Konfiguracja klastra replikacji master/slave jest powszechnym przypadkiem użycia w większości organizacji. Korzystanie z replikacji MySQL umożliwia replikację danych w różnych środowiskach i gwarantuje, że informacje zostaną skopiowane. Jest asynchroniczny i jednowątkowy (domyślnie), ale replikacja pozwala również skonfigurować go tak, aby był synchroniczny (a właściwie „półsynchroniczny”) i może uruchamiać wątek podrzędny w wielu wątkach lub równolegle.
Ten pomysł jest bardzo powszechny i zwykle pojawia się z prostą konfiguracją, dzięki czemu jego urządzenie podrzędne służy jako rozwiązanie do odzyskiwania lub do tworzenia kopii zapasowych. Jednak zawsze ma to swoją cenę, zwłaszcza gdy złe zapytania (takie jak brak podstawowych lub unikalnych kluczy) są replikowane lub jakieś problemy ze sprzętem (takie jak problemy z IO sieci lub dysku). W przypadku wystąpienia tych problemów najczęstszym problemem jest opóźnienie replikacji.
Opóźnienie replikacji to koszt opóźnienia transakcji lub operacji obliczony na podstawie różnicy czasu wykonania między węzłem podstawowym/głównym a węzłem rezerwowym/podrzędnym. Najbardziej pewne przypadki w MySQL polegają na replikacji błędnych zapytań, takich jak brak kluczy podstawowych lub złe indeksy, słaby sprzęt sieciowy lub nieprawidłowo działająca karta sieciowa, odległa lokalizacja między różnymi regionami lub strefami lub niektóre procesy, takie jak uruchamianie fizycznych kopii zapasowych, mogą powodować bazy danych MySQL, aby opóźnić zastosowanie bieżącej zreplikowanej transakcji. Jest to bardzo częsty przypadek podczas diagnozowania tych problemów. W tym blogu sprawdzimy, jak radzić sobie z takimi przypadkami i co zwrócić uwagę, jeśli doświadczasz opóźnienia replikacji MySQL.
„POKAŻ STATUS NIEWOLNIKA”:mantra administratora bazy danych MySQL
W niektórych przypadkach jest to srebrna kula, gdy mamy do czynienia z opóźnieniem replikacji i ujawnia głównie wszystkie przyczyny problemu w bazie danych MySQL. Po prostu uruchom tę instrukcję SQL w węźle podrzędnym, w przypadku którego istnieje podejrzenie, że występuje opóźnienie replikacji.
Początkowe pola, które są wspólne dla śledzenia problemów, to:
- Slave_IO_State - Mówi ci, co robi wątek. To pole zapewni dobry wgląd w to, czy kondycja replikacji działa normalnie, występują problemy z siecią, takie jak ponowne łączenie się z urządzeniem głównym lub zbyt dużo czasu na zatwierdzenie danych, co może wskazywać na problemy z dyskiem podczas synchronizowania danych z dyskiem. Możesz również określić tę wartość stanu podczas uruchamiania SHOW PROCESSLIST.
- Master_Log_File - Nazwa pliku logu administratora, w którym aktualnie pobierany jest wątek we/wy.
- Read_Master_Log_Pos - pozycja pliku binlog z mastera, gdzie wątek we/wy replikacji już odczytał.
- Relay_Log_File - nazwa pliku dziennika przekaźnika, dla którego wątek SQL aktualnie wykonuje zdarzenia
- Relay_Log_Pos - pozycja binlogu z pliku określonego w Relay_Log_File, dla którego wątek SQL został już wykonany.
- Relay_Master_Log_File – Plik logu binloga mastera, który wątek SQL już wykonał i jest zgodny z wartością Read_Master_Log_Pos.
- Seconds_Behind_Master – to pole pokazuje przybliżoną różnicę między bieżącym znacznikiem czasu na urządzeniu podrzędnym a znacznikiem czasu na urządzeniu głównym dla zdarzenia aktualnie przetwarzanego na urządzeniu podrzędnym. Jednak to pole może nie być w stanie podać dokładnego opóźnienia, jeśli sieć jest wolna, ponieważ bierze się pod uwagę różnicę w sekundach między podrzędnym wątkiem SQL a podrzędnym wątkiem we/wy. Mogą więc wystąpić przypadki, w których można go dogonić przez wolno czytający podrzędny wątek I/O, ale opanuję to już inaczej.
