Każde dochodowe przedsiębiorstwo wymaga wysokiej dostępności. Witryny i blogi nie różnią się od siebie, ponieważ nawet mniejsze firmy i osoby prywatne wymagają, aby ich witryny pozostały aktywne, aby zachować reputację.
WordPress jest zdecydowanie najpopularniejszym systemem CMS na świecie obsługującym miliony stron internetowych, od małych po duże. Ale jak możesz zapewnić, że Twoja witryna pozostanie aktywna. Mówiąc dokładniej, jak mogę zapewnić, że niedostępność mojej bazy danych nie wpłynie na moją witrynę?
W tym poście na blogu pokażemy, jak uzyskać przełączanie awaryjne witryny WordPress za pomocą ClusterControl.
Konfiguracja, której użyjemy w tym blogu, będzie korzystała z Percona Server 5.7. Będziemy mieli innego hosta, który zawiera aplikacje Apache i Wordpress. Nie będziemy dotykać części wysokiej dostępności aplikacji, ale to również coś, co chcesz mieć. Użyjemy ClusterControl do zarządzania bazami danych w celu zapewnienia dostępności, a trzeciego hosta użyjemy do zainstalowania i skonfigurowania samego ClusterControl.
Zakładając, że ClusterControl jest już uruchomiony, będziemy musieli zaimportować do niego naszą istniejącą bazę danych.
Importowanie klastra bazy danych za pomocą ClusterControl
Przejdź do opcji Importuj istniejący serwer/bazę danych w kreatorze wdrażania.
Musimy skonfigurować łączność SSH, ponieważ jest to wymagane przez ClusterControl do być w stanie zarządzać węzłami.
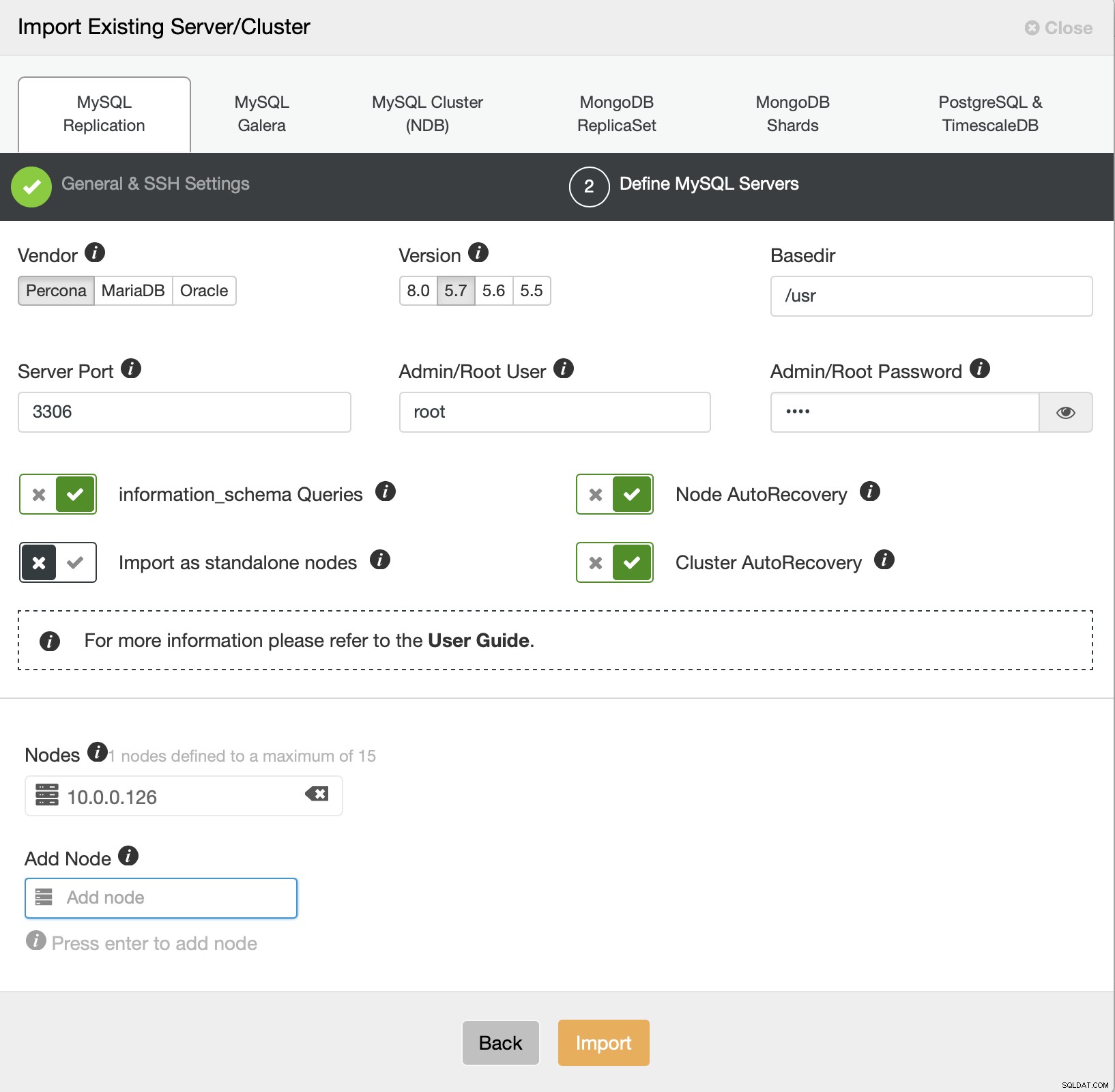
