W naszych poprzednich blogach uzasadniliśmy potrzebę przełączania awaryjnego bazy danych i wyjaśniliśmy, jak działa mechanizm przełączania awaryjnego. Dzielę się tym na wypadek, gdybyś miał pytania, dlaczego powinieneś skonfigurować mechanizm przełączania awaryjnego dla swojej bazy danych MySQL. Jeśli tak, przeczytaj nasze poprzednie posty na blogu.
Jak skonfigurować automatyczne przełączanie awaryjne
Zaletą korzystania z MySQL lub MariaDB do automatycznego zarządzania przełączaniem awaryjnym jest to, że istnieją dostępne narzędzia, które można wykorzystać i wdrożyć w swoim środowisku. Od rozwiązań open source po rozwiązania klasy korporacyjnej. Większość narzędzi umożliwia nie tylko przełączanie awaryjne, ale są też inne funkcje, takie jak przełączanie, monitorowanie i zaawansowane funkcje, które oferują więcej możliwości zarządzania klastrem baz danych MySQL. Poniżej omówimy najpopularniejsze z nich, których możesz użyć.
Korzystanie z MHA (Master High Availability)
Zajęliśmy się tym tematem za pomocą MHA z jego najczęstszymi problemami i sposobami ich naprawy. Porównaliśmy również MHA z MRM lub MaxScale.
Konfiguracja za pomocą MHA w celu zapewnienia wysokiej dostępności może nie być łatwa, ale jest wydajna w użyciu i elastyczna, ponieważ istnieją parametry, które można zdefiniować, aby dostosować przełączanie awaryjne. MHA został przetestowany i używany. Jednak wraz z postępem technologicznym MHA pozostaje w tyle, ponieważ nie obsługuje GTID dla MariaDB i nie wprowadza żadnych aktualizacji przez ostatnie 2 lub 3 lata.
Uruchamiając skrypt masterha_manager,
masterha_manager --conf=/etc/app1.cnfGdzie przykładowy /etc/app1.cnf powinien wyglądać następująco,
[server default]
user=cmon
password=pass
ssh_user=root
# working directory on the manager
manager_workdir=/var/log/masterha/app1
# working directory on MySQL servers
remote_workdir=/var/log/masterha/app1
[server1]
hostname=node1
candidate_master=1
[server2]
hostname=node2
candidate_master=1
[server3]
hostname=node3
no_master=1Parametry takie jak no_master i Candida_master powinny być kluczowe, gdy ustawiasz białą listę żądanych węzłów jako docelowego mastera i węzłów, których nie chcesz być masterem.
Po ustawieniu jesteś gotowy do przełączenia awaryjnego bazy danych MySQL na wypadek awarii bazy podstawowej lub głównej. Skrypt masterha_manager zarządza przełączaniem awaryjnym (automatycznym lub ręcznym), podejmuje decyzje o tym, kiedy i gdzie przełączać awaryjnie, a także zarządza odzyskiwaniem urządzeń podrzędnych podczas promocji kandydującego wzorca głównego w celu zastosowania dzienników przekaźników różnicowych. W przypadku śmierci głównej bazy danych, Menedżer MHA będzie koordynował współpracę z agentem MHA Node, ponieważ stosuje dzienniki przekaźników różnicowych do urządzeń podrzędnych, które nie mają najnowszych zdarzeń dziennika binarnego z urządzenia głównego.
Sprawdź, co robi agent MHA Node i jakie skrypty są zaangażowane. Zasadniczo jest to skrypt, który Menedżer MHA wywoła, gdy nastąpi przełączenie awaryjne. Będzie czekał na swój mandat od MHA Manager, szukając najnowszego urządzenia podrzędnego, które zawiera zdarzenia binlogu, kopiuje brakujące zdarzenia z urządzenia podrzędnego za pomocą scp i stosuje je do siebie. Jak wspomniano, stosuje logi przekaźnika, czyści logi przekaźnika lub zapisuje logi binarne.
