Pojedynczy punkt awarii (SPOF) jest częstym powodem, dla którego organizacje pracują nad rozmieszczeniem obecności środowisk baz danych w innej lokalizacji geograficznej. Jest to część strategicznych planów odzyskiwania po awarii i ciągłości działania.
Planowanie Disaster Recovery (DR) obejmuje procedury techniczne, które obejmują przygotowanie na nieoczekiwane problemy, takie jak klęski żywiołowe, wypadki (takie jak błąd ludzki) lub incydenty (takie jak przestępstwa).
W ciągu ostatniej dekady dystrybucja środowiska bazy danych w wielu lokalizacjach geograficznych była dość powszechną konfiguracją, ponieważ chmury publiczne oferują wiele sposobów radzenia sobie z tym problemem. Wyzwanie polega na skonfigurowaniu środowisk baz danych. Stwarza wyzwania, gdy próbujesz zarządzać bazami danych, przenosić dane do innej lokalizacji geograficznej lub stosować zabezpieczenia o wysokim poziomie obserwowalności.
W tym blogu pokażemy, jak można to zrobić za pomocą replikacji MySQL. Omówimy, w jaki sposób możesz skopiować swoje dane do innego węzła bazy danych znajdującego się w innym kraju, odległym od aktualnej geografii klastra MySQL. W tym przykładzie nasz region docelowy to us-east, podczas gdy moja lokalna lokalizacja znajduje się w Azji na Filipinach.
Dlaczego potrzebuję klastra bazy danych geolokalizacji?
Nawet Amazon AWS, czołowy dostawca chmury publicznej, twierdzi, że cierpi z powodu przestojów lub niezamierzonych przestojów (takich jak ta, która miała miejsce w 2017 roku). Załóżmy, że oprócz lokalnego centrum danych używasz AWS jako dodatkowego centrum danych. Nie możesz mieć żadnego wewnętrznego dostępu do podstawowego sprzętu ani do tych sieci wewnętrznych, które zarządzają węzłami obliczeniowymi. Są to w pełni zarządzane usługi, za które zapłaciłeś, ale nie możesz uniknąć tego, że w każdej chwili może ucierpieć awaria. Jeśli taka lokalizacja geograficzna ulegnie awarii, możesz mieć długi przestój.
Ten rodzaj problemu należy przewidzieć podczas planowania ciągłości biznesowej. Musiał zostać przeanalizowany i wdrożony w oparciu o to, co zostało zdefiniowane. Ciągłość biznesowa baz danych MySQL powinna obejmować długi czas pracy bez przestojów. Niektóre środowiska przeprowadzają testy porównawcze i stawiają wysoko poprzeczkę rygorystycznych testów, w tym słabą stronę, aby ujawnić wszelkie luki w zabezpieczeniach, jak bardzo może być odporna i jak skalowalna jest Twoja architektura technologiczna, w tym infrastruktura baz danych. W przypadku firm, szczególnie tych obsługujących duże transakcje, konieczne jest zapewnienie, aby produkcyjne bazy danych były dostępne dla aplikacji przez cały czas, nawet w przypadku wystąpienia katastrofy. W przeciwnym razie mogą wystąpić przestoje, które mogą kosztować Cię duże pieniądze.
W tych zidentyfikowanych scenariuszach organizacje zaczynają rozszerzać swoją infrastrukturę na różnych dostawców chmury i umieszczać węzły w różnych lokalizacjach geograficznych, aby mieć dłuższy czas pracy bez przestojów (jeśli to możliwe 99,999999999999), niższy RPO i nie mieć SPOF.
Aby zapewnić przetrwanie produkcyjnych baz danych w przypadku awarii, należy skonfigurować witrynę odzyskiwania po awarii (DR). Lokacje produkcyjne i DR muszą być częścią dwóch odległych geograficznie centrów danych. Oznacza to, że rezerwowa baza danych musi być skonfigurowana w lokacji DR dla każdej produkcyjnej bazy danych, tak aby zmiany danych zachodzące w produkcyjnej bazie danych były natychmiast synchronizowane z rezerwową bazą danych za pośrednictwem dzienników transakcji. Niektóre konfiguracje używają również swoich węzłów DR do obsługi odczytów, aby zapewnić równoważenie obciążenia między aplikacją a warstwą danych.
Pożądana konfiguracja architektoniczna
W tym blogu pożądana konfiguracja jest prosta, ale obecnie bardzo powszechna implementacja. Zobacz poniżej żądaną konfigurację architektoniczną tego bloga:
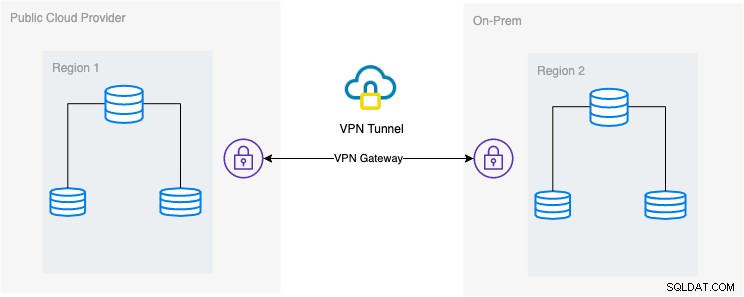
W tym blogu wybieram Google Cloud Platform (GCP) jako publiczną dostawcy usług w chmurze i używając mojej sieci lokalnej jako lokalnego środowiska bazy danych.
Konieczne jest, aby podczas korzystania z tego typu projektu zawsze potrzebne było zarówno środowisko, jak i platforma, aby komunikować się w bardzo bezpieczny sposób. Korzystanie z VPN lub korzystanie z alternatyw, takich jak AWS Direct Connect. Chociaż te chmury publiczne oferują obecnie zarządzane usługi VPN, z których można korzystać. Ale do tej konfiguracji będziemy używać OpenVPN, ponieważ nie potrzebuję zaawansowanego sprzętu ani usług dla tego bloga.
