Monitorowanie zmian schematu bazy danych w MySQL/MariaDB zapewnia ogromną pomoc, ponieważ pozwala zaoszczędzić czas na analizowanie wzrostu bazy danych, zmian definicji tabeli, rozmiaru danych, rozmiaru indeksu lub rozmiaru wiersza. W przypadku bazy danych MySQL/MariaDB uruchomienie zapytania odwołującego się do schematu information_schema wraz ze schematem performance_schema daje zbiorcze wyniki do dalszej analizy. Schemat sys zapewnia widoki, które służą jako zbiorcze metryki, które są bardzo przydatne do śledzenia zmian lub aktywności w bazie danych.
Jeśli masz wiele serwerów baz danych, ciągłe uruchamianie zapytań byłoby nużące. Musisz także przetrawić ten wynik na bardziej czytelny i łatwiejszy do zrozumienia.
W tym blogu utworzymy automatyzację, która będzie pomocna jako narzędzie do monitorowania istniejącej bazy danych i zbieranie metryk dotyczących zmian w bazie danych lub operacji zmiany schematu.
Tworzenie automatyzacji do sprawdzania obiektów schematu bazy danych
W tym ćwiczeniu będziemy monitorować następujące wskaźniki:
-
Brak tabel kluczy podstawowych
-
Powiel indeksy
-
Wygeneruj wykres dla łącznej liczby wierszy w naszych schematach baz danych
-
Wygeneruj wykres przedstawiający całkowity rozmiar schematów naszej bazy danych
To ćwiczenie da ci wskazówki i może być modyfikowane w celu zebrania bardziej zaawansowanych metryk z bazy danych MySQL/MariaDB.
Korzystanie z Puppet dla naszego IaC i automatyzacji
W tym ćwiczeniu wykorzystamy Puppet do zapewnienia automatyzacji i wygenerowania oczekiwanych wyników na podstawie metryk, które chcemy monitorować. Nie będziemy omawiać instalacji i konfiguracji Puppet, w tym serwera i klienta, więc oczekuję, że będziesz wiedział, jak korzystać z Puppet. Możesz odwiedzić nasz stary blog Automated Deployment MySQL Galera Cluster do Amazon AWS with Puppet, który obejmuje konfigurację i instalację Puppet.
W tym ćwiczeniu użyjemy najnowszej wersji Puppet, ale ponieważ nasz kod składa się z podstawowej składni, będzie działał dla starszych wersji Puppet.
Preferowany serwer bazy danych MySQL
W tym ćwiczeniu użyjemy Percona Server 8.0.22-13, ponieważ wolę Percona Server głównie do testowania i niektórych mniejszych wdrożeń, zarówno do użytku biznesowego, jak i osobistego.
Narzędzie do tworzenia wykresów
Istnieje mnóstwo opcji do wykorzystania, zwłaszcza w środowisku Linux. Na tym blogu użyję najłatwiejszego, jakie znalazłem i narzędzia opensource https://quickchart.io/.
Pobawmy się marionetką
Założenie, które tutaj postawiłem, jest takie, że masz skonfigurowany serwer główny z zarejestrowanym klientem, który jest gotowy do komunikacji z serwerem głównym w celu otrzymywania automatycznych wdrożeń.
Zanim przejdziemy dalej, oto informacje o moim serwerze:
Serwer główny:192.168.40.200
Klient/Serwer agenta:192.168.40.160
W tym blogu nasz serwer klient/agent jest miejscem, w którym działa nasz serwer bazy danych. W rzeczywistym scenariuszu nie musi to być specjalnie do monitorowania. Dopóki jest w stanie bezpiecznie komunikować się z węzłem docelowym, jest to również idealna konfiguracja.
