Być może słyszałeś o terminie „failover” w kontekście replikacji MySQL. Może zastanawiałeś się, co to jest, gdy zaczynasz swoją przygodę z bazami danych. Może wiesz, co to jest, ale nie masz pewności, jakie są potencjalne problemy z tym związane i jak można je rozwiązać?
W tym poście na blogu postaramy się przedstawić wprowadzenie do obsługi przełączania awaryjnego w MySQL i MariaDB.
Omówimy, czym jest przełączanie awaryjne, dlaczego jest nieuniknione, jaka jest różnica między przełączaniem awaryjnym a przełączaniem. Omówimy proces przełączania awaryjnego w najbardziej ogólnej formie. Poruszymy również nieco różne kwestie, z którymi będziesz musiał się uporać w związku z procesem przełączania awaryjnego.
Co oznacza „przełączenie awaryjne”?
Replikacja MySQL jest zbiorem węzłów, z których każdy może pełnić jedną rolę na raz. Może stać się mistrzem lub repliką. W danym momencie istnieje tylko jeden węzeł główny. Ten węzeł odbiera ruch związany z zapisem i replikuje zapisy do swoich replik.
Jak możesz sobie wyobrazić, będąc pojedynczym punktem wejścia danych do klastra replikacji, węzeł główny jest dość ważny. Co by się stało, gdyby zawiódł i stał się niedostępny?
To dość poważny warunek dla klastra replikacji. W danym momencie nie może przyjąć żadnych zapisów. Jak można się spodziewać, jedna z replik będzie musiała przejąć zadania mistrza i zacząć przyjmować zapisy. Reszta topologii replikacji może również wymagać zmiany - pozostałe repliki powinny zmienić swój master ze starego, uszkodzonego węzła na nowo wybrany. Ten proces „promowania” repliki na mastera po awarii starego mastera nazywa się „failover”.
Z drugiej strony „przełączenie” następuje, gdy użytkownik uruchomi promocję repliki. Nowy master jest promowany z repliki wskazanej przez użytkownika, a stary master zazwyczaj staje się repliką nowego mastera.
Najważniejszą różnicą między „failover” a „switchover” jest stan starego mastera. Kiedy wykonywane jest przełączanie awaryjne, stary master jest w pewien sposób nieosiągalny. Mogło ulec awarii, mogło dojść do partycjonowania sieci. W danym momencie nie można jej użyć, a jej stan jest zazwyczaj nieznany.
Z drugiej strony, kiedy następuje przełączenie, stary mistrz żyje i ma się dobrze. Ma to poważne konsekwencje. Jeśli master jest nieosiągalny, może to oznaczać, że niektóre dane nie zostały jeszcze wysłane do slaveów (chyba że użyto replikacji półsynchronicznej). Niektóre dane mogły zostać uszkodzone lub częściowo wysłane.
Istnieją mechanizmy zapobiegające rozprzestrzenianiu się takich uszkodzeń na niewolnikach, ale chodzi o to, że niektóre dane mogą zostać utracone w procesie. Z drugiej strony podczas przełączania stary master jest dostępny i zachowana jest spójność danych.
Proces przełączania awaryjnego
Poświęćmy trochę czasu na omówienie, jak dokładnie wygląda proces przełączania awaryjnego.
Wykryto awarię mastera
Na początek, master musi ulec awarii, zanim nastąpi przełączenie awaryjne. Gdy nie jest dostępny, wyzwalane jest przełączanie awaryjne. Jak dotąd wydaje się to proste, ale prawda jest taka, że już jesteśmy na śliskim gruncie.
Przede wszystkim, w jaki sposób testuje się zdrowie mistrza? Czy jest testowany z jednej lokalizacji, czy testy są dystrybuowane? Czy oprogramowanie do zarządzania przełączaniem awaryjnym po prostu próbuje połączyć się z urządzeniem głównym, czy też wdraża bardziej zaawansowane weryfikacje przed zadeklarowaniem awarii urządzenia głównego?
