W poprzedniej części testowaliśmy czas tworzenia kopii zapasowych i skuteczność kompresji dla różnych poziomów i metod kompresji kopii zapasowych. Na tym blogu będziemy kontynuować nasze wysiłki i porozmawiamy o kolejnych ustawieniach, których prawdopodobnie większość użytkowników tak naprawdę nie zmienia, ale mogą mieć widoczny wpływ na proces tworzenia kopii zapasowej.
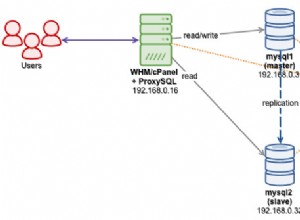
Konfiguracja jest taka sama jak w poprzedniej części:użyjemy klastra replikacji MariaDB master-slave z ProxySQL i Keepalived.
Wygenerowaliśmy 7,6 GB danych za pomocą sysbench:
sysbench /root/sysbench/src/lua/oltp_read_write.lua --threads=4 --mysql-host=10.0.0.111 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=6033 --tables=32 --table-size=1000000 prepareKorzystanie z PIGZ
Tym razem włączymy opcję Użyj PIGZ do równoległego gzip dla naszych kopii zapasowych. Tak jak poprzednio, przetestujemy każdy poziom kompresji, aby zobaczyć, jak działa.
Przechowujemy kopię zapasową lokalnie na instancji, dla której skonfigurowana jest instancja 4 procesory wirtualne.
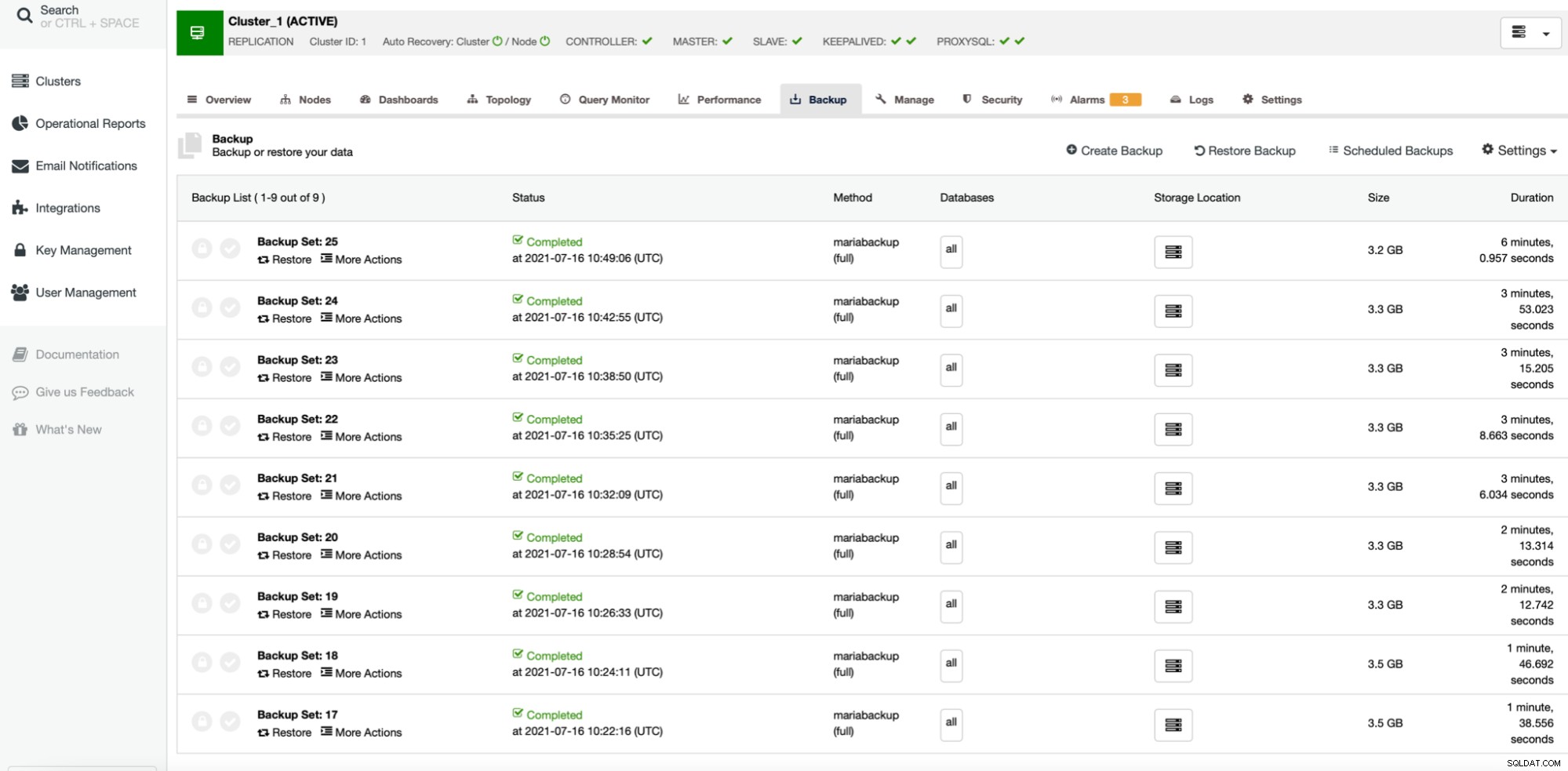