Jeśli chcesz dowiedzieć się więcej o dostrajalnych parametrach i jak dostosować zarządzanie przełączaniem awaryjnym, odwiedź stronę wiki Parametry dla MHA.
Korzystanie z programu Orchestrator
Orchestrator to narzędzie do zarządzania wysoką dostępnością i replikacją MySQL i MariaDB. Został wydany przez Shlomi Noach na warunkach licencji Apache w wersji 2.0. Jest to oprogramowanie typu open source, które obsługuje automatyczne przełączanie awaryjne, ale istnieje mnóstwo rzeczy, które można dostosować lub zrobić, aby zarządzać bazą danych MySQL/MariaDB oprócz odzyskiwania lub automatycznego przełączania awaryjnego.
Instalacja programu Orchestrator może być łatwa lub prosta. Po pobraniu określonych pakietów wymaganych dla środowiska docelowego można przystąpić do zarejestrowania klastra i węzłów w celu monitorowania przez program Orchestrator. Zapewnia interfejs użytkownika, który jest bardzo łatwy w zarządzaniu, ale ma wiele konfigurowalnych parametrów lub zestaw poleceń, których można użyć do zarządzania przełączaniem awaryjnym.
Załóżmy, że w końcu skonfigurowałeś i rejestrację klastra poprzez dodanie naszego węzła podstawowego lub głównego można wykonać za pomocą poniższego polecenia,
$ orchestrator -c discover -i pupnode21:3306
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: pupnode21
2021-01-07 12:32:31 DEBUG Cache hostname resolve pupnode21 as pupnode21
2021-01-07 12:32:31 DEBUG Connected to orchestrator backend: orchestrator:example@sqldat.com(127.0.0.1:3306)/orchestrator?timeout=1s
2021-01-07 12:32:31 DEBUG Orchestrator pool SetMaxOpenConns: 128
2021-01-07 12:32:31 DEBUG Initializing orchestrator
2021-01-07 12:32:31 INFO Connecting to backend 127.0.0.1:3306: maxConnections: 128, maxIdleConns: 32
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.222
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.222 as 192.168.40.222
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.223
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.223 as 192.168.40.223
pupnode21:3306Teraz dodaliśmy nasz klaster.
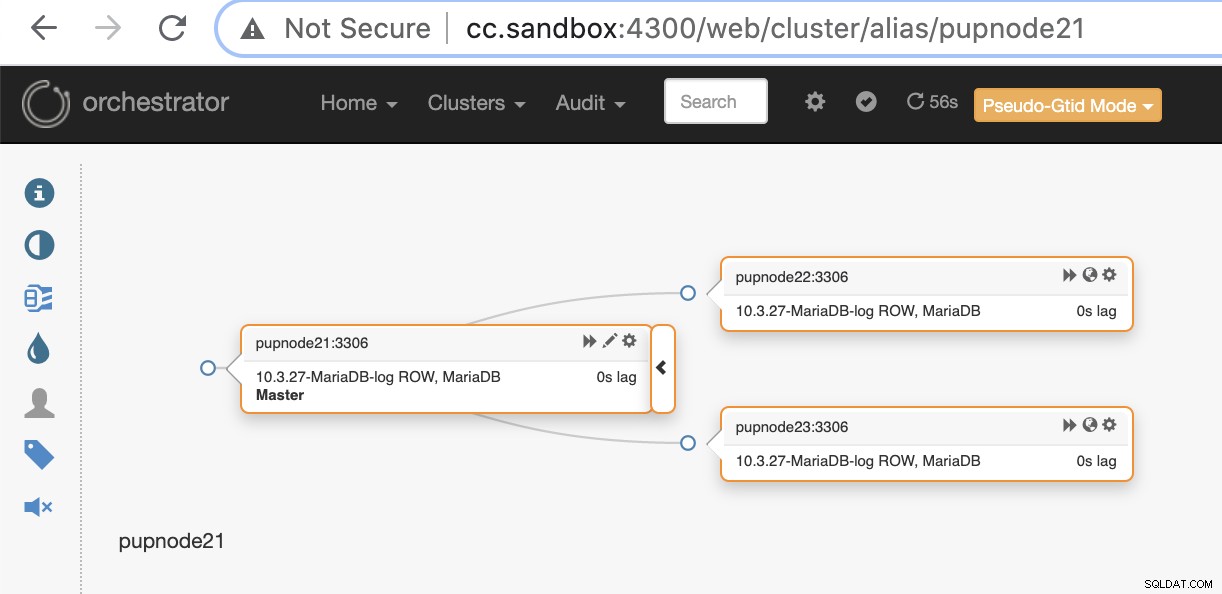
W przypadku awarii węzła podstawowego (awaria sprzętu lub awaria), program Orchestrator wykryj i znajdź najbardziej zaawansowany węzeł, który ma być promowany jako węzeł główny lub główny.
