Dość często zdarza się, że bazy danych są rozmieszczone w wielu lokalizacjach geograficznych. Jednym ze scenariuszy wykonania tego typu konfiguracji jest odzyskiwanie po awarii, w którym rezerwowe centrum danych znajduje się w innej lokalizacji niż główne centrum danych. Równie dobrze może być wymagane, aby bazy danych znajdowały się bliżej użytkowników.
Głównym wyzwaniem w osiągnięciu tej konfiguracji jest zaprojektowanie bazy danych w sposób, który zmniejsza ryzyko problemów związanych z partycjonowaniem sieci. Jednym z rozwiązań może być użycie Galera Cluster zamiast zwykłej replikacji asynchronicznej (lub półsynchronicznej). Na tym blogu omówimy zalety i wady tego podejścia. To pierwsza część serii dwóch blogów. W drugiej części zaprojektujemy rozproszony geograficznie klaster Galera i zobaczymy, jak ClusterControl może pomóc nam wdrożyć takie środowisko.
Dlaczego klaster Galera zamiast asynchronicznej replikacji w klastrach rozproszonych geograficznie?
Rozważmy główne różnice między Galerą a zwykłą replikacją. Zwykła replikacja zapewnia tylko jeden węzeł do zapisu, co oznacza, że każdy zapis ze zdalnego centrum danych musiałby zostać wysłany przez sieć rozległą (WAN), aby dotrzeć do mastera. Oznacza to również, że wszystkie serwery proxy znajdujące się w zdalnym centrum danych będą musiały monitorować całą topologię, obejmującą wszystkie zaangażowane centra danych, ponieważ muszą być w stanie stwierdzić, który węzeł jest aktualnie nadrzędnym.
To prowadzi do wielu problemów. Po pierwsze, w sieci WAN należy nawiązać wiele połączeń, co zwiększa opóźnienia i spowalnia wszelkie kontrole, które mogą być uruchomione przez serwer proxy. Ponadto zwiększa to niepotrzebne obciążenie serwerów proxy i baz danych. W większości przypadków interesuje Cię tylko kierowanie ruchu do lokalnych węzłów bazy danych. Jedynym wyjątkiem jest master i tylko z tego powodu serwery proxy zmuszone są do nadzorowania całej infrastruktury, a nie tylko części znajdującej się w lokalnym centrum danych. Oczywiście możesz spróbować przezwyciężyć ten problem, używając serwerów proxy do trasowania tylko SELECTów, jednocześnie używając innej metody (dedykowana nazwa hosta dla mastera zarządzanego przez DNS) w celu wskazania aplikacji do mastera, ale to dodaje niepotrzebne poziomy złożoności i przenoszenia części, co może poważnie wpłynąć na zdolność obsługi wielu awarii węzłów i sieci bez utraty spójności danych.
Galera Cluster może obsługiwać wielu pisarzy. Opóźnienie jest również istotnym czynnikiem, ponieważ wszystkie węzły w klastrze Galera muszą koordynować i komunikować się w celu certyfikacji zestawów zapisu. Może to być nawet powód, dla którego możesz zrezygnować z używania Galery, gdy opóźnienie jest zbyt duże. Jest to również problem w klastrach replikacji — w klastrach replikacji opóźnienie wpływa tylko na zapisy ze zdalnych centrów danych, podczas gdy połączenia z centrum danych, w którym znajduje się master, skorzystałyby z zatwierdzeń o niskim opóźnieniu.
W MySQL Replication musisz również wziąć pod uwagę najgorszy scenariusz i upewnić się, że aplikacja jest w porządku z opóźnionymi zapisami. Master zawsze może się zmienić i nie możesz być pewien, że przez cały czas będziesz pisać do lokalnego węzła.
Kolejną różnicą między replikacją a klastrem Galera jest obsługa opóźnienia replikacji. Klastry rozproszone geograficznie mogą być poważnie dotknięte opóźnieniami:opóźnieniami, ograniczoną przepustowością połączenia WAN — wszystko to wpłynie na zdolność replikowanego klastra do nadążania za replikacją. Należy pamiętać, że replikacja generuje jeden do całego ruchu.