Wynik jest oczekiwany. Proces tworzenia kopii zapasowej był znacznie szybszy niż wtedy, gdy używaliśmy tylko jednego rdzenia procesora. Rozmiar kopii zapasowej pozostaje prawie taki sam, nie ma prawdziwego powodu, aby miał się znacząco zmienić. Oczywiste jest, że użycie pigz poprawia czas podtrzymania. Istnieje jednak ciemna strona używania równoległego gzip, a jest to wykorzystanie procesora:
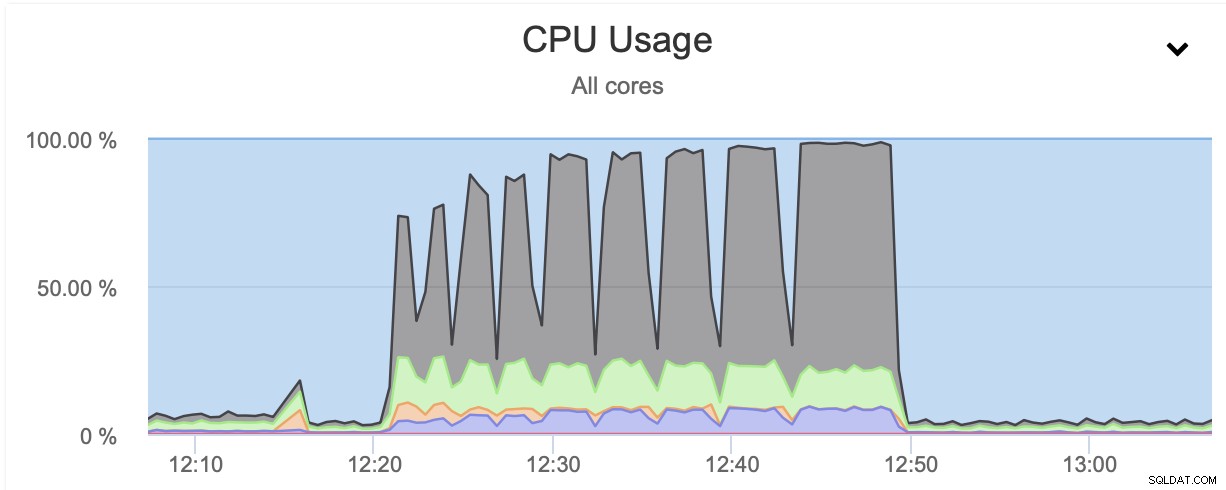
Jak widać, wykorzystanie procesora gwałtownie rośnie i sięga prawie 100% dla wyższych poziomów kompresji. Zwiększenie wykorzystania procesora na serwerze bazy danych niekoniecznie jest najlepszym pomysłem, ponieważ zazwyczaj chcemy, aby procesor był dostępny dla bazy danych. Z drugiej strony, jeśli mamy replikę dedykowaną do robienia kopii zapasowych i powiedzmy cięższe zapytania - węzeł, który nie jest wykorzystywany do obsługi ruchu typu OLTP, możemy włączyć równoległy gzip, aby znacznie zmniejszyć kopię zapasową czas. Jak widać, nie jest to opcja dla wszystkich, ale z pewnością jest to coś, co może się przydać w niektórych konkretnych scenariuszach. Pamiętaj tylko, że wykorzystanie procesora jest czymś, co musisz śledzić, ponieważ wpłynie ono na opóźnienia zapytań, a przez to wpłynie na wrażenia użytkownika - coś, co zawsze powinniśmy brać pod uwagę podczas pracy z bazami danych.
