Systemy równoważenia obciążenia są niezbędnym elementem każdej konfiguracji bazy danych o wysokiej dostępności. Służą do zwiększania wydajności i niezawodności krytycznych systemów i aplikacji, zapobiegając przeciążeniu jednego serwera. Dużo o nich mówimy na blogu Severalnines, np. dlaczego ich potrzebujesz i jak działają. Jednym z najpopularniejszych systemów równoważenia obciążenia dostępnych dla MySQL i MariaDB jest HAProxy.
Pod względem funkcji HAProxy nie jest porównywalny z ProxySQL czy MaxScale. Jednak HAProxy jest szybkim, niezawodnym systemem równoważenia obciążenia, który będzie działał doskonale w każdym środowisku, o ile aplikacja może wykonać podział odczytu/zapisu i wysyłać zapytania SELECT do jednego zaplecza, a wszystkie zapisy i polecenia SELECT...FOR UPDATE do oddzielnego backend.
Monitorowanie wszystkich metryk udostępnianych przez HAProxy jest bardzo ważne; musisz znać stan swojego serwera proxy, a zwłaszcza wiedzieć, czy napotkałeś jakiekolwiek problemy.
ClusterControl zawsze udostępniał stronę stanu HAProxy pokazującą stan proxy w czasie rzeczywistym. Teraz, dzięki nowym pulpitom nawigacyjnym SCUMM (Severalnines ClusterControl Unified Monitoring &Management) opartym na Prometheusie, można łatwo śledzić, jak te wskaźniki zmieniają się w czasie.