Najlepszy i najbardziej wydajny sposób
W przypadku środowisk baz danych MySQL/Percona/MariaDB najlepszym i wydajnym sposobem jest wykonanie kopii zapasowej bazy danych, wysłanie jej do węzła docelowego w celu wdrożenia lub utworzenia instancji. Istnieją różne sposoby wykorzystania tego podejścia:możesz użyć mysqldump, mydumper, rsync lub użyć Percona XtraBackup/Mariabackup i przesyłać strumieniowo dane do węzła docelowego.
Korzystanie z mysqldump
mysqldump tworzy logiczną kopię zapasową całej bazy danych lub możesz selektywnie wybrać listę baz danych, tabel, a nawet określonych rekordów, które chcesz zrzucić.
Prostym poleceniem, którego można użyć do wykonania pełnej kopii zapasowej, może być
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | mysql -h <target-host-db-node -u<user> -p<password> -vvv --show-warningsZa pomocą tego prostego polecenia uruchomi się bezpośrednio instrukcje MySQL w docelowym węźle bazy danych, na przykład w docelowym węźle bazy danych w Google Compute Engine. Może to być skuteczne, gdy dane są mniejsze lub masz dużą przepustowość. W przeciwnym razie spakowanie bazy danych do pliku, a następnie wysłanie jej do węzła docelowego może być twoją opcją.
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | gzip > mydata.db
$ scp mydata.db <target-host>:/some/pathNastępnie uruchom mysqldump do docelowego węzła bazy danych jako takiego,
zcat mydata.db | mysqlWadą korzystania z logicznej kopii zapasowej za pomocą mysqldump jest to, że jest wolniejsza i zajmuje miejsce na dysku. Używa również jednego wątku, więc nie możesz uruchomić tego równolegle. Opcjonalnie możesz użyć mydumper, zwłaszcza gdy Twoje dane są zbyt duże. mydumper może być uruchamiany równolegle, ale nie jest tak elastyczny w porównaniu do mysqldump.
Korzystanie z xtrabackup
xtrabackup to fizyczna kopia zapasowa, w której można wysyłać strumienie lub pliki binarne do węzła docelowego. Jest to bardzo wydajne i jest najczęściej używane podczas przesyłania strumieniowego kopii zapasowej przez sieć, zwłaszcza gdy węzeł docelowy ma inną lokalizację geograficzną lub inny region. ClusterControl używa xtrabackup podczas udostępniania lub tworzenia instancji nowego urządzenia podrzędnego, niezależnie od tego, gdzie się znajduje, o ile dostęp i uprawnienia zostały ustawione przed akcją.
Jeśli używasz xtrabackup do ręcznego uruchamiania, możesz uruchomić polecenie jako takie,
## Węzeł docelowy
$ socat -u tcp-listen:9999,reuseaddr stdout 2>/tmp/netcat.log | xbstream -x -C /var/lib/mysql## Węzeł źródłowy
$ innobackupex --defaults-file=/etc/my.cnf --stream=xbstream --socket=/var/lib/mysql/mysql.sock --host=localhost --tmpdir=/tmp /tmp | socat -u stdio TCP:192.168.10.70:9999Aby opracować te dwa polecenia, pierwsze polecenie musi zostać wykonane lub uruchomione jako pierwsze w węźle docelowym. Polecenie węzła docelowego nasłuchuje na porcie 9999 i zapisze każdy strumień odebrany z portu 9999 w węźle docelowym. Zależy to od poleceń socat i xbstream, co oznacza, że musisz mieć zainstalowane te pakiety.
W węźle źródłowym wykonuje skrypt perl innobackupex, który wywołuje xtrabackup w tle i używa xbstream do przesyłania strumieniowego danych, które będą przesyłane przez sieć. Polecenie socat otwiera port 9999 i wysyła dane do żądanego hosta, którym w tym przykładzie jest 192.168.10.70. Mimo to upewnij się, że masz zainstalowane socat i xbstream podczas korzystania z tego polecenia. Alternatywnym sposobem używania socat jest nc, ale socat oferuje bardziej zaawansowane funkcje niż nc, takie jak serializacja, ponieważ wielu klientów może nasłuchiwać na porcie.
ClusterControl używa tego polecenia podczas odbudowy urządzenia podrzędnego lub budowania nowego urządzenia podrzędnego. Jest szybki i gwarantuje, że dokładna kopia danych źródłowych zostanie skopiowana do węzła docelowego. W przypadku udostępniania nowej bazy danych w oddzielnej lokalizacji geograficznej użycie tego podejścia zapewnia większą wydajność i zapewnia szybsze zakończenie zadania. Chociaż w przypadku korzystania z logicznej lub binarnej kopii zapasowej podczas przesyłania strumieniowego przez sieć mogą być plusy i minusy. Korzystanie z tej metody jest bardzo powszechnym podejściem podczas konfigurowania nowego klastra bazy danych geolokalizacji w innym regionie i tworzenia dokładnej kopii środowiska bazy danych.
