Zwiększenie wydajności systemu, zwłaszcza w przypadku struktur komputerowych, wymaga procesu uzyskania dobrego przeglądu wydajności. Ten proces jest ogólnie nazywany monitorowaniem. Monitorowanie jest istotną częścią zarządzania bazą danych, a szczegółowe informacje o wydajności MongoDB pomogą Ci nie tylko ocenić jej stan funkcjonalny; ale także dają wskazówkę dotyczącą anomalii, która jest pomocna podczas przeprowadzania konserwacji. Istotne jest, aby zidentyfikować nietypowe zachowania i naprawić je, zanim przerodzą się w poważniejsze awarie.
Niektóre rodzaje awarii, które mogą się pojawić, to...
- Opóźnienie lub spowolnienie
- Nieadekwatność zasobów
- Czas w systemie
Monitorowanie często koncentruje się na analizie metryk. Niektóre z kluczowych wskaźników, które chcesz monitorować, obejmują...
- Wydajność bazy danych
- Wykorzystanie zasobów (wykorzystanie procesora, dostępnej pamięci i użycie sieci)
- Pojawiające się niepowodzenia
- Nasycenie i ograniczenie zasobów
- Operacje przepustowości
W tym blogu omówimy szczegółowo te metryki i przyjrzymy się dostępnym narzędziom MongoDB (takim jak narzędzia i polecenia). Przyjrzymy się również innym narzędziom programowym, takim jak Pandora, FMS Open Source i Robo 3T. Dla uproszczenia, w tym artykule użyjemy oprogramowania Robo 3T, aby zademonstrować metryki.
Wydajność bazy danych
Pierwszą i najważniejszą rzeczą do sprawdzenia w bazie danych jest jej ogólna wydajność, na przykład, czy serwer jest aktywny, czy nie. Jeśli uruchomisz to polecenie db.serverStatus() w bazie danych w Robo 3T, zobaczysz te informacje pokazujące stan twojego serwera.
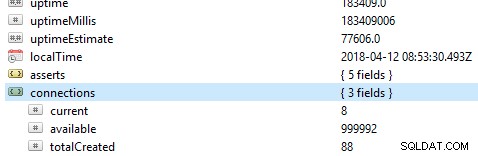

Zestawy replik
Zestaw replik to grupa procesów mongod, które utrzymują ten sam zestaw danych. Jeśli używasz zestawów replik, zwłaszcza w trybie produkcyjnym, dzienniki operacji będą stanowić podstawę procesu replikacji. Wszystkie operacje zapisu są śledzone przy użyciu węzłów, czyli węzła podstawowego i węzła pomocniczego, które przechowują kolekcję o ograniczonym rozmiarze. W węźle podstawowym operacje zapisu są stosowane i przetwarzane. Jeśli jednak węzeł podstawowy ulegnie awarii, zanim zostaną skopiowane do dzienników operacji, następuje zapis wtórny, ale w tym przypadku dane mogą nie zostać zreplikowane.
Kluczowe wskaźniki, na które warto mieć oko...
Opóźnienie replikacji
Określa, jak daleko węzeł drugorzędny znajduje się za węzłem podstawowym. Optymalny stan wymaga, aby odstęp był jak najmniejszy. W normalnym systemie operacyjnym opóźnienie to jest szacowane na 0. Jeśli luka jest zbyt duża, integralność danych zostanie naruszona, gdy węzeł dodatkowy zostanie przeniesiony na główny. W takim przypadku można ustawić próg, na przykład 1 minutę, a jeśli zostanie przekroczony, zostanie ustawiony alert. Najczęstsze przyczyny dużego opóźnienia replikacji to...
- Odłamki, które mogą mieć niewystarczającą pojemność zapisu, co często wiąże się z nasyceniem zasobów.
- Węzeł drugorzędny dostarcza dane wolniej niż węzeł główny.
- Węzły mogą być również w jakiś sposób utrudnione w komunikacji, prawdopodobnie z powodu słabej sieci.
- Operacje w węźle podstawowym mogą być również wolniejsze, co blokuje replikację. Jeśli tak się stanie, możesz uruchomić następujące polecenia:
- db.getProfilingLevel():jeśli uzyskasz wartość 0, operacje na bazie danych są optymalne.
