Galera Cluster 4.0 został po raz pierwszy wydany jako część MariaDB 10.4 i jest wiele znaczących ulepszeń w tej wersji. Najbardziej imponującą funkcją w tym wydaniu jest replikacja strumieniowa, która została zaprojektowana do obsługi następujących problemów.
- Problemy z długimi transakcjami
- Problemy z dużymi transakcjami
- Problemy z gorącymi punktami w tabelach
W poprzednim blogu zagłębiliśmy się w nową funkcję replikacji strumieniowej w dwuczęściowym blogu z serii (część 1 i część 2). Częścią tej nowej funkcji w Galera 4.0 są nowe tabele systemowe, które są bardzo przydatne do odpytywania i sprawdzania węzłów Galera Cluster, a także dzienników, które zostały przetworzone w Streaming Replication.
Również w poprzednich blogach pokazaliśmy również prosty sposób wdrożenia klastra MySQL Galera na AWS, a także jak wdrożyć klaster MySQL Galera Cluster 4.0 na Amazon AWS EC2.
Percona nie wydała jeszcze GA dla swojego Percona XtraDB Cluster (PXC) 8.0, ponieważ niektóre funkcje są wciąż w fazie rozwoju, takie jak funkcja wsrep MySQL WSREP_SYNC_WAIT_UPTO_GTID, która wydaje się jeszcze nie być dostępna (przynajmniej w wersji PXC 8.0.15-5-27dev.4.2). Jednak po wydaniu PXC 8.0 będzie on wyposażony w wspaniałe funkcje, takie jak...
- Ulepszony, odporny klaster
- Klaster przyjazny dla chmury
- ulepszone opakowanie
- Obsługa szyfrowania
- Atomowy DDL
Podczas gdy czekamy na wydanie PXC 8.0 GA, w tym blogu omówimy, jak utworzyć węzeł w trybie gotowości w trybie gotowości na Amazon AWS dla Galera Cluster 4.0 za pomocą MariaDB.
Co to jest gorący tryb gotowości?
Ciepła rezerwa jest powszechnym terminem w informatyce, zwłaszcza w systemach o wysokim stopniu rozproszenia. Jest to metoda redundancji, w której jeden system działa jednocześnie z identycznym systemem podstawowym. Gdy w węźle podstawowym wystąpi awaria, hot standby natychmiast przejmuje zastępowanie systemu podstawowego. Dane są kopiowane do obu systemów w czasie rzeczywistym.
W przypadku systemów baz danych serwer w stanie gotowości w trybie gotowości jest zwykle drugim węzłem po głównym serwerze głównym, który działa na potężnych zasobach (tak samo jak główny). Ten drugorzędny węzeł musi być tak stabilny, jak główny master, aby działał poprawnie.
Służy również jako węzeł odzyskiwania danych w przypadku awarii węzła głównego lub całego klastra. Węzeł gorącej gotowości zastąpi uszkodzony węzeł lub klaster, stale obsługując zapotrzebowanie klientów.
W Galera Cluster wszystkie serwery należące do klastra mogą służyć jako węzeł gotowości. Jeśli jednak region lub cały klaster upadnie, jak będziesz w stanie sobie z tym poradzić? Jedną z opcji jest utworzenie węzła rezerwowego poza określonym regionem lub siecią klastra.
W poniższej sekcji pokażemy, jak utworzyć węzeł rezerwowy w AWS EC2 przy użyciu MariaDB.
Wdrażanie gorącej gotowości w Amazon AWS
Wcześniej pokazaliśmy, jak utworzyć klaster Galera w AWS. Jeśli jesteś nowy w Galera 4.0, możesz przeczytać Wdrażanie MySQL Galera Cluster 4.0 na Amazon AWS EC2.
Wdrożenie węzła w trybie gotowości można przeprowadzić na innym zestawie Galera Cluster, który wykorzystuje replikację synchroniczną (sprawdź ten blog Migracja sieci bez przestojów z MySQL Galera Cluster przy użyciu węzła przekazującego) lub przez wdrożenie asynchronicznego węzła MySQL/MariaDB . W tym blogu skonfigurujemy i wdrożymy asynchroniczny węzeł w trybie gotowości w trybie gotowości z jednego z węzłów Galera.
