Obserwowalność danych to kluczowy element układanki operacji bazodanowych — dane umożliwiają wgląd w stan i kondycję krytycznych systemów. Najlepiej byłoby, gdyby dane te były dostępne w jednym miejscu. Gdy masz wiele aplikacji, z których każda obsługuje oddzielne fragmenty danych, narażasz się na potencjalnie poważne problemy. Kiedy pojawiają się problemy, musisz być w stanie szybko ocenić sytuację i określić, co się dzieje, zamiast próbować analizować i łączyć raporty z wielu źródeł.

ClusterControl, między innymi, zapewnia użytkownikom jeden punkt, z którego można śledzić kondycję swoich baz danych. W tym poście na blogu zademonstrujemy niektóre funkcje obserwowalności dostępne w ClusterControl.
Karta Przegląd
Sekcja Przegląd to skonsolidowane miejsce, w którym użytkownicy mogą łatwo śledzić stan jednego klastra, w tym wszystkich węzłów klastra i wszelkich systemów równoważenia obciążenia.
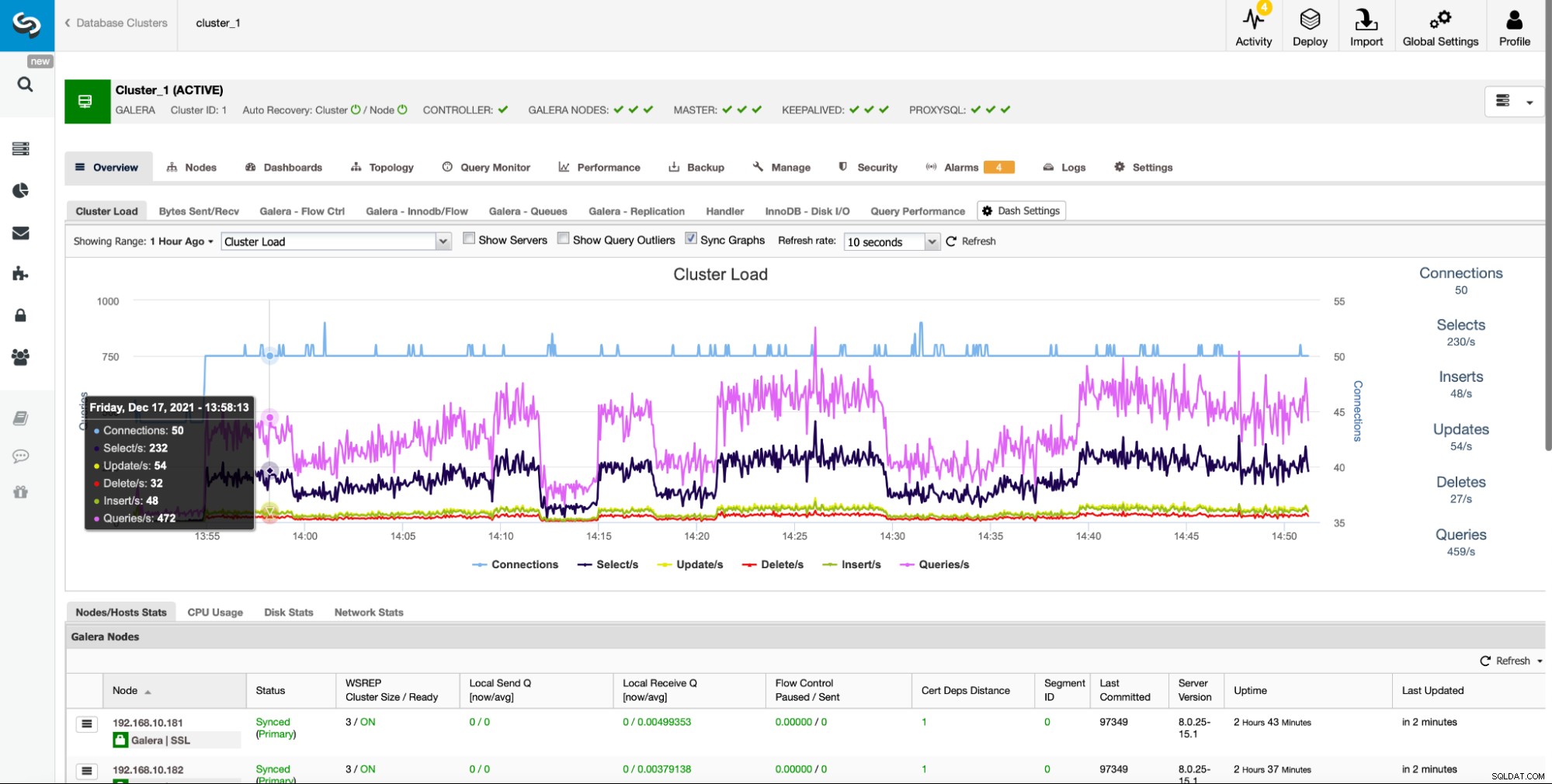
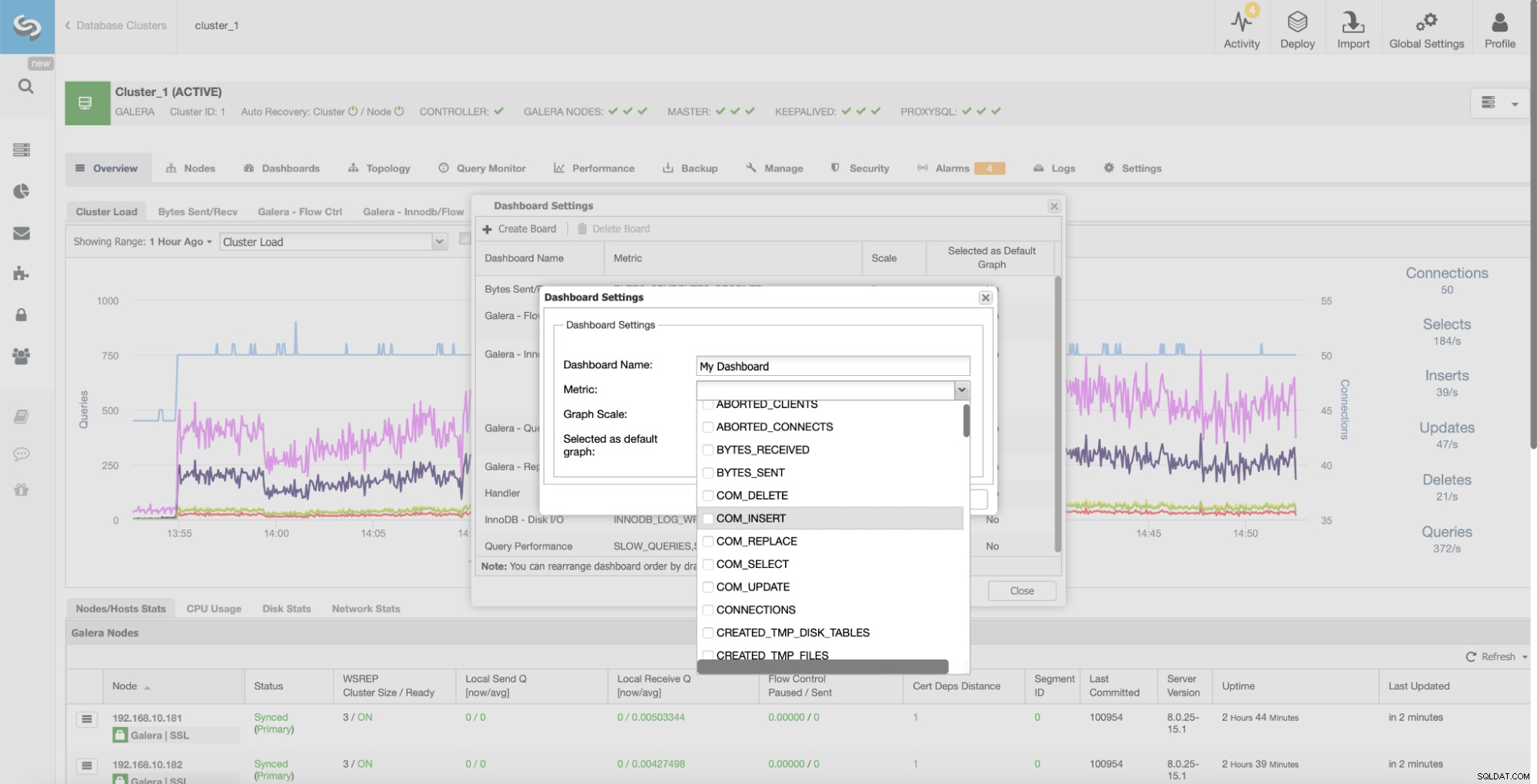
Zapewnia łatwy dostęp do wielu predefiniowanych pulpitów nawigacyjnych, które pokazują najważniejsze informacje dla danego typu klastra. ClusterControl obsługuje różne magazyny danych typu open source, a różne wykresy są wyświetlane w zależności od dostawcy. ClusterControl zapewnia również opcję tworzenia własnych niestandardowych pulpitów nawigacyjnych:
ClusterControl agreguje wykresy ze wszystkich węzłów klastra. Ta kluczowa funkcja ułatwia śledzenie stanu całego klastra. Jeśli chcesz sprawdzić wykresy z każdego węzła, możesz to łatwo zrobić, jak pokazano poniżej:
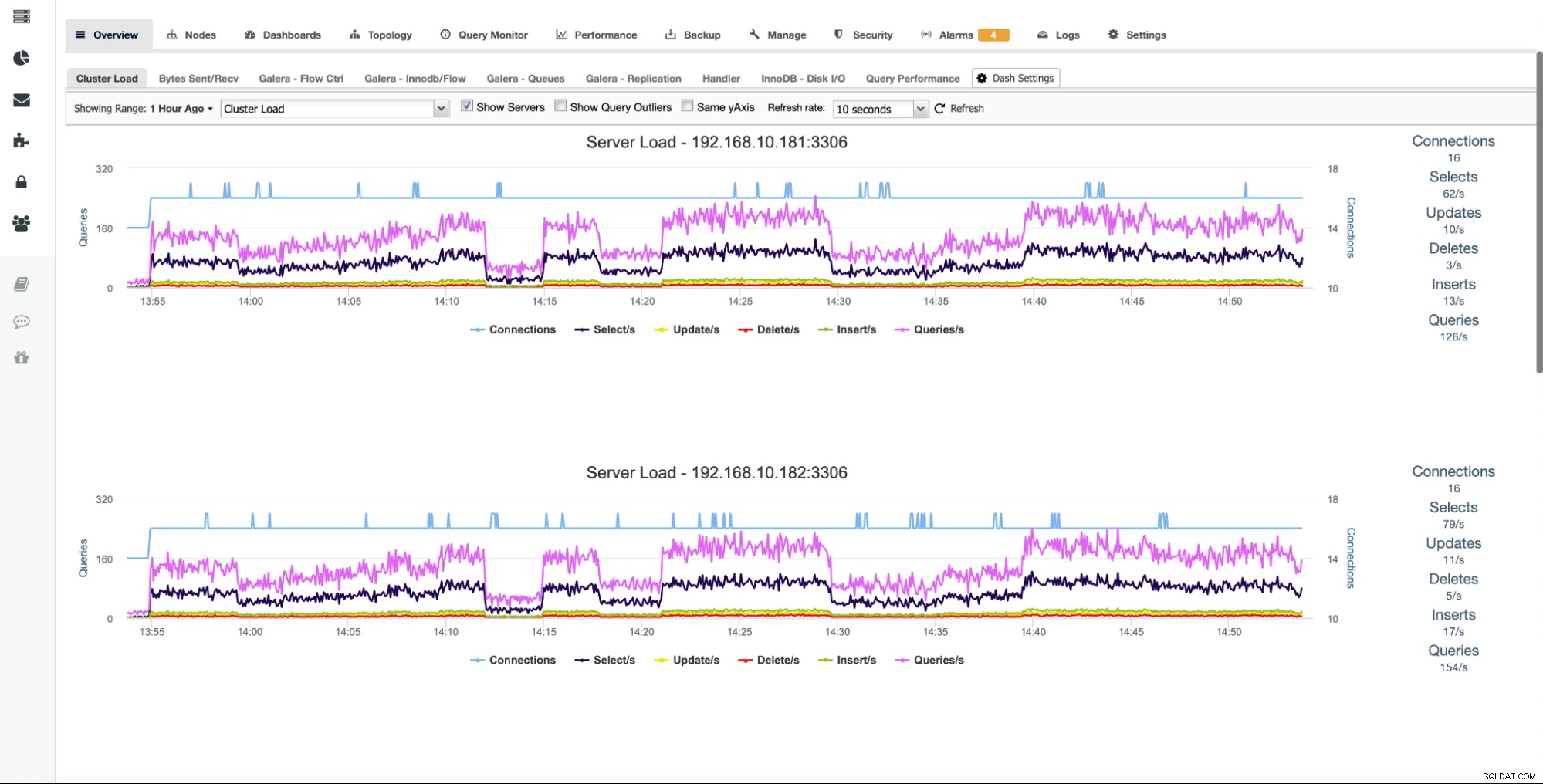
Po zaznaczeniu „Pokaż serwery” zostaną wyświetlone wszystkie węzły w klastrze osobno, co pozwala zagłębić się w każdą z nich.
Karta węzłów
Jeśli chcesz sprawdzić konkretny węzeł bardziej szczegółowo, możesz to zrobić na karcie Węzły.
