Wydajność bazy danych polega nie tylko na dopracowaniu najbardziej krytycznych parametrów, ale także na odpowiedniej prezentacji danych w powiązanych kolekcjach. Ostatnio pracowałem nad projektem, który rozwijał aplikację do czatu społecznościowego i po kilku dniach testów zauważyliśmy pewne opóźnienia podczas pobierania danych z bazy danych. Nie mieliśmy tak wielu użytkowników, więc wykluczyliśmy dostrajanie parametrów bazy danych i skupiliśmy się na naszych zapytaniach, aby dotrzeć do głównej przyczyny.
Ku naszemu zaskoczeniu zdaliśmy sobie sprawę, że nasza struktura danych nie była całkowicie odpowiednia, ponieważ mieliśmy więcej niż jedno żądanie odczytu w celu pobrania określonych informacji.
Koncepcyjny model rozmieszczenia sekcji aplikacji w dużej mierze zależy od struktury kolekcji bazy danych. Na przykład, jeśli zalogujesz się do aplikacji społecznościowej, dane są wprowadzane do różnych sekcji zgodnie z projektem aplikacji, jak pokazano na prezentacji bazy danych.
Krótko mówiąc, w przypadku dobrze zaprojektowanej bazy danych struktura schematu i relacje kolekcji są kluczowymi czynnikami wpływającymi na jej większą szybkość i integralność, jak zobaczymy w kolejnych sekcjach.
Omówimy czynniki, które należy wziąć pod uwagę podczas modelowania danych.
Co to jest modelowanie danych
Modelowanie danych to na ogół analiza elementów danych w bazie danych i ich powiązania z innymi obiektami w tej bazie danych.
Na przykład w MongoDB możemy mieć kolekcję użytkowników i kolekcję profili. Kolekcja użytkowników zawiera nazwy użytkowników dla danej aplikacji, podczas gdy kolekcja profili przechwytuje ustawienia profilu dla każdego użytkownika.
W modelowaniu danych musimy zaprojektować relację łączącą każdego użytkownika z profilem korespondenta. W skrócie, modelowanie danych jest podstawowym krokiem w projektowaniu baz danych, oprócz tworzenia podstawy architektury dla programowania obiektowego. Daje również wskazówkę, jak fizyczna aplikacja będzie wyglądać w trakcie rozwoju. Architekturę integracji aplikacji z bazą danych można zilustrować poniżej.
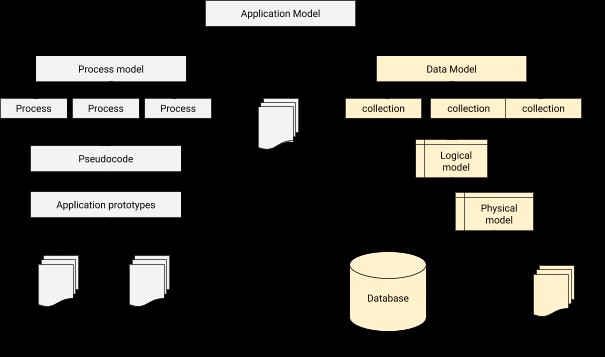
Proces modelowania danych w MongoDB
Modelowanie danych wiąże się z poprawioną wydajnością bazy danych, ale kosztem pewnych kwestii, które obejmują:
- Wzorce pobierania danych
- Zrównoważenie potrzeb aplikacji, takich jak:zapytania, aktualizacje i przetwarzanie danych
- Funkcje wydajnościowe wybranego silnika bazy danych
- Nieodłączna struktura samych danych
Struktura dokumentu MongoDB
Dokumenty w MongoDB odgrywają główną rolę w podejmowaniu decyzji o tym, którą technikę zastosować dla danego zestawu danych. Ogólnie rzecz biorąc, istnieją dwie zależności między danymi, które są:
- Dane osadzone
- Dane referencyjne
Dane osadzone
W takim przypadku powiązane dane są przechowywane w pojedynczym dokumencie jako wartość pola lub tablica w samym dokumencie. Główną zaletą tego podejścia jest to, że dane są zdenormalizowane, co daje możliwość manipulowania powiązanymi danymi w ramach pojedynczej operacji bazy danych. W konsekwencji poprawia to szybkość, z jaką wykonywane są operacje CRUD, stąd potrzeba mniej zapytań. Rozważmy przykład dokumentu poniżej:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"Settings" : {
"location" : "Embassy",
"ParentPhone" : 724765986
"bus" : "KAZ 450G",
"distance" : "4",
"placeLocation" : {