Wyobraźmy sobie następującą topologię:
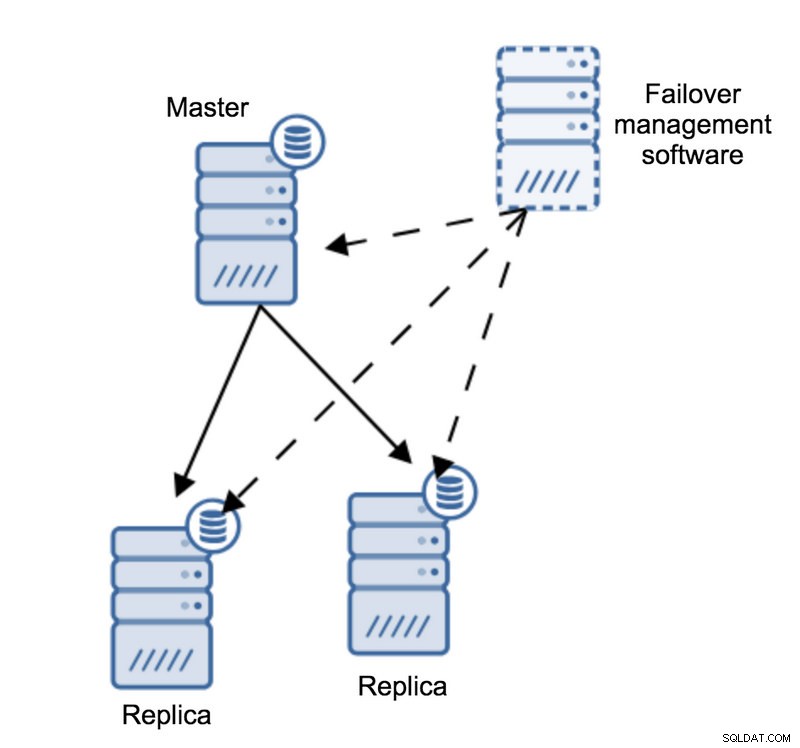
Mamy mistrza i dwie repliki. Posiadamy również oprogramowanie do zarządzania pracą awaryjną zlokalizowane na jakimś zewnętrznym hoście. Co by się stało, gdyby połączenie sieciowe między hostem z oprogramowaniem do przełączania awaryjnego a urządzeniem głównym nie powiodło się?
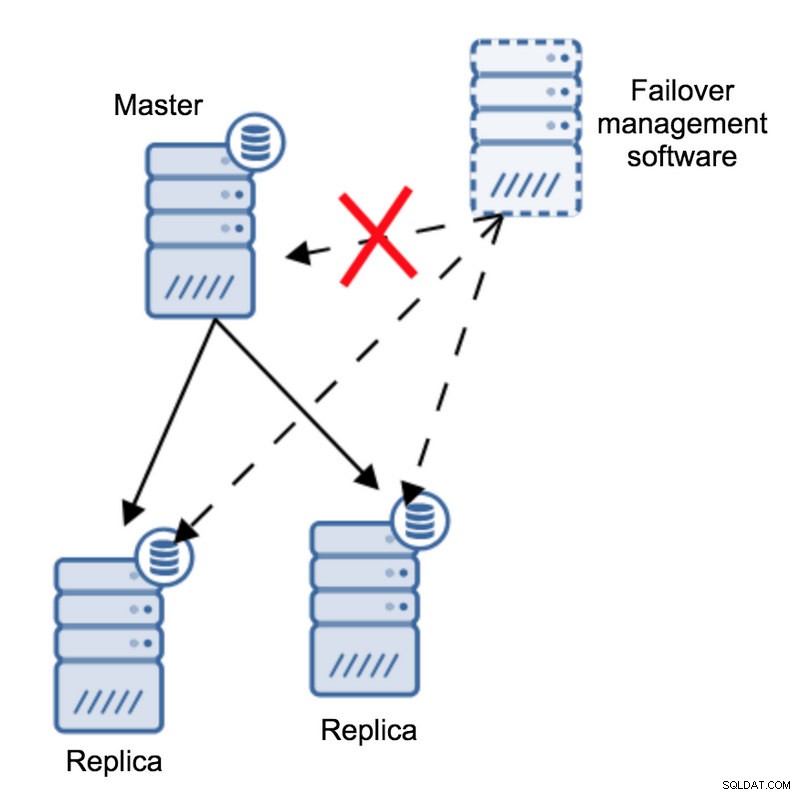
Według oprogramowania do zarządzania przełączaniem awaryjnym, master uległ awarii – nie ma z nim łączności. Mimo to sama replikacja działa dobrze. Powinno się tutaj zdarzyć, że oprogramowanie do zarządzania pracą awaryjną spróbuje połączyć się z replikami i zobaczyć, jaki jest ich punkt widzenia.
