Jest to trzecia z pięcioczęściowej serii, w której szczegółowo zagłębiamy się w sposób, w jaki rozpoczynają się równoległe plany SQL Server w trybie wiersza. Część 1 zainicjowała kontekst wykonania zero dla zadania nadrzędnego, a część 2 utworzyła drzewo skanowania zapytań. Jesteśmy teraz gotowi do rozpoczęcia skanowania zapytań, wykonaj kilka wczesnej fazy przetwarzania i rozpocznij pierwsze dodatkowe zadania równoległe.
Rozpoczęcie skanowania zapytań
Przypomnij sobie, że tylko zadanie nadrzędne istnieje już teraz, a giełdy (operatorzy równoległości) mają tylko stronę konsumencką. Jednak to wystarczy, aby rozpocząć wykonywanie zapytania w wątku roboczym zadania nadrzędnego. Procesor zapytań rozpoczyna wykonywanie, rozpoczynając proces skanowania zapytań poprzez wywołanie CQueryScan::StartupQuery . Przypomnienie planu (kliknij, aby powiększyć):
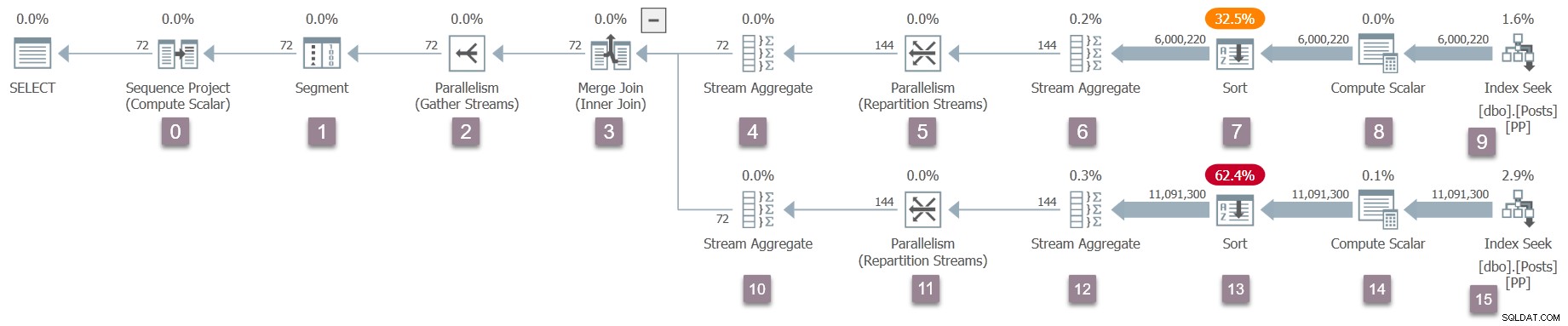
Jest to jak dotąd pierwszy punkt w procesie, w którym plan wykonania w locie jest dostępny (od wersji SQL Server 2016 SP1) w sys.dm_exec_query_statistics_xml . Na tym etapie nie ma nic szczególnie interesującego do zobaczenia w takim planie, ponieważ wszystkie liczniki przejściowe wynoszą zero, ale plan jest co najmniej dostępny . Nic nie wskazuje na to, że równoległe zadania nie zostały jeszcze stworzone, albo że na giełdach brakuje strony producenta. Plan wygląda „normalnie” pod każdym względem.
