Najlepszym scenariuszem jest to, że w przypadku awarii bazy danych masz dobry plan odzyskiwania po awarii (DRP) i wysoce dostępne środowisko z automatycznym procesem przełączania awaryjnego, ale… co się stanie, jeśli jakiś nieoczekiwany powód? Co zrobić, jeśli trzeba wykonać ręczne przełączanie awaryjne? Na tym blogu podzielimy się kilkoma zaleceniami, których należy przestrzegać w przypadku konieczności przełączenia awaryjnego bazy danych.
Kontrole weryfikacyjne
Przed wprowadzeniem jakichkolwiek zmian musisz zweryfikować kilka podstawowych rzeczy, aby uniknąć nowych problemów po procesie przełączania awaryjnego.
Stan replikacji
Możliwe, że w momencie awarii węzeł podrzędny nie jest aktualny z powodu awarii sieci, dużego obciążenia lub innego problemu, więc musisz upewnić się, że niewolnik ma wszystkie (lub prawie wszystkie) informacje. Jeśli masz więcej niż jeden węzeł podrzędny, powinieneś również sprawdzić, który z nich jest najbardziej zaawansowany i wybrać go do przełączenia awaryjnego.
np. Sprawdźmy stan replikacji na serwerze MariaDB.
MariaDB [(none)]> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.100.110
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000014
Read_Master_Log_Pos: 339
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 635
Relay_Master_Log_File: binlog.000014
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_Errno: 0
Skip_Counter: 0
Exec_Master_Log_Pos: 339
Relay_Log_Space: 938
Until_Condition: None
Until_Log_Pos: 0
Master_SSL_Allowed: No
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_SQL_Errno: 0
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3001
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3001-20
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)W przypadku PostgreSQL jest nieco inaczej, ponieważ musisz sprawdzić stan listów WAL i porównać zastosowane z pobranymi.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Poświadczenia
Przed uruchomieniem przełączania awaryjnego należy sprawdzić, czy aplikacja/użytkownicy będą mogli uzyskać dostęp do nowego systemu głównego przy użyciu bieżących poświadczeń. Jeśli nie replikujesz użytkowników bazy danych, być może poświadczenia zostały zmienione, więc będziesz musiał zaktualizować je w węzłach podrzędnych przed wprowadzeniem jakichkolwiek zmian.
np. Możesz wysłać zapytanie do tabeli użytkowników w bazie danych mysql, aby sprawdzić poświadczenia użytkownika w MariaDB/MySQL Server:
MariaDB [(none)]> SELECT Host,User,Password FROM mysql.user;
+-----------------+--------------+-------------------------------------------+
| Host | User | Password |
+-----------------+--------------+-------------------------------------------+
| localhost | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | mysql | invalid |
| 127.0.0.1 | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.100 | cmon | *F80B5EE41D1FB1FA67D83E96FCB1638ABCFB86E2 |
| 127.0.0.1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| ::1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.112 | user1 | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 127.0.0.1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| ::1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 192.168.100.110 | rpl_user | *EEA7B018B16E0201270B3CDC0AF8FC335048DC63 |
+-----------------+--------------+-------------------------------------------+
12 rows in set (0.001 sec)W przypadku PostgreSQL możesz użyć polecenia „\du”, aby poznać role, a także musisz sprawdzić plik konfiguracyjny pg_hba.conf, aby zarządzać dostępem użytkowników (nie poświadczeniami). A więc:
postgres=# \du
List of roles
Role name | Attributes | Member of
------------------+------------------------------------------------------------+-----------
admindb | Superuser, Create role, Create DB | {}
cmon_replication | Replication | {}
cmonexporter | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
s9smysqlchk | Superuser, Create role, Create DB | {}I pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD
host replication cmon_replication localhost md5
host replication cmon_replication 127.0.0.1/32 md5
host all s9smysqlchk localhost md5
host all s9smysqlchk 127.0.0.1/32 md5
local all all trust
host all all 127.0.0.1/32 trustDostęp do sieci/zapory
Poświadczenia to nie jedyny możliwy problem z dostępem do nowego mastera. Jeśli węzeł znajduje się w innym centrum danych lub masz lokalną zaporę sieciową do filtrowania ruchu, musisz sprawdzić, czy masz do niego dostęp, a nawet czy masz trasę sieciową umożliwiającą dotarcie do nowego węzła głównego.