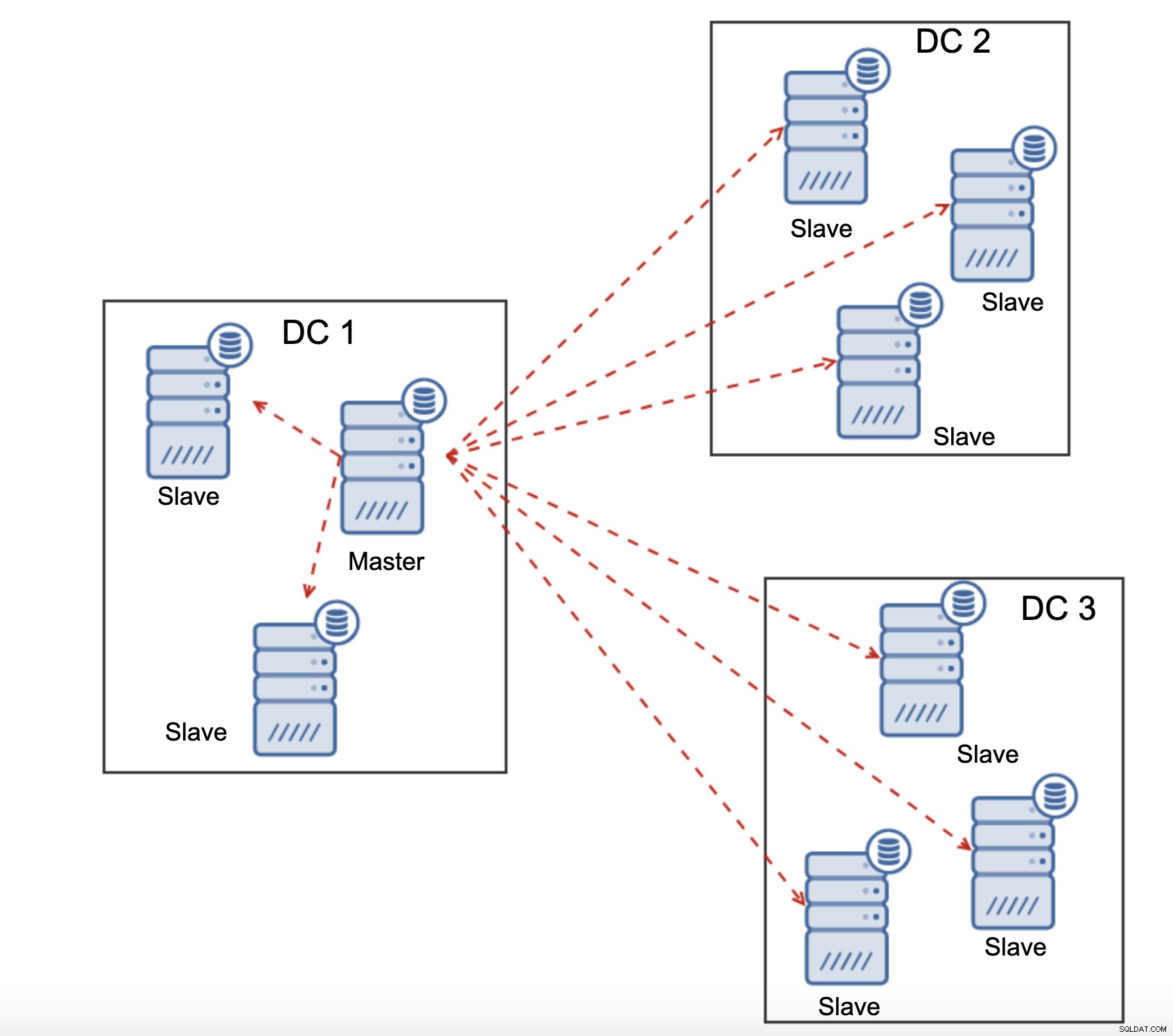
Wszystkie urządzenia slave muszą odbierać cały ruch replikacji - ilość danych, które masz wysyłanie do zdalnych urządzeń podrzędnych przez sieć WAN zwiększa się z każdym dodanym zdalnym urządzeniem podrzędnym. Może to łatwo spowodować nasycenie łącza WAN, zwłaszcza jeśli wykonasz wiele modyfikacji, a łącze WAN nie ma dobrej przepustowości. Jak widać na powyższym schemacie, z trzema centrami danych i trzema węzłami w każdym z nich, master musi wysyłać sześciokrotnie więcej ruchu replikacyjnego przez połączenie WAN.
