Wraz z wprowadzeniem Azure SQL Database i dodaniem większej liczby funkcji w wersji 12, administratorzy baz danych zaczynają widzieć, że ich organizacje są bardziej zainteresowane przenoszeniem baz danych na tę platformę.
Niedawno zacząłem bardziej zagłębiać się w Azure SQL Database, aby zobaczyć, co drastycznie różni się od obsługi wersji pudełkowej w centrach danych na całym świecie i Azure SQL Database. W moim poprzednim artykule „Dostrajanie:dobre miejsce na start” omówiłem moje podejście do dostrajania SQL Server. Postanowiłem porównać to z bazą danych Azure SQL Database, aby odkryć główne różnice.
W moim oryginalnym artykule zacząłem od typowych ustawień na poziomie instancji, które są ignorowane lub pozostawione jako domyślne, a także elementów konserwacji. Obejmują one pamięć, maxdop, próg kosztów dla równoległości, włączanie optymalizacji pod kątem obciążeń ad hoc i konfigurowanie tempdb. W przypadku Azure SQL Database nie odpowiadasz za wystąpienie i nie możesz modyfikować tych ustawień. Azure SQL Database to platforma jako usługa (PaaS), co oznacza, że firma Microsoft zarządza instancją za Ciebie; jesteś po prostu najemcą ze swoją bazą danych lub bazami danych.
Jesteś jednak odpowiedzialny za konserwację, więc musisz aktualizować statystyki i radzić sobie z fragmentacją indeksu, tak jak w przypadku produktu pudełkowego. Odkryłem, że w przypadku tych zadań większość klientów zarządza tymi procesami za pomocą dedykowanej maszyny wirtualnej platformy Azure z programem SQL Server i agentem programu SQL Server z zaplanowanymi zadaniami.
Podążając za krokami z mojego artykułu, kolejnymi obszarami, którymi zaczynam się zajmować, są statystyki plików i oczekiwania oraz zapytania o wysokim koszcie. Jeśli zastanawiasz się, czy ten aspekt Twojej pracy jako pracownika produkcyjnego z lokalnymi bazami danych zmieni się podczas pracy z usługą Azure SQL Database, odpowiedź brzmi nie do końca . Statystyki plików i oczekiwania wciąż tam są, ale musimy się do nich dostać w nieco inny sposób. Jeśli jesteś przyzwyczajony do używania skryptów Paula Randala do statystyk plików i statystyk oczekiwania (lub zapytań o statystyki plików dla okresu czasu i statystyk oczekiwania dla okresu czasu), będziesz musiał wprowadzić pewne zmiany, aby te skrypty do pracy z usługą Azure SQL Database.
Kiedy po raz pierwszy wypróbowałem skrypt statystyk plików Paula, nie powiodło się, ponieważ Azure SQL Database nie obsługuje sys.master_files :
Nieprawidłowa nazwa obiektu „sys.master_files”.
Udało mi się zmodyfikować skrypt, aby używał sys.databases w złączeniu, aby uzyskać nazwę bazy danych i usunąć część skryptu, aby uzyskać indywidualne nazwy plików, ponieważ będziemy mieli do czynienia tylko z pojedynczym plikiem danych i dziennika. Możesz zobaczyć zmiany, które musiałem wprowadzić na następującym obrazku:
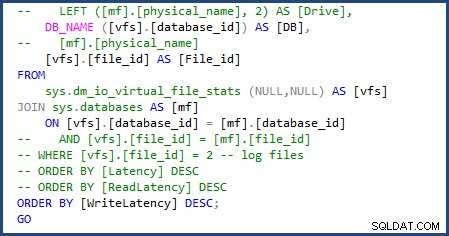
Kiedy uruchomiłem skrypt file-stats-over-a-period-of-time, wprowadzając tę samą zmianę w sys.databases i usunięcie odwołań do file_id w łączeniu nie powiodło się, ponieważ Azure SQL Database v12 nie obsługuje globalnych tabel ##temp.
Kiedy zmieniłem wszystkie globalne tabele ##temp na lokalne, miałem inny problem ze skryptem, który nie mógł usunąć istniejących tabel tymczasowych, które były używane, ponieważ lokalne tabele #temp nie mogą być bezpośrednio przywoływane przez nazwę, tak jak globalne tabele ##temp, ale było to łatwe do pokonania, zmieniając takie sprawdzenia na OBJECT_ID('tempdb..#SQLskillsStats1') . Dokonałem tej samej zmiany dla drugiej tabeli tymczasowej i zaktualizowałem blok kodu na początku i na końcu skryptu.
Musiałem wprowadzić jeszcze jedną zmianę i usunąć [mf].[type_desc] i LEFT ([mf].[physical_name], 2) AS [Drive] ponieważ są one zależne od sys.master_files . Skrypt był następnie gotowy i gotowy do użycia z usługą Azure SQL Database.
Podczas rozwiązywania problemów z wydajnością regularnie korzystam ze statystyk plików na przestrzeni czasu. Zbiorcze dane mają swój cel, ale bardziej interesują mnie określone segmenty czasu, w których wykonywane są obciążenia użytkowników.
