Presto to open-source, równolegle rozproszony silnik SQL do przetwarzania dużych zbiorów danych. Został opracowany od podstaw przez Facebooka. Pierwsze wewnętrzne wydanie miało miejsce w 2013 roku i było dość rewolucyjnym rozwiązaniem ich problemów z dużymi danymi.
Mając setki geolokalizowanych serwerów i petabajtów danych, Facebook zaczął szukać alternatywnej platformy dla swoich klastrów Hadoop. Ich zespół ds. infrastruktury chciał skrócić czas potrzebny na wykonanie zadań analitycznych wsadowych i uprościć opracowywanie potoku przy użyciu języka programowania powszechnie znanego w organizacji - SQL.
Według fundacji Presto „Facebook używa Presto do interaktywnych zapytań dotyczących kilku wewnętrznych magazynów danych, w tym ich hurtowni danych o wielkości 300 PB. Ponad 1000 pracowników Facebooka korzysta codziennie z Presto, aby uruchamiać ponad 30 000 zapytań, które w sumie skanują ponad petabajt każdego dnia”.
Chociaż Facebook ma wyjątkowe środowisko hurtowni danych, te same wyzwania są obecne w wielu organizacjach zajmujących się big data.
W tym blogu przyjrzymy się, jak skonfigurować podstawowe środowisko presto przy użyciu serwera Docker z pliku tar. Jako źródło danych skupimy się na źródle danych MySQL, ale może to być dowolny inny popularny RDBMS.
Uruchamianie Presto w środowisku Big Data
Zanim zaczniemy, rzućmy okiem na jego główne zasady architektury. Presto jest alternatywą dla narzędzi, które wysyłają zapytania do HDFS przy użyciu potoków zadań MapReduce — takich jak Hive. W przeciwieństwie do Hive Presto nie używa MapReduce. Presto działa ze specjalnym silnikiem wykonywania zapytań z operatorami wysokiego poziomu i przetwarzaniem w pamięci.
W przeciwieństwie do Hive Presto, może przesyłać strumieniowo dane przez wszystkie etapy jednocześnie, uruchamiając jednocześnie porcje danych. Jest przeznaczony do uruchamiania zapytań analitycznych ad hoc na pojedynczych lub rozproszonych heterogenicznych źródłach danych. Może sięgnąć z platformy Hadoop do wysyłania zapytań do relacyjnych baz danych lub innych magazynów danych, takich jak pliki płaskie.
Presto korzysta ze standardowego ANSI SQL, w tym agregacji, złączeń lub funkcji okna analitycznego. SQL jest dobrze znany i znacznie łatwiejszy w użyciu w porównaniu z MapReduce napisanym w Javie.
Wdrażanie Presto w Dockerze
Podstawową konfigurację Presto można wdrożyć za pomocą wstępnie skonfigurowanego obrazu Docker lub archiwum serwera presto.
Serwer docker i kontenery Presto CLI można łatwo wdrożyć za pomocą:
docker run -d -p 127.0.0.1:8080:8080 --name presto starburstdata/presto
docker exec -it presto presto-cliMożesz wybrać jedną z dwóch wersji serwera Presto. Wersja społecznościowa i wersja Enterprise firmy Starburst. Ponieważ zamierzamy uruchomić go w nieprodukcyjnym środowisku piaskownicy, w tym artykule użyjemy wersji Apache.
Wymagania wstępne
Presto jest w całości zaimplementowane w Javie i wymaga zainstalowania JVM w Twoim systemie. Działa na OpenJDK i Oracle Java. Minimalna wersja to Java 8u151 lub Java 11.
Aby pobrać JAVA JDK, odwiedź stronę https://openjdk.java.net/ lub https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Możesz sprawdzić swoją wersję Java za pomocą
$ java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)Instalacja Presto
Aby zainstalować Presto, pobierzemy serwer tar i plik wykonywalny Presto CLI jar.
Plik tar będzie zawierał pojedynczy katalog najwyższego poziomu, presto-server-0.223, który nazwiemy katalogiem instalacyjnym.