Konfiguracja klastra Galera
W tej przykładowej konfiguracji wdrożyliśmy 3-węzłowy klaster przy użyciu wersji MariaDB 10.4.8. Ten klaster jest wdrażany w regionie Wschodnie stany USA (Ohio), a topologia jest pokazana poniżej:
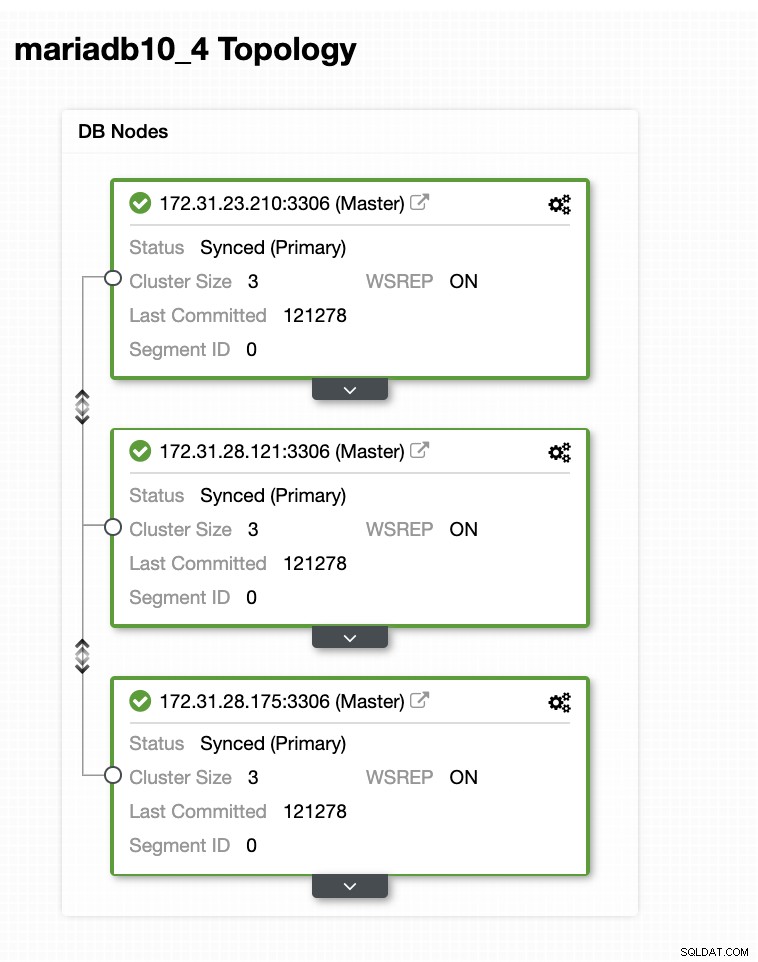
Użyjemy serwera 172.31.26.175 jako głównego dla naszego asynchronicznego urządzenia podrzędnego który będzie służył jako węzeł gotowości.
Konfigurowanie instancji EC2 dla węzła gorącej gotowości
W konsoli AWS przejdź do EC2 znajdującego się w sekcji Obliczenia i kliknij Uruchom instancję, aby utworzyć instancję EC2, tak jak poniżej.
Tę instancję utworzymy w regionie Zachodnie stany USA (Oregon). Dla twojego typu systemu operacyjnego możesz wybrać serwer, który ci się podoba (wolę Ubuntu 18.04) i wybrać typ instancji w oparciu o preferowany typ celu. W tym przykładzie użyję t2.micro, ponieważ nie wymaga on żadnej skomplikowanej konfiguracji i jest przeznaczony tylko do tego przykładowego wdrożenia.
Jak wspomnieliśmy wcześniej, najlepiej jest, aby węzeł gotowości w trybie gotowości znajdował się w innym regionie, a nie w tym samym regionie. Tak więc w przypadku awarii regionalnego centrum danych lub awarii sieci, aktywny tryb gotowości może być celem przełączania awaryjnego, gdy coś pójdzie nie tak.
Zanim przejdziemy dalej, w AWS różne regiony będą miały własną wirtualną chmurę prywatną (VPC) i własną sieć. Aby komunikować się z węzłami klastra Galera, musimy najpierw zdefiniować VPC Peering, aby węzły mogły komunikować się w ramach infrastruktury Amazon i nie musiały wychodzić poza sieć, co tylko zwiększa obciążenie i obawy o bezpieczeństwo.