"lat" : -0.376252,
"lng" : 36.937389
}
}
}W tym zestawie danych mamy ucznia z jego nazwiskiem i kilkoma dodatkowymi informacjami. Pole Ustawienia zostało osadzone z obiektem, a ponadto pole placeLocation jest również osadzone z obiektem z konfiguracją szerokości i długości geograficznej. Wszystkie dane tego ucznia zostały zawarte w jednym dokumencie. Jeśli musimy pobrać wszystkie informacje dla tego ucznia, po prostu uruchamiamy:
db.students.findOne({StudentName : "George Beckonn"})Siła osadzania
- Zwiększona prędkość dostępu do danych:Aby poprawić szybkość dostępu do danych, osadzanie jest najlepszą opcją, ponieważ pojedyncza operacja zapytania może manipulować danymi w określonym dokumencie za pomocą tylko jednego wyszukiwania w bazie danych.
- Zmniejszona niespójność danych:podczas pracy, jeśli coś pójdzie nie tak (na przykład odłączenie sieci lub awaria zasilania), może to dotyczyć tylko kilku dokumentów, ponieważ kryteria często wybierają pojedynczy dokument.
- Zredukowane operacje CRUD. Oznacza to, że operacje odczytu przewyższą liczbę operacji zapisu. Poza tym możliwa jest aktualizacja powiązanych danych w pojedynczej operacji zapisu atomowego. Tzn. dla powyższych danych możemy zaktualizować numer telefonu, a także zwiększyć odległość za pomocą tej pojedynczej operacji:
db.students.updateOne({StudentName : "George Beckonn"}, { $set: {"ParentPhone" : 72436986}, $inc: {"Settings.distance": 1} })
Słabe strony osadzania
- Ograniczony rozmiar dokumentu. Wszystkie dokumenty w MongoDB są ograniczone do rozmiaru BSON 16 megabajtów. Dlatego całkowity rozmiar dokumentu wraz z osadzonymi danymi nie powinien przekraczać tego limitu. W przeciwnym razie w przypadku niektórych silników pamięci masowej, takich jak MMAPv1, dane mogą przerosnąć i spowodować fragmentację danych w wyniku obniżonej wydajności zapisu.
- Duplikacja danych:wiele kopii tych samych danych utrudnia wysyłanie zapytań o zreplikowane dane, a filtrowanie osadzonych dokumentów może zająć więcej czasu, co pozwala przewyższyć podstawową zaletę osadzania.
Zapis kropkowy
Notacja kropkowa jest cechą identyfikującą dane osadzone w części programistycznej. Służy do uzyskiwania dostępu do elementów osadzonego pola lub tablicy. W powyższych przykładowych danych możemy za pomocą tego zapytania zwrócić informacje o uczniu, którego lokalizacja to „Ambasada”, używając notacji kropkowej.
db.users.find({'Settings.location': 'Embassy'})Dane referencyjne
Relacja danych w tym przypadku oznacza, że powiązane dane są przechowywane w różnych dokumentach, ale do tych powiązanych dokumentów wydawane jest pewne łącze referencyjne. Dla przykładowych danych powyżej możemy je zrekonstruować w taki sposób, aby:
Dokument użytkownika
{ "_id" : xyz,
"StudentName" : "George Beckonn",
"ParentPhone" : 075646344,
}Dokument ustawień
{
"id" :xyz,
"location" : "Embassy",
"bus" : "KAZ 450G",
"distance" : "4",
"lat" : -0.376252,
"lng" : 36.937389
}Istnieją 2 różne dokumenty, ale są one połączone tą samą wartością w polach _id i id. W ten sposób model danych zostaje znormalizowany. Jednak, abyśmy mogli uzyskać dostęp do informacji z powiązanego dokumentu, musimy zadać dodatkowe zapytania, co w konsekwencji skutkuje wydłużeniem czasu realizacji. Na przykład, jeśli chcemy zaktualizować ParentPhone i powiązane ustawienia odległości, będziemy mieli co najmniej 3 zapytania, tj.
