HAProxy i ProxySQL są bardzo popularnymi load balancerami w świecie MySQL, ale istnieje znacząca różnica między tymi dwoma proxy. Nie będziemy tutaj wchodzić w szczegóły, możesz przeczytać więcej o HAProxy w HAProxy Tutorial i ProxySQL w ProxySQL Tutorial. Najważniejszą różnicą jest to, że ProxySQL jest proxy rozpoznającym SQL, parsuje ruch i rozumie protokół MySQL i jako taki może być używany do zaawansowanego kształtowania ruchu - możesz blokować zapytania, przepisywać je, kierować do poszczególnych hostów, cache je i wiele innych. Z drugiej strony HAProxy jest bardzo prostym, ale wydajnym proxy warstwy 4 i wszystko, co robi, to wysyłanie pakietów do zaplecza. ProxySQL może być używany do wykonywania podziału odczytu i zapisu — rozumie on SQL i może być skonfigurowany tak, aby wykrywał, czy zapytanie jest SELECT czy nie, i odpowiednio je przekierowuje:SELECTy do wszystkich węzłów, inne zapytania tylko do masteru. Ta funkcja jest niedostępna w HAProxy, który musi korzystać z dwóch oddzielnych portów i dwóch oddzielnych zapleczy dla urządzenia nadrzędnego i podrzędnego – podział odczytu i zapisu musi być wykonany po stronie aplikacji.
Dlaczego migrować do ProxySQL?
Na podstawie różnic, które wyjaśniliśmy powyżej, powiedzielibyśmy, że głównym powodem, dla którego możesz chcieć przełączyć się z HAProxy na ProxySQL, jest brak podziału odczytu i zapisu w HAProxy. Jeśli używasz klastra baz danych MySQL i nie ma znaczenia, czy jest to replikacja asynchroniczna, czy klaster Galera, prawdopodobnie chcesz mieć możliwość rozdzielenia odczytów i zapisów. W przypadku replikacji MySQL byłby to oczywiście jedyny sposób wykorzystania klastra bazy danych, ponieważ zapisy zawsze muszą być wysyłane do mastera. Dlatego jeśli nie możesz dokonać podziału odczytu i zapisu, możesz wysyłać zapytania tylko do mastera. Dla Galery split do odczytu i zapisu nie jest koniecznością, ale zdecydowanie czymś, co warto mieć. Oczywiście, możesz skonfigurować wszystkie węzły Galera jako jeden backend w HAProxy i wysyłać ruch do nich wszystkich w sposób okrężny, ale może to spowodować konflikt zapisów z wielu węzłów, co prowadzi do zakleszczeń i spadku wydajności. Widzieliśmy również problemy i błędy w klastrze Galera, dla których, dopóki nie zostaną naprawione, obejściem było skierowanie wszystkich zapisów do jednego węzła. Dlatego najlepszą praktyką jest wysyłanie wszystkich zapisów do jednego węzła Galera, ponieważ prowadzi to do bardziej stabilnego zachowania i lepszej wydajności.
