W poprzednim poście omówiliśmy, jak sprawdzić, czy replikacja MySQL jest w dobrym stanie. Przyjrzeliśmy się również niektórym typowym problemom. W tym poście przyjrzymy się kilku innym problemom, które możesz napotkać, mając do czynienia z replikacją MySQL.
Brakujące lub zduplikowane wpisy
To jest coś, co nie powinno się zdarzyć, a zdarza się bardzo często - sytuacja, w której instrukcja SQL wykonana na masterze się powiedzie, ale ta sama instrukcja wykonana na jednym z slave'ów zawiedzie. Głównym powodem jest dryf niewolników - coś (zwykle błędne transakcje, ale także inne problemy lub błędy w replikacji) powoduje, że niewolnik różni się od swojego mistrza. Na przykład wiersz, który istniał na urządzeniu głównym, nie istnieje na urządzeniu podrzędnym i nie można go usunąć ani zaktualizować. Częstotliwość występowania tego problemu zależy głównie od ustawień replikacji. Krótko mówiąc, MySQL przechowuje zdarzenia dziennika binarnego na trzy sposoby. Po pierwsze, „instrukcja” oznacza, że SQL jest napisany zwykłym tekstem, tak jak został wykonany na wzorcu. To ustawienie ma najwyższą tolerancję na dryf niewolników, ale jest również tym, które nie może zagwarantować spójności niewolników - trudno polecić stosowanie go w produkcji. Drugi format, „wiersz”, przechowuje wynik zapytania zamiast wyrażenia zapytania. Na przykład wydarzenie może wyglądać tak:
### UPDATE `test`.`tab`
### WHERE
### @1=2
### @2=5
### SET
### @1=2
### @2=4Oznacza to, że aktualizujemy wiersz w tabeli 'tab' w schemacie 'test', gdzie pierwsza kolumna ma wartość 2, a druga kolumna ma wartość 5. Ustawiamy pierwszą kolumnę na 2 (wartość nie zmienia się) a druga kolumna do 4. Jak widać, nie ma zbyt wiele miejsca na interpretację - jest dokładnie określone, który wiersz jest używany i jak jest zmieniany. W rezultacie ten format jest świetny dla spójności niewolników, ale, jak możesz sobie wyobrazić, jest bardzo podatny na dryf danych. Mimo to jest to zalecany sposób uruchamiania replikacji MySQL.
Wreszcie trzecia, „mieszana”, działa w taki sposób, że te zdarzenia, które można bezpiecznie zapisać w formie wypowiedzi, używają formatu „oświadczenia”. Te, które mogą powodować dryf danych, będą używać formatu „wiersz”.
Jak je wykrywasz?
Jak zwykle, SHOW SLAVE STATUS pomoże nam zidentyfikować problem.
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000021, end_log_pos 970 Last_SQL_Errno: 1062
Last_SQL_Error: Could not execute Write_rows event on table test.tab; Duplicate entry '3' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log binlog.000021, end_log_pos 1229Jak widać, błędy są jasne i oczywiste (i są w zasadzie identyczne w MySQL i MariaDB.
Jak rozwiązać ten problem?
To jest niestety złożona część. Przede wszystkim musisz zidentyfikować źródło prawdy. Który host zawiera prawidłowe dane? Mistrz czy niewolnik? Zwykle zakładasz, że to mistrz, ale nie zakładaj tego domyślnie - zbadaj! Może się zdarzyć, że po przełączeniu awaryjnym jakaś część wydanej aplikacji nadal zapisuje do starego mastera, który teraz działa jako slave. Możliwe, że read_only nie zostało poprawnie ustawione na tym hoście lub aplikacja używa superużytkownika do łączenia się z bazą danych (tak, widzieliśmy to w środowiskach produkcyjnych). W takim przypadku niewolnik mógłby być źródłem prawdy - przynajmniej do pewnego stopnia.
W zależności od tego, które dane powinny pozostać, a które powinny zostać usunięte, najlepszym sposobem działania byłoby zidentyfikowanie tego, co jest potrzebne do przywrócenia synchronizacji replikacji. Po pierwsze, replikacja jest zepsuta, więc musisz się tym zająć. Zaloguj się do mastera i sprawdź dziennik binarny, nawet jeśli spowodował przerwanie replikacji.
