Wysoka dostępność to wysoki procent czasu, w którym system działa i reaguje zgodnie z potrzebami biznesowymi. W przypadku produkcyjnych systemów baz danych zazwyczaj najwyższym priorytetem jest utrzymanie go blisko 100%. Budujemy klastry baz danych, aby wyeliminować wszystkie pojedyncze punkty awarii. Jeśli instancja stanie się niedostępna, inny węzeł powinien być w stanie przejąć obciążenie i kontynuować stamtąd. W idealnym świecie klaster baz danych rozwiązałby wszystkie nasze problemy z dostępnością systemu. Niestety, choć na papierze wszystko może wyglądać dobrze, rzeczywistość jest często inna. Więc gdzie może się nie udać?
Systemy transakcyjnych baz danych są wyposażone w zaawansowane silniki pamięci masowej. Utrzymanie spójności danych w wielu węzłach znacznie utrudnia to zadanie. Klastrowanie wprowadza szereg nowych zmiennych, które w dużym stopniu zależą od sieci i infrastruktury bazowej. Nierzadko zdarza się, że samodzielna instancja bazy danych, która działała dobrze na pojedynczym węźle, nagle działa słabo w środowisku klastrowym.
Wśród wielu czynników, które mogą wpływać na dostępność klastra, kluczową rolę odgrywają kwestie opóźnień. Jednak jakie jest opóźnienie? Czy dotyczy to tylko sieci?
Termin „opóźnienie” w rzeczywistości odnosi się do kilku rodzajów opóźnień występujących w przetwarzaniu danych. Tyle czasu zajmuje przejście informacji ze sceny na drugą.
W tym poście na blogu przyjrzymy się dwóm głównym rozwiązaniom wysokiej dostępności dla MySQL i MariaDB oraz sposobom, w jaki na każde z nich mogą wpływać problemy z opóźnieniami.
Na końcu artykułu przyjrzymy się nowoczesnym systemom równoważenia obciążenia i omówimy, w jaki sposób mogą one pomóc rozwiązać niektóre rodzaje problemów z opóźnieniami.
W poprzednim artykule mój kolega Krzysztof Książek pisał o „Radzeniu sobie z zawodnymi sieciami podczas tworzenia rozwiązania HA dla MySQL lub MariaDB”. Znajdziesz wskazówki, które pomogą Ci zaprojektować gotową do produkcji architekturę HA i uniknąć niektórych problemów opisanych tutaj.
Replikacja typu master-slave dla wysokiej dostępności.
Replikacja typu master-slave MySQL jest prawdopodobnie najpopularniejszym typem klastra baz danych na świecie. Jedną z głównych rzeczy, które chcesz monitorować podczas uruchamiania klastra replikacji typu master-slave, jest opóźnienie urządzenia podrzędnego. W zależności od wymagań aplikacji i sposobu wykorzystania bazy danych opóźnienie replikacji (opóźnienie urządzenia podrzędnego) może określać, czy dane można odczytać z węzła podrzędnego, czy nie. Dane zatwierdzone w urządzeniu nadrzędnym, ale jeszcze niedostępne w asynchronicznym urządzeniu podrzędnym oznaczają, że urządzenie podrzędne ma starszy stan. Jeśli nie można czytać z urządzenia podrzędnego, trzeba będzie przejść do urządzenia nadrzędnego, co może wpłynąć na wydajność aplikacji. W najgorszym przypadku Twój system nie będzie w stanie obsłużyć całego obciążenia na urządzeniu głównym.
Slave lag i nieaktualne dane
Aby sprawdzić stan replikacji master-slave, należy zacząć od poniższego polecenia:
SHOW SLAVE STATUS\G
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.3.100
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000021
Read_Master_Log_Pos: 5101
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 809
Relay_Master_Log_File: binlog.000021
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 5101
Relay_Log_Space: 1101
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3-1179
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.01 sec)Korzystając z powyższych informacji, możesz określić, jak dobre jest ogólne opóźnienie replikacji. Im niższa wartość widoczna w „Seconds_Behind_Master”, tym lepsza prędkość przesyłania danych do replikacji.
