Ten wpis na blogu przedstawi prosty przykład „hello world”, jak uzyskać dane przechowywane w S3 zindeksowane i obsługiwane przez usługę Apache Solr hostowaną w klastrze Data Discovery and Exploration w CDP. Dla ciekawskich:DDE to wstępnie zoptymalizowana opcja wdrażania klastrów zoptymalizowana pod kątem Solr w CDP, która została niedawno wydana w przeglądzie technicznym . W tym blogu omówimy tylko środowiska AWS i S3. Opcje wdrażania platformy Azure i ADLS są również dostępne w wersji zapoznawczej, ale zostaną omówione w przyszłym poście na blogu.
Przedstawimy najprostszy scenariusz, aby ułatwić rozpoczęcie pracy. Istnieją oczywiście bardziej zaawansowane konfiguracje potoków danych i bardziej rozbudowane schematy, ale jest to dobry punkt wyjścia dla początkującego.
Założenia:
- Masz już konto CDP i masz uprawnienia zaawansowanego użytkownika lub administratora w środowisku, w którym planujesz uruchomić tę usługę.
Jeśli nie masz konta CDP AWS, skontaktuj się ze swoim ulubionym przedstawicielem Cloudera lub zarejestruj się, aby skorzystać z wersji próbnej CDP tutaj. - Masz zmapowane i skonfigurowane środowiska i tożsamości. Mówiąc dokładniej, wszystko, czego potrzebujesz, to mapowanie użytkownika CDP na rolę AWS, która zapewnia dostęp do konkretnego wiadra s3, z którego chcesz czytać (i pisać).
- Masz już ustawione hasło obciążenia (FreeIPA).
- Masz uruchomiony klaster DDE. Więcej informacji na temat korzystania z szablonów w CDP Data Hub znajdziesz tutaj.
- Masz dostęp CLI do tego klastra.
- Port SSH jest otwarty w AWS, tak jak w przypadku Twojego adresu IP. Możesz uzyskać publiczny adres IP dla jednego z węzłów Solr w szczegółach klastra Datahub. Dowiedz się tutaj, jak SSH do klastra AWS.
- Masz plik dziennika w zasobniku S3, który jest dostępny dla Twojego użytkownika (w tym przykładzie
/sample.log). Jeśli go nie masz, oto link do tego, którego użyliśmy.
Przepływ pracy
Poniższe sekcje przeprowadzą Cię przez kroki, aby uzyskać indeksowanie danych za pomocą narzędzia Crunch Indexer, które jest dostarczane po wyjęciu z pudełka z DDE.

Utwórz kolekcję do przechowywania indeksu
W HUE jest projektant indeksu; jednak tak długo, jak DDE jest w Tech Preview, będzie nieco w trakcie przebudowy i nie jest to zalecane w tym momencie. Ale spróbuj tego, gdy DDE przejdzie w GA i daj nam znać, co myślisz.
Na razie możesz stworzyć swój schemat i konfiguracje Solr za pomocą narzędzia CLI „solrctl”. Utwórz konfigurację o nazwie „moje-własne-logi” i kolekcję o nazwie „moje-własne-logi”. Wymaga to dostępu do CLI.
1. SSH do dowolnego węzła roboczego w klastrze.
2. kinit jako użytkownik z uprawnieniami do tworzenia konfiguracji kolekcji:
kinit
3. Upewnij się, że zmienna środowiskowa SOLR_ZK_ENSEMBLE jest ustawiona w /etc/solr/conf/solr-env.sh. Zapisz jego wartość, ponieważ będzie to wymagane w dalszych krokach.
Naciśnij Enter i wpisz hasło obciążenia (FreeIPA).
Na przykład:
cat /etc/solr/conf/solr-env.sh
Oczekiwany wynik:
export SOLR_ZK_ENSEMBLE=zk01.example.com:2181,zk02.example.com:2181,zk03.example.com:2181/solr
Jest to automatycznie ustawiane na hostach z rolą Solr Server lub Gateway w Cloudera Manager.