Kolejnym bardzo dobrym powodem migracji do ProxySQL jest potrzeba lepszej kontroli nad ruchem. Z HAProxy nie możesz nic zrobić - po prostu wysyła ruch do swoich backendów. Dzięki ProxySQL możesz kształtować ruch za pomocą reguł zapytań (dopasowywanie ruchu za pomocą wyrażeń regularnych, użytkownika, schematu, hosta źródłowego i wielu innych). Wybory OLAP SELECT można przekierować do modułu podrzędnego analizy (dotyczy to zarówno replikacji, jak i Galera). Możesz odciążyć swojego mastera, przekierowując niektóre z SELECTów z niego. Możesz zaimplementować zaporę SQL. Możesz dodać opóźnienie do niektórych zapytań, możesz zabić zapytania, jeśli zajmują więcej niż wstępnie zdefiniowany czas. Możesz przepisać zapytania, aby dodać wskazówki optymalizatora. Wszystko to nie jest możliwe z HAProxy.
Jak przeprowadzić migrację z HAProxy do ProxySQL?
Najpierw rozważmy następującą topologię...
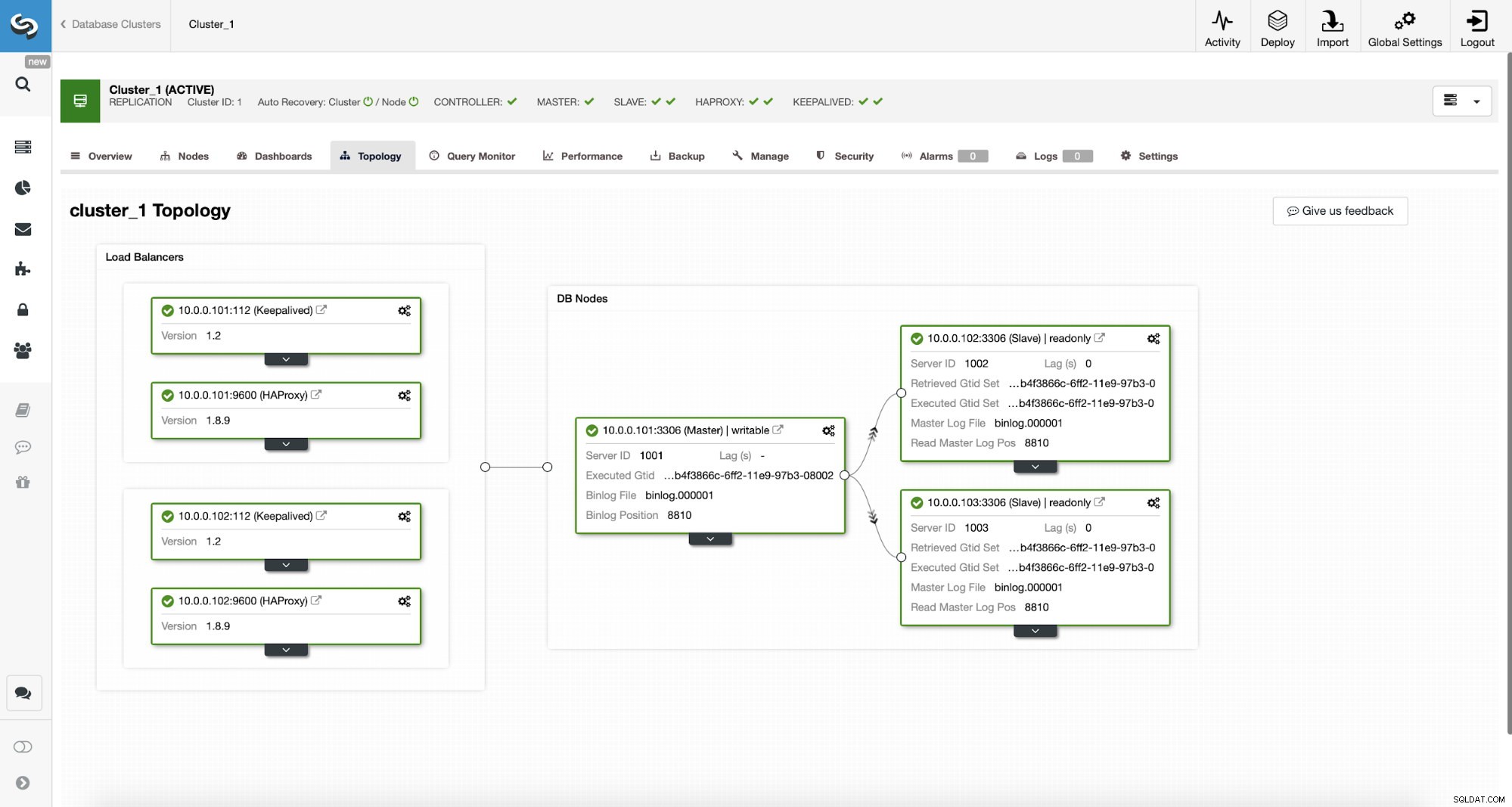 ClusterControl MySQL Topology
ClusterControl MySQL Topology 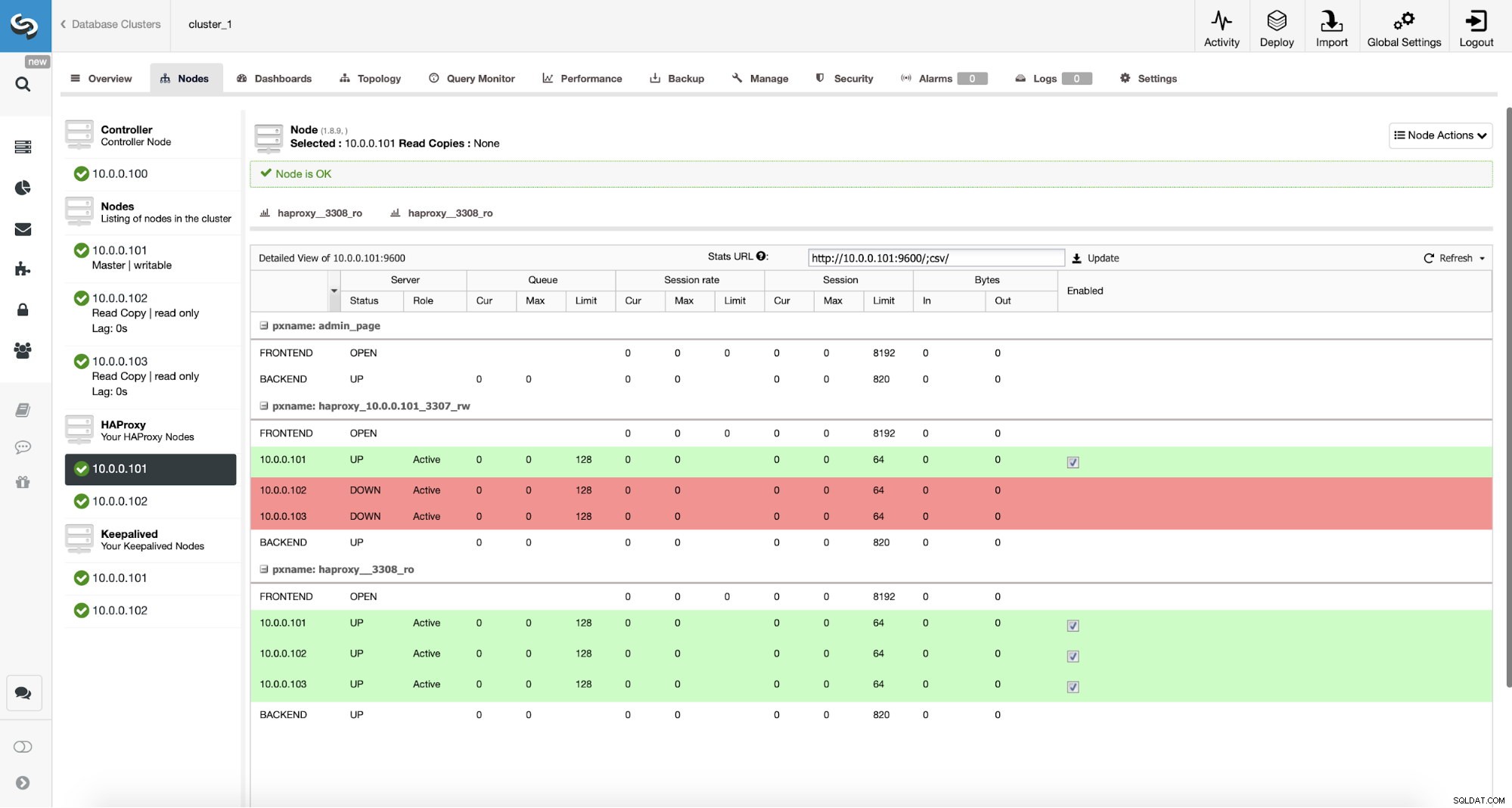 Klaster replikacji MySQL w ClusterControl
Klaster replikacji MySQL w ClusterControl Mamy tutaj klaster replikacyjny składający się z urządzenia nadrzędnego i dwóch podrzędnych. Mamy wdrożone dwa węzły HAProxy, każdy korzysta z dwóch backendów - na porcie 3307 dla mastera (zapis) i 3308 dla wszystkich węzłów (odczyt). Keepalived służy do zapewnienia wirtualnego adresu IP w tych dwóch instancjach HAProxy - jeśli jedna z nich zawiedzie, zostanie użyta kolejna. Nasza aplikacja łączy się bezpośrednio z VIP-em, za jego pośrednictwem do jednej z instancji HAProxy. Załóżmy, że nasza aplikacja (będziemy używać Sysbench) nie może wykonać podziału między odczyt-zapis, dlatego musimy połączyć się z backendem „writer”. W rezultacie większość obciążenia jest na naszym masterze (10.0.0.101).
Jakie byłyby kroki w celu migracji do ProxySQL? Zastanówmy się przez chwilę. Najpierw musimy wdrożyć i skonfigurować ProxySQL. Będziemy musieli dodać serwery do ProxySQL, stworzyć wymaganych użytkowników monitorujących i stworzyć odpowiednie reguły zapytań. Na koniec będziemy musieli wdrożyć Keepalive na ProxySQL, utworzyć kolejny wirtualny adres IP, a następnie zapewnić możliwie płynne przełączenie naszej aplikacji z HAProxy na ProxySQL.
Rzućmy okiem, jak możemy to osiągnąć...