Teraz musimy zdefiniować pewne szczegóły dotyczące dostawcy, wersji, użytkownika root dostęp, sam węzeł i czy chcemy, aby ClusterControl zarządzał automatycznym odzyskiwaniem za nas, czy nie. To wszystko, gdy zadanie się powiedzie, pojawi się klaster na liście.
Aby skonfigurować wysoce dostępne środowisko, musimy wykonać kilka działań. Nasze środowisko będzie składać się z...
- Para Master - Slave
- Dwie instancje ProxySQL do podziału odczytu/zapisu i wykrywania topologii
- Dwie instancje Keepalved do zarządzania wirtualnym adresem IP
Pomysł jest prosty - wdrożymy slave'a do naszego mastera, więc będziemy mieli drugą instancję do przełączenia awaryjnego w przypadku awarii mastera. ClusterControl będzie odpowiedzialny za wykrywanie awarii i będzie promować urządzenie podrzędne, jeśli master stanie się niedostępny. ProxySQL będzie śledzić topologię replikacji i przekieruje ruch do właściwego węzła - zapisy będą wysyłane do mastera, bez względu na to, w którym węźle się znajduje, odczyty mogą być wysyłane do mastera lub rozproszone na master i slave . Wreszcie, Keepalived będzie łączony z ProxySQL i zapewni VIP dla aplikacji, z którą będzie się łączyć. Ten VIP będzie zawsze przypisany do jednej z instancji ProxySQL, a Keepalived przeniesie go do drugiej, jeśli „główny” węzeł ProxySQL ulegnie awarii.
Po tym wszystkim skonfigurujmy to za pomocą ClusterControl. Wszystko to można zrobić za pomocą kilku kliknięć. Zaczniemy od dodania urządzenia podrzędnego.