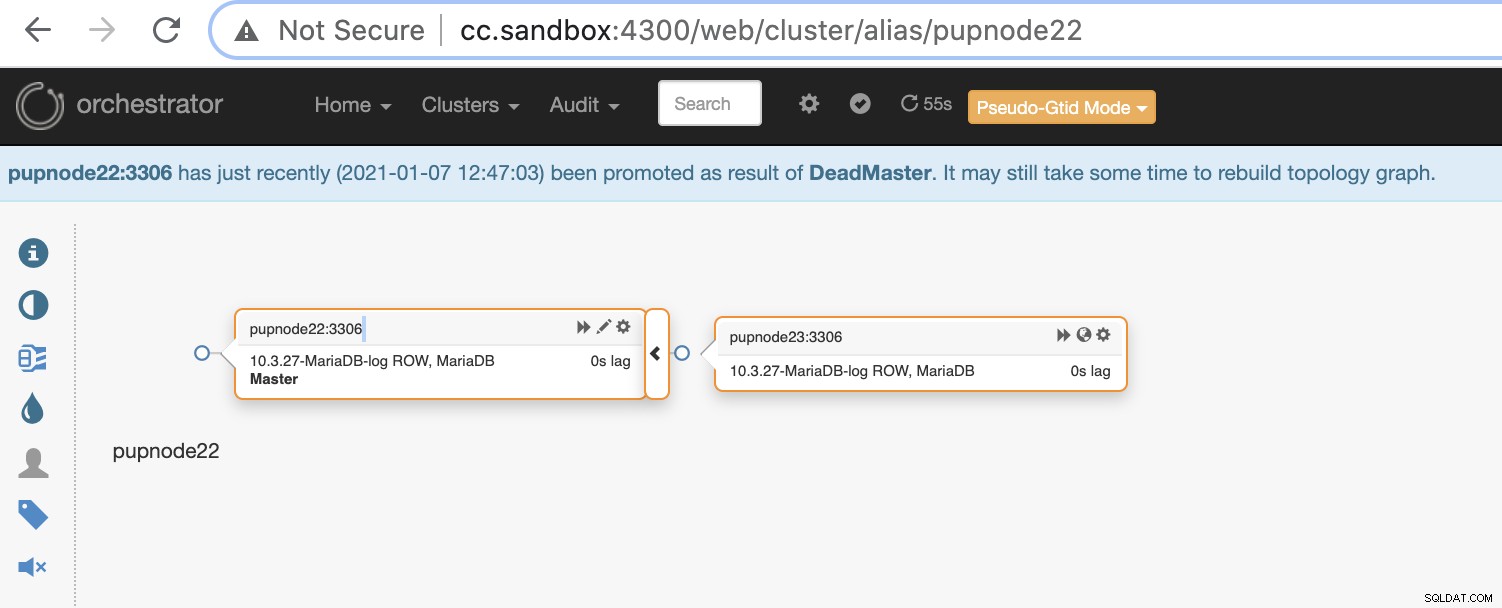
Teraz w klastrze pozostały dwa węzły, podczas gdy główny jest wyłączony .