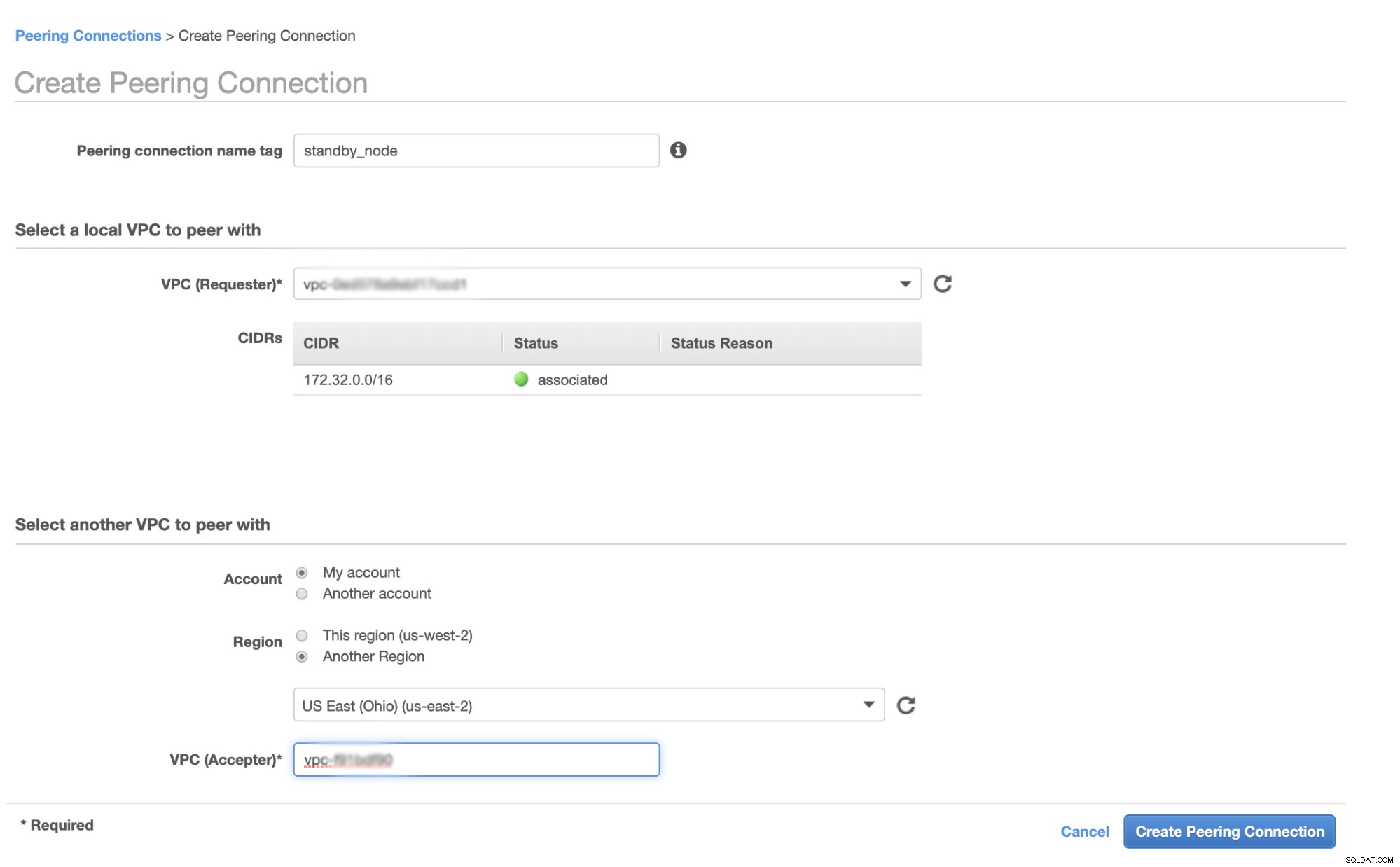
Najpierw przejdź do swojego VPC, z którego powinien znajdować się węzeł gotowości, a następnie przejdź do połączeń równorzędnych. Następnie musisz określić VPC węzła rezerwowego i VPC klastra Galera. W poniższym przykładzie mam połączenie us-zachód-2 z us-wschód-2.
