Długotrwałe zapytania/wypowiedzi/transakcje są czasami nieuniknione w środowisku MySQL. W niektórych przypadkach długotrwałe zapytanie może być katalizatorem katastrofalnego wydarzenia. Jeśli zależy Ci na swojej bazie danych, optymalizacja wydajności zapytań i wykrywanie długotrwałych zapytań muszą być wykonywane regularnie. Sprawy stają się jednak trudniejsze, gdy zaangażowanych jest wiele instancji w grupie lub klastrze.
Kiedy mamy do czynienia z wieloma węzłami, musimy unikać powtarzających się zadań sprawdzania każdego pojedynczego węzła. ClusterControl monitoruje wiele aspektów serwera bazy danych, w tym zapytania. ClusterControl agreguje wszystkie informacje związane z zapytaniami ze wszystkich węzłów w grupie lub klastrze, aby zapewnić scentralizowany widok obciążenia. Właśnie istnieje świetny sposób na zrozumienie całego klastra przy minimalnym wysiłku.
W tym poście na blogu pokazujemy, jak wykrywać długo działające zapytania MySQL za pomocą ClusterControl.
Dlaczego zapytanie zajmuje więcej czasu?
Przede wszystkim musimy znać charakter zapytania, czy oczekuje się, że będzie to zapytanie długo lub krótko. Niektóre operacje analityczne i wsadowe mają być długotrwałymi zapytaniami, więc na razie możemy je pominąć. Ponadto, w zależności od rozmiaru tabeli, modyfikowanie struktury tabeli poleceniem ALTER może być długotrwałą operacją.
W przypadku transakcji o krótkim rozpiętości należy ją wykonać tak szybko, jak to możliwe, zwykle w ciągu poniżej sekundy. Im krócej, tym lepiej. Jest to zestaw najlepszych praktyk dotyczących zapytań, których użytkownicy muszą przestrzegać, takich jak prawidłowe indeksowanie w instrukcji WHERE lub JOIN, używanie odpowiedniego silnika pamięci masowej, wybieranie odpowiednich typów danych, planowanie operacji wsadowych poza godzinami szczytu, odciążanie funkcji analitycznych /zgłaszanie ruchu do dedykowanych replik i tak dalej.
Istnieje kilka rzeczy, które mogą spowodować, że wykonanie zapytania zajmie więcej czasu:
- Nieefektywne zapytanie — używaj nieindeksowanych kolumn podczas wyszukiwania lub łączenia, dzięki czemu MySQL potrzebuje więcej czasu na dopasowanie warunku.
- Blokada tabeli — tabela jest zablokowana przez globalną lub jawną blokadę tabeli, gdy zapytanie próbuje uzyskać do niej dostęp.
- Zakleszczenie — zapytanie czeka na dostęp do tych samych wierszy, które są zablokowane przez inne zapytanie.
- Zbiór danych nie mieści się w pamięci RAM — jeśli dane zestawu roboczego mieszczą się w tej pamięci podręcznej, zapytania SELECT będą zwykle stosunkowo szybkie.
- Nieoptymalne zasoby sprzętowe — mogą to być powolne dyski, odbudowa RAID, przesycenie sieci itp.
- Operacja konserwacyjna — uruchomienie mysqldump może przenieść ogromne ilości nieużywanych w inny sposób danych do puli buforów, a jednocześnie (potencjalnie przydatne) dane, które już tam są, zostaną usunięte i opróżnione na dysk.
Powyższa lista podkreśla, że nie tylko samo zapytanie powoduje różnego rodzaju problemy. Istnieje wiele powodów, które wymagają przyjrzenia się różnym aspektom serwera MySQL. W najgorszym przypadku długotrwałe zapytanie może spowodować całkowite zakłócenie działania usługi, takie jak awaria serwera, awaria serwera i przekroczenie limitu połączeń. Jeśli zauważysz, że wykonanie zapytania trwa dłużej niż zwykle, sprawdź je.
Jak sprawdzić?
