Wiele JOINS w jednym zapytaniu
Wiele JOINS jest zwykle powiązanych z wieloma kolekcjami, ale musisz mieć podstawową wiedzę na temat działania INNER JOIN (zobacz moje poprzednie posty na ten temat). Oprócz naszych dwóch kolekcji, które mieliśmy wcześniej; jednostek i uczniów, dodajmy trzecią kolekcję i oznaczmy ją jako sport. Wypełnij kolekcję sportową poniższymi danymi:
{
"_id" : 1,"tournamentsPlayed" : 6,
"gamesParticipated" : [{"hockey" : "midfielder","football" : "stricker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa", "Rio Brazil"]
}
{
"_id" : 2,"tournamentsPlayed" : 3,
"gamesParticipated" : [{"hockey" : "goalkeeper","football" : "stricker", "handball" : "midfielder"}],
"sportPlaces" : ["Ukraine","India", "Argentina"]
}
{
"_id" : 3,"tournamentsPlayed" : 10,
"gamesParticipated" : [{"hockey" : "stricker","football" : "goalkeeper","tabletennis" : "doublePlayer"}],
"sportPlaces" : ["China","Korea","France"]
}Chcielibyśmy, na przykład, zwrócić wszystkie dane dla ucznia z wartością pola _id równą 1. Normalnie napisalibyśmy zapytanie, aby pobrać wartość pola _id z kolekcji uczniów, a następnie użyć zwróconej wartości do zapytania o dane w pozostałych dwóch kolekcjach. W związku z tym nie będzie to najlepsza opcja, zwłaszcza jeśli w grę wchodzi duży zestaw dokumentów. Lepszym rozwiązaniem byłoby użycie funkcji SQL programu Studio3T. Możemy wysłać zapytanie do naszej bazy danych MongoDB za pomocą normalnej koncepcji SQL, a następnie spróbować zgrubnie dostroić wynikowy kod powłoki Mongo, aby pasował do naszej specyfikacji. Na przykład pobierzmy wszystkie dane z _id równym 1 ze wszystkich kolekcji:
SELECT *
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;Dokumentem wynikowym będzie:
{
"students" : {"_id" : NumberInt(1),"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5},
"units" : {"_id" : NumberInt(1),"grades" : {Maths" : "A","English" : "A","Science" : "A","History" : "B"}
},
"sports" : {
"_id" : NumberInt(1),"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder", "football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa","Rio Brazil"]
}
}Na karcie Kod zapytania odpowiedni kod MongoDB będzie wyglądał następująco:
db.getCollection("students").aggregate(
[{ "$project" : {"_id" : NumberInt(0),"students" : "$$ROOT"}},
{ "$lookup" : {"localField" : "students._id","from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$unwind" : {"path" : "$units","preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id","from" : "sports", "foreignField" : "_id","as" : "sports"}},
{ "$unwind" : {"path" : "$sports", "preserveNullAndEmptyArrays" : false}},
{ "$match" : {"students._id" : NumberLong(1)}}
]
);Patrząc na zwrócony dokument, osobiście nie jestem zbyt zadowolony ze struktury danych, zwłaszcza w przypadku dokumentów osadzonych. Jak widać, zwracane są pola _id, a dla jednostek może nie być konieczne umieszczenie pola ocen w jednostkach.
Chcielibyśmy mieć pole jednostek z osadzonymi jednostkami, a nie jakiekolwiek inne pola. To prowadzi nas do części szorstkiej melodii. Podobnie jak w poprzednich postach, skopiuj kod za pomocą dostarczonej ikony kopiowania i przejdź do panelu agregacji, wklej zawartość za pomocą ikony wklej.
