Jedną z moich największych radości jako programisty jest poznanie, jak krzyżują się różne technologie.
Przez lata miałem okazję pracować z różnymi rodzajami oprogramowania i narzędzi. Z wielu narzędzi, których używałem, Python i Structured Query Language (SQL) to dwa z moich ulubionych.
W tym artykule podzielę się z Wami interakcją Pythona i różnych baz danych SQL.
Opowiem o najpopularniejszych bazach danych, SQLite, MySQL i PostgreSQL. Wyjaśnię kluczowe różnice każdej bazy danych i odpowiednie przypadki użycia. I zakończę artykuł jakimś kodem w Pythonie.
Kod pokaże Ci, jak napisać zapytanie SQL, aby pobrać dane z bazy danych PostgreSQL i przechowywać dane w ramce danych pandy.
Jeśli nie znasz relacyjnych baz danych (RDBMS), sugeruję zapoznanie się z artykułem Sameera na temat podstawowej terminologii RDBMS tutaj. W pozostałej części artykułu będą używane terminy, o których mowa w artykule Sameera.
Popularne bazy danych SQL
SQLite
SQLite jest najbardziej znany jako zintegrowana baza danych. Oznacza to, że nie musisz instalować dodatkowej aplikacji ani korzystać z oddzielnego serwera, aby uruchomić bazę danych.
Jeśli tworzysz MVP lub nie potrzebujesz mnóstwa miejsca do przechowywania danych, będziesz chciał skorzystać z bazy danych SQLite.
Zaletą jest to, że możesz poruszać się szybciej dzięki bazie danych SQLite w stosunku do MySQL i PostgreSQL. To powiedziawszy, utkniesz z ograniczoną funkcjonalnością. Nie będziesz w stanie dostosowywać funkcji ani dodawać mnóstwa funkcji dla wielu użytkowników.
MySQL/PostgreSQL
Istnieją wyraźne różnice między MySQL i PostgreSQL. To powiedziawszy, biorąc pod uwagę kontekst artykułu, pasują do podobnej kategorii.
Oba typy baz danych doskonale nadają się do rozwiązań dla przedsiębiorstw. Jeśli potrzebujesz szybko skalować, MySQL i PostgreSQL to najlepszy wybór. Zapewnią długoterminową infrastrukturę i zwiększą Twoje bezpieczeństwo.
Innym powodem, dla którego są świetne dla przedsiębiorstw, jest to, że mogą poradzić sobie z działaniami o wysokiej wydajności. Dłuższe instrukcje insert, update i select wymagają dużej mocy obliczeniowej. Będziesz w stanie napisać te instrukcje z mniejszym opóźnieniem niż to, co dałaby Ci baza danych SQLite.
Dlaczego łączyć Pythona i bazę danych SQL?
Być może zastanawiasz się, „dlaczego powinno mnie obchodzić połączenie Pythona i bazy danych SQL?”
Istnieje wiele przypadków użycia, w których ktoś chciałby połączyć Pythona z bazą danych SQL. Jak wspomniałem wcześniej, możesz pracować nad aplikacją internetową. W takim przypadku musisz połączyć bazę danych SQL, aby móc przechowywać dane pochodzące z aplikacji internetowej.
Być może pracujesz w inżynierii danych i potrzebujesz zbudować zautomatyzowany potok ETL. Połączenie Pythona z bazą danych SQL pozwoli Ci wykorzystać Pythona do jego automatyzacji. Będziesz także mógł komunikować się między różnymi źródłami danych. Nie będziesz musiał przełączać się między różnymi językami programowania.
Połączenie Pythona i bazy danych SQL sprawi, że nauka o danych będzie wygodniejsza. Będziesz mógł wykorzystać swoje umiejętności Pythona do manipulowania danymi z bazy danych SQL. Nie potrzebujesz pliku CSV.
Jak łączą się Python i bazy danych SQL

Bazy danych Python i SQL łączą się za pośrednictwem niestandardowych bibliotek Pythona. Możesz zaimportować te biblioteki do swojego skryptu Pythona.
Biblioteki Pythona specyficzne dla bazy danych służą jako instrukcje uzupełniające. Te instrukcje wyjaśniają, jak komputer może współdziałać z bazą danych SQL. W przeciwnym razie twój kod Pythona będzie językiem obcym dla bazy danych, z którą próbujesz się połączyć.
Jak skonfigurować projekt
Weźmy na przykład bazę danych PostgreSQL, AWS Redshift. Najpierw będziesz chciał zaimportować bibliotekę psycopg. Jest to uniwersalna biblioteka Pythona dla baz danych PostgreSQL.
