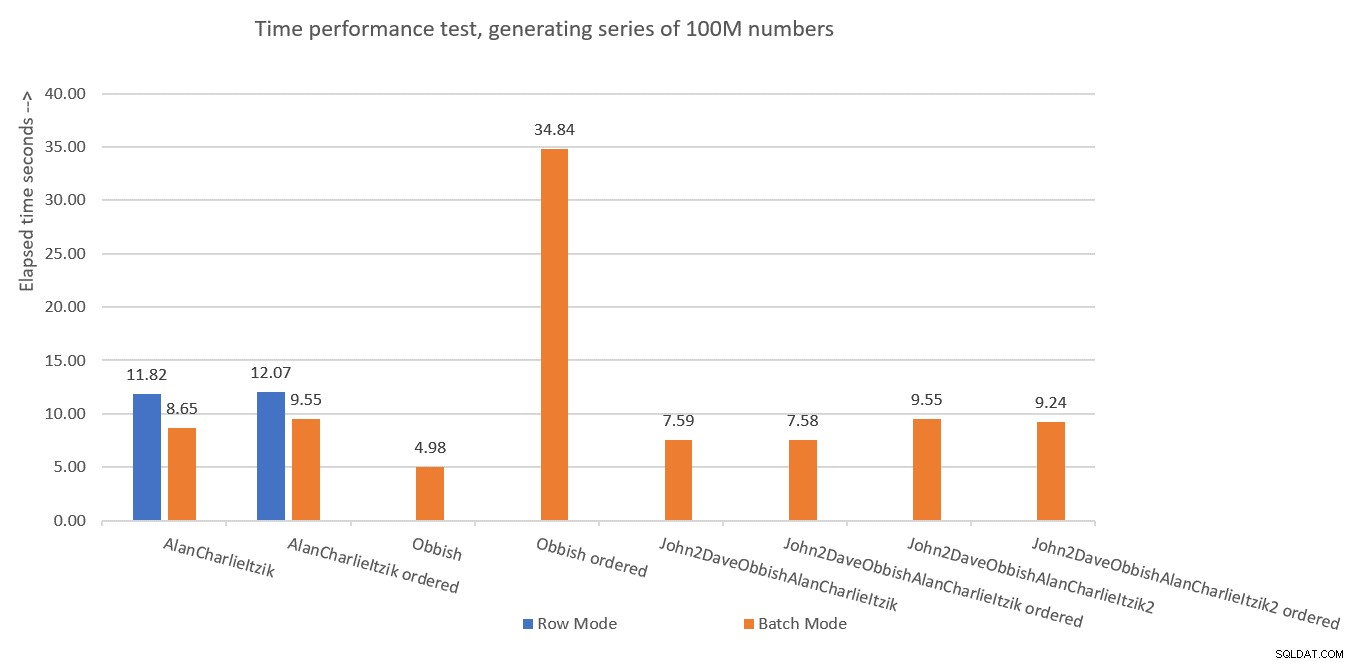 Figure 7:Time performance summary of solutions
Figure 7:Time performance summary of solutions
Figure 8 has a summary of the I/O statistics.
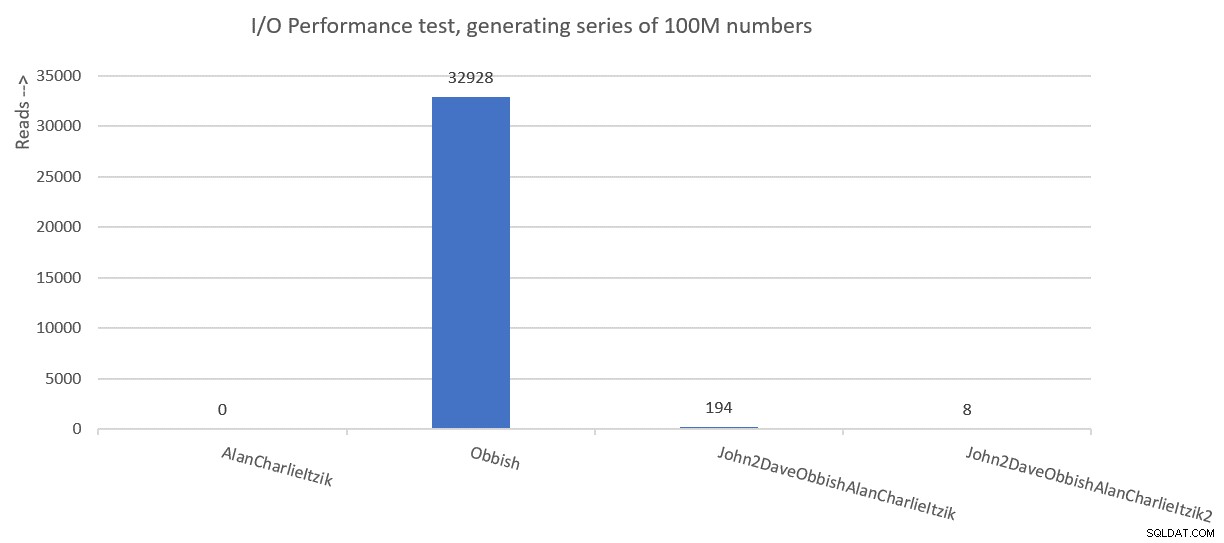 Figure 8:I/O performance summary of solutions
Figure 8:I/O performance summary of solutions
Thanks to all of you who posted ideas and suggestions in effort to create a fast number series generator. It’s a great learning experience!
We’re not done yet. Next month I’ll continue exploring additional solutions.