Po pierwsze, operator $match powinien być pierwszym etapem, więc przenieś go na pierwszą pozycję i wykonaj coś takiego:
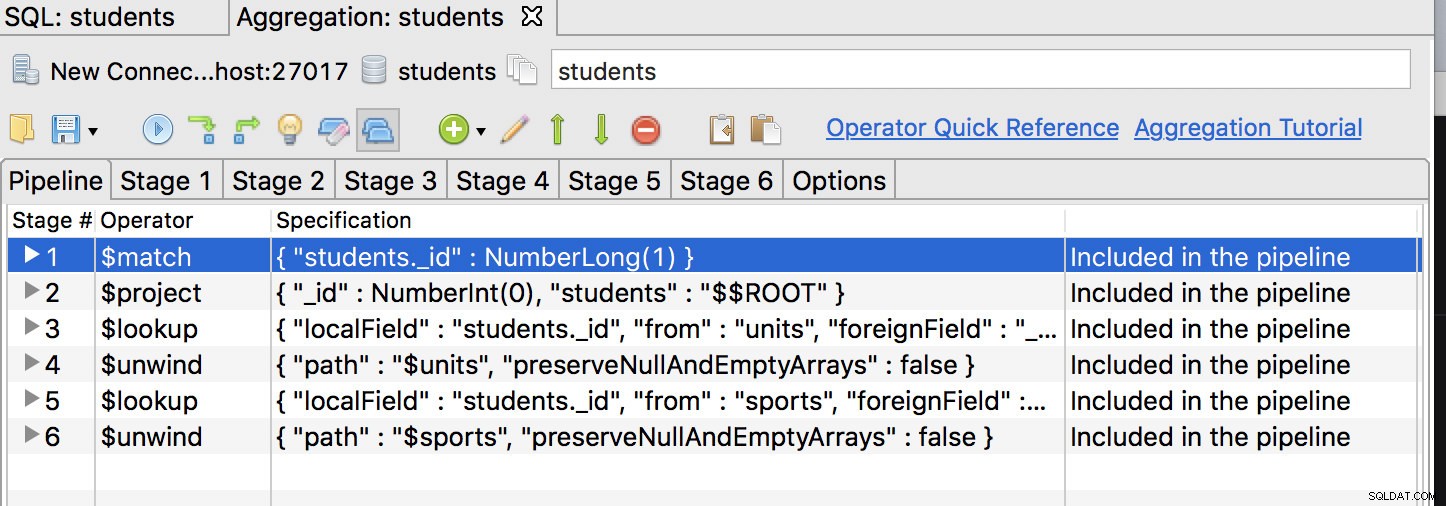
Kliknij kartę pierwszego etapu i zmodyfikuj zapytanie, aby:
{
"_id" : NumberLong(1)
}Następnie musimy dalej zmodyfikować zapytanie, aby usunąć wiele etapów osadzania naszych danych. W tym celu dodajemy nowe pola do przechwytywania danych dla pól, które chcemy wyeliminować, np.:
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : { "_id": "$students._id","units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"sports._id" : 0.0}}
]
);Jak widać, w procesie dostrajania wprowadziliśmy nowe jednostki pól, które nadpiszą zawartość poprzedniego potoku agregacji ocenami jako osadzone pole. Ponadto utworzyliśmy pole _id, aby wskazać, że dane były powiązane z dowolnymi dokumentami w kolekcjach o tej samej wartości. Ostatnim etapem $project jest usunięcie pola _id w dokumencie sportowym, dzięki czemu możemy mieć ładnie przedstawione dane, jak poniżej.
{ "_id" : NumberInt(1),
"students" : {"name" : "James Washington", "age" : 15.0, "grade" : "A", "score" : 10.5},
"units" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"},
"sports" : {
"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder","football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge", "South Africa", "Rio Brazil"]
}
}Możemy również ograniczyć na jakie pola mają być zwracane z punktu widzenia SQL. Na przykład możemy zwrócić imię i nazwisko ucznia, jednostki, które ten uczeń robi i liczbę turniejów rozegranych przy użyciu wielu JOINS z poniższym kodem:
SELECT students.name, units.grades, sports.tournamentsPlayed
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;To nie daje nam najbardziej odpowiedniego rezultatu. Więc jak zwykle skopiuj go i wklej w okienku agregacji. Dostrajamy poniższy kod, aby uzyskać odpowiedni wynik.
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : {"units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"name" : "$students.name", "grades" : "$units.grades", "tournamentsPlayed" : "$sports.tournamentsPlayed"}
}}
]
);Ten wynik agregacji z koncepcji SQL JOIN daje nam schludną i czytelną strukturę danych pokazaną poniżej.
{
"name" : "James Washington",
"grades" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"},
"tournamentsPlayed" : NumberInt(6)
}Całkiem proste, prawda? Dane są dość reprezentacyjne, jakby były przechowywane w jednym zbiorze jako pojedynczy dokument.