Czy narzekają na zepsutą replikację, czy też radośnie się replikują?
Sprawy mogą stać się jeszcze bardziej złożone. Co by było, gdybyśmy dodali proxy (lub zestaw proxy)? Będzie używany do kierowania ruchu - zapisuje do mastera i odczytuje do replik. Co się stanie, jeśli serwer proxy nie może uzyskać dostępu do mastera? Co się stanie, jeśli żaden z serwerów proxy nie ma dostępu do mastera?
Oznacza to, że aplikacja nie może działać w tych warunkach. Czy należy wyzwolić przełączenie awaryjne (w rzeczywistości byłoby to bardziej przełączenie, ponieważ technicznie urządzenie główne jest aktywne)?
Technicznie rzecz biorąc, mistrz żyje, ale nie może być używany przez aplikację. Tutaj musi wkroczyć logika biznesowa i należy podjąć decyzję.
Uniemożliwianie staremu mistrzowi biegania
Bez względu na to, jak i dlaczego, jeśli zostanie podjęta decyzja o promowaniu jednej z replik na nowy master, stary master musi zostać zatrzymany, a najlepiej, aby nie mógł zostać uruchomiony ponownie.
Sposób, w jaki można to osiągnąć, zależy od szczegółów konkretnego środowiska; dlatego ta część procesu przełączania awaryjnego jest zwykle wzmacniana przez zewnętrzne skrypty zintegrowane z procesem przełączania awaryjnego za pomocą różnych punktów zaczepienia.
Skrypty te można zaprojektować tak, aby wykorzystywały narzędzia dostępne w danym środowisku do zatrzymania starego mistrza. Może to być wywołanie CLI lub API, które zatrzyma maszynę wirtualną; może to być kod powłoki, który uruchamia polecenia za pomocą jakiegoś urządzenia „zarządzającego wyłączaniem świateł”; może to być skrypt, który wysyła pułapki SNMP do jednostki dystrybucji zasilania, które wyłączają gniazda zasilania używane przez stary master (bez zasilania elektrycznego możemy być pewni, że nie uruchomi się ponownie).
Jeśli oprogramowanie do zarządzania przełączaniem awaryjnym jest częścią bardziej złożonego produktu, który obsługuje również odzyskiwanie węzłów (tak jak w przypadku ClusterControl), stary system główny może zostać oznaczony jako wyłączony z procedur odzyskiwania.
Być może zastanawiasz się, dlaczego tak ważne jest, aby stary mistrz nie był ponownie dostępny?
Głównym problemem jest to, że w konfiguracjach replikacji tylko jeden węzeł może być używany do zapisu. Zazwyczaj zapewniasz to przez włączenie zmiennej tylko do odczytu (i super_tylko do odczytu, jeśli ma to zastosowanie) we wszystkich replikach i pozostawienie jej wyłączonej tylko w urządzeniu głównym.
Gdy nowy master zostanie wypromowany, zostanie wyłączony tylko do odczytu. Problem polega na tym, że jeśli stary master jest niedostępny, nie możemy przełączyć go z powrotem na read_only=1. Jeśli MySQL lub host ulegnie awarii, nie stanowi to większego problemu, ponieważ dobrymi praktykami jest skonfigurowanie my.cnf z tym ustawieniem, więc po uruchomieniu MySQL zawsze uruchamia się on w trybie tylko do odczytu.