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106672
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106671Jak widać przegapiamy jedno wydarzenie:5d1e2227-07c6-11e7-8123-080027495a77:1106672. Sprawdźmy to w logach binarnych mastera:
mysqlbinlog -v --include-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1106672' /var/lib/mysql/binlog.000021
#170320 20:53:37 server id 1 end_log_pos 1066 CRC32 0xc582a367 GTID last_committed=3 sequence_number=4
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672'/*!*/;
# at 1066
#170320 20:53:37 server id 1 end_log_pos 1138 CRC32 0x6f33754d Query thread_id=5285 exec_time=0 error_code=0
SET TIMESTAMP=1490043217/*!*/;
SET @@session.pseudo_thread_id=5285/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
BEGIN
/*!*/;
# at 1138
#170320 20:53:37 server id 1 end_log_pos 1185 CRC32 0xa00b1f59 Table_map: `test`.`tab` mapped to number 571
# at 1185
#170320 20:53:37 server id 1 end_log_pos 1229 CRC32 0x5597e50a Write_rows: table id 571 flags: STMT_END_F
BINLOG '
UUHQWBMBAAAALwAAAKEEAAAAADsCAAAAAAEABHRlc3QAA3RhYgACAwMAAlkfC6A=
UUHQWB4BAAAALAAAAM0EAAAAADsCAAAAAAEAAgAC//wDAAAABwAAAArll1U=
'/*!*/;
### INSERT INTO `test`.`tab`
### SET
### @1=3
### @2=7
# at 1229
#170320 20:53:37 server id 1 end_log_pos 1260 CRC32 0xbbc3367c Xid = 5224257
COMMIT/*!*/;Widzimy, że był to insert, który ustawia pierwszą kolumnę na 3, a drugą na 7. Sprawdźmy teraz, jak wygląda nasza tabela:
mysql> SELECT * FROM test.tab;
+----+------+
| id | b |
+----+------+
| 1 | 2 |
| 2 | 4 |
| 3 | 10 |
+----+------+
3 rows in set (0.01 sec)Teraz mamy dwie opcje, w zależności od tego, które dane powinny przeważać. Jeśli prawidłowe dane znajdują się na urządzeniu głównym, możemy po prostu usunąć wiersz o id=3 na urządzeniu podrzędnym. Tylko upewnij się, że wyłączyłeś logowanie binarne, aby uniknąć wprowadzania błędnych transakcji. Z drugiej strony, jeśli uznamy, że prawidłowe dane znajdują się na urządzeniu podrzędnym, musimy uruchomić polecenie REPLACE na urządzeniu głównym, aby ustawić wiersz o id=3 na poprawną zawartość (3, 10) z bieżącego (3, 7). Jednak na urządzeniu podrzędnym będziemy musieli pominąć bieżący GTID (a dokładniej, będziemy musieli utworzyć puste zdarzenie GTID), aby móc ponownie uruchomić replikację.
Usunięcie wiersza w urządzeniu podrzędnym jest proste:
SET SESSION log_bin=0; DELETE FROM test.tab WHERE id=3; SET SESSION log_bin=1;Wstawianie pustego identyfikatora GTID jest prawie tak proste:
mysql> SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672';
Query OK, 0 rows affected (0.00 sec)mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)mysql> COMMIT;
Query OK, 0 rows affected (0.00 sec)mysql> SET @@SESSION.GTID_NEXT=automatic;
Query OK, 0 rows affected (0.00 sec)Inną metodą rozwiązania tego konkretnego problemu (o ile akceptujemy mastera jako źródło prawdy) jest użycie narzędzi takich jak pt-table-checksum i pt-table-sync, aby zidentyfikować, gdzie slave nie jest zgodny ze swoim masterem i co SQL musi zostać wykonany na urządzeniu głównym, aby przywrócić synchronizację urządzenia podrzędnego. Niestety, ta metoda jest dość ciężka - do mastera jest dodawane duże obciążenie, a do strumienia replikacji zapisywanych jest kilka zapytań, co może wpłynąć na opóźnienia na urządzeniach podrzędnych i ogólną wydajność konfiguracji replikacji. Jest to szczególnie ważne, jeśli istnieje znaczna liczba wierszy, które wymagają synchronizacji.