Jak zainstalować ProxySQL
ProxySQL można zainstalować na wiele sposobów. Możesz użyć repozytorium, z samego ProxySQL (https://repo.proxysql.com) lub jeśli używasz Percona XtraDB Cluster, możesz również zainstalować ProxySQL z repozytorium Percona, chociaż może to wymagać dodatkowej konfiguracji, ponieważ opiera się na CLI narzędzia administracyjne stworzone dla PXC. Biorąc pod uwagę, że mówimy o replikacji, używanie ich może po prostu skomplikować sprawę. Na koniec możesz również zainstalować pliki binarne ProxySQL po pobraniu ich z ProxySQL GitHub. Obecnie istnieją dwie stabilne wersje, 1.4.xi 2.0.x. Istnieją różnice między ProxySQL 1.4 i ProxySQL 2.0 pod względem funkcji, w tym blogu będziemy trzymać się gałęzi 1.4.x, ponieważ jest lepiej przetestowana, a zestaw funkcji jest dla nas wystarczający.
Wykorzystamy repozytorium ProxySQL i wdrożymy ProxySQL na dwóch dodatkowych węzłach:10.0.0.103 i 10.0.0.104.
Najpierw zainstalujemy ProxySQL przy użyciu oficjalnego repozytorium. Upewnimy się również, że klient MySQL jest zainstalowany (wykorzystamy go do konfiguracji ProxySQL). Należy pamiętać, że proces, przez który przechodzimy, nie jest na poziomie produkcyjnym. W przypadku produkcji będziesz chciał przynajmniej zmienić domyślne poświadczenia dla użytkownika administracyjnego. Będziesz także chciał sprawdzić konfigurację i upewnić się, że jest zgodna z Twoimi oczekiwaniami i wymaganiami.
apt-get install -y lsb-release
wget -O - 'https://repo.proxysql.com/ProxySQL/repo_pub_key' | apt-key add -
echo deb https://repo.proxysql.com/ProxySQL/proxysql-1.4.x/$(lsb_release -sc)/ ./ | tee /etc/apt/sources.list.d/proxysql.list
apt-get -y update
apt-get -y install proxysql
service proxysql startTeraz, gdy ProxySQL został uruchomiony, użyjemy CLI do skonfigurowania ProxySQL.
mysql -uadmin -padmin -P6032 -h127.0.0.1Najpierw zdefiniujemy serwery zaplecza i grupy hostów replikacji:
mysql> INSERT INTO mysql_servers (hostgroup_id, hostname) VALUES (10, '10.0.0.101'), (20, '10.0.0.102'), (20, '10.0.0.103');
Query OK, 3 rows affected (0.91 sec)mysql> INSERT INTO mysql_replication_hostgroups (writer_hostgroup, reader_hostgroup) VALUES (10, 20);
Query OK, 1 row affected (0.00 sec)Mamy trzy serwery, zdefiniowaliśmy również, że ProxySQL powinien używać grupy hostów 10 dla mastera (węzeł z read_only=0) i grupy hostów 20 dla slave (tylko do odczytu=1).
W następnym kroku musimy dodać użytkownika monitorującego w węzłach MySQL, aby ProxySQL mógł je monitorować. Pójdziemy z ustawieniami domyślnymi, najlepiej, jeśli zmienisz dane uwierzytelniające w ProxySQL.
mysql> SHOW VARIABLES LIKE 'mysql-monitor_username';
+------------------------+---------+
| Variable_name | Value |
+------------------------+---------+
| mysql-monitor_username | monitor |
+------------------------+---------+
1 row in set (0.00 sec)mysql> SHOW VARIABLES LIKE 'mysql-monitor_password';
+------------------------+---------+
| Variable_name | Value |
+------------------------+---------+
| mysql-monitor_password | monitor |
+------------------------+---------+
1 row in set (0.00 sec)Musimy więc stworzyć użytkownika „monitor” z hasłem „monitor”. Aby to zrobić, będziemy musieli wykonać następujący grant na głównym serwerze MySQL:
mysql> create user example@sqldat.com'%' identified by 'monitor';
Query OK, 0 rows affected (0.56 sec)Wracając do ProxySQL - musimy skonfigurować użytkowników, których nasza aplikacja będzie używać do uzyskiwania dostępu do MySQL i reguł zapytań, które mają na celu zapewnienie podziału między odczytem a zapisem.
mysql> INSERT INTO mysql_users (username, password, default_hostgroup) VALUES ('sbtest', 'sbtest', 10);
Query OK, 1 row affected (0.34 sec)mysql> INSERT INTO mysql_query_rules (rule_id,active,match_digest,destination_hostgroup,apply) VALUES (100, 1, '^SELECT.*FOR UPDATE$',10,1), (200,1,'^SELECT',20,1), (300,1,'.*',10,1);
Query OK, 3 rows affected (0.01 sec)Należy pamiętać, że użyliśmy hasła w postaci zwykłego tekstu i będziemy polegać na ProxySQL, aby je hashować. Ze względów bezpieczeństwa powinieneś wyraźnie podać tutaj hash hasła MySQL.
Na koniec musimy zastosować wszystkie zmiany.
mysql> LOAD MYSQL SERVERS TO RUNTIME;
Query OK, 0 rows affected (0.02 sec)mysql> LOAD MYSQL USERS TO RUNTIME;
Query OK, 0 rows affected (0.01 sec)mysql> LOAD MYSQL QUERY RULES TO RUNTIME;
Query OK, 0 rows affected (0.01 sec)mysql> SAVE MYSQL SERVERS TO DISK;
Query OK, 0 rows affected (0.07 sec)mysql> SAVE MYSQL QUERY RULES TO DISK;
Query OK, 0 rows affected (0.02 sec)Chcemy również załadować zaszyfrowane hasła ze środowiska wykonawczego:hasła w postaci zwykłego tekstu są haszowane po załadowaniu do konfiguracji środowiska wykonawczego, aby zachować je na dysku, musimy je załadować ze środowiska wykonawczego, a następnie przechowywać na dysku:
mysql> SAVE MYSQL USERS FROM RUNTIME;
Query OK, 0 rows affected (0.00 sec)mysql> SAVE MYSQL USERS TO DISK;
Query OK, 0 rows affected (0.02 sec)To tyle, jeśli chodzi o ProxySQL. Przed podjęciem dalszych kroków sprawdź, czy możesz połączyć się z serwerami proxy z serwerów aplikacji.
example@sqldat.com:~# mysql -h 10.0.0.103 -usbtest -psbtest -P6033 -e "SELECT * FROM sbtest.sbtest4 LIMIT 1\G"
mysql: [Warning] Using a password on the command line interface can be insecure.
*************************** 1. row ***************************
id: 1
k: 50147
c: 68487932199-96439406143-93774651418-41631865787-96406072701-20604855487-25459966574-28203206787-41238978918-19503783441
pad: 22195207048-70116052123-74140395089-76317954521-98694025897W naszym przypadku wszystko wygląda dobrze. Teraz nadszedł czas, aby zainstalować Keepalived.