$ orchestrator-client -c topology -i pupnode21:3306
pupnode21:3306 [unknown,invalid,10.3.27-MariaDB-log,rw,ROW,>>,downtimed]
$ orchestrator-client -c topology -i pupnode22:3306
pupnode22:3306 [0s,ok,10.3.27-MariaDB-log,rw,ROW,>>]
+ pupnode23:3306 [0s,ok,10.3.27-MariaDB-log,ro,ROW,>>,GTID]Korzystanie z MaxScale
MariaDB MaxScale jest obsługiwany jako system równoważenia obciążenia bazy danych. Z biegiem lat MaxScale rozrósł się i dojrzał, wzbogacony o kilka bogatych funkcji, w tym automatyczne przełączanie awaryjne. Od czasu wydania MariaDB MaxScale 2.2 wprowadzono kilka nowych funkcji, w tym zarządzanie trybem failover klastra replikacji. Możesz przeczytać nasz poprzedni blog dotyczący mechanizmu przełączania awaryjnego MaxScale.
Korzystanie z MaxScale jest objęte BSL, chociaż oprogramowanie jest dostępne bezpłatnie, ale wymaga przynajmniej wykupienia usługi w MariaDB. Może to nie być odpowiednie, ale w przypadku nabycia usług korporacyjnych MariaDB może to być wielką zaletą, jeśli potrzebujesz zarządzania awaryjnego i innych jego funkcji.
Instalacja MaxScale jest łatwa, ale ustawienie wymaganej konfiguracji i zdefiniowanie jej parametrów nie jest i wymaga zrozumienia oprogramowania. Możesz zapoznać się z ich przewodnikiem konfiguracji.
W celu szybkiego i szybkiego wdrożenia możesz użyć ClusterControl, aby zainstalować MaxScale w istniejącym środowisku MySQL/MariaDB.
Po zainstalowaniu można skonfigurować bazę danych Moodle, wskazując hostowi adres IP lub nazwę hosta MaxScale oraz port do odczytu i zapisu. Na przykład
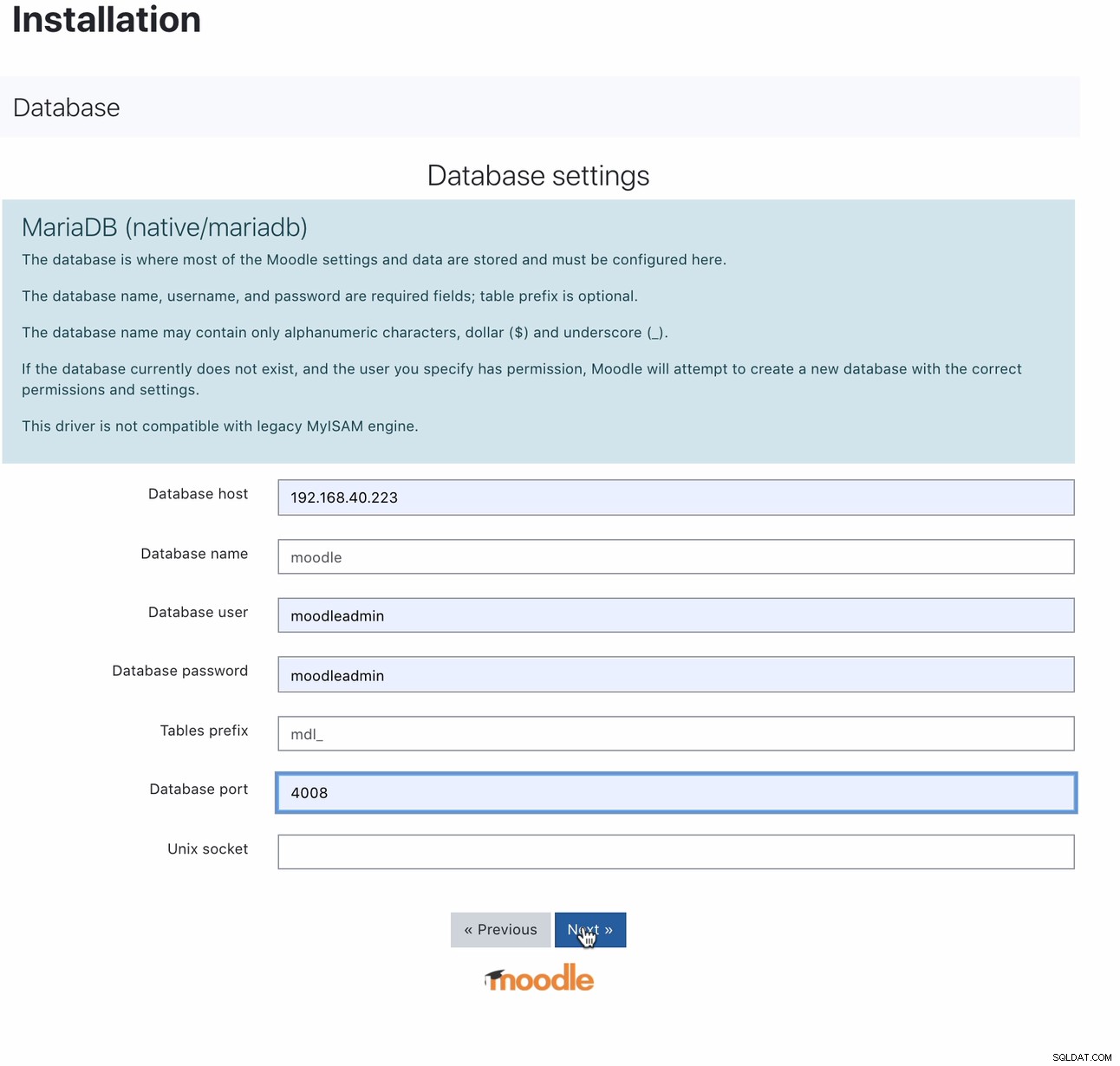
Dla którego portu 4008 jest twój odczyt i zapis dla programu nasłuchującego usługi. Na przykład, oto następująca konfiguracja usługi i odbiornika dla mojej MaxScale.
$ cat maxscale.cnf.d/rw-listener.cnf
[rw-listener]
type=listener
protocol=mariadbclient
service=rw-service
address=0.0.0.0
port=4008
