PostgreSQL to niesamowity projekt, który rozwija się w niesamowitym tempie. Skoncentrujemy się na ewolucji możliwości odporności na awarie w PostgreSQL we wszystkich jego wersjach w serii wpisów na blogu. To jest czwarty post z serii. Porozmawiamy o synchronicznym zatwierdzaniu i jego wpływie na odporność na błędy i niezawodność PostgreSQL.
Jeśli chcesz być świadkiem postępu ewolucji od samego początku, zapoznaj się z pierwszymi trzema wpisami na blogu z tej serii poniżej. Każdy post jest niezależny, więc tak naprawdę nie musisz czytać jednego, aby zrozumieć drugi.
- Ewolucja tolerancji błędów w PostgreSQL
- Ewolucja tolerancji błędów w PostgreSQL:faza replikacji
- Ewolucja tolerancji błędów w PostgreSQL:podróż w czasie
Zatwierdzenie synchroniczne
Domyślnie PostgreSQL implementuje replikację asynchroniczną, w której dane są przesyłane strumieniowo, gdy tylko jest to wygodne dla serwera. Może to oznaczać utratę danych w przypadku przełączenia awaryjnego. Możliwe jest poproszenie Postgresa o wymaganie jednego (lub więcej) stanów gotowości w celu potwierdzenia replikacji danych przed zatwierdzeniem, nazywa się to replikacją synchroniczną (zatwierdzenie synchroniczne ) .
W przypadku replikacji synchronicznej opóźnienie replikacji bezpośrednio wpływa na upływający czas transakcji na masterze. W przypadku replikacji asynchronicznej master może pracować z pełną prędkością.
Replikacja synchroniczna gwarantuje, że dane są zapisywane w co najmniej dwa węzły, zanim użytkownik lub aplikacja otrzyma informację, że transakcja została zatwierdzona.
Użytkownik może wybrać tryb zatwierdzania każdej transakcji , dzięki czemu możliwe jest jednoczesne działanie zarówno synchronicznych, jak i asynchronicznych transakcji zatwierdzania.
Pozwala to na elastyczne kompromisy między wydajnością a pewnością trwałości transakcji.
Konfigurowanie zatwierdzania synchronicznego
Aby skonfigurować synchroniczną replikację w Postgresie, musimy skonfigurować synchronous_commit parametr w postgresql.conf.
Parametr określa, czy zatwierdzanie transakcji będzie czekać na zapisanie rekordów WAL na dysku, zanim polecenie zwróci sukces wskazanie klientowi. Prawidłowe wartości to na , zdalne_zastosowanie , remote_write , lokalne i wyłączone . Omówimy, jak wszystko działa pod względem replikacji synchronicznej, gdy skonfigurujemy synchronous_commit parametr z każdą ze zdefiniowanych wartości.
Zacznijmy od dokumentacji Postgresa (9.6):
Rozumiemy tutaj koncepcję zatwierdzania synchronicznego, tak jak opisaliśmy we wstępnej części wpisu, możesz skonfigurować replikację synchroniczną, ale jeśli tego nie zrobisz, zawsze istnieje ryzyko utraty danych. Ale bez ryzyka powstania niespójności w bazie danych, w przeciwieństwie do wyłączania fsync off – to jednak temat na inny post. Na koniec dochodzimy do wniosku, że jeśli nie chcemy tracić żadnych danych między opóźnieniami replikacji i chcemy mieć pewność, że dane są zapisywane w co najmniej dwóch węzłach, zanim użytkownik/aplikacja zostanie poinformowana, że transakcja została zatwierdzona , musimy zaakceptować utratę wydajności.