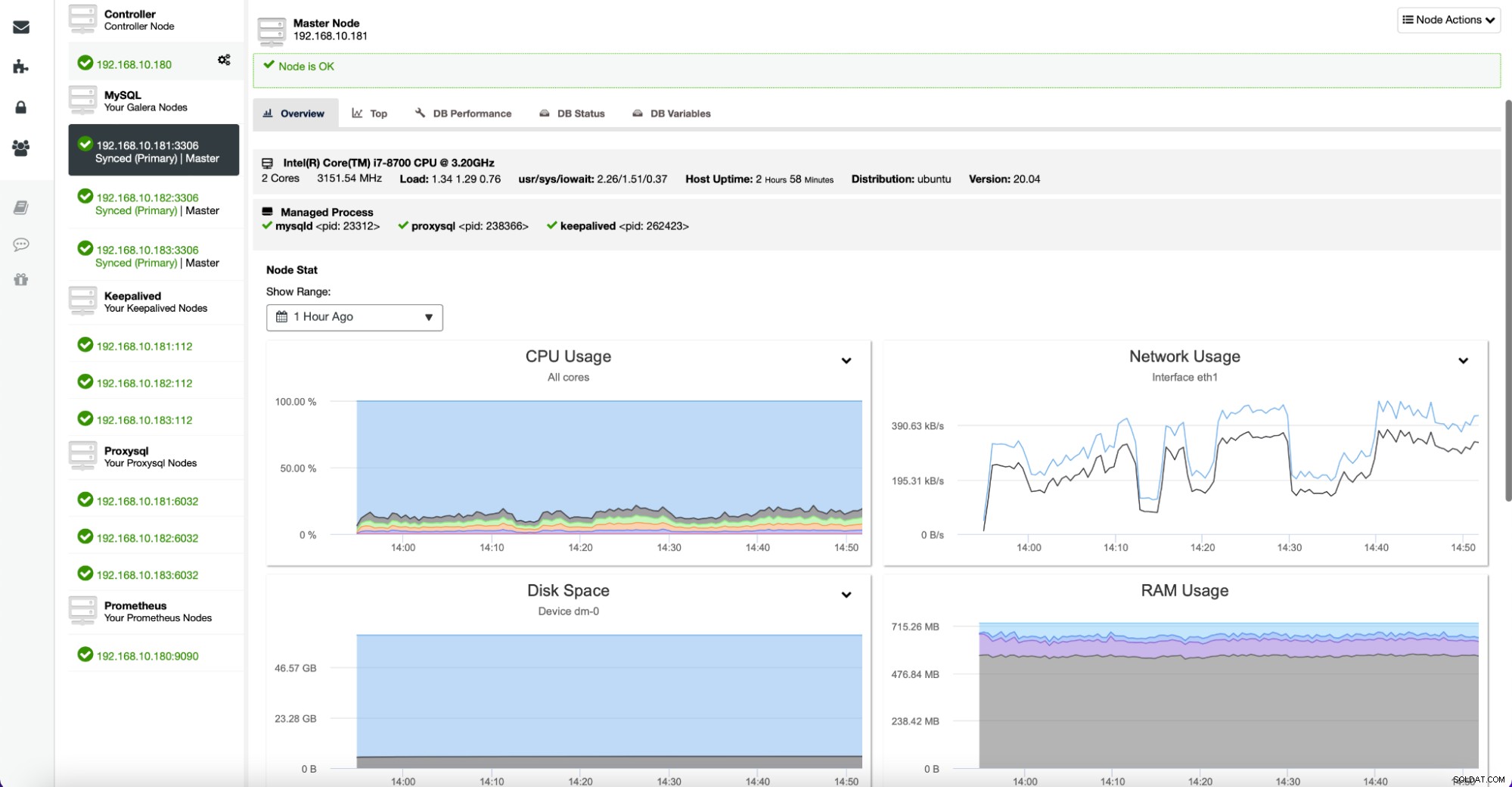
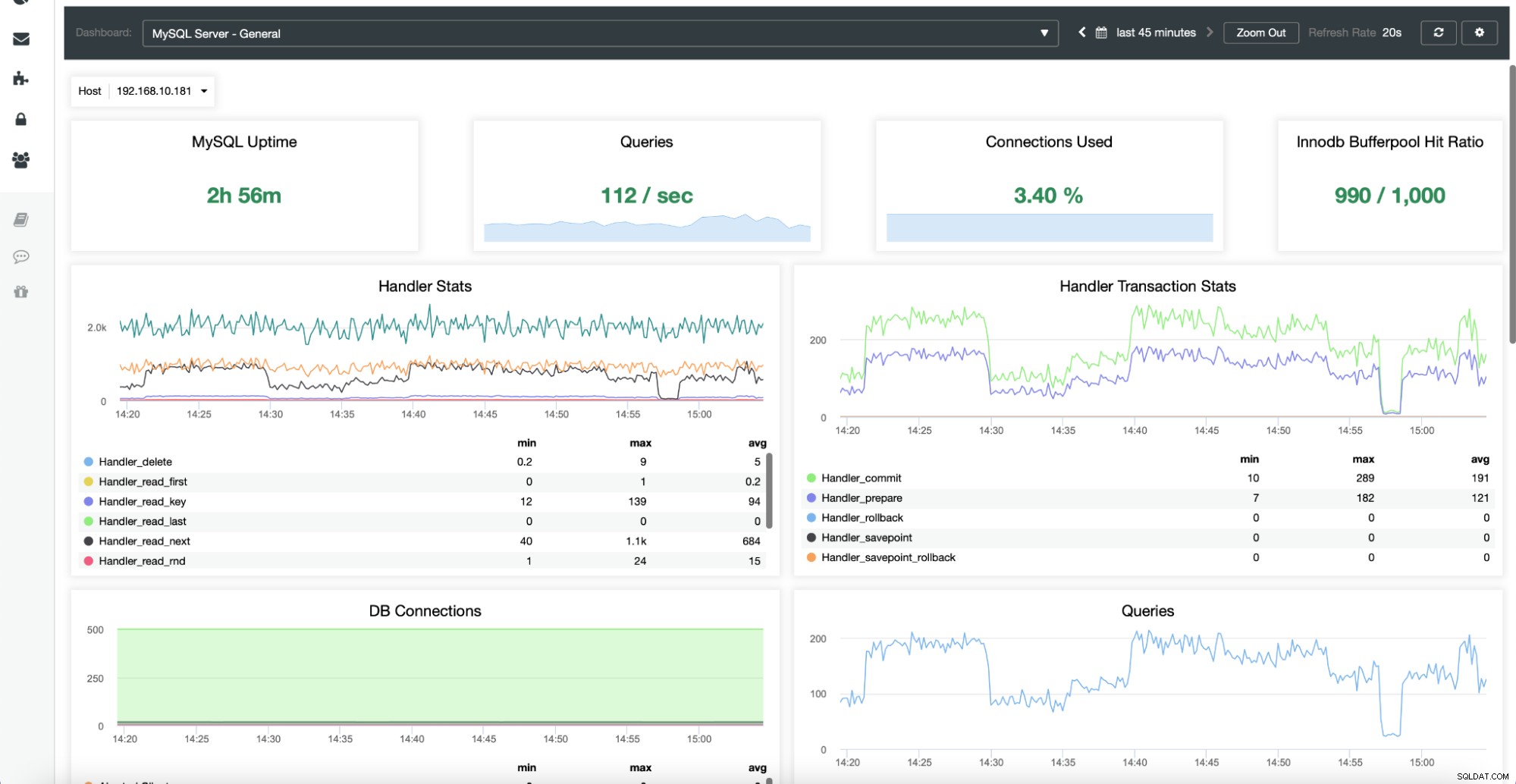
Tutaj znajdziesz metryki związane z danym hostem – Procesor, dysk, sieć i pamięć – wszystkie ważne bity danych, które definiują zachowanie danego serwera i jego obciążenie.
