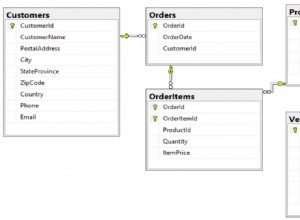
W tym artykule wyjaśnię, jak przenieść tabelę z podstawowej grupy plików do pomocniczej grupy plików. Najpierw zrozummy, czym są plik danych, grupa plików i typ grup plików.
Pliki bazy danych i grupy plików
Gdy program SQL Server jest zainstalowany na dowolnym serwerze, tworzy podstawowy plik danych i plik dziennika do przechowywania danych. Podstawowy plik danych przechowuje dane i obiekty bazy danych, takie jak tabele, indeksy, procedury składowane itp. Pliki dziennika przechowują informacje wymagane do odzyskania transakcji. Pliki danych można łączyć w grupy plików.
SQL Server ma trzy typy plików
- Plik podstawowy :Jest tworzony podczas instalacji serwera SQL i zawiera metadane bazy danych oraz informacje. Dane użytkownika, obiekty mogą być przechowywane w Podstawowych plikach danych. Podstawowy plik ma rozszerzenie .mdf.
- Plik dodatkowy :Pliki pomocnicze są definiowane przez użytkownika. Przechowują dane Użytkownika, Obiekty stworzone przez Użytkownika. Mają rozszerzenie .ndf.
- Plik dziennika transakcji s:Pliki T-Logs rejestrują wszystkie transakcje wykonane w celu odzyskania bazy danych. Rozszerzenie pliku dziennika w .ldf.
Jak wspomniałem powyżej, pliki danych można pogrupować w grupę plików. Podczas instalowania programu SQL Server tworzy podstawową grupę plików zawierającą podstawowy plik danych. Pomocnicze grupy plików są zdefiniowane przez użytkownika. Mają wtórne pliki danych. Kiedy tworzymy nową bazę danych, możemy tworzyć pomocnicze pliki danych i grupy plików. Dodanie wtórnych plików danych pomaga poprawić wydajność. Można go utworzyć na różnych dyskach lub oddzielnych partycjach dyskowych, co zmniejsza opóźnienie we/wy i odczyt-zapis.
Zaleca się przechowywanie tabel i indeksów w oddzielnych grupach plików. Ponadto przechowywanie dużych tabel w osobnych plikach poprawia wydajność.
Istnieją trzy typy grup plików:
- Grupa plików wiersza :Grupa plików wierszy, znana również jako podstawowa grupa plików, zawiera podstawowy plik danych. Obiekt SQL, dane, tabele systemowe przydzielają do podstawowej grupy plików.
- Grupa plików zoptymalizowana pod kątem pamięci :Grupa plików zoptymalizowana pod kątem pamięci zawiera tabele i dane zoptymalizowane pod kątem pamięci. Aby włączyć OLTP w pamięci, musimy utworzyć grupę plików zoptymalizowaną pod kątem pamięci.
- Strumień plików :Grupa plików strumienia plików zawiera dane strumienia plików, takie jak obrazy, dokumenty, pliki wykonywalne itp. Podstawowa grupa plików nie może zawierać danych strumienia plików, musimy utworzyć grupę plików FileStream. Zawiera dane FileStream.
Konfiguracja wersji demonstracyjnej
W tym demo stworzyłem „DemoDatabase” na instancji SQL Server 2017. W bazie danych zostały utworzone zakładki „Rekordy” i „PatientData”. Klucz podstawowy „PK_CIDX_Records_ID” został utworzony w tabeli „Rekordy”, a indeks klastrowy „CIDX_PatientData_ID” został utworzony w tabeli „PatientData”. W tym demo przeniosę tabele „Records” i „PatientData” z podstawowej grupy plików do dodatkowej grupy plików.
W tym celu musimy wykonać następujące czynności:
- Utwórz pomocniczą grupę plików.
- Dodaj pliki danych do pomocniczej grupy plików.