Zobaczmy, jak działają różne ustawienia dla różnych poziomów synchronizacji. Zanim zaczniemy, porozmawiajmy o tym, jak commit jest przetwarzany przez replikację PostgreSQL. Klient wykonuje zapytania w węźle głównym, zmiany są zapisywane w dzienniku transakcji (WAL) i kopiowane przez sieć do WAL w węźle rezerwowym. Następnie proces odzyskiwania w węźle gotowości odczytuje zmiany z WAL i stosuje je do plików danych, tak jak podczas odzyskiwania po awarii. Jeśli tryb gotowości jest w trybie gorącej gotowości W tym trybie klienci mogą wysyłać zapytania tylko do odczytu w węźle, gdy to się dzieje. Aby uzyskać więcej informacji na temat działania replikacji, zapoznaj się z wpisem na blogu dotyczącym replikacji z tej serii.
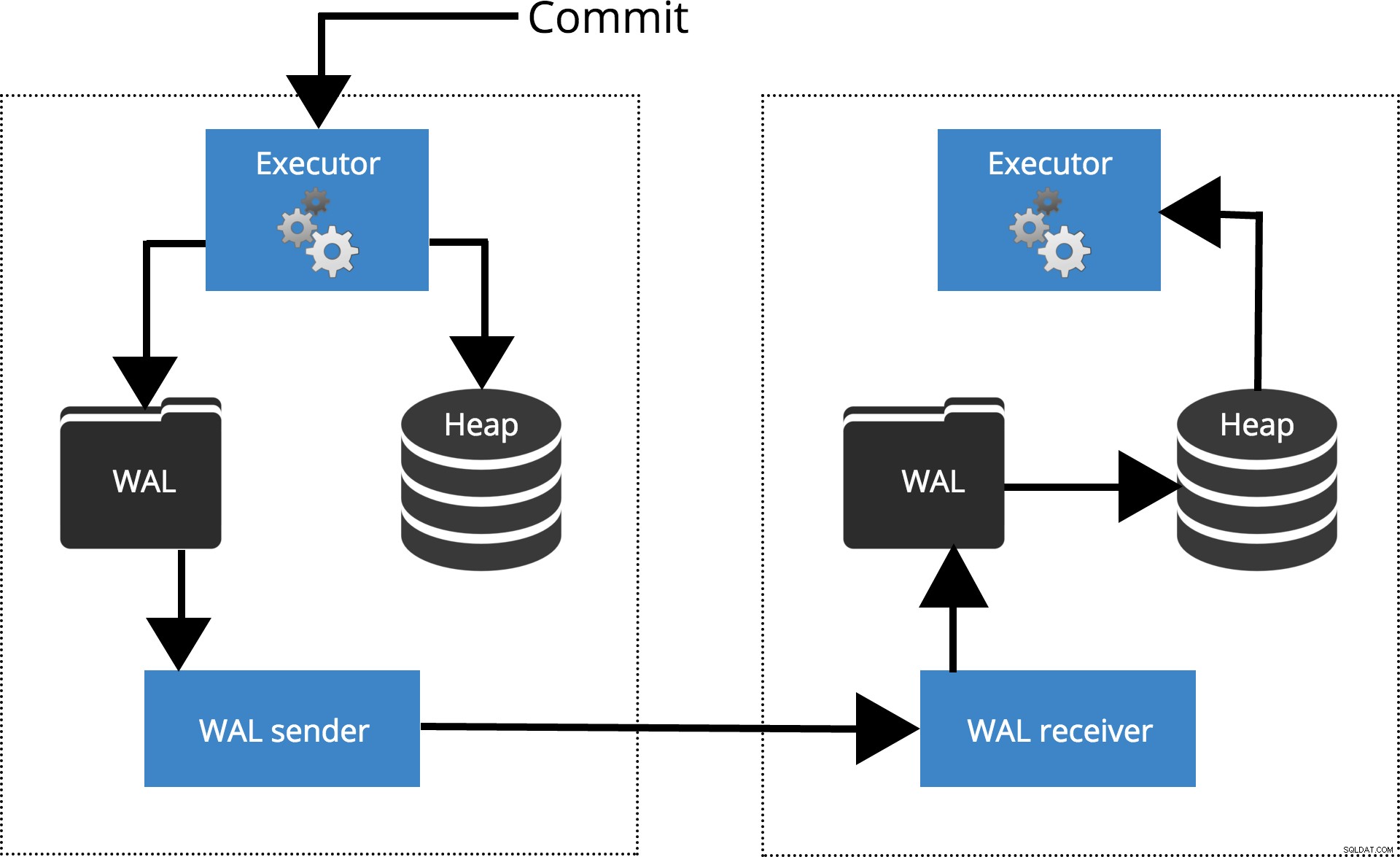
Rys. 1 Jak działa replikacja
synchronous_commit =wyłączone
Kiedy ustawimy sychronous_commit = off, COMMIT nie czeka na opróżnienie rekordu transakcji na dysk. Jest to zaznaczone na rys. 2 poniżej.
