MySQL jest łatwy w instalacji i obsłudze, zawsze był popularny wśród programistów i administratorów systemu. Z drugiej strony, wdrażanie gotowego do produkcji środowiska MySQL w przypadku obciążenia biznesowego o znaczeniu krytycznym to zupełnie inna historia. Może to być wyzwaniem i wymaga dogłębnej znajomości bazy danych. W tym poście na blogu omówimy niektóre kroki, które należy podjąć, zanim uznamy, że nasze wdrożenie MySQL jest gotowe do produkcji.
Wysoka dostępność

Jeśli należysz do tych szczęśliwców, którzy potrafią zaakceptować godziny przestojów, możesz przestać czytać tutaj i przejść do następnego akapitu. W przypadku 99,999% systemów o znaczeniu krytycznym dla biznesu byłoby to nie do zaakceptowania. Dlatego wdrożenie gotowe do produkcji musi obejmować środki wysokiej dostępności. Głównym wymaganiem byłoby automatyczne przełączanie awaryjne instancji bazy danych, a także warstwa proxy, która wykrywa zmiany w topologii i stanie MySQL i odpowiednio kieruje ruch. Istnieje wiele narzędzi, które można wykorzystać do budowy takich środowisk, na przykład MHA, MRM czy ClusterControl.
Warstwa proxy
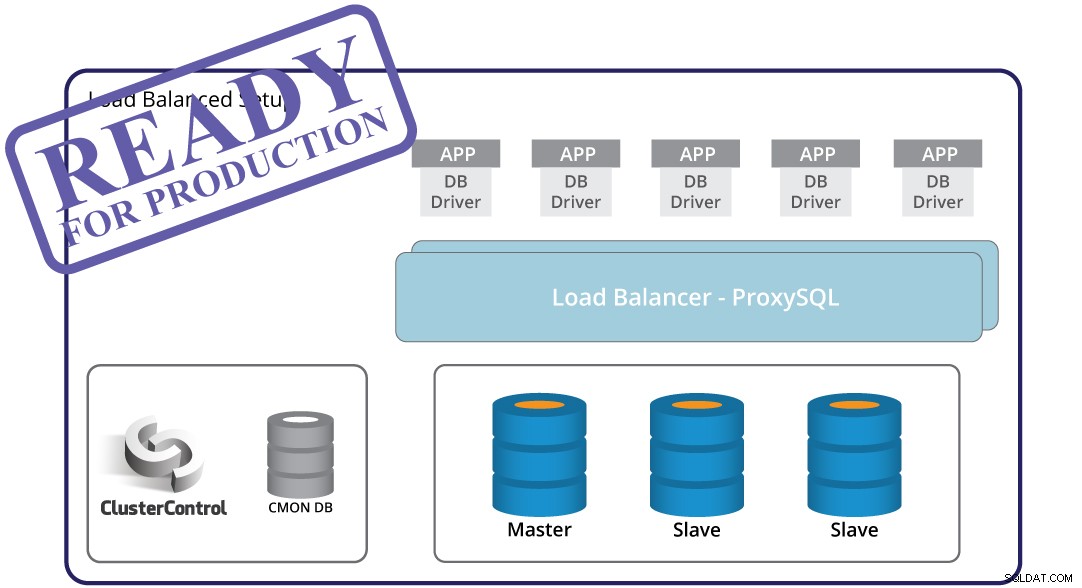
Nadrzędne wykrywanie awarii, automatyczne przełączanie awaryjne i odzyskiwanie — to kluczowe elementy podczas budowania infrastruktury gotowej do produkcji. Ale na własną rękę to nie wystarczy. Nadal istnieje aplikacja, która będzie musiała dostosować się do zmiany topologii wywołanej przełączeniem awaryjnym. Oczywiście możliwe jest zakodowanie aplikacji tak, aby była świadoma awarii instancji. Jest to jednak niewygodny i nieelastyczny sposób obsługi zmian topologii. Nadchodzi proxy bazy danych - środkowa warstwa między aplikacją a bazą danych. Proxy może ukryć przed aplikacją złożoność warstwy bazy danych — aplikacja łączy się tylko z proxy, a proxy zajmie się resztą. Proxy będzie kierować zapytania do instancji bazy danych, obsługiwać zmiany topologii i przekierowywać je w razie potrzeby. Serwer proxy może być również używany do implementacji podziału odczytu i zapisu, uwalniając aplikację od jeszcze jednego bardziej złożonego przypadku do omówienia. Stwarza to kolejne wyzwanie — którego serwera proxy użyć? Jak to skonfigurować? Jak to monitorować? Jak sprawić, by była wysoce dostępna, aby nie stała się SPOFem?