//fetch the id of a matching student
var studentId = db.students.findOne({"StudentName" : "George Beckonn"})._id
//use the id of a matching student to update the ParentPhone in the Users document
db.students.updateOne({_id : studentId}, {
$set: {"ParentPhone" : 72436986},
})
//use the id of a matching student to update the distance in settings document
db.students.updateOne({id : studentId}, {
$inc: {"distance": 1}
})Siła odniesienia
- Spójność danych. Dla każdego dokumentu zachowana jest forma kanoniczna, dlatego szanse na niespójność danych są dość niskie.
- Poprawiona integralność danych. Dzięki normalizacji łatwo jest aktualizować dane bez względu na długość trwania operacji, a zatem zapewnia prawidłowe dane dla każdego dokumentu bez powodowania zamieszania.
- Poprawione wykorzystanie pamięci podręcznej. Często używane dokumenty kanoniczne są przechowywane w pamięci podręcznej, a nie w przypadku dokumentów osadzonych, do których uzyskuje się dostęp kilka razy.
- Efektywne wykorzystanie sprzętu. W przeciwieństwie do osadzania, które może skutkować przerostem dokumentu, odwoływanie się nie promuje wzrostu dokumentu, co zmniejsza zużycie dysku i pamięci RAM.
- Większa elastyczność, zwłaszcza w przypadku dużego zestawu poddokumentów.
- Szybsze pisanie.
Słabe strony odniesień
- Wiele wyszukiwań:Ponieważ musimy szukać w wielu dokumentach spełniających kryteria, wydłuża się czas odczytu podczas pobierania z dysku. Poza tym może to skutkować błędami w pamięci podręcznej.
- Wysyłanych jest wiele zapytań w celu osiągnięcia pewnych operacji, dlatego znormalizowane modele danych wymagają większej liczby podróży w obie strony do serwera w celu ukończenia określonej operacji.
Normalizacja danych
Normalizacja danych odnosi się do restrukturyzacji bazy danych zgodnie z pewnymi normalnymi formami w celu poprawy integralności danych i zmniejszenia liczby przypadków redundancji danych.
Modelowanie danych obraca się wokół 2 głównych technik normalizacji, czyli:
-
Znormalizowane modele danych
Tak jak w przypadku danych referencyjnych, normalizacja dzieli dane na wiele kolekcji z odniesieniami między nowymi kolekcjami. Do drugiej kolekcji zostanie wydana pojedyncza aktualizacja dokumentu i odpowiednio zastosowana do pasującego dokumentu. Zapewnia to wydajną reprezentację aktualizacji danych i jest powszechnie używany w przypadku danych, które dość często się zmieniają.
-
Zdenormalizowane modele danych
Dane zawierają osadzone dokumenty, dzięki czemu operacje odczytu są dość wydajne. Wiąże się to jednak z większym wykorzystaniem miejsca na dysku, a także trudnościami z synchronizacją. Koncepcję denormalizacji można dobrze zastosować do poddokumentów, których dane nie zmieniają się dość często.
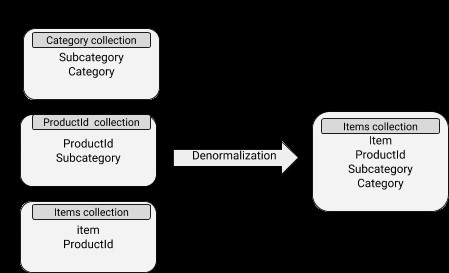
Schemat MongoDB
Schemat jest w zasadzie zarysowanym szkieletem pól i typu danych, które każde pole powinno zawierać dla danego zestawu danych. Biorąc pod uwagę punkt widzenia SQL, wszystkie wiersze są zaprojektowane tak, aby miały te same kolumny, a każda kolumna powinna zawierać zdefiniowany typ danych. Jednak w MongoDB domyślnie mamy elastyczny schemat, który nie zapewnia takiej samej zgodności dla wszystkich dokumentów.