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.223/presto-server-0.223.tar.gz
$ tar -xzvf presto-server-0.223.tar.gz
$ cd presto-server-0.223/
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.223/presto-cli-0.223-executable.jar
$ mv presto-cli-0.223-executable.jar presto
$ chmod +x prestoDodatkowo Presto potrzebuje katalogu danych do przechowywania dzienników itp.
Zaleca się utworzenie katalogu danych poza katalogiem instalacyjnym.
$ mkdir -p ~/data/presto/Ta lokalizacja to miejsce, w którym rozpoczynamy rozwiązywanie problemów.
Konfigurowanie Presto
Zanim zaczniemy naszą pierwszą instancję, musimy stworzyć kilka plików konfiguracyjnych. Zacznij od utworzenia katalogu etc/ w katalogu instalacyjnym. Ta lokalizacja będzie zawierać następujące pliki konfiguracyjne:
itp/
- Właściwości węzła - konfiguracja środowiska węzła
- Konfiguracja JVM (jvm.config) — konfiguracja wirtualnej maszyny Java
- Właściwości konfiguracji(config.properties) — konfiguracja dla serwera Presto
- Właściwości katalogu — konfiguracja łączników (źródła danych)
- Właściwości dziennika — konfiguracja rejestratorów
Poniżej znajdziesz podstawową konfigurację do uruchomienia piaskownicy Presto. Więcej informacji można znaleźć w dokumentacji.
