Minęły prawie dwa miesiące, odkąd wydaliśmy SCUMM (Severalnines ClusterControl Unified Management and Monitoring). SCUMM wykorzystuje Prometheus jako podstawową metodę gromadzenia danych szeregów czasowych od eksporterów działających na instancjach baz danych i systemach równoważenia obciążenia. Ten blog pokaże Ci, jak rozwiązać problemy, gdy eksportery Prometheus nie są uruchomione lub jeśli wykresy nie wyświetlają danych lub nie pokazują „Brak punktów danych”.
Co to jest Prometeusz?
Prometheus to system monitorowania typu open source z wymiarowym modelem danych, elastycznym językiem zapytań, wydajną bazą danych szeregów czasowych i nowoczesnym podejściem do alertów. Jest to platforma monitorująca, która zbiera metryki z monitorowanych celów poprzez zbieranie metryk punktów końcowych HTTP dla tych celów. Zapewnia dane wymiarowe, potężne zapytania, świetną wizualizację, wydajne przechowywanie, prostą obsługę, precyzyjne alerty, wiele bibliotek klienckich i wiele integracji.
Prometheus w akcji dla pulpitów SCUMM
Prometheus zbiera dane metryki od eksporterów, przy czym każdy eksporter działa na bazie danych lub hoście systemu równoważenia obciążenia. Poniższy diagram pokazuje, w jaki sposób eksporterzy są powiązani z serwerem obsługującym proces Prometheus. Pokazuje, że w węźle ClusterControl działa Prometheus, w którym działa również process_exporter i node_exporter.
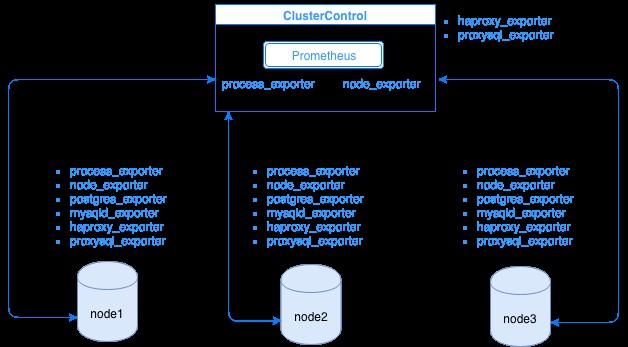
Diagram pokazuje, że Prometheus działa na hoście ClusterControl i eksporterach process_exporter i node_exporter działają również w celu zbierania metryk z własnego węzła. Opcjonalnie możesz ustawić swój host ClusterControl jako cel, w którym możesz skonfigurować HAProxy lub ProxySQL.
W przypadku powyższych węzłów klastra (węzeł1, węzeł2 i węzeł3) może działać mysqld_exporter lub postgres_exporter, które są agentami, które wewnętrznie zgarniają dane w tym węźle i przekazują je do serwera Prometheus i przechowują je we własnym magazynie danych. Możesz zlokalizować jego fizyczne dane poprzez /var/lib/prometheus/data na hoście, na którym skonfigurowany jest Prometheus.
Podczas konfigurowania Prometheusa, na przykład, na hoście ClusterControl, powinien mieć otwarte następujące porty. Zobacz poniżej:
[example@sqldat.com share]# netstat -tnvlp46|egrep 'ex[p]|prometheu[s]'
tcp6 0 0 :::9100 :::* LISTEN 16189/node_exporter
tcp6 0 0 :::9011 :::* LISTEN 19318/process_expor
tcp6 0 0 :::42004 :::* LISTEN 16080/proxysql_expo
tcp6 0 0 :::9090 :::* LISTEN 31856/prometheusW oparciu o dane wyjściowe, mam uruchomiony ProxySQL również na hoście testccnode, w którym hostowany jest ClusterControl.
Typowe problemy z pulpitami nawigacyjnymi SCUMM przy użyciu Prometheusa
Po włączeniu pulpitów nawigacyjnych ClusterControl zainstaluje i wdroży pliki binarne i eksportery, takie jak node_exporter, process_exporter, mysqld_exporter, postgres_exporter i demon. Są to wspólne zestawy pakietów do węzłów bazy danych. Po ich skonfigurowaniu i zainstalowaniu następujące polecenia demona są uruchamiane i uruchamiane, jak pokazano poniżej:
[example@sqldat.com bin]# ps axufww|egrep 'exporte[r]'
prometh+ 3604 0.0 0.0 10828 364 ? S Nov28 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 3605 0.2 0.3 256300 14924 ? Sl Nov28 4:06 \_ process_exporter
prometh+ 3838 0.0 0.0 10828 564 ? S Nov28 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 3839 0.0 0.4 44636 15568 ? Sl Nov28 1:08 \_ node_exporter
prometh+ 4038 0.0 0.0 10828 568 ? S Nov28 0:00 daemon --name=mysqld_exporter --output=/var/log/prometheus/mysqld_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/mysqld_exporter.pid --user=prometheus -- mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_status
prometh+ 4039 0.1 0.2 17368 11544 ? Sl Nov28 1:47 \_ mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_statusW przypadku węzła PostgreSQL
[example@sqldat.com vagrant]# ps axufww|egrep 'ex[p]'
postgres 1901 0.0 0.4 1169024 8904 ? Ss 18:00 0:04 \_ postgres: postgres_exporter postgres ::1(51118) idle
prometh+ 1516 0.0 0.0 10828 360 ? S 18:00 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 1517 0.2 0.7 117032 14636 ? Sl 18:00 0:35 \_ process_exporter
prometh+ 1700 0.0 0.0 10828 572 ? S 18:00 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 1701 0.0 0.7 44380 14932 ? Sl 18:00 0:10 \_ node_exporter
prometh+ 1897 0.0 0.0 10828 568 ? S 18:00 0:00 daemon --name=postgres_exporter --output=/var/log/prometheus/postgres_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --env=DATA_SOURCE_NAME=postgresql://postgres_exporter:example@sqldat.com:5432/postgres?sslmode=disable --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/postgres_exporter.pid --user=prometheus -- postgres_exporter
prometh+ 1898 0.0 0.5 16548 11204 ? Sl 18:00 0:06 \_ postgres_exporterMa te same eksportery, co węzeł MySQL, ale różni się tylko w przypadku postgres_exporter, ponieważ jest to węzeł bazy danych PostgreSQL.
Jednak gdy węzeł dozna przerwy w zasilaniu, awarii systemu lub ponownego uruchomienia systemu, eksporterzy przestaną działać. Prometheus zgłosi, że eksporter nie działa. ClusterControl pobiera próbki samego Prometheusa i pyta o status eksportera. Działa więc na podstawie tych informacji i ponownie uruchamia eksporter, jeśli nie działa.
