InnoDB to jeden z najczęściej używanych silników pamięci masowej w MySQL. Ten silnik pamięci masowej jest znany jako silnik pamięci masowej o wysokiej niezawodności i wysokiej wydajności, a jego główne zalety obejmują obsługę blokowania na poziomie wiersza, kluczy obcych i zgodność z modelem ACID. InnoDB zastępuje MyISAM jako domyślny silnik pamięci masowej od MySQL 5.5, który został wydany w 2010 roku.
Ten silnik pamięci masowej może być niezwykle wydajny i potężny, jeśli zostanie odpowiednio zoptymalizowany — dzisiaj przyjrzymy się temu, co możemy zrobić, aby działał jak najlepiej, ale zanim zaczniemy nurkować jednak do InnoDB, powinniśmy zrozumieć, czym jest wspomniany model ACID.
Co to jest KWAS i dlaczego jest to ważne?
ACID to zestaw właściwości transakcji bazodanowych. Akronim oznacza cztery słowa:atomowość, spójność, izolacja i trwałość. Krótko mówiąc, właściwości te zapewniają niezawodne przetwarzanie transakcji w bazie danych i gwarantują poprawność danych pomimo błędów, przerw w dostawie prądu lub innych tego typu problemów. Mówi się, że system zarządzania bazą danych, który jest zgodny z tymi zasadami, jest systemem DBMS zgodnym z ACID. Oto jak wszystko działa w InnoDB:
- Atomity zapewnia, że oświadczenia w transakcji działają jako niepodzielna jednostka i że ich skutki są postrzegane łącznie lub wcale;
- Spójność jest obsługiwana przez mechanizmy rejestrowania MySQL, które rejestrują wszystkie zmiany w bazie danych;
- Izolacja odnosi się do blokowania na poziomie wiersza InnoDB;
- Trwałość jest również utrzymywana, ponieważ InnoDB przechowuje plik dziennika, który śledzi wszystkie zmiany w systemie.
Zrozumienie InnoDB
Teraz, gdy omówiliśmy ACID, powinniśmy prawdopodobnie przyjrzeć się, jak InnoDB wygląda pod maską. Oto jak InnoDB wygląda od środka (zdjęcie dzięki uprzejmości Percony):
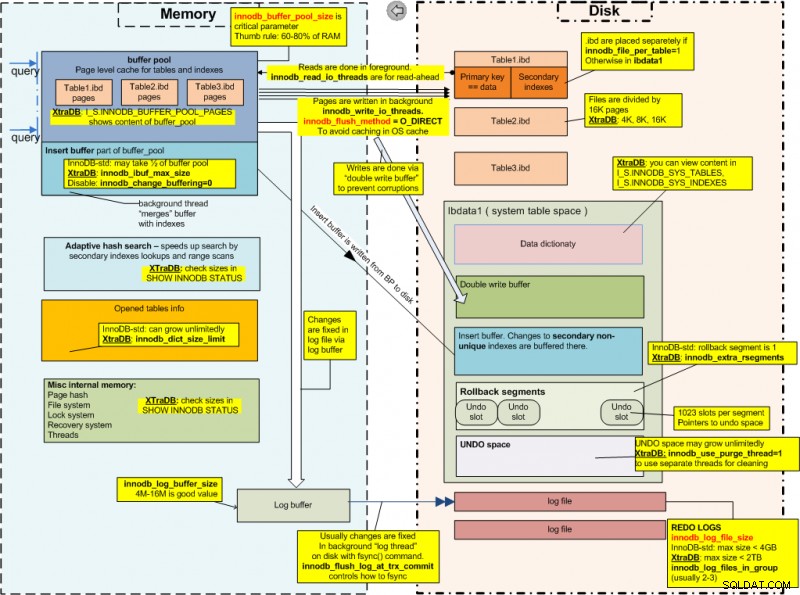 InnoDB Internals
InnoDB InternalsZ powyższego obrazka wyraźnie widać, że InnoDB ma kilka parametry kluczowe dla jego wydajności, a są to:
- Parametr innodb_data_file_path opisuje systemowy obszar tabel (systemowy obszar tabel to obszar przechowywania słownika danych InnoDB, podwójnych buforów zapisu i zmian oraz dzienników cofania). Parametr przedstawia plik, w którym będą przechowywane dane pochodzące z tabel InnoDB;
- Parametr innodb_buffer_pool_size to bufor pamięci, którego InnoDB używa do buforowania danych i indeksów swoich tabel;
- Parametr innodb_log_file_size przedstawia rozmiar plików dziennika InnoDB;
- Parametr innodb_log_buffer_size służy do zapisu do plików dziennika na dysku;
- Parametr innodb_flush_log_at_trx_commit kontroluje równowagę między ścisłą zgodnością z ACID a wyższą wydajnością;
- Parametr innodb_lock_wait_timeout to czas w sekundach, przez który transakcja InnoDB czeka na blokadę wiersza przed poddaniem się;