Równoległe gałęzie planu
Ponieważ jest to plan równoległy, przydatne będzie pokazanie go w rozbiciu na gałęzie. Są one zacieniowane poniżej i oznaczone jako gałęzie od A do D:
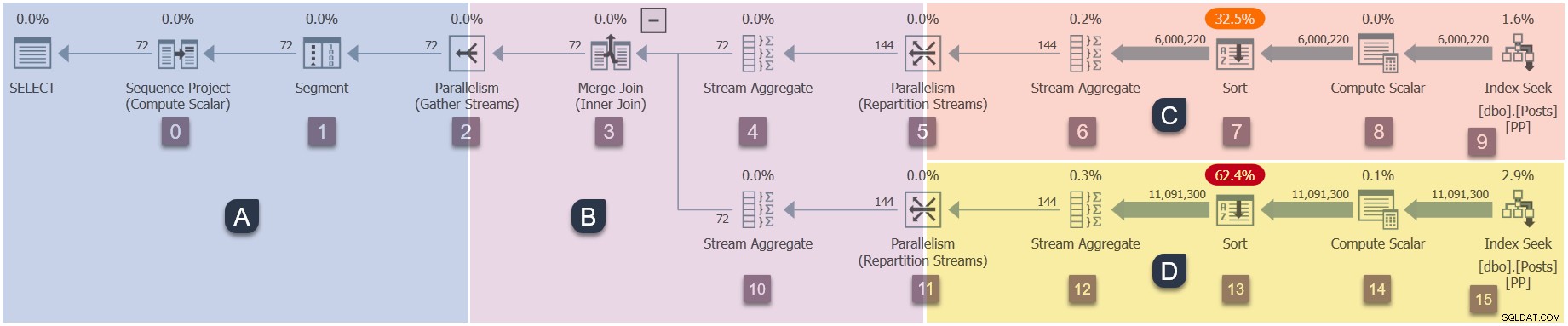
Gałąź A jest powiązana z zadaniem nadrzędnym, działającym w wątku roboczym dostarczonym przez sesję. Dodatkowi pracownicy równolegli zostaną uruchomieni do wykonywania dodatkowych zadań równoległych zawarte w gałęziach B, C i D. Te gałęzie są równoległe, więc w każdym z nich będą dodatkowe zadania DOP i pracownicy.
Nasze przykładowe zapytanie działa w DOP 2, więc gałąź B otrzyma dwa dodatkowe zadania. To samo dotyczy gałęzi C i gałęzi D, co daje w sumie sześć dodatkowe zadania. Każde zadanie będzie działać we własnym wątku roboczym we własnym kontekście wykonywania.
Dwóch planistów (S1 i S2 ) są przypisane do tego zapytania w celu uruchomienia dodatkowych pracowników równoległych. Każdy dodatkowy pracownik będzie działał na jednym z tych dwóch harmonogramów. Pracownik nadrzędny może działać w innym harmonogramie, więc nasze zapytanie DOP 2 może używać maksymalnie trzech rdzenie procesora w dowolnym momencie.
Podsumowując, nasz plan ostatecznie będzie zawierał:
- Oddział A (rodzic)
- Zadanie rodzica.
- Wątek pracownika nadrzędnego.
- Zerowy kontekst wykonania.
- Dowolny pojedynczy harmonogram dostępny dla zapytania.
- Oddział B (dodatkowe)
- Dwa dodatkowe zadania.
- Dodatkowy wątek roboczy powiązany z każdym nowym zadaniem.
- Dwa nowe konteksty wykonania, po jednym dla każdego nowego zadania.
- Jeden wątek roboczy działa w harmonogramie S1 . Drugi działa na harmonogramie S2 .
- Oddział C (dodatkowe)
- Dwa dodatkowe zadania.
- Dodatkowy wątek roboczy powiązany z każdym nowym zadaniem.
- Dwa nowe konteksty wykonania, po jednym dla każdego nowego zadania.
- Jeden wątek roboczy działa w harmonogramie S1 . Drugi działa na harmonogramie S2 .
- Oddział D (dodatkowe)
- Dwa dodatkowe zadania.
- Dodatkowy wątek roboczy powiązany z każdym nowym zadaniem.
- Dwa nowe konteksty wykonania, po jednym dla każdego nowego zadania.
- Jeden wątek roboczy działa w harmonogramie S1 . Drugi działa na harmonogramie S2 .
Pytanie brzmi, w jaki sposób tworzone są wszystkie te dodatkowe zadania, pracownicy i konteksty wykonania oraz kiedy zaczynają działać.
Sekwencja początkowa
Kolejność, w której dodatkowe zadania zacznij realizować dla tego konkretnego planu jest:
- Oddział A (zadanie nadrzędne).
- Gałąź C (dodatkowe zadania równoległe).
- Gałąź D (dodatkowe zadania równoległe).
- Gałąź B (dodatkowe zadania równoległe).
To może nie być zamówienie początkowe, którego się spodziewałeś.