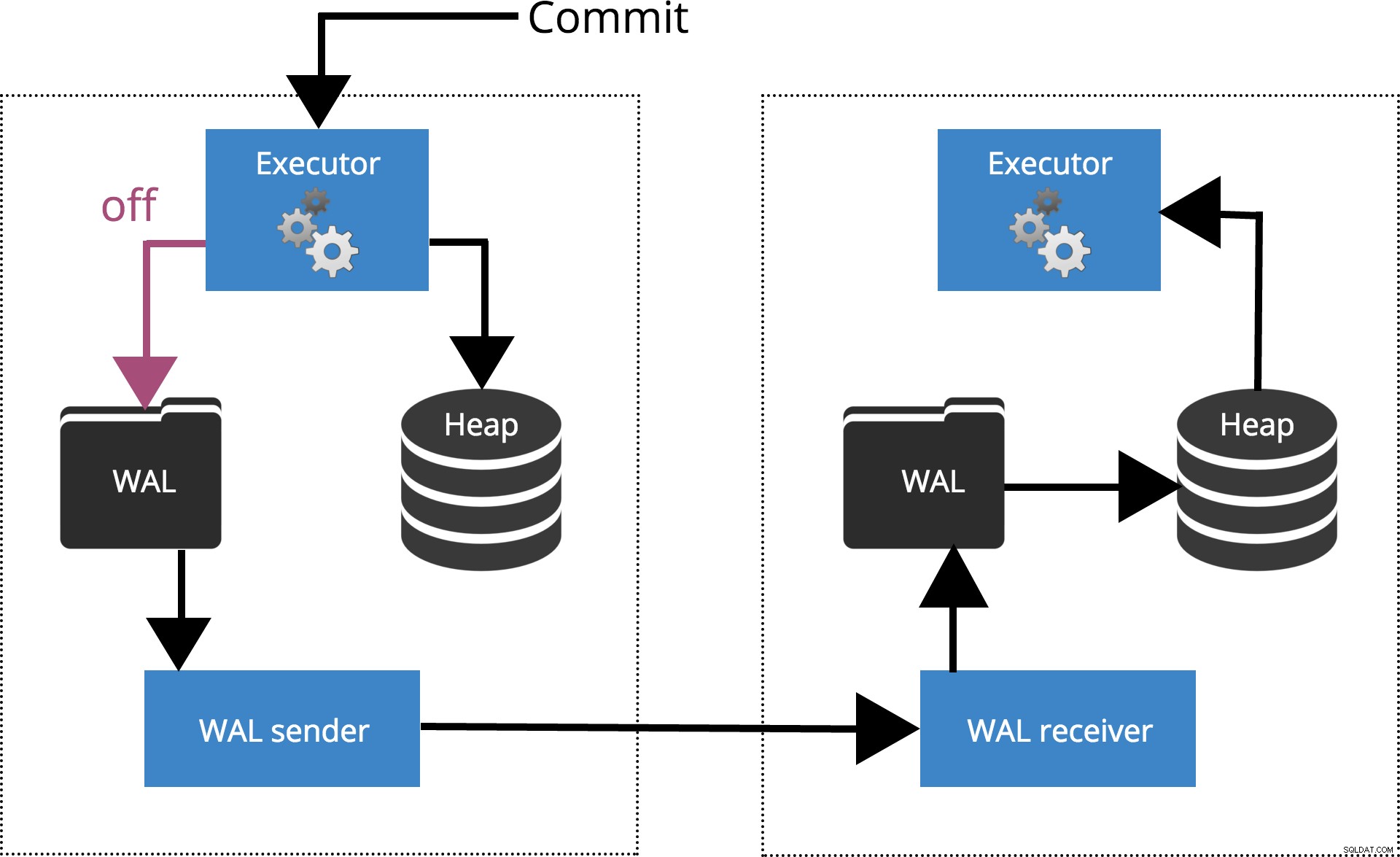
Rys. 2 synchronous_commit =off
synchronous_commit =lokalny
Kiedy ustawimy synchronous_commit = local, COMMIT czeka, aż rekord transakcji zostanie opróżniony na dysk lokalny. Jest to zaznaczone na rys. 3 poniżej.
