Chcesz dowiedzieć się wszystkiego o klastrze Hadoop?
Hadoop to platforma programowa do analizowania i przechowywania ogromnych ilości danych w klastrach zwykłego sprzętu. W tym artykule przyjrzymy się klasterowi Hadoop.
Zacznijmy od wprowadzenia do klastra.
Co to jest klaster?
Klaster to zbiór węzłów. Węzły to nic innego jak punkt połączenia/przecięcia w sieci.
Klaster komputerów to zbiór komputerów połączonych siecią, zdolnych do komunikowania się ze sobą i pracujących jako jeden system.
Co to jest klaster Hadoop?
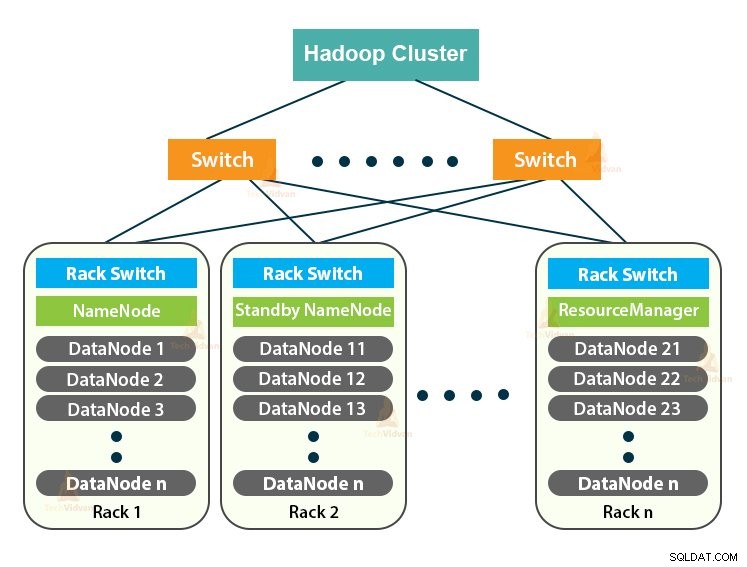
Klaster Hadoop to po prostu klaster komputerowy używany do obsługi dużej ilości danych w sposób rozproszony.
Jest to klaster obliczeniowy przeznaczony do przechowywania, a także analizowania ogromnych ilości nieustrukturyzowanych lub ustrukturyzowanych danych w rozproszonym środowisku obliczeniowym.
Klastry Hadoop są również znane jako systemy współdzielone ponieważ nic nie jest współdzielone między węzłami w klastrze, z wyjątkiem przepustowości sieci. Zmniejsza to opóźnienie przetwarzania.
Dlatego też, gdy zachodzi potrzeba przetwarzania zapytań na ogromnej ilości danych, opóźnienie w całym klastrze jest zminimalizowane.
Przeanalizujmy teraz architekturę klastra Hadoop.
Architektura klastra Hadoop
Klaster Hadoop działa w oparciu o architekturę master-slave. Składa się z węzła głównego, węzłów podrzędnych i węzła klienta.
1. Mistrz w klastrze Hadoop
Master in the Hadoop Cluster to maszyna o dużej mocy z wysoką konfiguracją pamięci i procesora. Dwa demony, które są NameNode i ResourceManager, działają na węźle głównym.
a. Funkcje NameNode
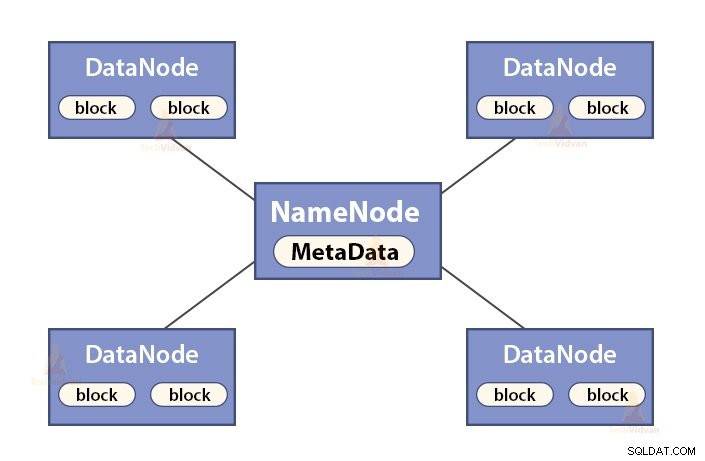
NameNode jest węzłem głównym w Hadoop HDFS . NameNode zarządza przestrzenią nazw systemu plików. Przechowuje metadane systemu plików w pamięci w celu szybkiego wyszukiwania. Dlatego powinien być skonfigurowany na maszynach z najwyższej półki.