Może wystąpić znaczne opóźnienie między każdym z tych kroków, z powodów, które wkrótce omówimy. Kluczowym punktem na tym etapie jest to, że dodatkowe zadania, pracownicy i konteksty wykonania nie wszystkie tworzone na raz i nie wszystkie zaczynają się wykonywać w tym samym czasie.
SQL Server mógł zostać zaprojektowany tak, aby wszystkie dodatkowe bity równoległe były uruchamiane jednocześnie. Może to być łatwe do zrozumienia, ale ogólnie nie byłoby zbyt wydajne. Zmaksymalizowałoby to liczbę dodatkowych wątków i innych zasobów wykorzystywanych przez zapytanie i spowodowałoby wiele niepotrzebnych równoległych czasów oczekiwania.
W przypadku projektu stosowanego przez SQL Server plany równoległe będą często wykorzystywać mniejszą liczbę wątków roboczych niż (DOP pomnożona przez całkowitą liczbę gałęzi). Osiąga się to poprzez rozpoznanie, że niektóre gałęzie mogą działać do końca, zanim inne gałęzie będą musiały się rozpocząć. Może to umożliwić ponowne wykorzystanie wątków w ramach tego samego zapytania i ogólnie zmniejsza ogólne zużycie zasobów.
Przejdźmy teraz do szczegółów uruchomienia naszego planu równoległego.
Otwarcie oddziału A
Skanowanie zapytania rozpoczyna się od zadania nadrzędnego wywołującego Open() na iteratorze w korzeniu drzewa. To jest początek sekwencji wykonywania:
- Oddział A (zadanie nadrzędne).
- Gałąź C (dodatkowe zadania równoległe).
- Gałąź D (dodatkowe zadania równoległe).
- Gałąź B (dodatkowe zadania równoległe).
Wykonujemy to zapytanie z żądanym „rzeczywistym” planem, więc iterator główny nie operator sekwencji projektu w węźle 0. Jest to raczej niewidoczny iterator profilowania który rejestruje metryki czasu wykonywania w planach trybu wiersza.
Poniższa ilustracja przedstawia iteratory skanowania zapytań w gałęzi A planu, z pozycją niewidocznych iteratorów profilowania reprezentowanych przez ikony „okularów”.
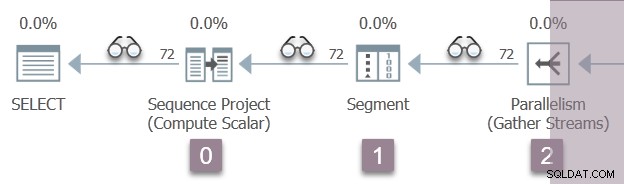
Wykonywanie rozpoczyna się od wywołania, aby otworzyć pierwszy profiler, CQScanProfileNew::Open . To ustawia czas otwarcia dla operatora projektu sekwencji podrzędnej za pośrednictwem interfejsu API Query Performance Counter systemu operacyjnego.
Widzimy ten numer w sys.dm_exec_query_profiles :
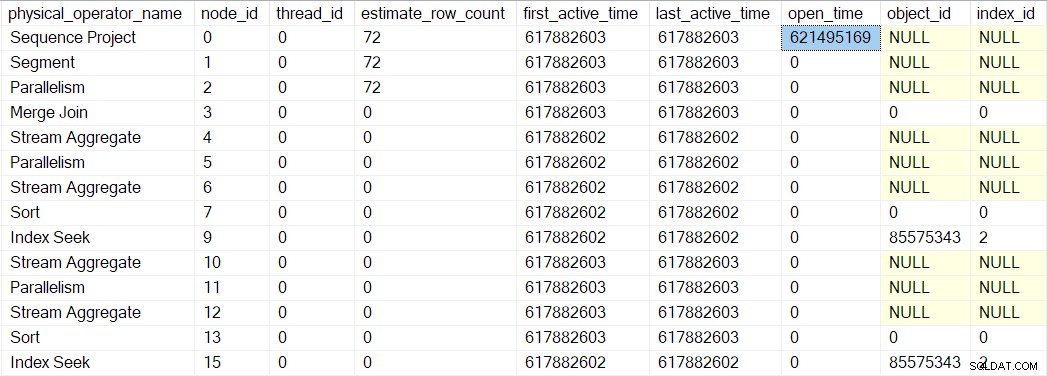
Wpisy tam mogą zawierać nazwy operatorów, ale dane pochodzą z profilera nad operatorem, a nie samym operatorem.