Jeśli chodzi o statystyki plików, martwimy się o opóźnienie dla każdego pliku bazy danych oraz o to, jak możemy dostroić, aby pomóc zredukować ogólne operacje we/wy. Podejście jest takie samo jak w przypadku SQL Server, gdzie należy odpowiednio dostroić zapytania i mieć prawidłowe indeksy. Jeśli obciążenie jest po prostu zbyt duże, musisz przejść do warstwy bazy danych DTU o szybszej wydajności. Dla mnie to jest świetne:po prostu rzucasz w to sprzętem; ale tak naprawdę nie jest to sprzęt w tradycyjnym tego słowa znaczeniu. Dzięki Azure SQL Database możesz zacząć od tańszej warstwy i skalowania w miarę wzrostu wymagań biznesowych i we/wy — zasadniczo po prostu przełączając przełącznik.
Próba znalezienia najlepszej metody na uzyskanie statystyk oczekiwania była łatwiejsza. Standardowy skrypt, którego wielu z nas używa, nadal działa, jednak pobiera statystyki oczekiwania na kontener, w którym działa Twoja baza danych. Te oczekiwania nadal dotyczą twojego systemu, ale mogą obejmować oczekiwania poniesione przez inne bazy danych w tym samym kontenerze. Azure SQL Database zawiera nowy DMV, sys.dm_db_wait_stats , który filtruje do bieżącej bazy danych. Jeśli jesteś podobny do mnie i używasz głównie skryptu statystyk oczekiwania Paula, który pomija wszystkie łagodne oczekiwania, po prostu zmień sys.dm_os_wait_stats do sys.dm_db_wait_stats . Ta sama zmiana działa również w skrypcie oczekiwania ponad okres czasu, ale musisz również dokonać zmiany ze zmiennych globalnych na lokalne.
Jeśli chodzi o wyszukiwanie zapytań o wysokich kosztach, jeden z moich ulubionych skryptów do uruchomienia znajduje najczęściej używane plany wykonania. Z mojego doświadczenia wynika, że dostrajanie zapytania, które jest wywoływane 100 000 razy dziennie, jest zwykle większą wygraną niż dostrajanie zapytania, które ma najwyższą liczbę we/wy, ale jest uruchamiane tylko raz w tygodniu. Poniższe zapytanie jest tym, czego używam, aby znaleźć najczęściej używane plany:
SELECT liczniki_użytków, typ_objjbuforu, typ_obiektu, [tekst]FROM sys.dm_exec_cached_plans KRZYŻ ZASTOSUJ sys.dm_exec_sql_text(plan_handle)WHERE liczniki_użytków> 1 AND objtype IN (N'Adhoc', N'Przygotowane') ORDER BY; pre>Korzystając z tego zapytania w wersjach demonstracyjnych, zawsze opróżniam pamięć podręczną planu, aby zresetować wartości. Kiedy próbowałem uruchomić
DBCC FREEPROCCACHEw Azure SQL Database otrzymałem następujący błąd:Okazuje się, że
SQL Azure obecnie nie obsługuje DBCC FREEPROCCACHE (języka Transact-SQL), więc nie można ręcznie usunąć planu wykonania z pamięci podręcznej. Jeśli jednak wprowadzisz zmiany w tabeli lub widoku, do którego odwołuje się zapytanie (ALTER TABLE i ALTER VIEW), plan zostanie usunięty z pamięci podręcznej.DBCC FREEPROCCACHEnie jest obsługiwana w Azure SQL Database. To było dla mnie kłopotliwe, co jeśli jestem na produkcji i mam złe plany i chcę wyczyścić pamięć podręczną procedur, tak jak mogę w wersji pudełkowej. Niewielkie badanie Google/Bing doprowadziło mnie do znalezienia artykułu firmy Microsoft „Understanding the Procedure Cache on SQL Azure”, który stwierdza:Podczas omawiania tego z Kimberly Tripp po tym, jak nie zauważył opisanego zachowania, nie usuwa planu z pamięci podręcznej, ale unieważnia plan (a następnie plan zostanie ostatecznie przestarzały z pamięci podręcznej). Chociaż jest to pomocne w niektórych sytuacjach, nie tego potrzebowałem. W moim demo chciałem zresetować liczniki w sys.dm_exec_cached_plans. Generowanie nowego planu nie przyniosłoby mi pożądanych rezultatów. Skontaktowałem się z moim zespołem i Glenn Berry polecił mi wypróbować następujący skrypt:
ZMIANA KONFIGURACJI W ZAKRESIE BAZY DANYCH WYCZYŚĆ PROCEDURE_CACHE;To polecenie zadziałało; Udało mi się wyczyścić pamięć podręczną procedur dla określonej bazy danych. Konfiguracje w zakresie bazy danych to nowa funkcja dodana w programie SQL Server 2016 RC0; Glenn napisał o tym tutaj:Używanie ALTER DATABASE SCOPED CONFIGURATION w SQL Server 2016.
Cieszę się, że mogę przenieść kilka własnych baz danych do Azure SQL Database i kontynuować poznawanie nowych funkcji i opcji skalowalności. Nie mogę się również doczekać współpracy z SentryOne DB Sentry, najnowszym dodatkiem do platformy SentryOne. Najbardziej interesuje mnie eksperymentowanie z pulpitem nawigacyjnym DTU Usage, który Mike Wood opisał w swoim ostatnim poście.