4. Aby wygenerować pliki konfiguracyjne dla kolekcji, uruchom następujące polecenie:
solrctl config --create my-own-logs-config schemalessTemplate -p immutable=false
schemalessTemplate jest jednym z domyślnych szablonów dostarczanych z Solr w CDP, ale jako szablon jest niezmienny. Na potrzeby tego przepływu pracy musisz go skopiować, a tym samym utworzyć nowy, który można modyfikować (tak właśnie działa opcja immutable=false). Zapewnia to elastyczną konfigurację bez schematu. Stworzenie dobrze zaprojektowanego schematu jest czymś, w co warto zainwestować czas projektowania, ale nie jest konieczne do wykorzystania eksploracyjnego. Z tego powodu wykracza to poza zakres tego wpisu na blogu. Jednak w rzeczywistym środowisku produkcyjnym zdecydowanie zalecamy korzystanie z dobrze zaprojektowanych schematów – i w razie potrzeby chętnie udzielimy fachowej pomocy!
5. Utwórz nową kolekcję za pomocą następującego polecenia:
solrctl collection --create my-own-logs -s 1 -c my-own-logs-config
Spowoduje to utworzenie kolekcji „my-own-logs” na podstawie konfiguracji kolekcji „my-own-logs-config” na jednym fragmencie.
6. Aby sprawdzić, czy kolekcja została utworzona, możesz przejść do interfejsu administratora Solr. Zbiór „moich własnych dzienników” będzie dostępny w menu rozwijanym w lewym panelu nawigacyjnym.

Indeksuj swoje dane
Tutaj opisujemy na prostym przykładzie, jak skonfigurować i uruchomić wbudowane narzędzie Crunch Indexer, aby szybko indeksować dane w S3 i obsługiwać przez Solr w DDE. Ponieważ zabezpieczenie klastra może wykorzystywać CM Auto TLS, Knox, Kerberos i Ranger, „przesłanie Spark” może zależeć od aspektów nieomówionych w tym poście.
Indeksowanie danych z S3 jest takie samo, jak indeksowanie z HDFS.
Wykonaj te czynności w węźle roboczym przędzy (nazywanym „pracownikiem przędzy” w interfejsie webUI konsoli zarządzania).
1. SSH do dedykowanego węzła roboczego Yarn klastra DDE jako użytkownik administracyjny Solr.
Aby znaleźć adres IP węzła roboczego Yarn, kliknij Sprzęt na stronie szczegółów klastra, a następnie przewiń do węzła „Przędzarka”.

2. Przejdź do katalogu zasobów (lub utwórz go, jeśli jeszcze go nie masz:
cd
Użyj folderu domowego administratora jako katalogu zasobów (
3. Dostosuj swojego użytkownika :
kinit
Naciśnij Enter i wpisz hasło obciążenia (FreeIPA).
4. Uruchom następujące polecenie curl, zastępując
curl --negotiate -u: "https://<SOLR_HOST>:<SOLR_PORT>/solr/admin?op=GETDELEGATIONTOKEN" --insecure > tokenFile.txt
5. Utwórz plik konfiguracyjny Morphline dla narzędzia Crunch Indexer, w tym przykładzie read-log-morphline.conf. Zastąp
SOLR_LOCATOR : {
# Name of solr collection
collection : my-own-logs
#zk ensemble
zkHost : <SOLR_ZK_ENSEMBLE>
}
morphlines : [
{
id : loadLogs
importCommands : ["org.kitesdk.**", "org.apache.solr.**"]
commands : [
{
readMultiLine {
regex : "(^.+Exception: .+)|(^\\s+at .+)|(^\\s+\\.\\.\\. \\d+ more)|(^\\s*Caused by:.+)"
what : previous
charset : UTF-8
}
}
{ logDebug { format : "output record: {}", args : ["@{}"] } }
{
loadSolr {
solrLocator : ${SOLR_LOCATOR}
}
}
]
}
]] } Ta Morphline odczytuje ślady stosu z podanego pliku dziennika, a następnie zapisuje dziennik wpisu debugowania i ładuje go do określonego Solr.