Jeśli wartość wynosi 1, oznacza to powolne operacje, które w konsekwencji mogą być spowodowane wolnymi zapytaniami. - db.getProfilingStatus():w tym przypadku sprawdzamy wartość slowms, domyślnie jest to 100ms. Jeśli wartość jest większa niż ta, być może występują intensywne operacje zapisu na zasobach podstawowych lub nieodpowiednie zasoby pomocnicze. Aby rozwiązać ten problem, możesz przeskalować drugorzędny, aby miał tyle zasobów, co podstawowy.
- db.getProfilingLevel():jeśli uzyskasz wartość 0, operacje na bazie danych są optymalne.
Kursory
Jeśli złożysz żądanie odczytu, na przykład find, otrzymasz kursor, który jest wskaźnikiem do zbioru danych wyniku. Jeśli uruchomisz to polecenie db.serverStatus() i przejdziesz do obiektu metryk, a następnie kursora, zobaczysz to…

W tym przypadku właściwość cursor.timeOut została zaktualizowana przyrostowo do wartości 9, ponieważ było 9 połączeń, które zerwały się bez zamykania kursora. Konsekwencją jest to, że pozostanie otwarty na serwerze, a tym samym będzie zużywał pamięć, chyba że zostanie zebrany przez domyślne ustawienie MongoDB. Alertem dla ciebie powinno być identyfikowanie nieaktywnych kursorów i zbieranie ich w celu zaoszczędzenia pamięci. Możesz także uniknąć kursorów bez limitu czasu, ponieważ często zatrzymują one zasoby, spowalniając w ten sposób wewnętrzną wydajność systemu. Można to osiągnąć, ustawiając wartość właściwości cursor.open.noTimeout na wartość 0.
Dziennik
Biorąc pod uwagę mechanizm WiredTiger Storage Engine, zanim dane zostaną zapisane, są one najpierw zapisywane w plikach dyskowych. Nazywa się to kronikowaniem. Kronikowanie zapewnia dostępność i trwałość danych w przypadku awarii, z której można przeprowadzić odzyskiwanie.
W celu odzyskania często używamy punktów kontrolnych (zwłaszcza w przypadku systemu przechowywania WiredTiger), aby odzyskać od ostatniego punktu kontrolnego. Jeśli jednak MongoDB nieoczekiwanie zamknie się, użyjemy techniki księgowania, aby odzyskać wszelkie dane, które zostały przetworzone lub dostarczone po ostatnim punkcie kontrolnym.
W pierwszym przypadku nie należy wyłączać kronikowania, ponieważ utworzenie nowego punktu kontrolnego zajmuje tylko 60 sekund. Dlatego w przypadku awarii MongoDB może odtworzyć dziennik, aby odzyskać utracone dane w ciągu tych sekund.
Kronikowanie generalnie zawęża przedział czasu od zastosowania danych do pamięci do trwałego zachowania na dysku. Obiekt storage.journal ma właściwość, która opisuje częstotliwość zatwierdzania, tj. commitIntervalMs, która często jest ustawiona na wartość 100 ms dla WiredTiger. Dostrojenie go do niższej wartości poprawi częste nagrywanie zapisów, zmniejszając w ten sposób przypadki utraty danych.
Wydajność blokowania
Może to być spowodowane wieloma żądaniami odczytu i zapisu od wielu klientów. Kiedy tak się dzieje, istnieje potrzeba zachowania spójności i unikania konfliktów zapisu. Aby to osiągnąć, MongoDB wykorzystuje blokowanie wielopoziomowe, które pozwala na wykonywanie operacji blokowania na różnych poziomach, takich jak poziom globalny, bazy danych lub kolekcji.
Jeśli masz słabe wzorce projektowania schematów, będziesz narażony na długotrwałe utrzymywanie blokad. Często zdarza się to podczas wykonywania dwóch lub więcej różnych operacji zapisu na jednym dokumencie w tej samej kolekcji, co skutkuje wzajemnym blokowaniem. W przypadku silnika przechowywania WiredTiger możemy użyć systemu biletów, w którym żądania odczytu lub zapisu pochodzą z czegoś takiego jak kolejka lub wątek.
Domyślnie równoczesna liczba operacji odczytu i zapisu jest definiowana przez parametry wiredTigerConcurrentWriteTransactions i wiredTigerConcurrentReadTransactions, które mają wartość 128.
Jeśli skalujesz tę wartość zbyt wysoko, będziesz ograniczony przez zasoby procesora. Aby zwiększyć przepustowość operacji, wskazane byłoby skalowanie w poziomie przez dostarczenie większej liczby fragmentów.