Problem pojawia się, gdy nie jest to awaria, ale problem z siecią. Stary master nadal działa z wyłączoną opcją read_only, po prostu nie jest dostępny. Kiedy sieci się zbiegają, otrzymasz dwa węzły z możliwością zapisu. Może to stanowić problem, ale nie musi. Niektóre serwery proxy używają ustawienia tylko do odczytu jako wskaźnika, czy węzeł jest nadrzędnym czy repliką. Pojawienie się dwóch masterów w danym momencie może spowodować ogromny problem, ponieważ dane są zapisywane na obu hostach, ale repliki otrzymują tylko połowę ruchu związanego z zapisem (część, która trafia do nowego mastera).
Czasami chodzi o zakodowane ustawienia w niektórych skryptach, które są skonfigurowane do łączenia się tylko z danym hostem. Normalnie by im się to nie udało i ktoś zauważyłby, że mistrz się zmienił.
Gdy stary mistrz będzie dostępny, z radością się z nim połączą i pojawią się rozbieżności w danych. Jak widać, upewnienie się, że stary mistrz się nie uruchomi, jest kwestią o wysokim priorytecie.
Wybierz głównego kandydata
Stary mistrz nie żyje i nie wróci z grobu, teraz czas zdecydować, którego hosta powinniśmy użyć jako nowego mistrza. Zazwyczaj do wyboru jest więcej niż jedna replika, więc trzeba podjąć decyzję. Istnieje wiele powodów, dla których jedna replika może zostać wybrana zamiast innej, dlatego należy przeprowadzić kontrole.
Białe i czarne listy
Na początek zespół zarządzający bazami danych może mieć swoje powody, aby wybrać jedną replikę zamiast innej, decydując o kandydatu na mistrza. Może używa słabszego sprzętu lub ma przydzielone jakieś konkretne zadanie (że replika wykonuje backup, zapytania analityczne, programiści mają do niego dostęp i uruchamiają niestandardowe, własnoręcznie tworzone zapytania). Może jest to replika testowa, w której nowa wersja przechodzi testy akceptacyjne przed przystąpieniem do aktualizacji. Większość oprogramowania do zarządzania przełączaniem awaryjnym obsługuje białe i czarne listy, które można wykorzystać do precyzyjnego określenia, które repliki powinny lub nie mogą być używane jako kandydaci nadrzędni.
Replikacja półsynchroniczna
Konfiguracja replikacji może być kombinacją replik asynchronicznych i półsynchronicznych. Jest między nimi ogromna różnica – replika semisynchroniczna gwarantuje, że pomieści wszystkie wydarzenia z mistrza. Replika asynchroniczna mogła nie odebrać wszystkich danych, dlatego przełączenie na nią może spowodować utratę danych. Wolelibyśmy raczej promować repliki półsynchroniczne.
Opóźnienie replikacji
Mimo że replika półsynchroniczna będzie zawierać wszystkie zdarzenia, zdarzenia te mogą nadal znajdować się tylko w dziennikach przekazywania. Przy dużym natężeniu ruchu wszystkie repliki, niezależnie od tego, czy są zsynchronizowane częściowo, czy asynchronicznie, mogą mieć opóźnienia.
Problem z opóźnieniem replikacji polega na tym, że promując replikę, należy zresetować ustawienia replikacji, aby nie próbowała połączyć się ze starym wzorcem. Spowoduje to również usunięcie wszystkich dzienników przekaźników, nawet jeśli nie zostały jeszcze zastosowane – co prowadzi do utraty danych.
Nawet jeśli nie zresetujesz ustawień replikacji, nadal nie będziesz mógł otworzyć nowego mastera dla połączeń, jeśli nie zastosował on wszystkich zdarzeń ze swojego dziennika przekazywania. W przeciwnym razie ryzykujesz, że nowe zapytania wpłyną na transakcje z dziennika przekaźnika, powodując różnego rodzaju problemy (na przykład aplikacja może usunąć niektóre wiersze, do których uzyskują dostęp transakcje z dziennika przekaźnika).
Biorąc to wszystko pod uwagę, jedyną bezpieczną opcją jest oczekiwanie na zastosowanie dziennika przekaźnika. Mimo to może minąć trochę czasu, jeśli replika mocno się opóźnia. Należy podjąć decyzje, która replika byłaby lepszym masterem — asynchroniczna, ale z małym opóźnieniem lub półsynchroniczna, ale z opóźnieniem, którego zastosowanie wymagałoby znacznej ilości czasu.