LISTA PROCESÓW
MySQL zapewnia szereg wbudowanych narzędzi do sprawdzania długo działającej transakcji. Przede wszystkim polecenia SHOW PROCESSLIST lub SHOW FULL PROCESSLIST mogą w czasie rzeczywistym ujawniać uruchomione zapytania. Oto zrzut ekranu funkcji ClusterControl Running Queries, podobnej do polecenia SHOW FULL PROCESSLIST (ale ClusterControl agreguje cały proces w jednym widoku dla wszystkich węzłów w klastrze):
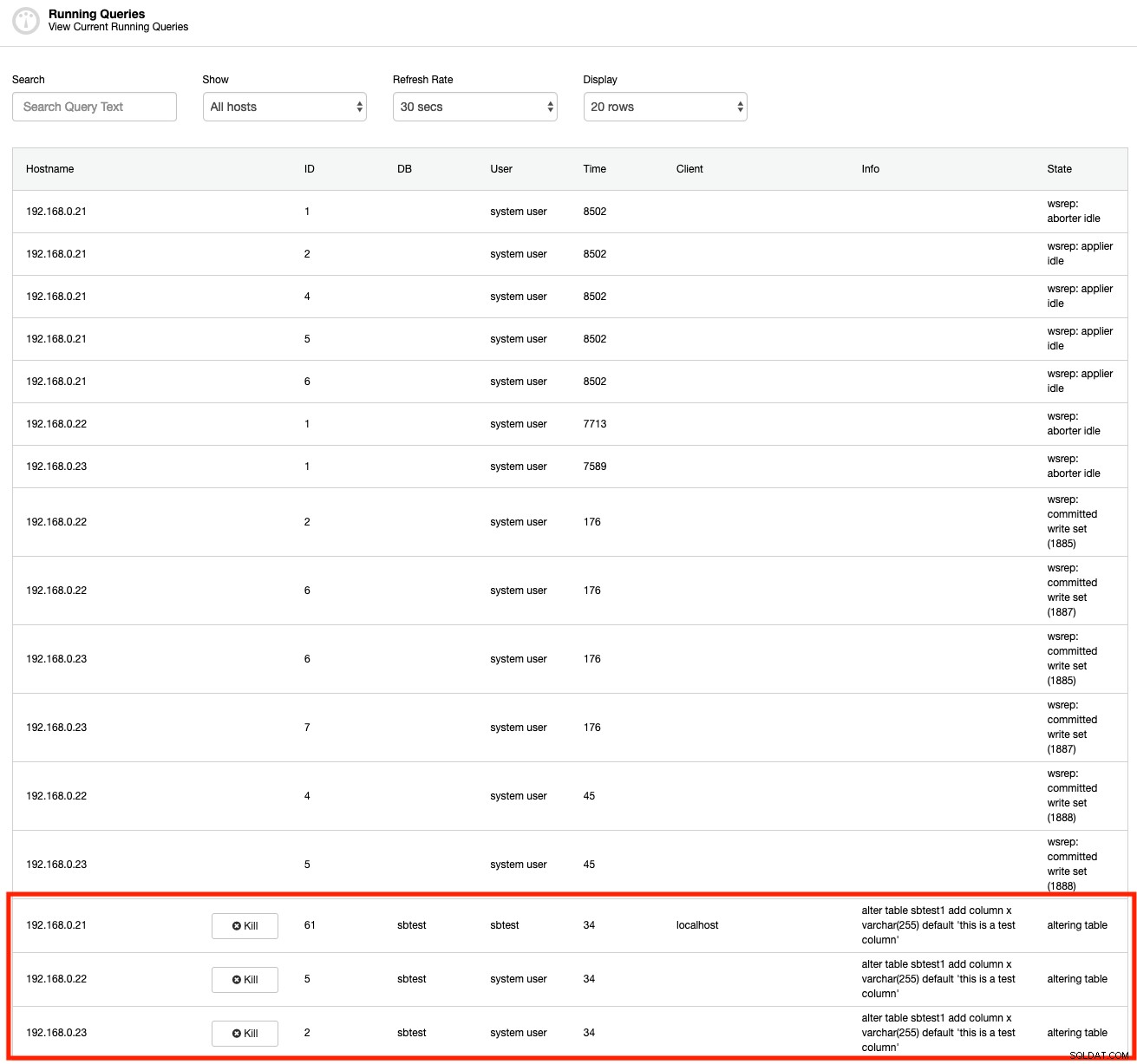
Jak widać, możemy natychmiast zobaczyć obraźliwe zapytanie od razu po wyjściu. Ale jak często przyglądamy się tym procesom? Jest to przydatne tylko wtedy, gdy zdajesz sobie sprawę z długotrwałej transakcji. W przeciwnym razie nie wiedziałbyś, dopóki coś się nie stanie — na przykład połączenia się nawarstwiają lub serwer działa wolniej niż zwykle.
Dziennik powolnych zapytań
Dziennik powolnych zapytań przechwytuje powolne zapytania (wyrażenia SQL, które zajmują więcej niż long_query_time) sekund do wykonania) lub zapytania, które nie używają indeksów do wyszukiwania (log_queries_not_using_indexes ). Ta funkcja nie jest domyślnie włączona i aby ją włączyć, wystarczy ustawić następujące wiersze i ponownie uruchomić serwer MySQL:
[mysqld]
slow_query_log=1
long_query_time=0.1
log_queries_not_using_indexes=1Powolny dziennik zapytań może służyć do znajdowania zapytań, których wykonanie zajmuje dużo czasu, a zatem są kandydatami do optymalizacji. Jednak badanie długiego, wolnego dziennika zapytań może być czasochłonnym zadaniem. Istnieją narzędzia do analizowania plików dziennika powolnych zapytań MySQL i podsumowywania ich zawartości, takie jak mysqldumpslow, pt-query-digest lub ClusterControl Top Queries.