Skonfiguruj moduł i kod
-
Przejdź do serwera głównego i w ścieżce /etc/puppetlabs/code/environments/production/module, utwórzmy wymagane katalogi do tego ćwiczenia:
mkdir schema_change_mon/{files,manifests}
-
Utwórz potrzebne nam pliki
touch schema_change_mon/files/graphing_gen.sh
touch schema_change_mon/manifests/init.pp
-
Wypełnij skrypt init.pp następującą treścią:
class schema_change_mon (
$db_provider = "mysql",
$db_user = "root",
$db_pwd = "example@sqldat.com",
$db_schema = []
) {
$dbs = ['pauldb', 'sbtest']
service { $db_provider :
ensure => running,
enable => true,
hasrestart => true,
hasstatus => true
}
exec { "mysql-without-primary-key" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"select concat(tables.table_schema,'.',tables.table_name,', ', tables.engine) from information_schema.tables left join ( select table_schema , table_name from information_schema.statistics group by table_schema , table_name , index_name having sum( case when non_unique = 0 and nullable != 'YES' then 1 else 0 end ) = count(*) ) puks on tables.table_schema = puks.table_schema and tables.table_name = puks.table_name where puks.table_name is null and tables.table_type = 'BASE TABLE' and tables.table_schema not in ('performance_schema', 'information_schema', 'mysql');\" >> /opt/schema_change_mon/assets/no-pk.log"
}
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"SELECT concat(t.table_schema,'.', t.table_name, '.', t.index_name, '(', t.idx_cols,')') FROM ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='${db}' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) t JOIN ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='pauldb' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) u where t.table_schema = u.table_schema AND t.table_name = u.table_name AND t.index_name<>u.index_name AND locate(t.idx_cols,u.idx_cols);\" information_schema >> /opt/schema_change_mon/assets/dupe-indexes.log"
}
}
$genscript = "/tmp/graphing_gen.sh"
file { "${genscript}" :
ensure => present,
owner => root,
group => root,
mode => '0655',
source => 'puppet:///modules/schema_change_mon/graphing_gen.sh'
}
exec { "generate-graph-total-rows" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_rows"
}
exec { "generate-graph-total-len" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_len"
}
}
-
Wypełnij plik graphing_gen.sh. Ten skrypt uruchomi się na węźle docelowym i wygeneruje wykresy dla całkowitej liczby wierszy w naszej bazie danych, a także całkowitego rozmiaru naszej bazy danych. W przypadku tego skryptu uprośćmy go i zezwólmy tylko na bazy danych typu MyISAM lub InnoDB.
#!/bin/bash
graph_ident="${1:-total_rows}"
unset json myisam innodb nmyisam ninnodb; json='' myisam='' innodb='' nmyisam='' ninnodb='' url=''; json=$(MYSQL_PWD="example@sqldat.com" mysql -uroot -Nse "select json_object('dbschema', concat(table_schema,' - ', engine), 'total_rows', sum(table_rows), 'total_len', sum(data_length+data_length), 'fragment', sum(data_free)) from information_schema.tables where table_schema not in ('performance_schema', 'sys', 'mysql', 'information_schema') and engine in ('myisam','innodb') group by table_schema, engine;" | jq . | sed ':a;N;$!ba;s/\n//g' | sed 's|}{|},{|g' | sed 's/^/[/g'| sed 's/$/]/g' | jq '.' ); innodb=""; myisam=""; for r in $(echo $json | jq 'keys | .[]'); do if [[ $(echo $json| jq .[$r].'dbschema') == *"MyISAM"* ]]; then nmyisam=$(echo $nmyisam || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; myisam=$(echo $myisam || echo '')$(echo $json| jq .[$r].'dbschema')','; else ninnodb=$(echo $ninnodb || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; innodb=$(echo $innodb || echo '')$(echo $json| jq .[$r].'dbschema')','; fi; done; myisam=$(echo $myisam|sed 's/,$//g'); nmyisam=$(echo $nmyisam|sed 's/,$//g'); innodb=$(echo $innodb|sed 's/,$//g');ninnodb=$(echo $ninnodb|sed 's/,$//g'); echo $myisam "|" $nmyisam; echo $innodb "|" $ninnodb; url=$(echo "{type:'bar',data:{labels:['MyISAM','InnoDB'],datasets:[{label:[$myisam],data:[$nmyisam]},{label:[$innodb],data:[$ninnodb]}]},options:{title:{display:true,text:'Database Schema Total Rows Graph',fontSize:20,}}}"); curl -L -o /vagrant/schema_change_mon/assets/db-${graph_ident}.png -g https://quickchart.io/chart?c=$(python -c "import urllib,os,sys; print urllib.quote(os.environ['url'])")
-
Na koniec przejdź do katalogu ścieżki modułu lub /etc/puppetlabs/code/environments /produkcja w mojej konfiguracji. Utwórzmy plik manifests/schema_change_mon.pp.
