Do tej pory omówiliśmy wprowadzenie Hadoop i Hadoop HDFS szczegółowo. W tym samouczku przedstawimy szczegółowy opis Reduktora Hadoop.
Tutaj omówimy, co to jest Reducer w MapReduce, jak działa Reducer w Hadoop MapReduce, różne fazy Hadoop Reducer, jak możemy zmienić liczbę Reducer w Hadoop MapReduce.
Co to jest Reduktor Hadoop?
Reduktor w Hadoop MapReduce redukuje zestaw wartości pośrednich, które mają wspólny klucz, do mniejszego zestawu wartości.
W przepływie wykonywania zadania MapReduce, Reducer przyjmuje zestaw pośredniej pary klucz-wartość wyprodukowane przez mappera jako wejście. Następnie Reduktor agreguje, filtruje i łączy pary klucz-wartość, co wymaga szerokiego zakresu przetwarzania.
Mapowanie jeden-jeden odbywa się między kluczami i reduktorami w wykonaniu zadania MapReduce. Działają równolegle, ponieważ są od siebie niezależne. Użytkownik decyduje o liczbie reduktorów w MapReduce.
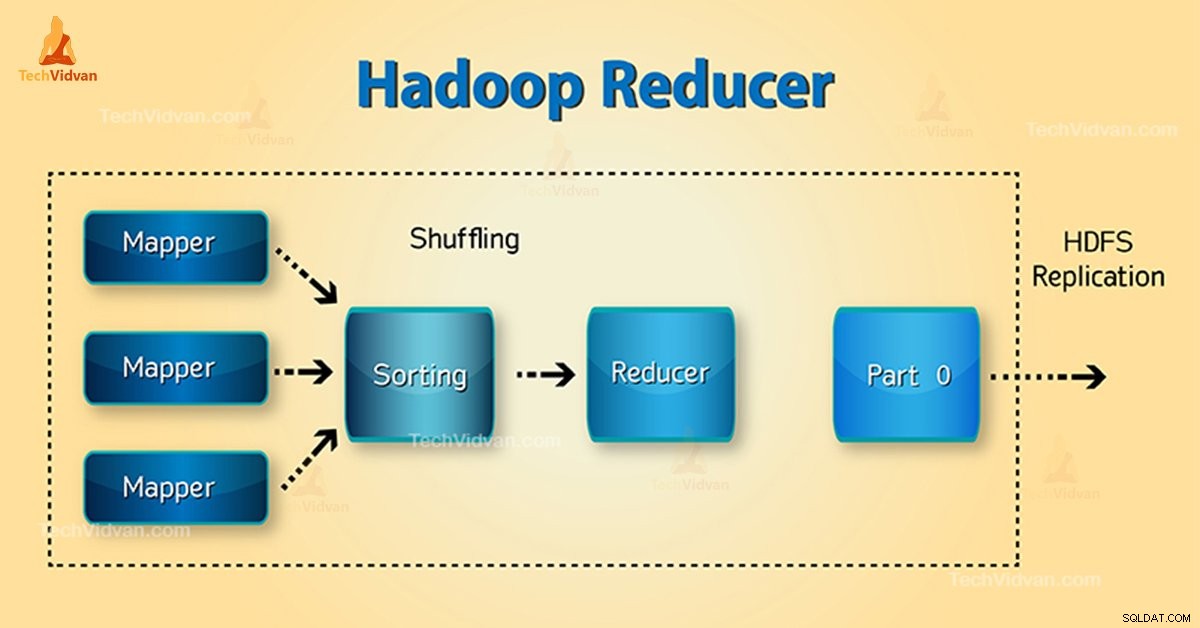
Fazy redukcji Hadoop
Trzy fazy Reduktora są następujące:
1. Faza tasowania
Jest to faza, w której posortowane wyjście z mapera jest wejściem do reduktora. Framework za pomocą HTTP pobiera odpowiednią partycję danych wyjściowych wszystkich maperów w tej fazie.Faza sortowania
2. Faza sortowania
Jest to faza, w której dane wejściowe z różnych programów mapujących są ponownie sortowane na podstawie podobnych kluczy w różnych programach mapujących.
Zarówno tasowanie, jak i sortowanie odbywają się jednocześnie.
3. Zmniejsz fazę
Ta faza następuje po przetasowaniu i sortowaniu. Zadanie redukcji agreguje pary klucz-wartość. Za pomocą OutputCollector.collect() właściwość, dane wyjściowe zadania zmniejszania są zapisywane w systemie plików. Wyjście reduktora nie jest sortowane.
Liczba reduktorów w Hadoop MapReduce
Użytkownik ustawia liczbę reduktorów za pomocą Job.setNumreduceTasks(int) własność. Zatem odpowiednia liczba reduktorów według wzoru:
0,95 lub 1,75 pomnożone przez (
Tak więc przy 0,95 wszystkie reduktory natychmiast się uruchamiają. Następnie rozpocznij przesyłanie danych wyjściowych map, gdy mapy się skończą.
Szybszy węzeł kończy pierwszą rundę reduktorów z 1,75. Następnie uruchamia drugą falę reduktora, który znacznie lepiej radzi sobie z równoważeniem obciążenia.
Wraz ze wzrostem liczby reduktorów:
- Wzrost kosztów ogólnych ram.
- Zwiększa się równoważenie obciążenia.
- Koszt awarii spada.
Wniosek
Dlatego Reduktor pobiera dane wyjściowe maperów jako dane wejściowe. Następnie przetwórz pary klucz-wartość i wygeneruj dane wyjściowe. Wyjście reduktora to wyjście końcowe. Jeśli podoba Ci się ten blog lub masz jakiekolwiek pytania związane z Hadoop Reducer, podziel się z nami, zostawiając komentarz.
Mam nadzieję, że Ci pomożemy.



