Na wypadek, gdybyś go nie widział, właśnie wydaliśmy ClusterControl 1.7.5 z dużymi ulepszeniami i nowymi przydatnymi funkcjami. Niektóre funkcje obejmują Cluster Wide Maintenance, obsługę wersji CentOS 8 i Debian 10, obsługę PostgreSQL 12, obsługę MongoDB 4.2 i Percona MongoDB v4.0, a także nową ramkę MySQL Freeze Frame.
Czekaj, ale co to jest zamrożenie ramki MySQL? Czy to coś nowego w MySQL?
Cóż, nie jest to nic nowego w samym jądrze MySQL. Jest to nowa funkcja, którą dodaliśmy do ClusterControl 1.7.5, która jest specyficzna dla baz danych MySQL. MySQL Freeze Frame w ClusterControl 1.7.5 obejmuje następujące rzeczy:
- Migawka stanu MySQL przed awarią klastra.
- Lista procesów Snapshot MySQL przed awarią klastra (wkrótce).
- Sprawdzaj incydenty klastra w raportach operacyjnych lub za pomocą narzędzia wiersza poleceń s9s.
Są to cenne zestawy informacji, które mogą pomóc w śledzeniu błędów i naprawianiu klastrów MySQL/MariaDB, gdy coś pójdzie nie tak. W przyszłości planujemy również dołączyć migawki wartości statusu SHOW ENGINE InnoDB. Więc proszę, bądźcie na bieżąco z naszymi przyszłymi wydaniami.
Pamiętaj, że ta funkcja jest nadal w fazie beta, spodziewamy się, że będziemy gromadzić więcej zestawów danych podczas pracy z naszymi użytkownikami. W tym blogu pokażemy, jak wykorzystać tę funkcję, zwłaszcza gdy potrzebujesz dodatkowych informacji podczas diagnozowania klastra MySQL/MariaDB.
ClusterControl na temat obsługi awarii klastra
W przypadku awarii klastra, ClusterControl nic nie robi, chyba że automatyczne odzyskiwanie (klaster/węzeł) jest włączone, tak jak poniżej:

Po włączeniu ClusterControl spróbuje odzyskać węzeł lub klaster przez wywołanie całej topologii klastra.
Dla MySQL, na przykład w replikacji master-slave, musi mieć przynajmniej jeden master aktywny w danym momencie, niezależnie od liczby dostępnych slave/ów. ClusterControl próbuje przynajmniej raz poprawić topologię dla klastrów replikacji, ale zapewnia więcej ponownych prób replikacji z wieloma wzorcami, takich jak klaster NDB i klaster Galera. Odzyskiwanie węzła próbuje odzyskać uszkodzony węzeł bazy danych, np. kiedy proces został zabity (nienormalne zamknięcie) lub proces utracił wartość OOM (brak pamięci). ClusterControl połączy się z węzłem przez SSH i spróbuje uruchomić MySQL. Wcześniej pisaliśmy na blogu o tym, jak ClusterControl wykonuje automatyczne odzyskiwanie baz danych i przełączanie awaryjne, więc zapoznaj się z tym artykułem, aby dowiedzieć się więcej o schemacie automatycznego odzyskiwania ClusterControl.
W poprzedniej wersji ClusterControl <1.7.5 te próby przywrócenia wyzwoliły alarmy. Jednak jedną z rzeczy, których nasi klienci przegapili, był pełniejszy raport o incydentach z informacjami o stanie tuż przed awarią klastra. Dopóki nie zdaliśmy sobie sprawy z tego niedociągnięcia i dodaliśmy tę funkcję w ClusterControl 1.7.5. Nazwaliśmy to "MySQL Freeze Frame". MySQL Freeze Frame w chwili pisania tego tekstu zawiera krótkie podsumowanie incydentów prowadzących do zmian stanu klastra tuż przed awarią. Co najważniejsze, zawiera na końcu raportu listę hostów oraz ich zmiennych i wartości statusu globalnego MySQL.
W jaki sposób MySQL zamrożoną ramkę różni się od automatycznego odzyskiwania?
Frame MySQL Freeze Frame nie są częścią automatycznego odzyskiwania ClusterControl. Niezależnie od tego, czy automatyczne odzyskiwanie jest wyłączone, czy włączone, MySQL Freeze Frame zawsze wykona swoją pracę, o ile zostanie wykryta awaria klastra lub węzła.
Jak działa MySQL Freeze Frame?
W ClusterControl istnieją pewne stany, które klasyfikujemy jako różne typy statusu klastra. MySQL Freeze Frame wygeneruje raport o incydencie, gdy te dwa stany zostaną wyzwolone:
- CLUSTER_DEGRADED
- CLUSTER_FAILURE
W ClusterControl CLUSTER_DEGRADED oznacza, że można pisać do klastra, ale jeden lub więcej węzłów jest wyłączonych. Gdy tak się stanie, ClusterControl wygeneruje raport incydentu.
W przypadku CLUSTER_FAILURE, chociaż sama nomenklatura wyjaśnia się, jest to stan, w którym klaster ulega awarii i nie jest już w stanie przetwarzać odczytów ani zapisów. To jest stan CLUSTER_FAILURE. Niezależnie od tego, czy proces automatycznego odzyskiwania próbuje naprawić problem, czy jest wyłączony, ClusterControl wygeneruje raport o incydencie.
Jak włączyć MySQL Freeze Frame?
Zamrożenie ramki MySQL programu ClusterControl jest domyślnie włączone i generuje raport o incydentach tylko wtedy, gdy zostaną wyzwolone lub napotkane stany CLUSTER_DEGRADED lub CLUSTER_FAILURE. Nie ma więc potrzeby, aby użytkownik ustawiał jakiekolwiek ustawienia konfiguracyjne ClusterControl, ClusterControl zrobi to za Ciebie automagicznie.
Lokalizowanie raportu incydentu MySQL Freeze Frame
W chwili pisania tego tekstu istnieją 4 sposoby na zlokalizowanie raportu o incydencie. Można je znaleźć, wykonując poniższe sekcje poniżej.
Korzystanie z karty Raporty operacyjne
Raporty operacyjne z poprzednich wersji są używane tylko do tworzenia, planowania lub tworzenia listy raportów operacyjnych, które zostały wygenerowane przez użytkowników. Od wersji 1.7.5 dołączyliśmy raport o incydentach wygenerowany przez naszą funkcję MySQL Freeze Frame. Zobacz poniższy przykład:
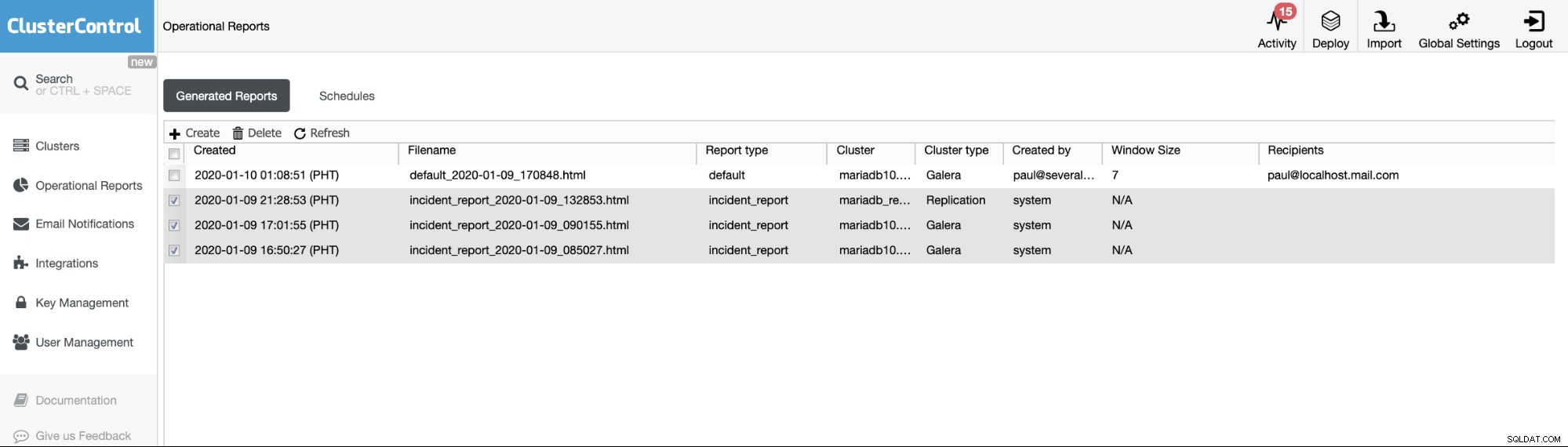
Incydentem są zaznaczone elementy lub elementy z typem raportu ==incydent_raport raporty generowane przez funkcję MySQL Freeze Frame w ClusterControl.
Korzystanie z raportów o błędach
Wybierając klaster i generując raport o błędach, czyli przechodząc przez ten proces:
Korzystanie z wiersza poleceń CLI s9s
W wygenerowanym raporcie o incydencie zawiera instrukcje lub wskazówkę, jak użyć tego z poleceniem s9s CLI. Poniżej przedstawiono informacje w raporcie o zdarzeniu:
Wskazówka! Korzystanie z narzędzia s9s CLI umożliwia łatwe wyszukiwanie danych w tym raporcie, np.:
s9s report --list --long
s9s report --cat --report-id=NJeśli chcesz znaleźć i wygenerować raport o błędach, możesz skorzystać z następującego podejścia:
[example@sqldat.com ~]$ s9s report --list --long --cluster-id=60
ID CID TYPE CREATED TITLE
19 60 incident_report 16:50:27 Incident Report - Cluster Failed
20 60 incident_report 17:01:55 Incident ReportJeśli chcę grepować zmienne wsrep_* na określonym hoście, mogę wykonać następujące czynności:
[example@sqldat.com ~]$ s9s report --cat --report-id=20 --cluster-id=60|sed -n '/WSREP.*/p'|sed 's/ */ /g'|grep '192.168.10.80'|uniq -d