ClusterControl może w tym pomóc. Może być używany do wdrażania różnych serwerów proxy w celu utworzenia warstwy proxy:ProxySQL, HAProxy i MaxScale. Wstępnie konfiguruje serwery proxy, aby upewnić się, że będą prawidłowo obsługiwać ruch. Ułatwia również wprowadzanie wszelkich zmian w konfiguracji, jeśli chcesz dostosować ustawienia proxy dla swojej aplikacji. Podział odczytu i zapisu można skonfigurować za pomocą dowolnego z serwerów proxy obsługiwanych przez ClusterControl. ClusterControl monitoruje również serwery proxy i odzyskuje je w przypadku awarii. Warstwa proxy może stać się pojedynczym punktem awarii, ponieważ automatyczne odzyskiwanie może nie wystarczyć - aby temu zaradzić, ClusterControl może wdrożyć Keepalived i skonfigurować wirtualny adres IP, aby zautomatyzować przełączanie awaryjne.
Kopie zapasowe
Nawet jeśli nie musisz wdrażać wysokiej dostępności, prawdopodobnie nadal musisz dbać o swoje dane. Backup jest koniecznością dla prawie każdej produkcyjnej bazy danych. Nic innego jak kopia zapasowa nie uchroni cię przed przypadkowym DROP TABLE lub DROP SCHEMA (no, może być niewolnikiem opóźnionej replikacji, ale tylko przez pewien czas). MySQL oferuje wiele metod wykonywania kopii zapasowych - mysqldump, xtrabackup, różne rodzaje migawek (niektóre dostępne tylko z konkretnym sprzętem lub dostawcą chmury). Nie jest łatwo zaprojektować odpowiednią strategię tworzenia kopii zapasowych, zdecydować, jakich narzędzi użyć, a następnie napisać cały proces, aby działał poprawnie. To też nie jest nauka o rakietach i wymaga starannego planowania i testowania. Po wykonaniu kopii zapasowej nie skończysz. Czy na pewno można przywrócić kopię zapasową, a dane nie są śmieciami? Weryfikacja kopii zapasowych jest czasochłonna i być może nie jest najbardziej ekscytującą rzeczą na liście rzeczy do zrobienia. Ale nadal jest to ważne i musi być wykonywane regularnie.
ClusterControl posiada rozbudowaną funkcjonalność tworzenia kopii zapasowych i przywracania. Obsługuje mysqldump do logicznego tworzenia kopii zapasowych i Percona Xtrabackup do fizycznego tworzenia kopii zapasowych - narzędzia te mogą być używane w prawie każdym środowisku, zarówno w chmurze, jak i lokalnie. Możliwe jest zbudowanie strategii tworzenia kopii zapasowych z mieszanką kopii logicznych i fizycznych, przyrostowych lub pełnych, w trybie online.
