W tym blogu przedstawimy pełne wprowadzenie Hadoop Mapper . ja
W tym blogu odpowiemy, co to jest Mapper w Hadoop MapReduce, jak działa maper hadoop, jaki jest proces mapowania w Mapreduce, jak Hadoop generuje parę klucz-wartość w MapReduce.
Wprowadzenie do Hadoop Mapper
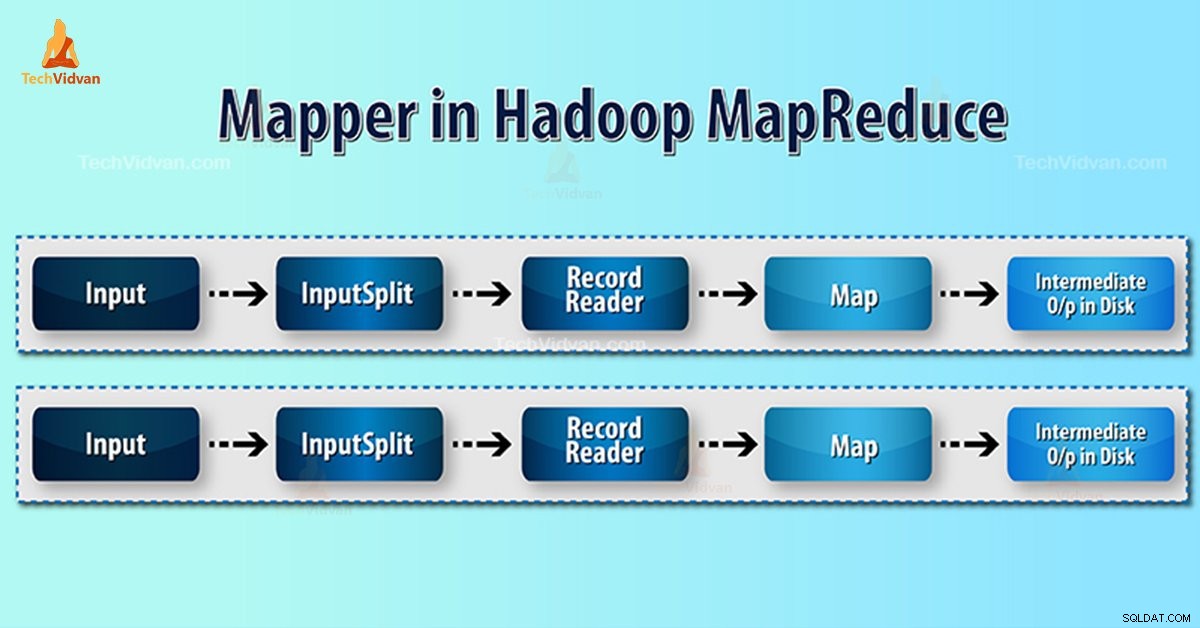
Twórca map Hadoop przetwarza rekord wejściowy utworzony przez RecordReader i generuje pośrednie pary klucz-wartość. Wyjście pośrednie jest zupełnie inne niż para wejściowa.
Wynikiem działania mapowania jest pełna kolekcja par klucz-wartość. Przed zapisaniem danych wyjściowych dla każdego zadania mapowania, partycjonowanie danych wyjściowych odbywa się na podstawie klucza. W ten sposób partycjonowanie wyszczególnia, że wszystkie wartości dla każdego klucza są zgrupowane razem.
Hadoop MapReduce generuje jedno zadanie mapy dla każdego InputSplit.
Hadoop MapReduce rozpoznaje tylko pary klucz-wartość danych. Dlatego przed wysłaniem danych do programu mapującego platforma Hadoop powinna ukryć dane w parze klucz-wartość.
W jaki sposób para klucz-wartość jest generowana w Hadoop?
Skoro zrozumieliśmy, czym jest mapper w hadoop, teraz omówimy, w jaki sposób Hadoop generuje parę klucz-wartość?
- InputSplit – Jest to logiczna reprezentacja danych generowanych przez InputFormat. W programie MapReduce opisuje jednostkę pracy zawierającą pojedyncze zadanie na mapie.
- RecordReader- Komunikuje się z inputSplit. A następnie konwertuje dane na pary klucz-wartość odpowiednie do odczytania przez program mapujący. RecordReader domyślnie używa TextInputFormat do konwersji danych na parę klucz-wartość.
Proces tworzenia map w Hadoop MapReduce
Podział danych konwertuje fizyczną reprezentację bloków na logiczną dla twórcy map. Na przykład, aby odczytać plik 100 MB, będzie to wymagało 2 InputSplit. Dla każdego bloku framework tworzy jeden InputSplit. Każdy InputSplit tworzy jednego mapera.
MapReduce InputSplit nie zawsze zależy od liczby bloków danych . Możemy zmienić numer podziału, ustawiając właściwość mapred.max.split.size podczas wykonywania pracy.
MapReduce RecordReader odpowiada za odczytywanie/konwertowanie danych na pary klucz-wartość do końca pliku. RecordReader przypisuje przesunięcie bajtów do każdego wiersza obecnego w pliku.
Następnie Mapper otrzyma tę parę kluczy. Mapper tworzy pośrednie dane wyjściowe (pary klucz-wartość, które można zredukować).
Ile zadań mapy w Hadoop?
Liczba zadań mapy zależy od całkowitej liczby bloków plików wejściowych. Na mapie MapReduce właściwy poziom równoległości wydaje się wynosić około 10-100 map/węzeł. Ale jest 300 map dla zadań związanych z mapą procesora.
Na przykład mamy rozmiar bloku 128 MB. I spodziewamy się 10 TB danych wejściowych. W ten sposób produkuje 82 000 map. Stąd liczba map zależy od InputFormat.
Mapper =(całkowity rozmiar danych)/ (wejściowy rozmiar podziału)
Przykład – rozmiar danych to 1 TB. Podział danych wejściowych wynosi 100 MB.
Twórca map =(1000*1000)/100 =10 000
Wniosek
Dlatego Mapper w Hadoop pobiera zestaw danych i konwertuje go na inny zestaw danych. W ten sposób dzieli poszczególne elementy na krotki (pary klucz/wartość).
Mam nadzieję, że podoba Ci się ten blok, jeśli masz jakiekolwiek pytania dotyczące mapowania Hadoop, więc zostaw komentarz w sekcji podanej poniżej. Z przyjemnością je rozwiążemy.