Wreszcie, jak zawsze, możesz odbudować swojego slave'a korzystając z danych z mastera - w ten sposób masz pewność, że slave zostanie odświeżony najświeższymi, aktualnymi danymi. W rzeczywistości niekoniecznie jest to zły pomysł — kiedy mówimy o dużej liczbie wierszy do synchronizacji za pomocą pt-table-checksum/pt-table-sync, wiąże się to ze znacznym obciążeniem wydajnością replikacji, ogólnym procesorem i we/wy wymagane obciążenie i roboczogodziny.
ClusterControl umożliwia odbudowanie urządzenia podrzędnego przy użyciu nowej kopii danych głównych.
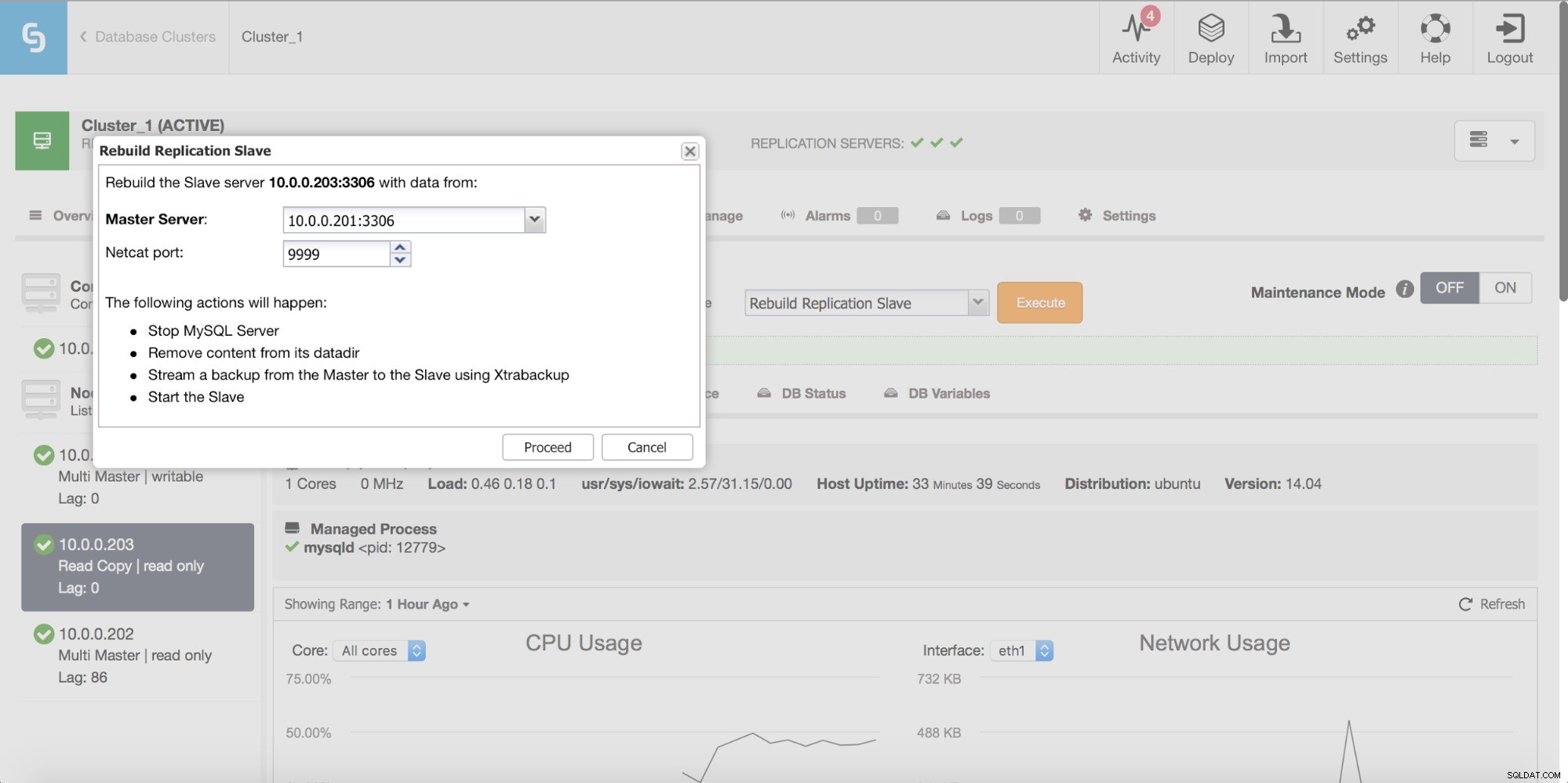
Kontrole spójności
Jak wspomnieliśmy w poprzednim rozdziale, spójność może stać się poważnym problemem i może powodować wiele bólu głowy dla użytkowników korzystających z konfiguracji replikacji MySQL. Zobaczmy, jak możesz sprawdzić, czy twoje serwery podrzędne MySQL są zsynchronizowane z urządzeniem głównym i co możesz z tym zrobić.