Karta Węzły daje również możliwość sprawdzenia metryk bazy danych dla danego węzła, jak pokazano poniżej:
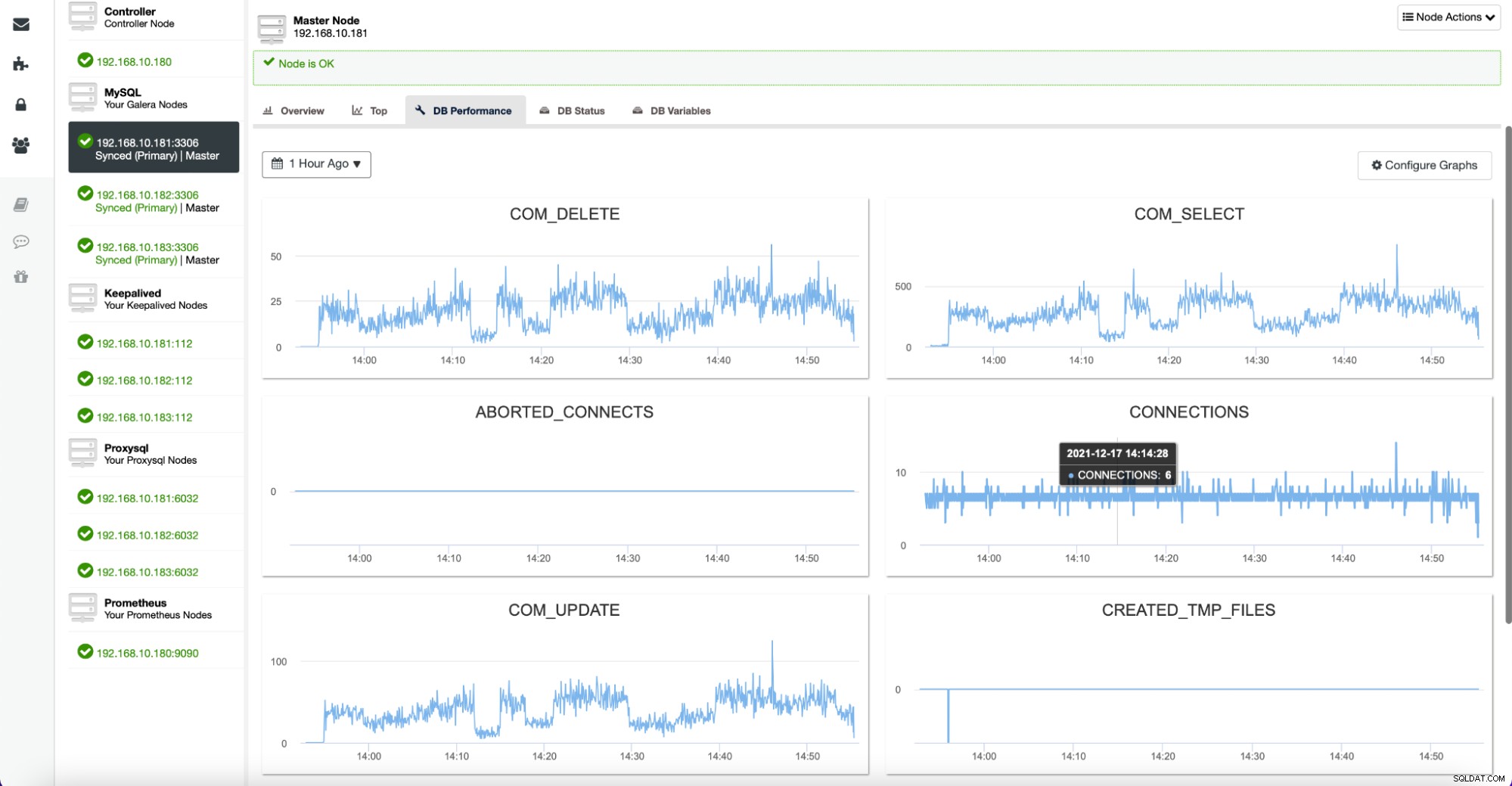
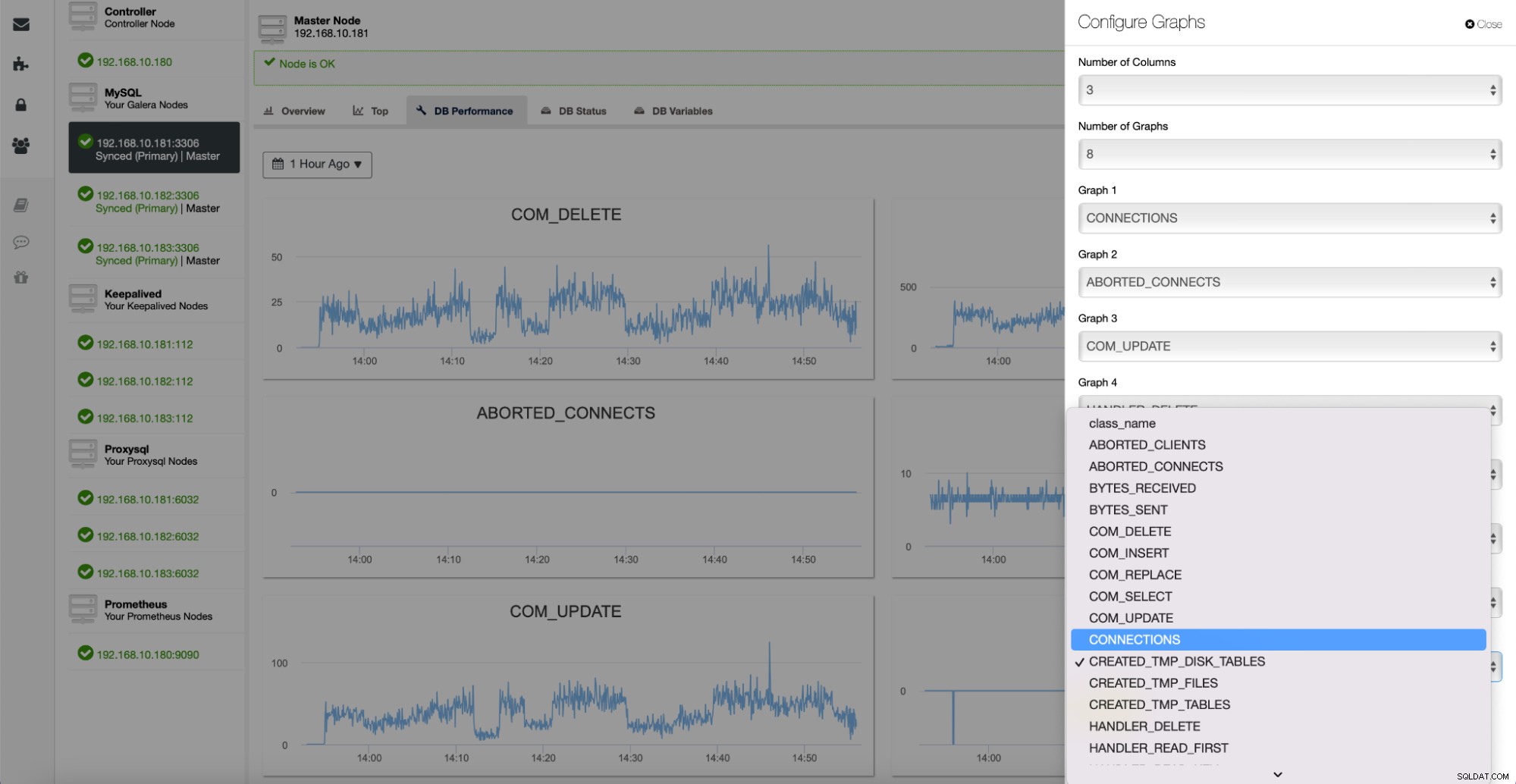
Wszystkie te wykresy można dostosować i w razie potrzeby można je łatwo dodawać :
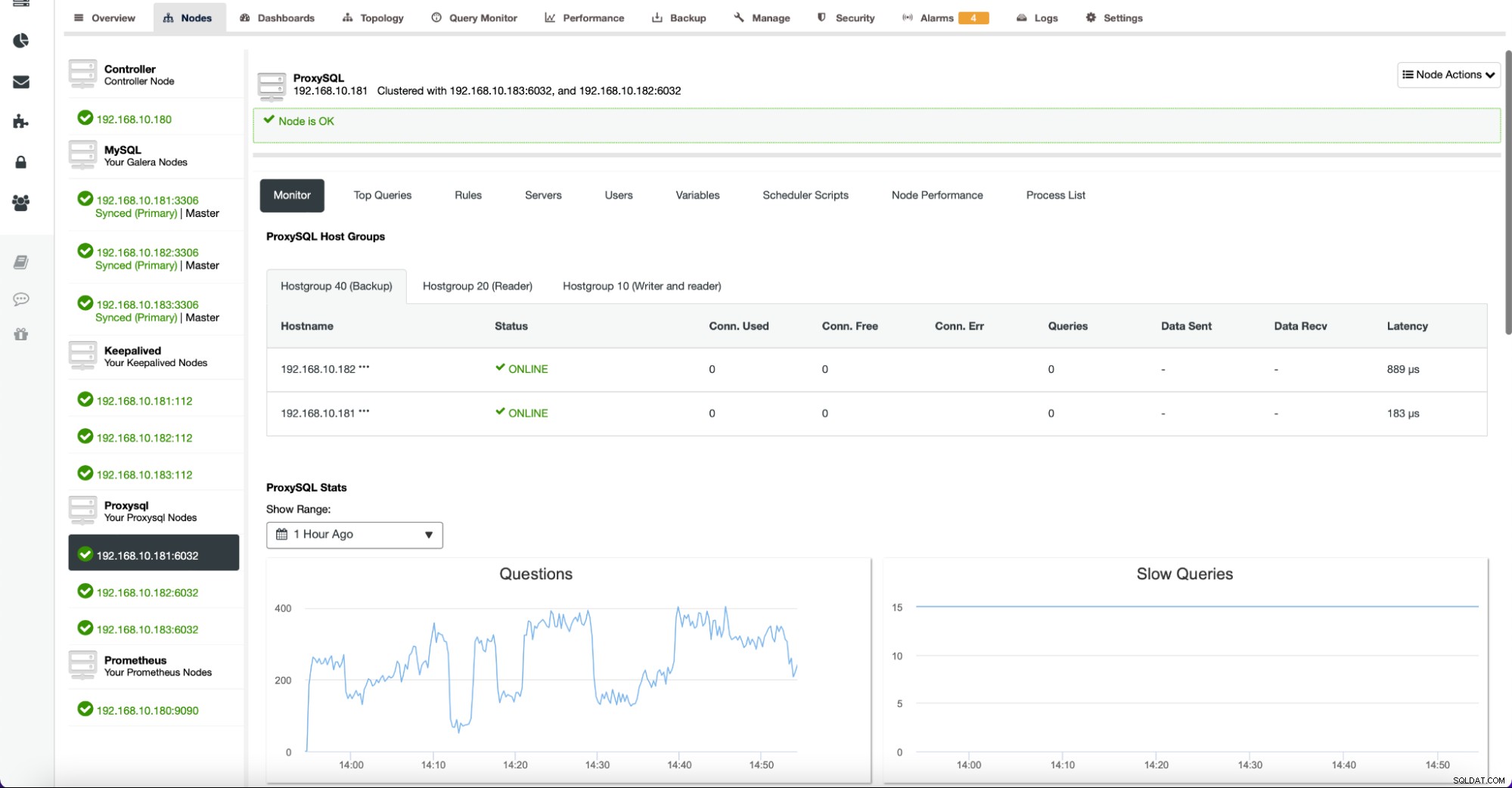
Karta Węzły zawiera również metryki związane z węzłami innymi niż bazy danych. Na przykład dla ProxySQL ClusterControl zapewnia obszerną listę wykresów do śledzenia stanu najważniejszych metryk.