| WSREP_APPLIER_THREAD_COUNT | 4 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_CONF_ID | 18446744073709551615 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_SIZE | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_DELAYED | 27ac86a9-3254-11ea-b104-bb705eb13dde:tcp://192.168.10.100:4567:1,9234d567-3253-11ea-92d3-b643c178d325:tcp://192.168.10.90:4567:1,9234d567-3253-11ea-92d4-b643c178d325:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25e-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25f-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b260-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b261-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b262-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b263-cfcbda888ea9:tcp://192.168.10.90:4567:1,b0b7cb15-3241-11ea-bdbc-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbd-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbe-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbf-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdc0-1a21deddc100:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b321-9a836d562a47:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b322-9a836d562a47:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ab-e298880f3348:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ac-e298880f3348:tcp://192.168.10.100:4567:1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_GCOMM_UUID | 781facbc-3241-11ea-8a22-d74e5dcf7e08 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LAST_COMMITTED | 443 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_CACHED_DOWNTO | 98 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_RECV_QUEUE_MAX | 2 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROTOCOL_VERSION | 10 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROVIDER_VERSION | 26.4.3(r4535) | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED | 112 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED_BYTES | 14413 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED_BYTES | 40592 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_DATA_BYTES | 31734 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS_BYTES | 2752 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_ROLLBACKER_THREAD_COUNT | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_THREAD_COUNT | 5 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_REPL_LATENCY | 4.508e-06/4.508e-06/4.508e-06/0/1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |Ręczne lokalizowanie za pomocą ścieżki pliku systemowego
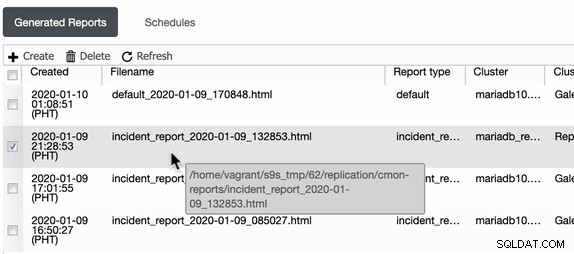
ClusterControl generuje te raporty o incydentach na hoście, na którym działa ClusterControl. ClusterControl tworzy katalog w /home/
Czy istnieją jakieś niebezpieczeństwa lub zastrzeżenia podczas korzystania z MySQL Freeze Frame?
ClusterControl nie zmienia ani nie modyfikuje niczego w węzłach MySQL lub klastrze. MySQL Freeze Frame będzie po prostu odczytywać POKAŻ GLOBALNY STATUS (na ten moment) w określonych odstępach czasu, aby zapisać rekordy, ponieważ nie możemy przewidzieć stanu węzła lub klastra MySQL, kiedy może ulec awarii lub kiedy może mieć problemy ze sprzętem lub dyskiem. Nie można tego przewidzieć, więc zapisujemy wartości i dlatego możemy wygenerować raport o incydentach w przypadku awarii konkretnego węzła. W takim przypadku niebezpieczeństwo tego jest prawie żadne. Teoretycznie może dodać serię żądań klienta do serwera(ów) w przypadku, gdy niektóre blokady są utrzymywane w MySQL, ale jeszcze tego nie zauważyliśmy. Seria testów tego nie pokazuje, więc bylibyśmy zadowoleni, jeśli możesz pozwolić znamy lub składamy zgłoszenie do pomocy technicznej w przypadku wystąpienia problemów.
Istnieją pewne sytuacje, w których raport o incydencie może nie być w stanie zebrać globalnych zmiennych stanu, jeśli problem z siecią był problemem, zanim ClusterControl zamroził określoną ramkę w celu zebrania danych. Jest to całkowicie rozsądne, ponieważ ClusterControl nie może zbierać danych do dalszej diagnozy, ponieważ nie ma połączenia z węzłem.
Na koniec możesz się zastanawiać, dlaczego nie wszystkie zmienne są wyświetlane w sekcji STAN GLOBALNY? W międzyczasie ustawiamy filtr, w którym puste lub 0 wartości są wykluczone z raportu incydentu. Powodem jest to, że chcemy zaoszczędzić trochę miejsca na dysku. Gdy te raporty o incydentach nie będą już potrzebne, możesz je usunąć za pomocą zakładki Raporty operacyjne.
Testowanie funkcji zamrożenia ramki MySQL
Wierzymy, że chcesz wypróbować ten i zobaczyć, jak działa. Ale proszę, upewnij się, że nie uruchamiasz ani nie testujesz tego w środowisku na żywo lub w środowisku produkcyjnym. Omówimy 2 fazy scenariusza w MySQL/MariaDB, jedną dla konfiguracji typu master-slave i jedną dla konfiguracji typu Galera.
Scenariusz testowy konfiguracji Master-Slave
W konfiguracji master-slave jest to łatwe i proste do wypróbowania.
Krok pierwszy
Upewnij się, że wyłączyłeś tryby automatycznego odzyskiwania (klaster i węzeł), jak poniżej:

więc nie będzie próbował naprawić scenariusza testowego.
Krok drugi
Przejdź do węzła głównego i spróbuj ustawić tryb tylko do odczytu:
example@sqldat.com[mysql]> set @@global.read_only=1;
Query OK, 0 rows affected (0.000 sec)Krok trzeci
Tym razem wszczęto alarm i wygenerowano raport o incydencie. Zobacz poniżej, jak wygląda mój klaster:

i alarm został uruchomiony:

i wygenerowano raport o incydencie:

Scenariusz testowy konfiguracji klastra Galera
W przypadku konfiguracji opartej na Galera musimy upewnić się, że klaster nie będzie już dostępny, co oznacza awarię całego klastra. W przeciwieństwie do testu Master-Slave, możesz włączyć Auto Recovery, ponieważ będziemy bawić się interfejsami sieciowymi.
Uwaga:w przypadku tej konfiguracji upewnij się, że masz wiele interfejsów, jeśli testujesz węzły w zdalnej instancji, ponieważ nie możesz uruchomić interfejsu po wyłączeniu tego interfejsu, z którym jesteś połączony.
Krok pierwszy
Utwórz 3-węzłowy klaster Galera (na przykład używając włóczęgi)
Krok drugi
Wydaj polecenie (tak jak poniżej), aby zasymulować problem z siecią i zrób to dla wszystkich węzłów
[example@sqldat.com ~]# ifdown eth1
Device 'eth1' successfully disconnected.Krok trzeci
Teraz mój klaster został wyłączony i mam następujący stan:

podniósł alarm,

i generuje raport o incydencie:

W przypadku przykładowego raportu o zdarzeniu możesz użyć tego nieprzetworzonego pliku i zapisać go jako html.
Spróbowanie jest dość proste, ale ponownie, rób to tylko w środowisku nieaktywnym i nieprodukcyjnym.
Wnioski
MySQL Freeze Frame w ClusterControl może być pomocna podczas diagnozowania awarii. Podczas rozwiązywania problemów potrzebujesz wielu informacji, aby określić przyczynę i właśnie to zapewnia MySQL Freeze Frame.