ClusterControl Top Queries podsumowuje wolne zapytanie za pomocą dwóch metod — dziennika wolnych zapytań MySQL lub schematu wydajności:
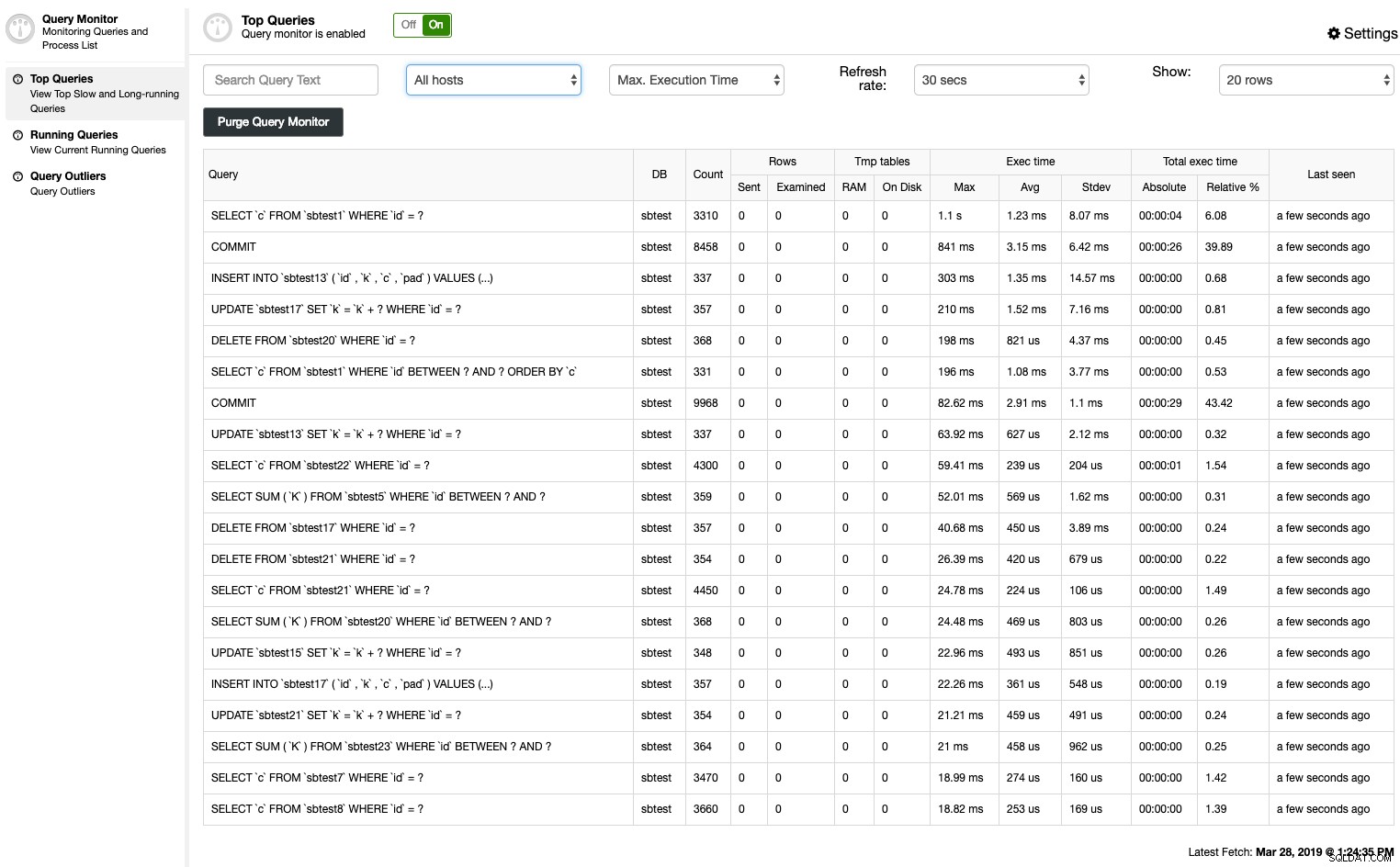
Możesz łatwo zobaczyć podsumowanie znormalizowanych skrótów instrukcji, posortowanych według kilku kryteriów:
- Gospodarz
- Zdarzenia
- Całkowity czas wykonania
- Maksymalny czas wykonania
- Średni czas wykonania
- Czas odchylenia standardowego
Szczegółowo omówiliśmy tę funkcję w tym poście na blogu, Jak korzystać z monitora zapytań ClusterControl dla MySQL, MariaDB i Percona Server.
Schemat wydajności
Performance Schema to doskonałe narzędzie dostępne do monitorowania elementów wewnętrznych MySQL Server i szczegółów wykonania na niższym poziomie. Poniższe tabele w schemacie wydajności mogą służyć do wyszukiwania wolnych zapytań:
- events_statements_current
- events_statements_history
- events_statements_history_long
- events_statements_summary_by_digest
- events_statements_summary_by_user_by_event_name
- events_statements_summary_by_host_by_event_name
MySQL 5.7.7 i nowsze zawierają schemat sys, zestaw obiektów, który pomaga administratorom baz danych i programistom interpretować dane zebrane przez schemat wydajności w bardziej zrozumiałej formie. Obiekty schematu sys mogą być używane w typowych przypadkach dostrajania i diagnostyki.