vi etc/config.properties
Config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = https://localhost:8080
vi etc/jvm.config
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
vi etc/log.properties
com.facebook.presto = INFOvi etc/node.properties
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/bartez/data/prestoPodstawowa struktura etc/ może wyglądać następująco:

Następnym krokiem jest skonfigurowanie łącznika MySQL.
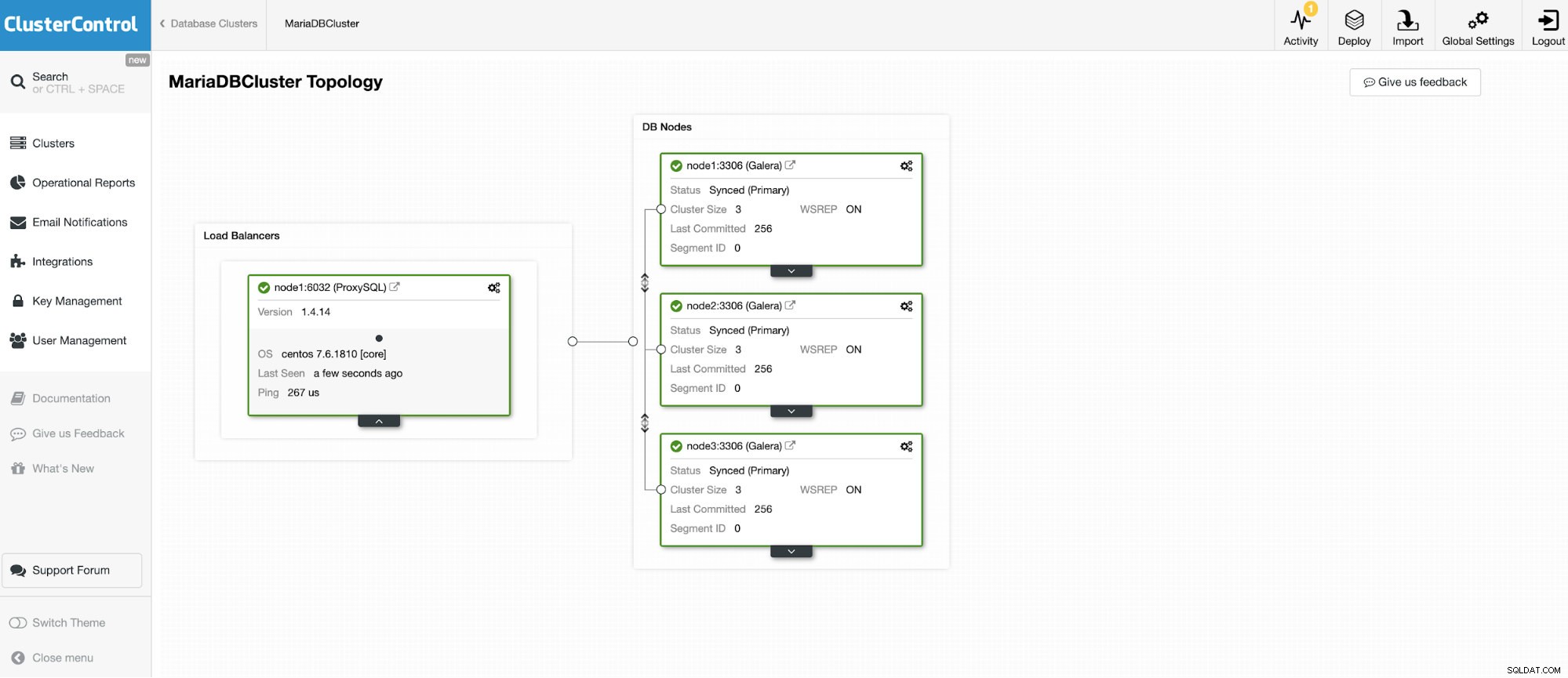
Zamierzamy połączyć się z jednym z 3 węzłów Klastra MariaDB.
I kolejna samodzielna instancja z Oracle MySQL 5.7.
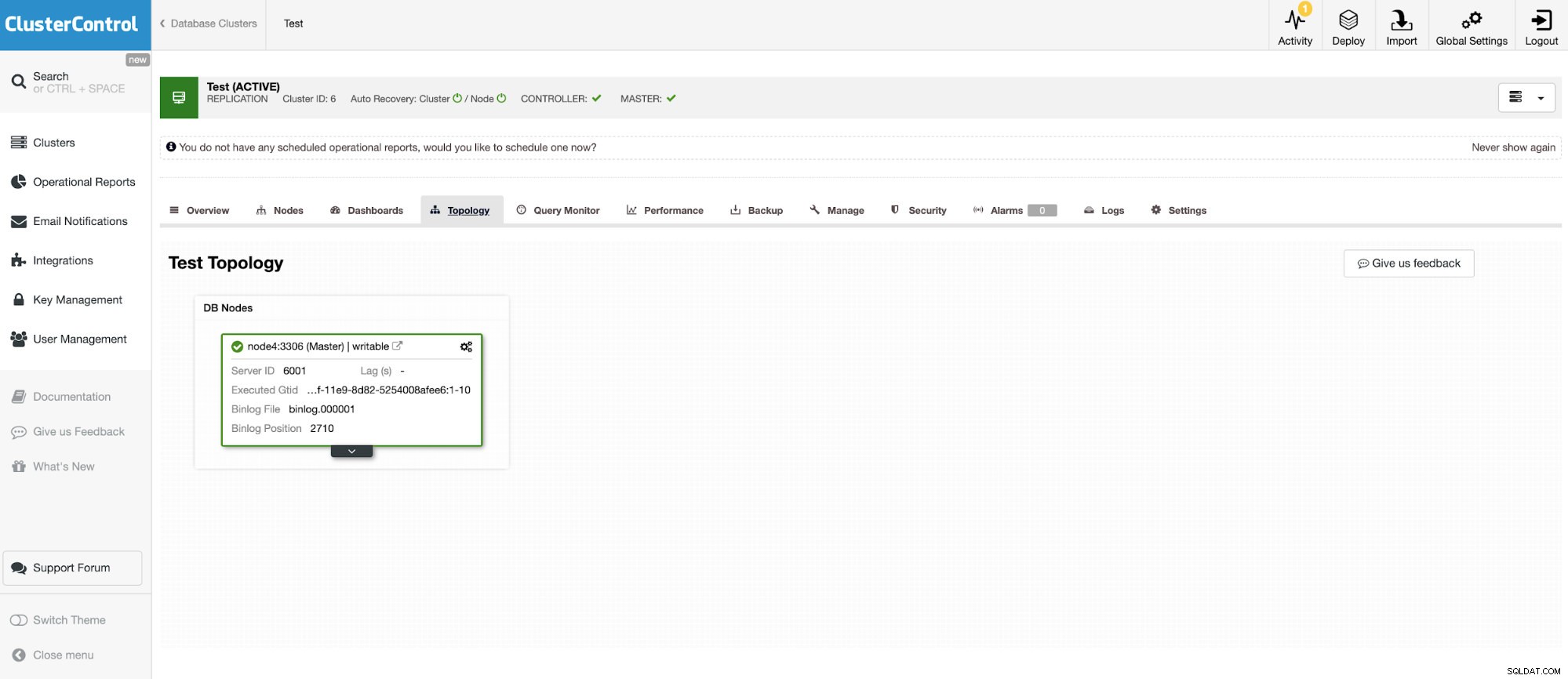
Łącznik MySQL umożliwia wykonywanie zapytań i tworzenie tabel w zewnętrznej bazie danych MySQL. Można to wykorzystać do łączenia danych między różnymi systemami, takimi jak MariaDB i MySQL firmy Oracle.
Presto wykorzystuje złącza wtykowe, a konfiguracja jest bardzo łatwa. Aby skonfigurować łącznik MySQL, utwórz plik właściwości katalogu w etc/catalog o nazwie na przykład mysql.properties, aby zamontować łącznik MySQL jako katalog mysql. Każdy z plików reprezentujących połączenie z innym serwerem. W tym przypadku mamy dwa pliki:
vi etc/catalog/mysq.properties:
connector.name=mysql
connection-url=jdbc:mysql://node1.net:3306