W tym poście na blogu omówimy różne wskaźniki prezentowane na pulpicie nawigacyjnym HAProxy SCUMM.
Eksplorowanie pulpitu nawigacyjnego HAProxy w ClusterControl
Wszystkie pulpity nawigacyjne Prometheus i SCUMM są domyślnie wyłączone w ClusterControl. Jednak wdrożenie ich dla dowolnego klastra to tylko kwestia jednego kliknięcia. Jeśli monitorujesz wiele klastrów za pomocą ClusterControl, możesz ponownie użyć tej samej instancji Prometheus dla każdego klastra.
Po wdrożeniu możesz uzyskać dostęp do pulpitu nawigacyjnego HAProxy. Rzućmy okiem na dane dostępne w panelu:
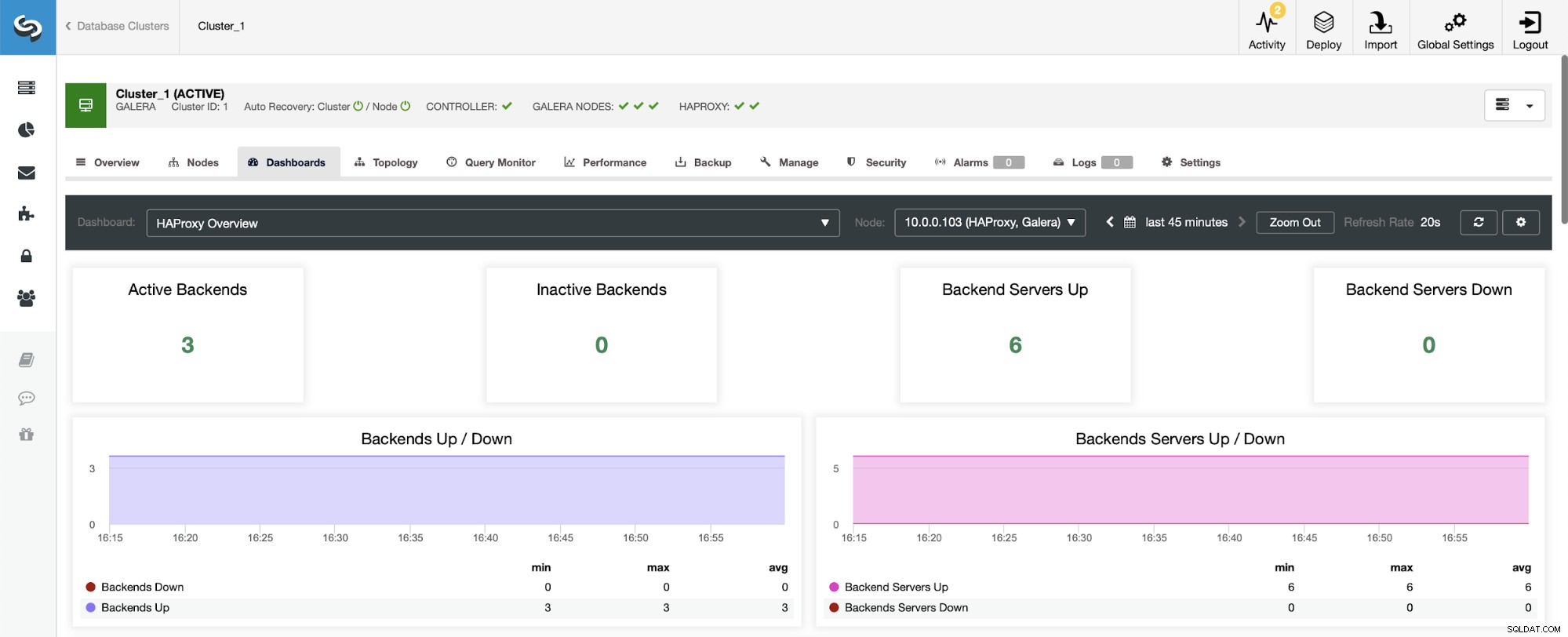
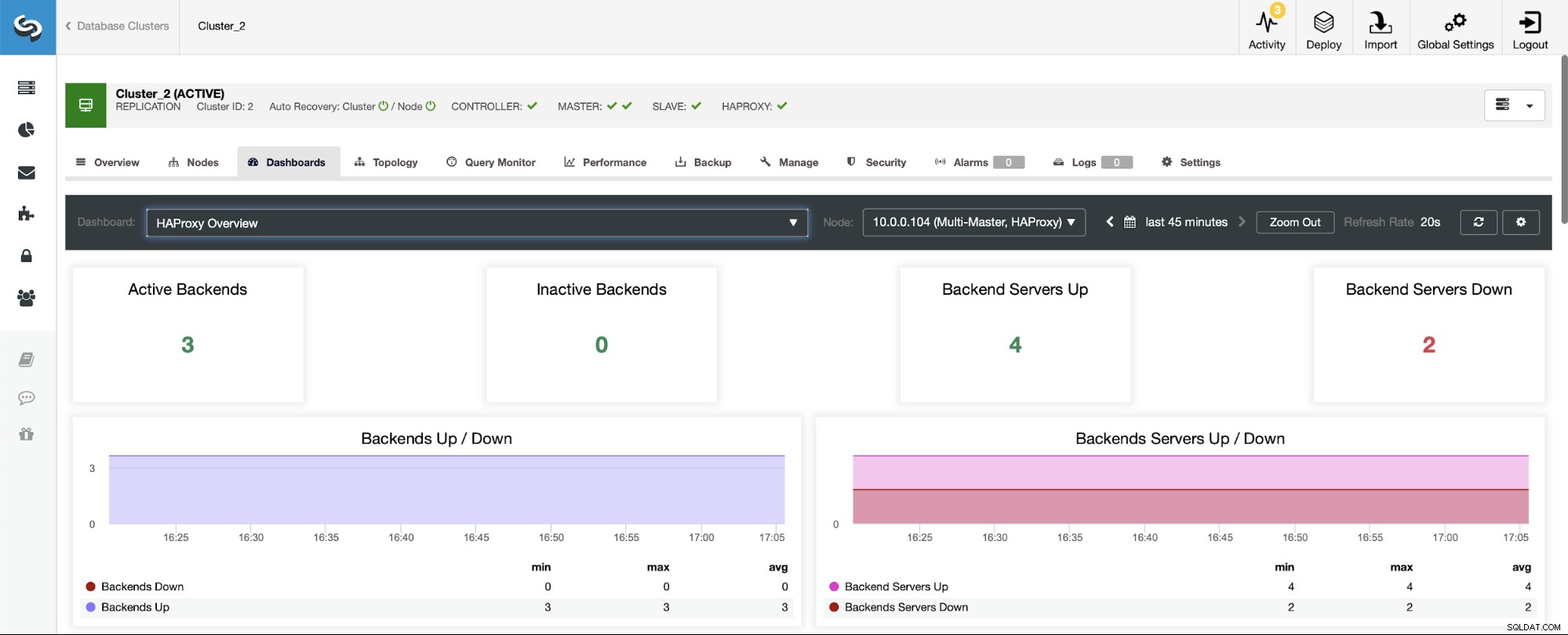
Pierwszą rzeczą, którą zobaczysz po przejściu do pulpitu nawigacyjnego HAProxy, jest informacje o stanie Twoich backendów. Pamiętaj, że to, co widzisz, może zależeć od typu klastra i sposobu wdrożenia HAProxy. W tym przypadku wdrożyliśmy klaster Galera, a HAProxy zostało wdrożone w trybie round-robin. Dlatego widzisz trzy backendy dla odczytów i trzy dla zapisów — łącznie sześć. Dlatego też widzisz wszystkie backendy oznaczone jako „W górę”.