Po utworzeniu zobaczysz wpis w swoich połączeniach równorzędnych. Musisz jednak zaakceptować żądanie z VPC klastra Galera, który w tym przykładzie znajduje się na us-east-2. Zobacz poniżej,
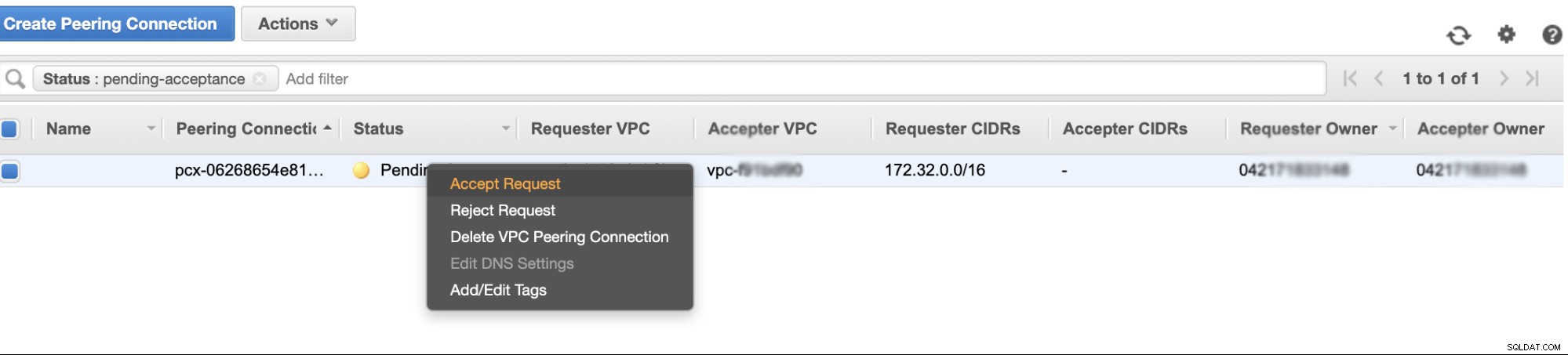
Po zaakceptowaniu nie zapomnij dodać CIDR do tabeli routingu. Zobacz ten zewnętrzny blog VPC Peering, aby dowiedzieć się, jak to zrobić po VPC Peering.
Teraz wróćmy i kontynuujmy tworzenie węzła EC2. Upewnij się, że grupa zabezpieczeń ma prawidłowe reguły lub wymagane porty, które należy otworzyć. Sprawdź instrukcję ustawień zapory, aby uzyskać więcej informacji na ten temat. W przypadku tej konfiguracji ustawiam akceptację całego ruchu, ponieważ jest to tylko test. Zobacz poniżej,
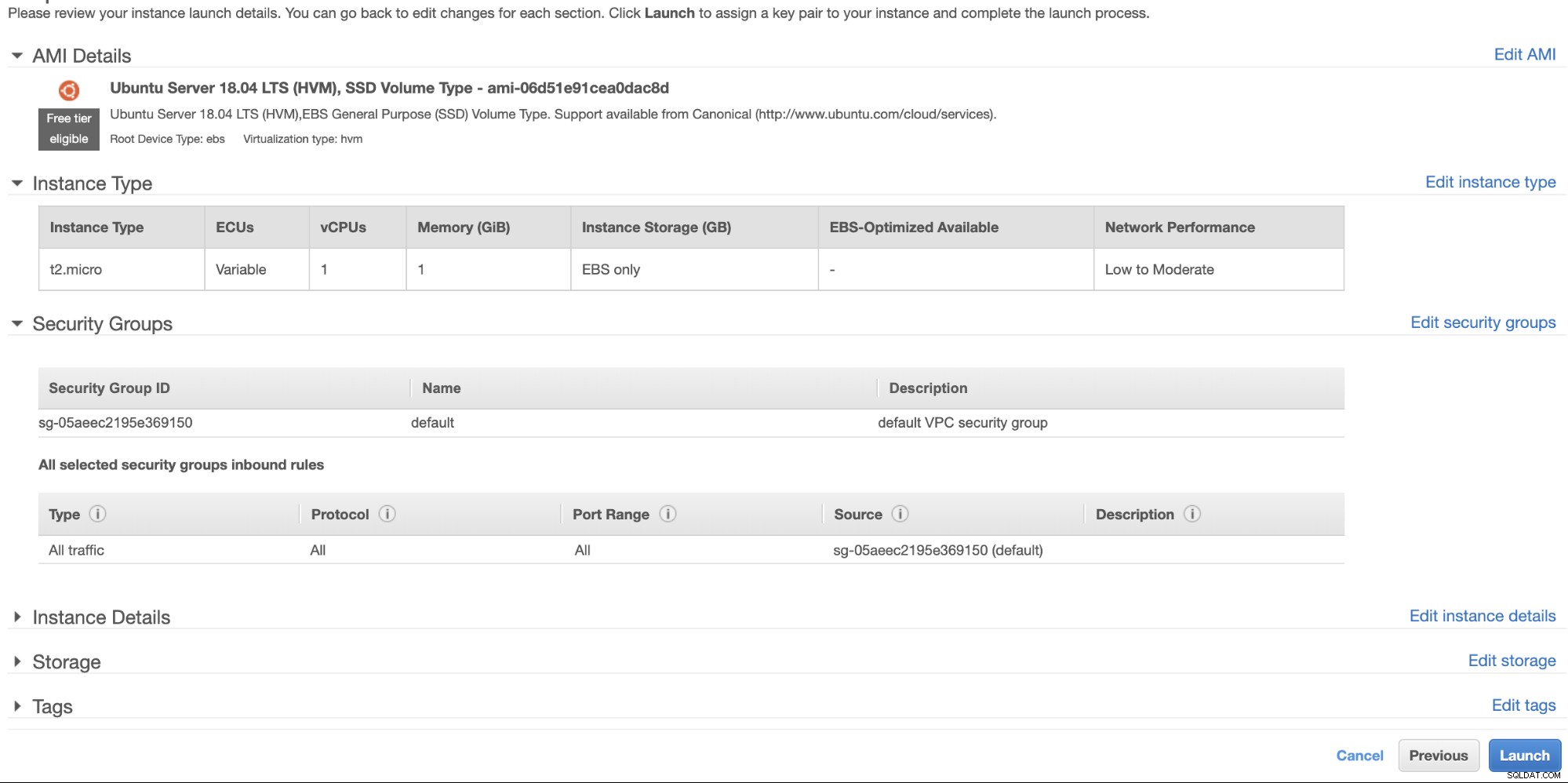
Upewnij się, że podczas tworzenia instancji ustawiono poprawny VPC i zdefiniowałeś właściwą podsieć. Możesz sprawdzić tego bloga, jeśli potrzebujesz pomocy.
Konfigurowanie MariaDB Async Slave
Krok pierwszy
Najpierw musimy skonfigurować repozytorium, dodać klucze repozytorium i zaktualizować listę pakietów w pamięci podręcznej repozytorium,