#Library for connecting to AWS Redshift
import psycopg
#Library for reading the config file, which is in JSON
import json
#Data manipulation library
import pandas as pdZauważysz, że zaimportowaliśmy również biblioteki JSON i pandy. Zaimportowaliśmy JSON, ponieważ utworzenie pliku konfiguracyjnego JSON to bezpieczny sposób przechowywania danych logowania do bazy danych. Nie chcemy, żeby ktokolwiek inny je oglądał!
Biblioteka pandas pozwoli Ci wykorzystać wszystkie możliwości statystyczne pandy w twoim skrypcie Pythona. W tym przypadku biblioteka umożliwi Pythonowi przechowywanie danych zwracanych przez zapytanie SQL w ramce danych.
Następnie będziesz chciał uzyskać dostęp do swojego pliku konfiguracyjnego. json.load() funkcja odczytuje plik JSON, dzięki czemu możesz uzyskać dostęp do danych logowania do bazy danych w następnym kroku.
config_file = open(r"C:\Users\yourname\config.json")
config = json.load(config_file)
Teraz, gdy Twój skrypt Pythona może uzyskać dostęp do pliku konfiguracyjnego JSON, będziesz chciał utworzyć połączenie z bazą danych. Musisz przeczytać i użyć poświadczeń z pliku konfiguracyjnego:
con = psycopg2.connect(dbname= "db_name", host=config[hostname], port = config["port"],user=config["user_id"], password=config["password_key"])
cur = con.cursor()Właśnie utworzyłeś połączenie z bazą danych! Kiedy importowałeś bibliotekę psycopg, przetłumaczyłeś kod Pythona, który napisałeś powyżej, aby mógł rozmawiać z bazą danych PostgreSQL (AWS Redshift).
Sam w sobie AWS Redshift nie zrozumiałby powyższego kodu. Ale ponieważ zaimportowałeś bibliotekę psycopg, teraz mówisz językiem, który AWS Redshift może zrozumieć.
Zaletą Pythona jest to, że posiada biblioteki dla SQLite, MySQL i PostgreSQL. Będziesz mógł z łatwością zintegrować technologie.
Jak napisać zapytanie SQL
Zapraszam do pobrania European Soccer Data do swojej bazy danych PostgreSQL. W tym przykładzie użyję jego danych.
Połączenie z bazą danych, które utworzyłeś w ostatnim kroku, umożliwia pisanie SQL, a następnie przechowywanie danych w strukturze danych przyjaznej Pythonowi. Teraz, po nawiązaniu połączenia z bazą danych, możesz napisać zapytanie SQL, aby rozpocząć pobieranie danych:
query = "SELECT *
FROM League
JOIN Country ON Country.id = League.country_id;"Jednak praca jeszcze się nie skończyła. Musisz napisać dodatkowy kod Pythona, który wykona zapytanie SQL:
#Runs your SQL query
execute1 = cur.execute(query)
result = cur.fetchall()Następnie musisz zapisać zwrócone dane w ramce danych pandy:
#Create initial dataframe from SQL data
raw_initial_df = pd.read_sql_query(query, con)
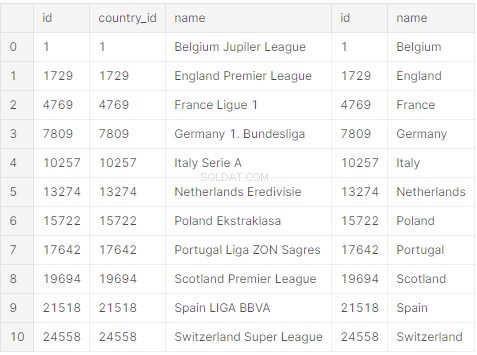
print(raw_initial_df)Powinieneś otrzymać ramkę danych pandy (raw_initial_df), która wygląda mniej więcej tak:
Jest baza danych dla każdego

SQLite, MySQL i PostgreSQL mają swoje wady i zalety. Ten, który wybierzesz, powinien zależeć od Twojego projektu lub potrzeb firmy. Powinieneś także rozważyć to, czego potrzebujesz teraz, w porównaniu z kilkoma latami w przyszłości.
Ważną rzeczą do zapamiętania jest to, że Python może integrować się z każdym typem bazy danych.
Ten artykuł pokazuje, co jest możliwe dzięki połączeniu Pythona z bazą danych SQL. Uwielbiam patrzeć, jak oprogramowanie przecina się i łączy, aby dodać niesamowitą wartość.
Jeśli chcesz więcej tego typu treści, możesz mnie znaleźć na Course to Hire! Chcę pomóc większej liczbie osób nauczyć się kodować i znaleźć pracę w branży technologicznej. Prosimy o kontakt w przypadku jakichkolwiek pytań lub jeśli chcesz się tylko przywitać :)