W scenariuszu z klastrem replikacji sytuacja będzie wyglądać inaczej, ponieważ HAProxy zostanie wdrożone w podziale do odczytu/zapisu, a skrypty będą utrzymywać tylko jeden host (master) działający i działający w backend.
Zauważ, dlatego poniżej widzisz dwa serwery zaplecza oznaczone jako „Nieaktywny”:
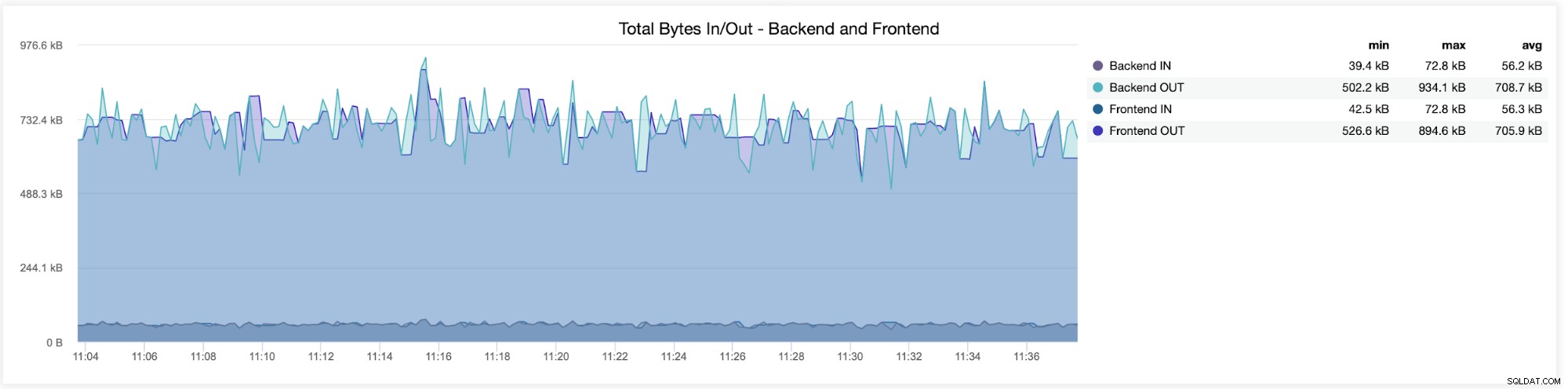
Na poniższym wykresie zobaczysz dane wysłane i odebrane przez obie backend (z HAProxy do serwerów baz danych) i frontend (między HAProxy a hostami klienckimi):
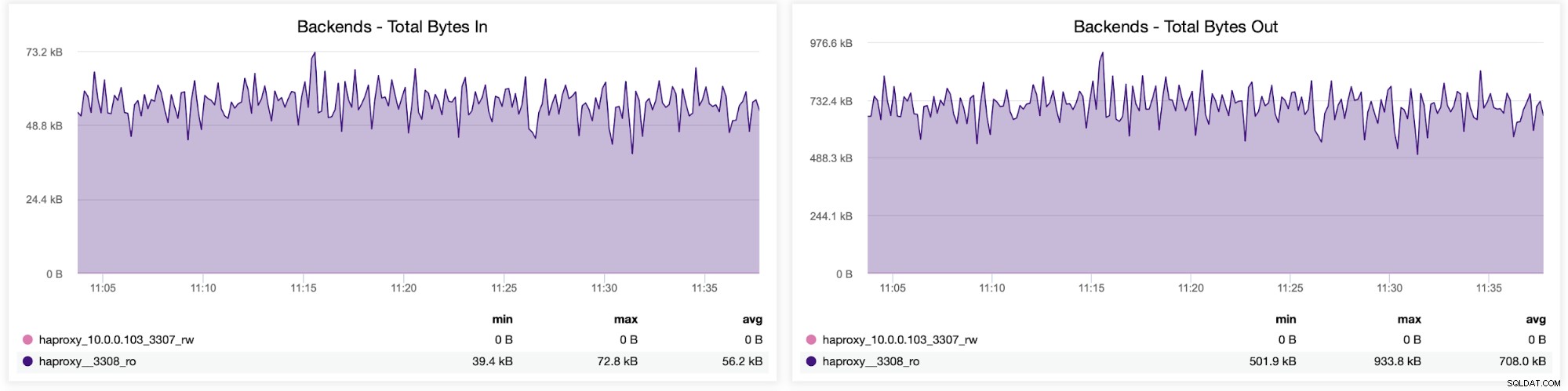
Możesz również sprawdzić rozkład ruchu między backendami w konfiguracji HAProxy. W tym przypadku mamy dwa backendy, a zapytania