W poprzednim blogu omówiliśmy kilka porad i wskazówek, jak przygotować serwer MySQL do użytku produkcyjnego z perspektywy administratora systemu. Ten wpis na blogu jest kontynuacją...
Użyj narzędzia do tworzenia kopii zapasowych bazy danych
Każde narzędzie do tworzenia kopii zapasowych ma swoje zalety i wady. Na przykład Percona Xtrabackup (lub MariaDB Backup for MariaDB) może wykonać fizyczną kopię zapasową na gorąco bez blokowania baz danych, ale można ją przywrócić tylko do tej samej wersji w innej instancji. Podczas gdy mysqldump jest kompatybilny z innymi głównymi wersjami MySQL i znacznie prostszy w przypadku częściowego tworzenia kopii zapasowych, aczkolwiek jest stosunkowo wolniejszy podczas przywracania w porównaniu z Percona Xtrabackup na dużych bazach danych. MySQL 5.7 wprowadza również mysqlpump, podobną do mysqldump z możliwościami przetwarzania równoległego w celu przyspieszenia procesu zrzutu.
Nie przegap konfiguracji wszystkich tych narzędzi do tworzenia kopii zapasowych na serwerze MySQL, ponieważ są one dostępne bezpłatnie i mają kluczowe znaczenie dla odzyskiwania danych. Ponieważ mysqldump i mysqlpump są już zawarte w MySQL 5.7 i nowszych, wystarczy zainstalować Percona Xtrabackup (lub MariaDB Backup dla MariaDB), ale wymaga to pewnych przygotowań, jak pokazano w następujących krokach:
Krok pierwszy
Upewnij się, że narzędzie do tworzenia kopii zapasowych i jego zależności są zainstalowane:
$ yum install -y epel-release
$ yum install -y socat pv percona-xtrabackupW przypadku serwerów MariaDB zamiast tego użyj MariaDB Backup:
$ yum install -y socat pv MariaDB-BackupKrok drugi
Utwórz użytkownika 'xtrabackup' na master, jeśli nie istnieje:
mysql> CREATE USER 'xtrabackup'@'localhost' IDENTIFIED BY 'Km4z9^sT2X';
mysql> GRANT RELOAD, LOCK TABLES, PROCESS, REPLICATION CLIENT ON *.* TO 'xtrabackup'@'localhost';Krok trzeci
Utwórz innego użytkownika o nazwie „mysqldump” na master, jeśli nie istnieje. Ten użytkownik będzie używany do 'mysqldump' i 'mysqlpump':
mysql> CREATE USER 'mysqldump'@'localhost' IDENTIFIED BY 'Km4z9^sT2X';
mysql> GRANT SELECT, SHOW VIEW, EVENT, TRIGGER, LOCK TABLES, RELOAD, REPLICATION CLIENT ON *.* TO 'mysqldump'@'localhost';Krok czwarty
Dodaj dane uwierzytelniające użytkowników kopii zapasowej w pliku konfiguracyjnym MySQL w ramach dyrektywy [xtrabackup], [mysqldump] i [mysqlpump]:
$ cat /etc/my.cnf
...
[xtrabackup]
user=xtrabackup
password='Km4z9^sT2X'
[mysqldump]
user=mysqldump
password='Km4z9^sT2X'
[mysqlpump]
user=mysqldump
password='Km4z9^sT2X'Poprzez określenie powyższych wierszy nie musimy określać nazwy użytkownika i hasła w poleceniu kopii zapasowej, ponieważ narzędzie do tworzenia kopii zapasowych automatycznie załaduje te opcje konfiguracji z głównego pliku konfiguracyjnego.