Utrzymana instalacja
Instalacja jest dość prosta (przynajmniej na Ubuntu 16.04, którego używaliśmy):
apt install keepalivedNastępnie musisz utworzyć pliki konfiguracyjne dla obu serwerów:
Główny węzeł podtrzymania aktywności:
vrrp_script chk_haproxy {
script "killall -0 haproxy" # verify the pid existance
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}
vrrp_instance VI_HAPROXY {
interface eth1 # interface to monitor
state MASTER
virtual_router_id 52 # Assign one ID for this route
priority 101
unicast_src_ip 10.0.0.103
unicast_peer {
10.0.0.104
}
virtual_ipaddress {
10.0.0.112 # the virtual IP
}
track_script {
chk_haproxy
}
# notify /usr/local/bin/notify_keepalived.sh
}Zapasowy węzeł podtrzymania aktywności:
vrrp_script chk_haproxy {
script "killall -0 haproxy" # verify the pid existance
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}
vrrp_instance VI_HAPROXY {
interface eth1 # interface to monitor
state MASTER
virtual_router_id 52 # Assign one ID for this route
priority 100
unicast_src_ip 10.0.0.103
unicast_peer {
10.0.0.104
}
virtual_ipaddress {
10.0.0.112 # the virtual IP
}
track_script {
chk_haproxy
}
# notify /usr/local/bin/notify_keepalived.shTo jest to, możesz zacząć utrzymywać aktywność na obu węzłach:
service keepalived startW dziennikach powinna pojawić się informacja, że jeden z węzłów wszedł w stan MASTER i że na tym węźle pojawił się VIP.
May 7 09:52:11 vagrant systemd[1]: Starting Keepalive Daemon (LVS and VRRP)...
May 7 09:52:11 vagrant Keepalived[26686]: Starting Keepalived v1.2.24 (08/06,2018)
May 7 09:52:11 vagrant Keepalived[26686]: Opening file '/etc/keepalived/keepalived.conf'.
May 7 09:52:11 vagrant Keepalived[26696]: Starting Healthcheck child process, pid=26697
May 7 09:52:11 vagrant Keepalived[26696]: Starting VRRP child process, pid=26698
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Initializing ipvs
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Registering Kernel netlink reflector
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Registering Kernel netlink command channel
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Registering gratuitous ARP shared channel
May 7 09:52:11 vagrant systemd[1]: Started Keepalive Daemon (LVS and VRRP).
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Unable to load ipset library
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Unable to initialise ipsets
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Opening file '/etc/keepalived/keepalived.conf'.
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: Using LinkWatch kernel netlink reflector...
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Registering Kernel netlink reflector
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Registering Kernel netlink command channel
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Opening file '/etc/keepalived/keepalived.conf'.
May 7 09:52:11 vagrant Keepalived_healthcheckers[26697]: Using LinkWatch kernel netlink reflector...
May 7 09:52:11 vagrant Keepalived_vrrp[26698]: pid 26701 exited with status 256
May 7 09:52:12 vagrant Keepalived_vrrp[26698]: VRRP_Instance(VI_HAPROXY) Transition to MASTER STATE
May 7 09:52:13 vagrant Keepalived_vrrp[26698]: pid 26763 exited with status 256
May 7 09:52:13 vagrant Keepalived_vrrp[26698]: VRRP_Instance(VI_HAPROXY) Entering MASTER STATE
May 7 09:52:15 vagrant Keepalived_vrrp[26698]: pid 26806 exited with status 256example@sqldat.com:~# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:ee:87:c4 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.15/24 brd 10.0.2.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:feee:87c4/64 scope link
valid_lft forever preferred_lft forever
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 08:00:27:fc:ac:21 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.103/24 brd 10.0.0.255 scope global eth1
valid_lft forever preferred_lft forever
inet 10.0.0.112/32 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::a00:27ff:fefc:ac21/64 scope link
valid_lft forever preferred_lft foreverJak widać, w węźle 10.0.0.103 został podniesiony VIP (10.0.0.112). Możemy teraz zakończyć przeniesieniem ruchu ze starej konfiguracji do nowej.
Przełączanie ruchu do konfiguracji ProxySQL
Istnieje wiele metod, jak to zrobić, w większości zależy to od konkretnego środowiska. Jeśli zdarzy ci się używać DNS do utrzymywania domeny wskazującej na Twój VIP HAProxy, możesz po prostu wprowadzić tam zmianę i stopniowo, z biegiem czasu, wszystkie połączenia będą przekierowywać do nowego VIP. Możesz także dokonać zmiany w swojej aplikacji, zwłaszcza jeśli szczegóły połączenia są zakodowane na stałe – po wdrożeniu zmiany węzły zaczną łączyć się z nową konfiguracją. Bez względu na to, jak to zrobisz, byłoby wspaniale przetestować nową konfigurację przed dokonaniem globalnego przełączenia. Na pewno przetestowałeś to na swoim środowisku pomostowym, ale nie jest złym pomysłem wybranie kilku serwerów aplikacji i przekierowanie ich do nowego serwera proxy, monitorując, jak wyglądają pod względem wydajności. Poniżej znajduje się prosty przykład wykorzystania iptables, który może być przydatny do testowania.
Na hostach ProxySQL przekieruj ruch z hosta 10.0.0.11 i portu 3307 do hosta 10.0.0.112 i portu 6033:
iptables -t nat -A OUTPUT -p tcp -d 10.0.0.111 --dport 3307 -j DNAT --to-destination 10.0.0.112:6033W zależności od aplikacji może być konieczne ponowne uruchomienie serwera WWW lub innych usług (jeśli Twoja aplikacja tworzy stałą pulę połączeń z bazą danych) lub po prostu poczekaj, aż nowe połączenia zostaną otwarte dla ProxySQL. Możesz sprawdzić, czy ProxySQL odbiera ruch:
mysql> show processlist;
+-----------+--------+--------+-----------+---------+---------+-----------------------------------------------------------------------------+
| SessionID | user | db | hostgroup | command | time_ms | info |
+-----------+--------+--------+-----------+---------+---------+-----------------------------------------------------------------------------+
| 12 | sbtest | sbtest | 20 | Sleep | 0 | |
| 13 | sbtest | sbtest | 10 | Query | 0 | DELETE FROM sbtest23 WHERE id=49957 |
| 14 | sbtest | sbtest | 10 | Query | 59 | DELETE FROM sbtest11 WHERE id=50185 |
| 15 | sbtest | sbtest | 20 | Query | 59 | SELECT c FROM sbtest8 WHERE id=46054 |
| 16 | sbtest | sbtest | 20 | Query | 0 | SELECT DISTINCT c FROM sbtest27 WHERE id BETWEEN 50115 AND 50214 ORDER BY c |
| 17 | sbtest | sbtest | 10 | Query | 0 | DELETE FROM sbtest32 WHERE id=50084 |
| 18 | sbtest | sbtest | 10 | Query | 26 | DELETE FROM sbtest28 WHERE id=34611 |
| 19 | sbtest | sbtest | 10 | Query | 16 | DELETE FROM sbtest4 WHERE id=50151 |
+-----------+--------+--------+-----------+---------+---------+-----------------------------------------------------------------------------+To wszystko, przenieśliśmy ruch z HAProxy do konfiguracji ProxySQL. Wymagało to kilku kroków, ale zdecydowanie jest to wykonalne przy bardzo niewielkich zakłóceniach w działaniu usługi.