Tak się składa, że projekt sekwencyjny (CQScanSeqProjectNew ) nie musi wykonywać żadnej pracy po otwarciu , więc tak naprawdę nie ma funkcji Open() metoda. Profiler nad projektem sekwencji jest tak więc czas otwarcia projektu sekwencji jest rejestrowany w DMV.
Open profilu profilera metoda nie wywołuje Open w projekcie sekwencji (ponieważ go nie ma). Zamiast tego wywołuje Open w profilerze dla następnego iteratora w kolejności. To jest segment iterator w węźle 1. To ustawia czas otwarcia segmentu, tak jak poprzedni profiler zrobił dla projektu sekwencji:
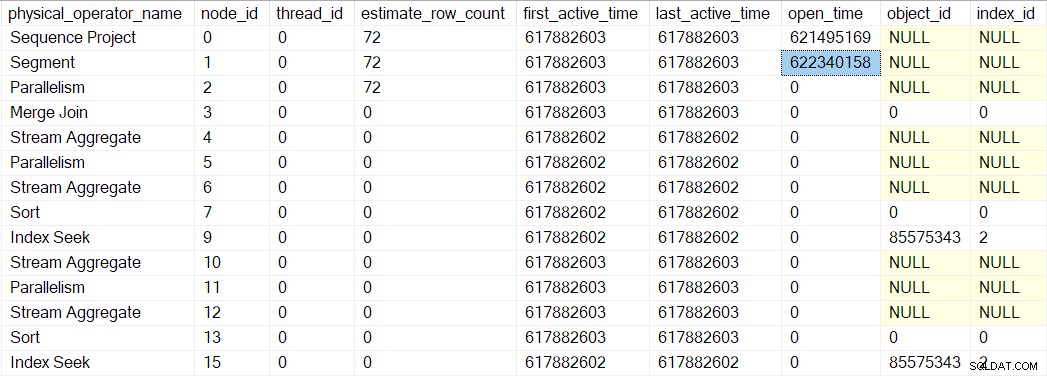
Iterator segmentu robi mieć rzeczy do zrobienia po otwarciu, więc następne wywołanie to CQScanSegmentNew::Open . Gdy segment wykona to, czego potrzebuje, wywołuje profiler dla następnego iteratora w kolejności — konsument strona zbierz wymianę strumieni w węźle 2:
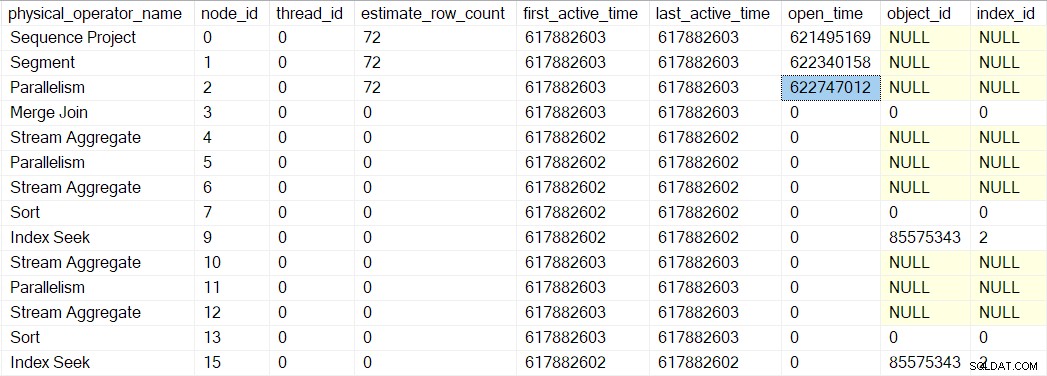
Następne wywołanie drzewa skanowania zapytań w procesie otwierania to CQScanExchangeNew::Open , w którym sprawy zaczynają się robić ciekawsze.