są wysyłane przez port 3308, który działa jako punkt dostępu round-robin do naszego klastra Galera:
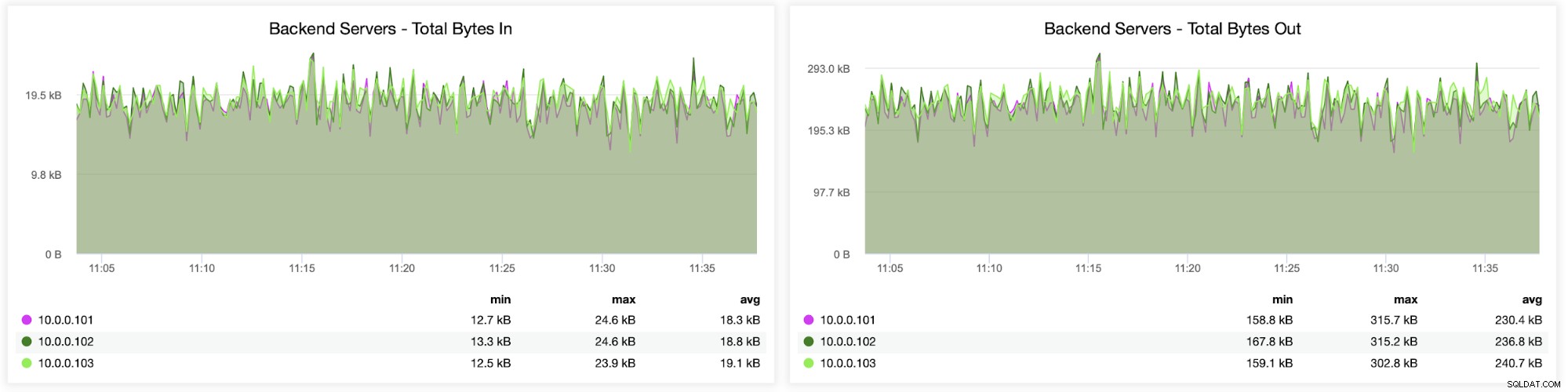
Następnie możesz zobaczyć, jak ruch był rozłożony na wszystkie serwery zaplecza. W tym scenariuszu — ze względu na schemat dostępu okrężnego — dane były mniej więcej równomiernie rozłożone na wszystkich trzech serwerach zaplecza Galera:
Informacje o sesjach, w tym o tym, ile sesji zostało otwartych z HAProxy do backendu serwery mogą być również monitorowane, jak widać na poniższym wykresie. Możesz także śledzić, ile razy na sekundę nowa sesja została otwarta na backend i jak te dane wyglądają na podstawie serwera backendu.
