Jeśli zarządzasz produkcyjną bazą danych, istnieje duże prawdopodobieństwo, że musiałeś sklonować bazę danych na inny serwer niż serwer produkcyjny. Podstawową metodą tworzenia klonu jest przywrócenie bazy danych z ostatniej kopii zapasowej na inny serwer bazy danych. Inną metodą jest replikacja ze źródłowej bazy danych, gdy jest jeszcze uruchomiona, w takim przypadku ważne jest, aby oryginalna baza danych nie została naruszona żadna procedura klonowania.
Dlaczego trzeba klonować bazę danych?
Klonowany klaster bazy danych jest przydatny w wielu scenariuszach:
- Rozwiąż problemy ze sklonowanym klastrem produkcyjnym w bezpiecznym środowisku testowym podczas wykonywania destrukcyjnych operacji na bazie danych.
- Test poprawek/aktualizacji sklonowanej bazy danych w celu weryfikacji procesu aktualizacji przed zastosowaniem jej do klastra produkcyjnego.
- Zweryfikuj tworzenie kopii zapasowych i odzyskiwanie klastra produkcyjnego przy użyciu sklonowanego klastra.
- Zweryfikuj lub przetestuj nowe aplikacje w sklonowanym klastrze produkcyjnym przed wdrożeniem ich w aktywnym klastrze produkcyjnym.
- Szybko sklonuj bazę danych pod kątem wymogów audytu lub zgodności informacji, na przykład do końca kwartału lub roku, kiedy zawartość bazy danych nie może być zmieniana.
- Baza danych raportowania może być tworzona w odstępach czasu, aby uniknąć zmian danych podczas generowania raportu.
- Przeprowadź migrację bazy danych na nowe serwery, nowe środowisko wdrażania lub nowe centrum danych.
Podczas uruchamiania infrastruktury bazy danych w chmurze koszt posiadania hosta (udostępnionej lub dedykowanej maszyny wirtualnej) jest znacznie niższy w porównaniu z tradycyjnym sposobem wynajmu powierzchni w centrum danych lub posiadania fizycznego serwera. Co więcej, większość wdrożeń w chmurze można łatwo zautomatyzować za pomocą interfejsów API dostawcy, oprogramowania klienckiego i skryptów. Dlatego klonowanie klastra może być powszechnym sposobem na zduplikowanie środowiska wdrażania, na przykład z poziomu deweloperskiego, tymczasowego, produkcyjnego lub odwrotnie.
Nie widzieliśmy tej funkcji oferowanej przez nikogo na rynku, dlatego mamy zaszczyt pokazać, jak działa z ClusterControl.
Klonowanie klastra MySQL Galera
Jedną z fajnych funkcji ClusterControl jest możliwość szybkiego klonowania istniejącego klastra MySQL Galera, dzięki czemu masz dokładną kopię zestawu danych w innym klastrze. ClusterControl wykonuje operację klonowania online, bez blokowania lub przestoju istniejącego klastra. Przypomina to operację skalowania klastra w poziomie, z wyjątkiem tego, że oba klastry są od siebie niezależne po zakończeniu synchronizacji. Sklonowany klaster niekoniecznie musi mieć taki sam rozmiar klastra jak istniejący. Moglibyśmy zacząć od klastra z jednym węzłem, a później skalować go z większą liczbą węzłów bazy danych.
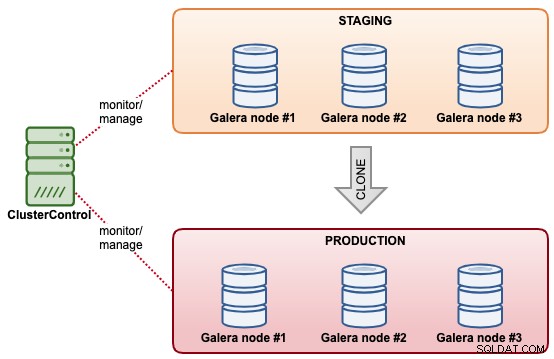
W tym przykładzie mamy klaster o nazwie „Staging”, który chcielibyśmy sklonować jako inny klaster o nazwie „Produkcja”. Założeniem jest to, że klaster pomostowy już przechowuje niezbędne dane, które wkrótce trafią do produkcji. Klaster produkcyjny składa się z kolejnych 3 węzłów ze specyfikacjami produkcyjnymi.