Panele informacyjne
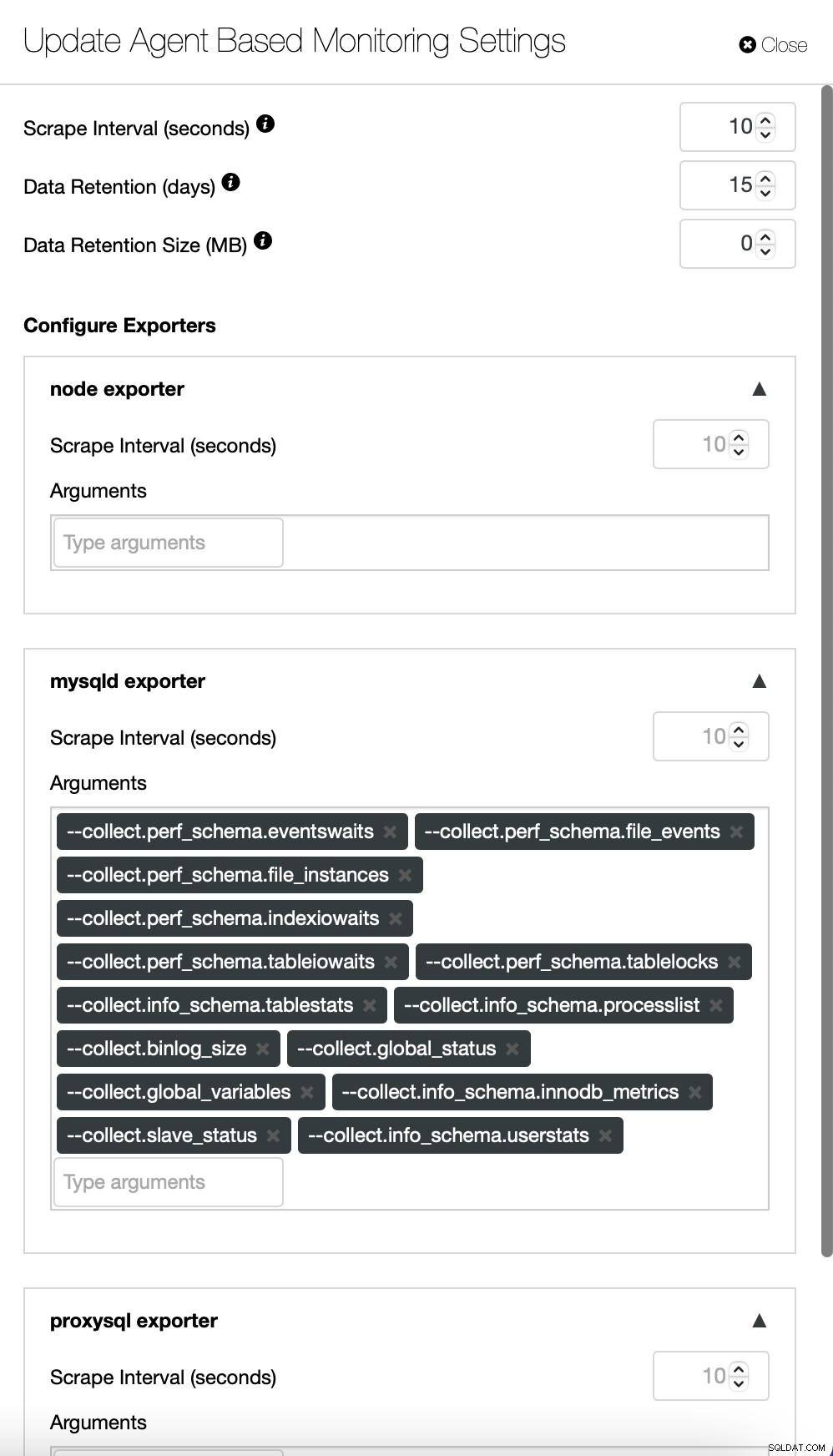
Domyślnie ClusterControl korzysta z bezagentowego podejścia do monitorowania, a wszystkie dane są zbierane bezpośrednio z ClusterControl przy użyciu SSH lub natywnego połączenia z bazą danych. Możliwe jest jednak umożliwienie podejścia opartego na agentach. Możesz to zrobić jednym kliknięciem.