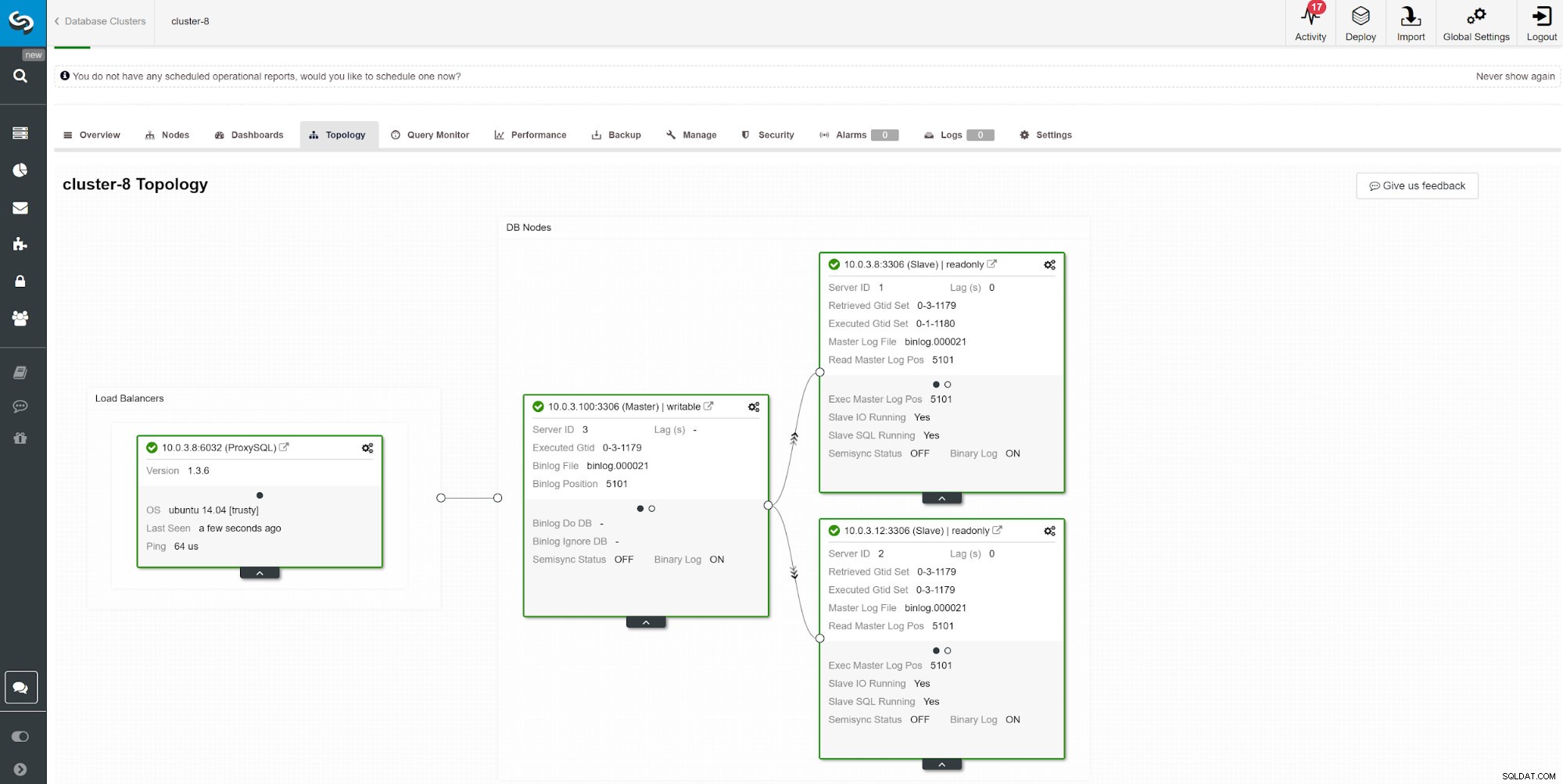 Innym sposobem monitorowania lagów podrzędnych jest użycie monitorowania replikacji ClusterControl. Na tym zrzucie ekranu możemy zobaczyć stan replikacji asymetrycznego klastra Master-Slave (2x) z ProxySQL.