Funkcje NameNode to:
- Zarządza przestrzenią nazw systemu plików
- Przechowuje metadane dotyczące bloków pliku, lokalizacji bloków, uprawnień itp.
- Wykonuje operacje przestrzeni nazw systemu plików, takie jak otwieranie, zamykanie, zmiana nazw plików i katalogów itp.
- Utrzymuje i zarządza DataNode.
b. Funkcje Menedżera zasobów
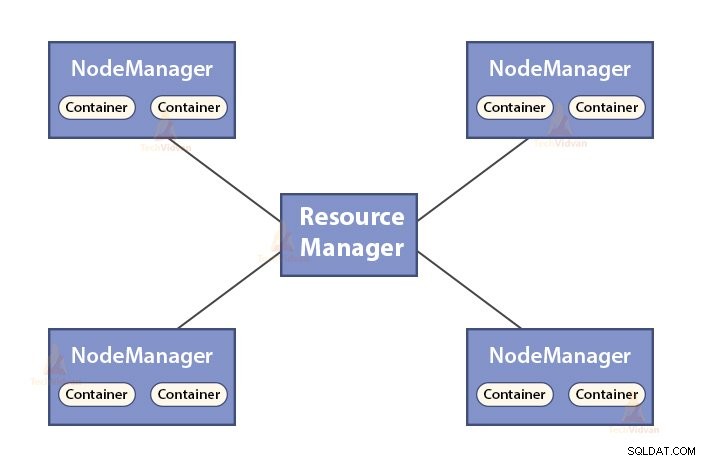
- ResourceManager jest głównym demonem YARN.
- Menedżer zasobów rozpatruje zasoby wśród wszystkich aplikacji w systemie.
- Śledzi aktywne i martwe węzły w klastrze.
2. Niewolnicy w gromadzie Hadoop
Urządzenia niewolnicze w klastrze Hadoop to niedrogi sprzęt. Dwa demony, które są DataNodes i YARN NodeManagers, działają na węzłach podrzędnych.
a. Funkcje DataNodes
- DataNodes przechowuje rzeczywiste dane biznesowe. Przechowuje bloki pliku.
- Wykonuje tworzenie, usuwanie, replikację bloków na podstawie instrukcji z NameNode.
- DataNode jest odpowiedzialny za obsługę operacji odczytu/zapisu klienta.
b. Funkcje NodeManagera
- NodeManager jest demonem podrzędnym YARN.
- Odpowiada za kontenery, monitorując wykorzystanie ich zasobów (takich jak procesor, dysk, pamięć, sieć) i zgłaszając je do Menedżera zasobów.
- NodeManager sprawdza również stan węzła, na którym jest uruchomiony.
3. Węzeł klienta w klastrze Hadoop
Węzły klienckie w Hadoop nie są ani węzłem głównym, ani węzłem podrzędnym. Mają zainstalowany Hadoop ze wszystkimi ustawieniami klastra.
Funkcje węzłów klienta
- Węzły klienckie ładują dane do klastra Hadoop.
- Przesyła zadania MapReduce, opisując sposób przetwarzania tych danych.
- Pobierz wyniki zadania po zakończeniu przetwarzania.
Możemy skalować klaster Hadoop, dodając więcej węzłów. To sprawia, że Hadoop jest liniowo skalowalny . Z każdym dodaniem węzła otrzymujemy odpowiedni wzrost przepustowości. Jeśli mamy „n” węzłów, dodanie 1 węzła daje (1/n) dodatkową moc obliczeniową.