- Parametr innodb_flush_method definiuje metodę używaną do opróżniania danych do plików danych i dzienników InnoDB, które mogą wpływać na przepustowość we/wy.
InnoDB przechowuje również dane ze swoich tabel w pliku o nazwie ibdata1 - logi są jednak przechowywane w dwóch oddzielnych plikach o nazwach ib_logfile0 i ib_logfile1:wszystkie te trzy pliki znajdują się w /var/lib/mysql informator.
Aby uczynić InnoDB tak wydajnym, jak to tylko możliwe, musimy dostroić te parametry i maksymalnie je zoptymalizować, patrząc na dostępne zasoby sprzętowe.
Dostrajanie InnoDB pod kątem wysokiej wydajności
Aby dostosować wydajność InnoDB na swoim sprzęcie, wykonaj następujące kroki:
-
Aby automatycznie rozszerzyć innodb_data_file_path, określ atrybut autoextend w ustawieniu i zrestartuj serwer. Na przykład:
innodb_data_file_path=ibdata1:10M:autoextendGdy używany jest parametr autoextend, plik danych automatycznie zwiększa rozmiar o 8 MB za każdym razem, gdy wymagana jest przestrzeń. Można również określić nowy automatycznie rozszerzający się plik danych w ten sposób (w tym przypadku nowy plik danych nazywa się ibdata2):
innodb_data_file_path=ibdata1:10M;ibdata2:10M:autoextend-
Podczas korzystania z InnoDB głównym używanym mechanizmem jest pula buforów. InnoDB w dużym stopniu opiera się na puli buforów i z reguły parametr innodb_buffer_pool_size powinien stanowić około 60% do 80% całkowitej dostępnej pamięci RAM na serwerze. Pamiętaj, że powinieneś zostawić trochę pamięci RAM dla procesów działających w systemie operacyjnym;
-
Rozmiar innodb_log_file_size InnoDB powinien być ustawiony tak duży, jak to możliwe, ale nie większy niż to konieczne. W takim przypadku należy pamiętać, że większy rozmiar pliku dziennika jest lepszy dla wydajności, ale im jest większy, tym dłuższy jest czas odzyskiwania po awarii. W związku z tym nie ma rozwiązania „jeden rozmiar dla wszystkich”, ale mówi się, że łączny rozmiar plików dziennika powinien być wystarczająco duży. Pomaga to serwerowi MySQL w regularnej pracy nad czynnościami kontrolnymi i opróżnianiem dysku. Oszczędza to zbyt dużo procesora i we/wy dysku i może działać płynnie w godzinach szczytu lub przy dużym obciążeniu. Chociaż zalecanym podejściem jest samodzielne przetestowanie i eksperymentowanie oraz samodzielne znalezienie optymalnej wartości;
-
Wartość innodb_log_buffer_size powinna być ustawiona na co najmniej 16M. Duży bufor dziennika umożliwia uruchamianie dużych transakcji bez konieczności zapisywania dziennika na dysku przed zapisaniem niektórych operacji we/wy na dysku;
-
Podczas strojenia innodb_flush_log_at_trx_commit należy pamiętać, że ten parametr akceptuje trzy wartości - 0, 1 i 2. Przy wartości 1 uzyskuje się zgodność z ACID a przy wartościach 0 lub 2 uzyskujesz większą wydajność, ale mniejszą niezawodność, ponieważ w takim przypadku transakcje, dla których logi nie zostały jeszcze opróżnione na dysk, mogą zostać utracone w wyniku awarii;