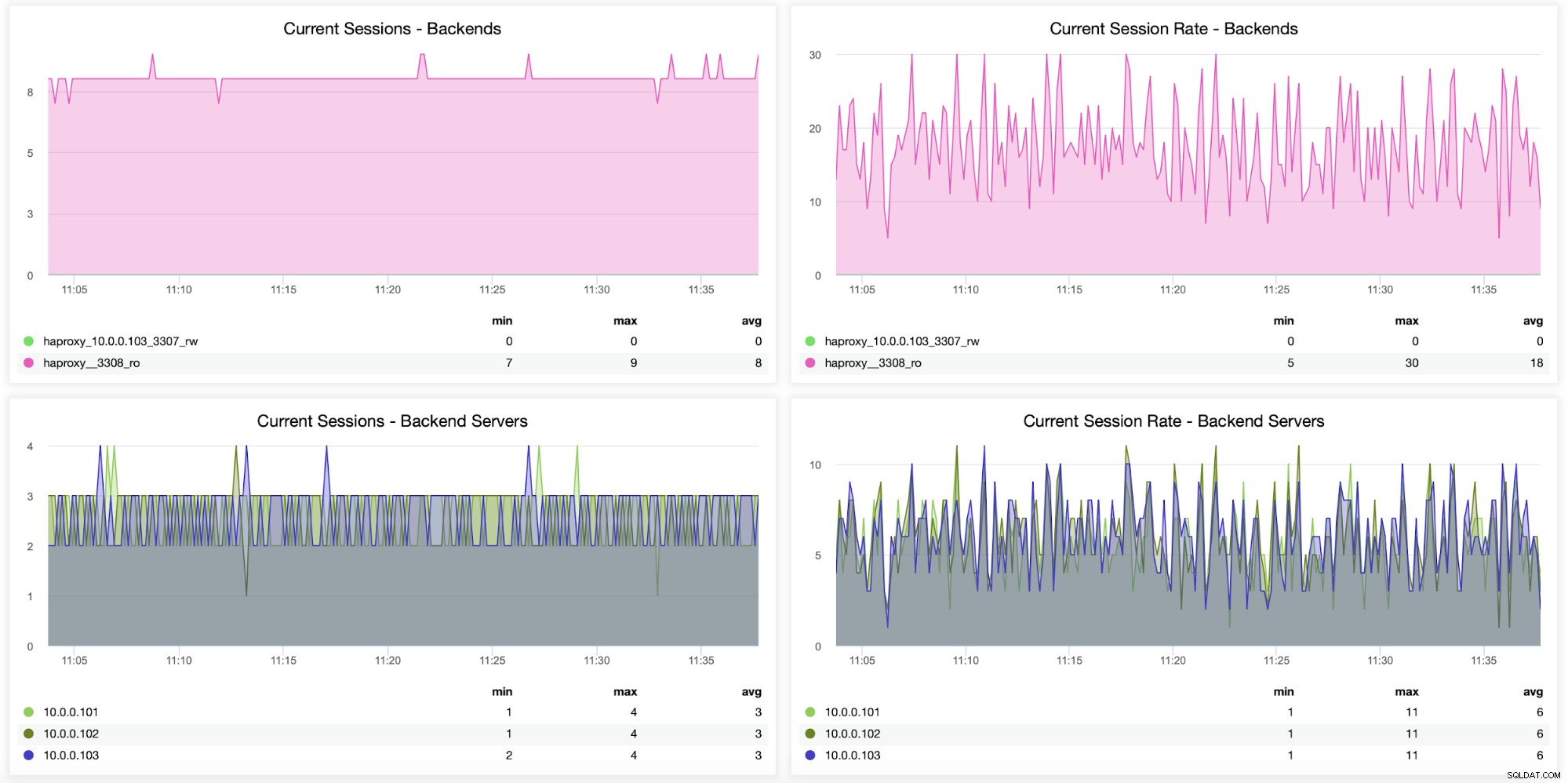
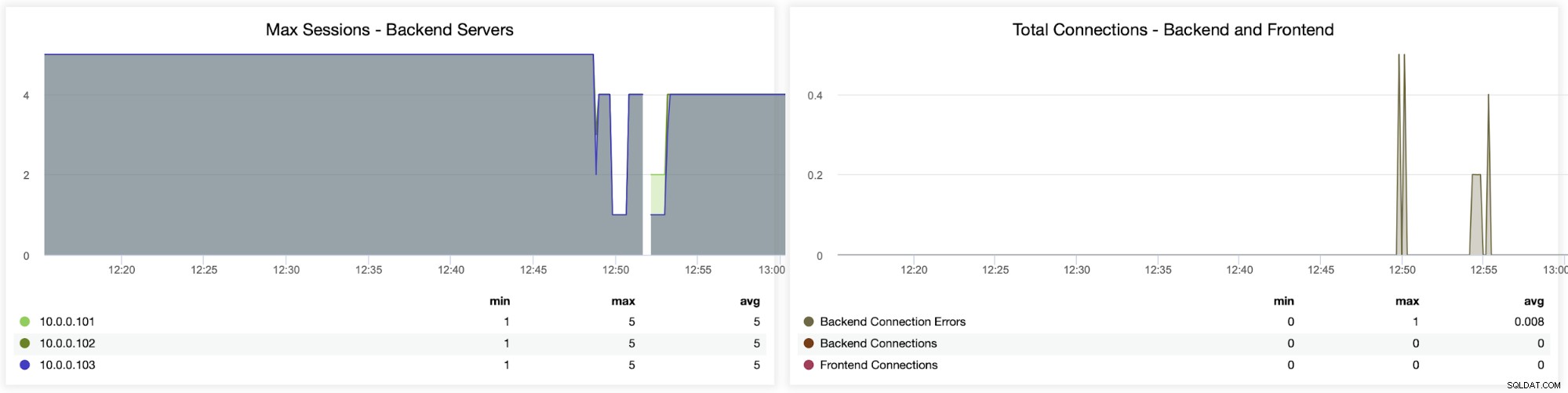
Poniższe dwa wykresy pokazują maksymalną liczbę sesji na serwer zaplecza i kiedy pojawiły się problemy z łącznością. Może to być bardzo przydatne do celów debugowania, gdy napotkasz błąd konfiguracji w instancji HAProxy i połączenia zaczną się zrywać.