connection-user=bart
connection-password=secretvi etc/catalog/mysq2.properties
connector.name=mysql
connection-url=jdbc:mysql://node4.net:3306
connection-user=bart2
connection-password=secretUruchamianie Presto
Gdy wszystko jest ustawione, czas uruchomić instancję Presto. Aby uruchomić presto, przejdź do katalogu bin podczas instalacji preso i uruchom następujące polecenie:
$ bin/launcher start
Started as 18363Aby zatrzymać uruchomienie Presto
$ bin/launcher stopTeraz, gdy serwer jest uruchomiony i działa, możemy połączyć się z Presto za pomocą CLI i zapytać o bazę danych MySQL.
Aby uruchomić konsolę Presto:
./presto --server localhost:8080 --catalog mysql --schema employeesTeraz możemy wysyłać zapytania do naszych baz danych przez CLI.
presto:mysql> select * from mysql.employees.departments;
dept_no | dept_name
---------+--------------------
d009 | Customer Service
d005 | Development
d002 | Finance
d003 | Human Resources
d001 | Marketing
d004 | Production
d006 | Quality Management
d008 | Research
d007 | Sales
(9 rows)
Query 20190730_232304_00019_uq3iu, FINISHED, 1 node
Splits: 17 total, 17 done (100,00%)
0:00 [9 rows, 0B] [81 rows/s, 0B/s]
Obie bazy danych klaster MariaDB i MySQL zostały zasilane bazą danych pracowników.