$ vi /etc/apt/sources.list.d/mariadb.list
$ apt-key adv --recv-keys --keyserver hkp://keyserver.ubuntu.com:80 0xF1656F24C74CD1D8
$ apt updateKrok drugi
Zainstaluj pakiety MariaDB i wymagane pliki binarne
$ apt-get install mariadb-backup mariadb-client mariadb-client-10.4 libmariadb3 libdbd-mysql-perl mariadb-client-core-10.4 mariadb-common mariadb-server-10.4 mariadb-server-core-10.4 mysql-commonKrok trzeci
Teraz zróbmy kopię zapasową za pomocą xbstream, aby przesłać pliki do sieci z jednego z węzłów w naszym klastrze Galera.
## Wyczyść katalog danych nowo zainstalowanego MySQL w węźle gotowości.
$ systemctl stop mariadb
$ rm -rf /var/lib/mysql/*## Następnie w gorącym węźle gotowości uruchom to na terminalu,
$ socat -u tcp-listen:9999,reuseaddr stdout 2>/tmp/netcat.log | mbstream -x -C /var/lib/mysql## Następnie na docelowym urządzeniu głównym, tj. jednym z węzłów w twoim klastrze Galera (który w tym przykładzie jest węzłem 172.31.28.175), uruchom to na terminalu,
$ mariabackup --backup --target-dir=/tmp --stream=xbstream | socat - TCP4:172.32.31.2:9999gdzie 172.32.31.2 to adres IP węzła gotowości hosta.