- Przenieś tabelę do pomocniczej grupy plików, przenosząc indeks klastrowy z ograniczeniem klucza podstawowego.
- Przenieś tabele do pomocniczej grupy plików, przenosząc indeks klastrowy bez klucza podstawowego.
Utwórz dodatkową grupę plików
Pomocniczą grupę plików można utworzyć za pomocą T-SQL LUB za pomocą Kreatora dodawania plików z programu SQL Server Management Studio. Aby dodać grupę plików za pomocą SSMS, otwórz SSMS i wybierz bazę danych, w której należy utworzyć grupę plików. Kliknij bazę danych prawym przyciskiem myszy i wybierz „Właściwości ”>> wybierz „Grupy plików ” i kliknij „Dodaj grupę plików ”, jak pokazano na poniższym obrazku:
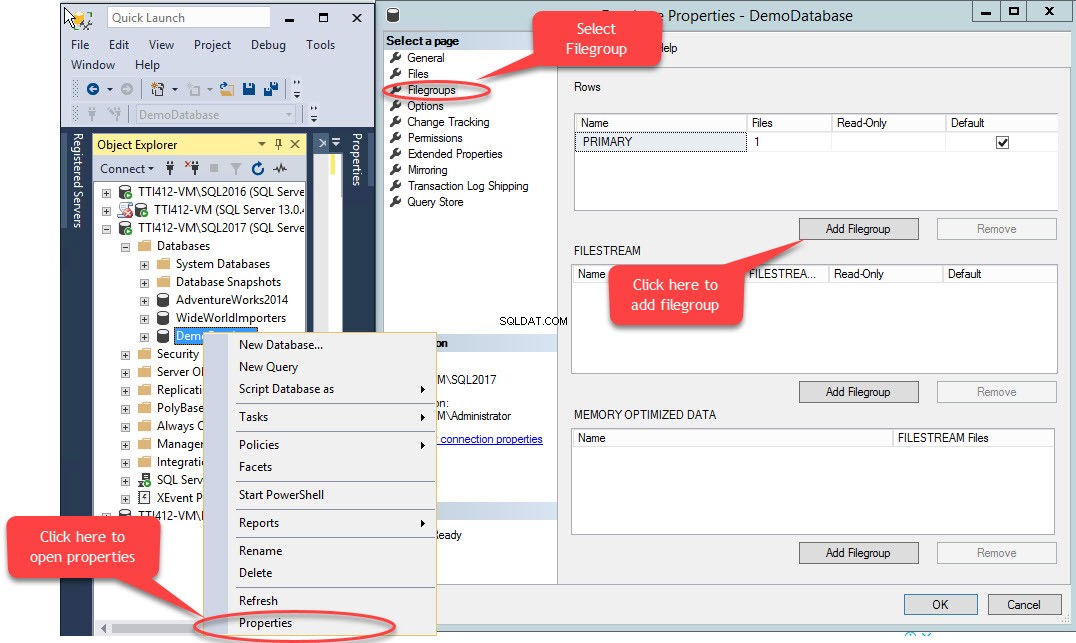
Kiedy klikniemy „Dodaj grupę plików ”, wiersz zostanie dodany w „Wiersze " siatka. W „Wierszach ”, podaj odpowiednią nazwę grupy plików w polu „Nazwa ” kolumna. Grupa plików nie jest tylko do odczytu ani domyślna; dlatego zachowaj Tylko do odczytu i Domyślne pola wyboru wyczyszczone dla nowej grupy plików. Zobacz następujący obraz:
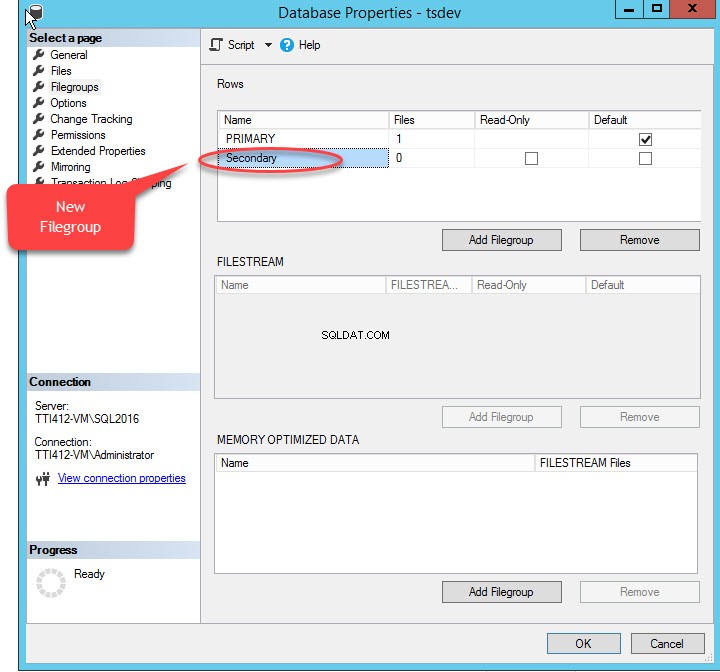
Kliknij OK, aby zamknąć okno dialogowe.