wget https://github.com/dataharmer/test_db/archive/master.zip
mysql -uroot -psecret < employees.sqlStatus zapytania jest również widoczny w konsoli internetowej Presto:https://localhost:8080/ui/#
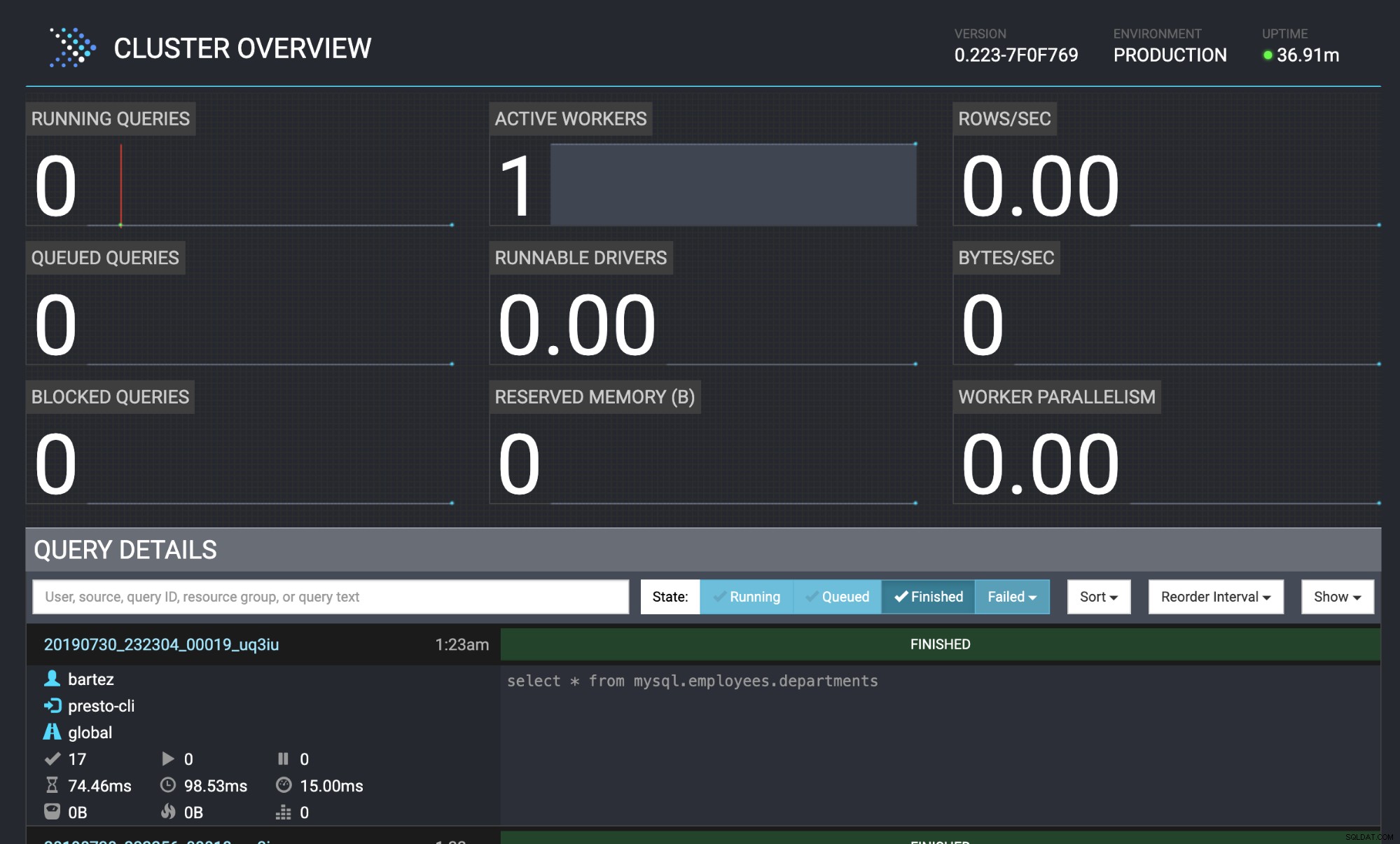 Omówienie klastra Presto
Omówienie klastra Presto Wniosek
Wiele znanych firm (takich jak Airbnb, Netflix, Twitter) korzysta z Presto w celu uzyskania niskich opóźnień. To bez wątpienia bardzo ciekawe oprogramowanie, które może wyeliminować konieczność uruchamiania ciężkich procesów hurtowni danych ETL. W tym blogu pokrótce przyjrzeliśmy się konektorowi MySQL, ale można go użyć do analizy danych z HDFS, magazynów obiektów, RDBMS (SQL Server, Oracle, PostgreSQL), Kafki, Cassandra, MongoDB i wielu innych.