Elastyczny schemat
Elastyczny schemat w MongoDB definiuje, że dokumenty niekoniecznie muszą mieć te same pola lub typ danych, ponieważ pole może się różnić w różnych dokumentach w kolekcji. Podstawową zaletą tej koncepcji jest to, że można dodawać nowe pola, usuwać istniejące lub zmieniać wartości pól na nowy typ, a tym samym aktualizować dokument do nowej struktury.
Na przykład możemy mieć te 2 dokumenty w tej samej kolekcji:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"ParentPhone" : 75646344,
"age" : 10
}
{ "_id" : ObjectId("5b98bfe7e8b9ab98757e8b9a"),
"StudentName" : "Fredrick Wesonga",
"ParentPhone" : false,
}W pierwszym dokumencie mamy pole wiek, natomiast w drugim nie ma pola wiek. Co więcej, typ danych dla pola ParentPhone jest liczbą, podczas gdy w drugim dokumencie został ustawiony na wartość false, która jest typem logicznym.
Elastyczność schematu ułatwia mapowanie dokumentów do obiektu, a każdy dokument może pasować do pól danych reprezentowanej encji.
Sztywny schemat
O ile powiedzieliśmy, że te dokumenty mogą się od siebie różnić, czasami możesz zdecydować się na stworzenie sztywnego schematu. Sztywny schemat zdefiniuje, że wszystkie dokumenty w kolekcji będą współdzielić tę samą strukturę, co da większą szansę na ustawienie niektórych zasad walidacji dokumentów jako sposobu na poprawę integralności danych podczas operacji wstawiania i aktualizowania.
Typy danych schematu
W przypadku korzystania z niektórych sterowników serwera dla MongoDB, takich jak mongoose, dostępne są pewne typy danych, które umożliwiają sprawdzanie poprawności danych. Podstawowe typy danych to:
- Ciąg
- Liczba
- Boole'a
- Data
- Bufor
- Identyfikator obiektu
- Tablica
- Mieszane
- Dziesiętny128
- Mapa
Spójrz na przykładowy schemat poniżej
var userSchema = new mongoose.Schema({
userId: Number,
Email: String,
Birthday: Date,
Adult: Boolean,
Binary: Buffer,
height: Schema.Types.Decimal128,
units: []
});Przykładowy przypadek użycia
var user = mongoose.model(‘Users’, userSchema )
var newUser = new user;
newUser.userId = 1;
newUser.Email = “example@sqldat.com”;
newUser.Birthday = new Date;
newUser.Adult = false;
newUser.Binary = Buffer.alloc(0);
newUser.height = 12.45;
newUser.units = [‘Circuit network Theory’, ‘Algerbra’, ‘Calculus’];
newUser.save(callbackfunction);Weryfikacja schematu
O ile możesz wykonać walidację danych od strony aplikacji, zawsze dobrą praktyką jest wykonanie walidacji również od strony serwera. Osiągamy to, stosując zasady walidacji schematu.
Reguły te są stosowane podczas operacji wstawiania i aktualizacji. Zwykle są deklarowane na zasadzie kolekcji podczas procesu tworzenia. Możesz jednak również dodać reguły walidacji dokumentów do istniejącej kolekcji za pomocą polecenia collMod z opcjami walidatora, ale te reguły nie są stosowane do istniejących dokumentów, dopóki nie zostanie do nich zastosowana aktualizacja.