6. Utwórz plik log4j.properties do konfiguracji dziennika:
log4j.rootLogger=INFO, A1 # A1 is set to be a ConsoleAppender. log4j.appender.A1=org.apache.log4j.ConsoleAppender # A1 uses PatternLayout. log4j.appender.A1.layout=org.apache.log4j.PatternLayout log4j.appender.A1.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
7. Sprawdź, czy plik, który chcesz przeczytać, istnieje na S3 (jeśli go nie masz, oto link do tego, którego użyliśmy w tym prostym przykładzie:
aws s3 ls s3://<S3_BUCKET>/sample.log
8. Uruchom polecenie spark-submit:
Zastąp symbole zastępcze w
export myDriverJarDir=/opt/cloudera/parcels/CDH/lib/solr/contrib/crunch export myDependencyJarDir=/opt/cloudera/parcels/CDH/lib/search/lib/search-crunch export myDriverJar=$(find $myDriverJarDir -maxdepth 1 -name 'search-crunch-*.jar' ! -name '*-job.jar' ! -name '*-sources.jar') export myDependencyJarFiles=$(find $myDependencyJarDir -name '*.jar' | sort | tr '\n' ',' | head -c -1) export myDependencyJarPaths=$(find $myDependencyJarDir -name '*.jar' | sort | tr '\n' ':' | head -c -1) export myJVMOptions="-DmaxConnectionsPerHost=10000 -DmaxConnections=10000 -Djava.io.tmpdir=/tmp/dir/ " export myResourcesDir="<RESOURCE_DIR>" export HADOOP_CONF_DIR="/etc/hadoop/conf" spark-submit \ --master yarn \ --deploy-mode cluster \ --jars $myDependencyJarFiles \ --executor-memory 1024M \ --conf "spark.executor.extraJavaOptions=$myJVMOptions" \ --driver-java-options "$myJVMOptions" \ --class org.apache.solr.crunch.CrunchIndexerTool \ --files $(ls $myResourcesDir/log4j.properties),$(ls $myResourcesDir/read-log-morphline.conf),tokenFile.txt \ $myDriverJar \ -Dhadoop.tmp.dir=/tmp \ -DtokenFile=tokenFile.txt \ --morphline-file read-log-morphline.conf \ --morphline-id loadLogs \ --pipeline-type spark \ --chatty \ --log4j log4j.properties \ s3a://<S3_BUCKET>/sample.log
Jeśli napotkasz podobny komunikat, możesz go zignorować:
WARN metadata.Hive: Failed to register all functions. org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.thrift.transport.TTransportException