ClusterControl zapewnia doradców, które są mini-programami, które można pisać za pomocą ClusterControl DSL (podobnie jak w JavaScript), aby rozszerzyć możliwości monitorowania ClusterControl dostosowane do Twoich potrzeb. Dostępnych jest wiele skryptów opartych na schemacie wydajności, których można używać do monitorowania wydajności zapytań, takich jak oczekiwanie na we/wy, czas oczekiwania na blokadę i tak dalej. Na przykład w Zarządzaj -> Studio programistyczne , przejdź do s9s -> mysql -> p_s -> top_tables_by_iowait.js i kliknij przycisk „Skompiluj i uruchom”. Powinieneś zobaczyć dane wyjściowe w zakładce Messages dla 10 najlepszych tabel posortowanych według I/O oczekiwania na serwer:
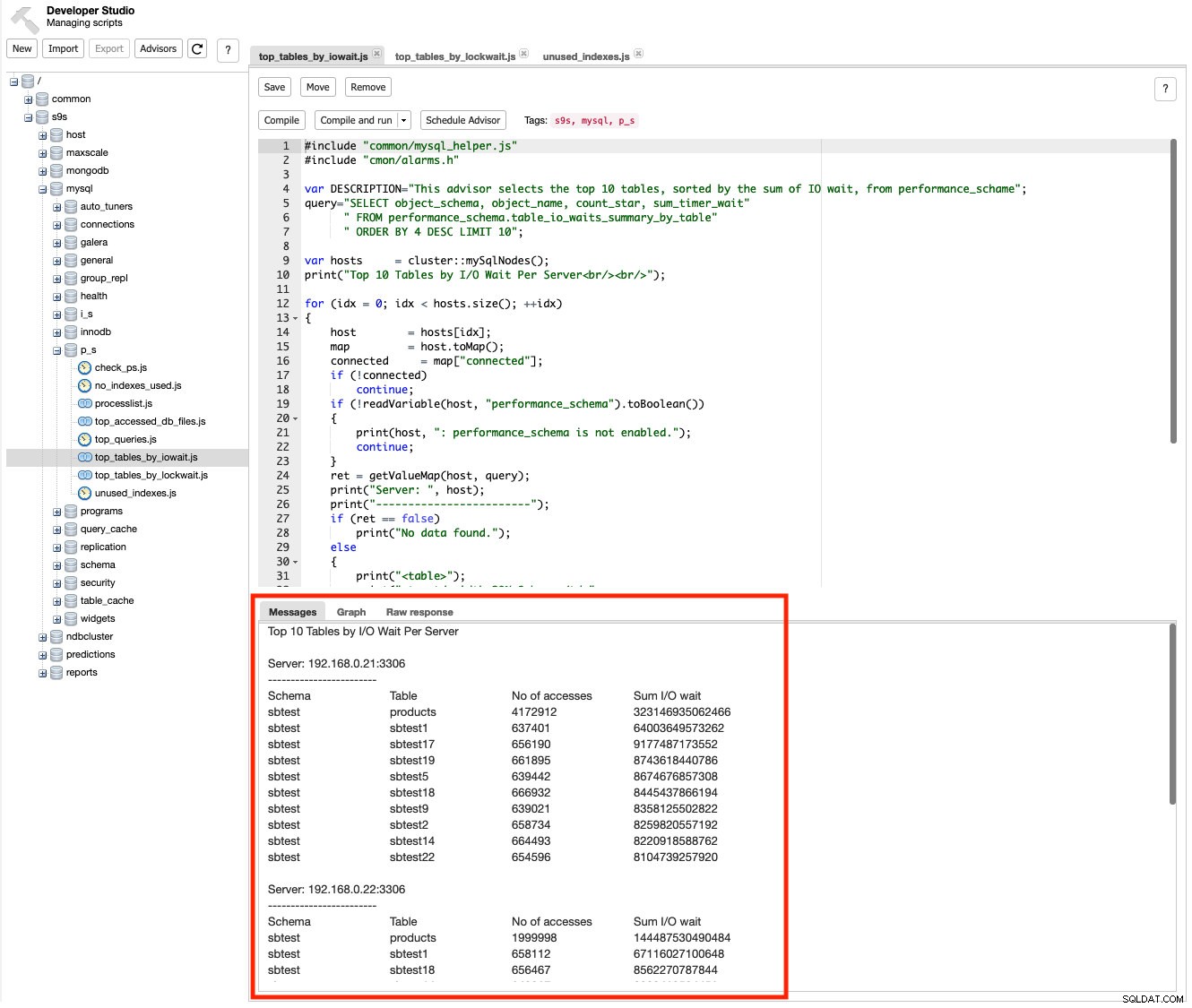
Istnieje wiele skryptów, których można użyć do zrozumienia informacji niskiego poziomu, gdzie i dlaczego występuje spowolnienie, takie jak top_tables_by_lockwait.js , top_accessed_db_files.js i tak dalej.