Należy jednak pamiętać, że eksportery, które nie zostały zainstalowane przez ClusterControl, nie zostaną ponownie uruchomione po awarii. Powodem jest to, że nie są one monitorowane przez systemd lub demona, który działa jak skrypt bezpieczeństwa, który zrestartuje proces po awarii lub nienormalnym zamknięciu. Dlatego poniższy zrzut ekranu pokaże, jak to wygląda, gdy eksporterzy nie działają. Zobacz poniżej:
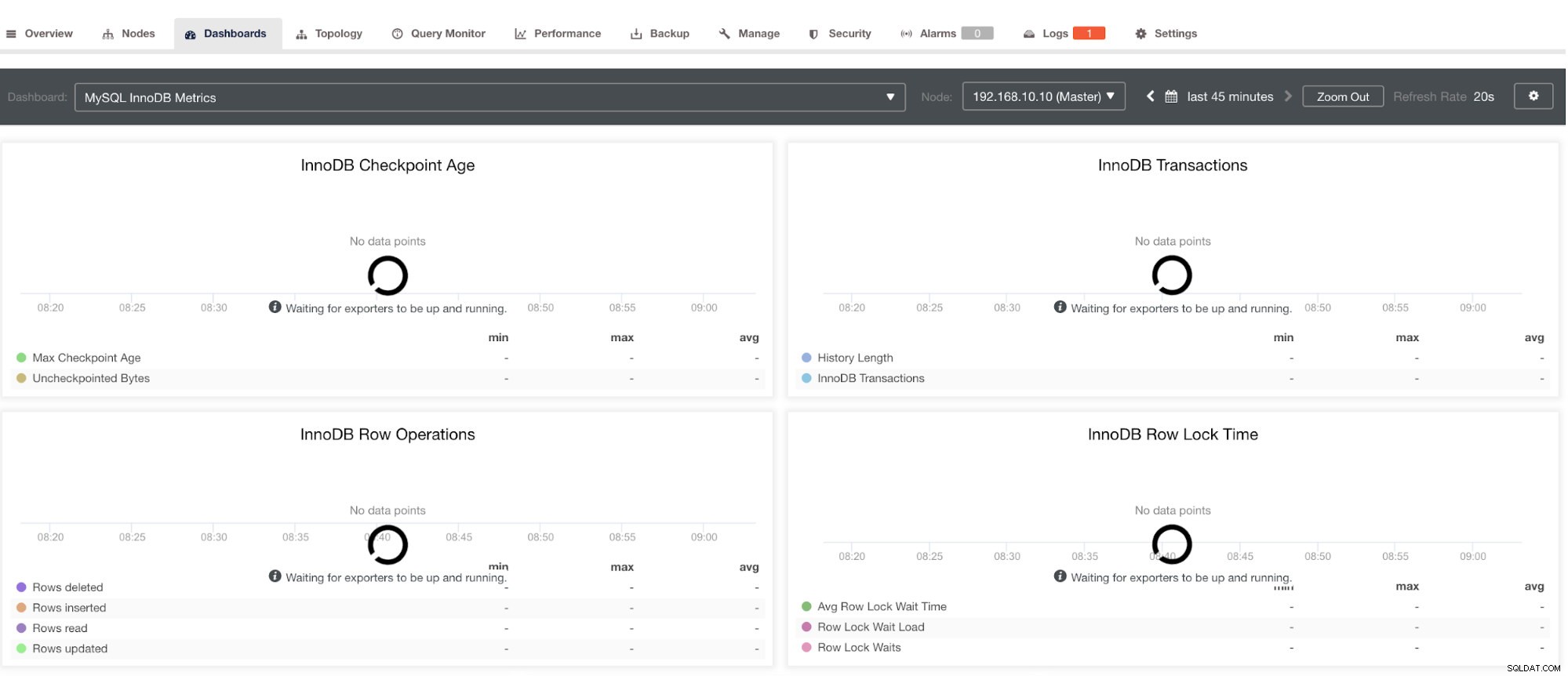
a w PostgreSQL Dashboard będzie miał tę samą ikonę ładowania z etykietą „Brak punktów danych” na wykresie. Zobacz poniżej:
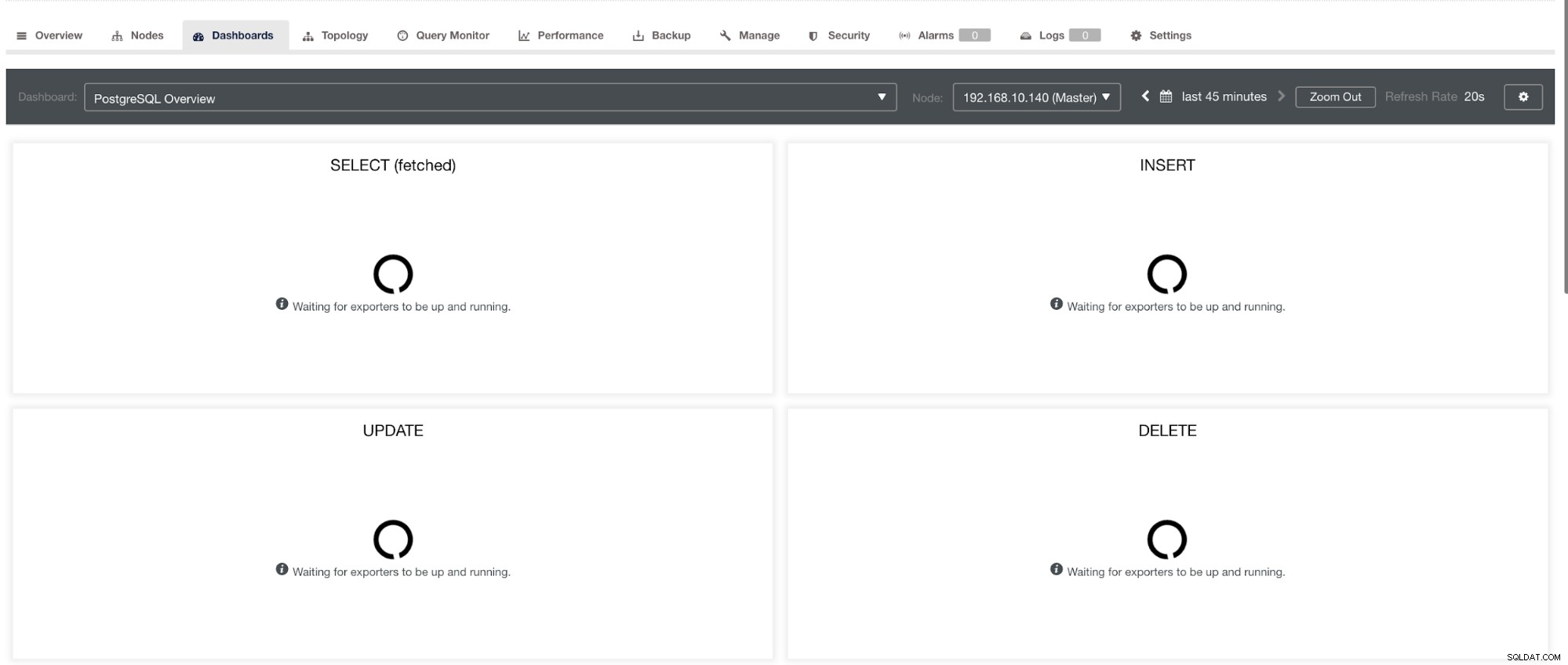
W związku z tym można je rozwiązać za pomocą różnych technik, które zostaną opisane w poniższych sekcjach.