9. Aby monitorować wykonanie polecenia, przejdź do Menedżera zasobów.

Tam wybierz Aplikacje karta > Kliknij Identyfikator aplikacji próby aplikacji, którą chcesz monitorować > Wybierz Dzienniki> Wybierz próbę pobrania kontenerów> Wybierz kontener do pobrania dzienników> Wybierz dziennik kontenera> Wybierz stderr dziennik> Kliknij Kliknij tutaj, aby wyświetlić pełny dziennik .
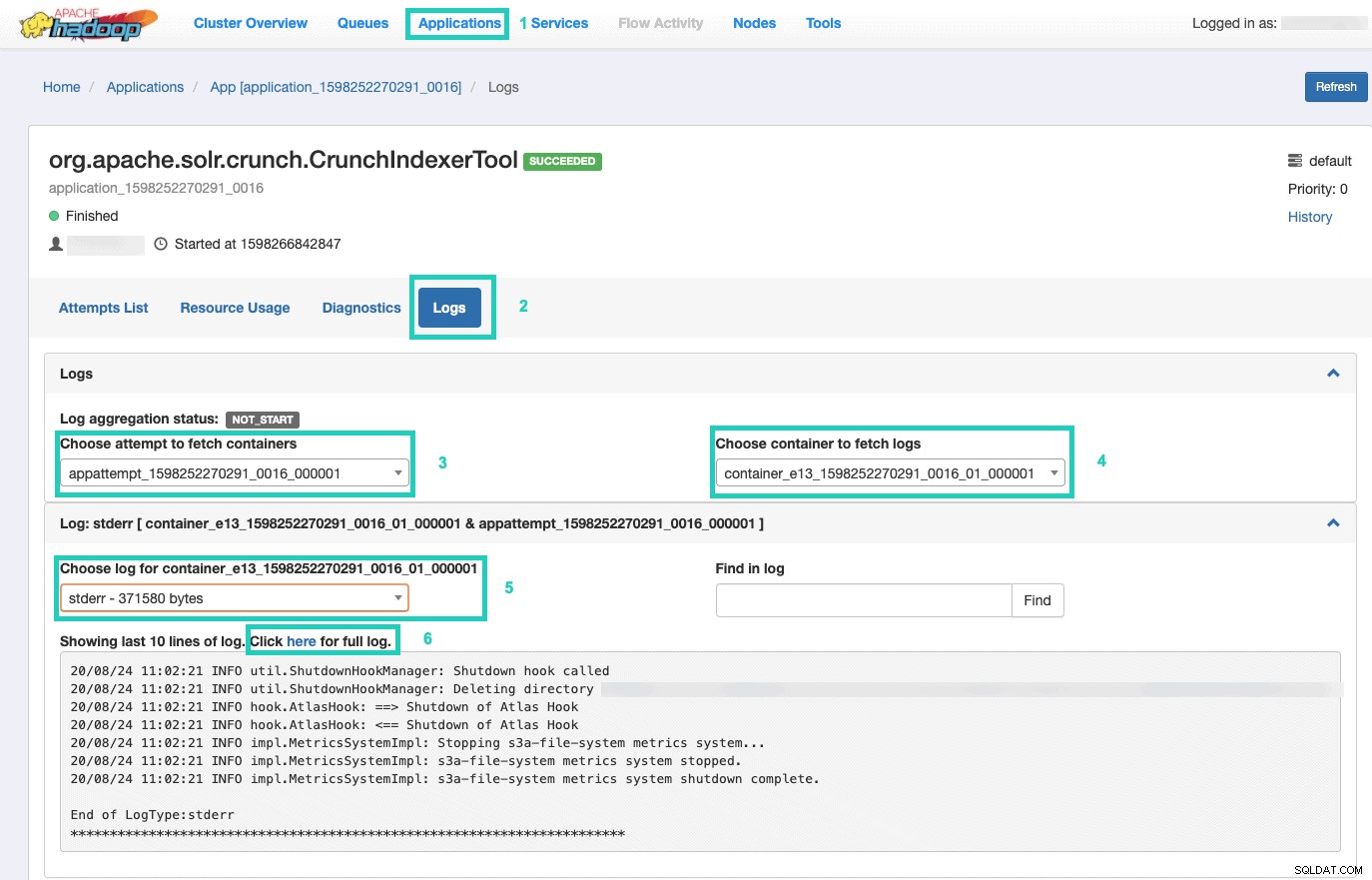
Obsługuj swój indeks
Dostępnych jest wiele opcji udostępniania zindeksowanych danych z możliwością wyszukiwania użytkownikom końcowym. Możesz zbudować własną bogatą aplikację w oparciu o bogate API Solr (bardzo powszechne). Możesz podłączyć swoje ulubione narzędzie innych firm, takie jak Qlik, Tableau itp., za pośrednictwem ich certyfikowanych połączeń Solr. Możesz użyć prostego pulpitu solr Hue do tworzenia prototypowych aplikacji.
Aby zrobić to drugie:
1. Przejdź do barwy.

2. W widoku pulpitu nawigacyjnego przejdź do wybranego pliku indeksu (np. właśnie utworzonego).
3. Rozpocznij przeciąganie i upuszczanie różnych elementów pulpitu nawigacyjnego i wybierz pola z indeksu, aby wypełnić dane dla dostępnej wizualizacji.
Krótki film instruktażowy dotyczący pulpitu nawigacyjnego z przeszłości można znaleźć tutaj, aby uzyskać inspirację.
Zostawimy głębsze omówienie w przyszłym wpisie na blogu.
Podsumowanie
Mamy nadzieję, że z tego wpisu na blogu nauczyłeś się wiele, jak uzyskać dane w S3 zindeksowane przez Solr w DDE za pomocą narzędzia Crunch Indexer. Oczywiście istnieje wiele innych sposobów (Spark w doświadczeniu Data Engineering, Nifi w doświadczeniu Data Flow, Kafka w doświadczeniu Stream Management itd.), ale zostaną one omówione w przyszłych wpisach na blogu. Mamy nadzieję, że Twoja nieustająca podróż w tworzeniu zaawansowanych aplikacji analitycznych obejmujących tekst i inne nieustrukturyzowane dane odnosi duże sukcesy. Jeśli zdecydujesz się wypróbować DDE w CDP, daj nam znać, jak to wszystko poszło!