np. iptables. Zezwólmy na ruch z sieci 167.124.57.0/24 i po dodaniu sprawdź aktualne reguły:
$ iptables -A INPUT -s 167.124.57.0/24 -m state --state NEW -j ACCEPT
$ iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- 167.124.57.0/24 0.0.0.0/0 state NEW
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destinationnp. trasy. Załóżmy, że nowy węzeł główny znajduje się w sieci 10.0.0.0/24, serwer aplikacji jest w 192.168.100.0/24, a do sieci zdalnej można się połączyć za pomocą 192.168.100.100, więc w serwerze aplikacji dodaj odpowiednią trasę:
$ route add -net 10.0.0.0/24 gw 192.168.100.100
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.100.1 0.0.0.0 UG 0 0 0 eth0
10.0.0.0 192.168.100.100 255.255.255.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1027 0 0 eth0
192.168.100.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0Punkty akcji
Po sprawdzeniu wszystkich wspomnianych punktów, powinieneś być gotowy do podjęcia działań w celu przełączenia awaryjnego bazy danych.
Nowy adres IP
Gdy będziesz promować węzeł podrzędny, główny adres IP ulegnie zmianie, więc będziesz musiał go zmienić w dostępie do aplikacji lub klienta.
Korzystanie z Load Balancera to doskonały sposób na uniknięcie tego problemu/zmiany. Po zakończeniu procesu przełączania awaryjnego Load Balancer wykryje stary master jako offline i (w zależności od konfiguracji) wyśle ruch do nowego, aby mógł na nim pisać, więc nie musisz nic zmieniać w swojej aplikacji.
np. Zobaczmy przykład konfiguracji HAProxy:
listen haproxy_5433
bind *:5433
mode tcp
timeout client 10800s
timeout server 10800s
balance leastconn
option tcp-check
server 192.168.100.119 192.168.100.119:5432 check
server 192.168.100.120 192.168.100.120:5432 checkW tym przypadku, jeśli jeden węzeł nie działa, HAProxy nie wyśle tam ruchu i prześle go tylko do dostępnego węzła.
Ponowna konfiguracja węzłów podrzędnych
Jeśli masz więcej niż jeden węzeł podrzędny, po wypromowaniu jednego z nich musisz ponownie skonfigurować pozostałe podrzędne, aby połączyć się z nowym nadrzędnym. Może to być czasochłonne zadanie, w zależności od liczby węzłów.
Zweryfikuj i skonfiguruj kopie zapasowe
Gdy masz już wszystko na swoim miejscu (awansowanie nowego mastera, rekonfiguracja slave'ów, pisanie aplikacji w nowym masterze), ważne jest, aby podjąć niezbędne działania, aby zapobiec nowemu problemowi, więc tworzenie kopii zapasowych jest koniecznością ten krok. Najprawdopodobniej przed incydentem była uruchomiona polityka tworzenia kopii zapasowych (jeśli nie, musisz ją mieć na pewno), więc musisz sprawdzić, czy kopie zapasowe nadal działają, czy też będą działać w nowej topologii. Możliwe, że kopie zapasowe były uruchomione na starym węźle głównym lub w węźle podrzędnym, który jest teraz nadrzędny, więc musisz to sprawdzić, aby upewnić się, że zasady tworzenia kopii zapasowych będą nadal działać po zmianach.
Monitorowanie bazy danych
Kiedy wykonujesz proces przełączania awaryjnego, monitorowanie jest koniecznością przed, w trakcie i po procesie. Dzięki temu możesz zapobiec problemowi, zanim się pogorszy, wykryć nieoczekiwany problem podczas przełączania awaryjnego, a nawet dowiedzieć się, czy coś pójdzie nie tak po nim. Na przykład musisz monitorować, czy Twoja aplikacja może uzyskać dostęp do nowego urządzenia głównego, sprawdzając liczbę aktywnych połączeń.