Innym sposobem monitorowania lagów podrzędnych jest użycie monitorowania replikacji ClusterControl. Na tym zrzucie ekranu możemy zobaczyć stan replikacji asymetrycznego klastra Master-Slave (2x) z ProxySQL. Istnieje wiele rzeczy, które mogą wpływać na czas replikacji. Najbardziej oczywistą jest przepustowość sieci i ilość danych, które możesz przesłać. MySQL jest dostarczany z wieloma opcjami konfiguracyjnymi, aby zoptymalizować proces replikacji. Podstawowe parametry związane z replikacją to:
- Zastosuj równolegle
- Algorytm zegara logicznego
- Kompresja
- Wybiórcza replikacja master-slave
- Tryb replikacji
Zastosuj równolegle
Często zdarza się, że dostrajanie replikacji rozpoczyna się od włączenia procesu równoległego. Powodem tego jest domyślnie MySQL stosuje sekwencyjny dziennik binarny, a typowy serwer bazy danych ma kilka procesorów do użycia.
Aby obejść zastosowanie dziennika sekwencyjnego, zarówno MariaDB, jak i MySQL oferują replikację równoległą. Implementacja może się różnić w zależności od dostawcy i wersji. Np. MySQL 5.6 oferuje replikację równoległą, o ile schemat oddziela zapytania, podczas gdy MariaDB (od wersji 10.0) i MySQL 5.7 mogą obsługiwać replikację równoległą między schematami. Różni dostawcy i wersje mają swoje ograniczenia i funkcje, więc zawsze sprawdzaj dokumentację.
Wykonywanie zapytań za pośrednictwem równoległych wątków podrzędnych może przyspieszyć strumień replikacji, jeśli intensywnie piszesz. Jeśli jednak nie, najlepiej będzie trzymać się tradycyjnej replikacji jednowątkowej. Aby włączyć przetwarzanie równoległe, zmień slave_parallel_workers na liczbę wątków procesora, które chcesz zaangażować w proces. Zaleca się, aby wartość była niższa od liczby dostępnych wątków procesora.
Replikacja równoległa działa najlepiej z zatwierdzeniami grupowymi. Aby sprawdzić, czy zachodzą zmiany grupowe, uruchom następujące zapytanie.
show global status like 'binlog_%commits';Im większy stosunek między tymi dwiema wartościami, tym lepiej.
Zegar logiczny
Slave_parallel_type=LOGICAL_CLOCK jest implementacją algorytmu zegara Lamporta. Podczas korzystania z wielowątkowego urządzenia podrzędnego zmienna ta określa metodę używaną do decydowania, które transakcje mogą być wykonywane równolegle na urządzeniu podrzędnym. Zmienna nie ma wpływu na urządzenia podrzędne, dla których wielowątkowość nie jest włączona, więc upewnij się, że slave_parallel_workers ma wartość wyższą niż 0.
Użytkownicy MariaDB powinni również sprawdzić tryb optymistyczny wprowadzony w wersji 10.1.3, ponieważ również może dać lepsze wyniki.
ID GTID
MariaDB ma własną implementację GTID. Sekwencja MariaDB składa się z domeny, serwera i transakcji. Domeny umożliwiają replikację z wielu źródeł z odrębnym identyfikatorem. Różne identyfikatory domeny mogą być używane do replikowania części danych poza kolejnością (równolegle). Dopóki jest to w porządku dla Twojej aplikacji, może to zmniejszyć opóźnienie replikacji.