Rozwiązywanie problemów z Prometheusem
Agenci Prometheusa, zwani eksporterami, korzystają z następujących portów:9100 (node_exporter), 9011 (process_exporter), 9187 (postgres_exporter), 9104 (mysqld_exporter), 42004 (proxysql_exporter) oraz własnego 9090, którego właścicielem jest prometeusz proces. To są porty dla tych agentów, które są używane przez ClusterControl.
Aby rozpocząć rozwiązywanie problemów z pulpitem nawigacyjnym SCUMM, możesz zacząć od sprawdzenia portów otwartych z węzła bazy danych. Możesz śledzić poniższe listy:
-
Sprawdź, czy porty są otwarte
np.
## Use netstat and check the ports [example@sqldat.com vagrant]# netstat -tnvlp46|egrep 'ex[p]' tcp6 0 0 :::9100 :::* LISTEN 5036/node_exporter tcp6 0 0 :::9011 :::* LISTEN 4852/process_export tcp6 0 0 :::9187 :::* LISTEN 5230/postgres_exporMoże istnieć możliwość, że porty nie są otwarte z powodu zapory (takiej jak iptables lub firewalld), która blokuje mu otwarcie portu lub sam demon procesu nie działa.
-
Użyj curl z monitora hosta i sprawdź, czy port jest dostępny i otwarty.
np.
## Using curl and grep mysql list of available metric names used in PromQL. [example@sqldat.com prometheus]# curl -sv mariadb_g01:9104/metrics|grep 'mysql'|head -25 * About to connect() to mariadb_g01 port 9104 (#0) * Trying 192.168.10.10... * Connected to mariadb_g01 (192.168.10.10) port 9104 (#0) > GET /metrics HTTP/1.1 > User-Agent: curl/7.29.0 > Host: mariadb_g01:9104 > Accept: */* > < HTTP/1.1 200 OK < Content-Length: 213633 < Content-Type: text/plain; version=0.0.4; charset=utf-8 < Date: Sat, 01 Dec 2018 04:23:21 GMT < { [data not shown] # HELP mysql_binlog_file_number The last binlog file number. # TYPE mysql_binlog_file_number gauge mysql_binlog_file_number 114 # HELP mysql_binlog_files Number of registered binlog files. # TYPE mysql_binlog_files gauge mysql_binlog_files 26 # HELP mysql_binlog_size_bytes Combined size of all registered binlog files. # TYPE mysql_binlog_size_bytes gauge mysql_binlog_size_bytes 8.233181e+06 # HELP mysql_exporter_collector_duration_seconds Collector time duration. # TYPE mysql_exporter_collector_duration_seconds gauge mysql_exporter_collector_duration_seconds{collector="collect.binlog_size"} 0.008825006 mysql_exporter_collector_duration_seconds{collector="collect.global_status"} 0.006489491 