authenticator=MySQLAuth
$ cat maxscale.cnf.d/rw-service.cnf
[rw-service]
type=service
servers=DB_123,DB_122,DB_124
router=readwritesplit
user=maxscale_adm
password=42BBD2A4DC1BF9BE05C41A71DEEBDB70
max_slave_connections=100%
max_sescmd_history=15000000
causal_reads=true
causal_reads_timeout=10
transaction_replay=true
transaction_replay_max_size=32Mi
delayed_retry=true
master_reconnection=true
max_connections=0
connection_timeout=0
use_sql_variables_in=master
master_accept_reads=true
disable_sescmd_history=falsePodczas konfiguracji monitora nie możesz zapomnieć o włączeniu automatycznego przełączania awaryjnego lub włączeniu automatycznego ponownego dołączania, jeśli chcesz, aby poprzedni system główny nie dołączył automatycznie po powrocie do trybu online. To wygląda tak,
$ egrep -r 'auto|^\[' maxscale.cnf.d/replication_monitor.cnf
[replication_monitor]
auto_failover=true
auto_rejoin=1Pamiętaj, że podane przeze mnie zmienne nie są przeznaczone do użytku produkcyjnego, ale tylko do tego wpisu na blogu i do celów testowych. Dobrą rzeczą w MaxScale jest to, że gdy główny lub mistrz przestanie działać, MaxScale jest wystarczająco sprytny, aby promować idealnego lub najlepszego kandydata do objęcia roli mistrza. W związku z tym nie ma potrzeby zmiany adresu IP i portu, ponieważ użyliśmy hosta/IP naszego węzła MaxScale i jego portu jako naszego punktu końcowego po awarii urządzenia głównego. Na przykład
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Węzeł DB_123 wskazujący na 192.168.40.221 jest bieżącym masterem. Zakończenie węzła DB_123 spowoduje, że MaxScale wykona przełączenie awaryjne i będzie to wyglądać tak,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Down │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Chociaż nasza baza danych Moodle wciąż działa, ponieważ nasz MaxScale wskazuje na najnowszy master, który był promowany.