- Slave_SQL_Running_State - stan wątku SQL i wartość jest identyczna z wartością stanu wyświetlaną w POKAŻ LISTA PROCESÓW.
- Retrieved_Gtid_Set — Dostępne podczas korzystania z replikacji GTID. Jest to zestaw identyfikatorów GTID odpowiadających wszystkim transakcjom odebranym przez to urządzenie podrzędne.
- Executed_Gtid_Set — Dostępne podczas korzystania z replikacji GTID. To zestaw identyfikatorów GTID zapisanych w dzienniku binarnym.
Weźmy na przykład poniższy przykład, który używa replikacji GTID i doświadcza opóźnienia w replikacji:
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.10.70
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000038
Read_Master_Log_Pos: 826608419
Relay_Log_File: relay-bin.000004
Relay_Log_Pos: 468413927
Relay_Master_Log_File: binlog.000038
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 826608206
Relay_Log_Space: 826607743
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 251
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 45003
Master_UUID: 36272880-a7b0-11e9-9ca6-525400cae48b
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: copy to tmp table
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 36272880-a7b0-11e9-9ca6-525400cae48b:7631-9192
Executed_Gtid_Set: 36272880-a7b0-11e9-9ca6-525400cae48b:1-9191,
864dd532-a7af-11e9-85f2-525400cae48b:1-173,
df68c807-a7af-11e9-9b56-525400cae48b:1-4
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Diagnozując takie problemy, mysqlbinlog może być również Twoim narzędziem do identyfikowania, jakie zapytanie zostało uruchomione na określonej pozycji binlog x i y. Aby to ustalić, weźmy Retrieved_Gtid_Set, Relay_Log_Pos i Relay_Log_File. Zobacz polecenie poniżej:
[example@sqldat.com mysql]# mysqlbinlog --base64-output=DECODE-ROWS --include-gtids="36272880-a7b0-11e9-9ca6-525400cae48b:9192" --start-position=468413927 -vvv relay-bin.000004
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @example@sqldat.com@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 468413927
#200206 4:36:14 server id 45003 end_log_pos 826608271 CRC32 0xc702eb4c GTID last_committed=1562 sequence_number=1563 rbr_only=no
SET @@SESSION.GTID_NEXT= '36272880-a7b0-11e9-9ca6-525400cae48b:9192'/*!*/;
# at 468413992
#200206 4:36:14 server id 45003 end_log_pos 826608419 CRC32 0xe041ec2c Query thread_id=24 exec_time=31 error_code=0
use `jbmrcd_date`/*!*/;
SET TIMESTAMP=1580963774/*!*/;
SET @@session.pseudo_thread_id=24/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
ALTER TABLE NewAddressCode ADD INDEX PostalCode(PostalCode)
/*!*/;
SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/;
DELIMITER ;
# End of log file
/*!50003 SET example@sqldat.com_COMPLETION_TYPE*/;
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;Informuje nas, że próbował zreplikować i wykonać instrukcję DML, która próbuje być źródłem opóźnienia. Ta tabela to ogromny stół zawierający 13 milionów wierszy.
Sprawdź SHOW PROCESSLIST, SHOW ENGINE INNODB STATUS, za pomocą kombinacji poleceń ps, top, iostat
W niektórych przypadkach POKAŻ STATUS SLAVE nie wystarczy, aby powiedzieć nam winowajcę. Możliwe, że na zreplikowane instrukcje mają wpływ procesy wewnętrzne uruchomione w module podrzędnym bazy danych MySQL. Uruchamianie instrukcji SHOW [FULL] PROCESSLIST i SHOW ENGINE INNODB STATUS dostarcza również danych informacyjnych, które dają wgląd w źródło problemu.
Załóżmy na przykład, że narzędzie do testów porównawczych jest uruchomione, powodując nasycenie operacji we/wy dysku i procesora. Możesz to sprawdzić, uruchamiając obie instrukcje SQL. Połącz to z poleceniami ps i top.