Kluczowe wskaźniki do monitorowania
Przyjrzyjmy się niektórym z najważniejszych wskaźników, które należy wziąć pod uwagę:
- Opóźnienie replikacji
- Stan replikacji
- Liczba połączeń
- Wykorzystanie/błędy sieci
- Obciążenie serwera (procesor, pamięć, dysk)
- Dzienniki bazy danych i systemu
Wycofanie
Oczywiście, jeśli coś poszło nie tak, musisz mieć możliwość wycofania. Blokowanie ruchu do starego węzła i utrzymywanie go w jak największej izolacji może być dobrą strategią, więc na wypadek konieczności wycofania starego węzła będzie dostępny. Jeśli wycofanie nastąpi po kilku minutach, w zależności od ruchu, prawdopodobnie będziesz musiał wprowadzić dane z tych minut do starego węzła głównego, więc upewnij się, że masz również dostępny i izolowany tymczasowy węzeł główny, aby wziąć te informacje i zastosować je z powrotem .
Automatyzacja procesu przełączania awaryjnego za pomocą ClusterControl
Widząc wszystkie te zadania niezbędne do wykonania przełączenia awaryjnego, najprawdopodobniej chcesz je zautomatyzować i uniknąć całej tej ręcznej pracy. W tym celu możesz skorzystać z niektórych funkcji, które ClusterControl może zaoferować dla różnych technologii baz danych, takich jak automatyczne odzyskiwanie, kopie zapasowe, zarządzanie użytkownikami, monitorowanie, a wszystko to z poziomu tego samego systemu.
Dzięki ClusterControl możesz weryfikować stan replikacji i jej opóźnienie, tworzyć lub modyfikować poświadczenia, znać stan sieci i hosta, a także przeprowadzać więcej weryfikacji.
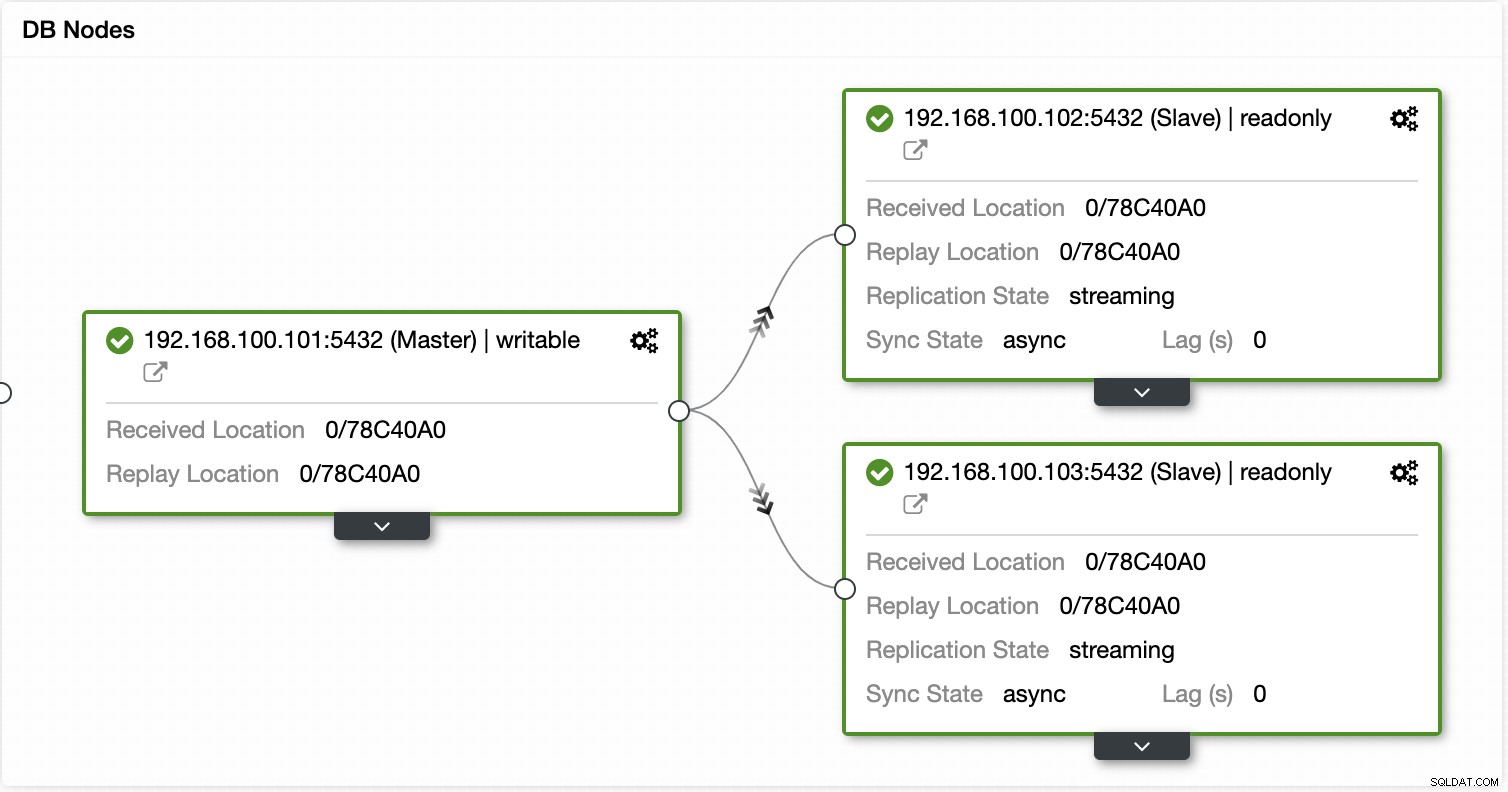
Za pomocą ClusterControl możesz również wykonywać różne akcje klastra i węzła, takie jak promowanie urządzenia podrzędnego , zrestartuj bazę danych i serwer, dodaj lub usuń węzły bazy danych, dodaj lub usuń węzły równoważenia obciążenia, odbuduj urządzenie podrzędne replikacji i nie tylko.
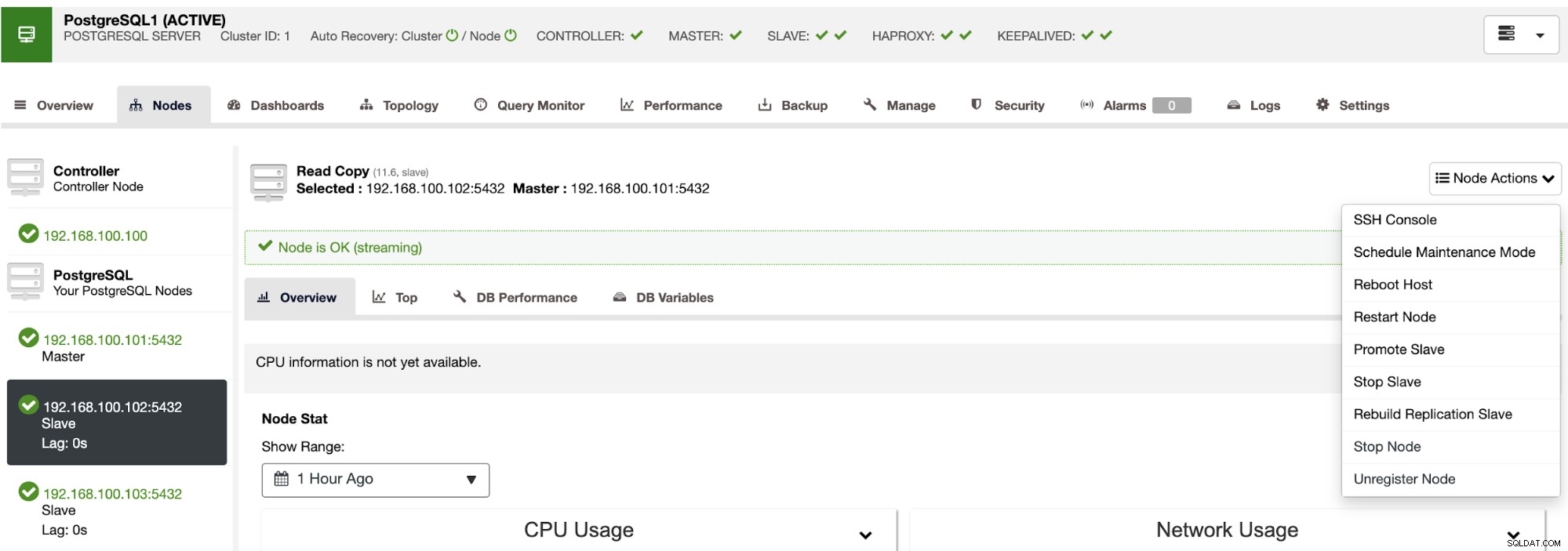
Korzystając z tych działań, możesz również w razie potrzeby cofnąć przełączanie awaryjne, odbudowując i promując poprzedni mistrz.