Dodawanie bazy danych Slave za pomocą ClusterControl

Zaczynamy od wybrania zadania „Dodaj moduł replikacji”. Następnie prosimy o wypełnienie formularza:
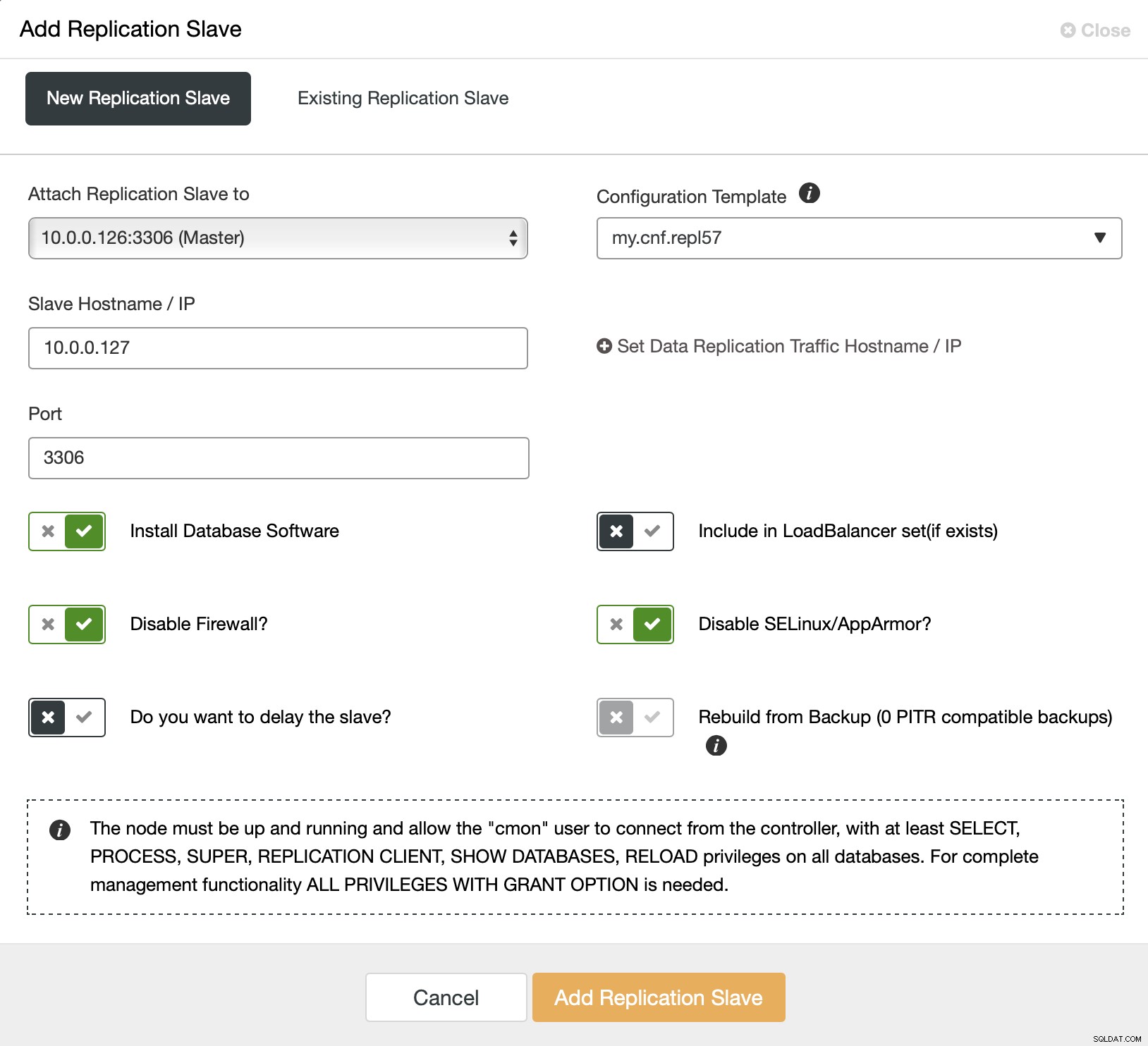
Musimy wybrać mistrza (w naszym przypadku nie mamy wiele opcji), musimy przekazać adres IP lub nazwę hosta dla nowego urządzenia podrzędnego. Gdybyśmy mieli wcześniej utworzone kopie zapasowe, moglibyśmy użyć jednej z nich do zaopatrywania slave'a. W naszym przypadku nie jest to dostępne, a ClusterControl udostępni urządzenie podrzędne bezpośrednio z urządzenia nadrzędnego. To wszystko, zadanie rozpoczyna się, a ClusterControl wykonuje wymagane działania. Możesz monitorować postęp w zakładce Aktywność.

Na koniec, po pomyślnym zakończeniu zadania, urządzenie podrzędne powinno być widoczne na lista klastrów.

Teraz przystąpimy do konfigurowania instancji ProxySQL. W naszym przypadku środowisko jest minimalne, więc dla uproszczenia umieścimy ProxySQL na jednym z węzłów bazy danych. Nie jest to jednak najlepsza opcja w rzeczywistym środowisku produkcyjnym. Idealnie byłoby, gdyby ProxySQL znajdował się w oddzielnym węźle lub był skolokowany z innymi hostami aplikacji.