ClusterControl — wykrywanie i ostrzeganie w przypadku długotrwałych zapytań
Dzięki ClusterControl uzyskasz dodatkowe zaawansowane funkcje, których nie znajdziesz w standardowej instalacji MySQL. ClusterControl można skonfigurować tak, aby proaktywnie monitorował uruchomione procesy oraz w przypadku przekroczenia długiego progu zapytań wszczynał alarm i wysyłał powiadomienie do użytkownika. Można to skonfigurować za pomocą Konfiguracji środowiska wykonawczego w Ustawieniach:
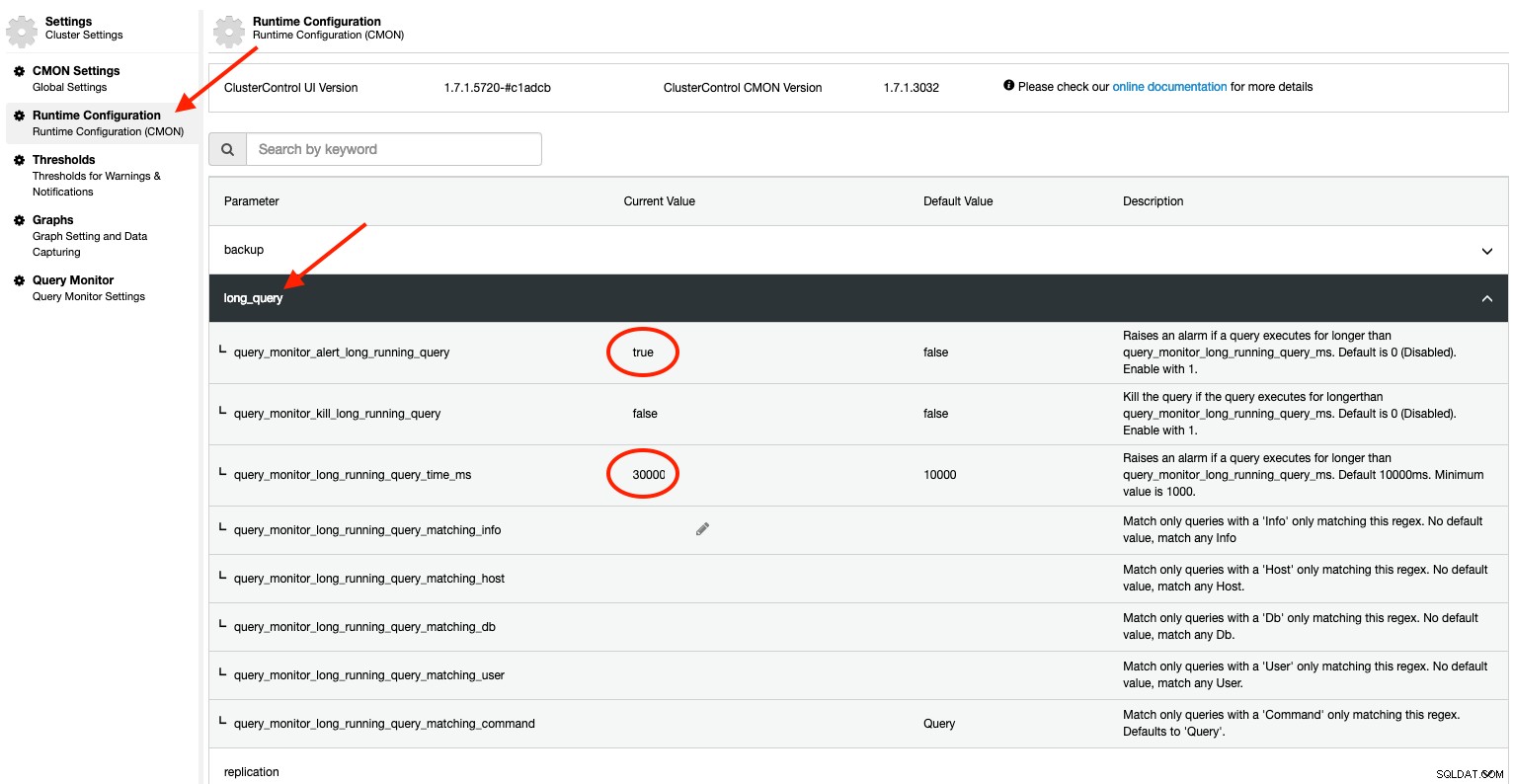
W wersji wcześniejszej niż 1.7.1 domyślna wartość query_monitor_alert_long_running_query to fałsz. Zachęcamy użytkownika do włączenia tej opcji poprzez ustawienie jej na 1 (prawda). Aby było trwałe, dodaj następującą linię do /etc/cmon.d/cmon_X.cnf:
query_monitor_alert_long_running_query=1
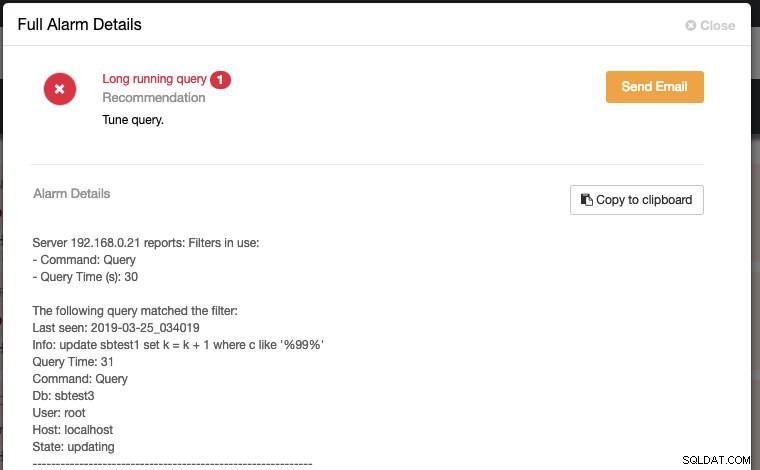