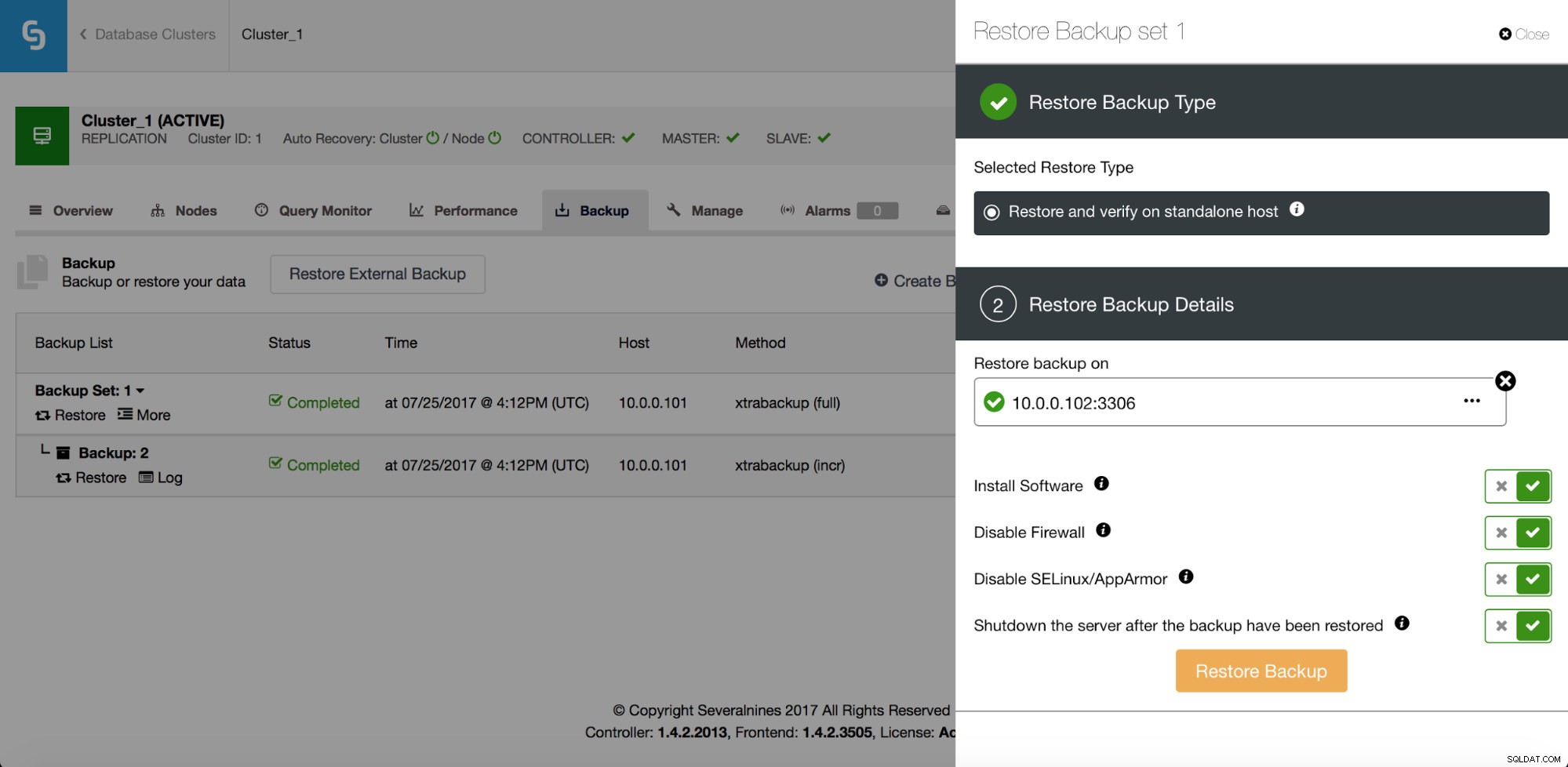
Oprócz odzyskiwania ma również opcje weryfikacji kopii zapasowej - na przykład przywróć ją na oddzielnym hoście, aby sprawdzić, czy proces tworzenia kopii zapasowej działa poprawnie, czy nie.