Otwieranie wymiany strumieni zbierania
Prośba strony konsumenta o otwarcie giełdy:
- Otwiera lokalną (równolegle zagnieżdżoną) transakcję (
CXTransLocal::Open). Każdy proces wymaga transakcji zawierającej, a dodatkowe zadania równoległe nie są wyjątkiem. Nie mogą bezpośrednio udostępniać transakcji nadrzędnej (podstawowej), dlatego używane są transakcje zagnieżdżone. Gdy zadanie równoległe musi uzyskać dostęp do transakcji podstawowej, synchronizuje się na zatrzask i może napotkaćNESTING_TRANSACTION_READONLYlubNESTING_TRANSACTION_FULLczeka. - Rejestruje bieżący wątek roboczy z portem wymiany (
CXPort::Register). - Synchronizuje się z innymi wątkami po stronie klienta na giełdzie (
sqlmin!CXTransLocal::Synchronize). Nie ma innych wątków po stronie konsumentów w strumieniach gromadzenia, więc w tej sytuacji zasadniczo nie ma opcji.
Przetwarzanie „Wczesne fazy”
Zadanie nadrzędne osiągnęło teraz krawędź Gałęzi A. Następny krok jest szczególny do planów równoległych w trybie wiersza:zadanie nadrzędne kontynuuje wykonywanie, wywołując CQScanExchangeNew::EarlyPhases w iteratorze wymiany strumieni zbierania w węźle 2. Jest to dodatkowa metoda iteratora poza zwykłym Open , GetRow i Close metody, z którymi wielu z Was będzie zaznajomionych. EarlyPhases jest wywoływana tylko w planach równoległych w trybie wiersza.
W tym momencie chcę coś wyjaśnić:strona producenta wymiany strumieni zbierania w węźle 2 nie został jeszcze utworzony i nie utworzono dodatkowe zadania równoległe. Nadal wykonujemy kod dla zadania nadrzędnego, używając jedynego działającego w tej chwili wątku.
Nie wszystkie iteratory implementują EarlyPhases , ponieważ nie wszystkie z nich mają w tym momencie coś specjalnego do zrobienia w równoległych planach w trybie wiersza. Jest to analogiczne do projektu sekwencji, który nie implementuje Open metody, ponieważ w tym czasie nie ma nic wspólnego. Główne iteratory z EarlyPhases metody to:
CQScanConcatNew(konkatenacja).CQScanMergeJoinNew(połącz dołączenie).CQScanSwitchNew(przełącznik).CQScanExchangeNew(równoległość).CQScanNew(dostęp do zestawu wierszy, np. skanuje i wyszukuje).CQScanProfileNew(niewidzialne profilery).CQScanLightProfileNew(niewidoczne lekkie profilery).
Wczesne fazy gałęzi B
Zadanie nadrzędne kontynuuje, wywołując EarlyPhases na operatorach podrzędnych poza wymianą strumieni zbierania w węźle 2. Zadanie przemieszczające się przez granicę gałęzi może wydawać się nietypowe, ale pamiętaj, że kontekst wykonania zero zawiera cały plan szeregowy wraz z wymianami. Przetwarzanie we wczesnej fazie polega na inicjowaniu równoległości, więc nie liczy się jako wykonanie per se .
Aby ułatwić śledzenie, poniższy rysunek przedstawia iteratory w gałęzi B planu:
Pamiętaj, że nadal znajdujemy się w kontekście wykonania zero, więc dla wygody nazywam to tylko Gałąź B. nie rozpoczęliśmy jakiekolwiek równoległe wykonanie jeszcze.
Sekwencja wywołań kodu we wczesnej fazie w gałęzi B to:
CQScanProfileNew::EarlyPhasesdla profilera powyżej węzła 3.CQScanMergeJoinNew::EarlyPhasesw węźle 3 scal połączenie .CQScanProfileNew::EarlyPhasesdla profilera powyżej węzła 4. Węzeł 4 agregat strumienia samo w sobie nie ma metody wczesnych faz.CQScanProfileNew::EarlyPhasesw profilerze powyżej węzła 5.CQScanExchangeNew::EarlyPhasesdla strumieni podziału wymiana w węźle 5.
Zauważ, że na tym etapie przetwarzamy tylko zewnętrzne (górne) dane wejściowe do łączenia przez scalanie. To jest po prostu normalna, iteracyjna sekwencja wykonywania w trybie wiersza. Nie dotyczy to planów równoległych.