Wydajność, obserwowalność i szybkość
Pytania pozostawione przez większość osób, które nie są zaznajomione z tym podejściem, zawsze dotyczą problemów typu „JAK, CO, GDZIE”. W tej sekcji omówimy, w jaki sposób można wydajnie skonfigurować bazę danych geolokalizacji przy mniejszym nakładzie pracy i możliwości zaobserwowania, dlaczego się nie udaje. Korzystanie z ClusterControl jest bardzo wydajne. W obecnej konfiguracji mam następujące środowisko, jako początkowo zaimplementowane:
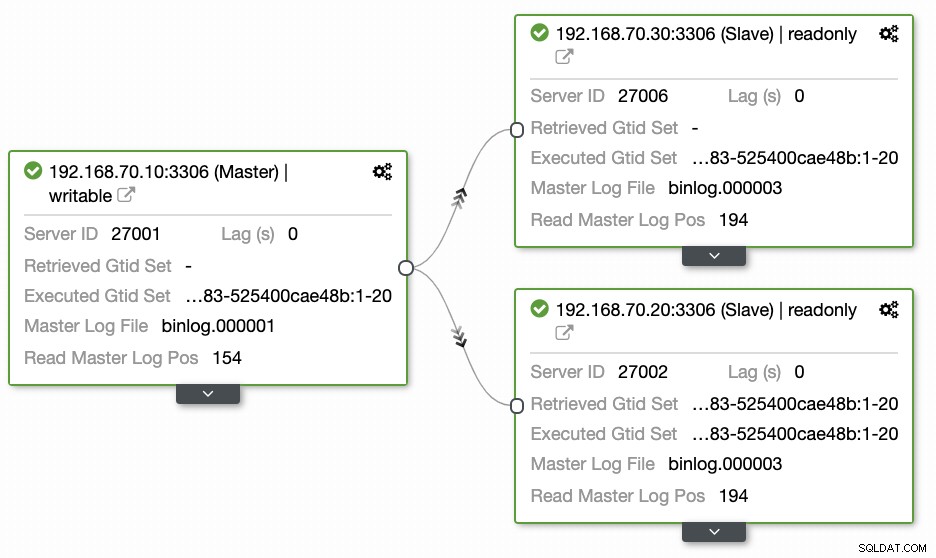
Rozszerzanie węzła do GCP
Rozpoczynając konfigurację klastra bazy danych geolokalizacji, aby rozszerzyć klaster i utworzyć kopię migawkową klastra, możesz dodać nowe urządzenie podrzędne. Jak wspomniano wcześniej, ClusterControl użyje xtrabackup (mariabackup dla MariaDB 10.2 i nowsze) i wdroży nowy węzeł w klastrze. Zanim będziesz mógł zarejestrować węzły obliczeniowe GCP jako węzły docelowe, musisz najpierw skonfigurować odpowiedniego użytkownika systemu, takiego samego jak użytkownik systemu zarejestrowany w ClusterControl. Możesz to sprawdzić w pliku /etc/cmon.d/cmon_X.cnf, gdzie X jest identyfikatorem klastra. Na przykład patrz poniżej:
# grep 'ssh_user' /etc/cmon.d/cmon_27.cnf
ssh_user=maximusmaximus (w tym przykładzie) musi być obecny w węzłach obliczeniowych GCP. Użytkownik w Twoich węzłach GCP musi mieć uprawnienia sudo lub superadministratora. Musi być również skonfigurowany z dostępem SSH bez hasła. Przeczytaj naszą dokumentację więcej o użytkowniku systemu i wymaganych uprawnieniach.
Zróbmy przykładową listę serwerów poniżej (z konsoli GCP:panel Compute Engine):
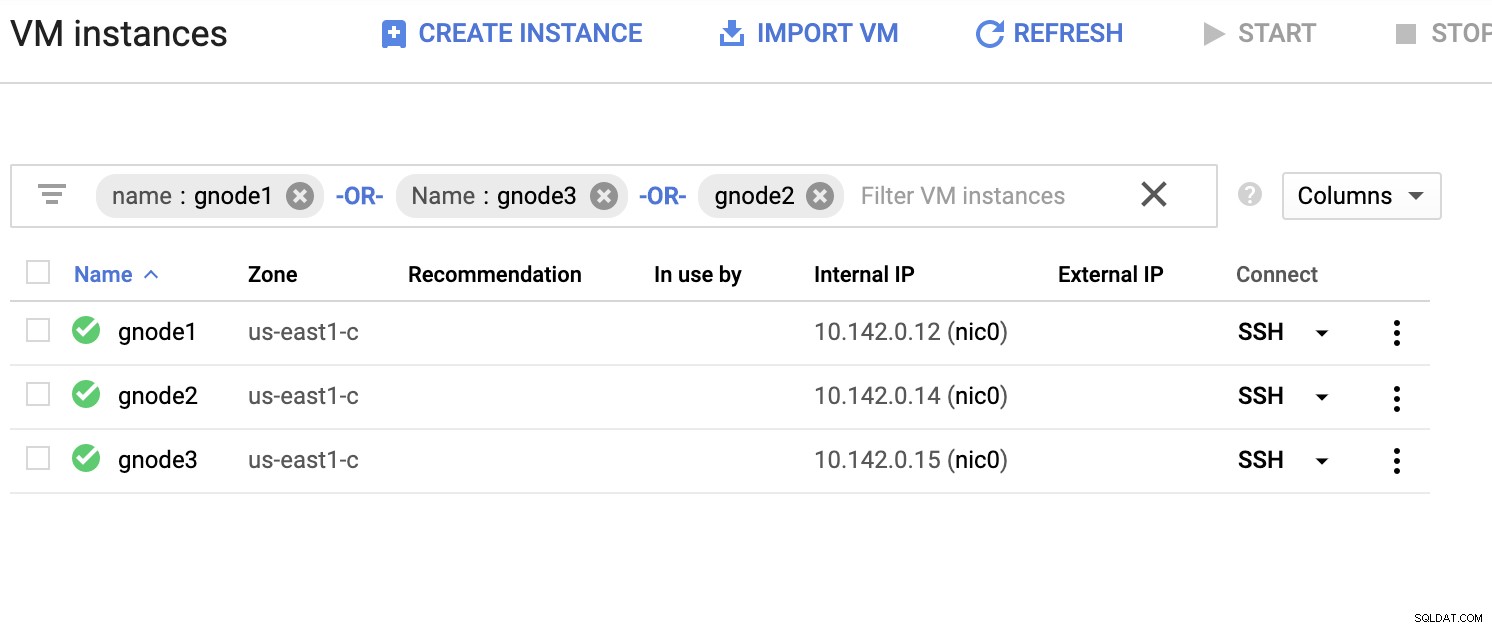
Na powyższym zrzucie ekranu nasz region docelowy jest oparty na region. Jak wspomniano wcześniej, moja sieć lokalna jest skonfigurowana na bezpiecznej warstwie przechodzącej przez GCP (odwrotnie) przy użyciu OpenVPN. Tak więc komunikacja z GCP przechodząca do mojej sieci lokalnej jest również enkapsulowana przez tunel VPN.