Krok czwarty
Przygotuj plik konfiguracyjny MySQL. Ponieważ jest to w Ubuntu, edytuję plik w /etc/mysql/my.cnf i za pomocą następującego przykładu my.cnf pobranego z naszego szablonu ClusterControl,
[MYSQLD]
user=mysql
basedir=/usr/
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
pid_file=/var/lib/mysql/mysql.pid
port=3306
log_error=/var/log/mysql/mysqld.log
log_warnings=2
# log_output = FILE
#Slow logging
slow_query_log_file=/var/log/mysql/mysql-slow.log
long_query_time=2
slow_query_log=OFF
log_queries_not_using_indexes=OFF
### INNODB OPTIONS
innodb_buffer_pool_size=245M
innodb_flush_log_at_trx_commit=2
innodb_file_per_table=1
innodb_data_file_path = ibdata1:100M:autoextend
## You may want to tune the below depending on number of cores and disk sub
innodb_read_io_threads=4
innodb_write_io_threads=4
innodb_doublewrite=1
innodb_log_file_size=64M
innodb_log_buffer_size=16M
innodb_buffer_pool_instances=1
innodb_log_files_in_group=2
innodb_thread_concurrency=0
# innodb_file_format = barracuda
innodb_flush_method = O_DIRECT
innodb_rollback_on_timeout=ON
# innodb_locks_unsafe_for_binlog = 1
innodb_autoinc_lock_mode=2
## avoid statistics update when doing e.g show tables
innodb_stats_on_metadata=0
default_storage_engine=innodb
# CHARACTER SET
# collation_server = utf8_unicode_ci
# init_connect = 'SET NAMES utf8'
# character_set_server = utf8
# REPLICATION SPECIFIC
server_id=1002
binlog_format=ROW
log_bin=binlog
log_slave_updates=1
relay_log=relay-bin
expire_logs_days=7
read_only=ON
report_host=172.31.29.72
gtid_ignore_duplicates=ON
gtid_strict_mode=ON
# OTHER THINGS, BUFFERS ETC
key_buffer_size = 24M
tmp_table_size = 64M
max_heap_table_size = 64M
max_allowed_packet = 512M
# sort_buffer_size = 256K
# read_buffer_size = 256K
# read_rnd_buffer_size = 512K
# myisam_sort_buffer_size = 8M
skip_name_resolve
memlock=0
sysdate_is_now=1
max_connections=500
thread_cache_size=512
query_cache_type = 0
query_cache_size = 0
table_open_cache=1024
lower_case_table_names=0
# 5.6 backwards compatibility (FIXME)
# explicit_defaults_for_timestamp = 1
performance_schema = OFF
performance-schema-max-mutex-classes = 0
performance-schema-max-mutex-instances = 0
[MYSQL]
socket=/var/lib/mysql/mysql.sock
# default_character_set = utf8
[client]
socket=/var/lib/mysql/mysql.sock
# default_character_set = utf8
[mysqldump]
socket=/var/lib/mysql/mysql.sock
max_allowed_packet = 512M
# default_character_set = utf8
[xtrabackup]
[MYSQLD_SAFE]