Kilkadziesiąt — Zostań administratorem baz danych MongoDB — wprowadzenie MongoDB do produkcjiDowiedz się, co trzeba wiedzieć, aby wdrażać, monitorować, zarządzać i skalować MongoDB. Pobierz za darmoWykorzystanie zasobów
Opisuje to ogólnie wykorzystanie dostępnych zasobów, takich jak moc procesora/szybkość przetwarzania i pamięć RAM. Wydajność, szczególnie dla procesora, może się drastycznie zmieniać w zależności od nietypowego obciążenia ruchem. Rzeczy do sprawdzenia to...
- Liczba połączeń
- Przechowywanie
- Pamięć podręczna
Liczba połączeń
Jeśli liczba połączeń jest wyższa niż ta, którą może obsłużyć system bazy danych, będzie dużo kolejek. W konsekwencji spowoduje to przytłoczenie wydajności bazy danych i spowolnienie działania instalacji. Ta liczba może spowodować problemy ze sterownikami, a nawet komplikacje z Twoją aplikacją.
Jeśli monitorujesz określoną liczbę połączeń przez pewien czas, a następnie zauważysz, że ta wartość osiągnęła szczyt, zawsze dobrą praktyką jest ustawienie alertu, jeśli połączenie przekroczy tę liczbę.
Jeśli liczba staje się zbyt wysoka, możesz zwiększyć skalę, aby zaspokoić ten wzrost. Aby to zrobić, musisz znać liczbę połączeń dostępnych w danym okresie, w przeciwnym razie, jeśli dostępne połączenia nie będą wystarczające, żądania nie będą obsługiwane w odpowiednim czasie.
Domyślnie MongoDB zapewnia obsługę do 1 miliona połączeń. Dzięki monitorowaniu zawsze upewnij się, że bieżące połączenia nigdy nie zbliżają się do tej wartości. Możesz sprawdzić wartość w obiekcie połączeń.

Pamięć
Każdy wiersz i rekord danych w MongoDB jest określany jako dokument. Dane dokumentu są w formacie BSON. W danej bazie danych, jeśli uruchomisz polecenie db.stats(), zostaną przedstawione te dane.
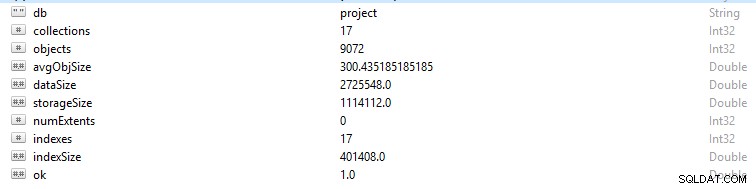
- StorageSize określa rozmiar wszystkich zakresów danych w bazie danych.
- IndexSize określa rozmiar wszystkich indeksów utworzonych w tej bazie danych.
- dataSize jest miarą całkowitej przestrzeni zajmowanej przez dokumenty w bazie danych.
Czasami można zauważyć zmianę w pamięci, zwłaszcza jeśli usunięto dużo danych. W takim przypadku należy skonfigurować alert, aby upewnić się, że nie jest to spowodowane złośliwą aktywnością.
Czasami całkowity rozmiar pamięci może wzrosnąć, gdy wykres ruchu w bazie danych jest stały i w takim przypadku należy sprawdzić strukturę aplikacji lub bazy danych, aby uniknąć duplikatów, jeśli nie jest to konieczne.
Podobnie jak ogólna pamięć komputera, MongoDB ma również pamięci podręczne, w których tymczasowo przechowywane są aktywne dane. Jednak operacja może zażądać danych, których nie ma w tej aktywnej pamięci, stąd żądanie z głównej pamięci dyskowej. To żądanie lub sytuacja jest określana jako błąd strony. Żądania błędów strony mają ograniczenie polegające na tym, że ich wykonanie zajmuje więcej czasu, i mogą być szkodliwe, jeśli występują często. Aby uniknąć tego scenariusza, upewnij się, że rozmiar pamięci RAM jest zawsze wystarczający do obsługi zestawów danych, z którymi pracujesz. Powinieneś również upewnić się, że nie masz nadmiarowości schematów ani niepotrzebnych indeksów.