Dodaj węzeł podrzędny do GCP
Poniższy zrzut ekranu pokazuje, jak możesz to zrobić. Zobacz zdjęcia poniżej:
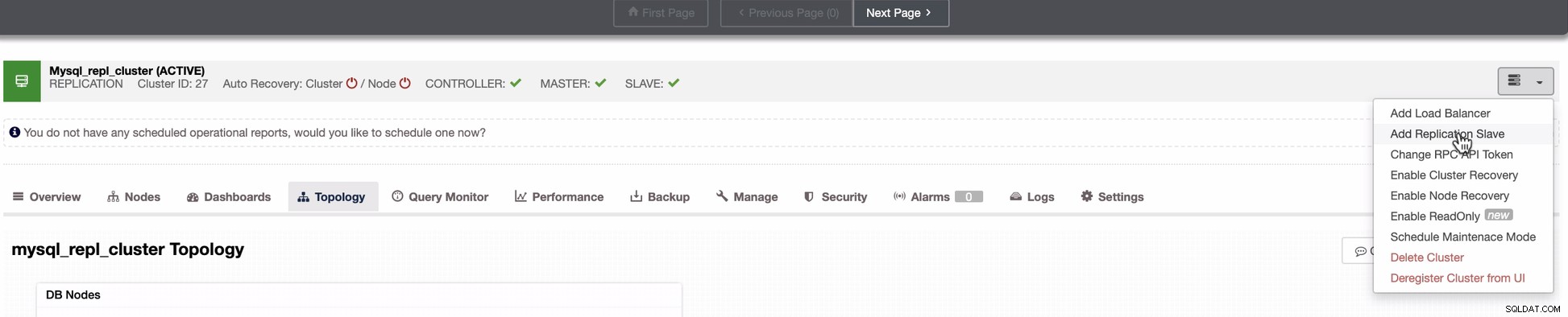
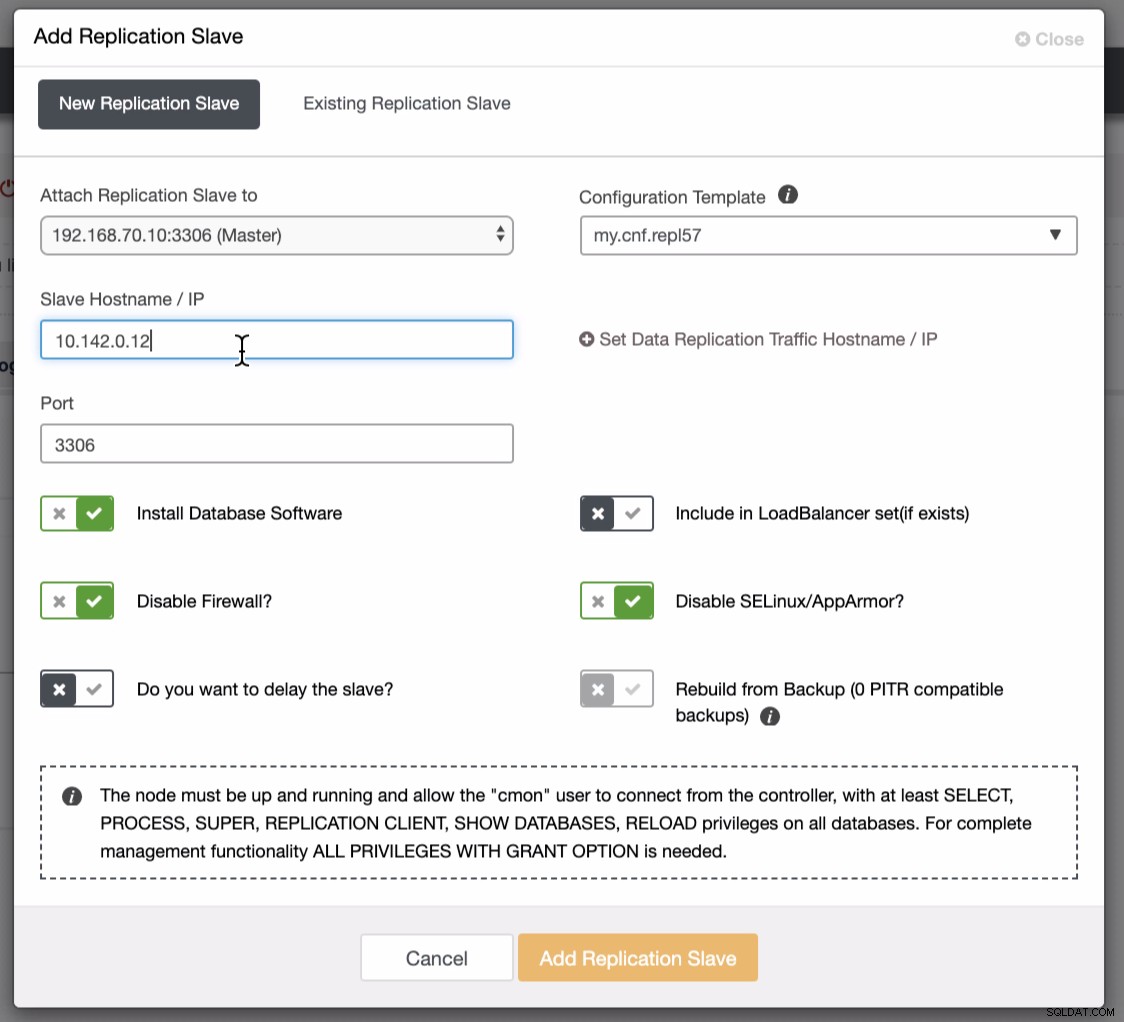
Jak widać na drugim zrzucie, celujemy w węzeł 10.142.0.12 a jego wzorcem źródłowym jest 192.168.70.10. ClusterControl