Upewnij się wcześniej, że narzędzia do tworzenia kopii zapasowych są odpowiednio przetestowane. W przypadku Xtrabackup, który obsługuje przesyłanie strumieniowe kopii zapasowych przez sieć, należy to najpierw przetestować, aby upewnić się, że połączenie komunikacyjne może zostać prawidłowo ustanowione między serwerem źródłowym a docelowym. Na serwerze docelowym uruchom następujące polecenie, aby socat nasłuchiwał na porcie 9999 i był gotowy do zaakceptowania przychodzącego przesyłania strumieniowego:
$ socat -u tcp-listen:9999,reuseaddr stdout 2>/tmp/netcat.log | xbstream -x -C /var/lib/mysqlNastępnie utwórz kopię zapasową na serwerze źródłowym i prześlij ją do portu 9999 na serwerze docelowym:
$ innobackupex --socket=/var/lib/mysql/mysql.sock --stream=xbstream /var/lib/mysql/ | socat - TCP4:192.168.0.202:9999Powinieneś otrzymywać ciągły strumień danych wyjściowych po wykonaniu polecenia kopii zapasowej. Poczekaj, aż zobaczysz wiersz „Ukończono OK” wskazujący na pomyślną kopię zapasową.
Dzięki pv możemy ograniczyć wykorzystanie przepustowości lub zobaczyć postęp jako proces, który jest przez nie przepuszczany. Zwykle proces przesyłania strumieniowego powoduje nasycenie sieci, jeśli nie jest włączone ograniczanie przepustowości, co może powodować problemy z interakcją innych serwerów z innymi w tym samym segmencie. Używając pv, możemy dławić proces przesyłania strumieniowego, zanim przekażemy go do narzędzia do przesyłania strumieniowego, takiego jak socat lub netcat. Poniższy przykład pokazuje, że przesyłanie strumieniowe kopii zapasowej zostanie ograniczone do około 80 MB/s zarówno dla połączeń przychodzących, jak i wychodzących:
$ innobackupex --slave-info --socket=/var/lib/mysql/mysql.sock --stream=xbstream /var/lib/mysql/ | pv -q -L 80m | socat - TCP4:192.168.0.202:9999Przesyłanie strumieniowe kopii zapasowej jest powszechnie używane do przygotowania urządzenia podrzędnego lub zdalnego przechowywania kopii zapasowej na innym serwerze.
Dla mysqldump i mysqlpump możemy testować za pomocą następujących poleceń:
$ mysqldump --set-gtid-purged=OFF --all-databases
$ mysqlpump --set-gtid-purged=OFF --all-databasesUpewnij się, że w danych wyjściowych nie pojawiają się wiersze bez błędów.
Test obciążenia serwera
Testowanie warunków skrajnych serwera bazy danych jest ważne, aby zrozumieć maksymalną pojemność, jaką możemy przewidzieć dla konkretnego serwera. Będzie to przydatne, gdy na późniejszym etapie zbliżasz się do progów lub wąskich gardeł. Możesz korzystać z wielu narzędzi do benchmarkingu dostępnych na rynku, takich jak mysqlslap, DBT2 i sysbench.
W tym przykładzie używamy sysbench do pomiaru szczytowej wydajności serwera, poziomu nasycenia, a także temperatury komponentów podczas pracy w środowisku o dużym obciążeniu bazy danych. Dzięki temu będziesz mógł zrozumieć, jak dobry jest serwer, i przewidzieć obciążenie, jakie serwer może przetworzyć dla naszej aplikacji w środowisku produkcyjnym.