Wczesne fazy gałęzi C
Przetwarzanie we wczesnej fazie jest kontynuowane w iteratorach w gałęzi C:

Sekwencja wywołań tutaj to:
CQScanProfileNew::EarlyPhasesdla profilera powyżej węzła 6.CQScanProfileNew::EarlyPhasesdla profilera powyżej węzła 7.CQScanProfileNew::EarlyPhasesw profilerze nad węzłem 9.CQScanNew::EarlyPhasesdla indeksu szukaj w węźle 9.
Nie ma EarlyPhases metody w strumieniu agregacji lub sortowania. Praca wykonywana przez skalar obliczeniowy w węźle 8 jest odroczona (w porządku), więc nie pojawia się w drzewie skanowania zapytań i nie ma skojarzonego profilera.
Informacje o taktowaniu profilera
Zadanie nadrzędne przetwarzanie wczesnej fazy rozpoczął się od wymiany strumieni zbierania w węźle 2. Schodził w dół drzewa skanowania zapytań, podążając za zewnętrznym (górnym) wejściem do łączenia scalającego, aż do wyszukiwania indeksu w węźle 9. Po drodze zadanie nadrzędne wywołało EarlyPhases w każdym iteratorze, który ją obsługuje.
Żadna z aktywności we wczesnych fazach jak dotąd nie została zaktualizowana w dowolnym momencie w profilu DMV. W szczególności żaden z iteratorów dotkniętych przetwarzaniem we wczesnych fazach nie miał ustawionego „czasu otwartego”. Ma to sens, ponieważ przetwarzanie we wczesnej fazie jest po prostu konfigurowaniem wykonywania równoległego — te operatory będą otwarte do wykonania później.
Indeks seek w węźle 9 jest węzłem liścia – nie ma dzieci. Zadanie nadrzędne zaczyna teraz powracać z zagnieżdżonych EarlyPhases połączenia, rosnące drzewo skanowania zapytań z powrotem w kierunku wymiany strumieni zbierania.
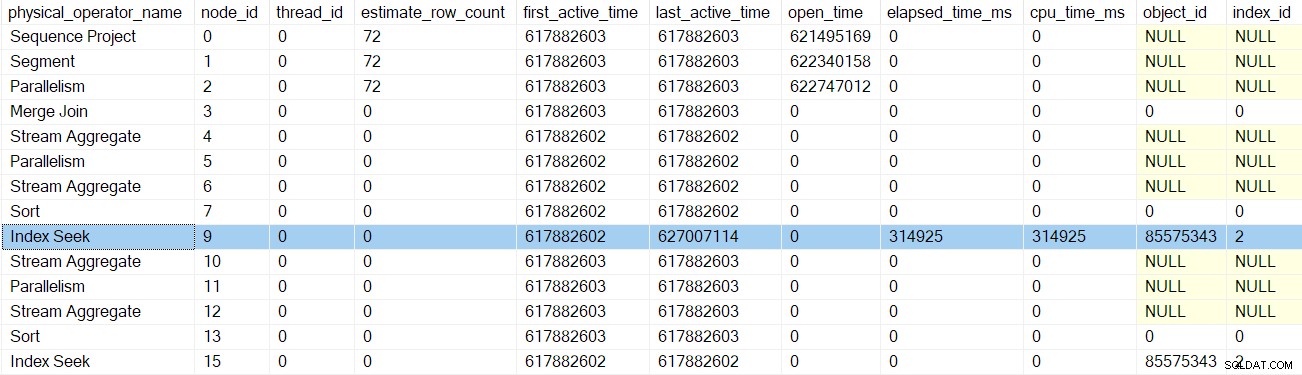
Każdy z profilerów wywołuje Licznik wydajności zapytań API przy wejściu do ich EarlyPhases metody i przywołują ją ponownie po wyjściu. Różnica między tymi dwiema liczbami reprezentuje upływ czasu dla iteratora i wszystkich jego elementów podrzędnych (ponieważ wywołania metod są zagnieżdżone).