Jak przeprowadzić migrację z HAProxy do ProxySQL za pomocą ClusterControl?
W poprzedniej sekcji wyjaśniliśmy, jak ręcznie wdrożyć konfigurację ProxySQL, a następnie przeprowadzić do niej migrację. W tej sekcji chcielibyśmy wyjaśnić, jak osiągnąć ten sam cel za pomocą ClusterControl. Początkowa konfiguracja jest dokładnie taka sama, dlatego musimy kontynuować wdrażanie ProxySQL.
Wdrażanie ProxySQL za pomocą ClusterControl
Wdrożenie ProxySQL w ClusterControl to tylko kwestia kilku kliknięć.
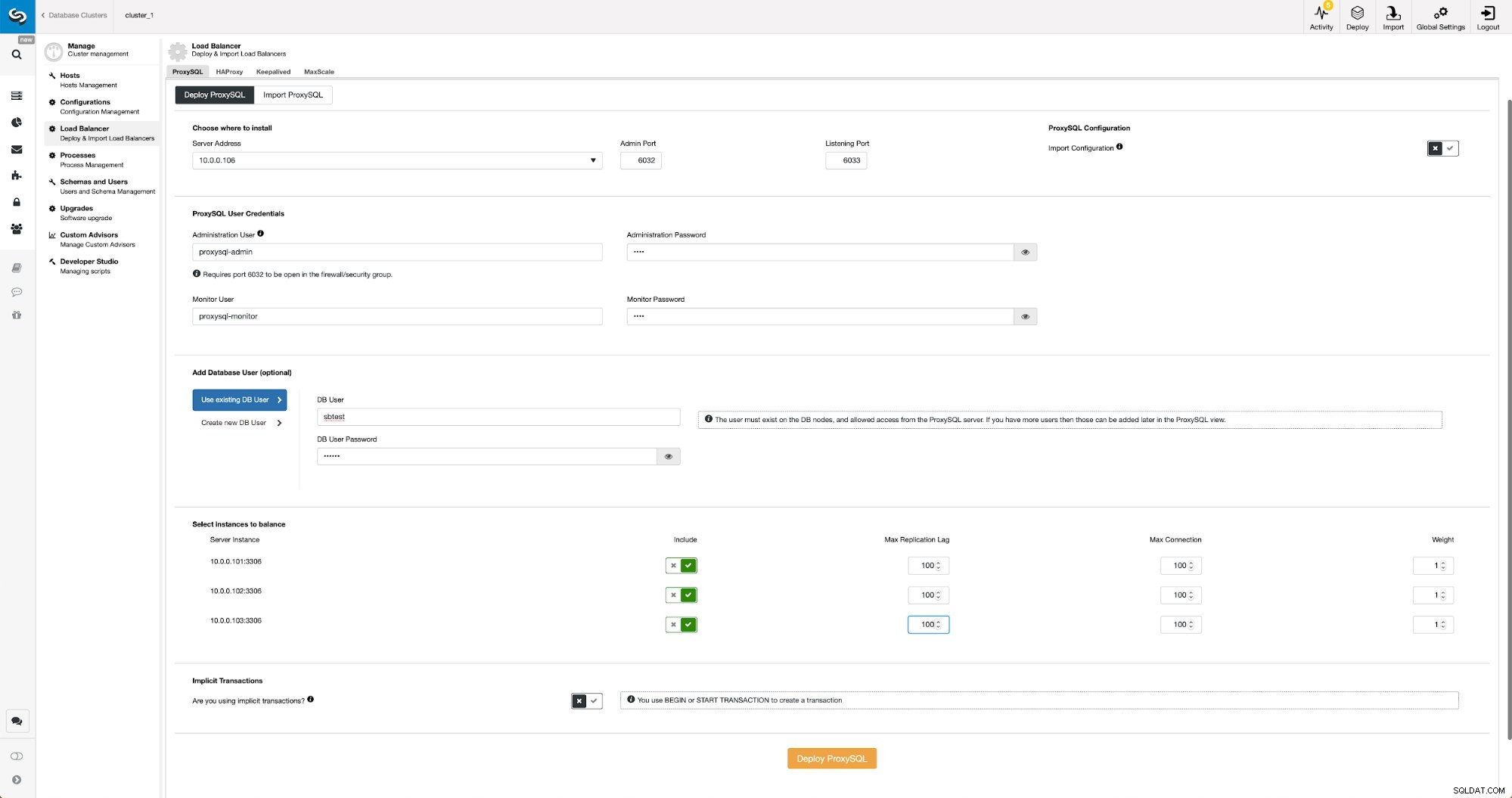 Wdróż ProxySQL w ClusterControl
Wdróż ProxySQL w ClusterControl Musieliśmy wybrać adres IP lub nazwę hosta węzła, przekazać dane uwierzytelniające dla użytkownika administracyjnego CLI i użytkownika monitorującego MySQL. Zdecydowaliśmy się na wykorzystanie istniejącego MySQL i przekazaliśmy dane dostępowe dla użytkownika „sbtest”@”%”, którego używamy w aplikacji. Wybraliśmy, które węzły chcemy użyć w load balancerze, zwiększyliśmy również maksymalne opóźnienie replikacji (jeśli ten próg zostanie przekroczony, ProxySQL nie wyśle ruchu do tego slave) z domyślnych 10 sekund do 100, ponieważ już cierpimy z powodu replikacji opóźnienie. Po chwili węzły ProxySQL zostaną dodane do klastra.
Wdrażanie Keepalive dla ProxySQL przy użyciu ClusterControl
Po dodaniu węzłów ProxySQL nadszedł czas na wdrożenie Keepalive.