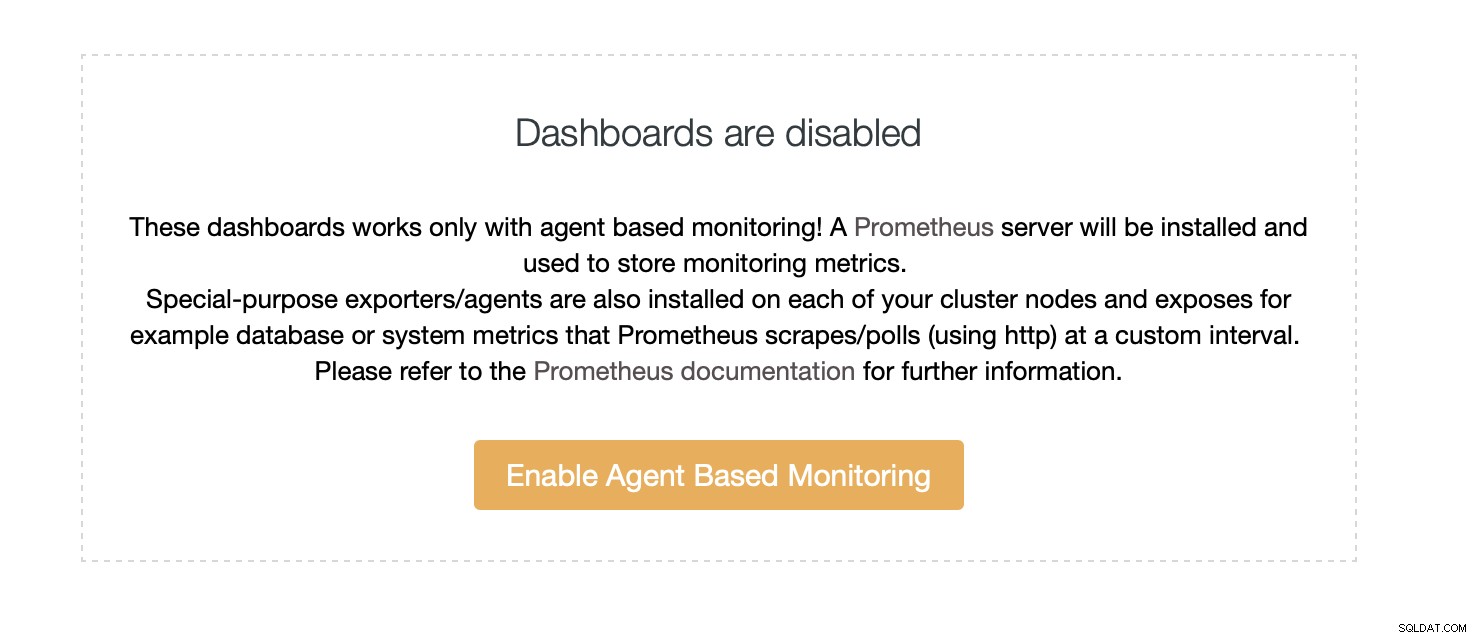
Po włączeniu monitorowania agentowego zostanie uruchomione zadanie, które skonfiguruje bazę danych szeregów czasowych Prometheusa, która będzie przechowywać dane, oraz różnych agentów, którzy będą gromadzić dane i przesyłać je do Prometheusa.
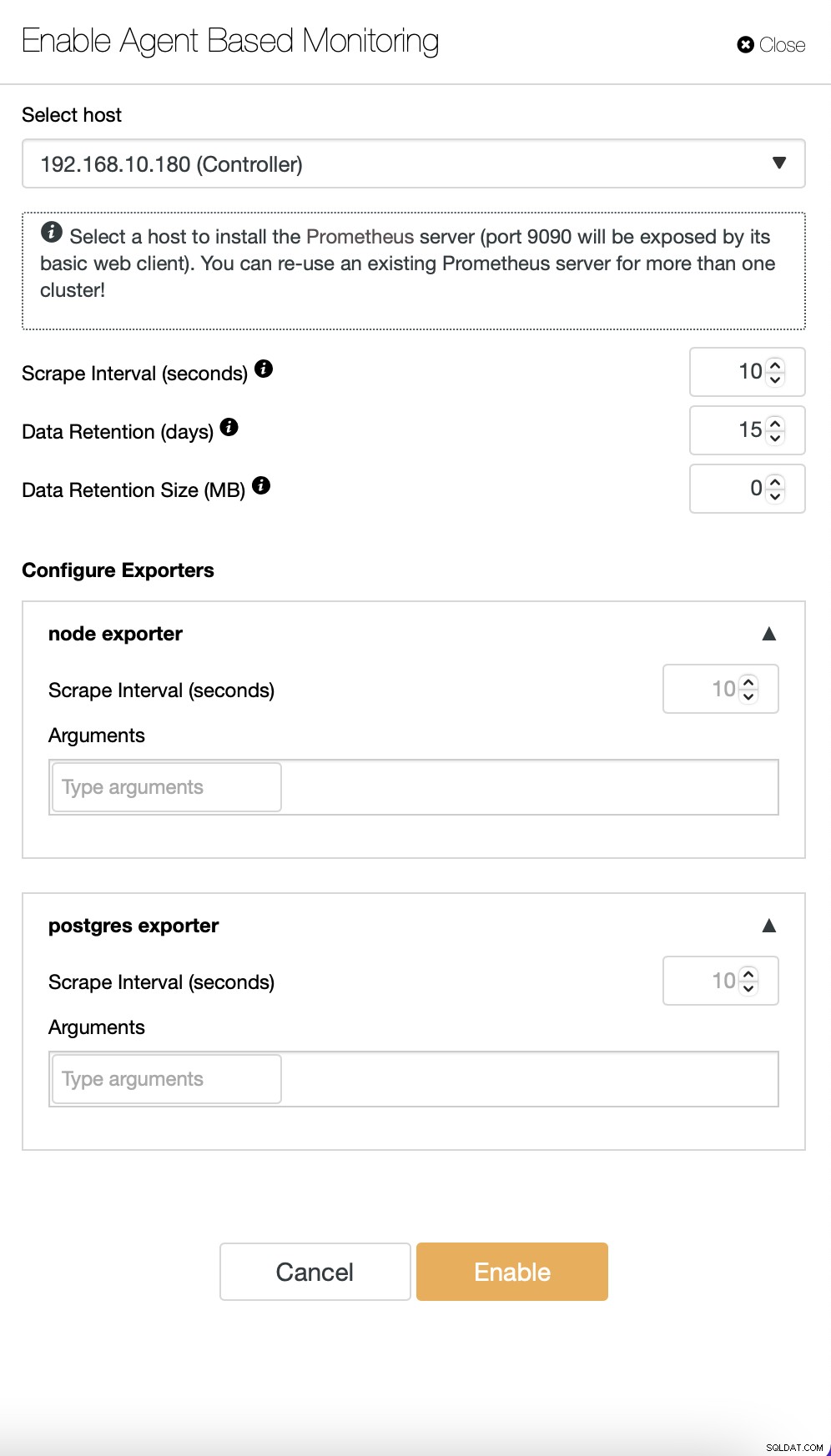
Gdy to będzie gotowe, zostanie utworzony zestaw dashboardów zgodnie z typy węzłów dostępnych w klastrze.
