Kiedy musisz pracować z bazą danych, której nie znasz w 100%, możesz być przytłoczony setkami dostępnych metryk. Które z nich są najważniejsze? Co powinienem monitorować i dlaczego? Jakie wzorce w metrykach powinny rozbrzmiewać niektórymi dzwonkami alarmowymi? W tym poście na blogu postaramy się przedstawić niektóre z najważniejszych wskaźników, na które należy zwracać uwagę podczas uruchamiania MySQL lub MariaDB w środowisku produkcyjnym.
Liczniki stanu Com_*
Zaczniemy od liczników Com_* - definiują one liczbę i typy zapytań, które wykonuje MySQL. Mówimy tutaj o typach zapytań, takich jak SELECT, INSERT, UPDATE i wielu innych. Bardzo ważne jest, aby mieć je na oku, ponieważ nagłe skoki lub nieoczekiwane spadki mogą sugerować, że coś poszło nie tak w systemie.
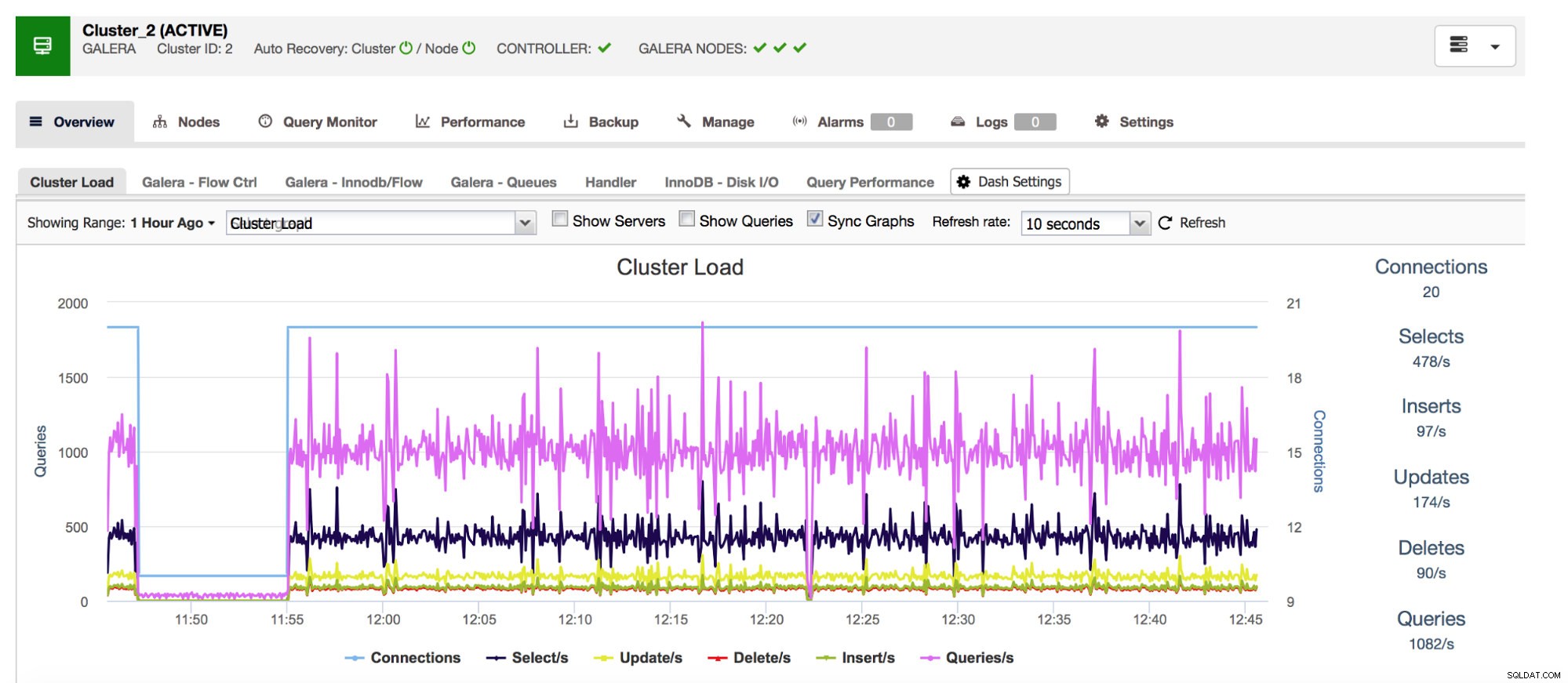
Nasz kompleksowy system zarządzania bazą danych ClusterControl pokazuje te dane związane z najczęstszymi typami zapytań w sekcji „Przegląd”.