Po powrocie profilera dla wyszukiwania indeksu, profiler DMV pokazuje upływ czasu i czas procesora dla przeszukiwania indeksu tylko, a także zaktualizowany ostatni aktywny czas. Zwróć też uwagę, że te informacje są rejestrowane w odniesieniu do zadania nadrzędnego (jedyna opcja w tej chwili):
Żaden z wcześniejszych iteratorów dotkniętych wywołaniami wczesnych faz nie upłynął ani nie zaktualizował czasu ostatniej aktywności. Te liczby są aktualizowane tylko wtedy, gdy wspinamy się na drzewo.
Po kolejnym wywołaniu następnego programu profilującego we wczesnych fazach, sortowanie czasy są aktualizowane:
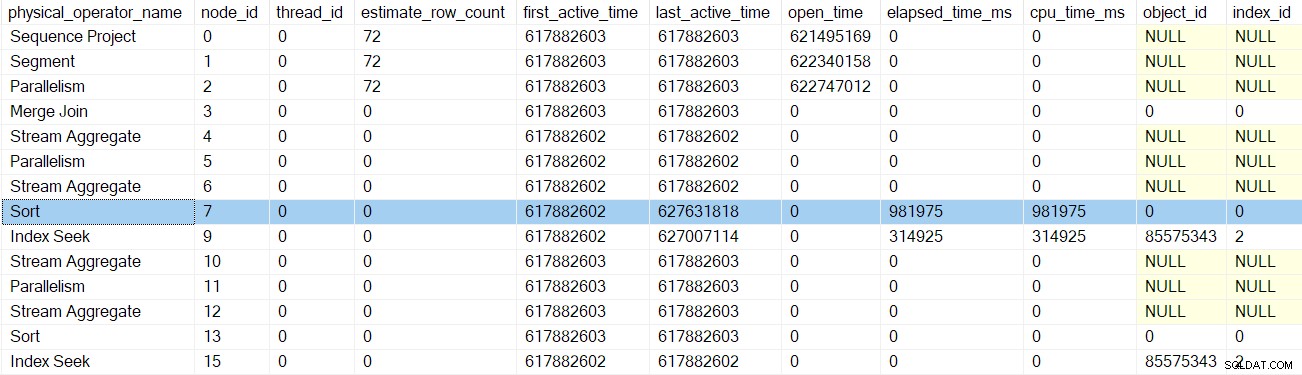
Następny powrót zabierze nas za profiler dla agregatu strumienia w węźle 6:
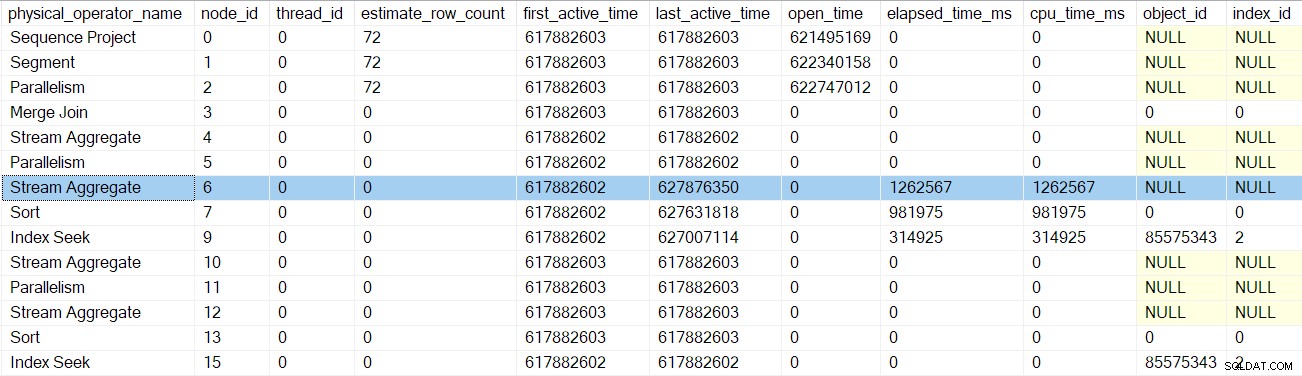
Powrót z tego profilera przenosi nas z powrotem do EarlyPhases zadzwoń na strumienie podziału wymiana w węźle 5 . Pamiętaj, że nie w tym miejscu zaczęła się sekwencja wywołań we wczesnych fazach — to była wymiana strumieni zbierania w węźle 2.