Możesz także określić wąskie gardła w pamięci dyskowej, uruchamiając iostat, który zapewnia statystyki bieżącego woluminu, który próbujesz zdiagnozować. Uruchomiony iostat może pokazać, jak zajęty lub obciążony jest twój serwer. Na przykład, zrobione przez urządzenie podrzędne, które jest opóźnione, ale jednocześnie doświadcza wysokiego wykorzystania IO,
[example@sqldat.com ~]# iostat -d -x 10 10
Linux 3.10.0-693.5.2.el7.x86_64 (testnode5) 02/06/2020 _x86_64_ (2 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.42 3.71 60.65 218.92 568.39 24.47 0.15 2.31 13.79 1.61 0.12 0.76
dm-0 0.00 0.00 3.70 60.48 218.73 568.33 24.53 0.15 2.36 13.85 1.66 0.12 0.76
dm-1 0.00 0.00 0.00 0.00 0.04 0.01 21.92 0.00 63.29 2.37 96.59 22.64 0.01
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.20 392.30 7983.60 2135.60 49801.55 12.40 36.70 3.84 13.01 3.39 0.08 69.02
dm-0 0.00 0.00 392.30 7950.20 2135.60 50655.15 12.66 36.93 3.87 13.05 3.42 0.08 69.34
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.06 183.67 0.00 183.67 61.67 1.85
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.40 370.93 6775.42 2557.04 46184.22 13.64 43.43 6.12 11.60 5.82 0.10 73.25
dm-0 0.00 0.00 370.93 6738.76 2557.04 47029.62 13.95 43.77 6.20 11.64 5.90 0.10 73.41
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.03 107.00 0.00 107.00 35.67 1.07
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 299.80 7253.35 1916.88 52766.38 14.48 30.44 4.59 15.62 4.14 0.10 72.09
dm-0 0.00 0.00 299.80 7198.60 1916.88 51064.24 14.13 30.68 4.66 15.70 4.20 0.10 72.57
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.10 215.50 8939.60 1027.60 67497.10 14.97 59.65 6.52 27.98 6.00 0.08 72.50
dm-0 0.00 0.00 215.50 8889.20 1027.60 67495.90 15.05 60.07 6.60 28.09 6.08 0.08 72.75
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.01 32.33 0.00 32.33 30.33 0.91
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.90 140.40 8922.10 625.20 54709.80 12.21 11.29 1.25 9.88 1.11 0.08 68.60
dm-0 0.00 0.00 140.40 8871.50 625.20 54708.60 12.28 11.39 1.26 9.92 1.13 0.08 68.83
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.01 27.33 0.00 27.33 9.33 0.28
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.70 284.50 8621.30 24228.40 51535.75 17.01 34.14 3.27 8.19 3.11 0.08 72.78
dm-0 0.00 0.00 290.90 8587.10 25047.60 53434.95 17.68 34.28 3.29 8.02 3.13 0.08 73.47
dm-1 0.00 0.00 0.00 2.00 0.00 8.00 8.00 0.83 416.45 0.00 416.45 63.60 12.72
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.30 851.60 11018.80 17723.60 85165.90 17.34 142.59 12.44 7.61 12.81 0.08 99.75
dm-0 0.00 0.00 845.20 10938.90 16904.40 83258.70 17.00 143.44 12.61 7.67 12.99 0.08 99.75
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 1.10 24.60 12965.40 420.80 51114.45 7.93 39.44 3.04 0.33 3.04 0.07 93.39
dm-0 0.00 0.00 24.60 12890.20 420.80 51114.45 7.98 40.23 3.12 0.33 3.12 0.07 93.35
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 3.60 13420.70 57.60 51942.00 7.75 0.95 0.07 0.33 0.07 0.07 92.11
dm-0 0.00 0.00 3.60 13341.10 57.60 51942.00 7.79 0.95 0.07 0.33 0.07 0.07 92.08
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00Powyższy wynik wyświetla wysokie wykorzystanie we/wy i dużą liczbę zapisów. Ujawnia również, że średni rozmiar kolejki i średni rozmiar żądań zmieniają się, co oznacza, że jest to oznaka dużego obciążenia pracą. W takich przypadkach musisz określić, czy istnieją zewnętrzne procesy, które powodują, że MySQL blokuje wątki replikacji.