Liczniki statusu Handler_*
Kategorią metryk, na którą należy zwracać uwagę, są liczniki Handler_* w MySQL. Liczniki Com_* informują o rodzaju zapytań wykonywanych przez Twoją instancję MySQL, ale jeden SELECT może być zupełnie inny od drugiego - SELECT może być wyszukiwaniem klucza podstawowego, może to być również skanowanie tabeli, jeśli nie można użyć indeksu. Programy obsługi informują, w jaki sposób MySQL uzyskuje dostęp do przechowywanych danych - jest to bardzo przydatne do badania problemów z wydajnością i oceny, czy istnieje możliwość zwiększenia przeglądów zapytań i dodatkowego indeksowania.
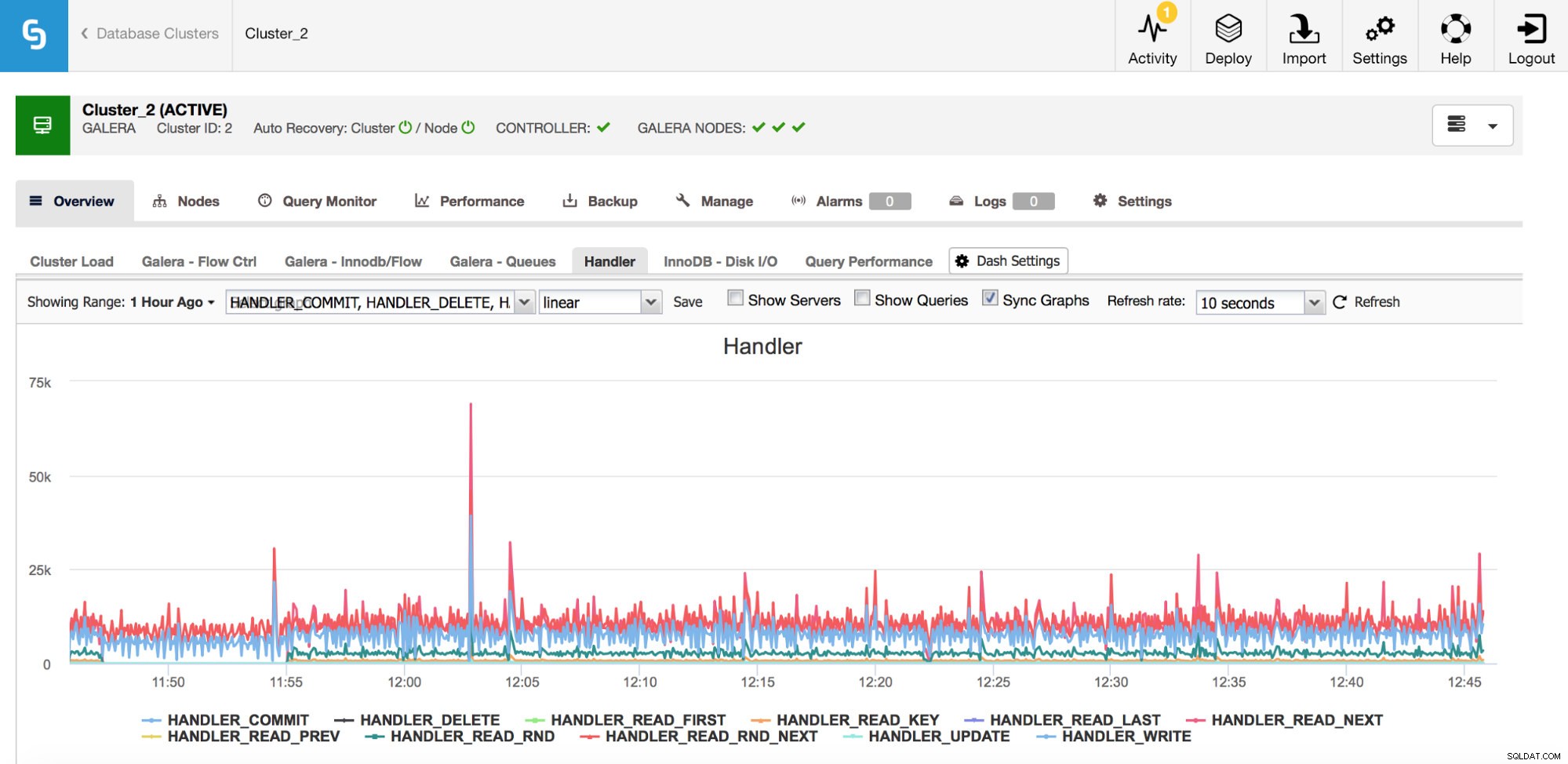
Jak widać na powyższym wykresie, jest wiele metryk do śledzenia (a najważniejsze z nich to wykresy ClusterControl) - nie będziemy ich tutaj omawiać (opis można znaleźć w dokumentacji MySQL), ale chcielibyśmy podkreślić najważniejsze.