Aby utworzyć grupę plików przy użyciu skryptu T-SQL, uruchom następujący skrypt.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILEGROUP [Secondary ] GO
Dodawanie plików do grupy plików
Aby dodać pliki w grupie plików, otwórz właściwości bazy danych, wybierz „pliki” i kliknij „Dodaj”. Jak pokazano na poniższym obrazku:
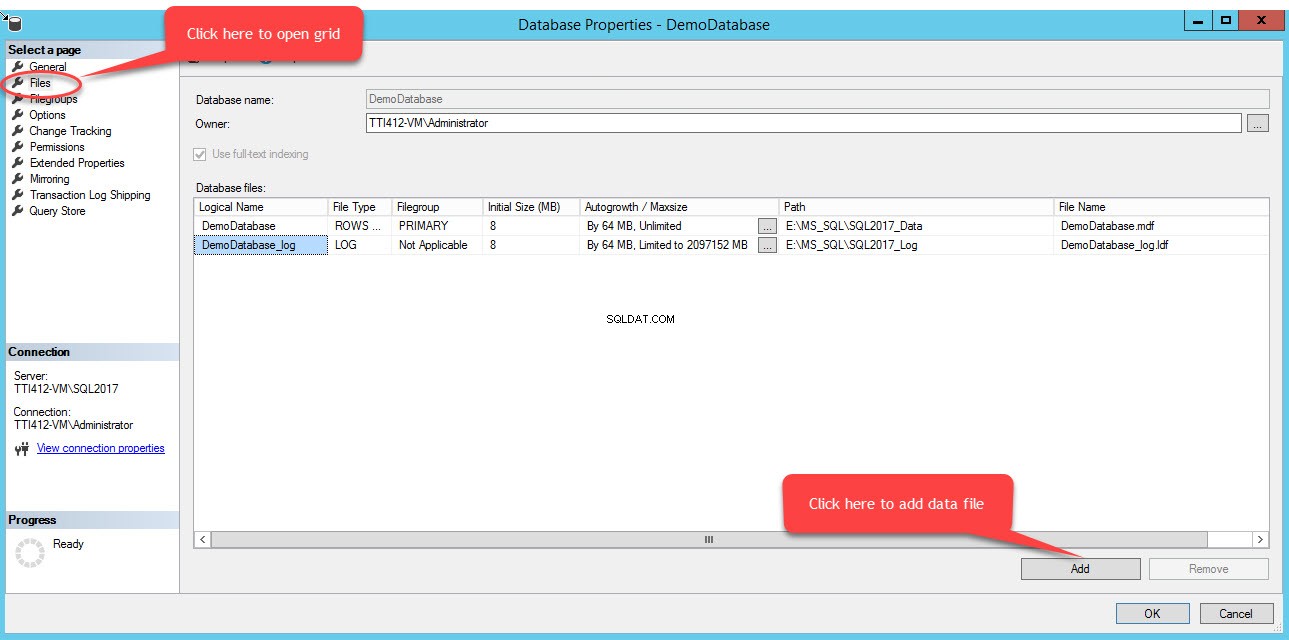
Pusty wiersz zostanie dodany w Plikach bazy danych widok siatki. W widoku siatki podaj odpowiednią nazwę logiczną w Nazwie logicznej kolumnę, wybierz Dane wierszy z Typu pliku z listy rozwijanej wybierz dodatkowe z grupy plików menu rozwijanego, ustaw początkowy rozmiar pliku w Rozmiar początkowy kolumn, ustaw parametr automatycznego wzrostu i maksymalnego