Jak ClusterControl może pomóc?
Dzięki ClusterControl radzenie sobie z opóźnieniem niewolników i określanie winowajcy jest bardzo łatwe i wydajne. Mówi bezpośrednio w interfejsie internetowym, patrz poniżej:
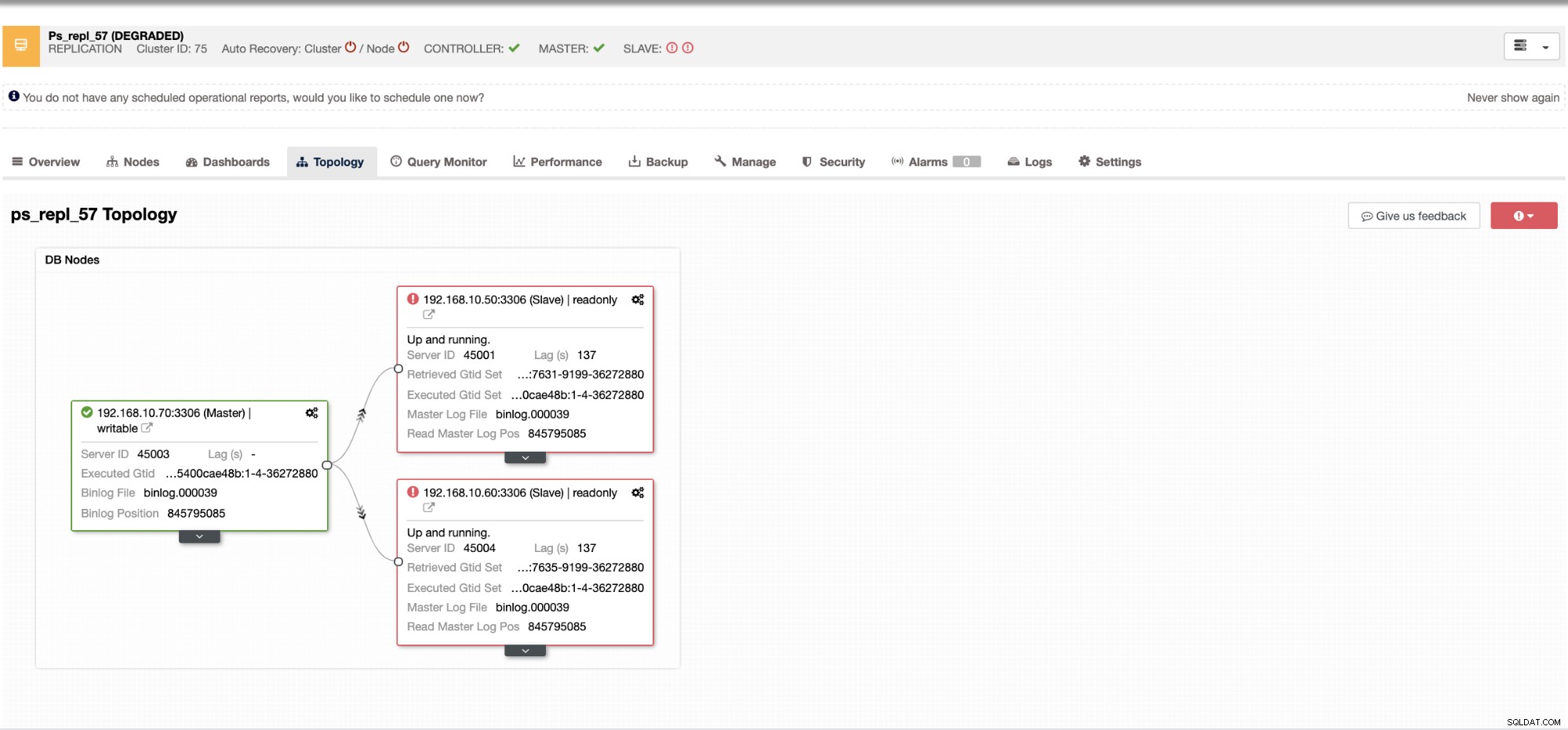
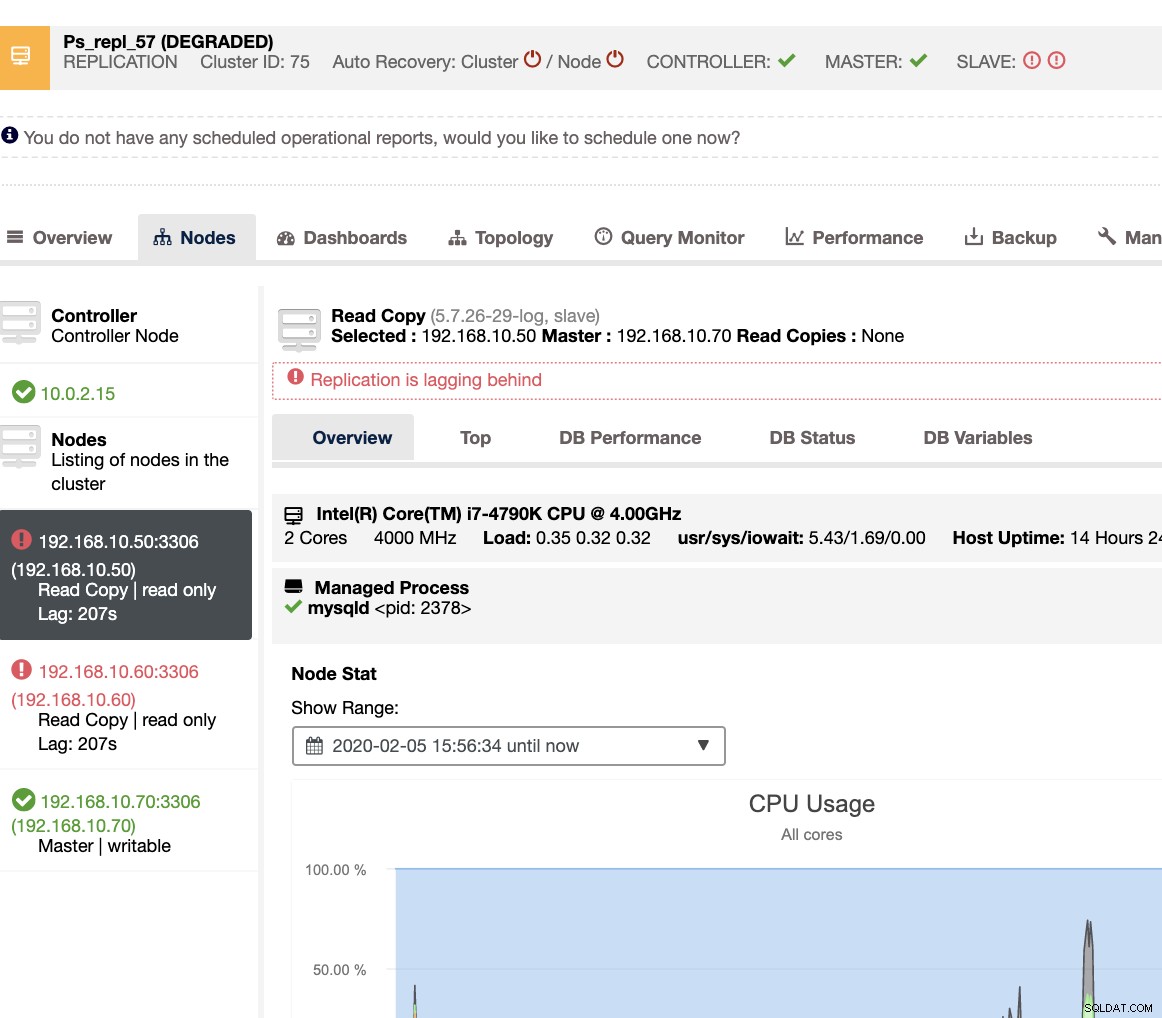