Aby zainstalować i skonfigurować sysbench, możesz skompilować go ze źródła lub zainstalować pakiet z repozytorium Percona:
$ yum install -y https://repo.percona.com/yum/percona-release-latest.noarch.rpm
$ yum install -y sysbenchUtwórz schemat bazy danych i użytkownika na serwerze MySQL:
mysql> CREATE DATABASE sbtest;
mysql> CREATE USER 'sbtest'@'localhost' IDENTIFIED BY 'sysbenchP4ss';
mysql> GRANT ALL PRIVILEGES ON sbtest.* TO example@sqldat.com'localhost';Wygeneruj dane testowe:
$ sysbench \
/usr/share/sysbench/oltp_common.lua \
--db-driver=mysql \
--mysql-host=localhost \
--mysql-user=sbtest \
--mysql-password=sysbenchP4ss \
--tables=50 \
--table-size=100000 \
prepareNastępnie uruchom test porównawczy na 1 godzinę (3600 sekund):
$ sysbench \
/usr/share/sysbench/oltp_read_write.lua \
--report-interval=2 \
--threads=64 \
--max-requests=0 \
--db-driver=mysql \
--time=3600 \
--db-ps-mode=disable \
--mysql-host=localhost \
--mysql-user=sbtest \
--mysql-password=sysbenchP4ss \
--tables=50 \
--table-size=100000 \
runGdy test jest uruchomiony, użyj iostat (dostępny w pakiecie sysstat) w innym terminalu, aby monitorować wykorzystanie dysku, przepustowość, IOPS i oczekiwanie na I/O:
$ yum install -y sysstat
$ iostat -x 60
avg-cpu: %user %nice %system %iowait %steal %idle
40.55 0.00 55.27 4.18 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.19 6.18 1236.23 816.92 61283.83 14112.44 73.44 4.00 1.96 2.83 0.65 0.34 69.29Powyższy wynik będzie drukowany co 60 sekund. Poczekaj, aż test się zakończy i weź średnią r/s (odczyty/sekundę), w/s (zapisy/sekundę), %iowait, %util, rkB/s i wkB/s (przepustowość). Jeśli widzisz stosunkowo niskie wykorzystanie dysku, procesora, pamięci RAM lub sieci, prawdopodobnie musisz zwiększyć wartość „--threads” do jeszcze wyższej wartości, aby wykorzystała wszystkie zasoby do granic możliwości.
Rozważ następujące aspekty do zmierzenia:
- Zapytania na sekundę =Podsumowanie Sysbench po zakończeniu testu w statystykach SQL -> Zapytania -> Na sek.
- Opóźnienie zapytania =Podsumowanie Sysbench po zakończeniu testu pod Opóźnienie (ms) -> 95. percentyl.
- IOPS dysku =średnia r/s + w/s
- Wykorzystanie dysku =Średnia z %util
- Przepustowość dysku O/Z =Średnia rkB/s / Średnia wkB/s
- Oczekiwanie na dysk we/wy =średnia z %iowait
- Średnie obciążenie serwera =Średnie obciążenie średnie zgłoszone przez najwyższe polecenie.
- Użycie procesora MySQL =Średnie wykorzystanie procesora zgodnie z raportem top command.
Dzięki ClusterControl możesz łatwo obserwować i uzyskać powyższe informacje za pomocą panelu Przegląd węzłów, jak pokazano na poniższym zrzucie ekranu:
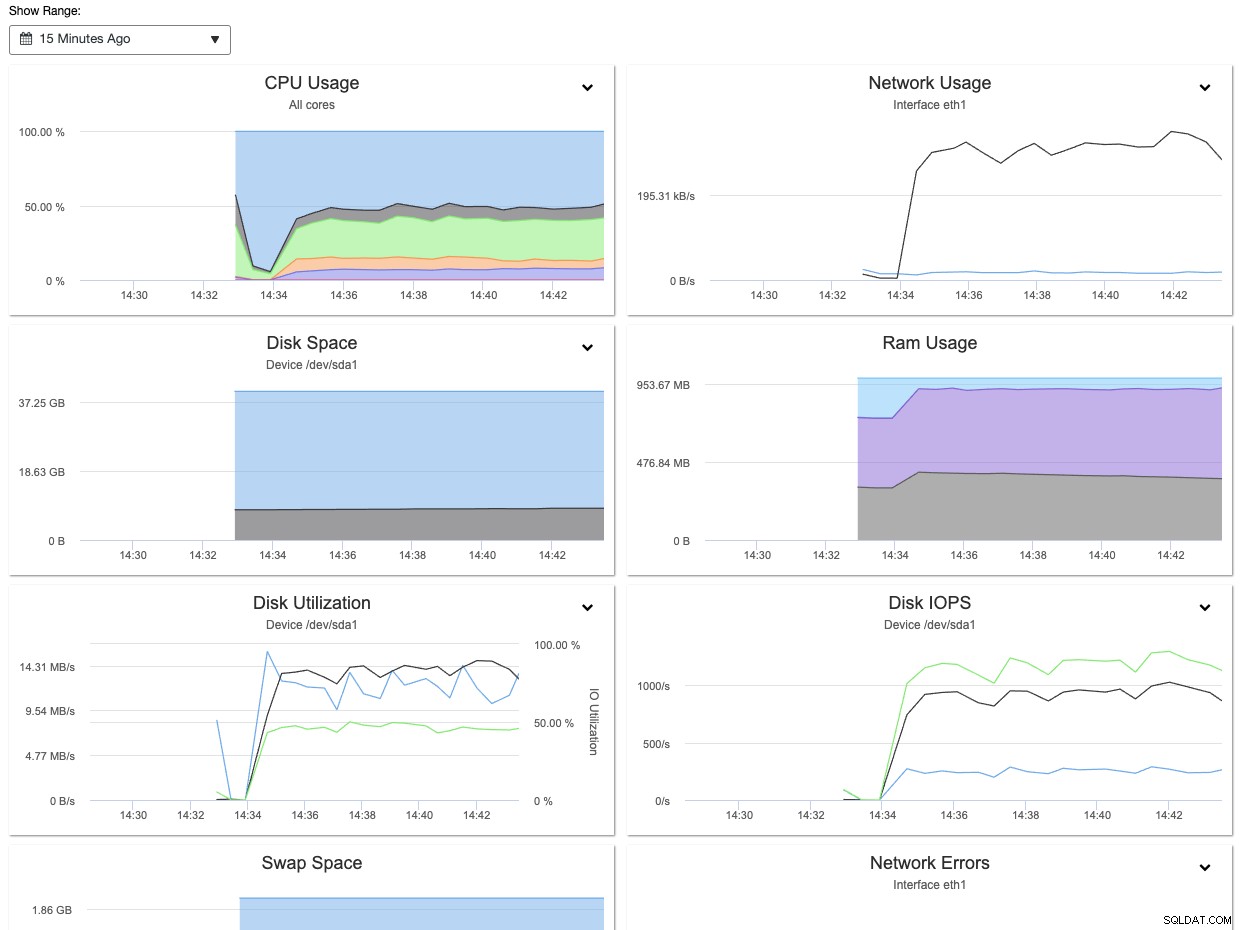
Ponadto informacje zebrane podczas testu warunków skrajnych można wykorzystać do dostrojenia MySQL i odpowiednio zmienne InnoDB, takie jak innodb_buffer_pool_size, innodb_io_capacity, innodb_io_capacity_max, innodb_write_io_threads, innodb_read_io_threads, a także max_connections.
Aby dowiedzieć się więcej na temat testu porównawczego wydajności MySQL przy użyciu sysbench, zapoznaj się z tym wpisem na blogu Jak przeprowadzić test porównawczy wydajności MySQL i MariaDB przy użyciu SysBench.
Użyj narzędzia zmiany schematu online
Zmiana schematu jest czymś nieuniknionym w relacyjnych bazach danych. Ponieważ aplikacja rozrasta się i z czasem staje się coraz bardziej wymagająca, z pewnością wymaga pewnych zmian w strukturze bazy danych. Istnieją pewne operacje DDL, które przebudują tabelę, blokując w ten sposób uruchamianie innych instrukcji DML, co może wpłynąć na dostępność bazy danych, jeśli wykonujesz zmiany strukturalne na ogromnej tabeli. Aby zobaczyć listę blokujących operacji DDL, zapoznaj się z tą stroną dokumentacji MySQL i poszukaj operacji, dla których „Zezwalaj na współbieżne DML” =Nie.