touch manifests/schema_change_mon.pp-
Następnie wypełnij plik manifests/schema_change_mon.pp następującą zawartością,
node 'pupnode16.puppet.local' { # Applies only to mentioned node. If nothing mentioned, applies to all.
class { 'schema_change_mon':
}
}
Jeśli skończyłeś, powinieneś mieć następującą strukturę drzewa, taką jak moja,
example@sqldat.com:/etc/puppetlabs/code/environments/production/modules# tree schema_change_mon
schema_change_mon
├── files
│ └── graphing_gen.sh
└── manifests
└── init.ppCo robi nasz moduł?
Nasz moduł o nazwie schema_change_mon gromadzi następujące elementy,
exec { "mysql-without-primary-key" :...
Która wykonuje polecenie mysql i uruchamia zapytanie w celu pobrania tabel bez kluczy podstawowych. Następnie
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :który zbiera zduplikowane indeksy istniejące w tabelach bazy danych.
Następnie linie generują wykresy na podstawie zebranych danych. Oto następujące wiersze,
exec { "generate-graph-total-rows" :
...
exec { "generate-graph-total-len" :
…Po pomyślnym uruchomieniu zapytania generuje wykres, który zależy od interfejsu API udostępnianego przez https://quickchart.io/.
Oto następujące wyniki wykresu:
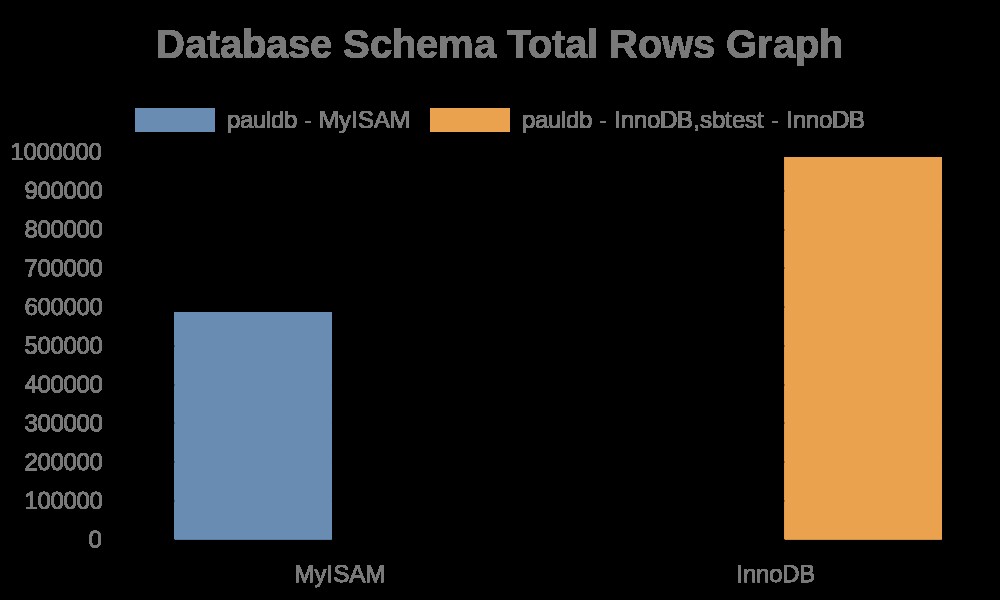
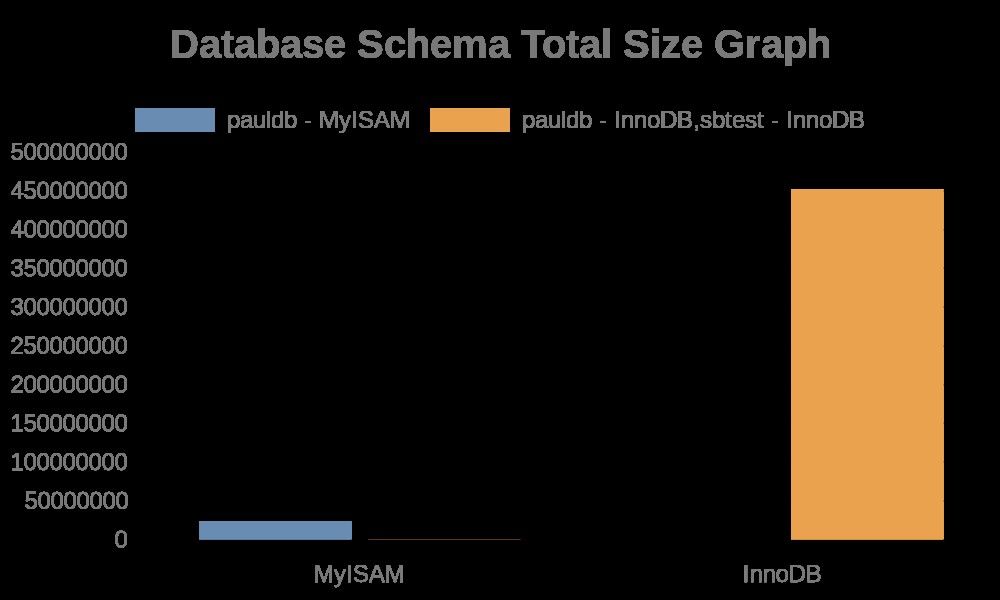
Dzienniki plików zawierają po prostu ciągi z nazwami tabel, nazwami indeksów. Zobacz wynik poniżej,
example@sqldat.com:~# tail -n+1 /opt/schema_change_mon/assets/*.log
==> /opt/schema_change_mon/assets/dupe-indexes.log <==
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
==> /opt/schema_change_mon/assets/no-pk.log <==