LEWE POŁĄCZENIE ZEWNĘTRZNE
LEWE ZŁĄCZENIE ZEWNĘTRZNE jest zwykle używane do pokazywania dokumentów, które nie są zgodne z najczęściej przedstawianą relacją. Wynikowy zestaw sprzężenia LEFT OUTER zawiera wszystkie wiersze z obu kolekcji, które spełniają kryteria klauzuli WHERE, tak samo jak zestaw wyników INNER JOIN. Poza tym wszystkie dokumenty z lewej kolekcji, które nie mają pasujących dokumentów w prawej kolekcji, również zostaną uwzględnione w zestawie wyników. Pola wybrane z prawej strony tabeli zwrócą wartości NULL. Jednak żadne dokumenty z prawej kolekcji, które nie mają pasujących kryteriów z lewej kolekcji, nie są zwracane.
Spójrz na te dwie kolekcje:
studenci
{"_id" : 1,"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5}
{"_id" : 2,"name" : "Clinton Ariango","age" : 14.0,"grade" : "B","score" : 7.5}
{"_id" : 4,"name" : "Mary Muthoni","age" : 16.0,"grade" : "A","score" : 11.5}Jednostki
{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}
{"_id" : 2,"Maths" : "B","English" : "B","Science" : "A","History" : "B"}
{"_id" : 3,"Maths" : "A","English" : "A","Science" : "A","History" : "A"}W kolekcji studentów nie mamy wartości pola _id ustawionej na 3, ale w kolekcji jednostek, którą mamy. Podobnie w kolekcji jednostek nie ma wartości 4 pola _id. Jeśli użyjemy kolekcji uczniów jako naszej lewej opcji w podejściu JOIN z poniższym zapytaniem:
SELECT *
FROM students
LEFT OUTER JOIN units
ON students._id = units._idZa pomocą tego kodu otrzymamy następujący wynik:
{
"students" : {"_id" : 1,"name" : "James Washington","age" : 15,"grade" : "A","score" : 10.5},
"units" : {"_id" : 1,"grades" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"}}
}
{
"students" : {"_id" : 2,"name" : "Clinton Ariango", "age" : 14,"grade" : "B", "score" : 7.5 }
}
{
"students" : {"_id" : 3,"name" : "Mary Muthoni","age" : 16,"grade" : "A","score" : 11.5},
"units" : {"_id" : 3,"grades" : {"Maths" : "A","English" : "A","Science" : "A","History" : "A"}}
}Drugi dokument nie zawiera pola jednostek, ponieważ w kolekcji jednostek nie ma pasującego dokumentu. W przypadku tego zapytania SQL odpowiedni kod Mongo to
db.getCollection("students").aggregate(
[
{
"$project" : {"_id" : NumberInt(0), "students" : "$$ROOT"}},
{
"$lookup" : {"localField" : "students._id", "from" : "units", "foreignField" : "_id", "as" : "units"}
},
{
"$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : true}
}
]
);Oczywiście dowiedzieliśmy się o dostrajaniu, dzięki czemu możesz przejść dalej i zmienić strukturę potoku agregacji, aby dopasować go do pożądanego rezultatu końcowego. SQL jest bardzo potężnym narzędziem, jeśli chodzi o zarządzanie bazami danych. Sam w sobie jest to obszerny temat, możesz również spróbować użyć klauzul IN i GROUP BY, aby uzyskać odpowiedni kod dla MongoDB i zobaczyć, jak to działa.
Wniosek
Przyzwyczajenie się do nowej technologii (bazy danych) oprócz tej, z którą jesteś przyzwyczajony, może zająć dużo czasu. Relacyjne bazy danych są nadal bardziej powszechne niż te nierelacyjne. Niemniej jednak wraz z wprowadzeniem MongoDB wiele się zmieniło i ludzie chcieliby nauczyć się go tak szybko, jak to możliwe, ze względu na związaną z nim wysoką wydajność.
Nauka MongoDB od zera może być nieco żmudna, ale możemy wykorzystać znajomość SQL do manipulowania danymi w MongoDB, uzyskania odpowiedniego kodu MongoDB i dostrojenia go, aby uzyskać najbardziej odpowiednie wyniki. Jednym z dostępnych narzędzi, które to usprawniają, jest Studio 3T. Oferuje dwie ważne funkcje ułatwiające obsługę złożonych danych, czyli:funkcję zapytań SQL oraz Edytor agregacji. Precyzyjne zapytania dostrajające nie tylko zapewnią uzyskanie najlepszych wyników, ale także poprawią wydajność pod względem oszczędności czasu.