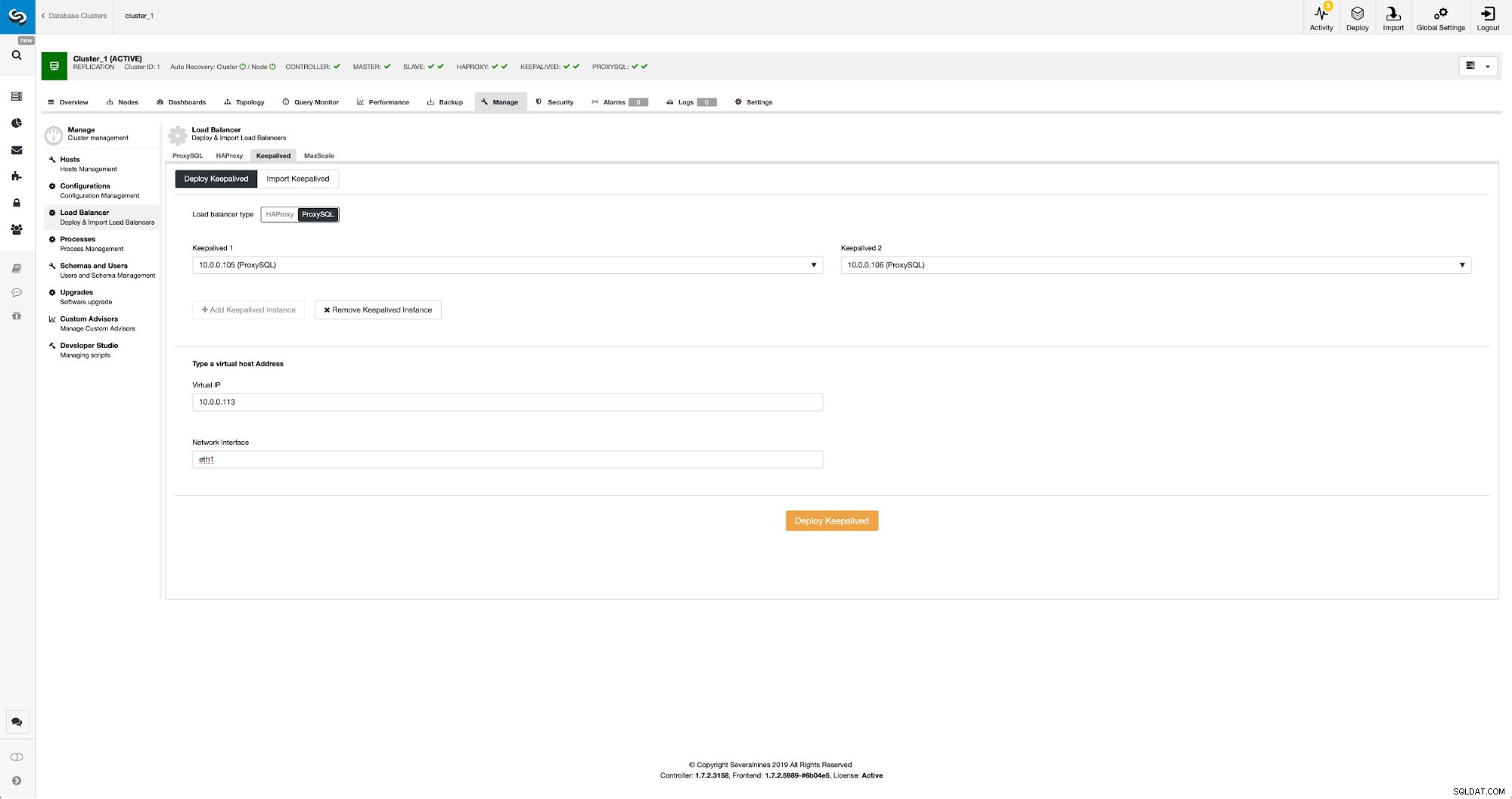 Zachowaj z ProxySQL w ClusterControl
Zachowaj z ProxySQL w ClusterControl Wszystko, co musieliśmy zrobić, to wybrać węzły ProxySQL, na których chcemy wdrożyć Keepalived, wirtualny adres IP i interfejs, z którym będzie powiązany VIP. Po zakończeniu wdrażania przełączymy ruch do nowej konfiguracji za pomocą jednej z metod wymienionych w sekcji „Przełączanie ruchu do konfiguracji ProxySQL” powyżej.