# log_error = /var/log/mysqld.log
basedir=/usr/
# datadir = /var/lib/mysqlOczywiście możesz to zmienić zgodnie z konfiguracją i wymaganiami.
Krok piąty
Przygotuj kopię zapasową z kroku 3, tj. końcową kopię zapasową, która znajduje się teraz w węźle gorącej gotowości, uruchamiając poniższe polecenie,
$ mariabackup --prepare --target-dir=/var/lib/mysqlKrok szósty
Ustaw własność katalogu datadir w węźle gorącej gotowości,
$ chown -R mysql.mysql /var/lib/mysqlKrok siódmy
Teraz uruchom instancję MariaDB
$ systemctl start mariadbKrok ósmy
Na koniec musimy skonfigurować replikację asynchroniczną,
## Utwórz użytkownika replikacji w węźle głównym, tj. węźle w klastrze Galera
MariaDB [(none)]> CREATE USER 'cmon_replication'@'172.32.31.2' IDENTIFIED BY 'PahqTuS1uRIWYKIN';
Query OK, 0 rows affected (0.866 sec)
MariaDB [(none)]> GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'cmon_replication'@'172.32.31.2';
Query OK, 0 rows affected (0.127 sec)## Uzyskaj pozycję podrzędną GTID z xtrabackup_binlog_info w następujący sposób,
$ cat /var/lib/mysql/xtrabackup_binlog_info
binlog.000002 71131632 1000-1000-120454## Następnie skonfiguruj replikację podrzędną w następujący sposób,
MariaDB [(none)]> SET GLOBAL gtid_slave_pos='1000-1000-120454';
Query OK, 0 rows affected (0.053 sec)
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='172.31.28.175', MASTER_USER='cmon_replication', master_password='PahqTuS1uRIWYKIN', MASTER_USE_GTID = slave_pos;## Teraz sprawdź status urządzenia podrzędnego,
MariaDB [(none)]> show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.31.28.175
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 60
Master_Log_File:
Read_Master_Log_Pos: 4
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 4
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-120454
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)Dodawanie węzła Hot Standby do ClusterControl
Jeśli używasz ClusterControl, monitorowanie stanu serwera bazy danych jest łatwe. Aby dodać to jako urządzenie podrzędne, wybierz klaster węzłów Galera, a następnie przejdź do przycisku wyboru, jak pokazano poniżej, aby dodać urządzenie podrzędne replikacji:
Kliknij Dodaj podrzędną replikację i wybierz dodawanie istniejącego podrzędnego, tak jak poniżej,
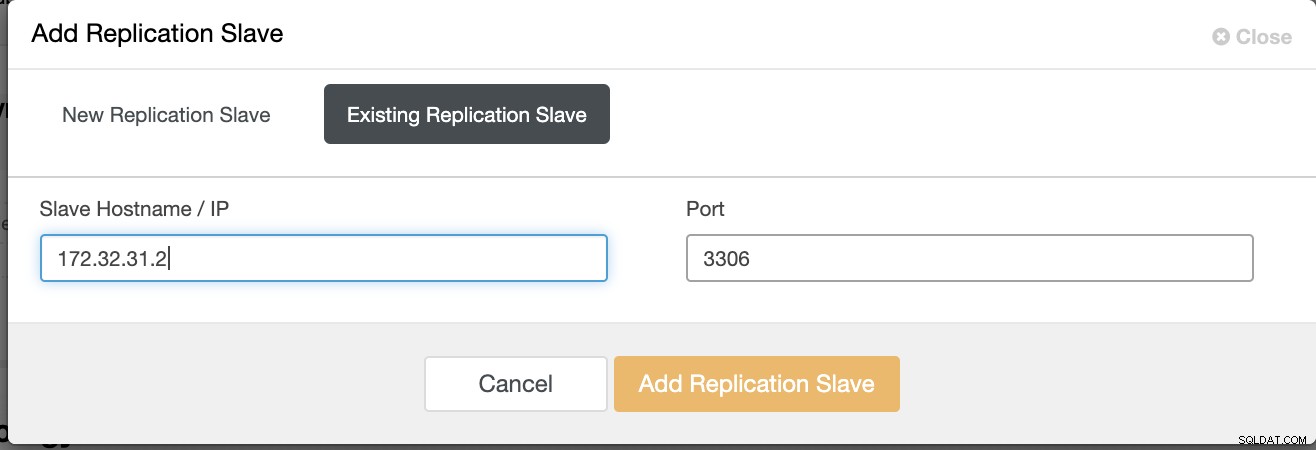
Nasza topologia wygląda obiecująco.