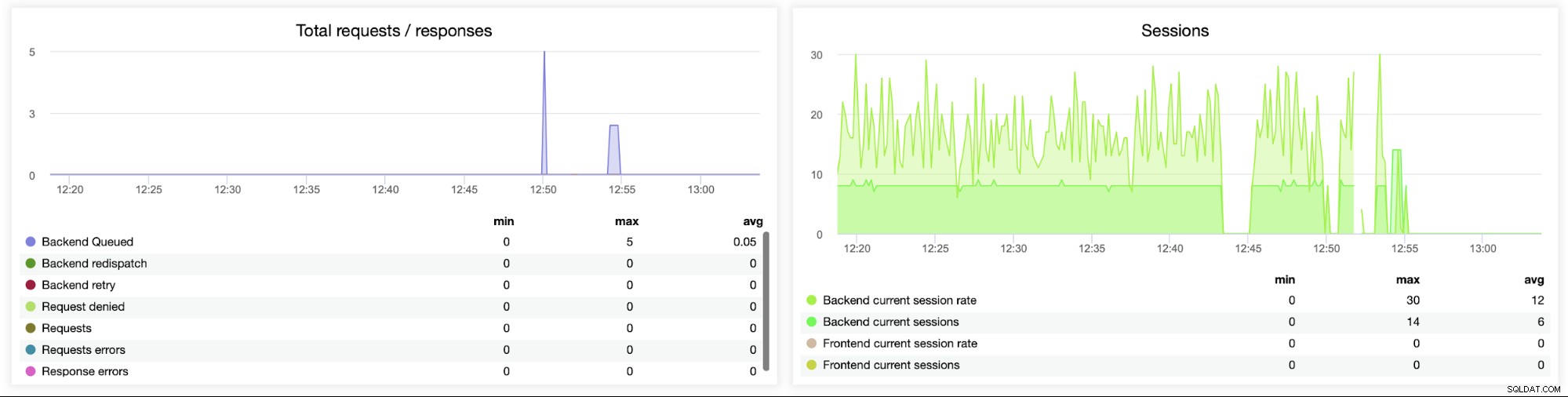
Ten następny wykres jest potencjalnie bardziej wartościowy, ponieważ pokazuje różne metryki związane z błędem obsługi, takich jak błędy, błędy żądań, ponawianie prób po stronie zaplecza itp. Dostępny jest również wykres „Sesje” przedstawiający przegląd danych sesji.