Handler_read_rnd_next - za każdym razem, gdy MySQL uzyskuje dostęp do wiersza bez wyszukiwania indeksu, w kolejności sekwencyjnej, licznik ten zostanie zwiększony. Jeśli w Twoim obciążeniu handler_read_rnd_next odpowiada za wysoki procent całego ruchu, oznacza to, że Twoje tabele najprawdopodobniej mogą korzystać z dodatkowych indeksów, ponieważ MySQL wykonuje wiele skanów tabel.
Handler_read_next i handler_read_prev - te dwa liczniki są aktualizowane za każdym razem, gdy MySQL wykonuje skanowanie indeksu - do przodu lub do tyłu. Handler_read_first i handler_read_last mogą rzucić więcej światła na rodzaj skanowania indeksu - jeśli mówimy o pełnym skanowaniu indeksu (do przodu lub do tyłu), te dwa liczniki zostaną zaktualizowane.
Handler_read_key - z drugiej strony ten licznik, jeśli jego wartość jest wysoka, informuje, że twoje tabele są dobrze zindeksowane, ponieważ dostęp do wielu wierszy uzyskano poprzez wyszukiwanie indeksu.
Opóźnienie replikacji
Jeśli pracujesz z replikacją MySQL, opóźnienie replikacji jest metryką, którą zdecydowanie chcesz monitorować. Opóźnienie replikacji jest nieuniknione i będziesz musiał sobie z nim poradzić, ale aby sobie z nim poradzić, musisz zrozumieć, dlaczego tak się dzieje. W tym celu pierwszym krokiem będzie sprawdzenie, _kiedy_ się pojawił.