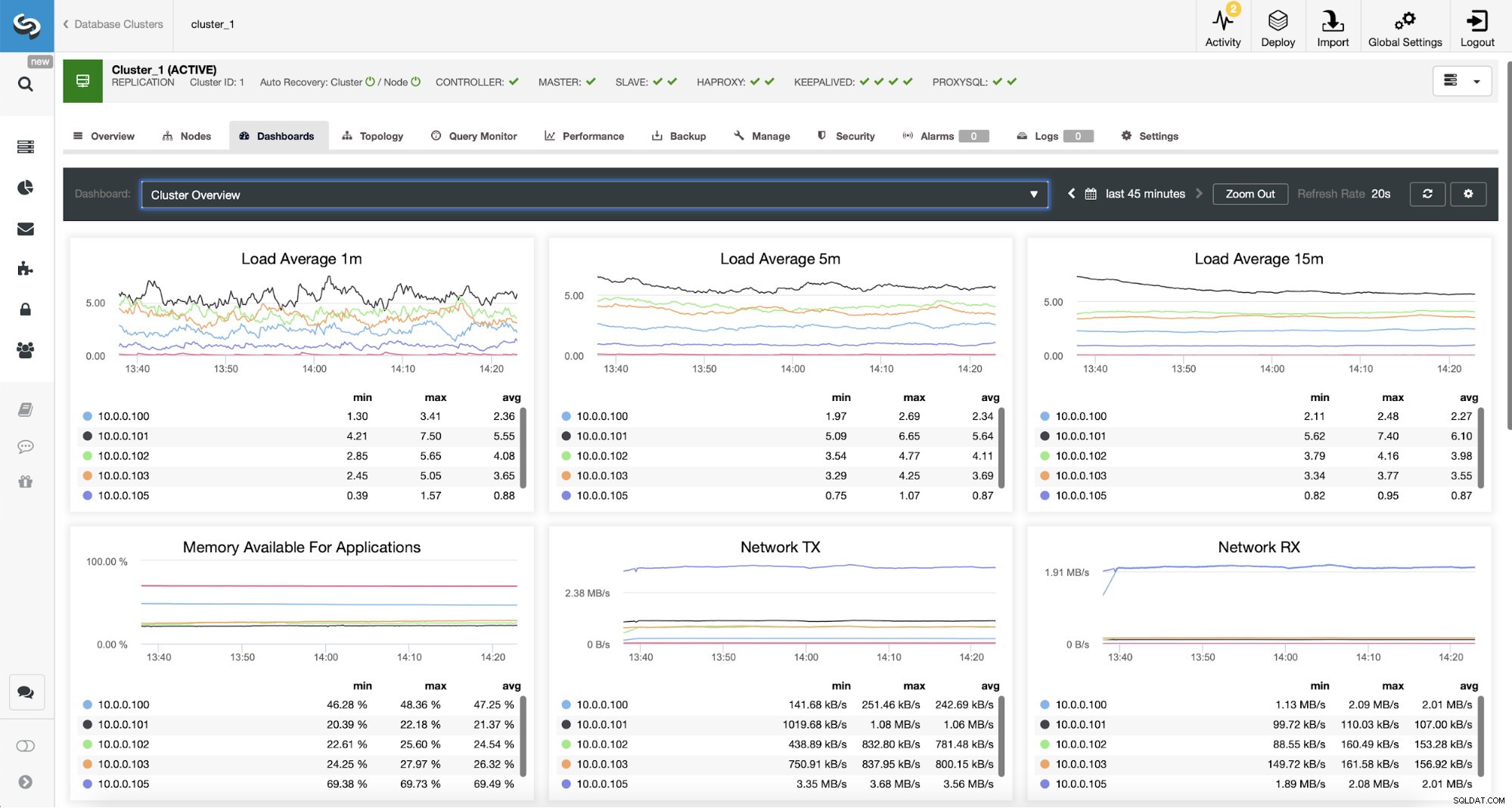 Monitorowanie ruchu ProxySQL w ClusterControl
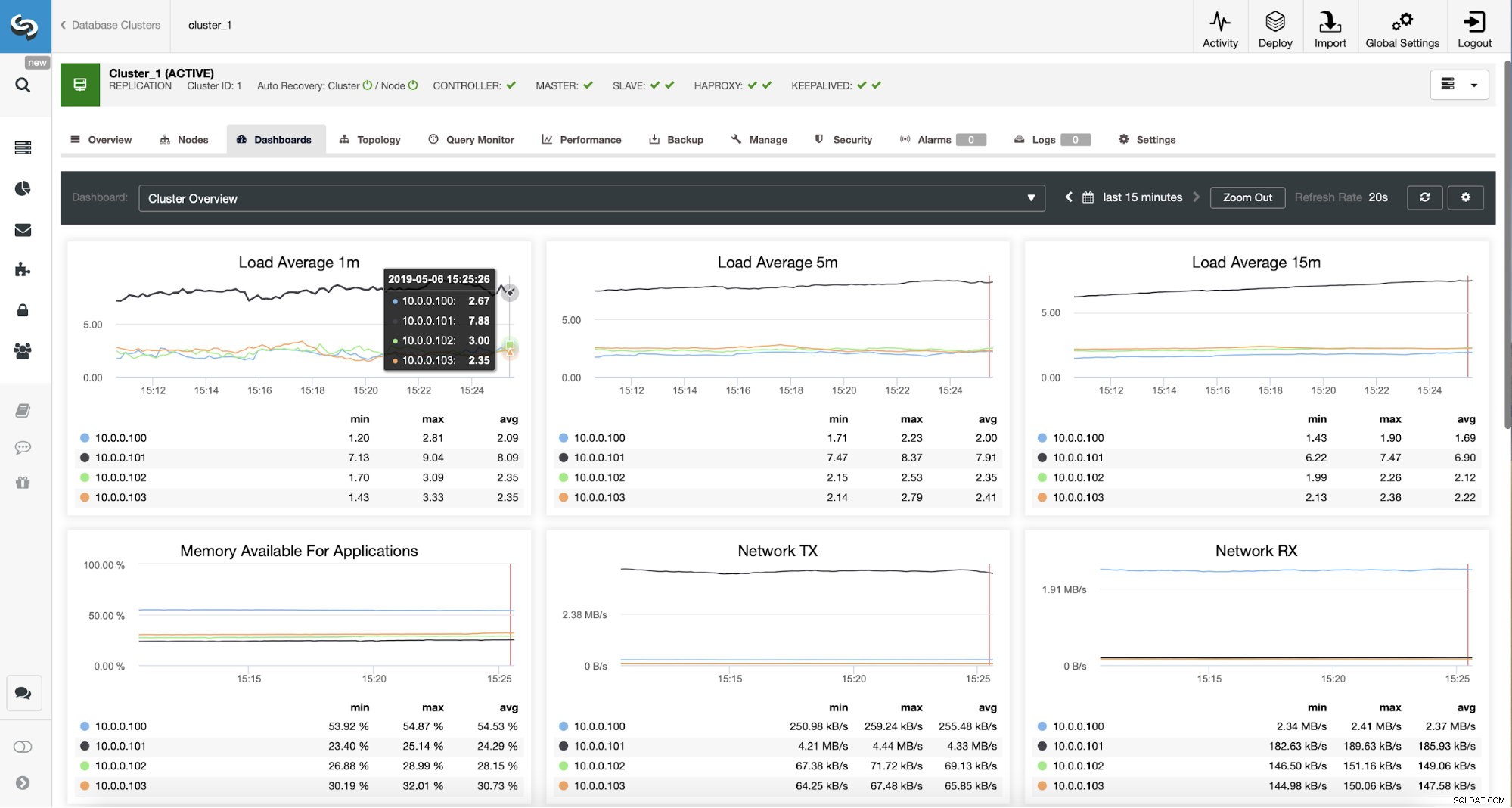
Monitorowanie ruchu ProxySQL w ClusterControl Możemy zweryfikować, czy ruch przeszedł do ProxySQL, patrząc na wykres obciążenia - jak widać, obciążenie jest znacznie bardziej rozłożone na węzły w klastrze. Możesz to również zobaczyć na poniższym wykresie, który pokazuje rozkład zapytań w klastrze.