Wątki kopiowania równoległego Xtrabackup
Innym ustawieniem, które chcemy podkreślić, jest Xtrabackup Parallel Copy Threads. Aby zrozumieć, co to jest, porozmawiajmy trochę o sposobie działania Xtrabackup (lub MariaBackup). Krótko mówiąc, narzędzia te wykonują jednocześnie dwie czynności. Kopiują dane, pliki fizyczne, z serwera bazy danych do lokalizacji kopii zapasowej, jednocześnie monitorując logi przeróbek InnoDB pod kątem wszelkich aktualizacji. Kopia zapasowa składa się z plików i zapisu wszystkich zmian w InnoDB, które nastąpiły podczas procesu tworzenia kopii zapasowej. To, dzięki blokadom kopii zapasowych lub FLUSH TABLES WITH READ LOCK, umożliwia tworzenie kopii zapasowej spójnej w momencie zakończenia przesyłania danych. Xtrabackup Parallel Copy Threads definiują liczbę wątków, które wykonają transfer danych. Jeśli ustawimy ją na 1, jeden plik zostanie skopiowany w tym samym czasie. Jeśli ustawimy na 8, teoretycznie można przesłać do 8 plików na raz. Oczywiście musi być wystarczająco dużo miejsca na przechowywanie, aby rzeczywiście skorzystać z takiego ustawienia. Przeprowadzimy kilka testów, zmieniając wątki kopiowania równoległego Xtrabackup z 1 przez 2 i 4 na 8. Przeprowadzimy testy na poziomie kompresji 6 (domyślnie) z włączonym równoległym gzip i bez niego.
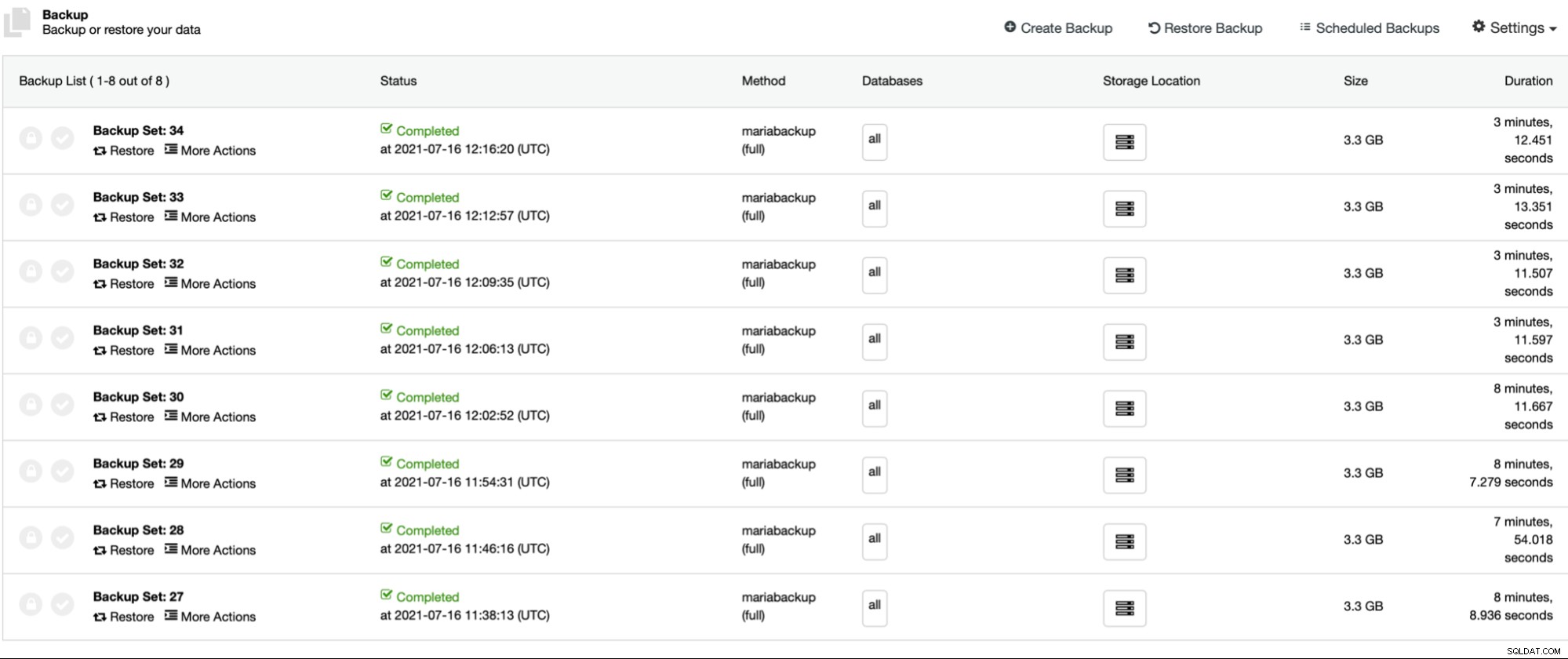
Pierwsze cztery kopie zapasowe (27 - 30) zostały utworzone bez równoległego gzip, zaczynając od 1 do 2, 4 i 8 równoległych wątków kopiowania. Następnie powtórzyliśmy ten sam proces dla kopii zapasowych 31 do 34, tym razem używając równoległego gzip. Jak widać, w naszym przypadku nie ma prawie żadnej różnicy między wątkami kopiowania równoległego. Najprawdopodobniej będzie to miało większy wpływ, jeśli zwiększymy rozmiar zestawu danych. Poprawiłoby to również wydajność tworzenia kopii zapasowych, gdybyśmy używali