Jedenwęzłowy klaster Hadoop VS wielowęzłowy klaster Hadoop
1. Klaster Hadoop z jednym węzłem
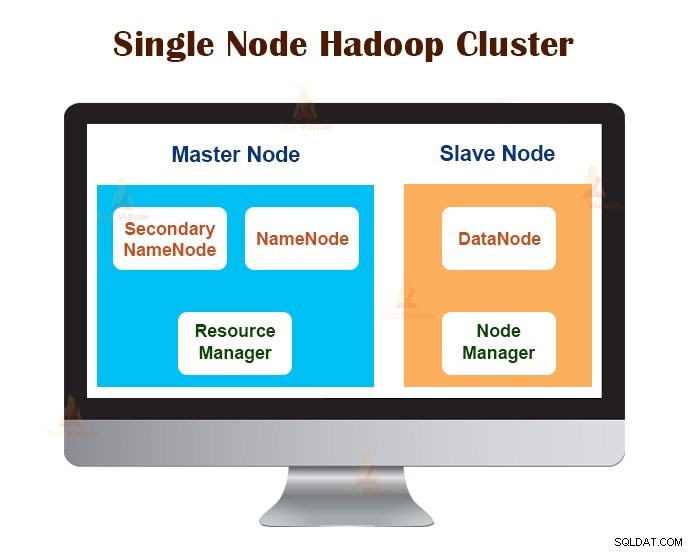
Klaster Hadoop z jednym węzłem jest wdrażany na jednym komputerze. Wszystkie demony, takie jak NameNode, DataNode, ResourceManager, NodeManager działają na tym samym komputerze/hoście.
W konfiguracji klastra z jednym węzłem wszystko działa na jednej instancji JVM. Użytkownik Hadoop nie musiał wprowadzać żadnych ustawień konfiguracyjnych poza ustawieniem zmiennej JAVA_HOME.
Domyślny współczynnik replikacji dla klastra Hadoop z jednym węzłem wynosi zawsze 1.
2. Wielowęzłowy klaster Hadoop
Wielowęzłowy klaster Hadoop jest wdrażany na wielu komputerach. Wszystkie demony w wielowęzłowym klastrze Hadoop działają na różnych maszynach/hostach.
Wielowęzłowy klaster Hadoop jest zgodny z architekturą master-slave. Demony Namenode i ResourceManager działają na węzłach głównych, które są wysokiej klasy komputerami.
Demony DataNodes i NodeManagers działają na węzłach podrzędnych (węzłach roboczych), które są niedrogim, standardowym sprzętem.
W wielowęzłowym klastrze Hadoop maszyny podrzędne mogą znajdować się w dowolnej lokalizacji, niezależnie od lokalizacji fizycznej lokalizacji serwera głównego.
Protokoły komunikacyjne używane w klastrze Hadoop
Protokoły komunikacyjne HDFS są umieszczone na szczycie protokołu TCP/IP. Klient nawiązuje połączenie z NameNode przez konfigurowalny port TCP na maszynie NameNode.
Klaster Hadoop nawiązuje połączenie z klientem za pośrednictwem protokołu ClientProtocol. Ponadto DataNode komunikuje się z NameNode za pomocą protokołu DataNode.
Abstrakcja Remote Procedure Call (RPC) obejmuje Client Protocol i DataNode. Z założenia NameNode nie inicjuje żadnych RPC. Odpowiada tylko na żądania RPC wysyłane przez klientów lub DataNodes.
Sprawdzone metody tworzenia klastra Hadoop
Wydajność klastra Hadoop zależy od różnych czynników w oparciu o dobrze zwymiarowane zasoby sprzętowe, które wykorzystują procesor, pamięć, przepustowość sieci, dysk twardy i inne dobrze skonfigurowane warstwy oprogramowania.
Budowanie klastra Hadoop to nietrywialne zadanie. Wymaga rozważenia różnych czynników, takich jak wybór odpowiedniego sprzętu, wielkość klastrów Hadoop i konfiguracja klastra Hadoop.
Przyjrzyjmy się teraz szczegółowo każdemu z nich.