Miejscem do rozpoczęcia zadania jest Zarządzanie -> Systemy równoważenia obciążenia.
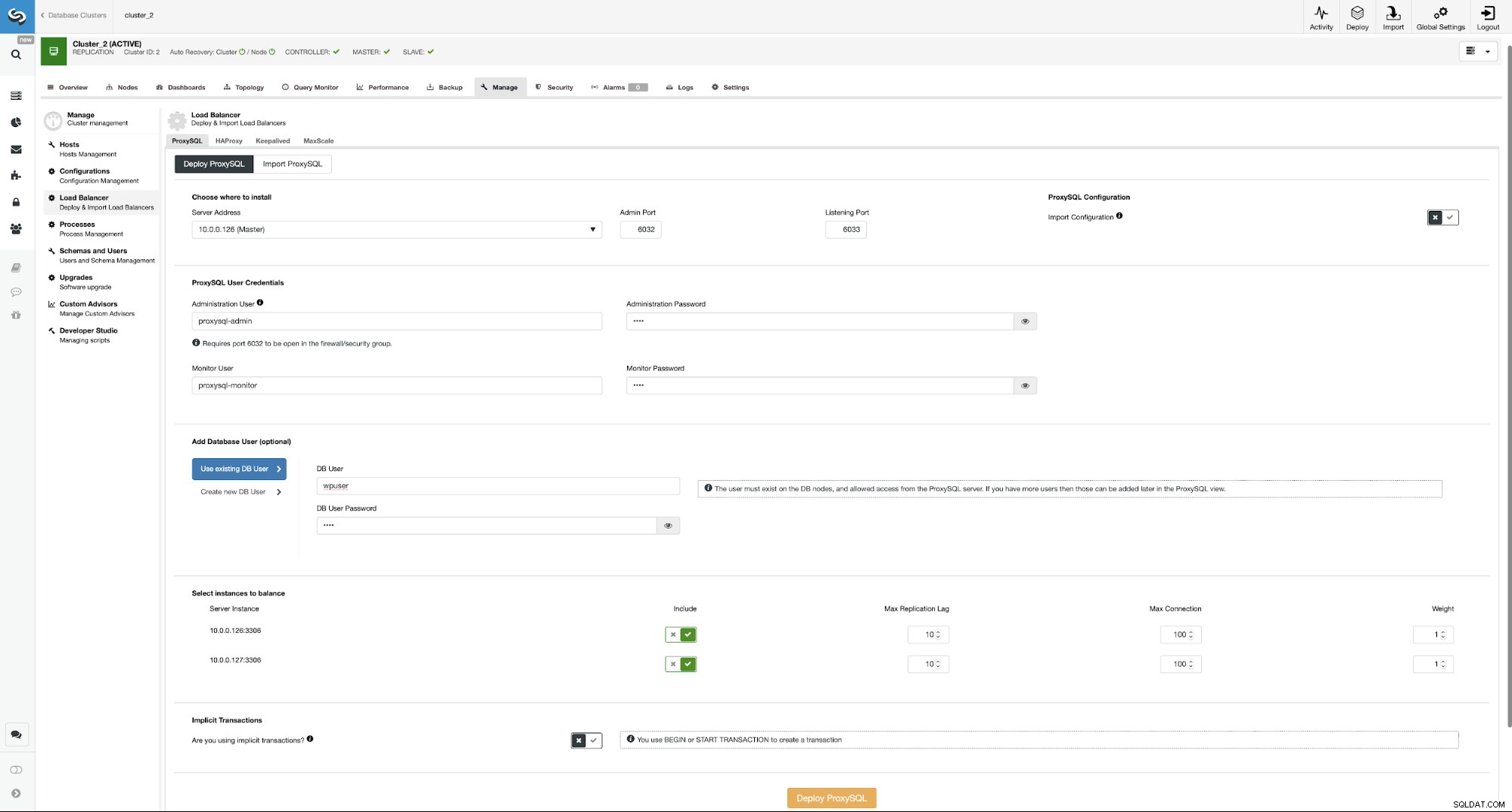
Tutaj musisz wybrać miejsce instalacji ProxySQL, przekazać poświadczenia administracyjne i dodaj użytkownika bazy danych. W naszym przypadku użyjemy naszego istniejącego użytkownika, ponieważ nasza aplikacja WordPress już używa go do łączenia się z bazą danych. Następnie musimy wybrać, które węzły mają być używane w ProxySQL (chcemy tutaj zarówno master, jak i slave) i poinformować ClusterControl, czy używamy jawnych transakcji, czy nie. W naszym przypadku nie ma to większego znaczenia, ponieważ ponownie skonfigurujemy ProxySQL po jego wdrożeniu. Gdy ta opcja jest włączona, podział odczytu/zapisu nie będzie włączony. W przeciwnym razie ClusterControl skonfiguruje ProxySQL do podziału odczytu/zapisu. W naszej minimalnej konfiguracji powinniśmy poważnie zastanowić się, czy chcemy, aby nastąpił podział odczytu/zapisu. Przeanalizujmy to.