jest wystarczająco inteligentny, aby określić zapory, moduły bezpieczeństwa, pakiety, konfigurację i ustawienia, które należy wykonać. Zobacz poniżej przykład dziennika aktywności zawodowej:
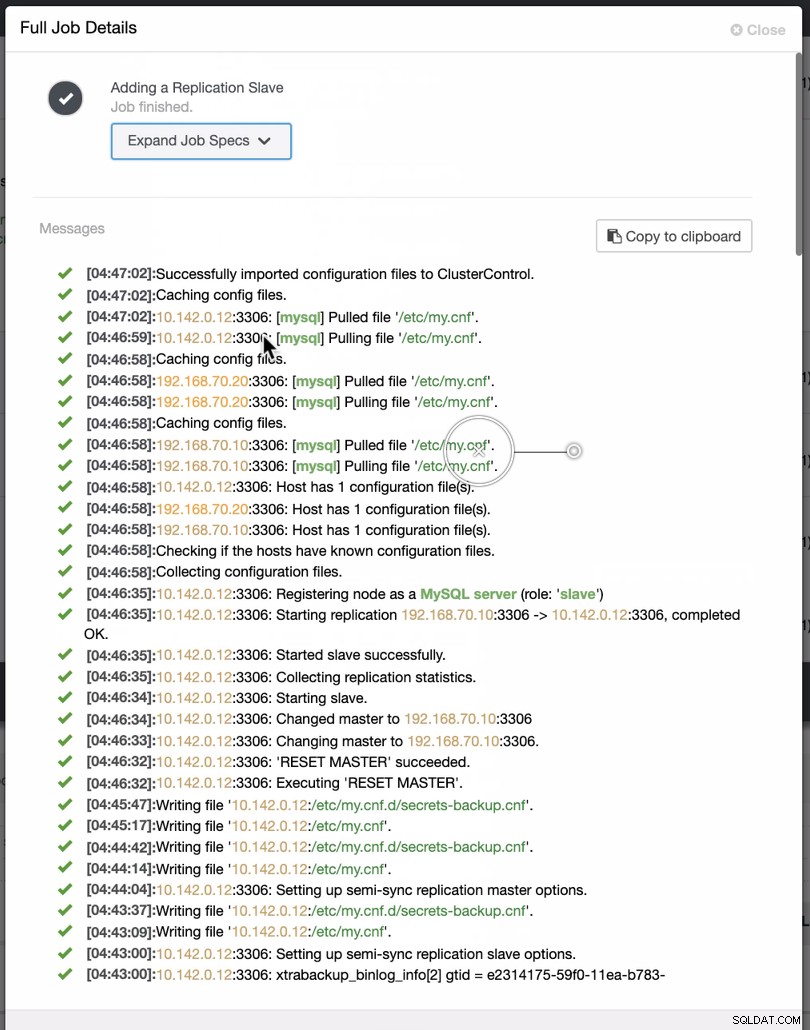
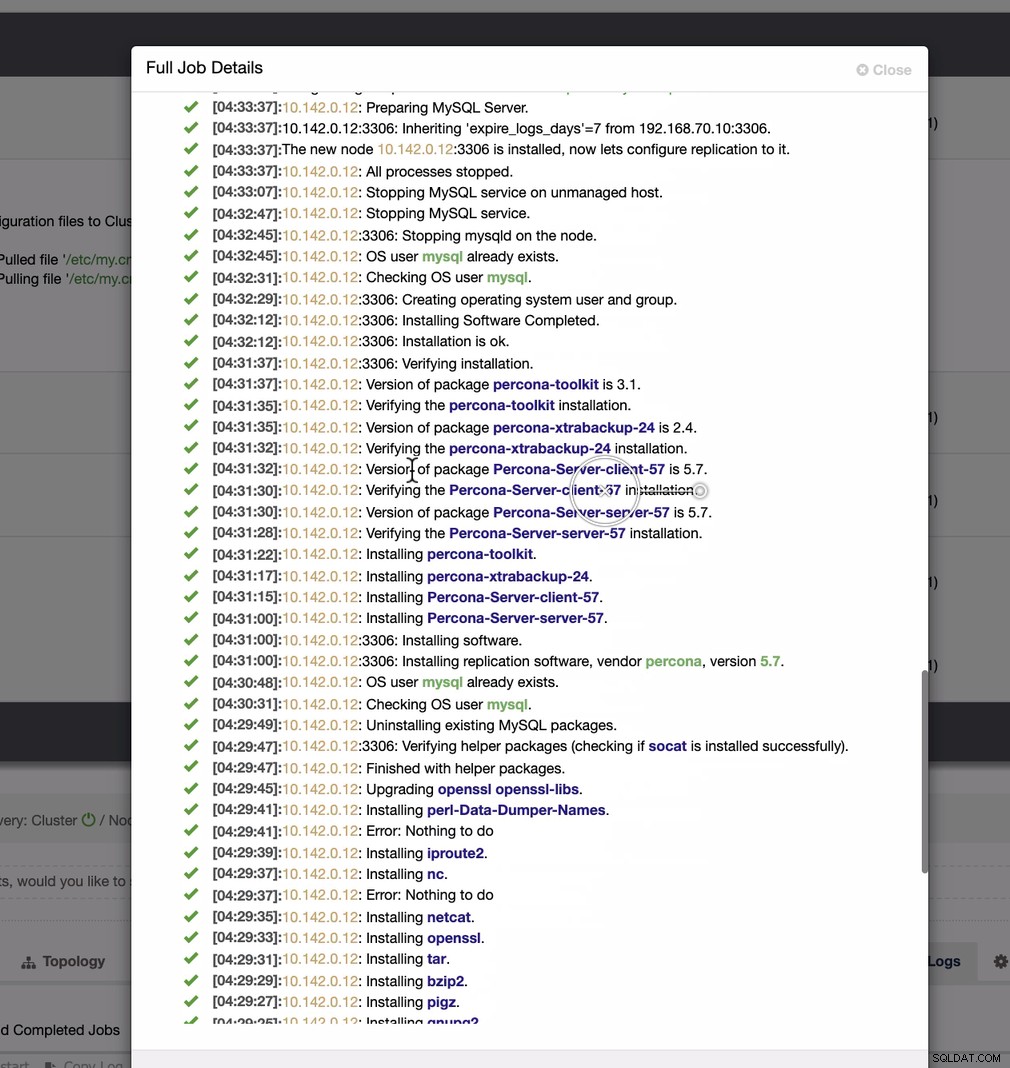
Całkiem proste zadanie, prawda?