W przypadku klastra Galera sytuacja wygląda nieco inaczej. Na początek Galera używa kontroli przepływu, aby zsynchronizować węzły. Jeśli jeden z węzłów zacznie pozostawać w tyle, może poprosić resztę klastra o spowolnienie i pozwolić mu nadrobić zaległości. Oczywiście, zmniejsza to wydajność całego klastra, ale i tak jest lepiej niż wtedy, gdy naprawdę nie można używać urządzeń podrzędnych do SELECTów, ponieważ mają one tendencję do opóźnień od czasu do czasu - w takich przypadkach wyniki, które otrzymasz, mogą być nieaktualne i nieprawidłowe.
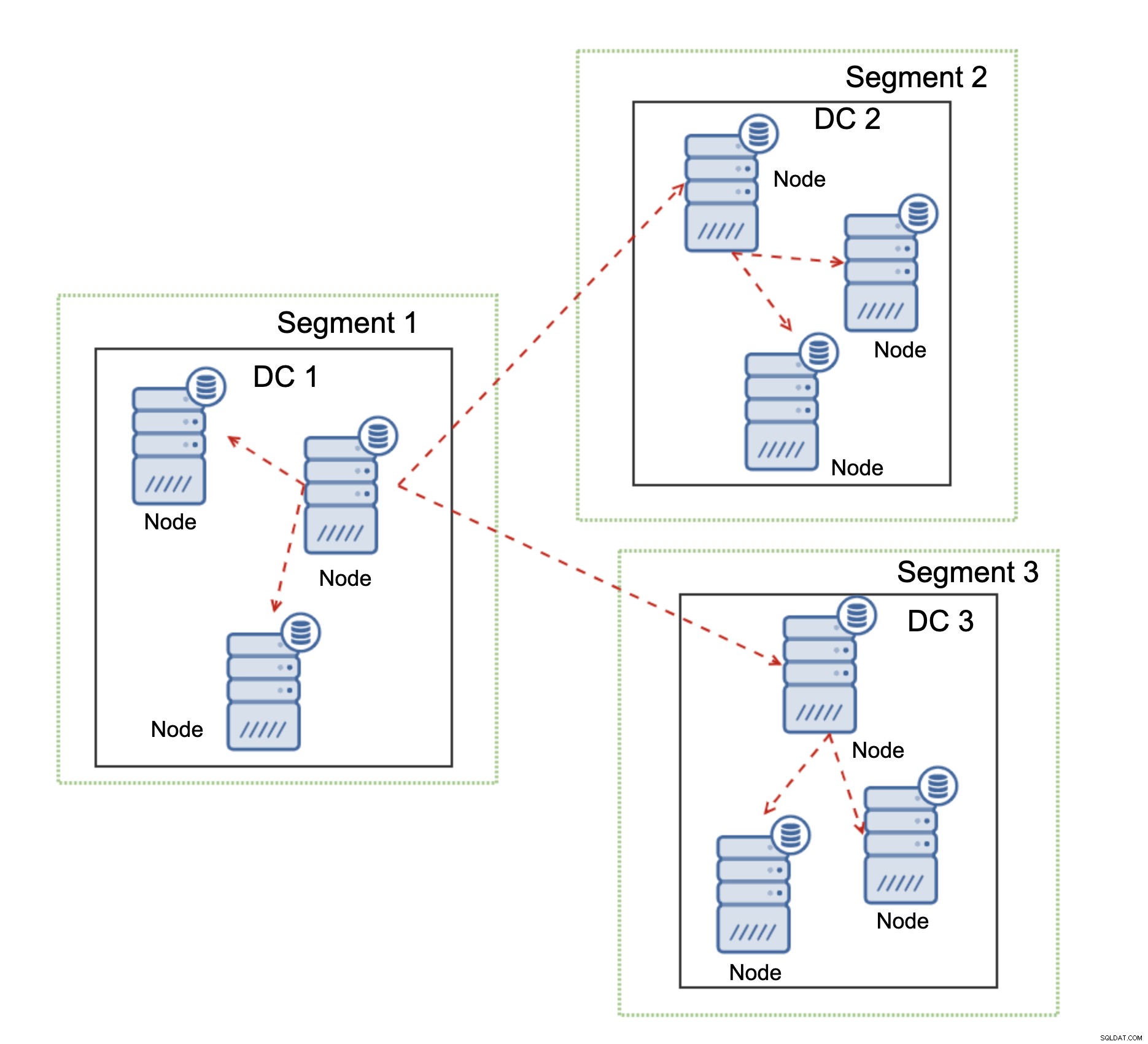
Kolejna funkcja Galera Cluster, która może znacznie poprawić jego wydajność, gdy jest używana WAN to segmenty. Domyślnie Galera używa komunikacji all to all, a każdy zestaw zapisów jest wysyłany przez węzeł do wszystkich pozostałych węzłów w klastrze. To zachowanie można zmienić za pomocą segmentów. Segmenty pozwalają użytkownikom podzielić klaster Galera na kilka części. Każdy segment może zawierać wiele węzłów i wybiera jeden z nich jako węzeł przekaźnikowy. Taki