Pamięć podręczna
Pamięć podręczna jest elementem tymczasowego przechowywania danych dla często używanych danych. W WiredTiger często wykorzystuje się pamięć podręczną systemu plików i pamięć podręczną silnika pamięci masowej. Zawsze upewnij się, że twój zestaw roboczy nie wybrzusza się poza dostępną pamięć podręczną, w przeciwnym razie liczba błędów stron wzrośnie, powodując pewne problemy z wydajnością.
W pewnym momencie możesz zdecydować się na modyfikację swoich częstych operacji, ale zmiany czasami nie są odzwierciedlane w pamięci podręcznej. Te niezmodyfikowane dane są określane jako „Brudne dane”. Istnieje, ponieważ nie został jeszcze usunięty na dysk. Wąskie gardła pojawią się, jeśli ilość „brudnych danych” wzrośnie do pewnej średniej wartości określonej przez powolny zapis na dysku. Dodanie większej liczby odłamków pomoże zmniejszyć tę liczbę.
Wykorzystanie procesora
Niewłaściwe indeksowanie, słaba struktura schematu i nieprzyjazne zaprojektowane zapytania będą wymagały większej uwagi procesora, co oczywiście zwiększy jego wykorzystanie.
Operacje przepustowości
W dużej mierze uzyskanie wystarczającej ilości informacji na temat tych operacji może umożliwić uniknięcie wynikających z tego niepowodzeń, takich jak błędy, nasycenie zasobów i komplikacje funkcjonalne.
Należy zawsze zwracać uwagę na liczbę operacji odczytu i zapisu w bazie danych, czyli wysokopoziomowy widok działań klastra. Znajomość liczby operacji generowanych dla żądań pozwoli Ci obliczyć obciążenie, jakie ma obsłużyć baza danych. Obciążenie można następnie obsłużyć albo skalując bazę danych, albo skalując w górę; w zależności od rodzaju posiadanych zasobów. Pozwala to łatwo ocenić stosunek ilorazu, w jakim gromadzą się żądania, do tempa, w jakim są przetwarzane. Ponadto możesz odpowiednio zoptymalizować swoje zapytania, aby poprawić wydajność.
Aby sprawdzić liczbę operacji odczytu i zapisu, uruchom to polecenie db.serverStatus(), a następnie przejdź do obiektu locks.global, wartość właściwości r reprezentuje liczbę żądań odczytu, aw liczbę zapisów.
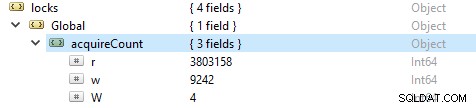
Częściej operacje odczytu to więcej niż operacje zapisu. Metryki aktywnego klienta są raportowane pod globalLock.
Nasycenie i ograniczenie zasobów
Czasami baza danych może nie nadążać za tempem zapisu i odczytu, co obrazuje rosnąca liczba kolejek żądań. W takim przypadku musisz skalować swoją bazę danych, dostarczając więcej fragmentów, aby umożliwić MongoDB wystarczająco szybkie adresowanie żądań.
Pojawiające się niepowodzenia
Pliki dziennika MongoDB zawsze zawierają ogólny przegląd zwracanych wyjątków asercji. Ten wynik da wskazówkę dotyczącą możliwych przyczyn błędów. Jeśli uruchomisz polecenie db.serverStatus(), niektóre z alertów o błędach, które zauważysz, obejmują:

- Zwykłe twierdzenia:są one wynikiem niepowodzenia operacji. Na przykład w schemacie, jeśli wartość ciągu jest dostarczona do pola liczb całkowitych, co skutkuje niepowodzeniem odczytu dokumentu BSON.
- Ostrzeżenie zapewnia:są to często alerty dotyczące jakiegoś problemu, ale nie mają one dużego wpływu na jego działanie. Na przykład podczas uaktualniania MongoDB możesz zostać ostrzeżony przy użyciu przestarzałych funkcji.
- Msg potwierdza:są one wynikiem wyjątków wewnętrznego serwera, takich jak wolna sieć lub brak aktywności serwera.
- Afirmacje użytkownika:podobnie jak zwykłe potwierdzenia, błędy te pojawiają się podczas wykonywania polecenia, ale często są zwracane do klienta. Na przykład, jeśli istnieją zduplikowane klucze, niewystarczająca ilość miejsca na dysku lub brak dostępu do zapisu w bazie danych. Zdecydujesz się sprawdzić swoją aplikację, aby naprawić te błędy.