Podobna technika ma zastosowanie do MySQL 5.7, który może również wykorzystywać wieloźródłowy master i niezależne kanały replikacji.
Kompresja
Moc procesora staje się z czasem coraz mniej kosztowna, więc użycie jej do kompresji binlogów może być dobrą opcją w wielu środowiskach baz danych. Parametr slave_compressed_protocol mówi MySQL, aby używał kompresji, jeśli zarówno master, jak i slave ją obsługują. Domyślnie ten parametr jest wyłączony.
Począwszy od MariaDB 10.2.3, wybrane zdarzenia w dzienniku binarnym można opcjonalnie skompresować, aby zapisać transfery sieciowe.
Formaty replikacji
MySQL oferuje kilka trybów replikacji. Wybór odpowiedniego formatu replikacji pomaga zminimalizować czas przesyłania danych między węzłami klastra.
Replikacja multimaster zapewniająca wysoką dostępność
Niektóre aplikacje nie mogą sobie pozwolić na działanie na nieaktualnych danych.
W takich przypadkach można wymusić spójność w węzłach za pomocą replikacji synchronicznej. Utrzymanie synchronizacji danych wymaga dodatkowej wtyczki, a dla niektórych najlepszym rozwiązaniem na rynku jest Galera Cluster.
Klaster Galera jest wyposażony w interfejs API wsrep, który odpowiada za przesyłanie transakcji do wszystkich węzłów i wykonywanie ich zgodnie z porządkiem klastra. Spowoduje to zablokowanie wykonywania kolejnych zapytań, dopóki węzeł nie zastosuje wszystkich zestawów zapisu ze swojej kolejki aplikacji. Chociaż jest to dobre rozwiązanie dla spójności, możesz napotkać pewne ograniczenia architektoniczne. Typowe problemy z opóźnieniami mogą być związane z:
- Najwolniejszy węzeł w klastrze
- Skalowanie w poziomie i operacje zapisu
- Geolokowane klastry
- Wysoki ping
- Rozmiar transakcji
Najwolniejszy węzeł w klastrze
Zgodnie z projektem wydajność zapisu klastra nie może być wyższa niż wydajność najwolniejszego węzła w klastrze. Rozpocznij przegląd klastra, sprawdzając zasoby maszyny i zweryfikuj pliki konfiguracyjne, aby upewnić się, że wszystkie działają z tymi samymi ustawieniami wydajności.
Równoległość
Wątki równoległe nie gwarantują lepszej wydajności, ale mogą przyspieszyć synchronizację nowych węzłów z klastrem. Status wsrep_cert_deps_distance mówi nam o możliwym stopniu zrównoleglania. Jest to wartość średniej odległości między najwyższą i najniższą wartością seqno, którą można ewentualnie zastosować równolegle. Możesz użyć zmiennej statusu wsrep_cert_deps_distance, aby określić maksymalną możliwą liczbę wątków podrzędnych.
Skalowanie w poziomie
Dodając więcej węzłów w klastrze, mamy mniej punktów, które mogą się nie powieść; jednak informacje muszą przechodzić przez wiele wystąpień, dopóki nie zostaną zatwierdzone, co zwielokrotnia czasy odpowiedzi. Jeśli potrzebujesz skalowalnych zapisów, rozważ architekturę opartą na shardingu. Dobrym rozwiązaniem może być silnik pamięci masowej Spider.
W niektórych przypadkach, aby zmniejszyć ilość informacji udostępnianych przez węzły klastra, można rozważyć posiadanie jednego programu zapisującego na raz. Jest to stosunkowo łatwe do wdrożenia przy użyciu load balancera. Gdy zrobisz to ręcznie, upewnij się, że masz procedurę zmiany wartości DNS, gdy węzeł zapisujący przestanie działać.