Błędne transakcje
Nawet jeśli nie należy pisać do replik, nadal może się zdarzyć, że ktoś (lub coś) do nich napisał.
W przeszłości mogła to być tylko pojedyncza transakcja, ale nadal może mieć poważny wpływ na możliwość wykonania przełączenia awaryjnego. Problem jest ściśle związany z globalnym identyfikatorem transakcji (GTID), funkcją, która przypisuje odrębny identyfikator do każdej transakcji wykonanej na danym węźle MySQL.
Obecnie jest to dość popularna konfiguracja, ponieważ zapewnia wysoki poziom elastyczności i pozwala na lepszą wydajność (z replikami wielowątkowymi).
Problem polega na tym, że podczas ponownego podporządkowania do nowego mastera replikacja GTID wymaga, aby wszystkie zdarzenia z tego mastera (które nie zostały wykonane w replice) zostały zreplikowane do repliki.
Rozważmy następujący scenariusz:w pewnym momencie w przeszłości na replice miał miejsce zapis. To było dawno temu i to zdarzenie zostało usunięte z dzienników binarnych repliki. W pewnym momencie master uległ awarii i replika została wyznaczona jako nowy master. Wszystkie pozostałe repliki zostaną podporządkowane nowemu masterowi. Zapytają o transakcje wykonane na nowym wzorcu. W odpowiedzi wyświetli listę identyfikatorów GTID, które pochodzą od starego wzorca i pojedynczego identyfikatora GTID związanego z tym starym zapisem. Identyfikatory GTID ze starego mastera nie stanowią problemu, ponieważ wszystkie pozostałe repliki zawierają przynajmniej większość z nich (jeśli nie wszystkie), a wszystkie brakujące zdarzenia powinny być na tyle aktualne, aby były dostępne w dziennikach binarnych nowego mastera.
W najgorszym przypadku niektóre brakujące zdarzenia zostaną odczytane z dzienników binarnych i przeniesione do replik. Problem jest z tym starym zapisem - zdarzyło się to tylko na nowym masterze, gdy był to jeszcze replika, więc nie istnieje na pozostałych hostach. Jest to stare zdarzenie, dlatego nie ma możliwości odzyskania go z dzienników binarnych. W rezultacie żadna z replik nie będzie w stanie podporządkować sobie nowego mastera. Jedynym rozwiązaniem jest wykonanie ręcznej akcji i wstrzyknięcie pustego zdarzenia z tym problematycznym identyfikatorem GTID we wszystkich replikach. Oznacza to również, że w zależności od tego, co się stało, repliki mogą nie być zsynchronizowane z nowym wzorcem.
Jak widać, bardzo ważne jest śledzenie błędnych transakcji i ustalenie, czy można bezpiecznie promować daną replikę na nowego mastera. Jeśli zawiera błędne transakcje, może nie być najlepszą opcją.
Obsługa przełączania awaryjnego aplikacji
Należy pamiętać, że wyłącznik główny, wymuszony lub nie, ma wpływ na całą topologię. Zapisy muszą być przekierowane do nowego węzła. Można to zrobić na wiele sposobów i bardzo ważne jest, aby ta zmiana była jak najbardziej przejrzysta dla aplikacji. W tej sekcji przyjrzymy się niektórym przykładom, w jaki sposób przełączanie awaryjne może być przezroczyste dla aplikacji.
DNS
Jednym ze sposobów wskazywania aplikacji na mastera jest wykorzystanie wpisów DNS. Przy niskim TTL możliwa jest zmiana adresu IP, na który wskazuje wpis DNS, taki jak „master.dc1.example.com”. Taka zmiana może zostać wykonana za pomocą zewnętrznych skryptów wykonywanych podczas procesu przełączania awaryjnego.