Ujawnia to, jakie jest aktualne opóźnienie, którego doświadczają twoje węzły podrzędne. Co więcej, dzięki pulpitom nawigacyjnym SCUMM, jeśli są włączone, uzyskasz więcej informacji na temat kondycji węzła podrzędnego, a nawet całego klastra:
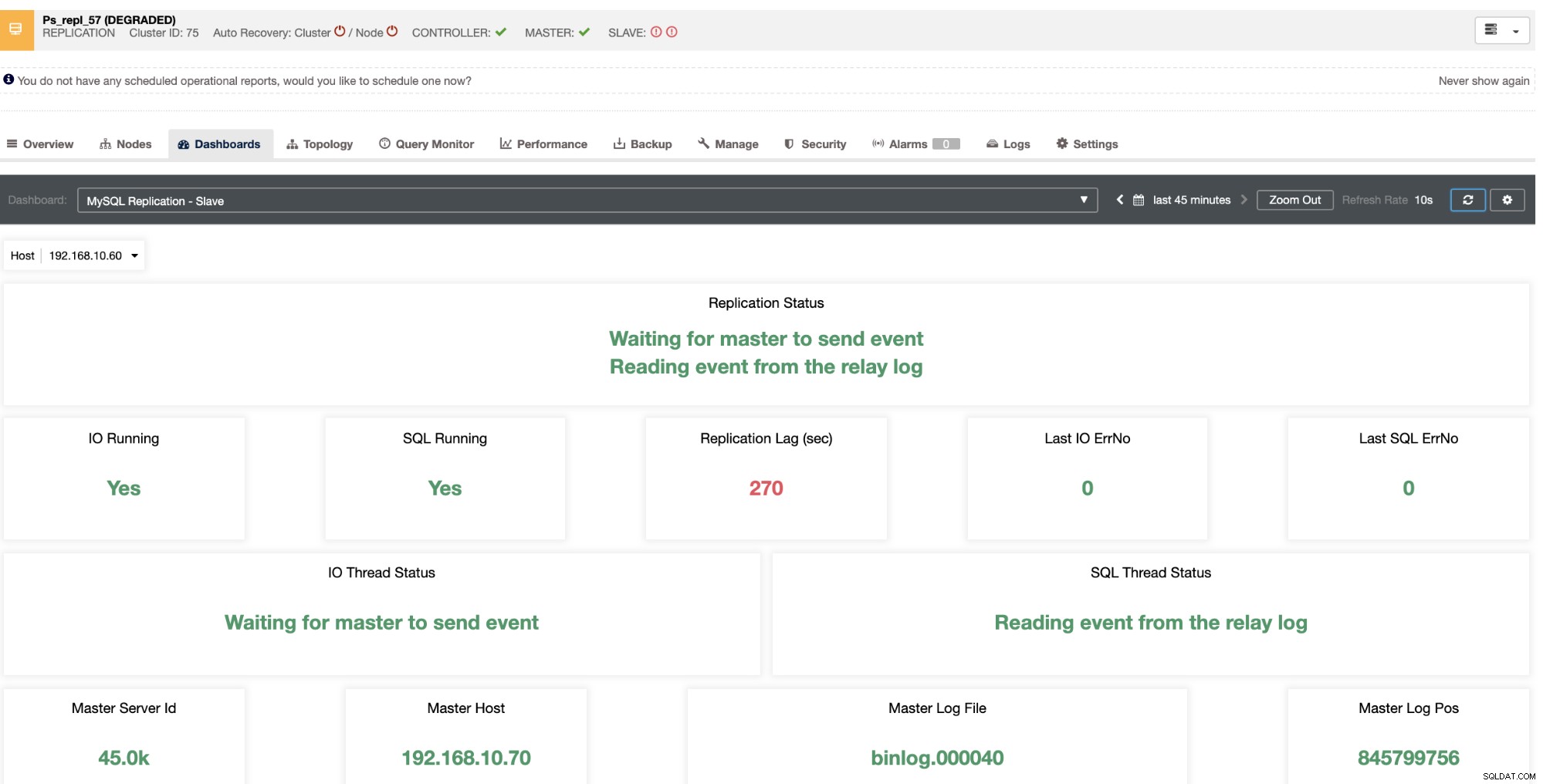


Nie tylko, że te rzeczy są dostępne w ClusterControl, ale także możliwość uniknięcia złych zapytań z tymi funkcjami, jak widać poniżej,