query_monitor_long_running_query_ms=30000Wszelkie zmiany wprowadzone w konfiguracji środowiska wykonawczego są stosowane natychmiast i nie jest wymagane ponowne uruchomienie. Zobaczysz coś takiego w sekcji Alarmy, jeśli zapytanie przekroczy próg 30000 ms (30 sekund):
Jeśli skonfigurujesz ustawienia odbiorcy poczty jako „Dostarcz” dla kategorii ważności DbComponent plus KRYTYCZNE (jak pokazano na poniższym zrzucie ekranu):
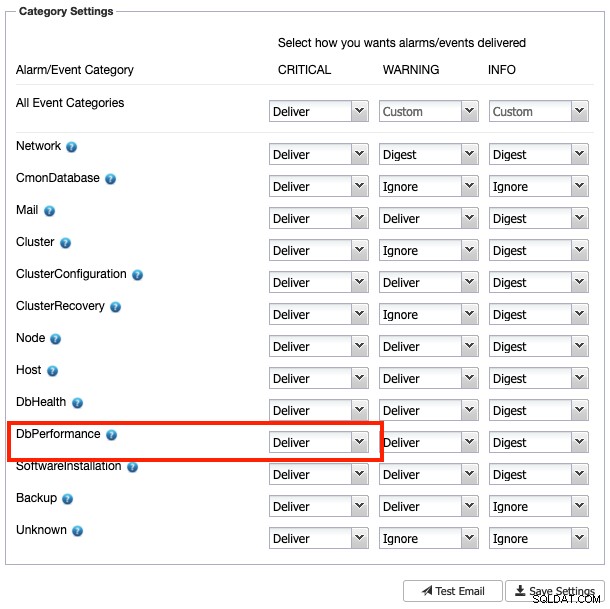
Powinieneś otrzymać kopię tego alarmu na swój e-mail. W przeciwnym razie można go przekazać ręcznie, klikając przycisk „Wyślij e-mail”.
Ponadto możesz odfiltrować dowolny rodzaj zasobów listy procesów, które spełniają określone kryteria za pomocą wyrażenia regularnego (regex). Na przykład, jeśli chcesz, aby ClusterControl wykrywał długotrwałe zapytania dla trzech użytkowników MySQL o nazwach „sbtest”, „myshop” i „db_user1”, należy wykonać następujące czynności:
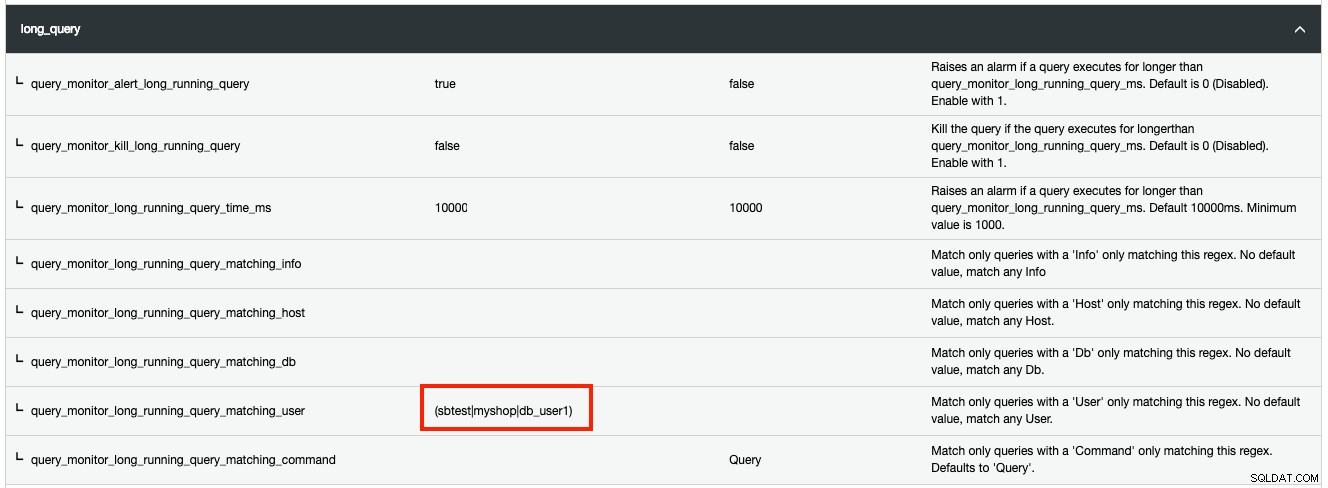
Wszelkie zmiany wprowadzone w konfiguracji środowiska wykonawczego są stosowane natychmiast i nie jest wymagane ponowne uruchomienie.