ClusterControl oferuje usługi monitorowania i ostrzegania, które pomagają wiedzieć, co się dzieje, a nawet jeśli coś się wydarzyło wcześniej.
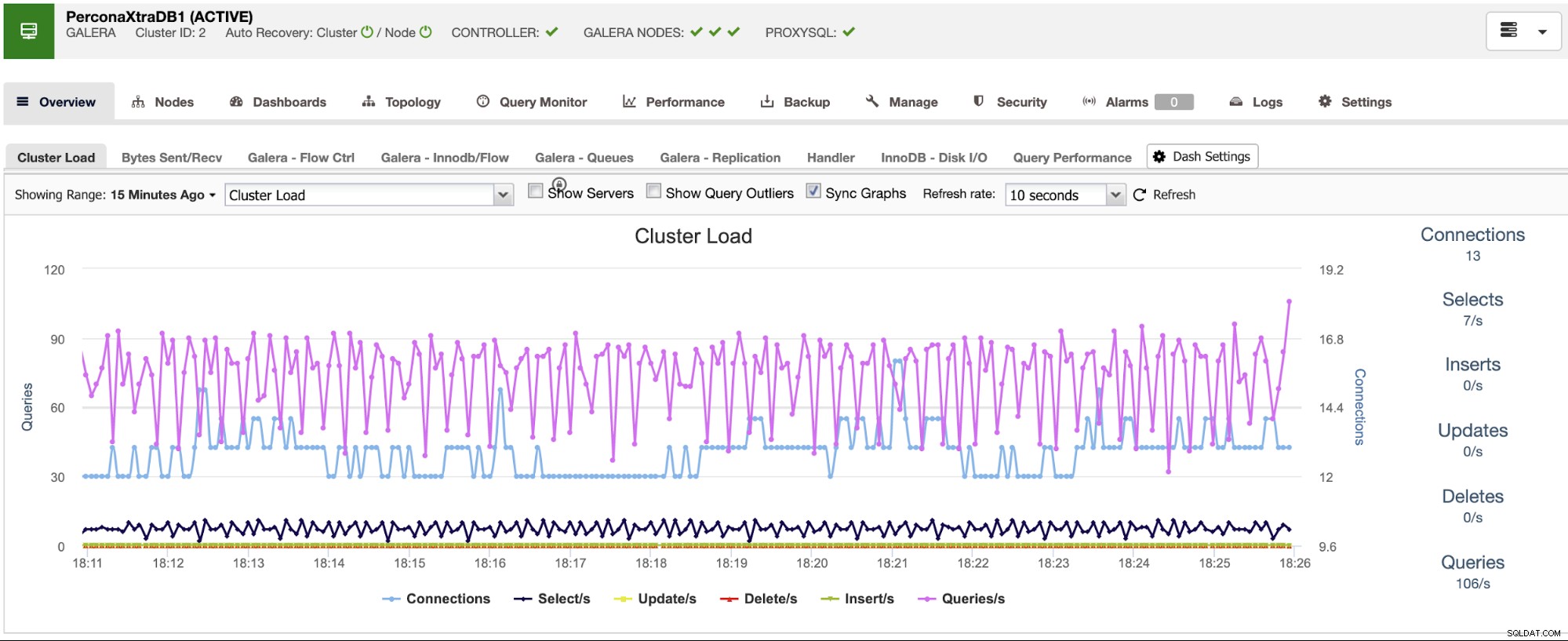
Możesz również użyć sekcji pulpitu nawigacyjnego, aby uzyskać bardziej przyjazny dla użytkownika widok o stanie Twoich systemów.
Wnioski
W przypadku awarii głównej bazy danych będziesz chciał mieć wszystkie informacje na miejscu, aby podjąć niezbędne działania JAK NAJSZYBCIEJ. Posiadanie dobrego DRP jest kluczem do utrzymania działania systemu przez cały (lub prawie cały) czas. Ten plan DRP powinien obejmować dobrze udokumentowany proces przełączania awaryjnego, aby mieć akceptowalny RTO (cel czasu odzyskiwania) dla firmy.