Zalety i wady odczytu/zapisu Spit w ProxySQL
Główną zaletą korzystania z podziału odczytu/zapisu jest to, że cały ruch SELECT będzie dzielony między master i slave. Oznacza to, że obciążenie węzłów będzie mniejsze, a czas odpowiedzi również powinien być niższy. Brzmi to dobrze, ale pamiętaj, że jeśli jeden węzeł ulegnie awarii, drugi węzeł będzie musiał być w stanie obsłużyć cały ruch. Automatyczne przełączanie awaryjne nie ma sensu, jeśli utrata jednego węzła oznacza, że drugi węzeł będzie przeciążony i de facto również niedostępny.
Rozłożenie obciążenia może mieć sens, jeśli masz wiele urządzeń podrzędnych — utrata jednego węzła z pięciu ma mniejszy wpływ niż utrata jednego z dwóch. Bez względu na to, na co się zdecydujesz, możesz łatwo zmienić zachowanie, przechodząc do węzła ProxySQL i klikając kartę Reguły.
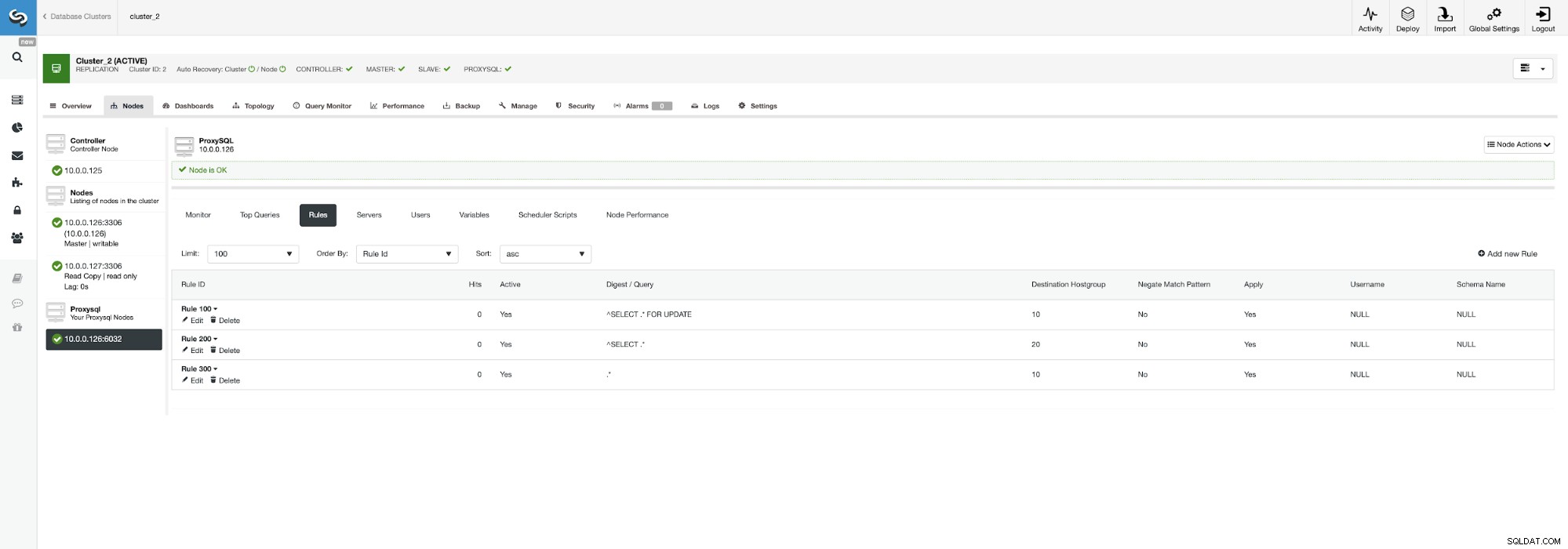
Pamiętaj, aby spojrzeć na regułę 200 (tę, która przechwytuje wszystkie instrukcje SELECT ). Na poniższym zrzucie ekranu widać, że docelowa grupa hostów to 20, co oznacza, że wszystkie węzły w klastrze — podział odczytu/zapisu i skalowanie w poziomie są włączone. Możemy to łatwo wyłączyć, edytując tę regułę i zmieniając Docelową grupę hostów na 10 (tę, która zawiera master).