Podobnie podczas tworzenia nowej kolekcji za pomocą polecenia db.createCollection() można wydać opcję walidatora. Spójrz na ten przykład podczas tworzenia kolekcji dla uczniów. Od wersji 3.6 MongoDB obsługuje walidację schematu JSON, dlatego wystarczy użyć operatora $jsonSchema.
db.createCollection("students", {
validator: {$jsonSchema: {
bsonType: "object",
required: [ "name", "year", "major", "gpa" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
gender: {
bsonType: "string",
description: "must be a string and is not required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
exclusiveMaximum: false,
description: "must be an integer in [ 2017, 2020 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
gpa: {
bsonType: [ "double" ],
minimum: 0,
description: "must be a double and is required"
}
}
}})W tym projekcie schematu, jeśli spróbujemy wstawić nowy dokument, taki jak:
db.students.insert({
name: "James Karanja",
year: NumberInt(2016),
major: "History",
gpa: NumberInt(3)
})Funkcja wywołania zwrotnego zwróci poniższy błąd, ponieważ niektóre naruszone reguły walidacji, takie jak podana wartość roku, nie mieszczą się w określonych granicach.
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 121,
"errmsg" : "Document failed validation"
}
})Ponadto możesz dodać wyrażenia zapytania do opcji walidacji za pomocą operatorów zapytań z wyjątkiem $where, $text, near i $nearSphere, tj.:
db.createCollection( "contacts",
{ validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
}
} )Poziomy walidacji schematów
Jak wspomniano wcześniej, walidacja jest wystawiana na operacje zapisu, zwykle.
Jednak walidację można również zastosować do już istniejących dokumentów.
Istnieją 3 poziomy walidacji:
- Ścisłe:jest to domyślny poziom walidacji MongoDB i stosuje reguły walidacji do wszystkich wstawek i aktualizacji.
- Umiarkowane:Reguły walidacji są stosowane podczas wstawiania, aktualizacji i do już istniejących dokumentów, które spełniają tylko kryteria walidacji.
- Wyłączone:ten poziom ustawia zasady walidacji dla danego schematu na wartość null, dlatego nie zostanie wykonana walidacja dokumentów.
Przykład:
Wstawmy poniższe dane do kolekcji klienta.
db.clients.insert([
{
"_id" : 1,
"name" : "Brillian",
"phone" : "+1 778 574 666",
"city" : "Beijing",
"status" : "Married"
},
{
"_id" : 2,
"name" : "James",
"city" : "Peninsula"
}
]Jeśli zastosujemy umiarkowany poziom walidacji za pomocą:
db.runCommand( {
collMod: "test",
validator: { $jsonSchema: {
bsonType: "object",
required: [ "phone", "name" ],
properties: {
phone: {
bsonType: "string",
description: "must be a string and is required"
},
name: {
bsonType: "string",
description: "must be a string and is required"
}
}
} },
validationLevel: "moderate"
} )Reguły walidacji zostaną zastosowane tylko do dokumentu z _id równym 1, ponieważ będzie on pasował do wszystkich kryteriów.
W przypadku drugiego dokumentu, ponieważ zasady walidacji nie są spełnione z wydanymi kryteriami, dokument nie zostanie zweryfikowany.
Działania walidacji schematu
Po przeprowadzeniu walidacji na dokumentach mogą wystąpić takie, które mogą naruszać zasady walidacji. Zawsze istnieje potrzeba podjęcia działania, gdy tak się stanie.
MongoDB udostępnia dwie akcje, które można wykonać na dokumentach, które nie spełniają zasad walidacji:
- Błąd:jest to domyślna akcja MongoDB, która odrzuca każdą wstawkę lub aktualizację w przypadku naruszenia kryteriów walidacji.
-
Ostrzegaj:Ta akcja zarejestruje naruszenie w dzienniku MongoDB, ale umożliwi zakończenie operacji wstawiania lub aktualizowania. Na przykład:
db.createCollection("students", { validator: {$jsonSchema: { bsonType: "object", required: [ "name", "gpa" ], properties: { name: { bsonType: "string", description: "must be a string and is required" }, gpa: { bsonType: [ "double" ], minimum: 0, description: "must be a double and is required" } } }, validationAction: “warn” })Jeśli spróbujemy wstawić taki dokument:
db.students.insert( { name: "Amanda", status: "Updated" } );Brakuje gpa niezależnie od tego, że jest to wymagane pole w projekcie schematu, ale ponieważ akcja walidacji została ustawiona na ostrzeżenie, dokument zostanie zapisany, a w dzienniku MongoDB zostanie zapisany komunikat o błędzie.