Dodatkowo ClusterControl wyświetli listę wszystkich zakleszczonych transakcji wraz ze statusem InnoDB, gdy miało to miejsce w Wydajność -> Dziennik transakcji :
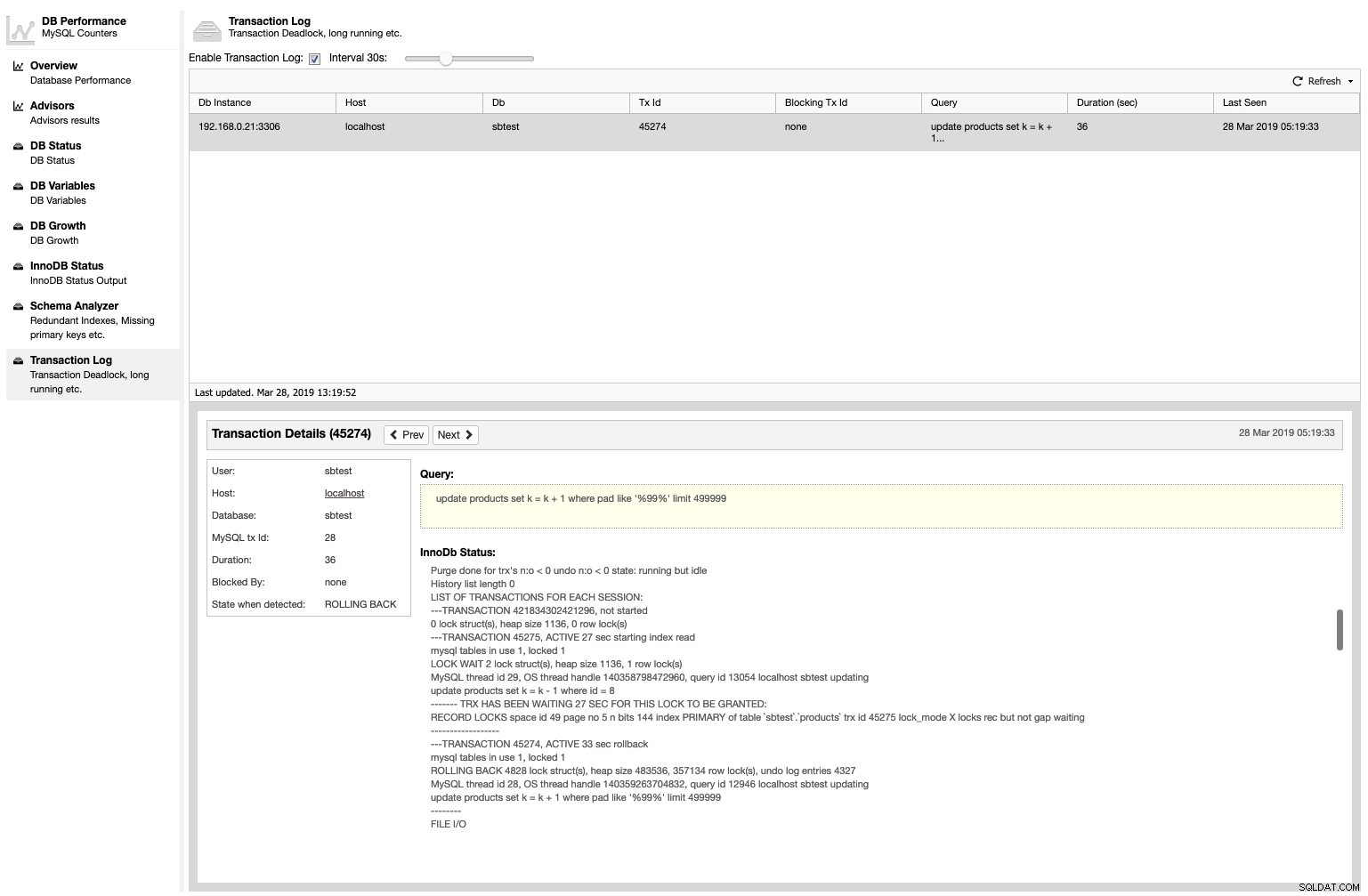
Ta funkcja nie jest domyślnie włączona, ponieważ wykrywanie zakleszczeń wpłynie na użycie procesora w węzłach bazy danych. Aby go włączyć, po prostu zaznacz pole wyboru „Włącz dziennik transakcji” i określ żądany interwał. Aby była trwała, dodaj zmienną z wartością w sekundach w /etc/cmon.d/cmon_X.cnf:
db_deadlock_check_interval=30Podobnie, jeśli chcesz sprawdzić stan InnoDB, po prostu przejdź do Wydajność -> Stan InnoDB i wybierz serwer MySQL z listy rozwijanej. Na przykład:
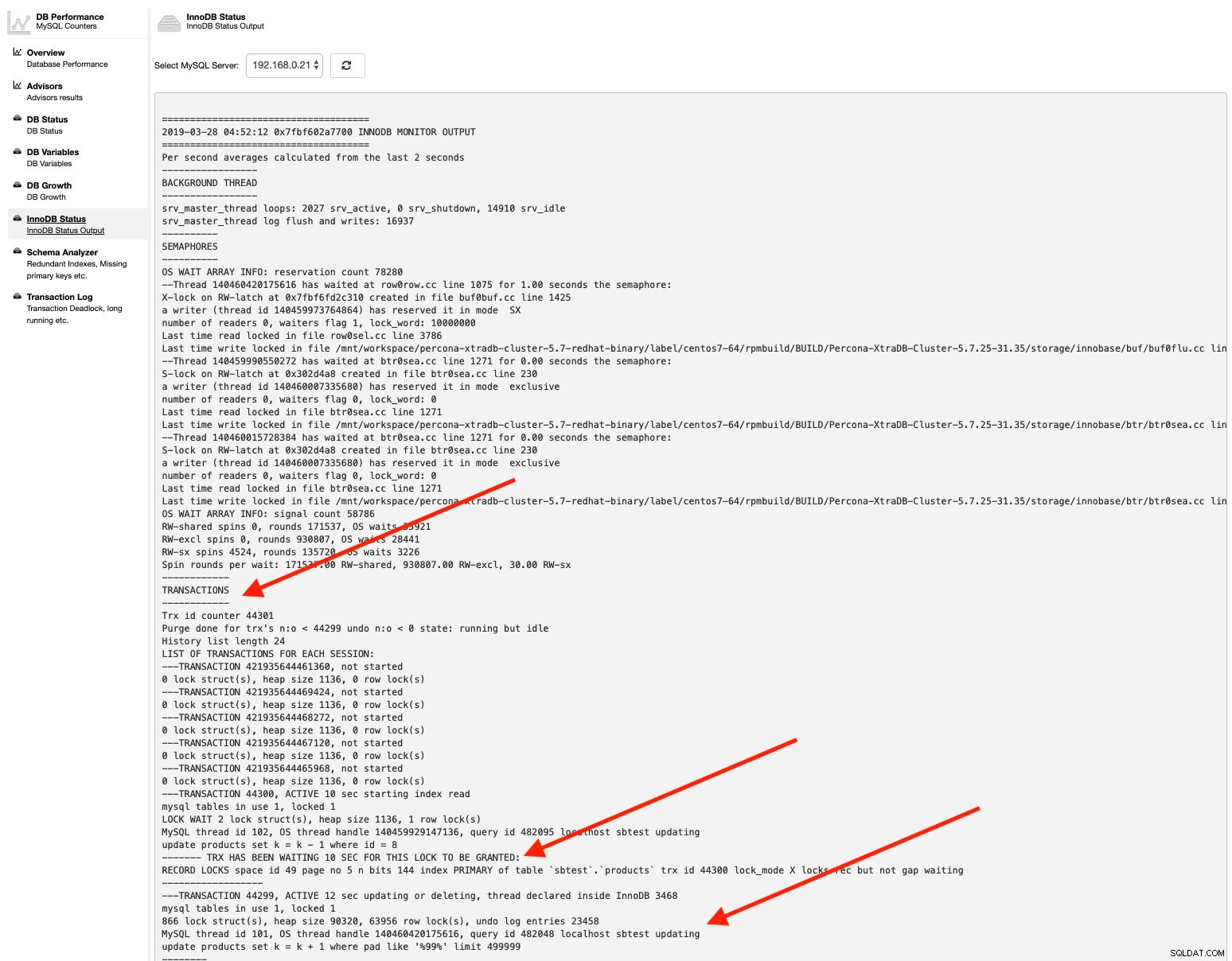
Proszę bardzo - wszystkie wymagane informacje można łatwo pobrać za pomocą kilku kliknięć.
Podsumowanie
Długotrwałe transakcje mogą prowadzić do obniżenia wydajności, awarii serwera, przeciążenia połączeń i zakleszczeń. Dzięki ClusterControl możesz wykrywać długo działające zapytania bezpośrednio z interfejsu użytkownika, bez konieczności sprawdzania każdego węzła MySQL w klastrze.