Za każdym razem, gdy widzisz gwałtowny wzrost opóźnienia replikacji, chciałbyś sprawdzić inne wykresy, aby uzyskać więcej wskazówek — dlaczego tak się stało? Co mogło to spowodować? Przyczyny mogą być różne - długie, ciężkie DML, znaczny wzrost liczby DML wykonywanych w krótkim czasie, ograniczenia procesora lub I/O.
InnoDB we/wy
Istnieje wiele ważnych wskaźników do monitorowania, które są związane z I/O.
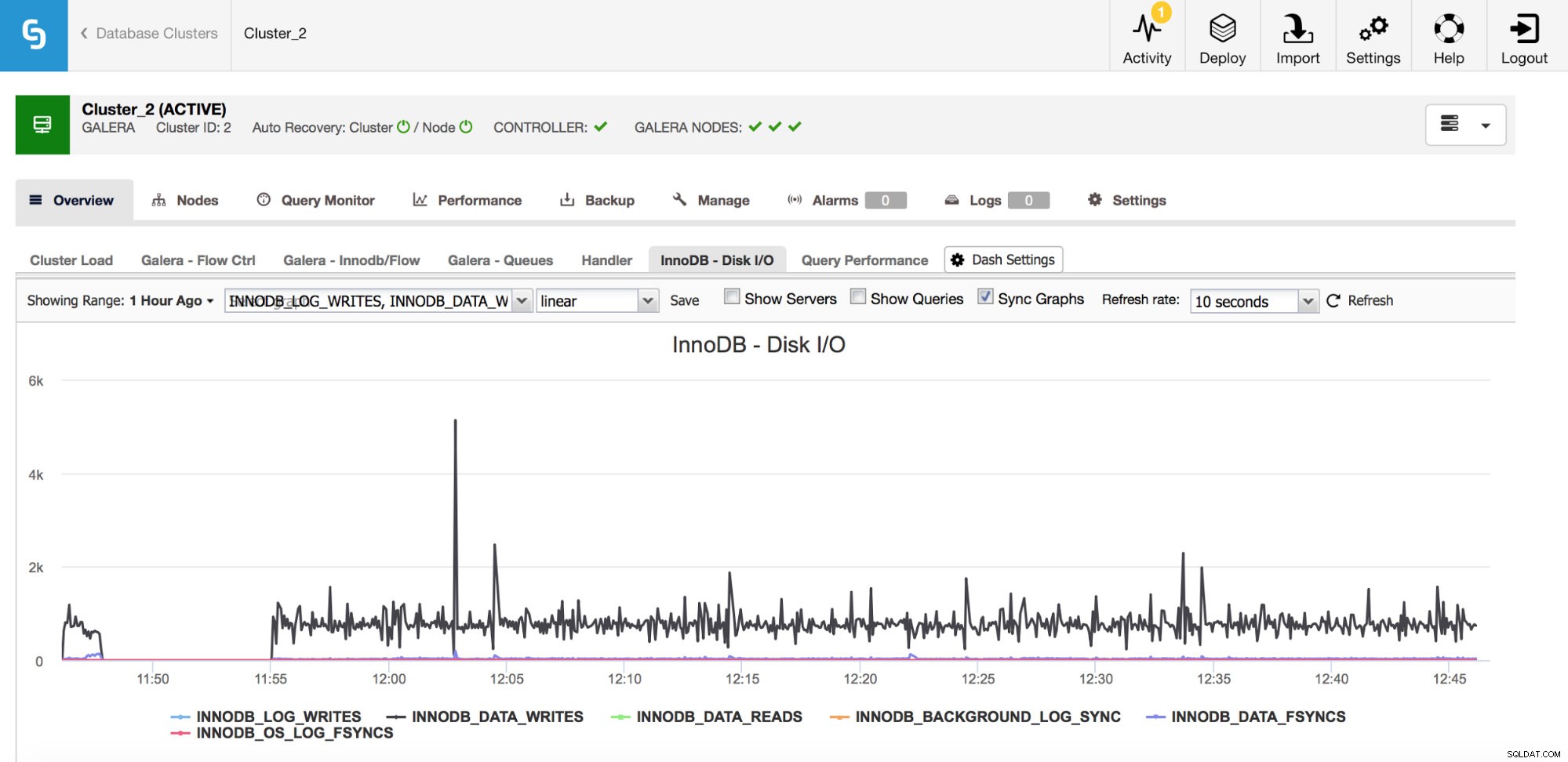
Na powyższym wykresie możesz zobaczyć kilka metryk, które mówią, jaki rodzaj I/O robi InnoDB - zapisy i odczyty danych, ponowne zapisy logów, fsyncs. Te metryki pomogą Ci na przykład zdecydować, czy opóźnienie replikacji było spowodowane wzrostem liczby operacji we/wy, czy może z innego powodu. Ważne jest również, aby śledzić te metryki i porównywać je z ograniczeniami sprzętowymi — jeśli zbliżasz się do ograniczeń sprzętowych swoich dysków, być może nadszedł czas, aby się temu przyjrzeć, zanim będzie to miało bardziej poważny wpływ na wydajność bazy danych.
Manynines DevOps Przewodnik po zarządzaniu bazami danychDowiedz się, co musisz wiedzieć, aby zautomatyzować i zarządzać bazami danych typu open sourcePobierz za darmoGalera Metrics — kontrola przepływu i kolejki
Jeśli zdarzy ci się korzystać z Galera Cluster (bez względu na to, jakiego smaku używasz), jest jeszcze kilka innych wskaźników, które chciałbyś ściśle monitorować, są one nieco ze sobą powiązane. Pierwsza z nich to metryki związane z kontrolą przepływu.