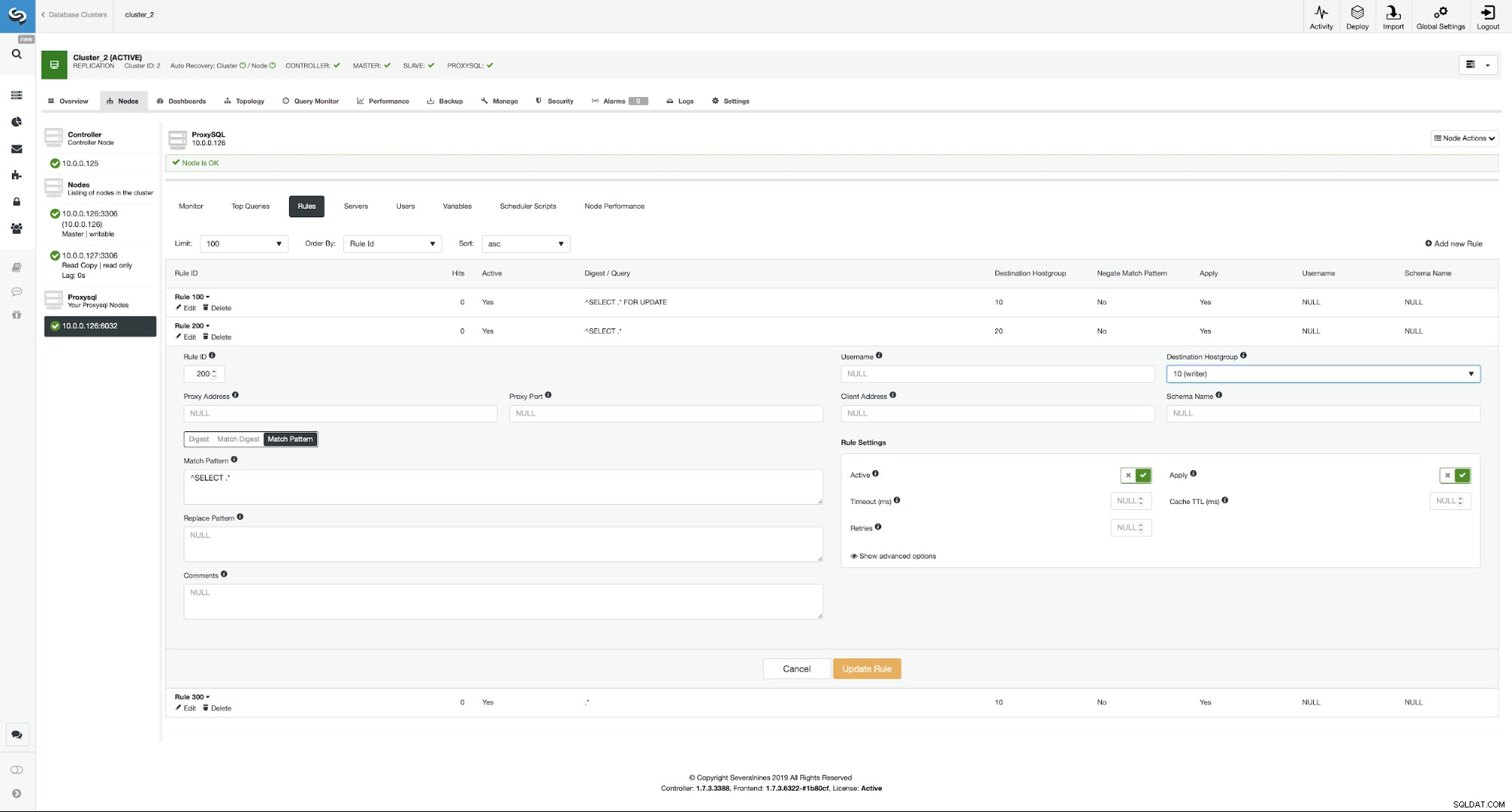
Jeśli chcesz włączyć podział odczytu/zapisu, możesz łatwo zrób to, ponownie edytując tę regułę zapytania i ustawiając docelową grupę hostów z powrotem na 20.