1. Wybór odpowiedniego sprzętu dla klastra Hadoop
Wiele organizacji podczas konfigurowania infrastruktury Hadoop znajduje się w trudnej sytuacji, ponieważ nie są świadome rodzaju maszyn, które muszą kupić, aby skonfigurować zoptymalizowane środowisko Hadoop, ani idealnej konfiguracji, z której muszą korzystać.
Aby wybrać odpowiedni sprzęt dla klastra Hadoop, należy wziąć pod uwagę następujące punkty:
- Objętość danych, które klaster będzie obsługiwał.
- Rodzaj obciążeń, z jakimi będzie miał do czynienia klaster (powiązanie z procesorem, powiązanie we/wy).
- Metodologia przechowywania danych, taka jak kontenery danych, techniki kompresji danych, jeśli takie istnieją.
- Zasady przechowywania danych, czyli jak długo chcemy przechowywać dane przed ich usunięciem.
2. Rozmiar klastra Hadoop
Aby określić rozmiar klastra Hadoop, kluczową kwestią powinna być ilość danych, które użytkownicy będą przetwarzać w klastrze Hadoop.
Znajomość ilości danych do przetworzenia pomaga zdecydować, ile węzłów będzie potrzebnych do wydajnego przetwarzania danych i pojemności pamięci wymaganej dla każdego węzła. Powinna istnieć równowaga między wydajnością a kosztem zatwierdzonego sprzętu.
3. Konfigurowanie klastra Hadoop
Znalezienie idealnej konfiguracji dla klastra Hadoop nie jest łatwym zadaniem. Framework Hadoop musi być dostosowany do klastra, w którym działa, a także do zadania.
Najlepszym sposobem określenia idealnej konfiguracji klastra Hadoop jest uruchomienie zadań Hadoop z dostępną konfiguracją domyślną w celu uzyskania punktu odniesienia. Następnie możemy przeanalizować pliki dziennika historii zadań, aby sprawdzić, czy występuje jakakolwiek słabość zasobów lub czy czas potrzebny na wykonanie zadań jest dłuższy niż oczekiwano.
Jeśli tak, zmień konfigurację. Powtórzenie tego samego procesu może dostroić konfigurację klastra Hadoop, która najlepiej odpowiada wymaganiom biznesowym.
Wydajność klastra Hadoop w dużej mierze zależy od zasobów przydzielonych demonom. W przypadku małych i średnich kontekstów danych Hadoop rezerwuje jeden rdzeń procesora w każdym węźle DataNode, podczas gdy w przypadku długich zestawów danych przydziela 2 rdzenie procesora w każdym węźle DataNode dla demonów HDFS i MapReduce.
Zarządzanie klastrem Hadoop
Po wdrożeniu klastra Hadoop w środowisku produkcyjnym jest oczywiste, że powinien on skalować się we wszystkich wymiarach, takich jak objętość, różnorodność i prędkość.
Różne funkcje, które powinien posiadać, aby stać się gotowym do produkcji, to:całodobowa dostępność, niezawodność, łatwość zarządzania i wydajność. Zarządzanie klastrem Hadoop jest głównym aspektem inicjatywy Big Data.
Najlepsze narzędzie do zarządzania klastrem Hadoop powinno mieć następujące funkcje:-
- Musi zapewniać wysoką dostępność przez całą dobę, 7 dni w tygodniu, udostępnianie zasobów, zróżnicowane zabezpieczenia, zarządzanie obciążeniem, monitorowanie kondycji, optymalizację wydajności. Ponadto musi zapewniać planowanie zadań, zarządzanie zasadami, tworzenie kopii zapasowych i odzyskiwanie w jednym lub większej liczbie węzłów.
- Zaimplementuj nadmiarowy HDFS NameNode o wysokiej dostępności z równoważeniem obciążenia, gorącym stanem gotowości, ponowną synchronizacją i automatycznym przełączaniem awaryjnym.
- Egzekwowanie mechanizmów kontroli opartych na zasadach, które uniemożliwiają jakiejkolwiek aplikacji przejęcie nieproporcjonalnego udziału zasobów w już wymaksowanym klastrze Hadoop.
- Wykonywanie testów regresji w celu zarządzania wdrażaniem dowolnych warstw oprogramowania w klastrach Hadoop. Ma to na celu upewnienie się, że żadne zadania lub dane nie ulegną awarii lub nie napotkają żadnych wąskich gardeł w codziennych operacjach.