Jak wykryć niespójne urządzenie podrzędne
Niestety, typowym sposobem, w jaki użytkownik dowiaduje się, że niewolnik jest niespójny, jest napotkanie jednego z problemów, o których wspomnieliśmy w poprzednim rozdziale. Aby tego uniknąć, wymagane jest proaktywne monitorowanie spójności urządzenia podrzędnego. Sprawdźmy, jak można to zrobić.
Użyjemy narzędzia z Percona Toolkit:pt-table-checksum. Jest przeznaczony do skanowania klastra replikacji i identyfikowania wszelkich rozbieżności.
Zbudowaliśmy niestandardowy scenariusz za pomocą sysbench i wprowadziliśmy trochę niespójności na jednym z niewolników. Co ważne (jeśli chcesz przetestować to tak jak my), musisz zastosować łatkę poniżej, aby zmusić pt-table-checksum do rozpoznawania schematu „sbtest” jako schematu niesystemowego:
--- pt-table-checksum 2016-12-15 14:31:07.000000000 +0000
+++ pt-table-checksum-fix 2017-03-21 20:32:53.282254794 +0000
@@ -7614,7 +7614,7 @@
my $filter = $self->{filters};
- if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|test/ ) {
+ if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|^test/ ) {
PTDEBUG && _d('Database', $db, 'is a system database, ignoring');
return 0;
}Najpierw wykonamy pt-table-checksum w następujący sposób:
master:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T20:33:30 0 0 1000000 15 0 27.103 sbtest.sbtest1
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2
03-21T20:34:26 0 0 1000000 15 0 28.503 sbtest.sbtest3
03-21T20:34:52 0 0 1000000 18 0 26.021 sbtest.sbtest4
03-21T20:35:34 0 0 1000000 17 0 42.730 sbtest.sbtest5
03-21T20:36:04 0 0 1000000 16 0 29.309 sbtest.sbtest6
03-21T20:36:42 0 0 1000000 15 0 38.071 sbtest.sbtest7
03-21T20:37:16 0 0 1000000 12 0 33.737 sbtest.sbtest8Kilka ważnych uwag na temat tego, jak wywołaliśmy narzędzie. Przede wszystkim ustawiony przez nas użytkownik musi istnieć na wszystkich slave'ach. Jeśli chcesz, możesz również użyć „--slave-user”, aby zdefiniować innego, mniej uprzywilejowanego użytkownika, aby uzyskać dostęp do urządzeń podrzędnych. Kolejna rzecz warta wyjaśnienia - używamy replikacji wierszowej, która nie jest w pełni kompatybilna z sumą kontrolną pt-table. Jeśli masz replikację opartą na wierszach, suma kontrolna pt-table-checksum zmieni format dziennika binarnego na poziomie sesji na „instrukcję”, ponieważ jest to jedyny obsługiwany format. Problem w tym, że taka zmiana zadziała tylko na pierwszym poziomie urządzeń podrzędnych, które są bezpośrednio połączone z masterem. Jeśli masz mastery pośrednie (a więc więcej niż jeden poziom slave), użycie sumy kontrolnej pt-table-check może przerwać replikację. Dlatego domyślnie, jeśli narzędzie wykryje replikację opartą na wierszach, kończy działanie i wyświetla błąd:
„Replika slave1 ma wiersz binlog_format, który może spowodować przerwanie replikacji przez sumę kontrolną pt-table-table. Przeczytaj „Repliki korzystające z replikacji opartej na wierszach” w sekcji OGRANICZENIA w dokumentacji narzędzia. Jeśli rozumiesz ryzyko, określ --no-check-binlog-format, aby wyłączyć to sprawdzanie”.