-
Aby ustawić innodb_lock_wait_timeout na właściwą wartość, należy pamiętać, że ten parametr określa czas w sekundach (wartość domyślna to 50) przed wystawienie następującego błędu i wycofanie aktualnej instrukcji:
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction-
W InnoDB dostępnych jest wiele metod opróżniania. Domyślnie to ustawienie jest ustawione na „async_unbuffered” na komputerach z systemem Windows, jeśli wartość jest ustawiona na NULL i na „fsync” na komputerach z systemem Linux. Oto, jakie są metody i co robią:
| Metoda opróżniania InnoDB | Cel |
| normalny | InnoDB użyje symulowanych asynchronicznych we/wy i buforowanych we/wy. |
| niebuforowane | InnoDB użyje symulowanych asynchronicznych we/wy i niebuforowanych we/wy. |
| async_unbuffered | InnoDB będzie używać asynchronicznych operacji we/wy systemu Windows i niebuforowanych operacji we/wy. Ustawienia domyślne na komputerach z systemem Windows. |
| fsync | InnoDB użyje funkcji fsync() do usunięcia danych i plików dziennika. Ustawienie domyślne na komputerach z systemem Linux. |
| O_DSYNC | InnoDB użyje O_SYNC do otwierania i opróżniania plików dziennika oraz funkcji fsync() do opróżniania plików danych. O_DSYNC jest szybszy niż O_DIRECT, ale dane mogą, ale nie muszą być spójne z powodu opóźnienia lub całkowitej awarii. |
| nosync | Używane do wewnętrznych testów wydajności — nieobsługiwane. |
| littlesync | Używane do wewnętrznych testów wydajności — nieobsługiwane. |
| O_DIRECT | InnoDB użyje O_DIRECT do otwarcia plików danych i funkcji fsync() do opróżnienia zarówno danych, jak i plików dziennika. W porównaniu z O_DSYNC, O_DIRECT jest bardziej stabilny i bardziej spójny dla danych, ale wolniej. Dzięki temu ustawieniu unika się pamięci podręcznej systemu operacyjnego — to ustawienie jest zalecane na komputerach z systemem Linux. |
| O_DIRECT_NO_FSYNC | InnoDB użyje O_DIRECT podczas opróżniania I/O - część „NO_FSYNC” określa, że funkcja fsync() zostanie pominięta. |
- Należy również rozważyć włączenie ustawienia innodb_file_per_table. Ten parametr jest domyślnie włączony w MySQL 5.6 i nowszych. Ten parametr zwalnia Cię z problemów związanych z zarządzaniem tabelami InnoDB, przechowując je w oddzielnych plikach i unikając przerostu głównych słowników i tabel systemowych. Włączenie tej zmiennej pozwala również uniknąć złożoności odzyskiwania danych, gdy pewna tabela jest uszkodzona
- Teraz, gdy zmodyfikowałeś te ustawienia zgodnie z instrukcjami przedstawionymi powyżej, powinieneś być prawie gotowy do pracy! Zanim jednak zaczniesz działać, prawdopodobnie powinieneś mieć oko na najbardziej zajęty plik w całej infrastrukturze InnoDB - ibdata1.