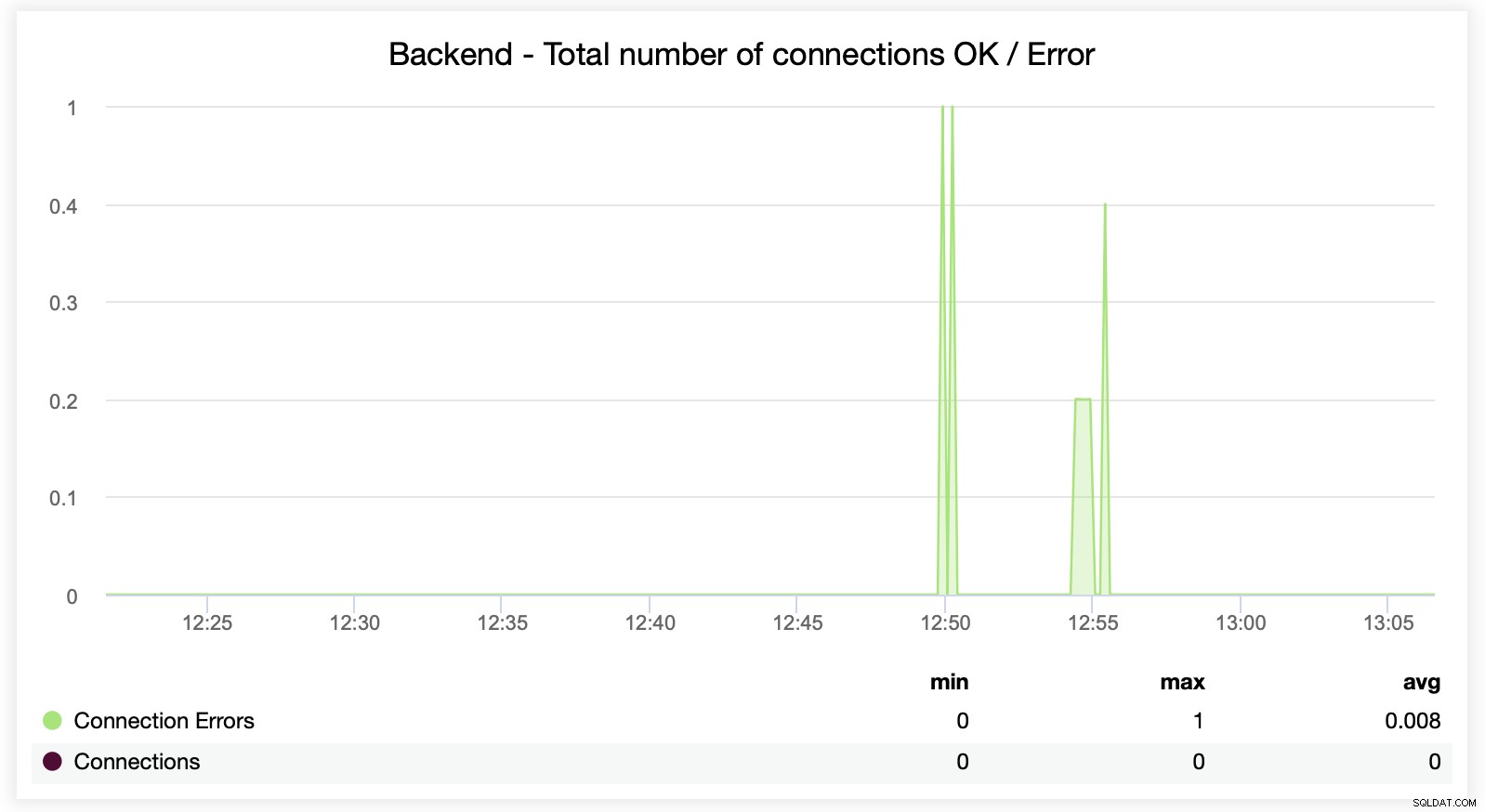
Tutaj widać, że ClusterControl śledzi błędy połączenia w czasie rzeczywistym, które mogą pomóc określić dokładny czas, w którym problemy zaczęły się rozwijać.
