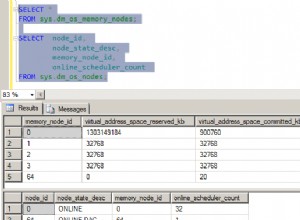
Za każdym razem informacje są jeden do jednego (każdy użytkownik ma jedną nazwę i hasło), wtedy prawdopodobnie lepiej jest mieć jedną tabelę, ponieważ zmniejsza to liczbę złączeń, które baza danych będzie musiała wykonać, aby pobrać wyniki. Myślę, że niektóre bazy danych mają limit liczby kolumn na tabelę, ale w normalnych przypadkach nie martwiłbym się tym i zawsze możesz je podzielić później, jeśli zajdzie taka potrzeba.
Jeśli dane są typu jeden do wielu (każdy użytkownik ma tysiące wierszy informacji o użyciu), należy je podzielić na osobne tabele, aby zmniejszyć duplikaty danych (duplikaty danych marnują miejsce do przechowywania, pamięć podręczną i utrudniają utrzymanie bazy danych ).
Możesz znaleźć artykuł w Wikipedii na temat normalizacji baz danych interesujące, ponieważ szczegółowo omawia przyczyny takiego stanu rzeczy:
Normalizacja bazy danych to proces organizowania pól i tabel relacyjnej bazy danych w celu zminimalizowania nadmiarowości i zależności. Normalizacja zwykle polega na podzieleniu dużych tabel na mniejsze (i mniej nadmiarowe) i zdefiniowaniu relacji między nimi. Celem jest wyizolowanie danych, tak aby można było dodawać, usuwać i modyfikować pola tylko w jednej tabeli, a następnie propagować je w pozostałej części bazy danych za pośrednictwem zdefiniowanych relacji.
Denormalizacja jest również czymś, o czym należy pamiętać, ponieważ zdarzają się przypadki, w których powtarzanie danych jest lepsze (ponieważ zmniejsza ilość pracy, jaką baza danych musi wykonać podczas odczytu danych). Zdecydowanie zalecam, aby na początek Twoje dane były jak najbardziej znormalizowane, a denormalizacja tylko wtedy, gdy masz świadomość problemów z wydajnością w określonych zapytaniach.