mysql_exporter_collector_duration_seconds{collector="collect.global_variables"} 0.00324821 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.innodb_metrics"} 0.008209824 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.processlist"} 0.007524068 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tables"} 0.010236411 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tablestats"} 0.000610684 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.eventswaits"} 0.009132491 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_events"} 0.009235416 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_instances"} 0.009451361 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.indexiowaits"} 0.009568397 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tableiowaits"} 0.008418406 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tablelocks"} 0.008656682 mysql_exporter_collector_duration_seconds{collector="collect.slave_status"} 0.009924652 * Failed writing body (96 != 14480) * Closing connection 0Idealnie byłoby, gdybym praktycznie uznał to podejście za wykonalne, ponieważ mogę łatwo grep i debugować z terminala.
-
Dlaczego nie skorzystać z interfejsu internetowego?
-
Prometheus ujawnia port 9090, który jest używany przez ClusterControl w naszych pulpitach nawigacyjnych SCUMM. Poza tym porty, które ujawniają eksporterzy, mogą być również używane do rozwiązywania problemów i określania dostępnych nazw metryk za pomocą PromQL. Na serwerze, na którym działa Prometheus, możesz odwiedzić https://
:9090/targets . Poniższy zrzut ekranu pokazuje to w akcji: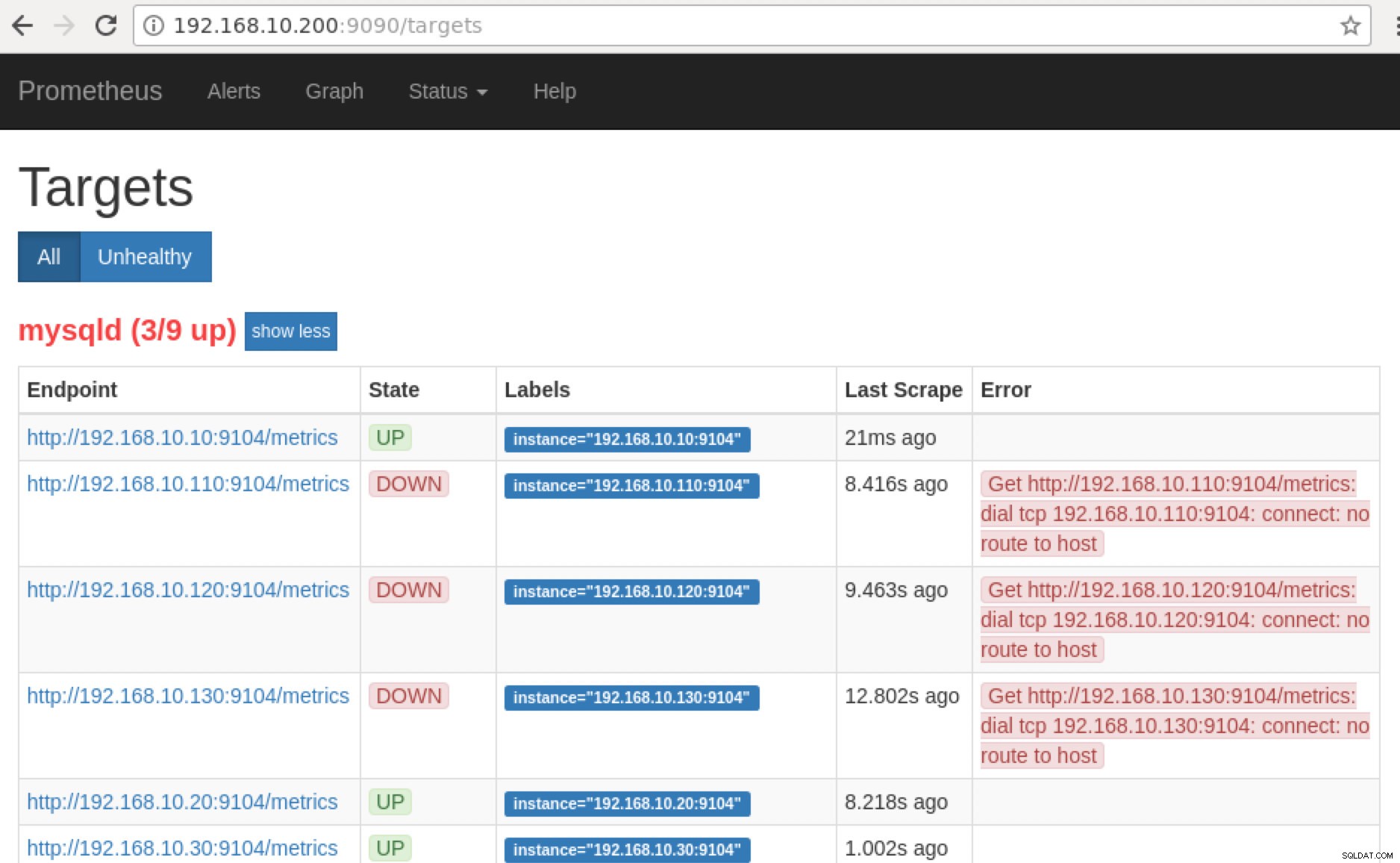
i klikając „Punkty końcowe”, możesz zweryfikować dane tak samo, jak na poniższym zrzucie ekranu:
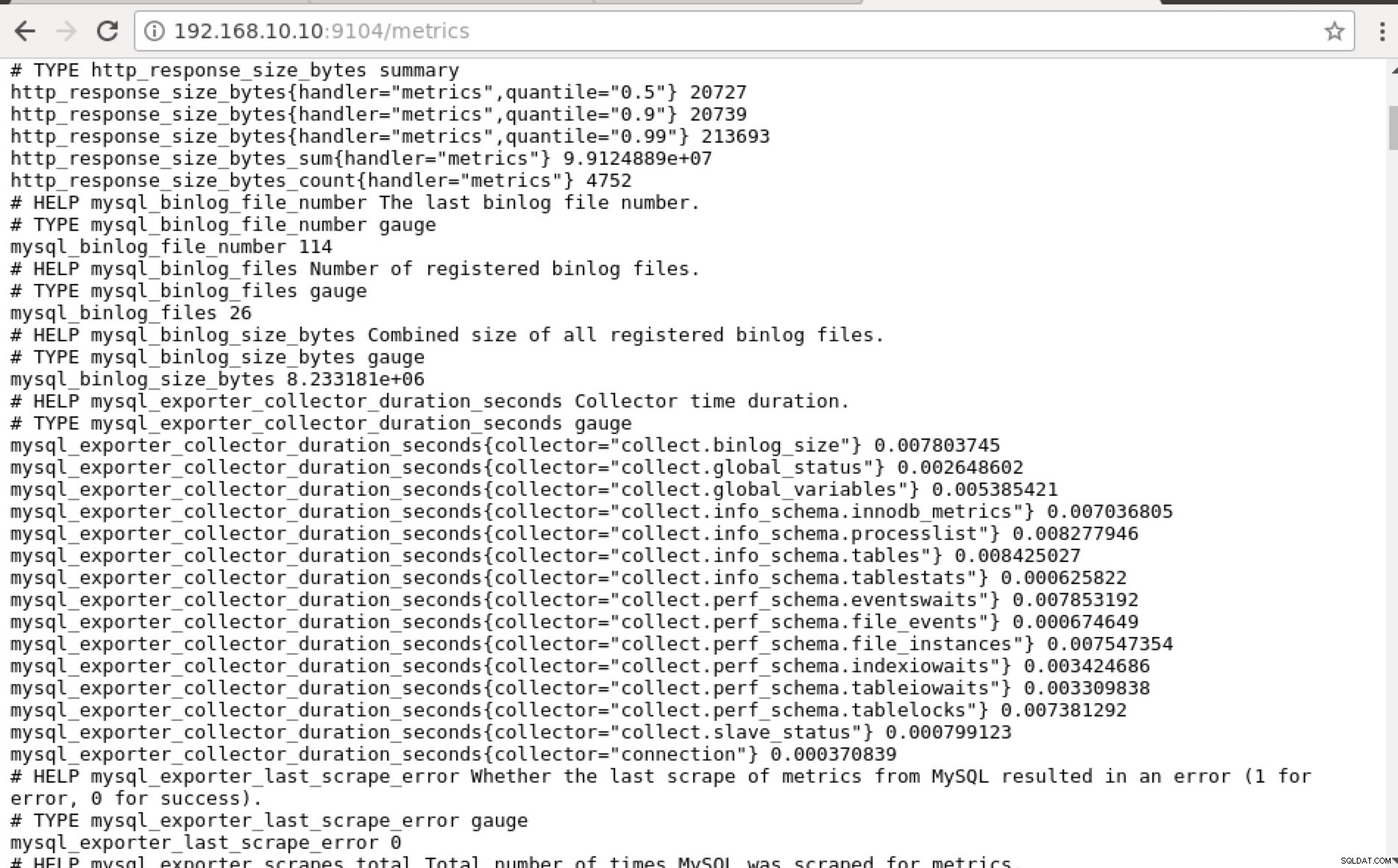
Zamiast używać adresu IP, możesz również sprawdzić to lokalnie przez localhost w tym konkretnym węźle, na przykład odwiedzając https://localhost:9104/metrics w interfejsie WWW lub za pomocą cURL.
Teraz, jeśli wrócimy do „Cele ”, możesz zobaczyć listę węzłów, w których może być problem z portem. Powody, które mogą to spowodować, są wymienione poniżej:
- Serwer nie działa
- Sieć jest nieosiągalna lub porty nie są otwarte z powodu działającej zapory
- Demon nie działa, gdy
_exporter nie pracuje. Na przykład mysqld_exporter nie działa.