Geolokowane klastry
Chociaż Galera Cluster jest synchroniczny, możliwe jest wdrożenie Galera Cluster w różnych centrach danych. Replikacja synchroniczna, taka jak MySQL Cluster (NDB), implementuje zatwierdzanie dwufazowe, w którym komunikaty są wysyłane do wszystkich węzłów w klastrze w fazie przygotowania, a kolejny zestaw komunikatów jest wysyłany w fazie zatwierdzania. Takie podejście zwykle nie jest odpowiednie dla węzłów odległych geograficznie, ze względu na opóźnienia w wysyłaniu wiadomości między węzłami.
Wysoki ping
Galera Cluster z ustawieniami domyślnymi nie radzi sobie dobrze z wysokimi opóźnieniami sieci. Jeśli masz sieć z węzłem, który pokazuje wysoki czas pingowania, rozważ zmianę parametrów evs.send_window i evs.user_send_window. Zmienne te definiują jednocześnie maksymalną liczbę pakietów danych replikowanych. W przypadku konfiguracji WAN zmienną można ustawić na znacznie wyższą wartość niż domyślna wartość 2. Często ustawia się ją na 512. Te parametry są częścią wsrep_provider_options.
--wsrep_provider_options="evs.send_window=512;evs.user_send_window=512"Rozmiar transakcji
Jedną z rzeczy, które należy wziąć pod uwagę podczas uruchamiania Galera Cluster, jest wielkość transakcji. Znalezienie równowagi między wielkością transakcji, wydajnością i procesem certyfikacji Galera to coś, co musisz oszacować w swojej aplikacji. Więcej informacji na ten temat można znaleźć w artykule Jak poprawić wydajność klastra Galera dla MySQL lub MariaDB autorstwa Ashraf Sharif.
Odczyty dotyczące spójności przyczynowej modułu równoważenia obciążenia
Nawet przy zminimalizowanym ryzyku problemów z opóźnieniami danych, standardowa replikacja asynchroniczna MySQL nie może zagwarantować spójności. Nadal jest możliwe, że dane nie są jeszcze replikowane do serwera podrzędnego, gdy aplikacja odczytuje je stamtąd. Replikacja synchroniczna może rozwiązać ten problem, ale ma ograniczenia architektury i może nie odpowiadać wymaganiom aplikacji (np. intensywne zapisy zbiorcze). Jak więc to przezwyciężyć?
Pierwszym krokiem w celu uniknięcia nieaktualnych odczytów danych jest uświadomienie aplikacji o opóźnieniu replikacji. Zwykle jest programowany w kodzie aplikacji. Na szczęście istnieją nowoczesne systemy równoważenia obciążenia baz danych z obsługą adaptacyjnego routingu zapytań w oparciu o śledzenie GTID. Najpopularniejsze to ProxySQL i Maxscale.
ProxySQL 2.0
ProxySQL Binlog Reader pozwala ProxySQL wiedzieć w czasie rzeczywistym, który GTID został wykonany na każdym serwerze MySQL, slave'ach i samym masterze. Dzięki temu, gdy klient wykonuje odczyty, które muszą zapewnić spójność przyczynową odczytów, ProxySQL od razu wie, na którym serwerze może zostać wykonane zapytanie. Jeśli z jakiegoś powodu zapisy nie zostały jeszcze wykonane na jakimkolwiek slave, ProxySQL będzie wiedział, że zapis został wykonany na master i wyśle tam odczyt.
Maksymalna skala 2,3
MariaDB wprowadziła zwykłe odczyty w Maxscale 2.3.0. Sposób działania jest podobny do ProxySQL 2.0. Zasadniczo, gdy causal_reads są włączone, wszelkie kolejne odczyty wykonywane na serwerach podrzędnych będą wykonywane w sposób, który zapobiega wpływowi opóźnienia replikacji na wyniki. Jeśli urządzenie podrzędne nie dogoni urządzenia nadrzędnego w skonfigurowanym czasie, zapytanie zostanie ponowione na urządzeniu nadrzędnym.