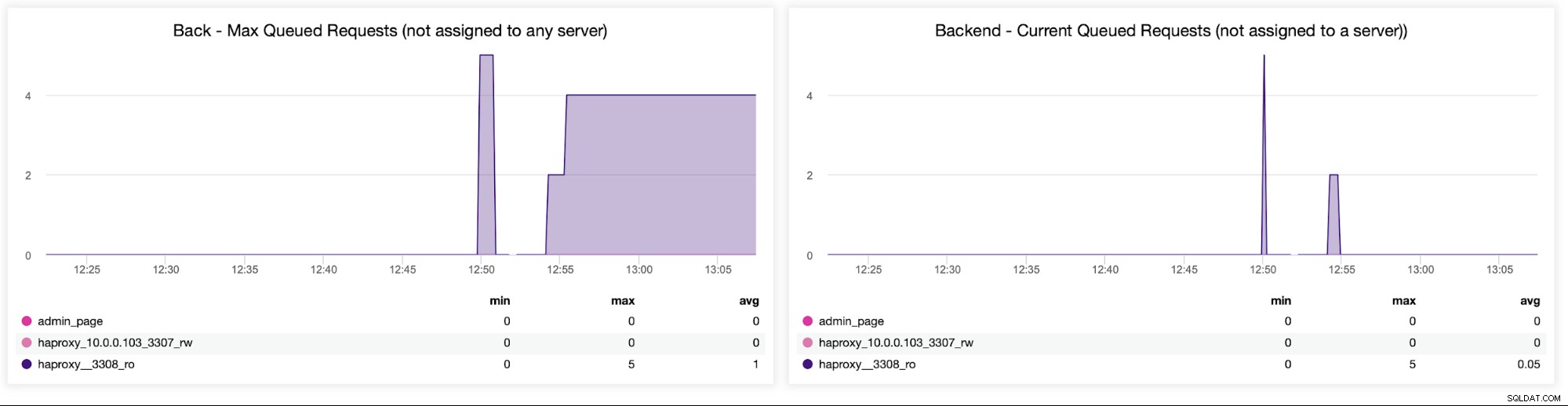
Na koniec przyjrzymy się następującym dwóm wykresom dotyczącym żądań w kolejce . HAProxy kolejkuje żądania do zaplecza, jeśli serwery zaplecza są przesycone. Może to wskazywać na przykład na przeciążone serwery baz danych, które nie mogą obsłużyć więcej ruchu.
Zawijanie
Wdrożenie i monitorowanie systemu równoważenia obciążenia HAProxy w ClusterControl może ułatwić pracę związaną z zarządzaniem i monitorowaniem połączeń. Posiadanie jasnego wglądu w wydajność backendów, dystrybucję ruchu, metryki sesji, błędy połączeń i liczbę żądań w kolejce może pomóc w zapewnieniu dostępności i skalowalności dowolnej konfiguracji bazy danych.
ClusterControl sprawia, że konfigurowanie i monitorowanie systemów równoważenia obciążenia jest dziecinnie proste w przypadku dowolnej konfiguracji bazy danych. Jeszcze nie korzystasz z ClusterControl? Jeśli chcesz się przekonać, jak łatwo jest wdrożyć i monitorować system równoważenia obciążenia HAProxy za pomocą ClusterControl, zapraszamy Cię do bezpłatnego 30-dniowego okresu próbnego platformy, bez żadnych zobowiązań. Aby uzyskać bardziej szczegółowy przewodnik wyjaśniający, dlaczego i jak używać HAProxy do równoważenia obciążenia, zapoznaj się z naszym samouczkiem dotyczącym równoważenia obciążenia MySQL za pomocą HAProxy.