rozmiaru w Autogrowth/Maxsize kolumna, podaj fizyczną lokalizację pomocniczego pliku danych w Ścieżce i podaj odpowiednią nazwę pliku w Nazwie pliku kolumna. Zobacz następujący obraz:
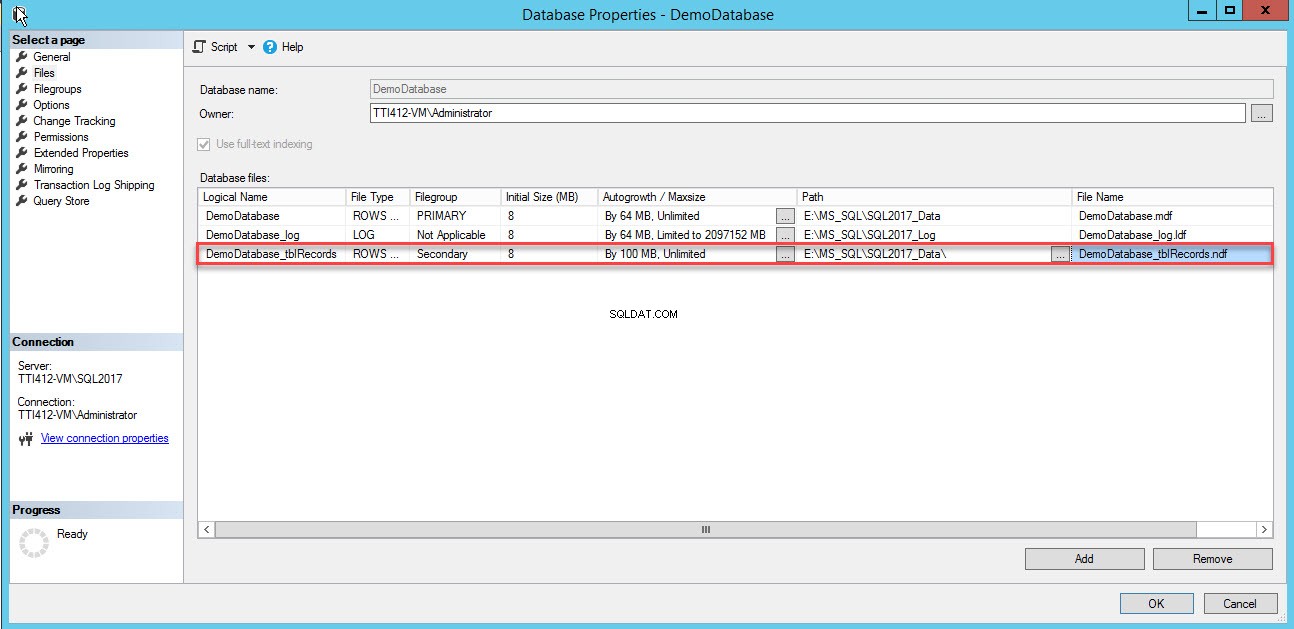
Użyj następującego skryptu T-SQL, aby utworzyć dodatkowy plik danych.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILE ( NAME = N'DemoDatabase_tblRecords', FILENAME = N'E:\MS_SQL\SQL2017_Data\DemoDatabase_tblRecords.ndf' , SIZE = 8192KB , FILEGROWTH = 102400KB ) TO FILEGROUP [Secondary] GO
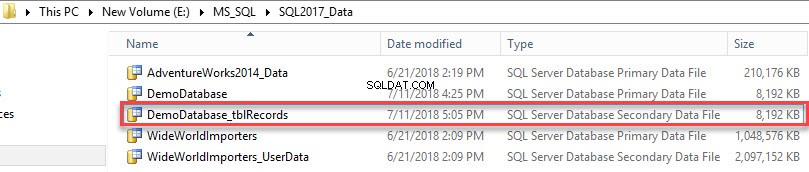
Utworzono pomocniczy plik danych. Zobacz następujący obraz:
Aby wyświetlić listę grup plików utworzonych w bazie danych, wykonaj następujące zapytanie.