Poniższy diagram podsumowuje ostateczną architekturę tego, co chcemy osiągnąć:
Pierwszą rzeczą do zrobienia jest skonfigurowanie bezhasłowego SSH z serwera ClusterControl na serwery produkcyjne. Na serwerze ClusterControl uruchom następujące polecenie:
$ whoami
root
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.comWprowadź hasło roota serwera docelowego, jeśli zostaniesz o to poproszony.
Na liście klastrów bazy danych ClusterControl kliknij przycisk Akcja klastra i wybierz opcję Klonuj klaster. Pojawi się następujący kreator:
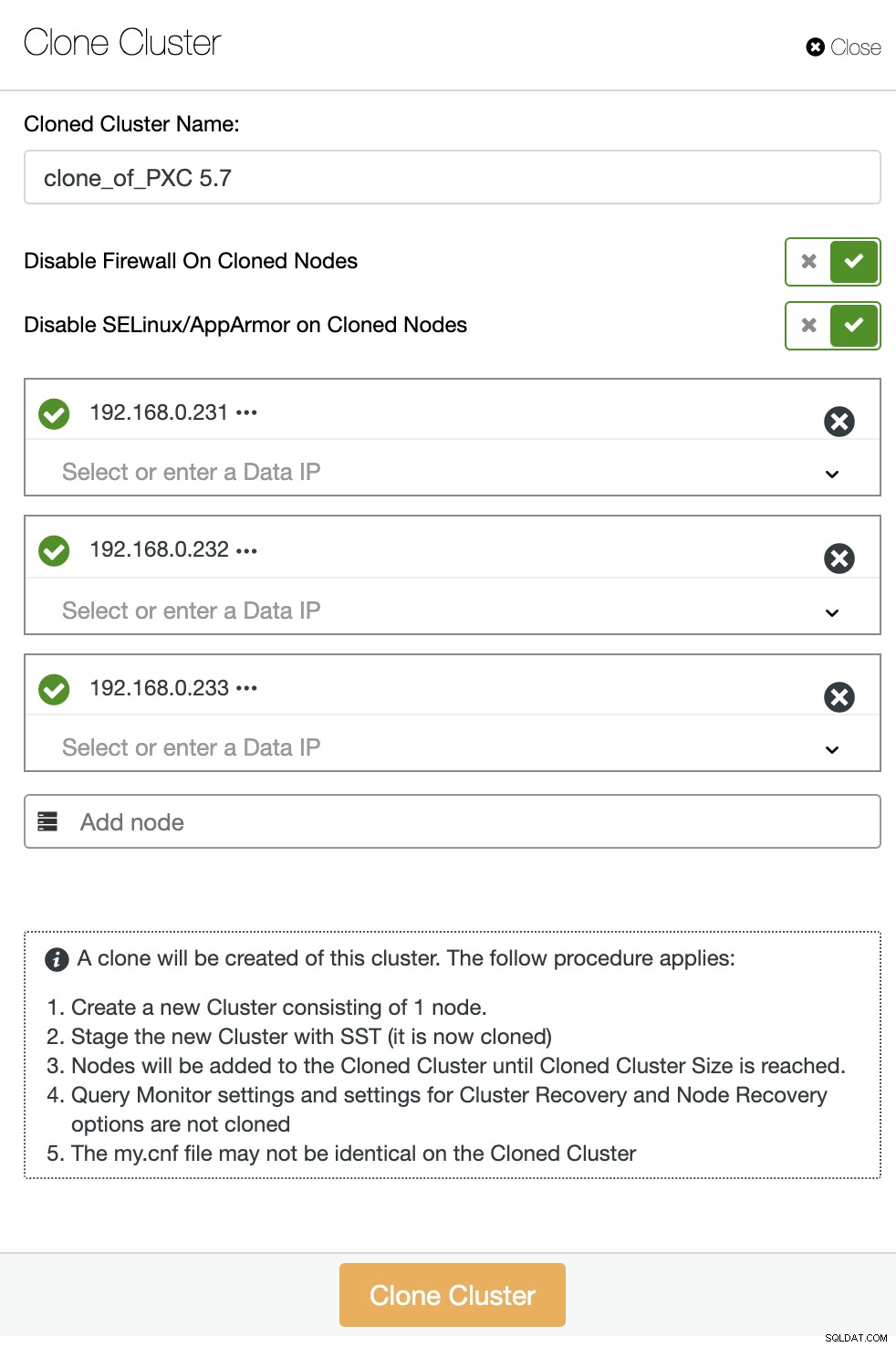
Określ adresy IP lub nazwy hostów nowego klastra i upewnij się, że otrzymujesz wszystkie zielone ikony zaznaczenia obok określonego hosta. Zielona ikona oznacza, że ClusterControl może połączyć się z hostem przez SSH bez hasła. Kliknij przycisk „Klonuj klaster”, aby rozpocząć wdrażanie.