szybszego i bardziej niezawodnego magazynu. Jak zwykle Twój przebieg będzie się różnić i w różnych środowiskach to ustawienie może wpłynąć na proces tworzenia kopii zapasowej bardziej niż to, co widzimy tutaj.
Ograniczanie przepustowości sieci
Na koniec, w tej części naszej krótkiej serii chcielibyśmy porozmawiać o możliwości ograniczania użycia sieci.
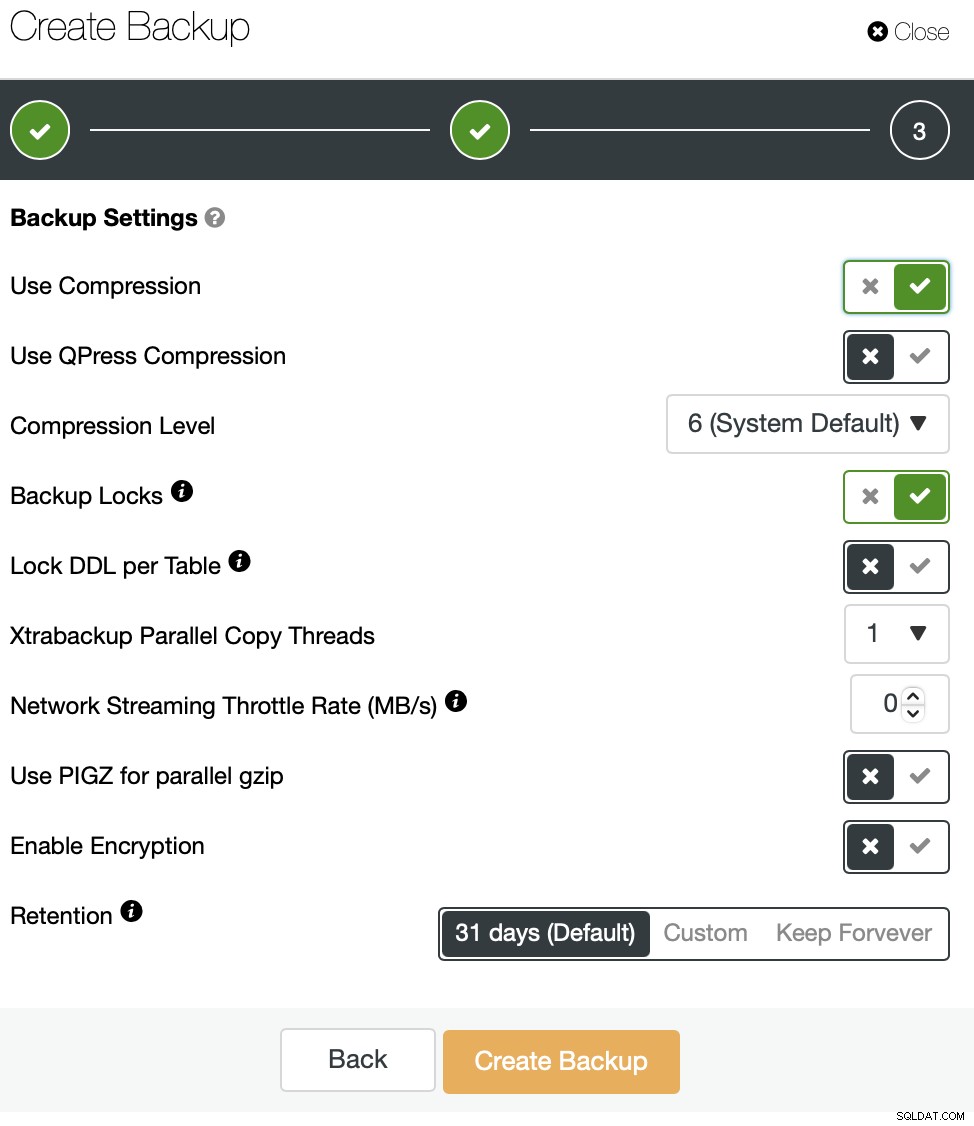
Jak widać, kopie zapasowe mogą być przechowywane lokalnie w węźle lub może być również przesyłany strumieniowo do hosta kontrolera. Dzieje się to przez sieć i domyślnie zostanie to zrobione „tak szybko, jak to możliwe”.
W niektórych przypadkach, gdy przepustowość sieci jest ograniczona (na przykład wystąpienia chmury), można zmniejszyć użycie sieci spowodowane przez MariaBackup, ustawiając limit transferu sieciowego. Gdy to zrobisz, ClusterControl użyje narzędzia „pv”, aby ograniczyć przepustowość dostępną dla procesu.