Uzupełnij klaster GCP MySQL
Musimy dodać jeszcze dwa węzły do klastra GCP, aby uzyskać topologię równowagi, tak jak w przypadku sieci lokalnej. W przypadku drugiego i trzeciego węzła upewnij się, że master musi wskazywać na Twój węzeł GCP. W tym przykładzie wzorcem jest 10.142.0.12. Zobacz poniżej, jak to zrobić,
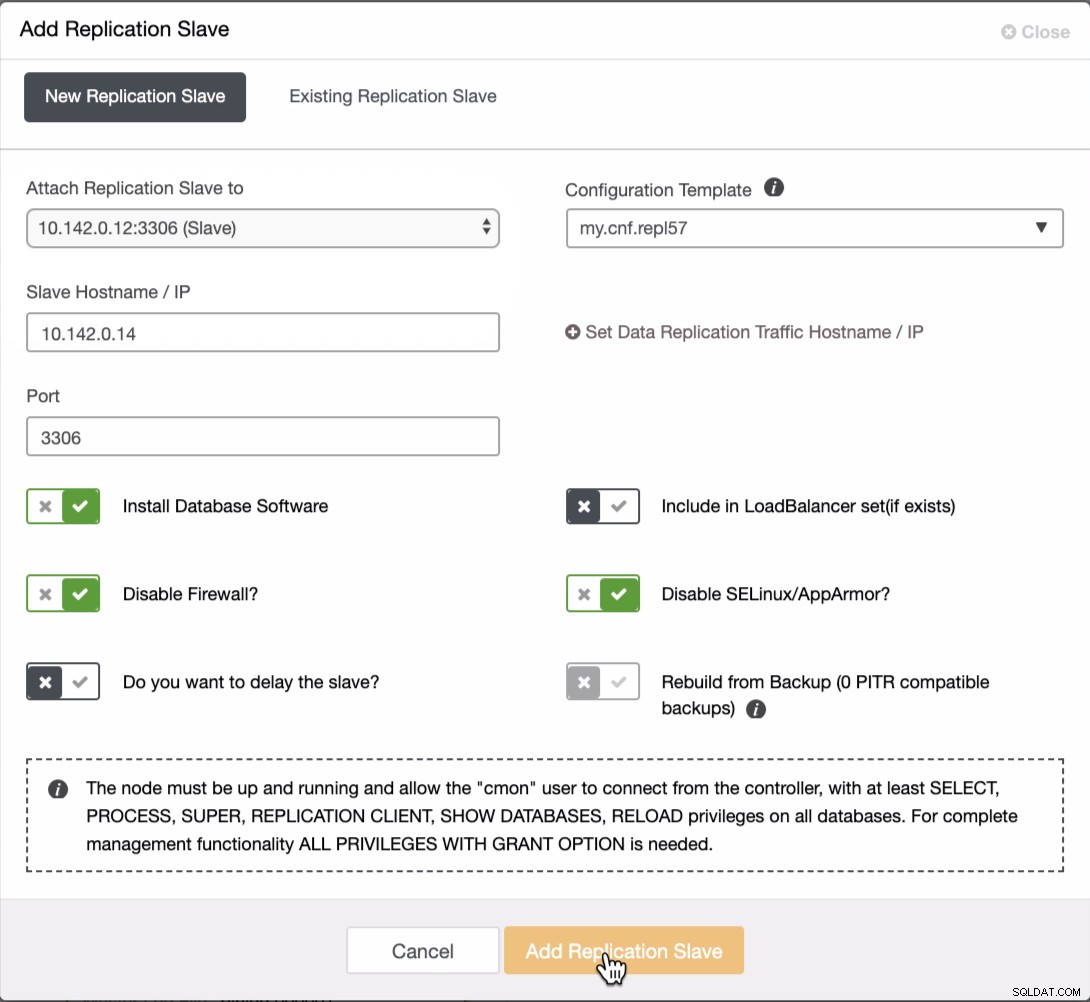
Jak widać na powyższym zrzucie ekranu, wybrałem 10.142.0.12 (slave ), który jest pierwszym węzłem, który dodaliśmy do klastra. Pełny wynik przedstawia się następująco:
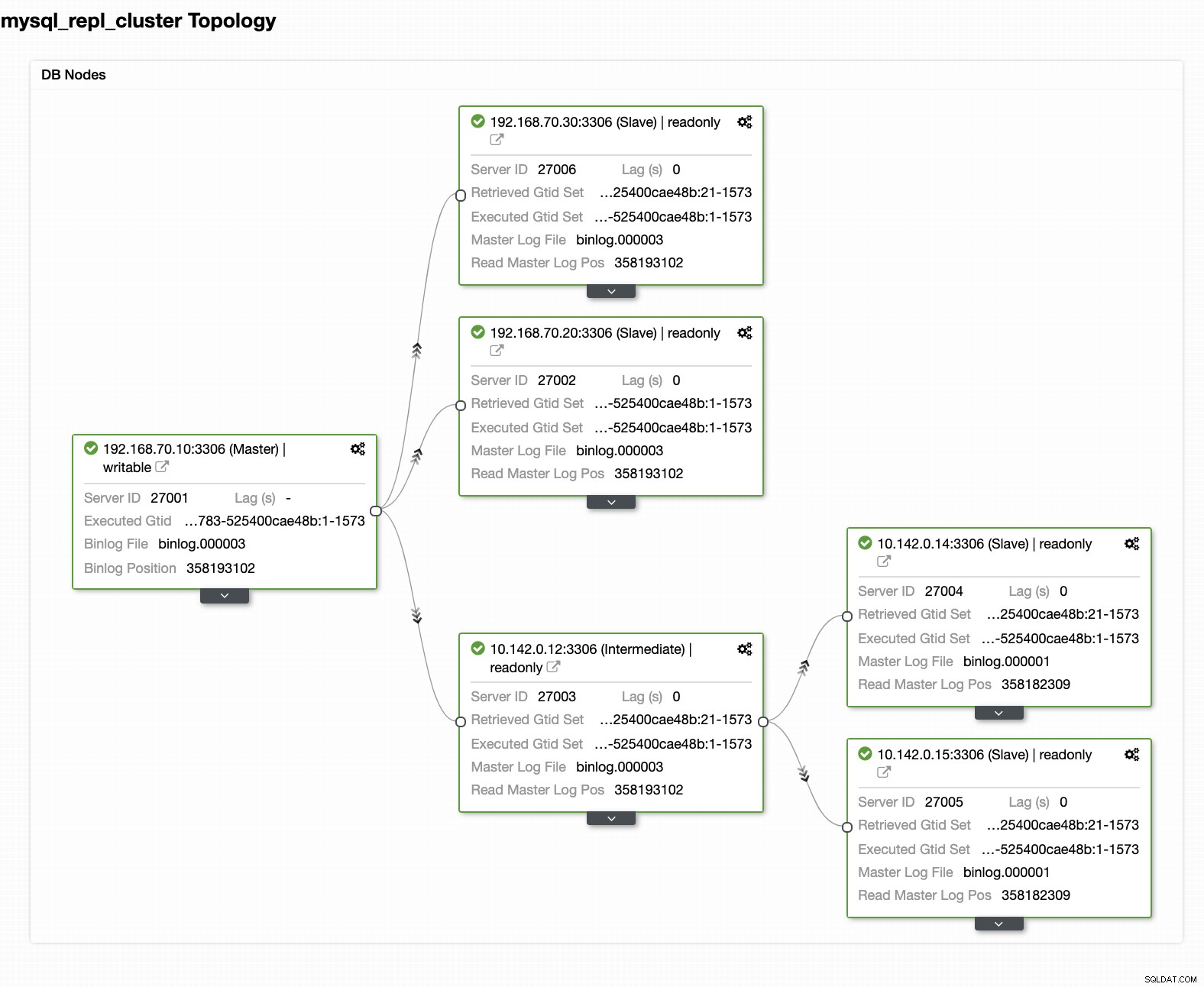
Twoja ostateczna konfiguracja klastra baz danych geolokalizacji