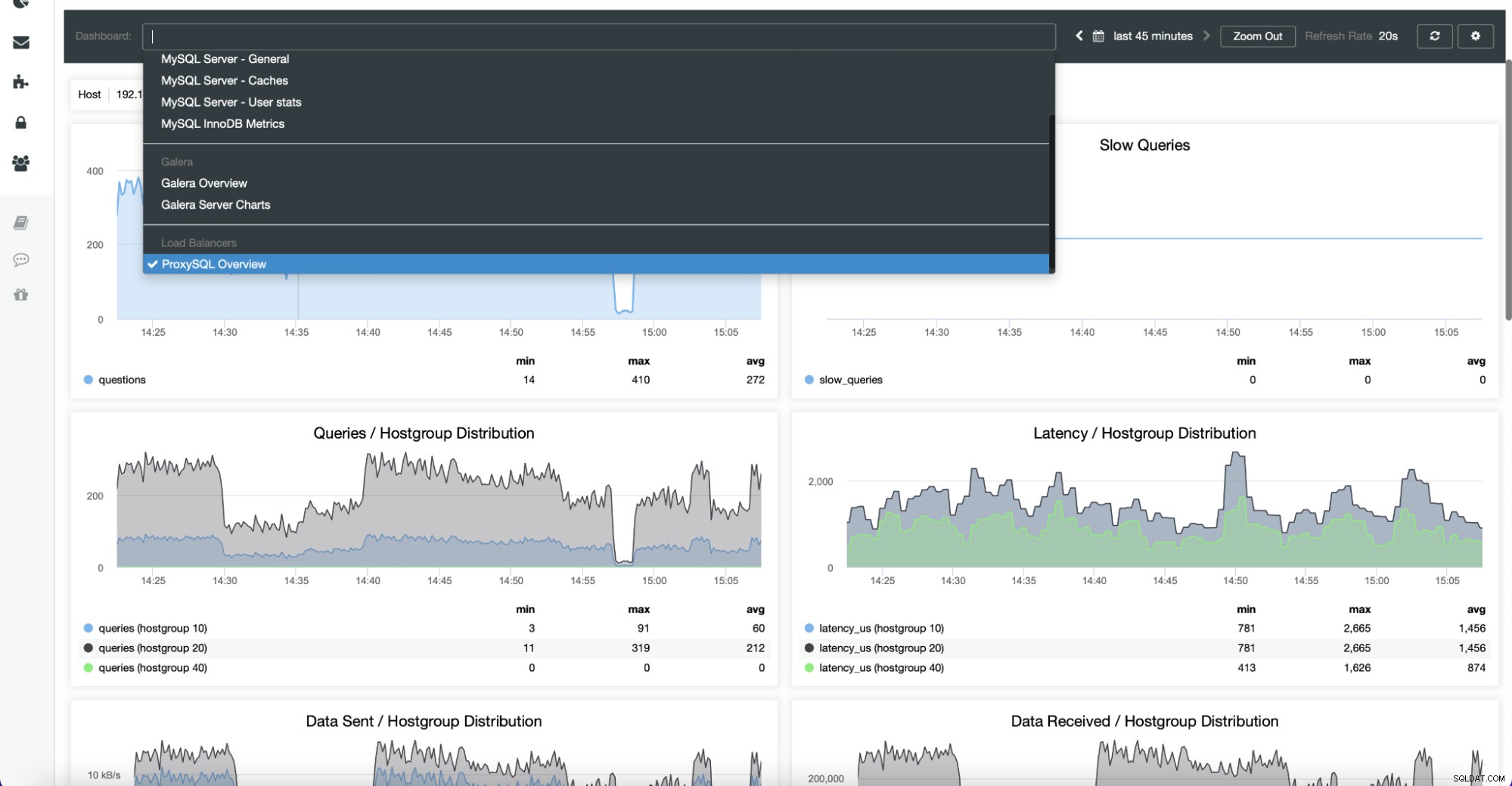
Panele nawigacyjne zawierają również systemy równoważenia obciążenia, które zostały wdrożone w klastrze. W razie potrzeby można ponownie włączyć monitorowanie oparte na agentach, co obejmuje ponowną instalację i ponowną konfigurację eksporterów:
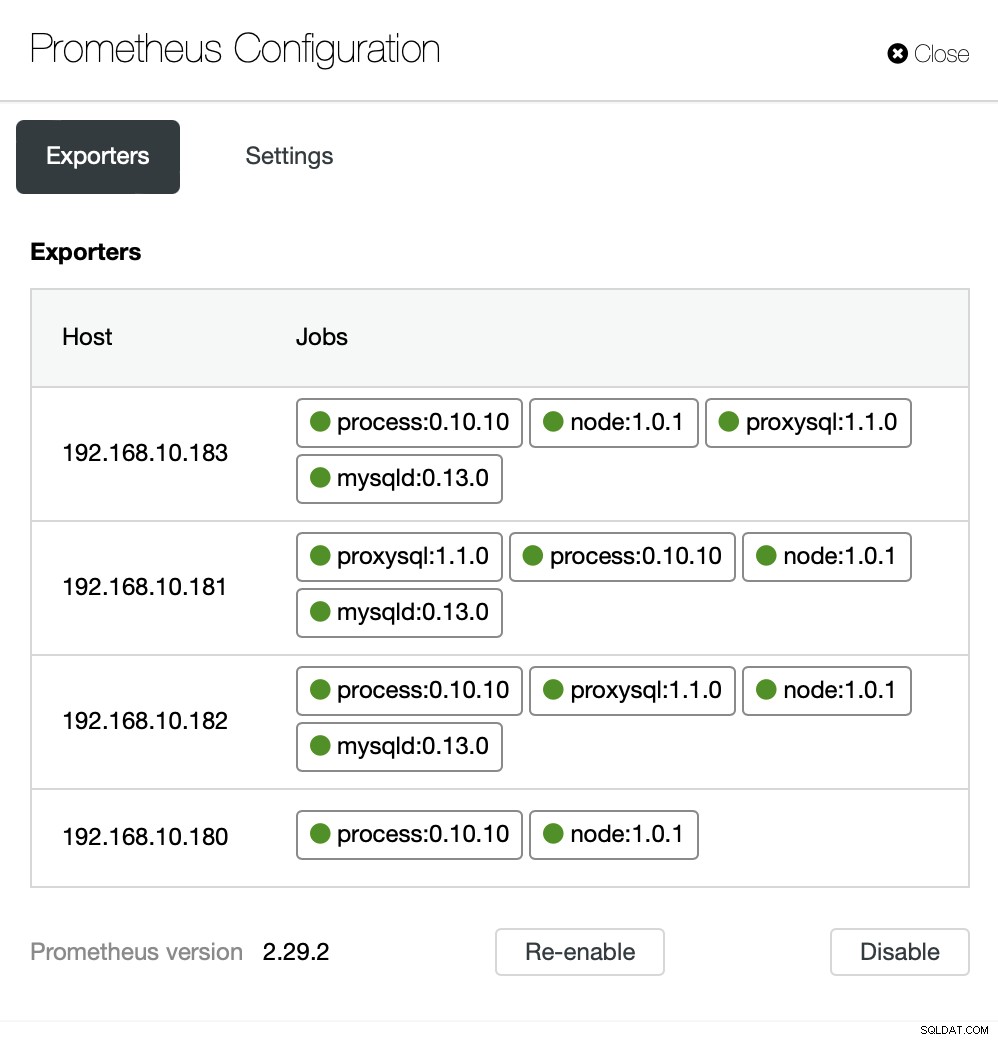
Jeśli chcesz, możesz również zmienić konfigurację agentów i Prometheusa :
Doradcy
Dane dotyczące trendów same w sobie nie wystarczą. Jasne, świetnie nadaje się do analizy pośmiertnej lub podczas pracy nad planowaniem wydajności; dane historyczne przechowywane w postaci wykresów mogą być bardzo przydatne. Ale aby mieć pełny obraz klastra, będziesz potrzebować alertów. Jeśli w tej chwili wystąpi problem, użytkownik musi zostać ostrzeżony.
ClusterControl udostępnia listę wstępnie zdefiniowanych doradców, którzy śledzą stan różnych metryki i stan Twoich baz danych. W razie potrzeby ClusterControl tworzy alert.
Jak widać na powyższym zrzucie ekranu, nie chodzi tylko o metryki. ClusterControl przeprowadza również testy poprawności dla ważnych ustawień i zapewnia pewne prognozy. Na przykład, jeśli chodzi o wykorzystanie miejsca na dysku, ClusterControl próbuje ostrzec użytkownika w przypadku zbyt szybkiego wzrostu wykorzystania dysku. Oczywiście alerty wysyłane są nie tylko przez doradców. Zdarzenia takie jak „node down” lub „nieudana kopia zapasowa” również spowodują powiadomienie.