Jeśli nie możesz sobie pozwolić na przestoje na serwerach produkcyjnych podczas zmiany schematu, prawdopodobnie dobrym pomysłem jest skonfigurowanie narzędzia zmiany schematu online na wczesnym etapie. W tym przykładzie instalujemy i konfigurujemy gh-ost, zmianę schematu online zbudowaną przez Github. Gh-ost używa strumienia logów binarnych do przechwytywania zmian w tabeli i asynchronicznie stosuje je do tabeli duchów.
Aby zainstalować gh-ost na polu CentOS, po prostu wykonaj następujące kroki:
Krok pierwszy
Pobierz najnowsze duchy stąd:
$ wget https://github.com/github/gh-ost/releases/download/v1.0.48/gh-ost-1.0.48-1.x86_64.rpmKrok drugi
Zainstaluj pakiet:
$ yum localinstall gh-ost-1.0.48-1.x86_64.rpm Krok trzeci
Utwórz użytkownika bazy danych dla gh-ost, jeśli nie istnieje, i nadaj mu odpowiednie uprawnienia:
mysql> CREATE USER 'gh-ost'@'{host}' IDENTIFIED BY 'ghostP455';
mysql> GRANT ALTER, CREATE, DELETE, DROP, INDEX, INSERT, LOCK TABLES, SELECT, TRIGGER, UPDATE ON {db_name}.* TO 'gh-ost'@'{host}';
mysql> GRANT SUPER, REPLICATION SLAVE ON *.* TO 'gh-ost'@'{host}';** Zastąp {host} i {db_name} odpowiednimi wartościami. W idealnym przypadku, {host} jest jednym z hostów podrzędnych, które dokonają zmiany schematu online. Szczegółowe informacje można znaleźć w dokumentacji gh-ost.
Krok czwarty
Utwórz plik konfiguracyjny gh-ost, aby przechowywać nazwę użytkownika i hasło w /root/.gh-ost.cnf:
[client]
user=gh-ost
password=ghostP455Podobnie możesz skonfigurować Percona Toolkit Online Schema Change (pt-osc) na serwerze bazy danych. Pomysł polega na upewnieniu się, że jesteś przygotowany z tym narzędziem najpierw na serwerze bazy danych, który prawdopodobnie będzie uruchamiał tę operację w przyszłości.
Skorzystaj z zestawu narzędzi Percona
Percona Toolkit to zbiór zaawansowanych narzędzi wiersza poleceń typu open source, opracowanych przez firmę Percona, zaprojektowanych do wykonywania różnych zadań serwerowych i systemowych MySQL, MongoDB i PostgreSQL, które są zbyt trudne lub złożone do wykonać ręcznie. Narzędzia te stały się ostatecznym wybawcą, używanym przez administratorów baz danych na całym świecie do rozwiązywania lub rozwiązywania problemów technicznych występujących na serwerach MySQL i MariaDB.
Aby zainstalować Percona Toolkit, po prostu uruchom następujące polecenie:
$ yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm
$ yum install percona-toolkitW tym pakiecie dostępnych jest ponad 30 narzędzi. Niektóre z nich są specjalnie zaprojektowane dla MongoDB i PostgreSQL. Niektóre z najpopularniejszych narzędzi do rozwiązywania problemów z MySQL i dostrajania wydajności to pt-stalk, pt-mysql-summary, pt-query-digest, pt-table-checksum, pt-table-sync i pt-archiver. Ten zestaw narzędzi może pomóc administratorom baz danych w weryfikacji integralności replikacji MySQL poprzez sprawdzanie spójności danych głównych i replik, wydajne archiwizowanie wierszy, znajdowanie zduplikowanych indeksów, analizowanie zapytań MySQL z dzienników i tcpdump oraz wiele więcej.
Poniższy przykład przedstawia dane wyjściowe jednego z narzędzi (pt-table-checksum), w którym można przeprowadzić kontrolę spójności replikacji online, wykonując zapytania sum kontrolnych na wzorcu, co daje różne wyniki w replikach, które są niezgodne z wzorcem:
$ pt-table-checksum --no-check-binlog-format --replicate-check-only
Checking if all tables can be checksummed ...