Kroki wdrażania to:
- Utwórz nowy klaster składa się z jednego węzła.
- Zsynchronizuj nowy jednowęzłowy klaster przez SST. Dawcą jest jeden z serwerów źródłowych.
- Pozostałe nowe węzły dołączą do klastra po zsynchronizowaniu dawcy sklonowanego klastra z klastrem.
Po zakończeniu nowy klaster MySQL Galera zostanie wyświetlony w panelu klastra ClusterControl po zakończeniu zadania wdrażania.
Zauważ, że klonowanie klastra klonuje tylko serwery bazy danych, a nie cały stos klastra. Oznacza to, że inne komponenty wspierające związane z klastrem, takie jak load balancery, wirtualny adres IP, arbiter Galera czy asynchroniczny slave nie będą klonowane przez ClusterControl. Niemniej jednak, jeśli chcesz sklonować jako dokładną kopię istniejącej infrastruktury bazy danych, możesz to osiągnąć dzięki ClusterControl, wdrażając te komponenty osobno po zakończeniu operacji klonowania bazy danych.
Tworzenie klastra bazy danych z kopii zapasowej
Kolejną podobną funkcją oferowaną przez ClusterControl jest „Utwórz klaster z kopii zapasowej”. Ta funkcja została wprowadzona w ClusterControl 1.7.1, specjalnie dla klastrów Galera Cluster i PostgreSQL, w których można utworzyć nowy klaster z istniejącej kopii zapasowej. W przeciwieństwie do klonowania klastra, ta operacja nie powoduje dodatkowego obciążenia klastra źródłowego, a kompromis sklonowanego klastra nie będzie w bieżącym stanie jako klaster źródłowy.
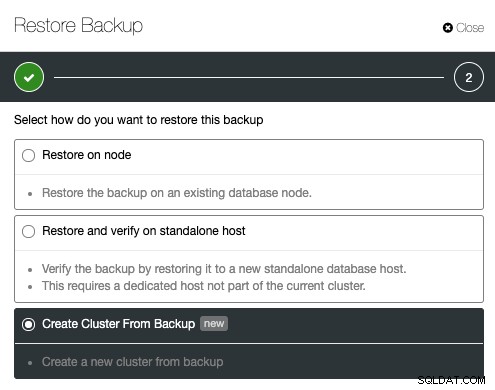
Aby utworzyć klaster z kopii zapasowej, musisz mieć utworzoną działającą kopię zapasową. W przypadku Galera Cluster obsługiwane są wszystkie metody tworzenia kopii zapasowych, podczas gdy w przypadku PostgreSQL tylko pgbackrest nie jest obsługiwany w przypadku wdrażania nowego klastra. Z ClusterControl można łatwo utworzyć lub zaplanować kopię zapasową w ClusterControl -> Kopie zapasowe -> Utwórz kopię zapasową. Z listy utworzonej kopii zapasowej kliknij Przywróć kopię zapasową, wybierz kopię zapasową z listy i wybierz „Utwórz klaster z kopii zapasowej” z opcji przywracania:
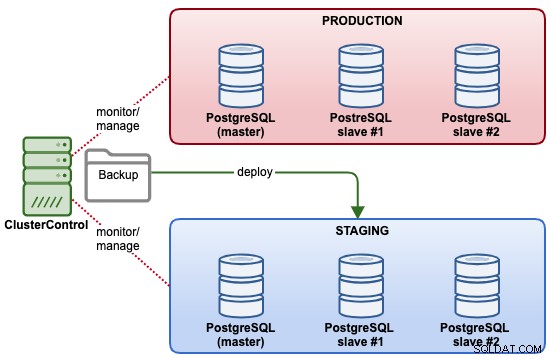
W tym przykładzie wdrożymy nowy klaster PostgreSQL Streaming Replication dla środowiska postojowego, w oparciu o istniejący backup, który posiadamy w klastrze produkcyjnym. Poniższy diagram ilustruje ostateczną architekturę:
Pierwszą rzeczą do zrobienia jest skonfigurowanie bezhasłowego SSH z serwera ClusterControl na serwery produkcyjne. Na serwerze ClusterControl uruchom następujące polecenie:
$ whoami
root
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.com
$ ssh-copy-id example@sqldat.comGdy wybierzesz opcję Utwórz klaster z kopii zapasowej, ClusterControl otworzy okno dialogowe kreatora wdrażania, które pomoże Ci skonfigurować nowy klaster:
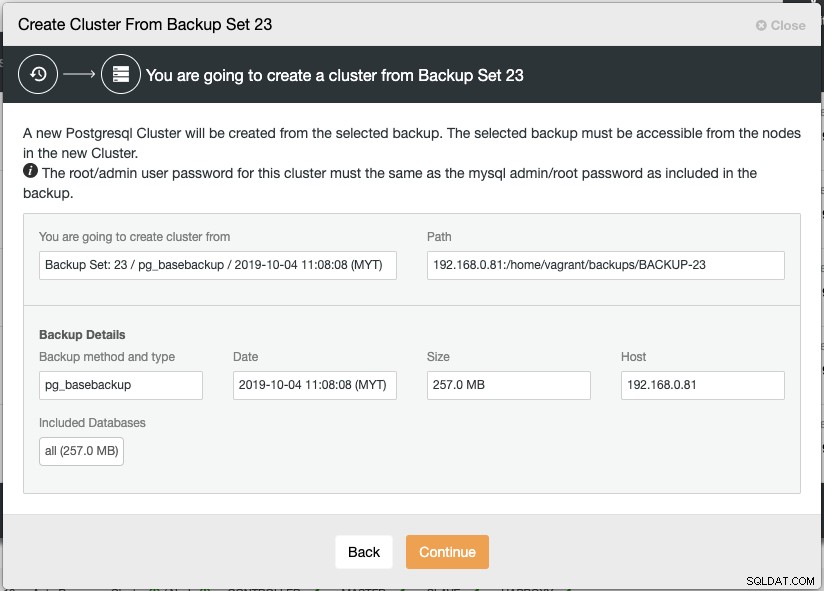
Nowa instancja PostgreSQL Streaming Replication zostanie utworzona z wybranej kopii zapasowej, będzie używany jako podstawowy zestaw danych dla nowego klastra. Wybrana kopia zapasowa musi być dostępna z węzłów w nowym klastrze lub przechowywana na hoście ClusterControl.
Kliknięcie „Kontynuuj” spowoduje otwarcie standardowego kreatora wdrażania klastra bazy danych:
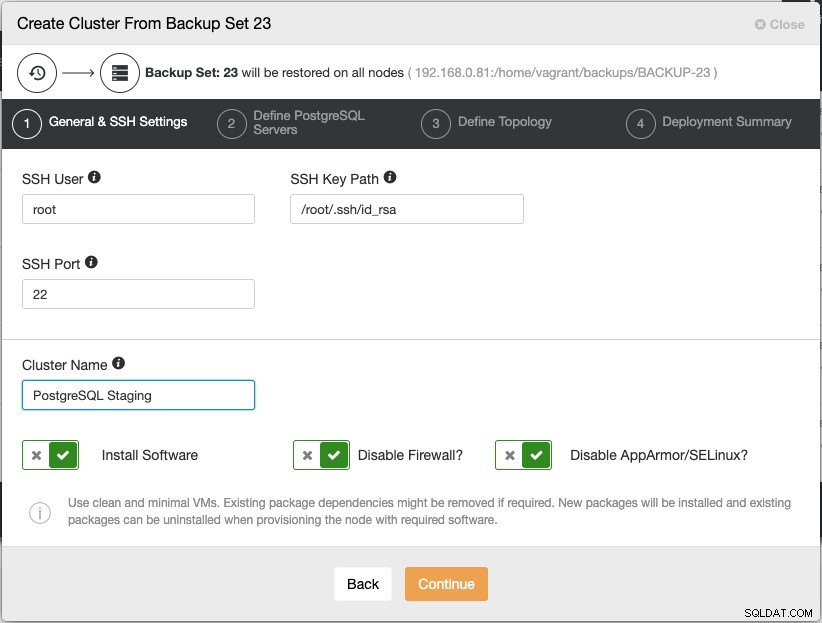
Pamiętaj, że hasło użytkownika root/administratora dla tego klastra musi być takie samo jak hasło administratora/root PostgreSQL zawarte w kopii zapasowej. Postępuj zgodnie z instrukcjami kreatora konfiguracji i ClusterControl, a następnie wykonaj instalację w następującej kolejności:
- Zainstaluj niezbędne oprogramowanie i zależności na wszystkich węzłach PostgreSQL.
- Uruchom pierwszy węzeł.
- Przesyłaj strumieniowo i przywracaj kopię zapasową w pierwszym węźle.
- Skonfiguruj i dodaj resztę węzłów.
Po zakończeniu nowy klaster replikacji PostgreSQL zostanie wyświetlony w panelu klastra ClusterControl po zakończeniu zadania wdrażania.