Warto zauważyć, że doradcy są napisane w języku podobnym do JavaScript i można je edytować za pomocą Developer Studio w ClusterControl, jak pokazano poniżej:
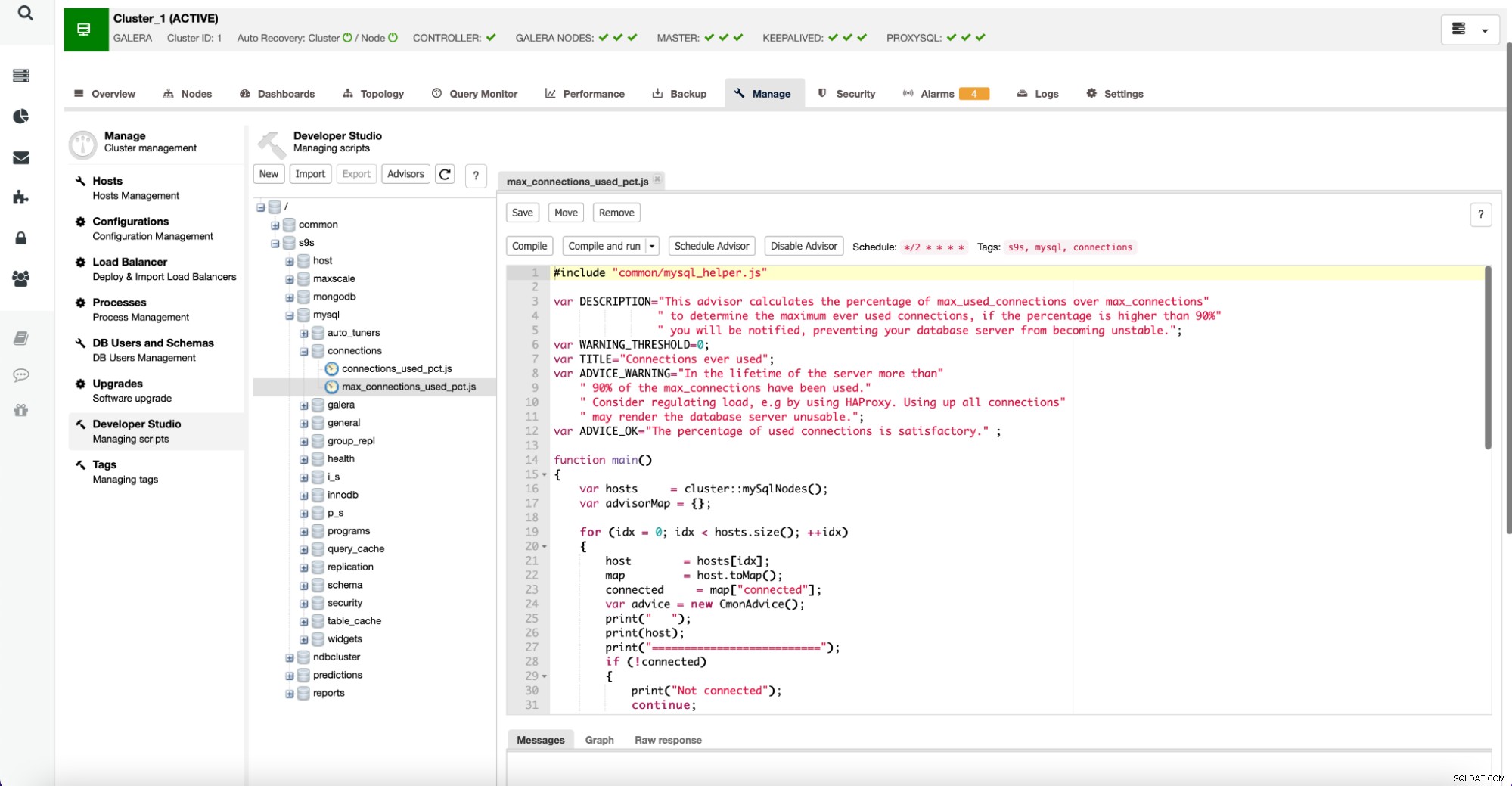
Użytkownicy mogą również tworzyć nowych doradców i planować ich wykonywanie przez ClusterControl.
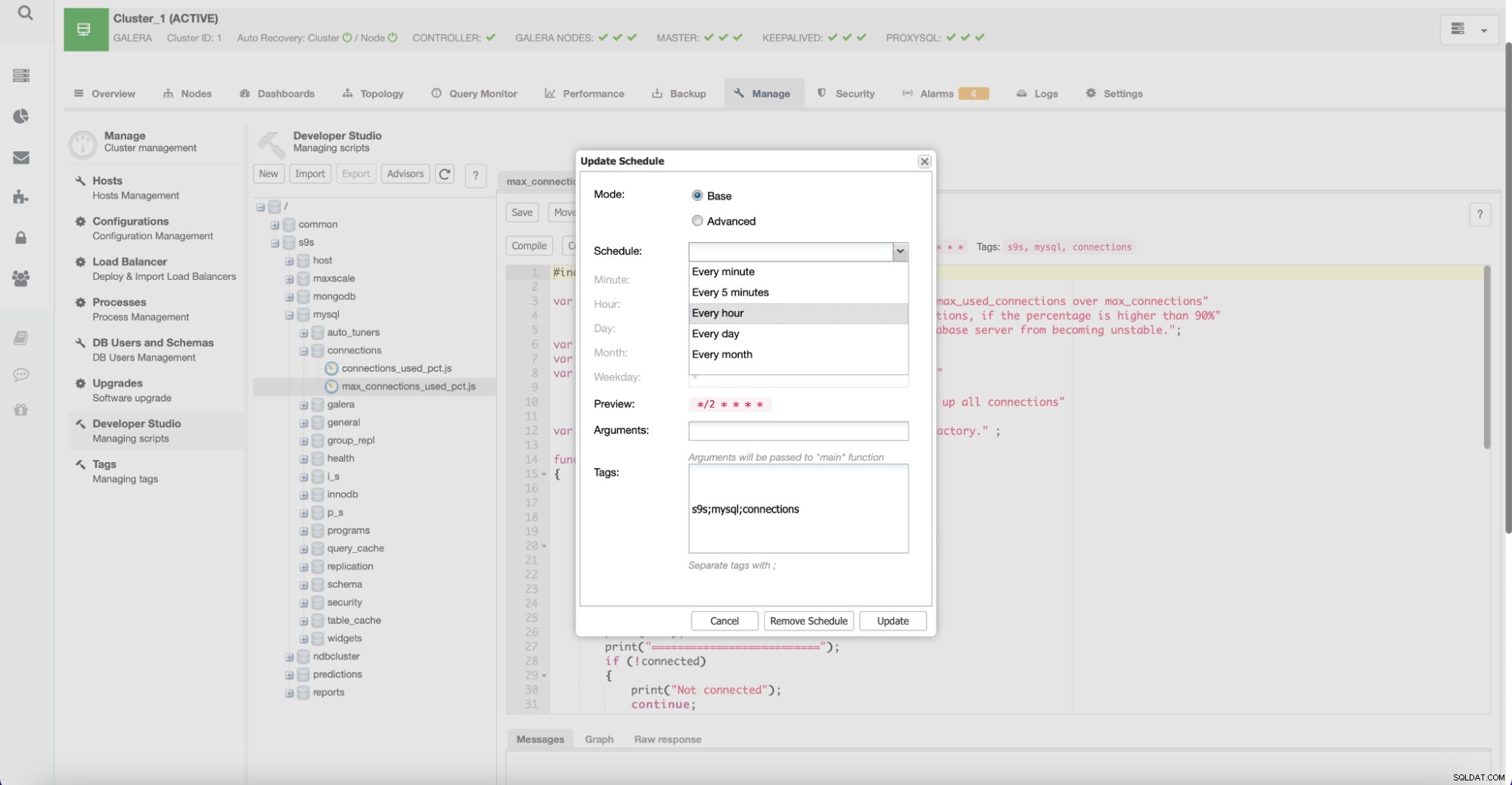
Dzięki tej funkcji użytkownicy mogą tworzyć własne skrypty sprawdzające ważne fragmenty specyficzne dla środowiska. Takie skrypty mogą również wykorzystywać inne funkcje ClusterControl, na przykład, jeśli chcesz wdrożyć automatyczne skalowanie w oparciu o wzrost niektórych metryk.
Gotowy do rozpoczęcia pracy z ClusterControl?
Jak widać, zdolność ClusterControl do automatyzacji zadań monitorowania i alarmowania, zapewniając jednocześnie łatwe do zrozumienia i konfigurowalne pulpity nawigacyjne, sprawia, że jest to niezbędne narzędzie dla DevOps i administratorów systemu. W rzeczywistości ClusterControl pozwala szybko i łatwo zautomatyzować wszystkie operacje na bazach danych z jednego okienka. Chcesz zobaczyć z pierwszej ręki, jak ClusterControl może pomóc Ci skutecznie monitorować bazy danych? Pobierz ClusterControl już dziś, aby wypróbować bezpłatnie przez 30 dni.