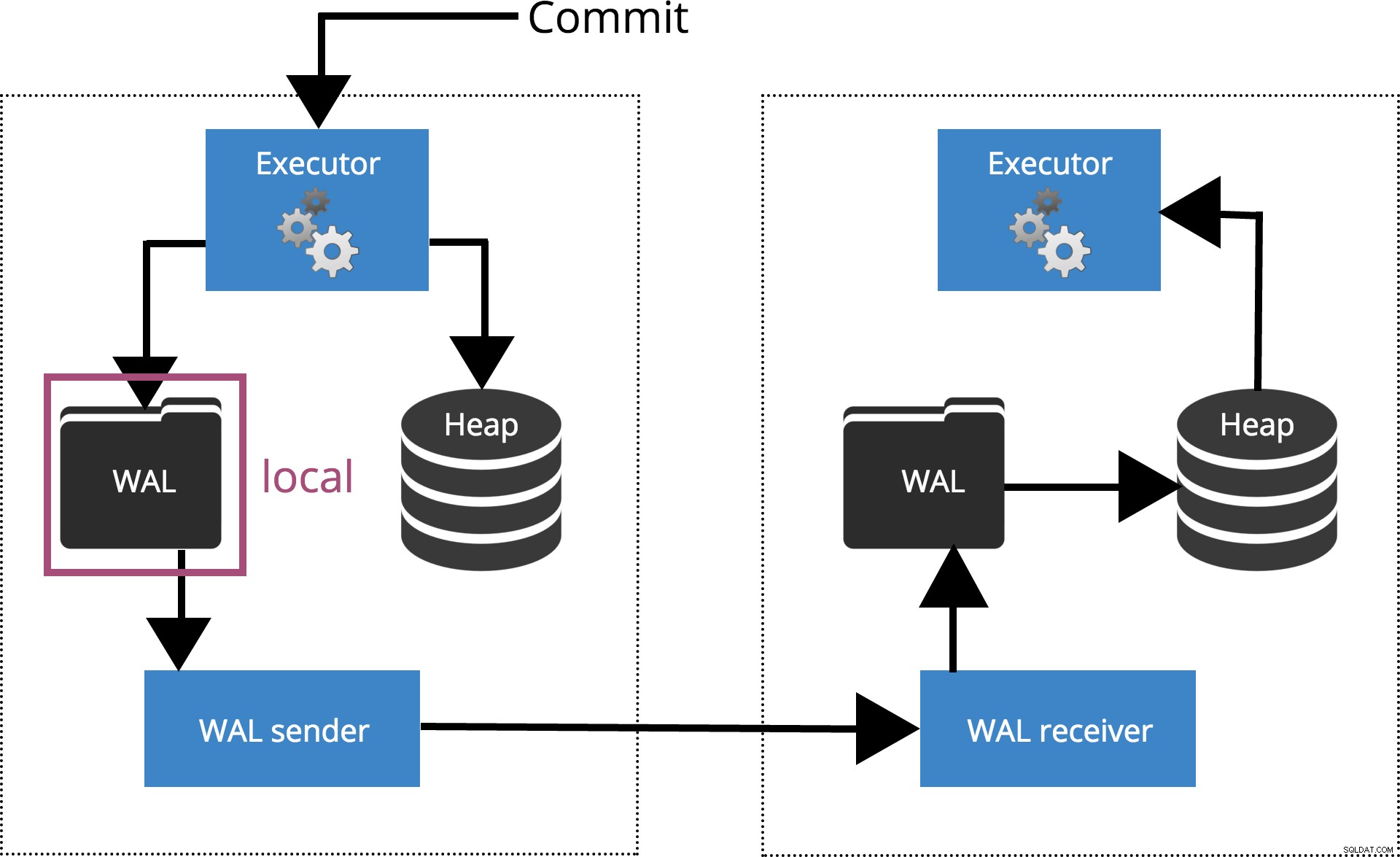
Rys. 3 synchronous_commit =lokalny
synchronous_commit =włączone (domyślnie)
Gdy ustawimy synchronous_commit = on, COMMIT będzie czekać, aż serwery określone przez synchronous_standby_names potwierdź, że rekord transakcji został bezpiecznie zapisany na dysku. Jest to zaznaczone na rys. 4 poniżej.
Uwaga: Kiedy synchronous_standby_names jest puste, to ustawienie zachowuje się tak samo jak synchronous_commit = local .
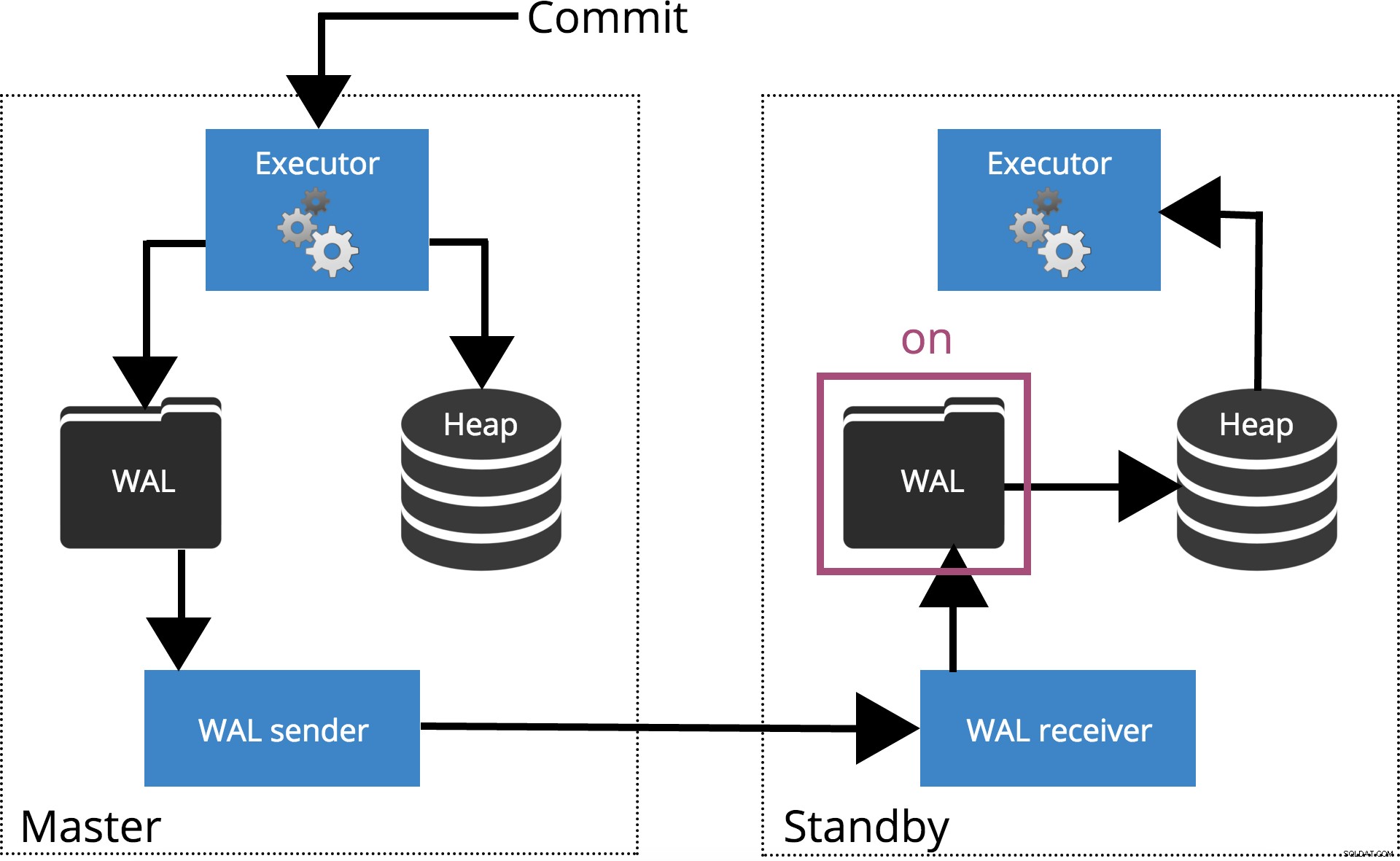
Rys. 4 synchronous_commit =wł.
synchronous_commit =zdalny_zapis