$ mysql -hmaxscale.local.domain -umoodleuser -pmoodlepassword -P4008
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 9
Server version: 10.3.27-MariaDB-log MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> select @@hostname;
+------------+
| @@hostname |
+------------+
| 192.168.40.222 |
+------------+
1 row in set (0.001 sec)Korzystanie z ClusterControl
ClusterControl można pobrać bezpłatnie i oferuje licencje dla Community, Advance i Enterprise. Automatyczne przełączanie awaryjne jest dostępne tylko w Advance i Enterprise. Automatyczne przełączanie awaryjne jest objęte naszą funkcją automatycznego odzyskiwania, która próbuje odzyskać uszkodzony klaster lub uszkodzony węzeł. Jeśli chcesz uzyskać więcej informacji na temat tego, jak to zrobić, zapoznaj się z naszym poprzednim postem W jaki sposób ClusterControl wykonuje automatyczne odzyskiwanie bazy danych i przełączanie awaryjne. Oferuje regulowane parametry, które są bardzo wygodne i łatwe w użyciu. Przeczytaj nasz poprzedni post również na temat Jak zautomatyzować przełączanie awaryjne bazy danych za pomocą ClusterControl.
Zarządzanie automatycznym przełączaniem awaryjnym bazy danych Moodle musi przynajmniej wymagać wirtualnego adresu IP (VIP) jako punktu końcowego dla klienta aplikacji Moodle łączącego się z zapleczem bazy danych. Aby to zrobić, możesz wdrożyć Keepalived z HAProxy (lub ProxySQL — w zależności od wybranego modułu równoważenia obciążenia). W takim przypadku punkt końcowy bazy danych Moodle powinien wskazywać na wirtualny adres IP, który jest w zasadzie przypisywany przez Keepalived po jego wdrożeniu, tak jak pokazaliśmy wcześniej podczas konfigurowania MaxScale. Możesz również sprawdzić na tym blogu, jak to zrobić.
Jak wspomniano powyżej, dostępne są dostrajalne parametry, które można ustawić za pomocą pliku /etc/cmon.d/cmon_
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- Replication_post_failover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
ClusterControl jest bardzo elastyczny podczas zarządzania przełączaniem awaryjnym, dzięki czemu można wykonać pewne zadania przed lub po awarii.
Wnioski
Istnieją inne świetne możliwości podczas konfigurowania i automatycznego zarządzania przełączaniem awaryjnym bazy danych MySQL dla Moodle. To zależy od Twojego budżetu i tego, na co prawdopodobnie będziesz musiał wydawać pieniądze. Korzystanie z rozwiązań typu open source wymaga wiedzy specjalistycznej i wielu testów w celu zapoznania się, ponieważ nie ma wsparcia, które można uruchomić, gdy potrzebujesz pomocy innej niż społeczność. W przypadku rozwiązań dla przedsiębiorstw jest to cena, ale zapewnia wsparcie i łatwość, ponieważ czasochłonna praca może zostać zmniejszona. Należy pamiętać, że jeśli przełączanie awaryjne jest używane błędnie, może to spowodować uszkodzenie bazy danych, jeśli nie zostanie odpowiednio obsłużone i zarządzane. Skoncentruj się na tym, co jest ważniejsze i na tym, jak jesteś w stanie wykorzystać rozwiązania, z których korzystasz do zarządzania przełączaniem awaryjnym bazy danych Moodle.