Teraz wdrożmy drugi serwer ProxySQL.
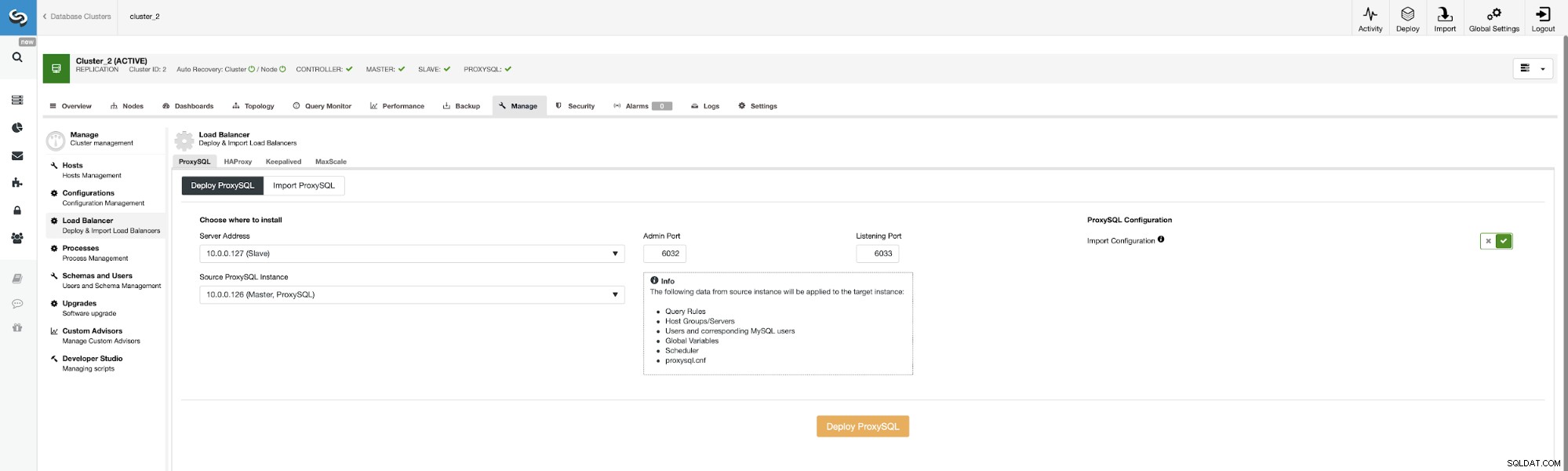
Aby uniknąć ponownego przekazywania wszystkich opcji konfiguracyjnych, możemy użyć opcji „Importuj konfigurację ” i wybierz nasz istniejący serwer ProxySQL jako źródło.
Kiedy to zadanie zostanie zakończone, nadal musimy wykonać ostatni krok w ustawianiu naszego środowiska. Musimy wdrożyć Keepalived na instancjach ProxySQL.