Kiedy ustawimy synchronous_commit = remote_write, COMMIT będzie czekać, aż serwery określone przez synchronous_standby_names potwierdzić zapis rekordu transakcji w systemie operacyjnym, ale niekoniecznie dotarł do dysku. Jest to podkreślone na ryc. 5 poniżej.
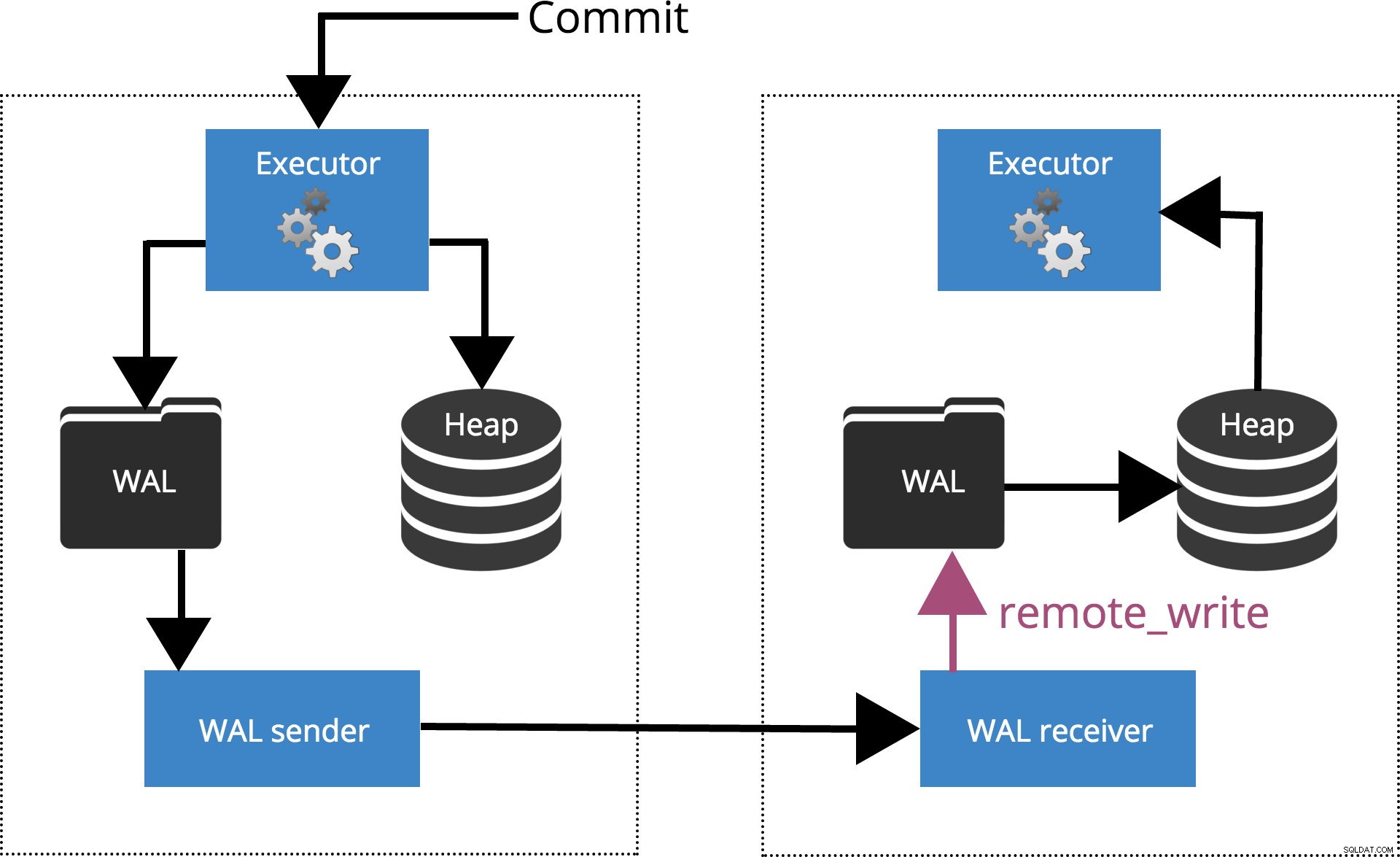
Rys.5 synchronous_commit =remote_write
synchronous_commit =remote_apply
Kiedy ustawimy synchronous_commit = remote_apply, COMMIT będzie czekać, aż serwery określone przez synchronous_standby_names potwierdzić, że rekord transakcji został zastosowany do bazy danych. Jest to podkreślone na ryc. 6 poniżej.