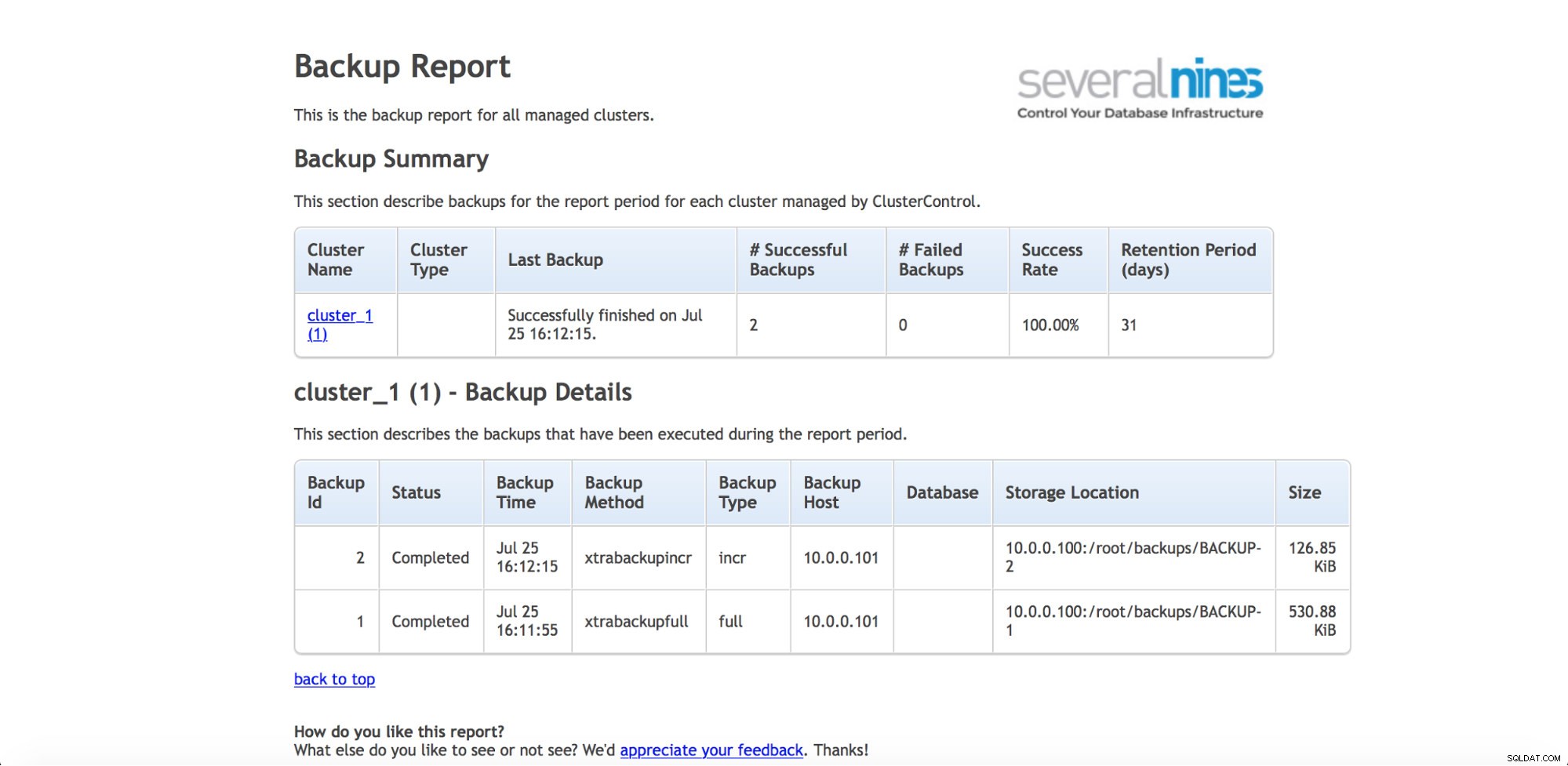
Jeśli chcesz regularnie kontrolować kopie zapasowe (i prawdopodobnie chciałbyś to robić), ClusterControl ma możliwość generowania raportów operacyjnych. Raport kopii zapasowej pomaga śledzić wykonane kopie zapasowe i informuje, czy podczas ich wykonywania wystąpiły jakiekolwiek problemy.