Radzenie się z ibdata1
Istnieje kilka klas informacji przechowywanych w ibdata1:
- Dane tabel InnoDB;
- Indeksy tabel InnoDB;
- Metadane tabeli InnoDB;
- Dane Multiversion Concurrency Control (MVCC);
- Bufor podwójnego zapisu - taki bufor umożliwia InnoDB odzyskiwanie ze stron zapisanych w połowie. Celem takiego bufora jest zapobieganie uszkodzeniu danych;
- Bufor wstawiania - taki bufor jest używany przez InnoDB do buforowania aktualizacji na tej samej stronie, dzięki czemu mogą być wykonywane od razu, a nie jedna po drugiej.
Kiedy mamy do czynienia z dużymi zestawami danych, plik ibdata1 może stać się bardzo duży i może to być sedno bardzo frustrującego problemu - plik może się tylko powiększać i domyślnie nie może się zmniejszać. Możesz zamknąć MySQL i usunąć ten plik, ale nie jest to zalecane, chyba że wiesz, co robisz. Po usunięciu MySQL nie będzie działał poprawnie, ponieważ słownik i tabele systemowe znikną, przez co główna tabela systemowa jest uszkodzona.
Aby raz na zawsze zmniejszyć ibdata1, wykonaj następujące kroki:
- Zrzuć wszystkie dane z baz danych InnoDB. Możesz użyć mysqldump lub mysqlpump do tej akcji;
- Upuść wszystkie bazy danych z wyjątkiem baz danych mysql, performance_schema i information_schema;
- Zatrzymaj MySQL;
- Dodaj następujące elementy do pliku my.cnf:
[mysqld] innodb_file_per_table = 1 innodb_flush_method = O_DIRECT innodb_log_file_size = 25% of innodb_buffer_pool_size innodb_buffer_pool_size = up to 60-80% of available RAM. - Usuń pliki ibdata1 i ib_logfile* (zostaną odtworzone przy następnym ponownym uruchomieniu MySQL);
- Uruchom MySQL i przywróć dane ze zrzutu, który zrobiłeś wcześniej. Po wykonaniu powyższych kroków plik ibdata1 będzie nadal rósł, ale nie będzie już zawierał danych z tabel InnoDB - plik będzie zawierał tylko metadane, a każda tabela InnoDB będzie istniała poza ibdata1. Teraz, jeśli przejdziesz do katalogu /var/lib/mysql, zobaczysz dwa pliki reprezentujące każdą tabelę, którą masz z silnikiem InnoDB. Pliki będą wyglądać tak:
- zdejmowalny.frm
- demotable.ibd
Plik .frm zawiera nagłówek mechanizmu pamięci masowej, a plik .ibd zawiera dane i indeksy tabeli.
Zanim jednak wprowadzisz zmiany, dostosuj parametry do swojej infrastruktury. Te parametry mogą zwiększyć lub zmniejszyć wydajność InnoDB, więc miej je na oku przez cały czas. Teraz powinieneś być gotowy!
Podsumowanie
Podsumowując, optymalizacja wydajności InnoDB może być wielką korzyścią, jeśli tworzysz aplikacje, które wymagają jednocześnie integralności danych i wysokiej wydajności - InnoDB pozwala zmienić ilość pamięci, którą silnik może zużywać, aby zmienić rozmiar pliku dziennika, metodę opróżniania używaną przez silnik itd. - te zmiany mogą sprawić, że InnoDB będzie działać wyjątkowo dobrze, jeśli zostaną odpowiednio dostrojone. Jednak przed wprowadzeniem jakichkolwiek ulepszeń uważaj na konsekwencje swoich działań zarówno dla serwera, jak i MySQL.
Jak zawsze, przed optymalizacją czegokolwiek pod kątem wydajności zawsze wykonuj (i testuj!) kopie zapasowe, aby w razie potrzeby móc przywrócić dane i zawsze testować wszelkie zmiany na lokalnym serwerze przed wdrożeniem zmian w środowisku produkcyjnym.