-
Gdy te eksportery są uruchomione, możesz uruchomić i uruchomić proces za pomocą demona Komenda. Możesz odwołać się do dostępnych uruchomionych procesów, których użyłem w powyższym przykładzie lub wspomniałem w poprzedniej sekcji tego bloga.
A co z wykresami „brak punktów danych” w moim panelu?
Pulpity nawigacyjne SCUMM zawierają ogólny scenariusz użycia, który jest powszechnie używany przez MySQL. Istnieją jednak pewne zmienne, gdy wywoływanie takich metryk może nie być dostępne w określonej wersji MySQL lub dostawcy MySQL, takim jak MariaDB lub Percona Server.
Pokażę przykład poniżej:
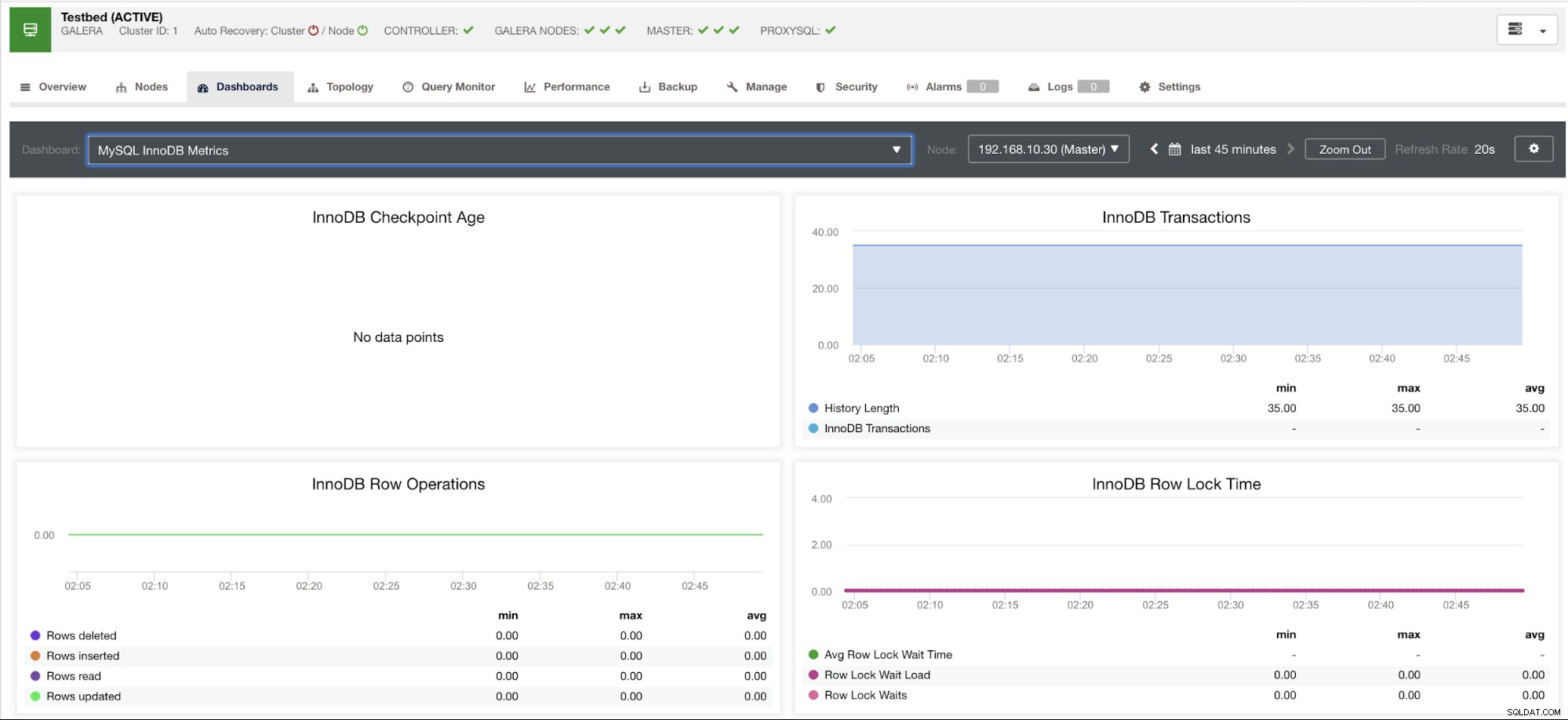
Ten wykres został wykonany na serwerze bazy danych działającym w wersji 10.3.9-MariaDB-log MariaDB Server z wsrep_patch_version instancji wsrep_25.23. Teraz pytanie brzmi, dlaczego nie ładują się żadne punkty danych? Cóż, gdy zapytałem węzeł o status wieku punktu kontrolnego, okazało się, że jest pusty lub nie znaleziono żadnej zmiennej. Zobacz poniżej:
MariaDB [(none)]> show global status like 'Innodb_checkpoint_max_age';
Empty set (0.000 sec)Nie mam pojęcia, dlaczego MariaDB nie ma tej zmiennej (jeśli masz odpowiedź, daj nam znać w sekcji komentarzy na tym blogu). Jest to przeciwieństwo serwera klastrowego Percona XtraDB, w którym istnieje zmienna Innodb_checkpoint_max_age. Zobacz poniżej:
mysql> show global status like 'Innodb_checkpoint_max_age';
+---------------------------+-----------+
| Variable_name | Value |
+---------------------------+-----------+
| Innodb_checkpoint_max_age | 865244898 |
+---------------------------+-----------+
1 row in set (0.00 sec)Oznacza to jednak, że mogą istnieć wykresy, które nie mają zebranych punktów danych, ponieważ nie są zbierane żadne dane dotyczące tej konkretnej metryki podczas wykonywania zapytania Prometheus.
Jednak wykres, który nie zawiera punktów danych, nie oznacza, że Twoja aktualna wersja MySQL lub jego wariant go nie obsługuje. Na przykład, istnieją pewne wykresy, które wymagają pewnych zmiennych, które muszą być odpowiednio skonfigurowane lub włączone.
Poniższa sekcja pokaże, jakie są te wykresy.
Wykres przesuwania stanu indeksu (ICP)

Ten wykres został wspomniany na moim poprzednim blogu. Opiera się na globalnej zmiennej MySQL o nazwie innodb_monitor_enable. Ta zmienna jest dynamiczna, więc możesz ją ustawić bez twardego restartu bazy danych MySQL. Wymaga również innodb_monitor_enable =module_icp lub możesz ustawić tę zmienną globalną na innodb_monitor_enable =all. Zazwyczaj, aby uniknąć takich przypadków i nieporozumień dotyczących tego, dlaczego taki wykres nie pokazuje żadnych punktów danych, być może będziesz musiał używać wszystkich, ale ostrożnie. Gdy ta zmienna jest włączona i ustawiona na wszystko, może wystąpić pewne obciążenie.