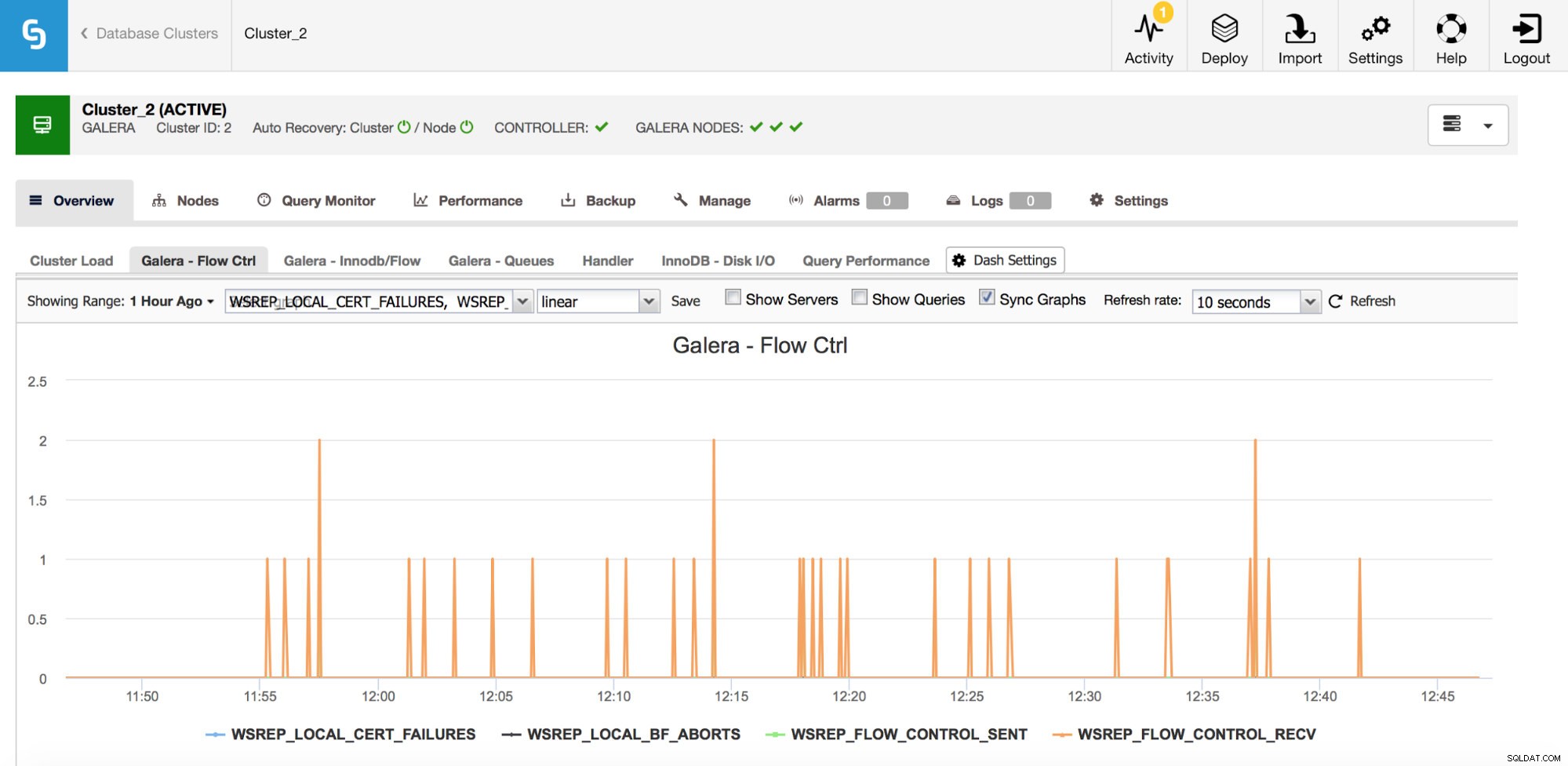
Kontrola przepływu w Galera to sposób na synchronizację klastra. Za każdym razem, gdy węzeł zatrzymuje się i nie może nadążyć za resztą klastra, zaczyna wysyłać komunikaty sterowania przepływem, prosząc pozostałe węzły klastra o spowolnienie. To pozwala mu nadrobić zaległości. Zmniejsza to wydajność klastra, dlatego ważne jest, aby móc określić, który węzeł i kiedy zaczął wysyłać komunikaty kontroli przepływu. Może to wyjaśniać niektóre spowolnienia doświadczane przez użytkowników lub ograniczać okno czasowe i hosta do dalszego badania.
Drugi zestaw wskaźników do monitorowania to te związane z kolejkami wysyłania i odbierania w Galera.