Wykrywanie usług
Narzędzia takie jak Consul lub etc.d mogą być również używane do kierowania ruchu do właściwej lokalizacji. Takie narzędzia mogą zawierać informację, że adres IP aktualnego mastera jest ustawiony na pewną wartość. Niektóre z nich dają również możliwość korzystania z wyszukiwania nazw hostów w celu wskazania prawidłowego adresu IP. Ponownie, wpisy w narzędziach do wykrywania usług muszą być utrzymywane, a jednym ze sposobów na to jest wprowadzenie tych zmian podczas procesu przełączania awaryjnego, przy użyciu zaczepów wykonywanych na różnych etapach przełączania awaryjnego.
Prokurent
Proxy mogą być również wykorzystywane jako źródło prawdy o topologii. Ogólnie rzecz biorąc, bez względu na to, jak odkryją topologię (może to być proces automatyczny lub serwer proxy musi zostać ponownie skonfigurowany po zmianie topologii), powinny one zawierać aktualny stan łańcucha replikacji, ponieważ w przeciwnym razie nie byłyby w stanie kieruj zapytania poprawnie.
Podejście polegające na użyciu serwera proxy jako źródła prawdy może być dość powszechne w połączeniu z podejściem do kolokacji serwerów proxy na hostach aplikacji. Istnieje wiele zalet kolokacji serwerów proxy i serwerów WWW:szybka i bezpieczna komunikacja za pomocą gniazda Unix, utrzymywanie warstwy buforowania (ponieważ niektóre proxy, takie jak ProxySQL, mogą również wykonywać buforowanie) blisko aplikacji. W takim przypadku sensowne jest, aby aplikacja po prostu połączyła się z serwerem proxy i założyła, że będzie prawidłowo kierować zapytania.
Przełączanie awaryjne w ClusterControl
ClusterControl stosuje najlepsze praktyki branżowe, aby upewnić się, że proces przełączania awaryjnego jest wykonywany prawidłowo. Zapewnia również bezpieczeństwo procesu — ustawienia domyślne mają na celu przerwanie przełączania awaryjnego w przypadku wykrycia ewentualnych problemów. Te ustawienia mogą zostać nadpisane przez użytkownika, jeśli chce nadać priorytet przełączaniu awaryjnemu nad bezpieczeństwem danych.
Po wykryciu awarii głównej przez ClusterControl inicjowany jest proces przełączania awaryjnego i natychmiast wykonywane jest pierwsze przełączenie awaryjne:

Następnie testowana jest dostępność urządzenia głównego.

ClusterControl przeprowadza szeroko zakrojone testy, aby upewnić się, że master jest rzeczywiście niedostępny. To zachowanie jest domyślnie włączone i zarządzane przez następującą zmienną:
replication_check_external_bf_failover
Before attempting a failover, perform extended checks by checking the slave status to detect if the master is truly down, and also check if ProxySQL (if installed) can still see the master. If the master is detected to be functioning, then no failover will be performed. Default is 1 meaning the checks are enabled.W kolejnym kroku ClusterControl zapewnia, że stary master jest wyłączony, a jeśli nie, to ClusterControl nie będzie próbował go odzyskać:

Następnym krokiem jest określenie, który host może być używany jako główny kandydat. ClusterControl sprawdza, czy zdefiniowano białą lub czarną listę.
Możesz to zrobić, używając następujących zmiennych w pliku konfiguracyjnym cmon:
replication_failover_blacklist
Comma separated list of hostname:port pairs. Blacklisted servers will not be considered as a candidate during failover. replication_failover_blacklist is ignored if replication_failover_whitelist is set.replication_failover_whitelist
Comma separated list of hostname:port pairs. Only whitelisted servers will be considered as a candidate during failover. If no server on the whitelist is available (up/connected) the failover will fail. replication_failover_blacklist is ignored if replication_failover_whitelist is set.Możliwe jest również skonfigurowanie ClusterControl do wyszukiwania różnic w filtrach dzienników binarnych we wszystkich replikach. Można to zrobić za pomocą zmiennej replication_check_binlog_filtration_bf_failover. Domyślnie te sprawdzenia są wyłączone. ClusterControl sprawdza również, czy nie ma błędnych transakcji, które mogłyby powodować problemy.