Wykresy schematów wydajności MySQL
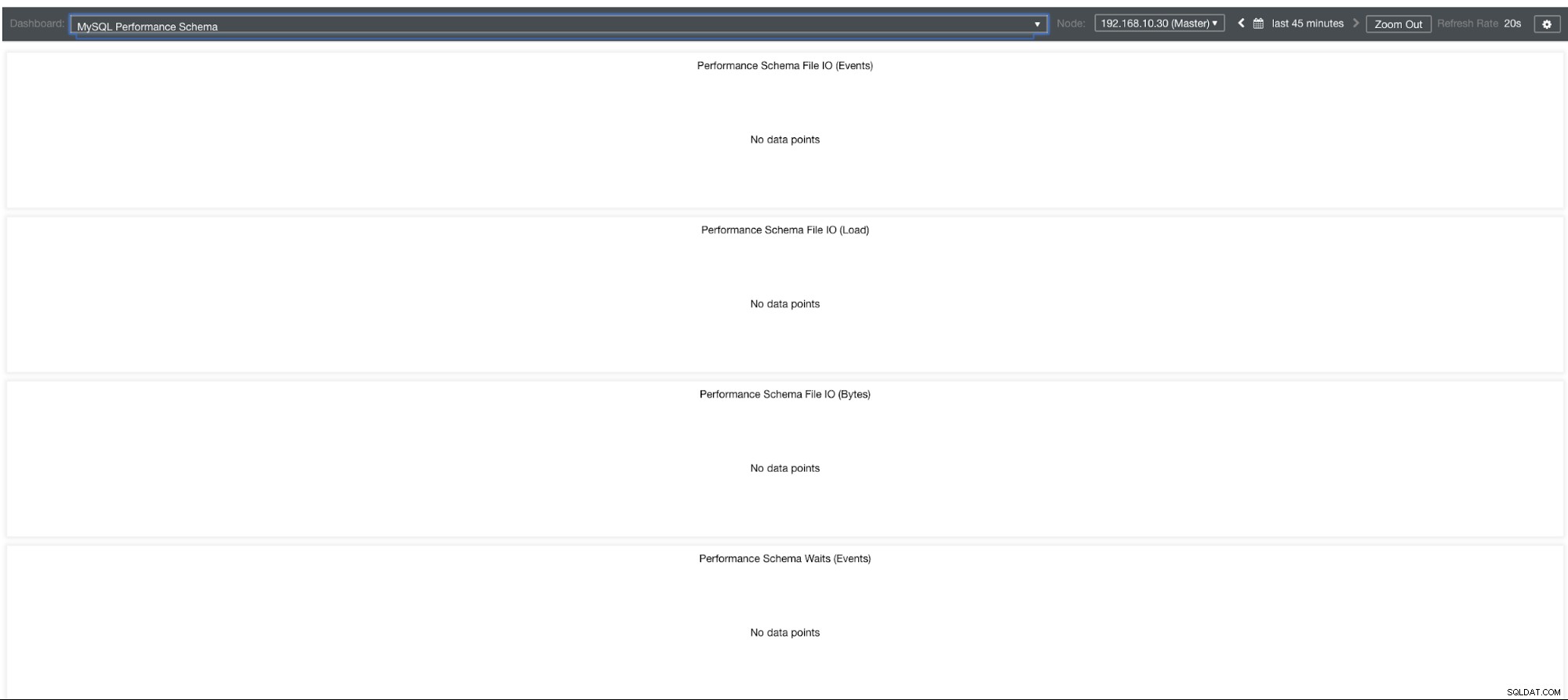
Dlaczego więc te wykresy pokazują „Brak punktów danych”? Kiedy tworzysz klaster za pomocą ClusterControl przy użyciu naszych szablonów, domyślnie definiuje on zmienne performance_schema. Na przykład ustawione są poniższe zmienne:
performance_schema = ON
performance-schema-max-mutex-classes = 0
performance-schema-max-mutex-instances = 0Jeśli jednak performance_schema =OFF, to jest to powód, dla którego powiązane wykresy wyświetlają „Brak punktów danych”.
Ale mam włączony performance_schema, dlaczego inne wykresy nadal stanowią problem?
Cóż, nadal istnieją wykresy, które wymagają ustawienia wielu zmiennych. Zostało to już omówione w naszym poprzednim blogu. Dlatego musisz ustawić innodb_monitor_enable =all i userstat=1. Wynik wyglądałby tak:
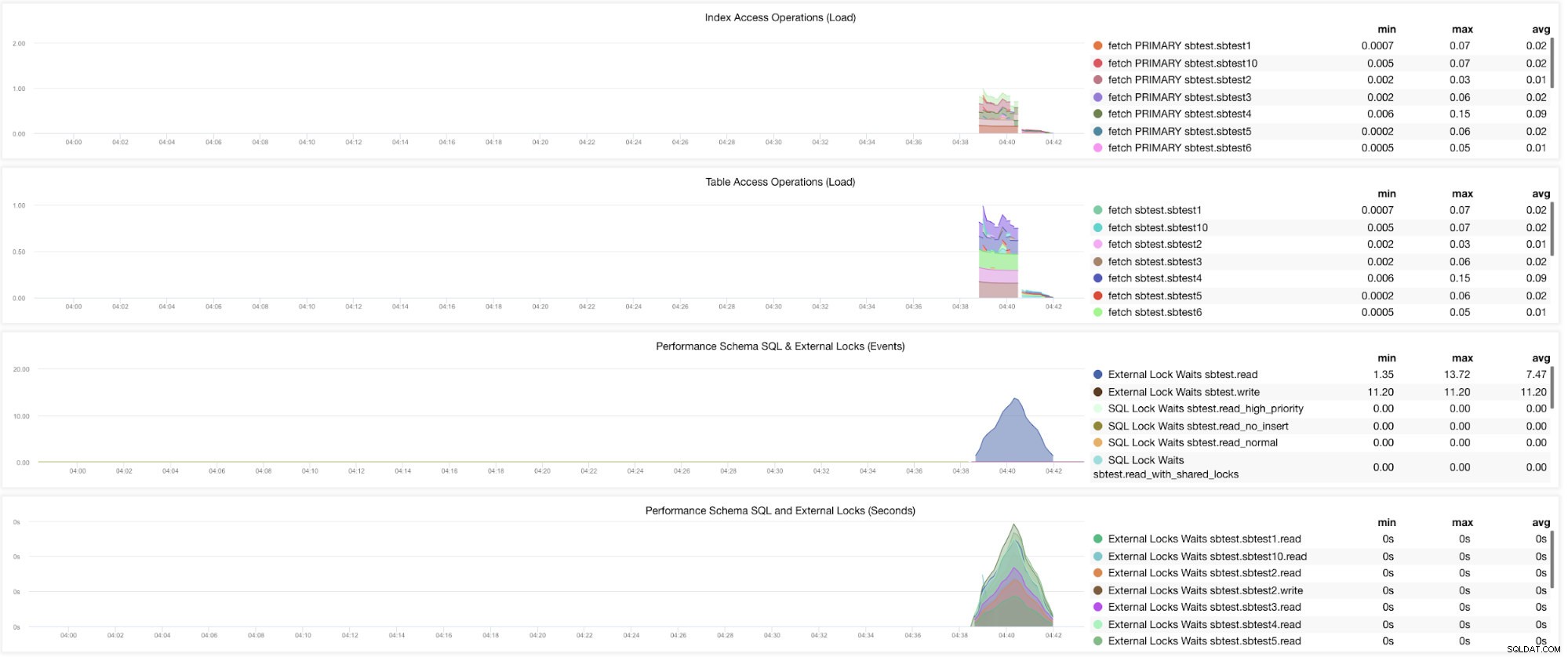
Zauważyłem jednak, że w wersji MariaDB 10.3 (szczególnie 10.3.11) ustawienie performance_schema=ON spowoduje wypełnienie metryk wymaganych dla MySQL Performance Schema Dashboard. Jest to wielka zaleta, ponieważ nie trzeba ustawiać innodb_monitor_enable=ON, co zwiększałoby obciążenie serwera bazy danych.