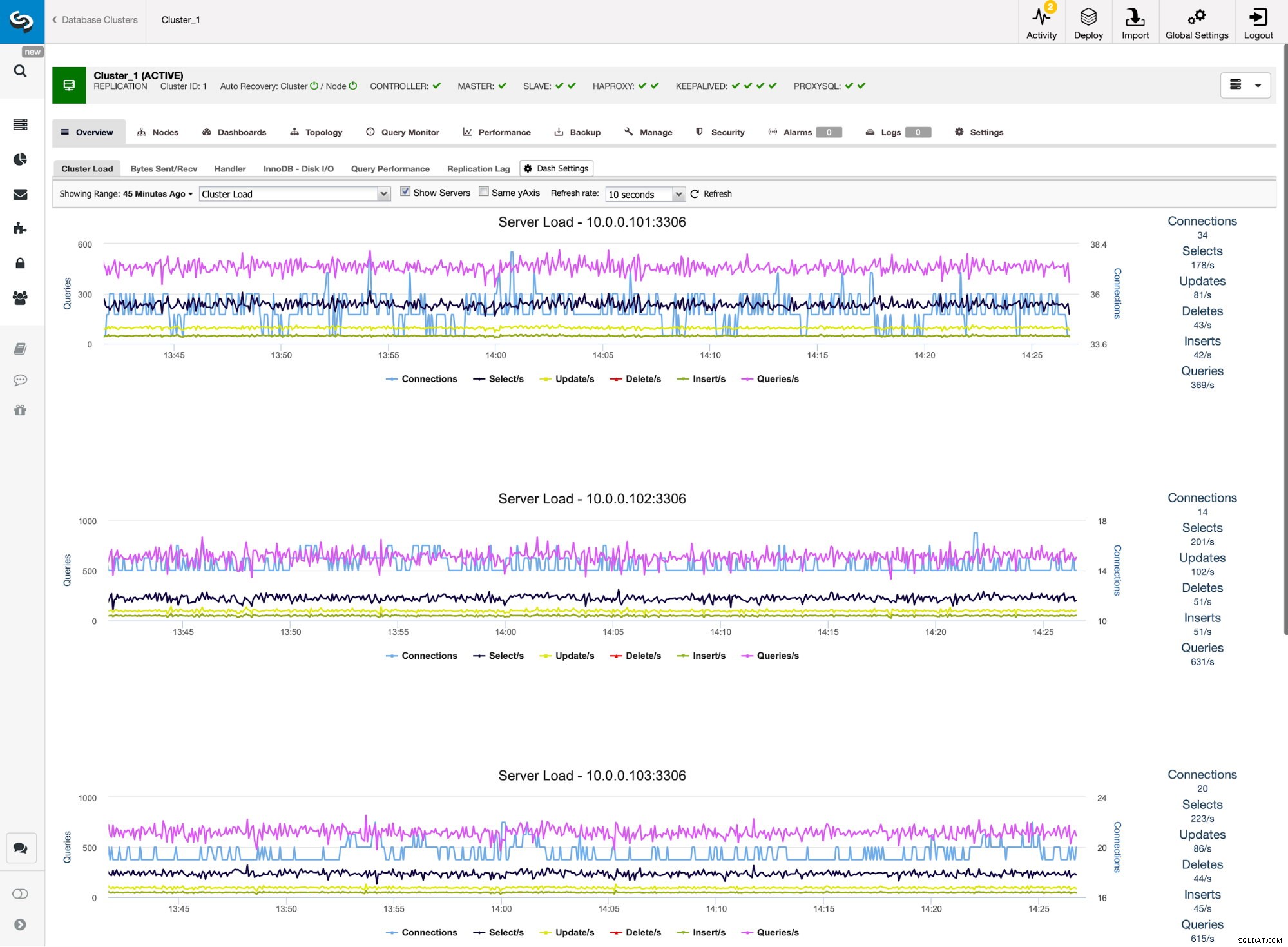 Panel ProxySQL w ClusterControl
Panel ProxySQL w ClusterControl Wreszcie, pulpit nawigacyjny ProxySQL pokazuje również, że ruch jest rozłożony na wszystkie węzły w klastrze:
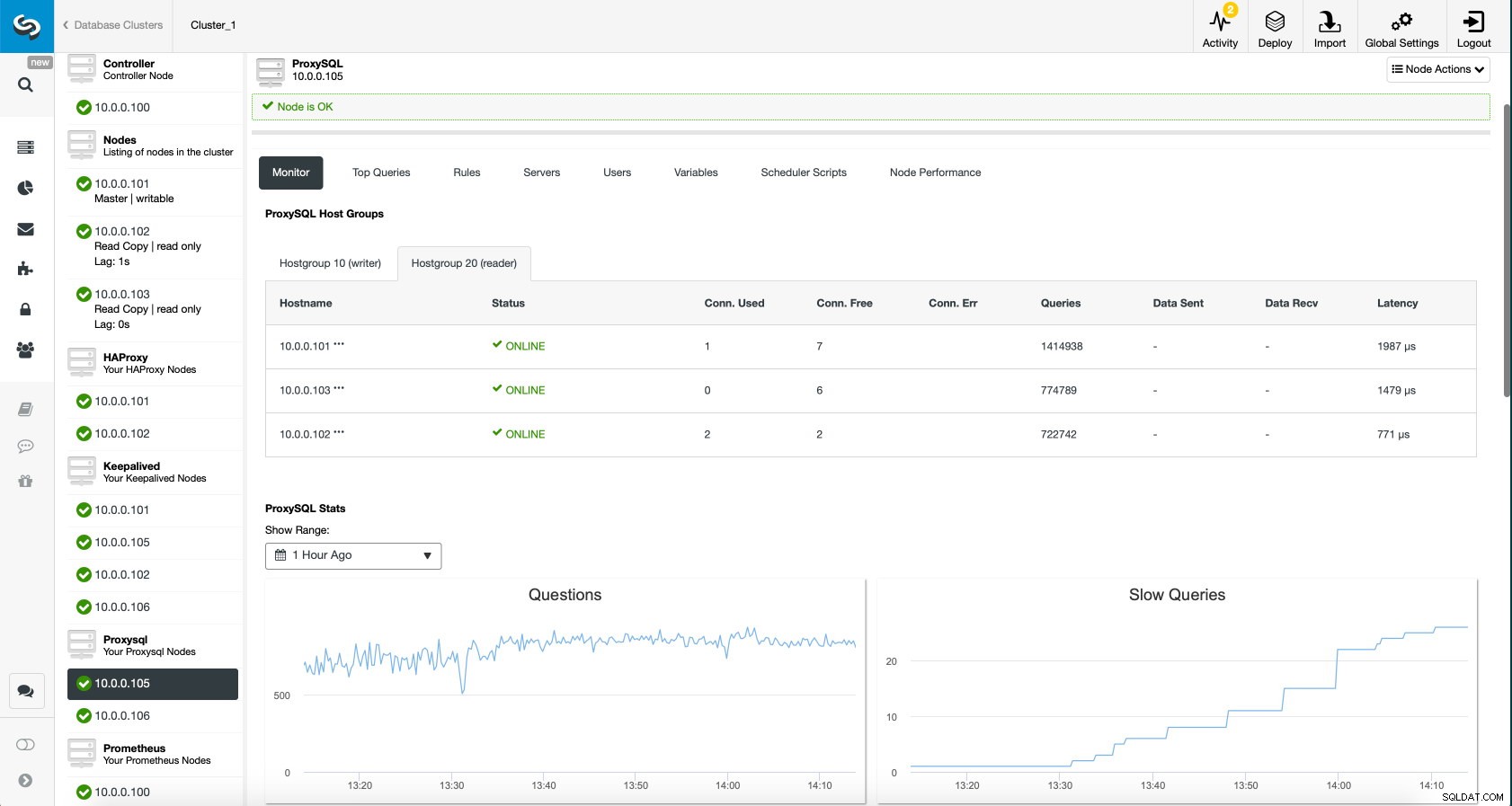 Panel ProxySQL w ClusterControl
Panel ProxySQL w ClusterControl Mamy nadzieję, że ten wpis na blogu przyniesie Ci korzyści, ponieważ ClusterControl wdrożenie nowej architektury zajmuje tylko chwilę i wymaga tylko kilku kliknięć, aby wszystko działało. Daj nam znać o swoich doświadczeniach z takimi migracjami.