use DemoDatabase go select a.Name as 'File group Name', type_desc as 'Filegroup Type', case when is_default=1 then 'Yes' else 'No' end as 'Is filegroup default?', b.filename as 'File Location', b.name 'Logical Name', Convert(numeric(10,3),Convert(numeric(10,3),(size/128))/1024) as 'File Size in MB' from sys.filegroups a inner join sys.sysfiles b on a.data_space_id=b.groupid
Poniżej znajduje się wynik zapytania.

Przenoszenie istniejącej tabeli z podstawowej grupy plików do dodatkowej grupy plików
Istniejącą tabelę można przenieść do innej grupy plików, przenosząc indeks klastrowany do innej grupy plików. Jak wiemy, węzeł-liść indeksu klastrowego zawiera rzeczywiste dane; stąd przeniesienie indeksu klastrowego może przenieść całą tabelę do innej grupy plików. Przenoszenie indeksu ma ograniczenie:jeśli indeks jest kluczem podstawowym lub ograniczeniem przez unikalność, nie można przenieść indeksu za pomocą SQL Server Management Studio. Aby przenieść te indeksy, musimy użyć utwórz indeks oświadczenie i z DROP_Existing=ON opcja.
Przenoszenie indeksu klastrowego z ograniczeniem klucza podstawowego.
Klucz podstawowy wymusza unikatowe wartości, dlatego tworzy unikalny indeks klastrowy. Kluczową kolumną jest PRN. Aby utworzyć go w pomocniczej grupie plików, ustaw DROP_EXISTING=ON opcja i grupa plików powinna być drugorzędna. Wykonaj następujący skrypt.
USE [DemoDatabas] GO Create Unique Clustered index [PK_CIDX_Records_ID] ON [Records] (ID asc) WITH (DROP_EXISTING=ON) ON [Secondary]
