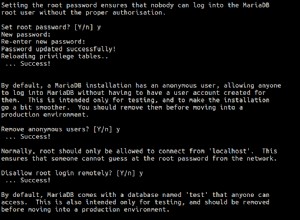
Dodam nieco dłuższe i bardziej szczegółowe wyjaśnienie kroków, które należy podjąć, aby rozwiązać ten problem. Przepraszam, jeśli to za długo.
Zacznę od bazy, którą podałeś i użyję jej do zdefiniowania kilku terminów, których będę używał w dalszej części tego postu. To będzie tabela podstawowa :
select * from history;
+--------+----------+-----------+
| hostid | itemname | itemvalue |
+--------+----------+-----------+
| 1 | A | 10 |
| 1 | B | 3 |
| 2 | A | 9 |
| 2 | C | 40 |
+--------+----------+-----------+
To będzie nasz cel, ładna tabela przestawna :
select * from history_itemvalue_pivot;
+--------+------+------+------+
| hostid | A | B | C |
+--------+------+------+------+
| 1 | 10 | 3 | 0 |
| 2 | 9 | 0 | 40 |
+--------+------+------+------+
Wartości w history.hostid kolumna zmieni się w wartości y w tabeli przestawnej. Wartości w history.itemname kolumna zmieni się w wartości x (z oczywistych powodów).
Kiedy muszę rozwiązać problem tworzenia tabeli przestawnej, radzę sobie z nim w trzyetapowym procesie (z opcjonalnym czwartym krokiem):
- wybierz interesujące kolumny, tj. wartości y i wartości x
- rozszerz tabelę podstawową o dodatkowe kolumny — po jednej dla każdej wartości x
- grupuj i agreguj rozszerzoną tabelę – jedna grupa dla każdej wartości y
- (opcjonalnie) upiększ tabelę zagregowaną
Zastosujmy te kroki do Twojego problemu i zobaczmy, co otrzymamy:
Krok 1:wybierz interesujące kolumny . W żądanym wyniku hostid dostarcza wartości y i itemname dostarcza wartości x .
Krok 2:rozszerz tabelę podstawową o dodatkowe kolumny . Zwykle potrzebujemy jednej kolumny na wartość x. Przypomnij sobie, że nasza kolumna x-value to itemname :
create view history_extended as (
select
history.*,
case when itemname = "A" then itemvalue end as A,
case when itemname = "B" then itemvalue end as B,
case when itemname = "C" then itemvalue end as C
from history
);
select * from history_extended;
+--------+----------+-----------+------+------+------+
| hostid | itemname | itemvalue | A | B | C |
+--------+----------+-----------+------+------+------+
| 1 | A | 10 | 10 | NULL | NULL |
| 1 | B | 3 | NULL | 3 | NULL |
| 2 | A | 9 | 9 | NULL | NULL |
| 2 | C | 40 | NULL | NULL | 40 |
+--------+----------+-----------+------+------+------+
Zwróć uwagę, że nie zmieniliśmy liczby wierszy — po prostu dodaliśmy dodatkowe kolumny. Zwróć także uwagę na wzorzec NULL s -- wiersz z itemname = "A" ma wartość inną niż null dla nowej kolumny A i wartości null dla innych nowych kolumn.
Krok 3:pogrupuj i agreguj rozszerzoną tabelę . Musimy group by hostid , ponieważ dostarcza wartości y:
create view history_itemvalue_pivot as (
select
hostid,
sum(A) as A,
sum(B) as B,
sum(C) as C
from history_extended
group by hostid
);
select * from history_itemvalue_pivot;
+--------+------+------+------+
| hostid | A | B | C |
+--------+------+------+------+
| 1 | 10 | 3 | NULL |
| 2 | 9 | NULL | 40 |
+--------+------+------+------+
(Zauważ, że mamy teraz jeden wiersz na wartość y). Dobra, już prawie jesteśmy! Musimy tylko pozbyć się tych brzydkich NULL s.
Krok 4:upiększ . Zamienimy po prostu wszystkie wartości null na zera, aby zestaw wyników był przyjemniejszy do oglądania:
create view history_itemvalue_pivot_pretty as (
select
hostid,
coalesce(A, 0) as A,
coalesce(B, 0) as B,
coalesce(C, 0) as C
from history_itemvalue_pivot
);
select * from history_itemvalue_pivot_pretty;
+--------+------+------+------+
| hostid | A | B | C |
+--------+------+------+------+
| 1 | 10 | 3 | 0 |
| 2 | 9 | 0 | 40 |
+--------+------+------+------+
I gotowe — zbudowaliśmy ładną, ładną tabelę przestawną za pomocą MySQL.
Uwagi dotyczące stosowania tej procedury:
- jakiej wartości użyć w dodatkowych kolumnach. Użyłem
itemvaluew tym przykładzie - jakiej „neutralnej” wartości użyć w dodatkowych kolumnach. Użyłem
NULL, ale może to być również0lub"", w zależności od Twojej dokładnej sytuacji - jakiej funkcji agregującej użyć podczas grupowania. Użyłem
sum, alecountimaxsą również często używane (maxjest często używany podczas budowania jednorzędowych „obiektów”, które były rozłożone na wiele wierszy) - używanie wielu kolumn dla wartości y. To rozwiązanie nie ogranicza się do używania pojedynczej kolumny dla wartości y — po prostu podłącz dodatkowe kolumny do
group byklauzula (i nie zapomnijselectich)
Znane ograniczenia:
- to rozwiązanie nie zezwala na n kolumn w tabeli przestawnej — każdą kolumnę przestawną należy dodać ręcznie podczas rozszerzania tabeli podstawowej. Tak więc dla 5 lub 10 wartości x to rozwiązanie jest dobre. Za 100, nie tak miło. Istnieje kilka rozwiązań z procedurami składowanymi generującymi zapytania, ale są one brzydkie i trudne do wykonania. Obecnie nie znam dobrego sposobu na rozwiązanie tego problemu, gdy tabela przestawna musi mieć wiele kolumn.