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDB
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDBDlaczego nie używać ClusterControl?
Ponieważ nasze ćwiczenie pokazuje automatyzację i pobieranie statystyk schematu bazy danych, takich jak zmiany lub operacje, ClusterControl również to zapewnia. Oprócz tego są inne funkcje i nie musisz wymyślać koła na nowo. ClusterControl może dostarczyć dzienniki transakcji, takie jak zakleszczenia, jak pokazano powyżej, lub długo działające zapytania, jak pokazano poniżej:
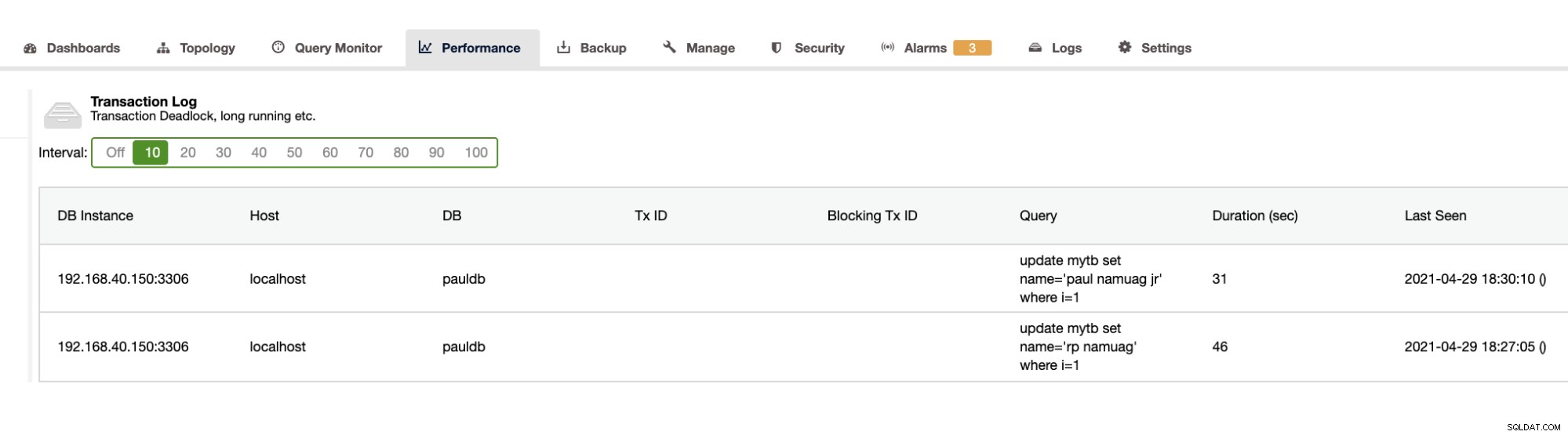
ClusterControl pokazuje również wzrost bazy danych, jak pokazano poniżej,
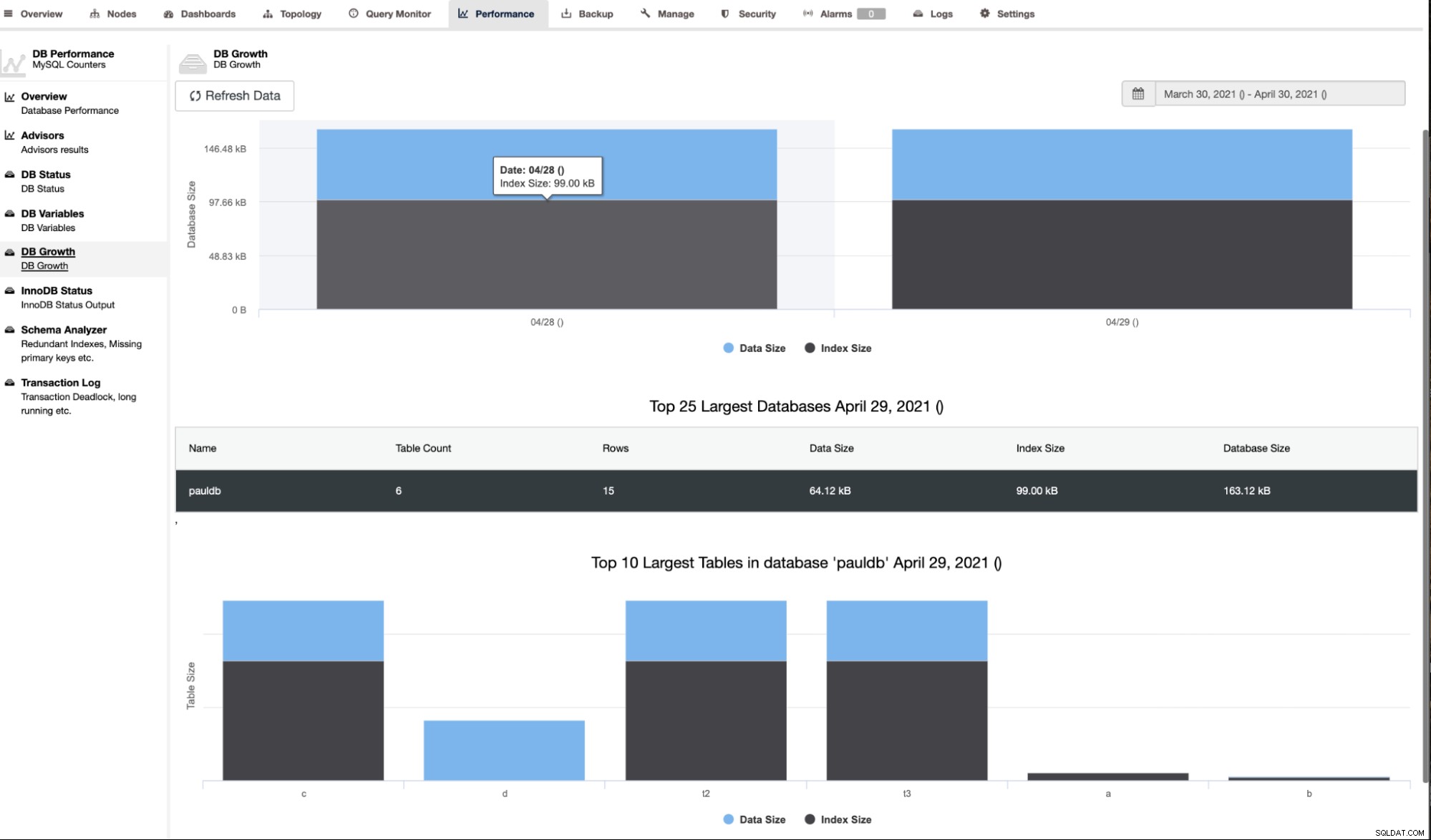
ClusterControl podaje również dodatkowe informacje, takie jak liczba wierszy, rozmiar dysku, rozmiar indeksu i całkowity rozmiar.