Możesz również poprosić ClusterControl o automatyczne odbudowanie replik, które nie mogą być replikowane z nowego mastera, używając następującego ustawienia w pliku konfiguracyjnym cmon:
* replication_auto_rebuild_slave:
If the SQL THREAD is stopped and error code is non-zero then the slave will be automatically rebuilt. 1 means enable, 0 means disable (default).
Następnie wykonywany jest drugi skrypt:jest zdefiniowany w ustawieniu replication_pre_failover_script. Następnie kandydat przechodzi proces przygotowania.


ClusterControl czeka na zastosowanie dzienników ponawiania (upewniając się, że utrata danych jest minimalna). Sprawdza również, czy są dostępne inne transakcje na pozostałych replikach, które nie zostały zastosowane do kandydata na mistrza. Oba zachowania mogą być kontrolowane przez użytkownika za pomocą następujących ustawień w pliku konfiguracyjnym cmon:
replication_skip_apply_missing_txs
Force failover/switchover by skipping applying transactions from other slaves. Default disabled. 1 means enabled.replication_failover_wait_to_apply_timeout
Candidate waits up to this many seconds to apply outstanding relay log (retrieved_gtids) before failing over. Default -1 seconds (wait forever). 0 means failover immediately.Jak widać, możesz wymusić przełączenie awaryjne, nawet jeśli nie wszystkie zdarzenia dziennika ponownego wykonania zostały zastosowane - pozwala to użytkownikowi zdecydować, co ma wyższy priorytet - spójność danych lub szybkość przełączania.


Na koniec wybierany jest master i wykonywany jest ostatni skrypt (skrypt, który można zdefiniować jako replication_post_failover_script.
Jeśli jeszcze nie próbowałeś ClusterControl, zachęcam do pobrania go (jest bezpłatny) i wypróbowania go.
Wykrywanie nadrzędne w ClusterControl
ClusterControl daje możliwość wdrożenia pełnego stosu wysokiej dostępności, w tym warstw bazy danych i proxy. Odkrywanie mistrzów jest zawsze jednym z problemów, z którymi trzeba się uporać.