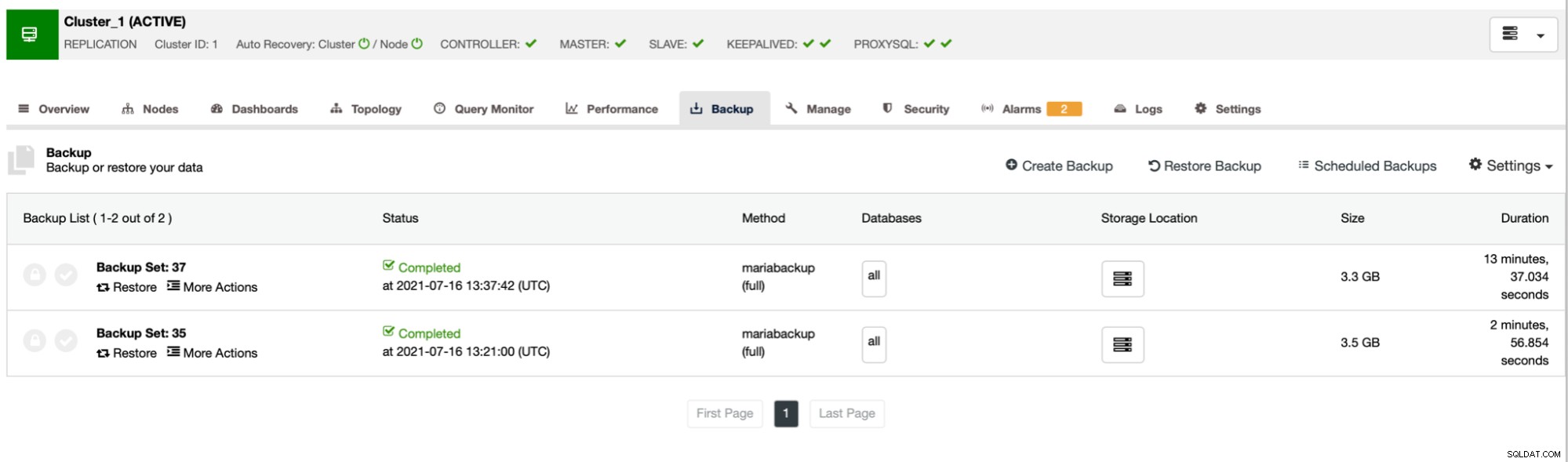
Jak widać, pierwsza kopia zapasowa trwała około 3 minut, ale kiedy ograniczyło przepustowość sieci, tworzenie kopii zapasowej trwało 13 minut i 37 sekund.
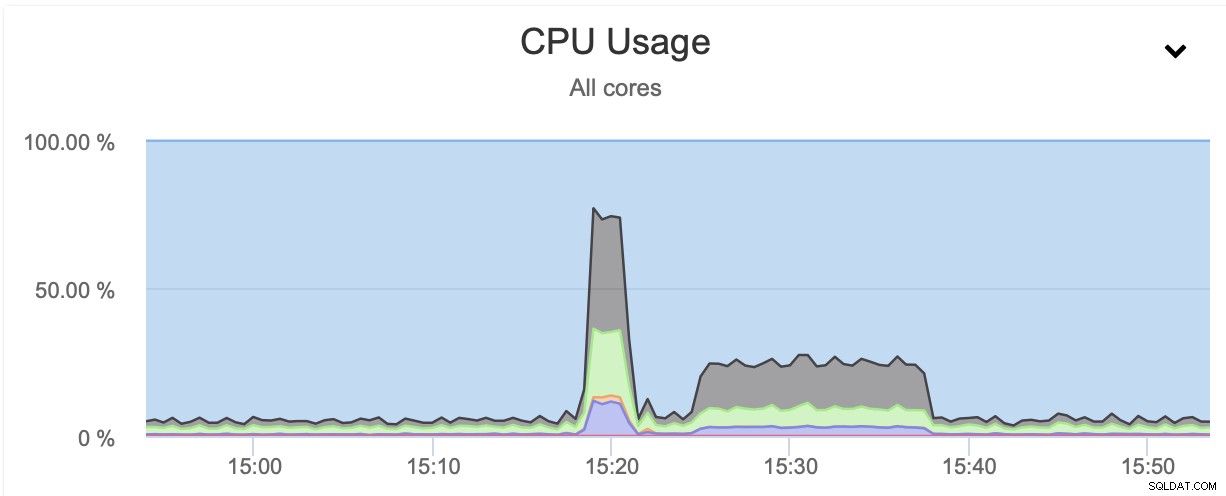
W obu przypadkach użyliśmy pigz i stopnia kompresji 1. Powyższy wykres pokazuje, że dławienie sieci również zmniejszyło wykorzystanie procesora. Ma to sens, jeśli Pigz musi czekać na przesłanie danych przez sieć, nie musi mocno naciskać na procesor, ponieważ przez większość czasu jest bezczynny.
Mam nadzieję, że ten krótki blog był dla Ciebie interesujący i może zachęci Cię do eksperymentowania z niektórymi niezbyt często używanymi funkcjami i opcjami MariaBackup. Jeśli chcesz podzielić się swoimi doświadczeniami, chcielibyśmy usłyszeć od Ciebie w komentarzach poniżej.