Zaawansowane rozwiązywanie problemów
Czy mogę polecić jakieś wcześniejsze rozwiązywanie problemów? Tak jest! Jednak potrzebujesz przynajmniej pewnych umiejętności JavaScript. Ponieważ pulpity nawigacyjne SCUMM korzystające z Prometheusa opierają się na wysokich wykresach, sposób, w jaki metryki używane w żądaniach PromQL można określić za pomocą skryptu app.js, który pokazano poniżej:
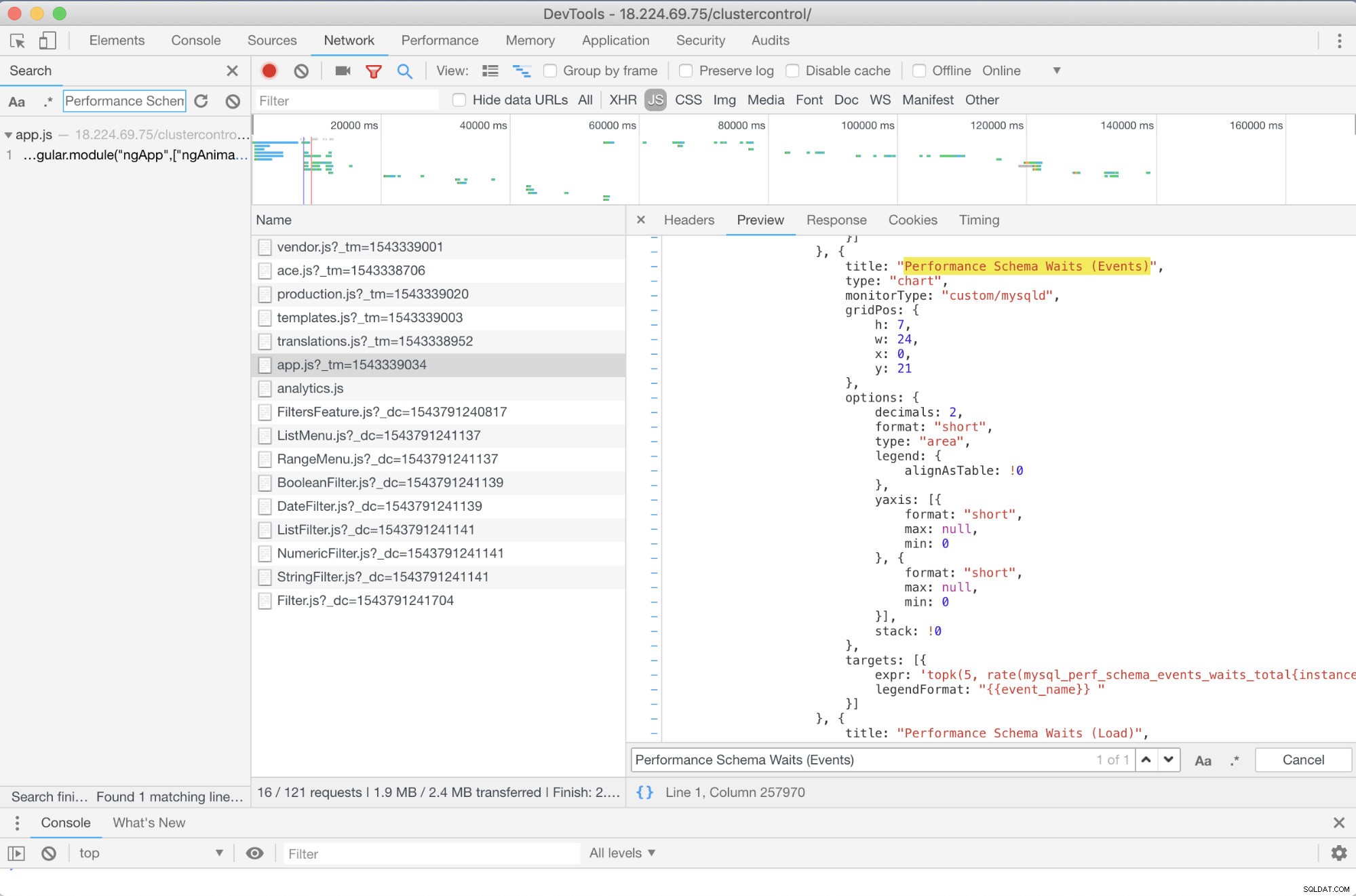
W tym przypadku korzystam z narzędzi Google Chrome DevTools i próbowałem wyszukać Performance Schema Waits (Events) . Jak to może pomóc? Cóż, jeśli spojrzysz na cele, zobaczysz:
targets: [{
expr: 'topk(5, rate(mysql_perf_schema_events_waits_total{instance="$instance"}[$interval])>0) or topk(5, irate(mysql_perf_schema_events_waits_total{instance="$instance"}[5m])>0)',
legendFormat: "{{event_name}} "
}]
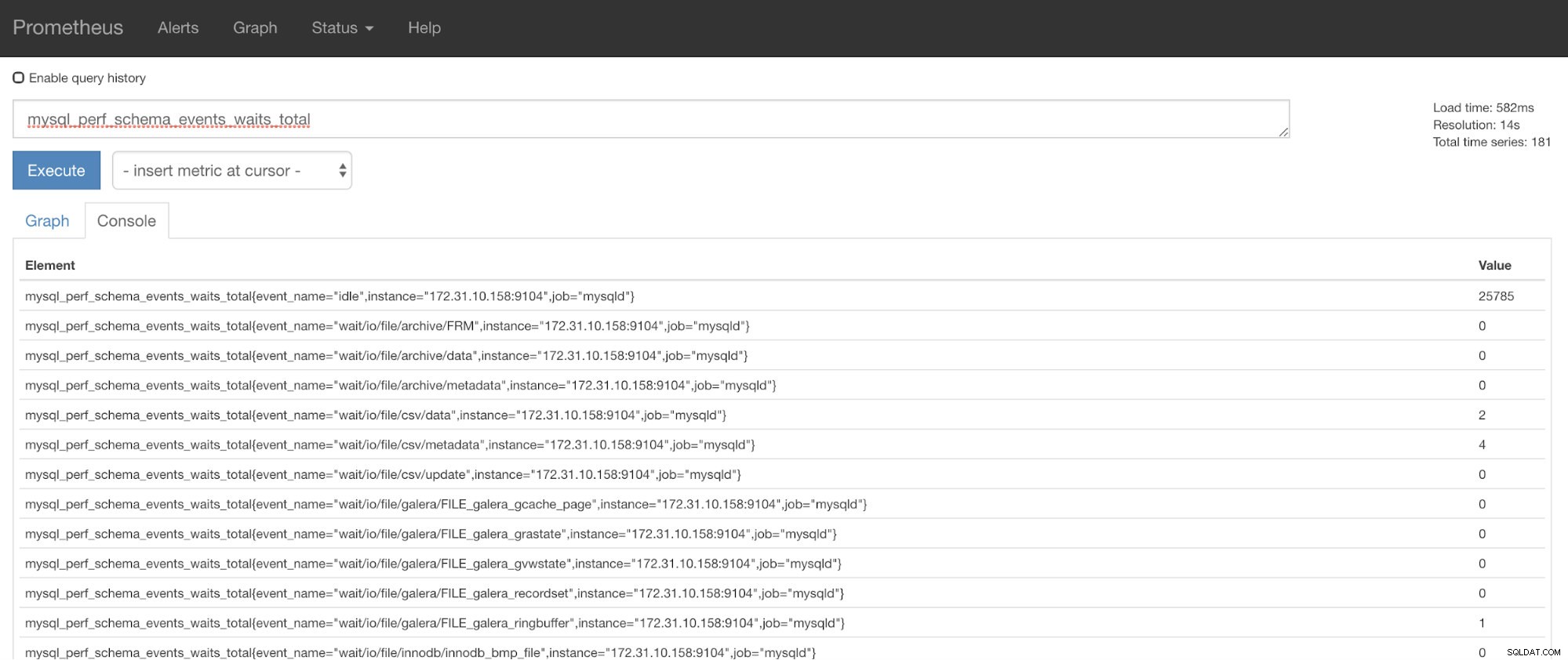
Teraz możesz użyć żądanych metryk, którymi jest mysql_perf_schema_events_waits_total. Możesz to sprawdzić np. przechodząc przez https://
Automatyczne odzyskiwanie ClusterControl na ratunek!
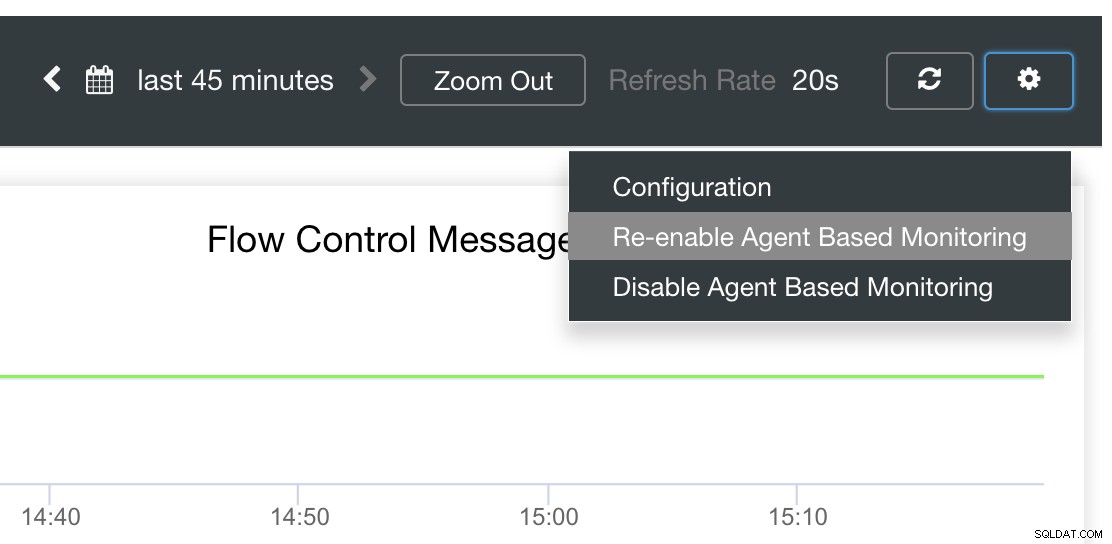