Jak to działa w ClusterControl?
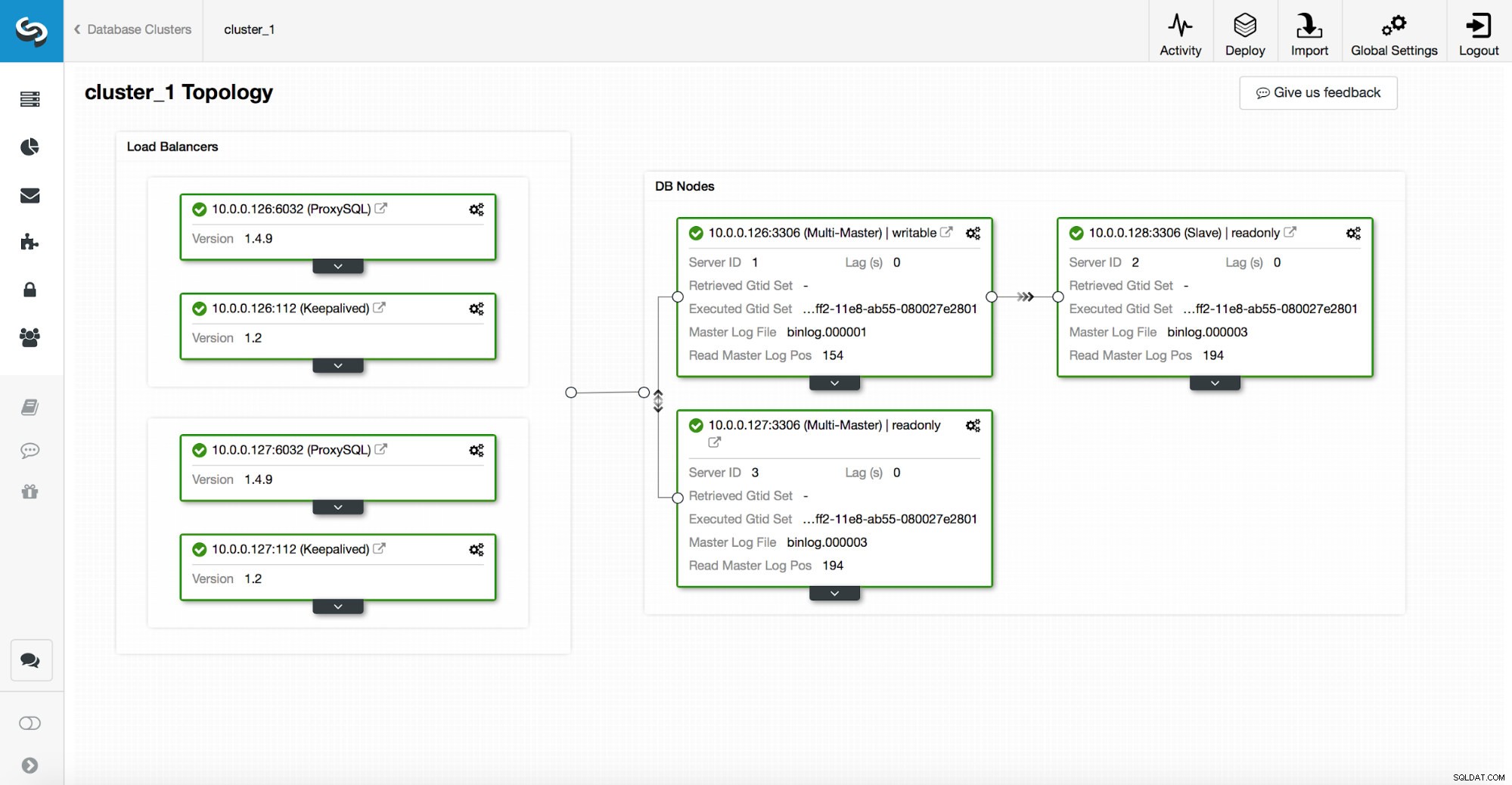
Stos wysokiej dostępności, wdrażany za pośrednictwem ClusterControl, składa się z trzech elementów:
- warstwa bazy danych
- warstwa proxy, która może być HAProxy lub ProxySQL
- warstwa utrzymywana, która przy użyciu wirtualnego adresu IP zapewnia wysoką dostępność warstwy proxy
Serwery proxy opierają się na zmiennych tylko do odczytu w węzłach.
Jak widać na powyższym zrzucie ekranu, tylko jeden węzeł w topologii jest oznaczony jako „zapisywalny”. To jest master i jest to jedyny węzeł, który otrzyma zapisy.
Proxy (w tym przykładzie ProxySQL) będzie monitorować tę zmienną i automatycznie się skonfiguruje.
Po drugiej stronie tego równania, ClusterControl zajmuje się zmianami topologii:przełączaniem awaryjnym i przełączaniem. Wprowadzi niezbędne zmiany w wartości tylko do odczytu, aby odzwierciedlić stan topologii po zmianie. Jeśli nowy master zostanie wypromowany, stanie się jedynym węzłem do zapisu. Jeśli master zostanie wybrany po przełączeniu awaryjnym, zostanie wyłączony tylko do odczytu.
Na wierzchu warstwy proxy wdrażany jest keepalived. Wdraża VIP i monitoruje stan podstawowych węzłów proxy. VIP wskazuje na jeden węzeł proxy w określonym czasie. Jeśli ten węzeł ulegnie awarii, wirtualny adres IP zostanie przekierowany do innego węzła, zapewniając, że ruch skierowany do VIP dotrze do sprawnego węzła proxy.
Podsumowując, aplikacja łączy się z bazą danych za pomocą wirtualnego adresu IP. Ten adres IP wskazuje na jeden z serwerów proxy. Serwery proxy przekierowują ruch zgodnie ze strukturą topologii. Informacje o topologii pochodzą ze stanu tylko do odczytu. Ta zmienna jest zarządzana przez ClusterControl i jest ustawiana na podstawie zmian topologii żądanych przez użytkownika lub ClusterControl przeprowadzanych automatycznie.