Zalety klastra Hadoop
Różne korzyści zapewniane przez klaster Hadoop to:
1. Skalowalny
Klastry Hadoop są skalowalne. Do klastra Hadoop możemy dodać dowolną liczbę węzłów bez przestojów i bez dodatkowych wysiłków. Z każdym dodaniem węzła otrzymujemy odpowiedni wzrost przepustowości.
2. Wytrzymałość
Klaster Hadoop jest najbardziej znany ze swojej niezawodnej pamięci masowej. Może niezawodnie przechowywać dane, nawet w przypadkach takich jak awaria DataNode, awaria NameNode i partycja sieciowa. DataNode okresowo wysyła sygnał pulsu do NameNode.
W partycji sieciowej zestaw DataNode zostaje odłączony od NameNode, przez co NameNode nie otrzymuje żadnego pulsu z tych DataNode. Następnie NameNode traktuje te DataNode jako martwe i nie przekazuje do nich żadnych żądań I/O.
Ponadto współczynnik replikacji bloków przechowywanych w tych DataNodes spada poniżej określonej wartości. W rezultacie NameNode inicjuje replikację tych bloków i przywraca działanie po awarii.
3. Ponowne równoważenie klastra
Architektura Hadoop HDFS automatycznie przeprowadza ponowne równoważenie klastra. Jeśli wolne miejsce w DataNode spadnie poniżej poziomu progowego, architektura HDFS automatycznie przenosi niektóre dane do innego DataNode, gdzie dostępna jest wystarczająca ilość miejsca.
4. Opłacalne
Skonfigurowanie klastra Hadoop jest opłacalne, ponieważ obejmuje niedrogi sprzęt. Każda organizacja może łatwo skonfigurować potężny klaster Hadoop bez wydawania dużych pieniędzy na drogi sprzęt serwerowy.
Ponadto klastry Hadoop z topologią rozproszonej pamięci masowej przezwyciężają ograniczenia tradycyjnego systemu. Ograniczone miejsce do przechowywania można rozszerzyć, dodając do systemu dodatkowe niedrogie jednostki pamięci.
5. Elastyczny
Klastry Hadoop są bardzo elastyczne, ponieważ mogą przetwarzać dane dowolnego typu, ustrukturyzowane, częściowo ustrukturyzowane lub nieustrukturyzowane, io dowolnych rozmiarach, od gigabajtów do petabajtów.
6. Szybkie przetwarzanie
W klastrze Hadoop dane mogą być przetwarzane równolegle w środowisku rozproszonym. Zapewnia to szybkie przetwarzanie danych w usłudze Hadoop. Klastry Hadoop mogą przetwarzać terabajty lub petabajty danych w ułamku sekundy.
7. Integralność danych
Aby sprawdzić, czy w blokach danych nie ma uszkodzeń spowodowanych błędnym oprogramowaniem, błędami urządzenia pamięci masowej itp., klaster Hadoop implementuje sumę kontrolną w każdym bloku pliku. Jeśli znajdzie uszkodzony blok, szuka go w innym DataNode, który zawiera replikę tego samego bloku. W ten sposób klaster Hadoop zachowuje integralność danych.
Podsumowanie
Po przeczytaniu tego artykułu możemy stwierdzić, że Klaster Hadoop to specjalny klaster obliczeniowy przeznaczony do analizy i przechowywania dużych zbiorów danych. Klaster Hadoop jest zgodny z architekturą master-slave.
Węzeł nadrzędny to wysokiej klasy maszyna komputerowa, a węzły podrzędne to maszyny z normalną konfiguracją procesora i pamięci. Widzieliśmy również, że klaster Hadoop można skonfigurować na pojedynczej maszynie zwanej jednowęzłowym klastrem Hadoop lub na wielu maszynach zwanej wielowęzłowym klastrem Hadoop.
W tym artykule omówiliśmy również najlepsze praktyki, których należy przestrzegać podczas tworzenia klastra Hadoop. Dostrzegliśmy również wiele zalet klastra Hadoop, w tym skalowalność, elastyczność, opłacalność itp.