węzeł odbiera zestawy zapisów z innych segmentów i rozprowadza je w węzłach Galera lokalnych względem segmentu. W rezultacie, jak widać na powyższym diagramie, możliwe jest trzykrotne zmniejszenie ruchu replikacyjnego przechodzącego przez sieć WAN — tylko dwie „repliki” strumienia replikacji są przesyłane przez sieć WAN:jedna na centrum danych w porównaniu do jednej na urządzenie podrzędne w replikacji MySQL.
Obsługa partycjonowania sieci klastra Galera
Tym, co wyróżnia Galera Cluster, jest obsługa partycjonowania sieci. Galera Cluster stale monitoruje stan węzłów w klastrze. Każdy węzeł próbuje połączyć się ze swoimi peerami i wymienić stan klastra. Jeśli podzbiór węzłów jest nieosiągalny, Galera próbuje przekazać komunikację, więc jeśli istnieje sposób na dotarcie do tych węzłów, zostaną one osiągnięte.

Przykład można zobaczyć na powyższym schemacie:DC 1 stracił łączność z DC2, ale DC2 i DC3 mogą się łączyć. W tym przypadku jeden z węzłów w DC3 będzie używany do przekazywania danych z DC1 do DC2, zapewniając utrzymanie komunikacji wewnątrz klastra.