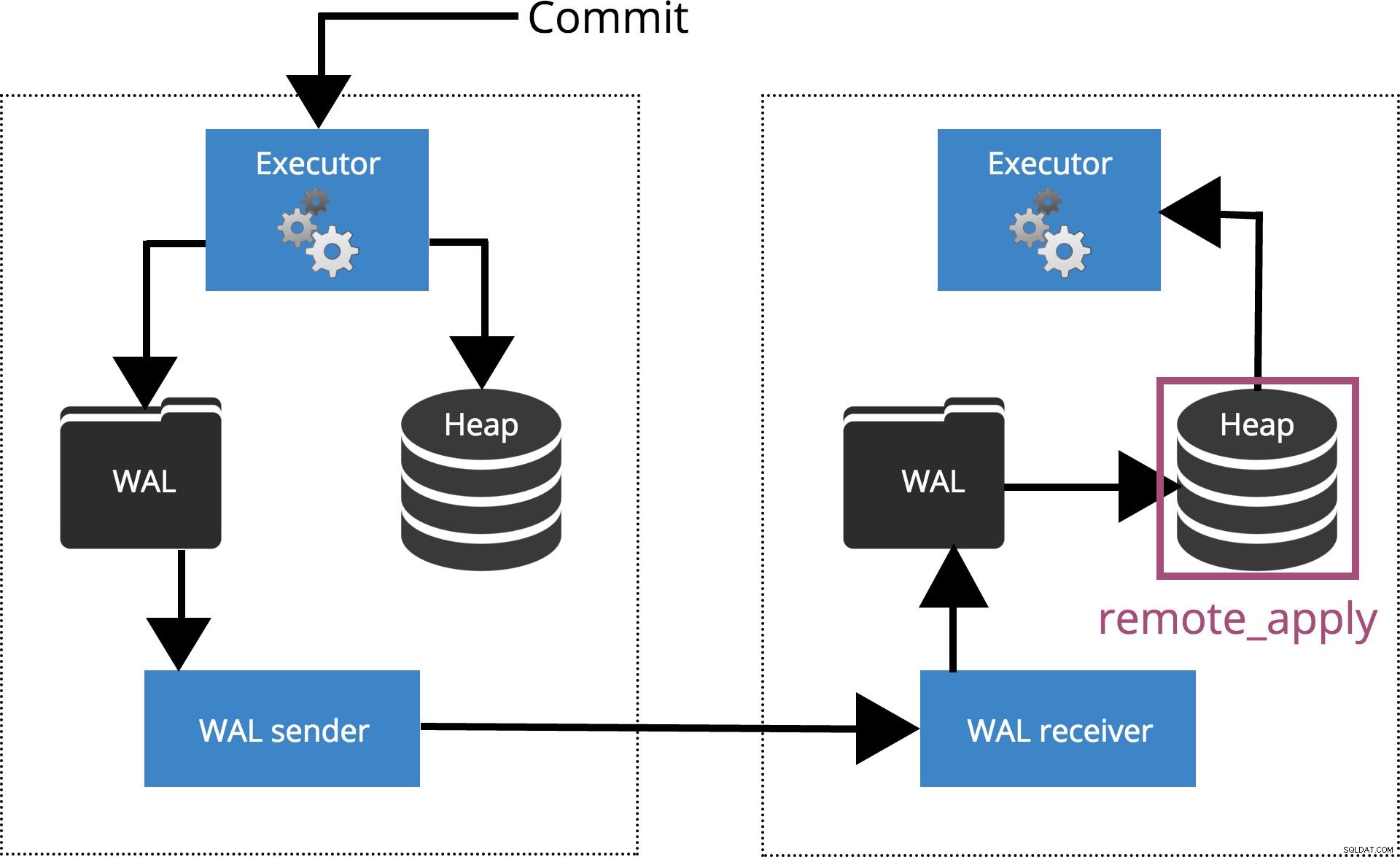
Rys.6 synchronous_commit =remote_apply
Teraz spójrzmy na sychronous_standby_names szczegółowo parametr, o którym mowa powyżej podczas ustawiania synchronous_commit jako on , remote_apply lub remote_write .
synchronous_standby_names =„nazwa_gotowości [, …]”
Zatwierdzenie synchroniczne będzie oczekiwało na odpowiedź z jednego ze stanów gotowości wymienionych w kolejności priorytetów. Oznacza to, że jeśli pierwsza rezerwa jest podłączona i przesyłana strumieniowo, synchroniczne zatwierdzanie zawsze będzie czekać na odpowiedź, nawet jeśli druga