Manynines DevOps Przewodnik po zarządzaniu bazami danychDowiedz się, co musisz wiedzieć, aby zautomatyzować i zarządzać bazami danych typu open sourcePobierz za darmoMonitorowanie i trendy

Żadne wdrożenie nie jest gotowe do produkcji bez odpowiedniego monitorowania usług. Chcesz mieć pewność, że zostaniesz powiadomiony, jeśli niektóre usługi staną się niedostępne, dzięki czemu możesz podjąć działanie, zbadać lub rozpocząć procedury odzyskiwania. Oczywiście chcesz również mieć rozwiązanie zyskujące popularność. Nie można wystarczająco podkreślić, jak ważne jest posiadanie danych z monitoringu do oceny stanu infrastruktury lub do jakiegokolwiek dochodzenia, zarówno pośmiertnego, jak i monitorowania stanu usług w czasie rzeczywistym. Metryki nie są jednakowo ważne – jeśli nie znasz się zbyt dobrze na konkretnym produkcie bazodanowym, najprawdopodobniej nie będziesz wiedział, które są najważniejsze do zebrania i obserwowania. Jasne, możesz być w stanie zebrać wszystko, ale jeśli chodzi o przeglądanie danych, prawie nie jest możliwe przejrzenie setek wskaźników na hosta – musisz wiedzieć, na którym z nich powinieneś się skupić.
Świat open source jest pełen narzędzi zaprojektowanych do monitorowania i zbierania metryk z różnych baz danych - większość z nich wymagałaby zintegrowania ich z ogólną infrastrukturą monitorowania, platformą chatops lub narzędziami wsparcia telefonicznego (np. PagerDuty). Może być również wymagana instalacja i integracja wielu komponentów - przechowywania (jakiś rodzaj bazy danych szeregów czasowych), warstwy prezentacji i narzędzi do gromadzenia danych.
ClusterControl to trochę inne podejście, ponieważ jest to jeden produkt z monitorowaniem w czasie rzeczywistym, trendami i pulpitami nawigacyjnymi, które pokazują najważniejsze szczegóły. Doradcy bazy danych, którymi mogą być dowolne porady dotyczące konfiguracji, ostrzeżenia dotyczące progów lub bardziej złożone reguły dotyczące przewidywań, zazwyczaj generują obszerne zalecenia.
Możliwość skalowania

Bazy danych mają tendencję do powiększania się i nie jest nieprawdopodobne, że zwiększy się pod względem wolumenu transakcji lub liczby użytkowników. Możliwość skalowania w górę lub w górę może mieć kluczowe znaczenie dla produkcji. Nawet jeśli wykonasz świetną robotę w oszacowaniu wymagań sprzętowych na początku cyklu życia produktu, prawdopodobnie będziesz musiał poradzić sobie z fazą wzrostu – o ile Twój produkt odnosi sukcesy (ale to jest to, co wszyscy planujemy, prawda ?). Musisz mieć środki do łatwego skalowania infrastruktury, aby poradzić sobie z przychodzącym obciążeniem. W przypadku usług bezstanowych, takich jak serwery internetowe, jest to dość łatwe — wystarczy udostępnić więcej instancji przy użyciu najnowszego obrazu produkcyjnego lub kodu z narzędzia do kontroli wersji. W przypadku usług stanowych, takich jak bazy danych, jest to trudniejsze. Musisz aprowizować nowe instancje przy użyciu bieżących danych produkcyjnych, skonfigurować replikację lub jakąś formę klastrowania między bieżącą i nową instancją. Może to być złożony proces i aby go dobrze wykonać, musisz mieć bardziej dogłębną wiedzę na temat wybranego modelu klastrowania lub replikacji.
ClusterControl, jak sama nazwa wskazuje, zapewnia szerokie wsparcie dla tworzenia klastrowych lub replikowanych konfiguracji baz danych. Stosowane metody są testowane w boju przez tysiące wdrożeń. Jest wyposażony w interfejs wiersza poleceń (CLI), dzięki czemu można go łatwo zintegrować z systemami zarządzania konfiguracją. Pamiętaj jednak, że możesz nie chcieć zbyt często wprowadzać zmian w swojej puli baz danych — udostępnienie nowej instancji zajmuje trochę czasu i zwiększa obciążenie istniejących baz danych. Dlatego możesz chcieć pozostać po stronie „nadmiernej alokacji”, aby mieć trochę czasu na rozkręcenie nowej instancji, zanim klaster zostanie przeciążony.
Podsumowując, po wstępnym wdrożeniu należy jeszcze wykonać kilka kroków, aby upewnić się, że środowisko jest gotowe do produkcji. Dzięki odpowiednim narzędziom znacznie łatwiej się tam dostać.