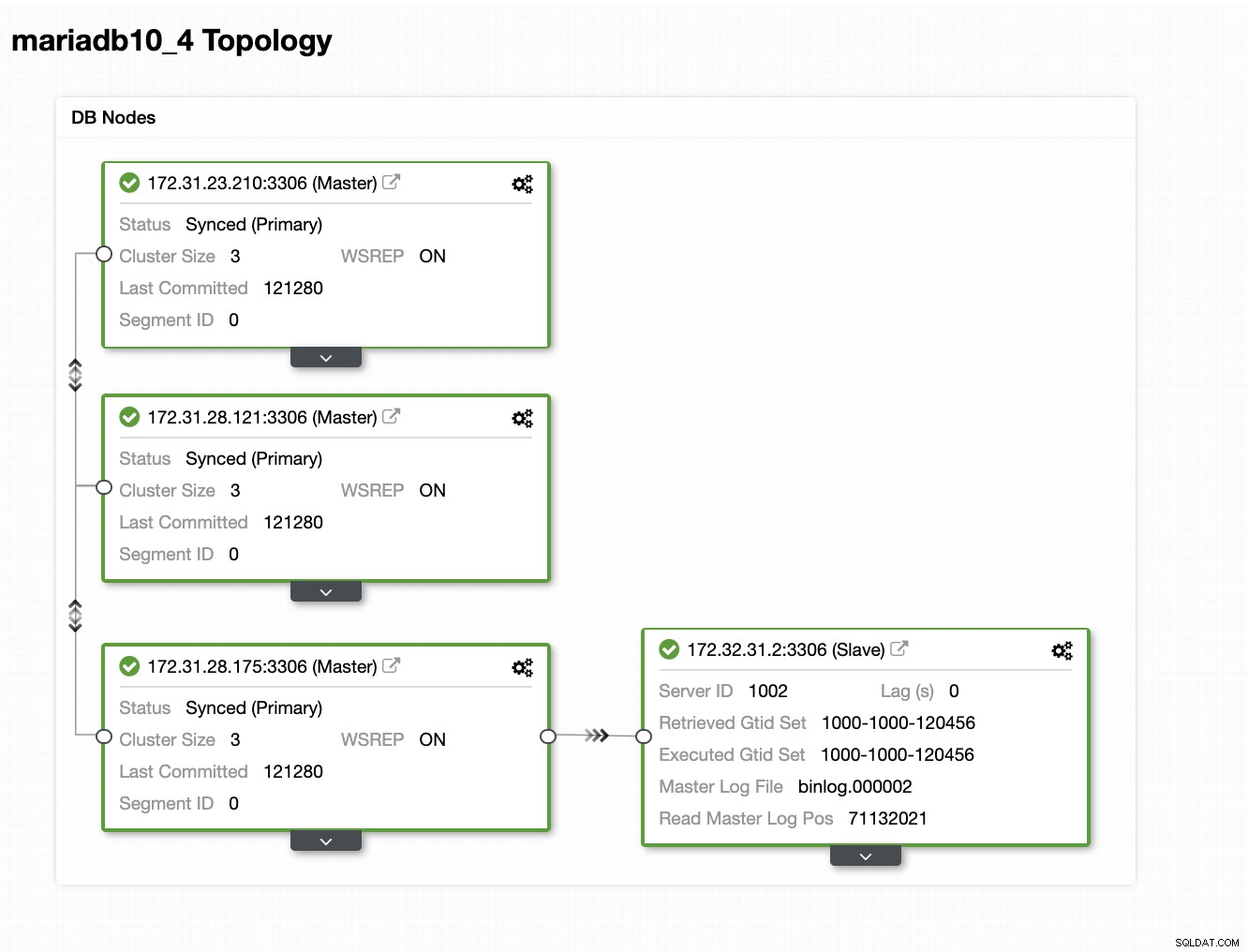
Jak można zauważyć, nasz węzeł 172.32.31.2 służy jako nasz hot standby węzeł ma inny CIDR, który ma prefiksy 172.32.% us-west-2 (Oregon), podczas gdy inne węzły mają 172.31.% zlokalizowane na us-east-2 (Ohio). Znajdują się one całkowicie w innym regionie, więc w przypadku awarii sieci w węzłach Galera można przełączyć się awaryjnie na węzeł gotowości.
Wnioski
Budowanie Hot Standby w Amazon AWS jest łatwe i proste. Wszystko, czego potrzebujesz, to określenie wymagań dotyczących pojemności oraz topologii sieci, zabezpieczeń i protokołów, które należy skonfigurować.
Korzystanie z VPC Peering pomaga przyspieszyć komunikację wewnętrzną między różnymi regionami bez korzystania z publicznego Internetu, dzięki czemu połączenie pozostaje w infrastrukturze sieci Amazon.
Używanie replikacji asynchronicznej z jednym urządzeniem podrzędnym to oczywiście za mało, ale ten blog służy jako podstawa, w jaki sposób można to zainicjować. Możesz teraz łatwo utworzyć kolejny klaster, w którym replikuje się asynchroniczne urządzenie podrzędne i utworzyć kolejną serię klastrów Galera służących jako węzły odzyskiwania po awarii lub możesz również użyć zmiennej gmcast.segment w Galera, aby replikować synchronicznie, tak jak mamy na tym blogu.