rezerwa już odpowiedziała. Specjalna wartość * może być używany jako stanby_name który będzie pasował do każdego podłączonego trybu gotowości.
synchronous_standby_names =„liczba (nazwa_gotowości [, …])”
Zatwierdzenie synchroniczne będzie czekać na odpowiedź od co najmniej num liczba stanów gotowości wymieniona w kolejności priorytetów. Obowiązują te same zasady, co powyżej. Na przykład ustawienie synchronous_standby_names = '2 (*)' sprawi, że synchroniczne zatwierdzanie będzie czekać na odpowiedź z dowolnych 2 serwerów oczekujących.
synchronous_standby_names jest pusty
Jeśli ten parametr jest pusty, jak pokazano, zmienia zachowanie ustawienia synchronous_commit do on , remote_write lub remote_apply zachowywać się tak samo jak local (tj. COMMIT będzie czekać tylko na opróżnienie na dysk lokalny).
Wniosek
W tym poście omówiliśmy replikację synchroniczną i opisaliśmy różne poziomy ochrony dostępne w Postgresie. W następnym wpisie na blogu będziemy kontynuować replikację logiczną.
Referencje
Specjalne podziękowania dla mojego kolegi Petra Jelinka za pomysł na ilustracje.
Dokumentacja PostgreSQL
Książka kucharska administracji PostgreSQL 9 – wydanie drugie