Starting checksum ...
Differences on mysql2.local
TABLE CHUNK CNT_DIFF CRC_DIFF CHUNK_INDEX LOWER_BOUNDARY UPPER_BOUNDARY
mysql.proc 1 0 1
mysql.tables_priv 1 0 1
mysql.user 1 1 1Powyższe dane wyjściowe pokazują, że na serwerze podrzędnym (mysql2.local) znajdują się 3 tabele, które są niezgodne z tabelą nadrzędną. Następnie możemy użyć narzędzia pt-table-sync, aby załatać brakujące dane z mastera lub po prostu ponownie zsynchronizować slave'a.
Zablokuj serwer
Na koniec, po zakończeniu etapu konfiguracji i przygotowania, możemy odizolować węzeł bazy danych od sieci publicznej i ograniczyć dostęp serwera do znanych hostów i sieci. Możesz użyć zapory (iptables, firewalld, ufw), grup bezpieczeństwa, hosts.allow i/lub hosts.deny lub po prostu wyłączyć interfejs sieciowy skierowany do Internetu, jeśli masz wiele interfejsów sieciowych.
W przypadku iptables ważne jest, aby określić komentarz dla każdej reguły za pomocą flagi '-m comment --comment':
$ iptables -A INPUT -p tcp -s 192.168.0.0/24 --dport 22 -m comment --comment 'Allow local net to SSH port' -j ACCEPT
$ iptables -A INPUT -p tcp -s 192.168.0.0/24 --dport 3306 -m comment --comment 'Allow local net to MySQL port' -j ACCEPT
$ iptables -A INPUT -p tcp -s 192.168.0.0/24 --dport 9999 -m comment --comment 'Allow local net to backup streaming port' -j ACCEPT
$ iptables -A INPUT -p tcp -s 0.0.0.0/0 -m comment --comment 'Drop everything apart from the above' -j DROPPodobnie dla zapory Ubuntu (ufw), musimy najpierw zdefiniować domyślną regułę, a następnie możemy utworzyć podobne reguły dla MySQL/MariaDB, podobne do tego:
$ sudo ufw default deny incoming comment 'Drop everything apart from the above'
$ sudo ufw default allow outgoing comment 'Allow outgoing everything'
$ sudo ufw allow from 192.168.0.0/24 to any port 22 comment 'Allow local net to SSH port'
$ sudo ufw allow from 192.168.0.0/24 to any port 3306 comment 'Allow local net to MySQL port'
$ sudo ufw allow from 192.168.0.0/24 to any port 9999 comment 'Allow local net to backup streaming port'Włącz zaporę:
$ ufw enableNastępnie sprawdź, czy reguły zostały poprawnie załadowane:
$ ufw status verbose
Status: active
Logging: on (low)
Default: deny (incoming), allow (outgoing), disabled (routed)
New profiles: skip
To Action From
-- ------ ----
22 ALLOW IN 192.168.0.0/24 # Allow local net to SSH port
3306 ALLOW IN 192.168.0.0/24 # Allow local net to MySQL port
9999 ALLOW IN 192.168.0.0/24 # Allow local net to backup streaming portPonownie bardzo ważne jest określenie komentarzy do każdej reguły, aby pomóc nam lepiej ją zrozumieć.
W celu ograniczenia dostępu do zdalnej bazy danych możemy również użyć serwera VPN, jak pokazano w tym poście na blogu, Używanie OpenVPN do zabezpieczania dostępu do klastra baz danych w chmurze.
Wnioski
Przygotowanie serwera produkcyjnego nie jest oczywiście łatwym zadaniem, co pokazaliśmy w tej serii blogów. Jeśli obawiasz się, że możesz coś schrzanić, dlaczego nie użyjesz ClusterControl do wdrożenia klastra bazy danych? ClusterControl ma bardzo dobre wyniki we wdrażaniu baz danych i do tej pory umożliwił ponad 70 000 wdrożeń MySQL i MariaDB we wszystkich środowiskach.