Po pomyślnym wykonaniu polecenia sprawdź, czy indeks został utworzony w pomocniczej grupie plików. W tym celu kliknij prawym przyciskiem myszy Pamięć opcja w Właściwościach indeksu Okno dialogowe. Aby otworzyć właściwości indeksu, rozwiń Bazę danych Demo baza danych>> rozwiń Tabele>> rozwiń Indeksy . Kliknij prawym przyciskiem myszy PK_CIDX_Records_ID , jak pokazano na poniższym obrazku:
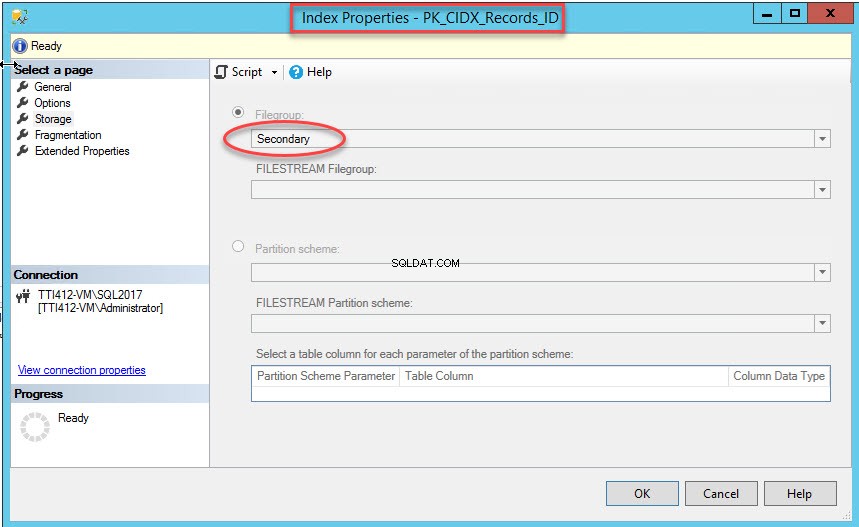
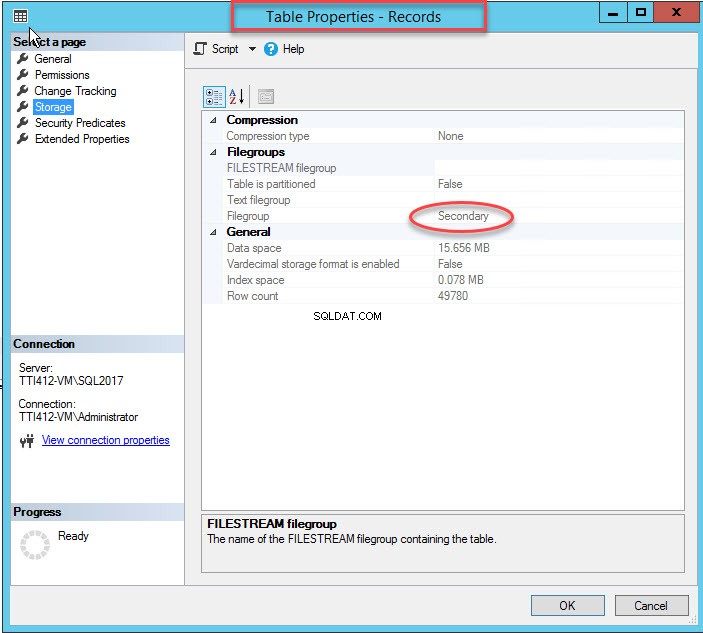
Jak już wspomniałem, po przeniesieniu indeksu klastrowanego do pomocniczej grupy plików tabela zostanie przeniesiona do pomocniczej grupy plików. Aby to zweryfikować, kliknij prawym przyciskiem myszy Pamięć opcja w Właściwościach tabeli Okno dialogowe. Aby otworzyć właściwości indeksu, rozwiń Bazę danych Demo baza danych>> rozwiń Tabela s>> kliknij prawym przyciskiem myszy Rekordy, i wybierz pamięć, jak pokazano na poniższym obrazku:
Przenoszenie indeksu klastrowego bez klucza podstawowego
Indeks klastrowy możemy przenieść bez klucza podstawowego za pomocą SQL Server Management Studio. Aby to zrobić, rozwiń Bazę DemoData baza danych>> rozwiń Tabele>> rozwiń Indeks s>> kliknij prawym przyciskiem myszy CIDX_PatientData_ID indeks i wybierz Właściwości, jak pokazano na poniższym obrazku:
Właściwości indeksu otworzy się okno dialogowe. W oknie dialogowym wybierz Pamięć, i w oknie Przechowywanie kliknij Grupę plików menu rozwijane wybierz Dodatkowe grupy plików i kliknij OK, jak pokazano na poniższym obrazku:
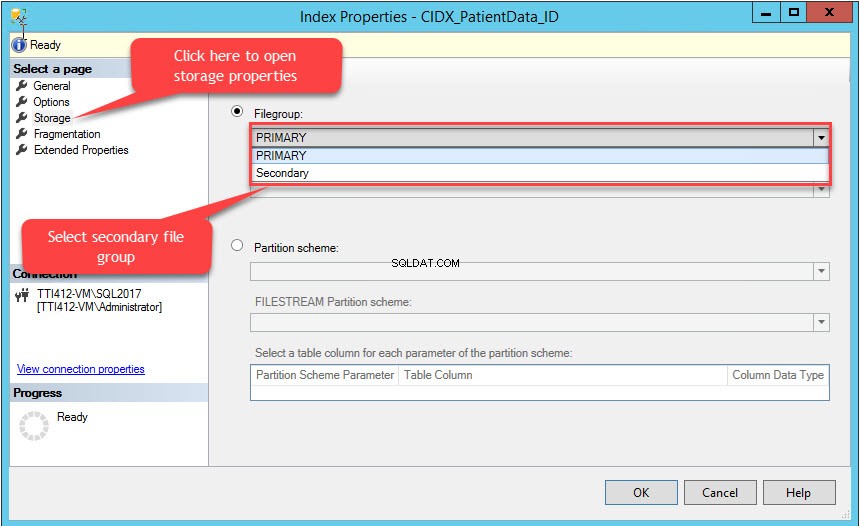
Zmiana grupy plików indeksu spowoduje ponowne utworzenie całego indeksu. Po ponownym utworzeniu indeksu otwórz Właściwości tabeli i wybierz magazyn.