W kolejce umieszczono zadania równoległe oddziału C
Oprócz aktualizacji danych profilowania, wcześniejsze wywołania we wczesnych fazach nie wydawały się robić zbyt wiele. To wszystko zmienia się w strumieniach podziału wymiana w węźle 5.
Opiszę gałąź C dość szczegółowo, aby wprowadzić kilka ważnych pojęć, które będą miały zastosowanie również do innych gałęzi równoległych. Omówienie tego tematu raz teraz oznacza, że późniejsza dyskusja branżowa może być bardziej zwięzła.
Po zakończeniu przetwarzania zagnieżdżonego wczesnej fazy dla swojego poddrzewa (aż do wyszukiwania indeksu w węźle 9), giełda może rozpocząć własną pracę w początkowej fazie. To zaczyna się tak samo jak otwarcie wymiana strumieni zbierania w węźle 2:
CXTransLocal::Open(otwarcie lokalnej równoległej pod-transakcji).CXPort::Register(rejestracja na porcie wymiany).
Kolejne kroki są inne, ponieważ gałąź C zawiera w pełni blokowanie iterator (sortowanie w węźle 7). Przetwarzanie we wczesnej fazie w strumieniach podziału węzła 5 wykonuje następujące czynności:
- Połączenia
CQScanExchangeNew::StartAllProducers. Po raz pierwszy napotkaliśmy coś, co odnosi się do strony producenta wymiany. Węzeł 5 to pierwsza giełda w tym planie, która ma stworzyć stronę producenta. - Uzyskuje muteks więc żaden inny wątek nie może jednocześnie kolejkować zadań.
- Uruchamia równoległe transakcje zagnieżdżone dla zadań producenta (
CXPort::StartNestedTransactionsiReadOnlyXactImp::BeginParallelNestedXact). - Rejestruje transakcje podrzędne z nadrzędnym obiektem skanowania zapytania (
CQueryScan::AddSubXact). - Tworzy deskryptory producenta (
CQScanExchangeNew::PxproddescCreate). - Tworzy nowe konteksty wykonania producenta (
CExecContext) pochodzące z kontekstu wykonania zero. - Aktualizuje połączoną mapę iteratorów planu.
- Ustawia DOP dla nowego kontekstu (
CQueryExecContext::SetDop), aby wszystkie zadania wiedziały, jakie jest ogólne ustawienie DOP. - Inicjuje pamięć podręczną parametrów (
CQueryExecContext::InitParamCache). - Łączy równoległe transakcje zagnieżdżone z transakcją bazową (
CExecContext::SetBaseXact). - Kolejkuje nowe podprocesy do wykonania (
SubprocessMgr::EnqueueMultipleSubprocesses). - Tworzy nowe zadania równoległe zadania przez
sqldk!SOS_Node::EnqueueMultipleTasksDirect.
Stos wywołań zadania nadrzędnego (dla tych, którzy lubią te rzeczy) w tym momencie to:
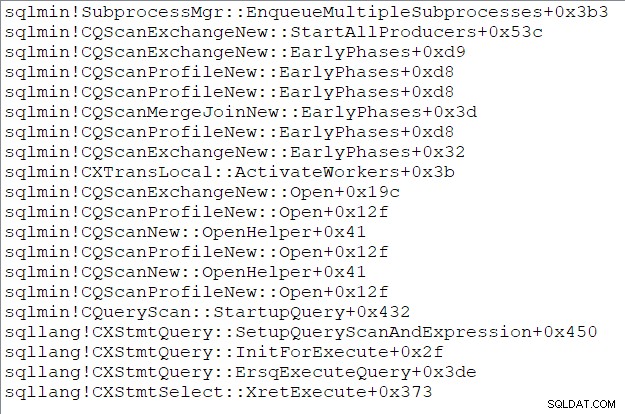
Koniec części trzeciej
Stworzyliśmy teraz stronę producenta wymiany strumieni repartycji w węźle 5, utworzono dodatkowe równoległe zadania uruchomić gałąź C i połączyć wszystko z rodzicem struktury zgodnie z wymaganiami. Gałąź C jest pierwszą oddział, aby rozpocząć równoległe zadania. W końcowej części tej serii przyjrzymy się szczegółowo otwarciu gałęzi C i rozpoczniemy pozostałe równoległe zadania.