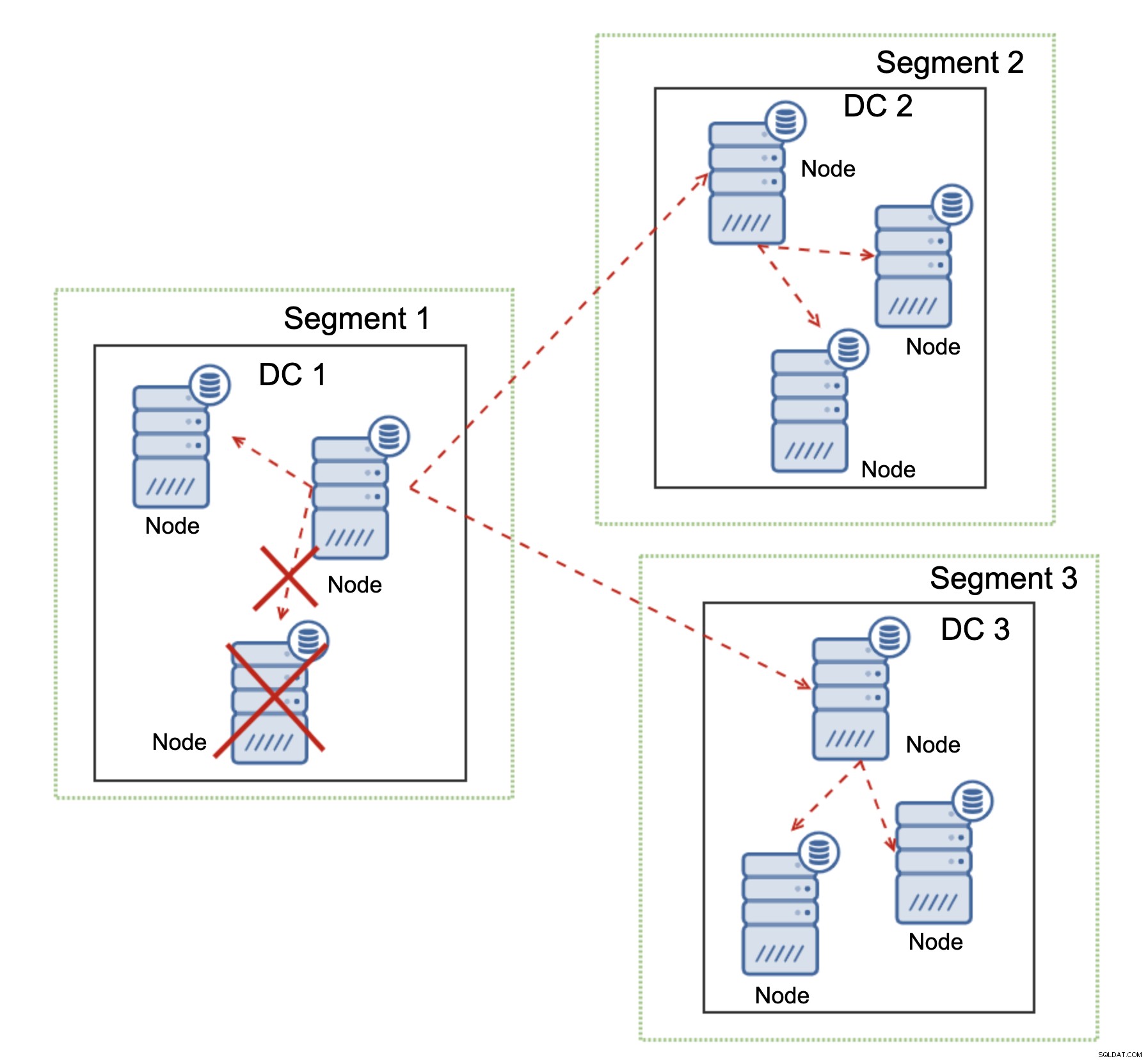
Galera Cluster może podejmować działania na podstawie stanu klastra. Implementuje kworum — większość węzłów musi być dostępna, aby klaster mógł działać. Jeśli węzeł zostanie odłączony od klastra i nie może połączyć się z żadnym innym węzłem, przestanie działać.
Jak widać na powyższym diagramie, nastąpiła częściowa utrata komunikacji sieciowej w DC1 i węzeł, którego dotyczy problem, jest usuwany z klastra, zapewniając, że aplikacja nie uzyska dostępu do nieaktualnych danych.
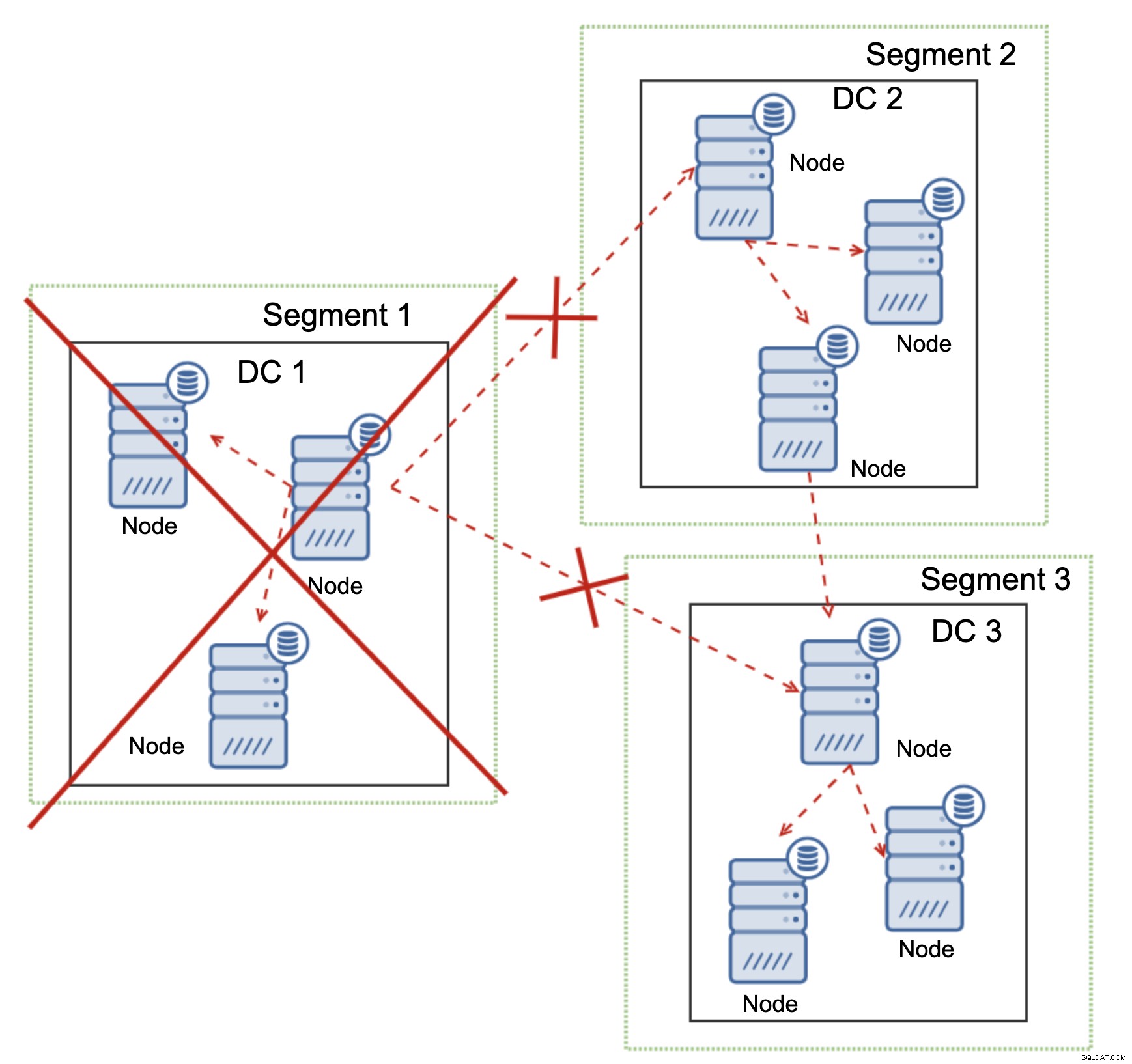
Odnosi się to również na większą skalę. DC1 został odcięty od całej komunikacji. W rezultacie całe centrum danych zostało usunięte z klastra i żaden z jego węzłów nie będzie obsługiwał ruchu. Pozostała część klastra zachowała większość (dostępnych jest 6 z 9 węzłów) i zrekonfigurowała się, aby utrzymać połączenie między DC 2 i DC3. Na powyższym diagramie założyliśmy, że zapis trafia do węzła w DC2, ale pamiętaj, że Galera może działać z wieloma programami zapisującymi.
Replikacja MySQL nie ma żadnej świadomości klastrów, co sprawia, że rozwiązywanie problemów z siecią jest problematyczne. Nie może się wyłączyć po utracie połączenia z innymi węzłami. Nie ma łatwego sposobu, aby zapobiec pojawieniu się starego mastera po rozdzieleniu sieci.
Jedyne możliwości są ograniczone do warstwy proxy lub nawet wyższej. Trzeba zaprojektować system, który będzie starał się zrozumieć stan klastra i podjąć niezbędne działania. Jednym z możliwych sposobów jest użycie narzędzi obsługujących klastry, takich jak Orchestrator, a następnie uruchomienie skryptów, które sprawdzają stan klastra Orchestrator RAFT i na podstawie tego stanu podejmują wymagane działania w warstwie bazy danych. Jest to dalekie od ideału, ponieważ każde działanie podjęte na warstwie wyższej niż baza danych powoduje dodatkowe opóźnienie:umożliwia to pojawienie się problemu i naruszenie spójności danych przed podjęciem prawidłowego działania. Z drugiej strony Galera podejmuje działania na poziomie bazy danych, zapewniając najszybszą możliwą reakcję.