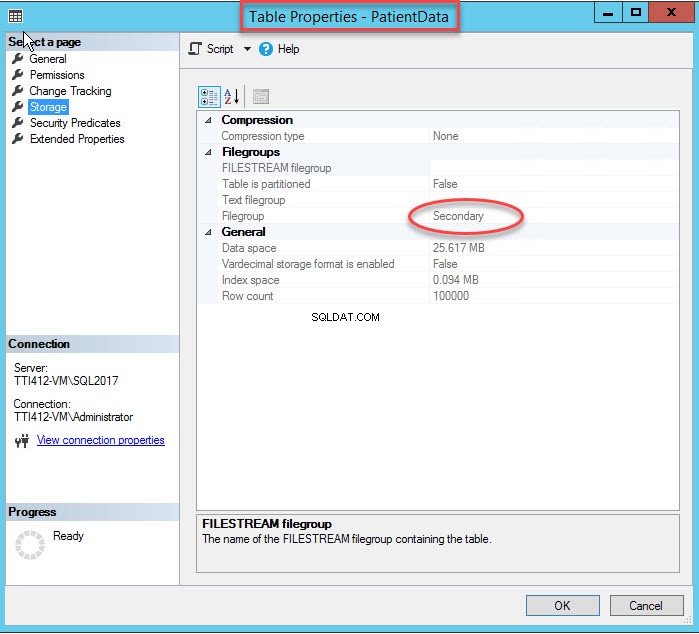
Jak widać na powyższym obrazku, wraz z przeniesieniem CIDX_PatientData_ID indeks klastrowy do pomocniczej grupy plików, PatientData tabela jest również przeniesiona do dodatkowego grupa plików.
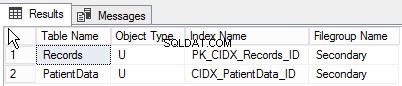
Wykonując następujące zapytanie, możesz znaleźć listę obiektów utworzonych w różnych grupach plików:
SELECT obj.[name] as [Table Name],
obj.[type] as [Object Type],
Indx.[name] as [Index Name],
fG.[name] as [Filegroup Name]
FROM sys.indexes INDX
INNER JOIN sys.filegroups FG
ON INDX.data_space_id = fG.data_space_id
INNER JOIN sys.all_objects Obj
ON INDX.[object_id] = obj.[object_id]
WHERE INDX.data_space_id = fG.data_space_id
And obj.type='U'
go Poniżej znajduje się wynik zapytania:
Podsumowanie
W tym artykule wyjaśniłem
-
- Podstawy plików danych i grup plików.
- Jak utworzyć drugorzędną grupę plików i dodać do niej drugorzędny plik danych.
- Przenieś tabelę do pomocniczej grupy plików, przenosząc:
- Klucz główny.
- Indeks klastrowy.