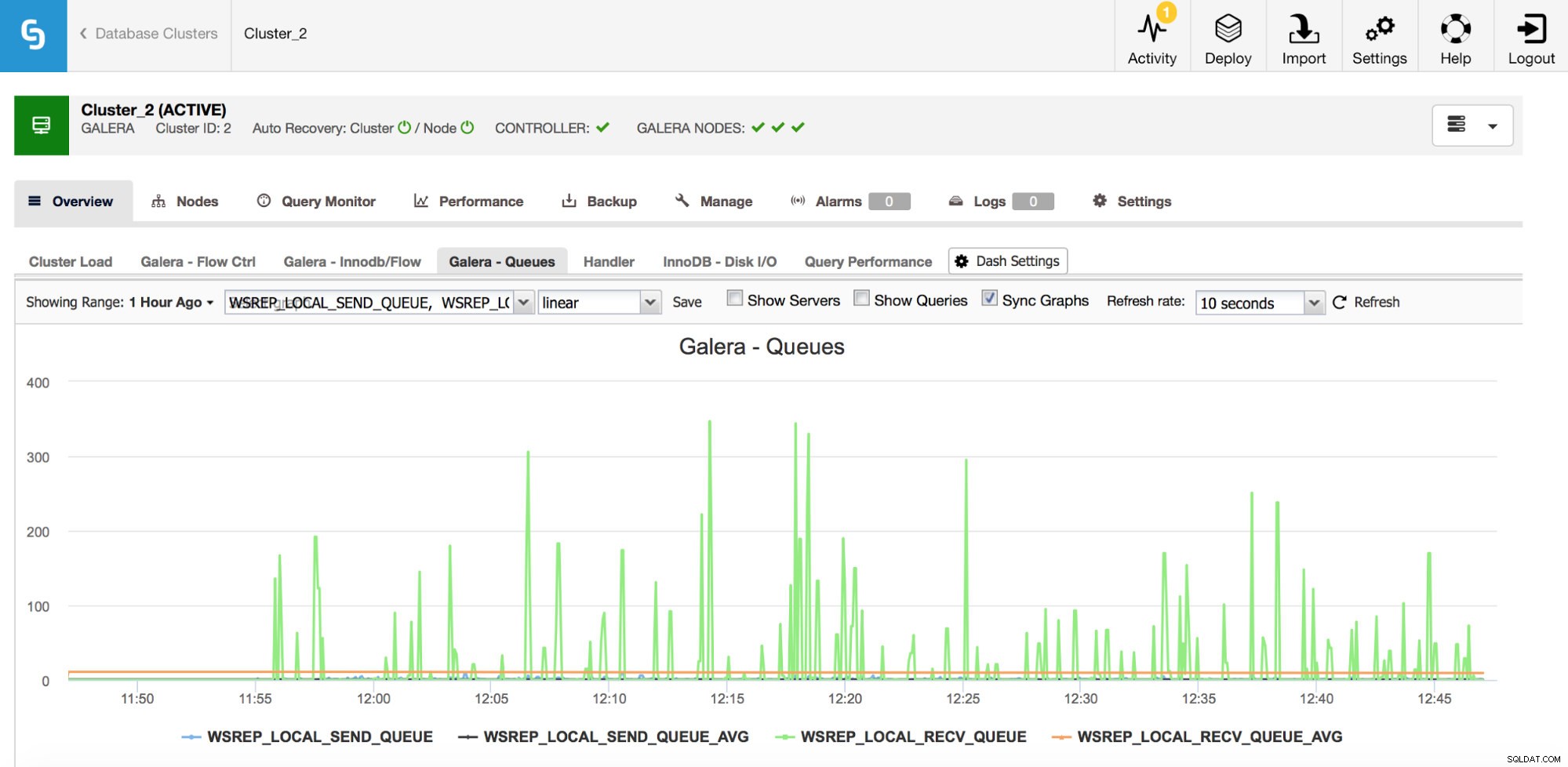
Węzły Galera mogą buforować zestawy zapisów (transakcje), jeśli nie mogą natychmiast zastosować ich wszystkich. W razie potrzeby mogą również buforować zbiory zapisów, które mają zostać wysłane do innych węzłów (jeśli dany węzeł odbiera zapisy z aplikacji). Oba przypadki są objawami spowolnienia, które najprawdopodobniej spowoduje wysłanie komunikatów kontroli przepływu i wymaga pewnego zbadania – dlaczego to się stało, na którym węźle, o której godzinie?
To oczywiście tylko wierzchołek góry lodowej, gdy weźmiemy pod uwagę wszystkie metryki udostępniane przez MySQL – nadal nie możesz się pomylić, jeśli zaczniesz oglądać te, które tutaj omówiliśmy, oprócz zwykłych wskaźników systemu operacyjnego/sprzętu, takich jak procesor , pamięć, wykorzystanie dysku i stan usług.