Strefy MongoDB
Aby zrozumieć strefy MongoDB, musimy najpierw zrozumieć, czym jest strefa:grupa fragmentów oparta na określonym zestawie tagów.
Strefy MongoDB pomagają w dystrybucji porcji opartych na tagach między shardami. Cała praca (odczyt i zapis) związana z dokumentami w strefie jest wykonywana na fragmentach pasujących do tej strefy.
Mogą istnieć różne scenariusze, w których klastry podzielone na fragmenty (oparte na strefach) mogą okazać się bardzo przydatne. Powiedzmy:
- Aplikacja, która jest rozproszona geograficznie, może wymagać frontendu, a także magazynu danych
- Aplikacja ma architekturę n-warstwową, tak że niektóre rekordy są pobierane ze sprzętu o wyższej warstwie (o małym opóźnieniu), podczas gdy inne mogą być pobierane ze sprzętu o niskiej warstwie (powodującego duże opóźnienia)
Zalety korzystania ze stref MongoDB
Za pomocą stref MongoDB administratorzy baz danych mogą tworzyć warstwowe rozwiązania pamięci masowej, które obsługują cykl życia danych, z często używanymi danymi przechowywanymi w pamięci, rzadziej używanymi danymi przechowywanymi na serwerze oraz zarchiwizowanymi we właściwym czasie danymi pobranymi w trybie offline.
Jak skonfigurować strefy
W klastrach podzielonych na fragmenty można tworzyć strefy reprezentujące grupę fragmentów i kojarzyć z tą strefą co najmniej jeden zakres wartości klucza fragmentu. MongoDB kieruje wszystkie odczyty i wszystkie zapisy, które wchodzą do zakresu strefy, tylko do tych fragmentów wewnątrz strefy. Każdą strefę można skojarzyć z jednym lub większą liczbą fragmentów w klastrze, a fragment może skojarzyć się z dowolną liczbą stref.
Oto niektóre z najczęstszych wzorców rozmieszczania, w których można zastosować strefy:
- Wyizoluj określony podzbiór danych na określonym zestawie odłamków.
- Upewniając się, że najistotniejsze dane znajdują się we fragmentach, które są geograficznie najbliżej serwerów aplikacji.
- Przekieruj dane do fragmentów na podstawie wydajności sprzętu fragmentu.
Poniższy obraz przedstawia klaster podzielonego na fragmenty z trzema fragmentami i dwiema strefami. Strefa A reprezentuje zakres z dolną granicą 0 i górną granicą 10. Strefa B przedstawia zakres z dolną granicą 10 i górną granicą 20. Odłamki CZERWONY i NIEBIESKI mają strefę A. Shard BLUE ma również strefę B. Shard GREEN nie ma z nim powiązanych stref. Klaster jest w stanie stabilnym i żadne fragmenty nie naruszają żadnej ze stref
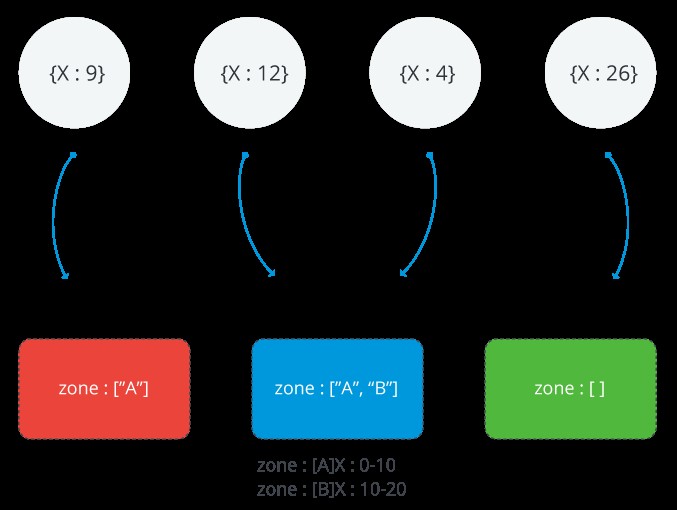
Zakres strefy MongoDB
Każda strefa obejmuje co najmniej jeden zakres wartości klucza fragmentu. Każdy zakres, który obejmuje strefa, zawsze obejmuje dolną granicę i nie obejmuje górnej granicy.
PAMIĘTAJ: Strefy nie mogą dzielić zakresów i nie mogą mieć nakładających się zakresów.
Dodawanie odłamków do strefy
Metoda sh.addShardTag() służy do dodawania stref do sharda. Pojedynczy fragment może mieć wiele stref, a wiele fragmentów może mieć również tę samą strefę. Poniższy przykład dodaje strefę A do jednego fragmentu.
sh.addShardTag("shard0000", "A")Usuwanie odłamków do strefy
Aby usunąć strefę z fragmentu, używana jest metoda sh.removeShardTag(). Poniższy przykład usuwa strefę A z fragmentu.
sh.removeShardTag("shard0002", "A")Wskazówki dotyczące stref MongoDB
Zadbaj o prostotę dokumentów
MongoDB to baza danych pozbawiona schematów. Oznacza to, że domyślnie nie ma wstępnie zdefiniowanego schematu. W nowszych wersjach możemy dodać predefiniowany schemat, ale nie jest to obowiązkowe. Nie lekceważ trudności, które pojawiają się podczas pracy z dokumentami i tablicami, ponieważ parsowanie danych po stronie aplikacji/procesie ETL może być naprawdę trudne. Poza tym macierze mogą pogorszyć wydajność replikacji:przy każdej zmianie w tablicy wszystkie wartości tablicy są replikowane.
Najlepszy sprzęt nie zawsze jest najlepszą opcją
Korzystanie z dobrego sprzętu zdecydowanie pomaga w uzyskaniu dobrej wydajności. Ale co może się stać w środowisku, gdy zginie jedna instancja dużej maszyny? Odpowiedź brzmi „awaria”.
Posiadanie wielu małych maszyn (zamiast jednego lub dwóch) w środowisku rozproszonym może zapewnić, że awarie będą miały wpływ tylko na kilka części fragmentu z niewielkim lub żadnym postrzeganiem przez aplikację. Ale jednocześnie większa liczba maszyn oznacza duże prawdopodobieństwo awarii. Rozważ ten kompromis podczas projektowania środowiska. Właściwe wybory wpływają na wydajność.
Zestaw roboczy
Jak duży jest zestaw roboczy? Zwykle aplikacja nie wykorzystuje wszystkich danych. Niektóre dane są często aktualizowane, a inne nie. Czy Twój działający zestaw danych mieści się w pamięci RAM? Optymalna wydajność występuje, gdy cały zestaw danych roboczych znajduje się w pamięci RAM.