Użyliśmy tylko jednego poziomu niewolników, więc bezpiecznie było określić „--no-check-binlog-format” i przejść dalej.
Na koniec ustawiliśmy maksymalne opóźnienie na 5 sekund. Jeśli ten próg zostanie osiągnięty, suma kontrolna pt-table zostanie wstrzymana na czas potrzebny do sprowadzenia opóźnienia poniżej progu.
Jak widać z danych wyjściowych,
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2wykryto niezgodność w tabeli sbtest.sbtest2.
Domyślnie pt-table-checksum przechowuje sumy kontrolne w tabeli percona.checksums. Te dane można wykorzystać w innym narzędziu z Percona Toolkit, pt-table-sync, w celu określenia, które części tabeli należy szczegółowo sprawdzić, aby znaleźć dokładną różnicę w danych.
Jak naprawić niespójny Slave
Jak wspomniano powyżej, użyjemy do tego celu pt-table-sync. W naszym przypadku użyjemy danych zebranych przez sumę kontrolną pt-table-check, chociaż możliwe jest również wskazanie pt-table-sync dwóch hostów (master i slave) i porówna wszystkie dane na obu hostach. Jest to zdecydowanie bardziej czasochłonny i zasobożerny proces, dlatego o ile masz już dane z sumy kontrolnej pt-table-check to znacznie lepiej z niej skorzystać. W ten sposób wykonaliśmy to, aby przetestować wyjście:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=master --printREPLACE INTO `sbtest`.`sbtest2`(`id`, `k`, `c`, `pad`) VALUES ('1', '434041', '61753673565-14739672440-12887544709-74227036147-86382758284-62912436480-22536544941-50641666437-36404946534-73544093889', '23608763234-05826685838-82708573685-48410807053-00139962956') /*percona-toolkit src_db:sbtest src_tbl:sbtest2 src_dsn:h=10.0.0.101,p=...,u=sbtest dst_db:sbtest dst_tbl:sbtest2 dst_dsn:h=10.0.0.103,p=...,u=sbtest lock:1 transaction:1 changing_src:percona.checksums replicate:percona.checksums bidirectional:0 pid:25776 user:root host:vagrant-ubuntu-trusty-64*/;Jak widać, w rezultacie wygenerowano trochę kodu SQL. Należy zauważyć, że zmienna --replicate. To, co się tutaj dzieje, to wskazujemy pt-table-sync na tabelę wygenerowaną przez sumę kontrolną pt-table-check. Wskazujemy go również na mistrza.
Aby sprawdzić, czy SQL ma sens, użyliśmy opcji --print. Należy pamiętać, że wygenerowany kod SQL jest ważny tylko w momencie jego wygenerowania — tak naprawdę nie można go gdzieś przechowywać, przejrzeć, a następnie wykonać. Wszystko, co możesz zrobić, to zweryfikować, czy SQL ma sens, i natychmiast po tym ponownie uruchomić narzędzie z flagą --execute:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=10.0.0.101 --executePowinno to sprawić, że slave będzie zsynchronizowany z masterem. Możemy to zweryfikować sumą kontrolną pt-table:
example@sqldat.com:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T21:36:04 0 0 1000000 13 0 23.749 sbtest.sbtest1
03-21T21:36:26 0 0 1000000 7 0 22.333 sbtest.sbtest2
03-21T21:36:51 0 0 1000000 10 0 24.780 sbtest.sbtest3
03-21T21:37:11 0 0 1000000 14 0 19.782 sbtest.sbtest4
03-21T21:37:42 0 0 1000000 15 0 30.954 sbtest.sbtest5
03-21T21:38:07 0 0 1000000 15 0 25.593 sbtest.sbtest6
03-21T21:38:27 0 0 1000000 16 0 19.339 sbtest.sbtest7
03-21T21:38:44 0 0 1000000 15 0 17.371 sbtest.sbtest8Jak widać, nie ma już różnic w tabeli sbtest.sbtest2.
Mamy nadzieję, że ten post na blogu okazał się przydatny i pouczający. Kliknij tutaj, aby dowiedzieć się więcej o replikacji MySQL. Jeśli masz jakieś pytania lub sugestie, skontaktuj się z nami, korzystając z poniższych komentarzy.