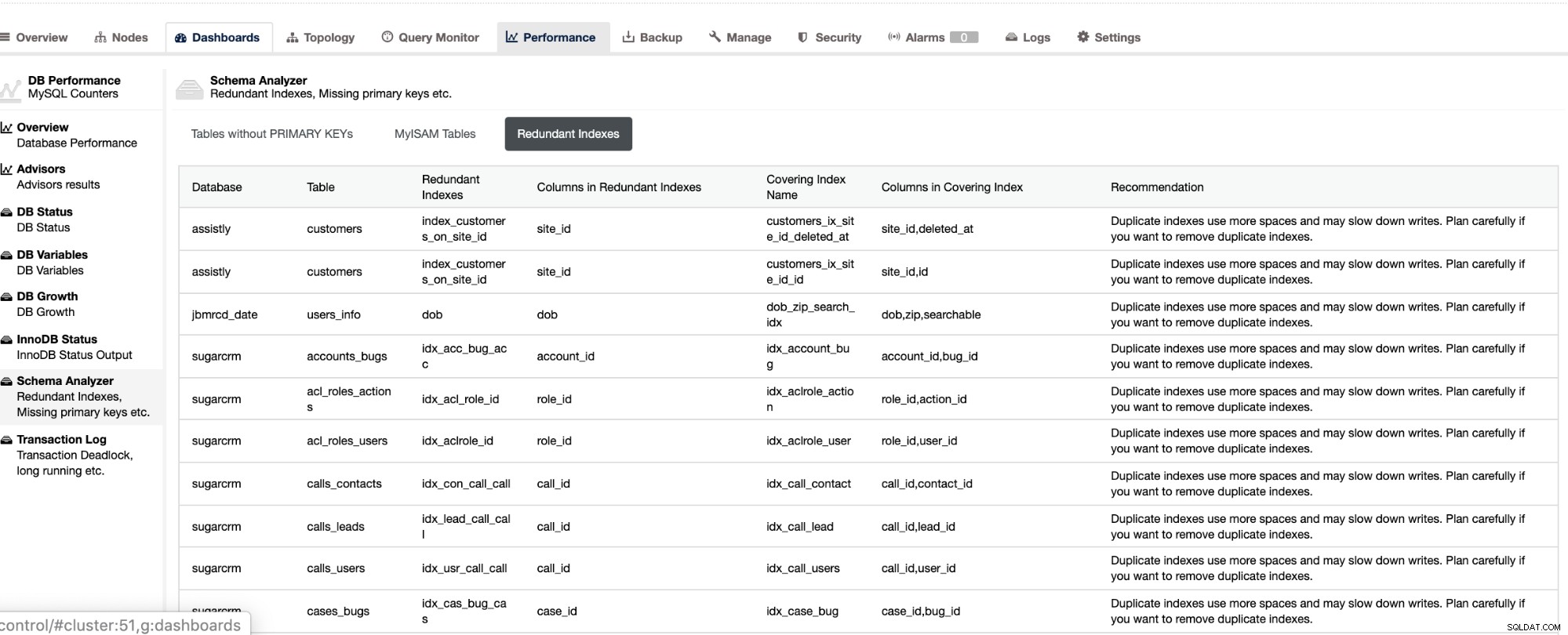
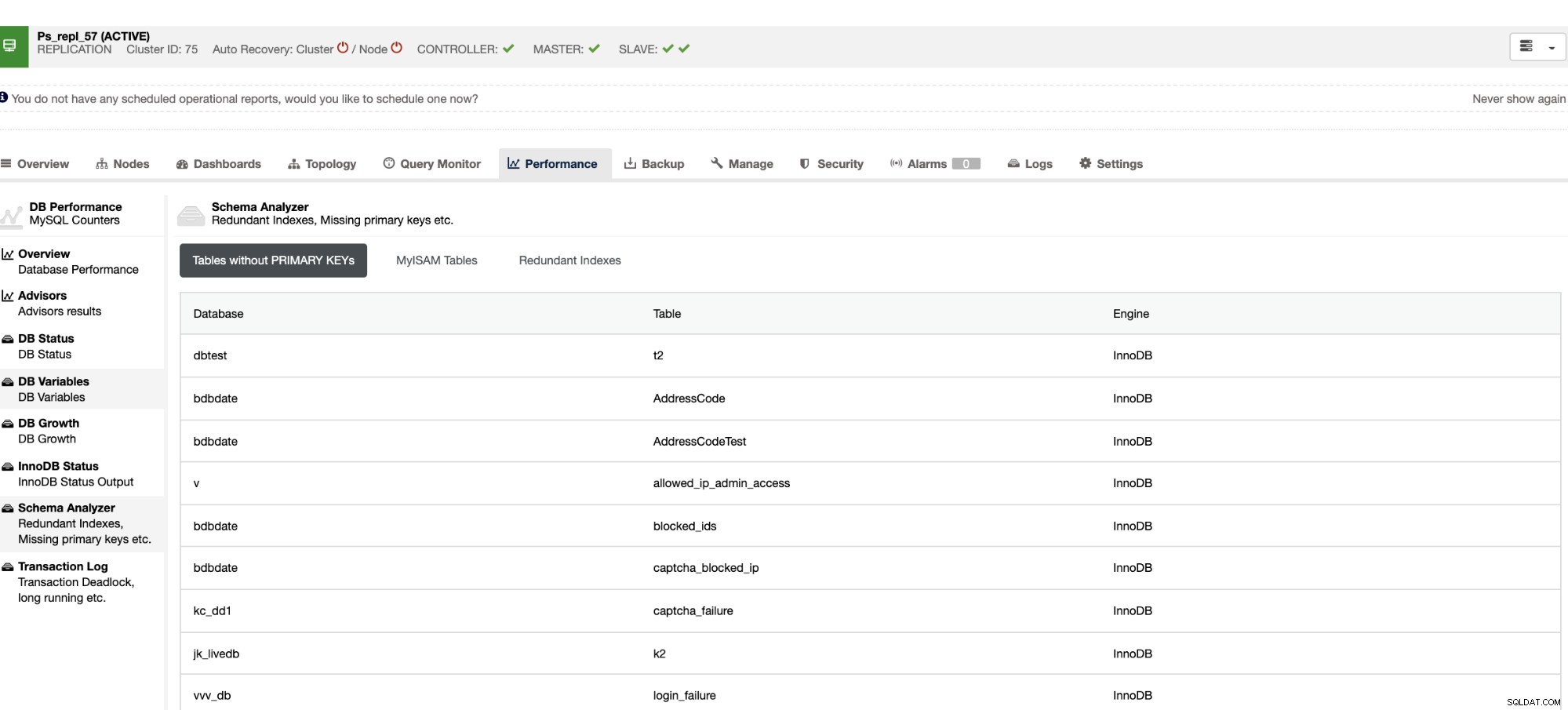
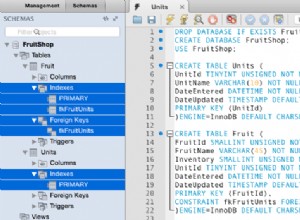
Zbędne indeksy pozwalają określić, że te indeksy mogą powodować problemy z wydajnością zapytania przychodzące, które odwołują się do zduplikowanych indeksów. Informuje również tabele, które nie mają kluczy podstawowych, które są zwykle częstym problemem opóźnienia slave, gdy pewne zapytanie SQL lub transakcje, które odwołują się do dużych tabel bez kluczy podstawowych lub unikalnych, gdy są replikowane do urządzeń podrzędnych.
Wnioski
Radzenie sobie z opóźnieniem replikacji MySQL jest częstym problemem w konfiguracji replikacji typu master-slave. To może być łatwe do zdiagnozowania, ale trudne do rozwiązania. Upewnij się, że masz tabele z kluczem podstawowym lub kluczem unikalnym, a następnie określ kroki i narzędzia, jak rozwiązywać problemy i diagnozować przyczynę opóźnienia podrzędnego. Wydajność jest jednak zawsze kluczem do rozwiązywania problemów.