Z ostatniego zrzutu ekranu ten rodzaj topologii może nie być idealną konfiguracją. W większości przypadków musi to być konfiguracja z wieloma wzorcami, w której klaster DR służy jako klaster rezerwowy, a lokalny serwer służy jako podstawowy aktywny klaster. Aby to zrobić, w ClusterControl jest to dość proste. Zobacz poniższe zrzuty ekranu, aby osiągnąć ten cel.
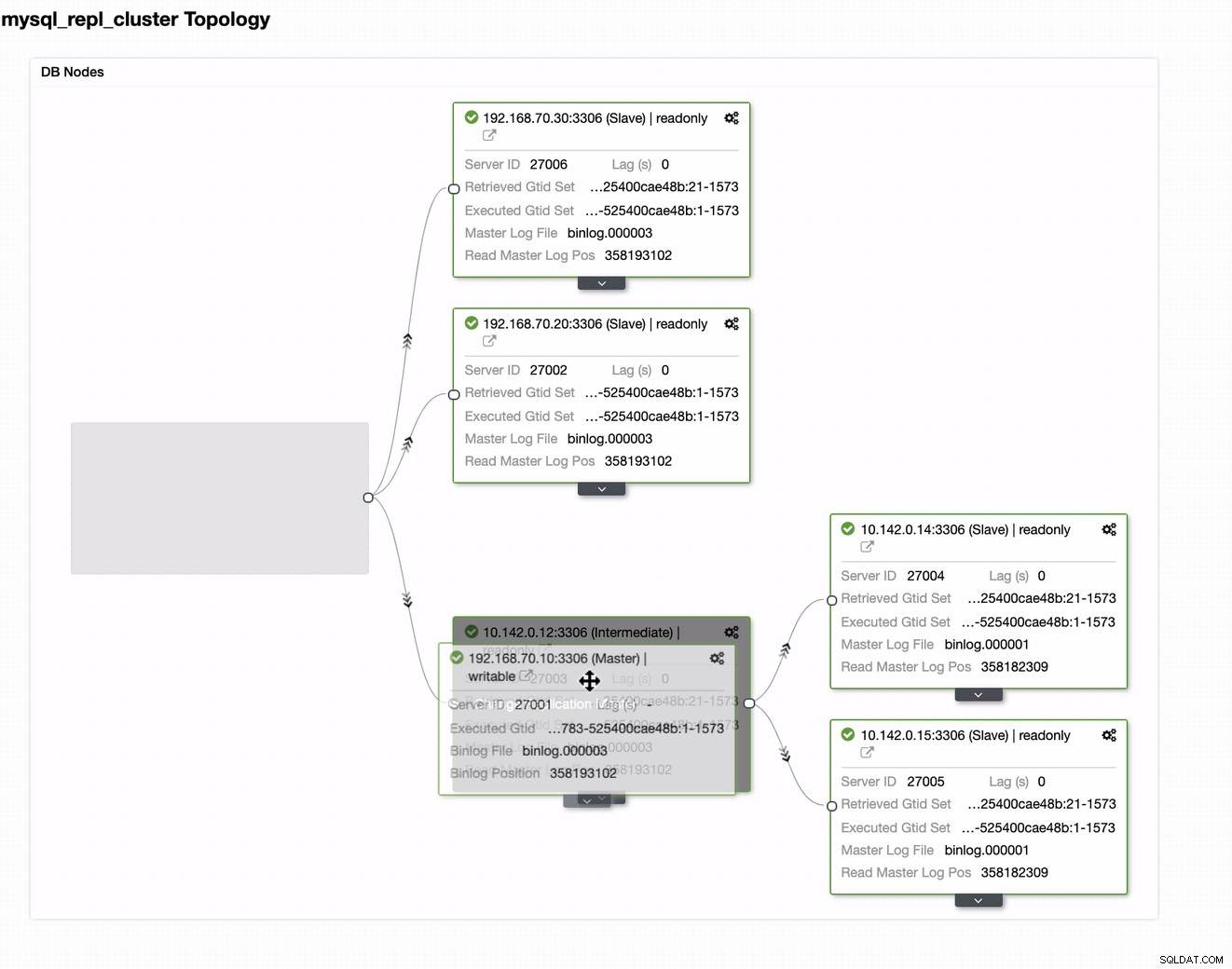
Możesz po prostu przeciągnąć obecnego wzorca do docelowego wzorca, który ma być skonfigurować jako główny pisarz rezerwowy na wypadek, gdyby Twoja lokalna sytuacja była zagrożona. W tym przykładzie przeciągamy docelowy host 10.142.0.12 (węzeł obliczeniowy GCP). Wynik końcowy pokazano poniżej:
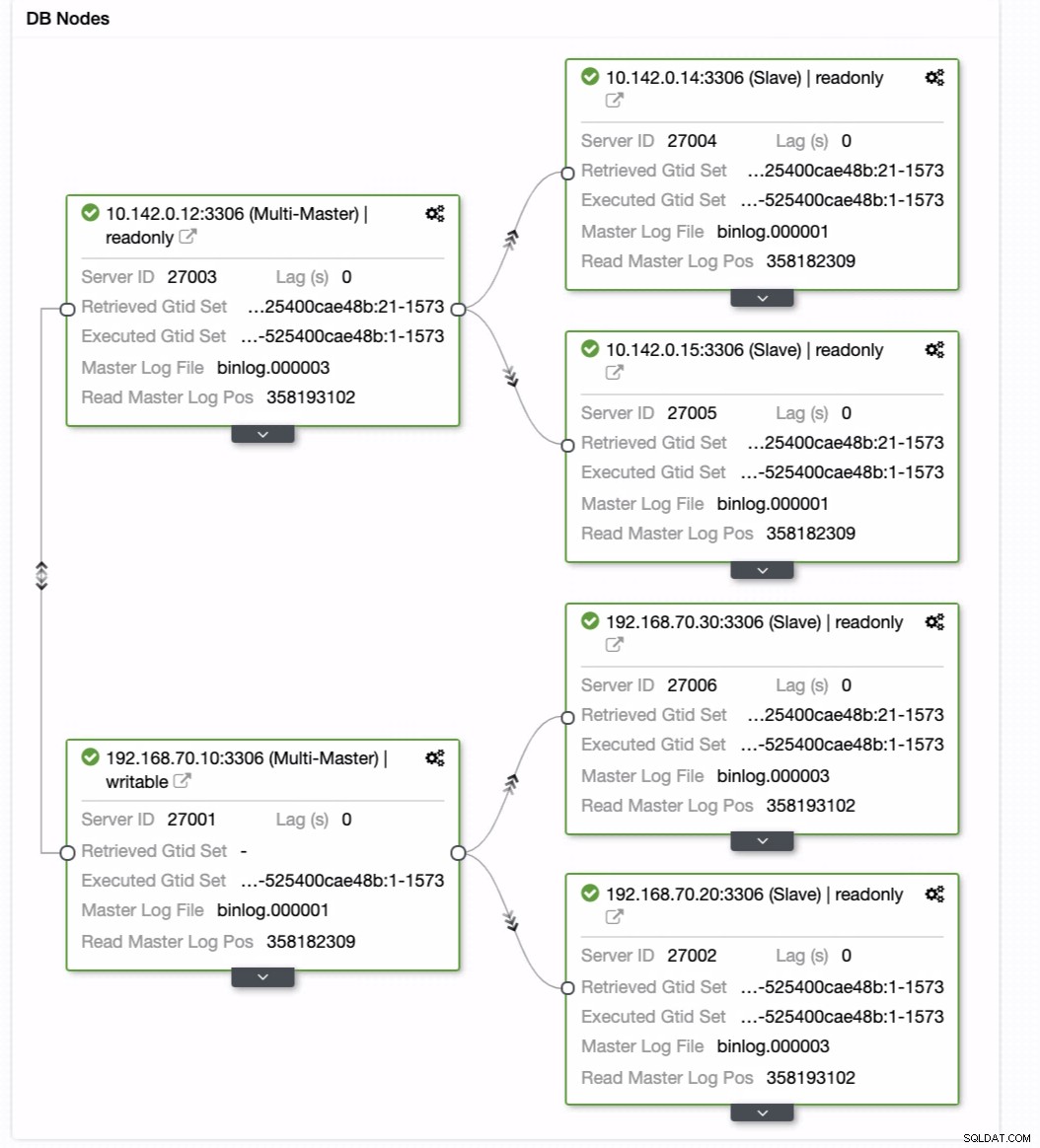
Wtedy osiąga pożądany rezultat. Łatwe i bardzo szybkie tworzenie klastra bazy danych geolokalizacji za pomocą replikacji MySQL.
Wnioski
Posiadanie klastra bazy danych geolokalizacji nie jest nowością. Jest to pożądana konfiguracja dla firm i organizacji unikających SPOF, które chcą odporności i niższego wskaźnika RPO.
Główne aspekty tej konfiguracji to bezpieczeństwo, nadmiarowość i odporność. Opisuje również wykonalność i wydajność wdrożenia nowego klastra w innym regionie geograficznym. Chociaż ClusterControl może to zaoferować, spodziewaj się, że szybciej osiągniemy więcej ulepszeń, ponieważ możesz efektywnie tworzyć z kopii zapasowej i tworzyć nowy klaster w ClusterControl, więc bądź na bieżąco.