Na koniec, główne pytanie brzmi, czy istnieje łatwy sposób na ponowne uruchomienie nieudanych eksporterów? Tak! Wspomnieliśmy wcześniej, że ClusterControl obserwuje stan eksportu i w razie potrzeby uruchamia go ponownie. Jeśli zauważysz, że pulpity nawigacyjne SCUMM nie ładują wykresów normalnie, upewnij się, że masz włączoną funkcję automatycznego odzyskiwania. Zobacz obrazek poniżej:

Gdy ta opcja jest włączona, zapewni to, że
Możliwa jest również ponowna instalacja lub ponowna konfiguracja eksporterów.
Wniosek
W tym blogu widzieliśmy, jak ClusterControl wykorzystuje Prometheus do oferowania pulpitów nawigacyjnych SCUMM. Zapewnia potężny zestaw funkcji, od danych monitorowania o wysokiej rozdzielczości i bogatych wykresów. Dowiedziałeś się, że dzięki PromQL możesz określić i rozwiązać problemy z naszymi pulpitami nawigacyjnymi SCUMM, które pozwalają agregować dane szeregów czasowych w czasie rzeczywistym. Możesz również generować wykresy lub przeglądać za pomocą konsoli wszystkie zebrane dane.
Nauczyłeś się również, jak debugować nasze pulpity nawigacyjne SCUMM, zwłaszcza gdy nie są gromadzone żadne punkty danych.
Jeśli masz pytania, dodaj swoje komentarze lub daj nam znać za pośrednictwem naszych forów społeczności.