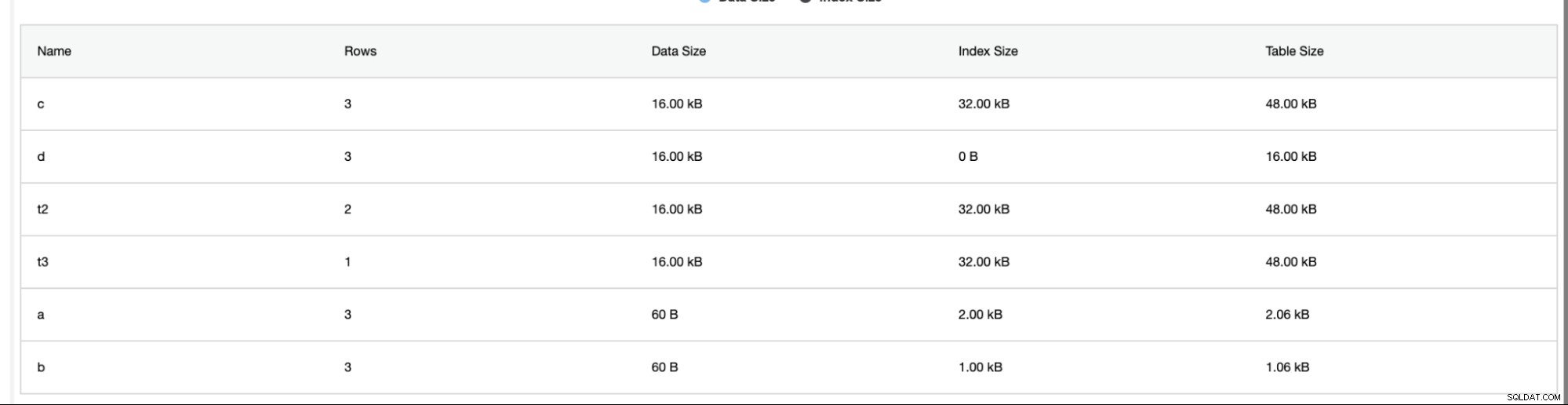
Analizator schematu w zakładce Wydajność -> Analizator schematu jest bardzo pomocny. Udostępnia tabele bez kluczy podstawowych, tabele MyISAM i zduplikowane indeksy,

Zapewnia również alarmy w przypadku wykrycia zduplikowanych indeksów lub tabel bez podstawowych klawisze takie jak poniżej,

Więcej informacji o ClusterControl i innych funkcjach można znaleźć na naszej stronie Produktu.
Wnioski
Zapewnienie automatyzacji monitorowania zmian w bazie danych lub wszelkich statystyk schematów, takich jak zapisy, duplikaty indeksów, aktualizacje operacji, takie jak zmiany DDL, i wiele działań w bazach danych jest bardzo korzystne dla administratorów baz danych. Pomaga szybko zidentyfikować słabe łącza i problematyczne zapytania, które dają przegląd możliwej przyczyny złych zapytań, które mogą zablokować lub przestarzać bazę danych.