Wdrażanie funkcji Keepalive na wierzchu instancji ProxySQL
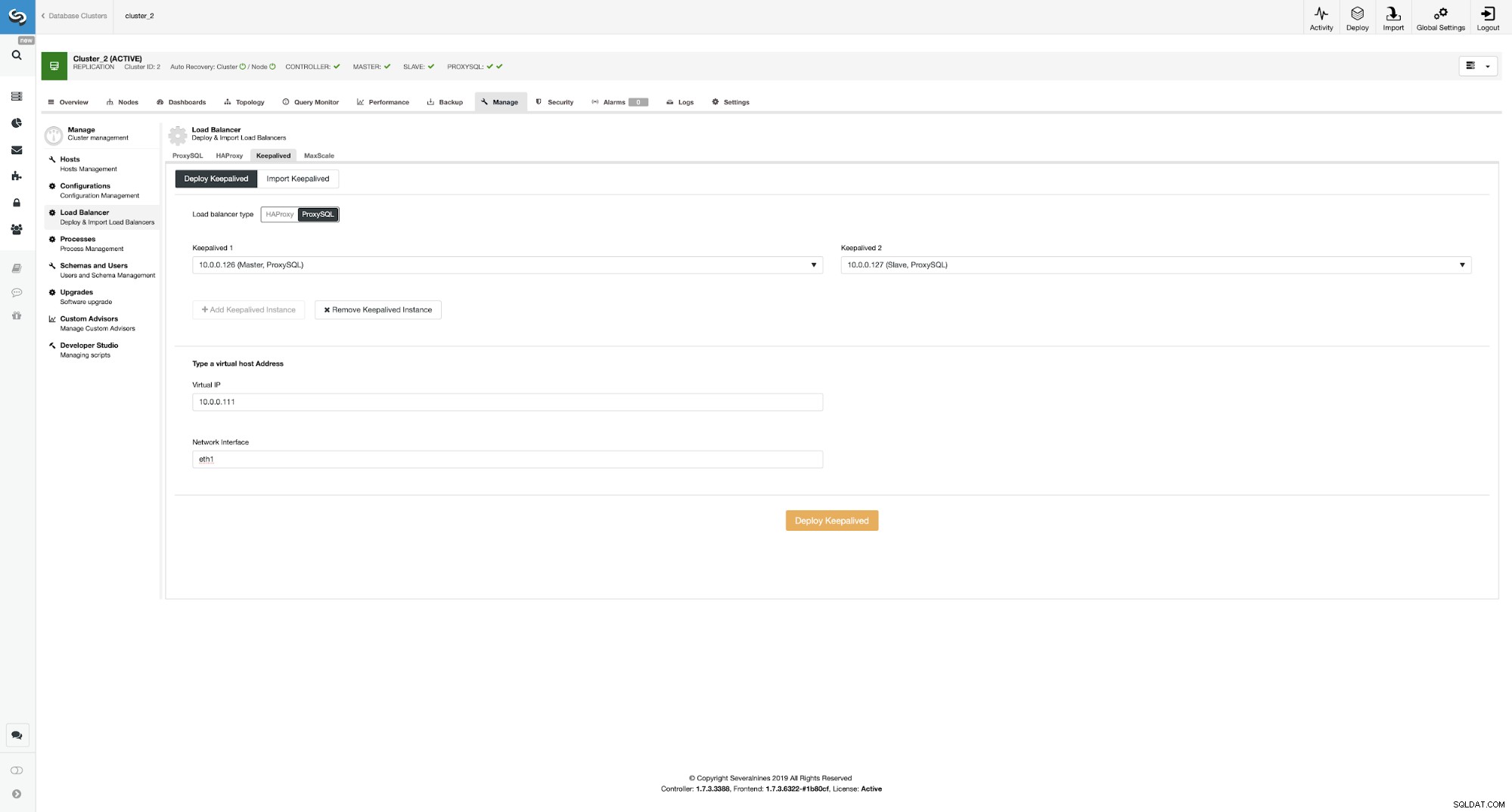
Tutaj wybraliśmy ProxySQL jako typ równoważenia obciążenia, przekazaliśmy obie instancje ProxySQL dla Pozostawiony do zainstalowania i wpisaliśmy nasz VIP i interfejs sieciowy.
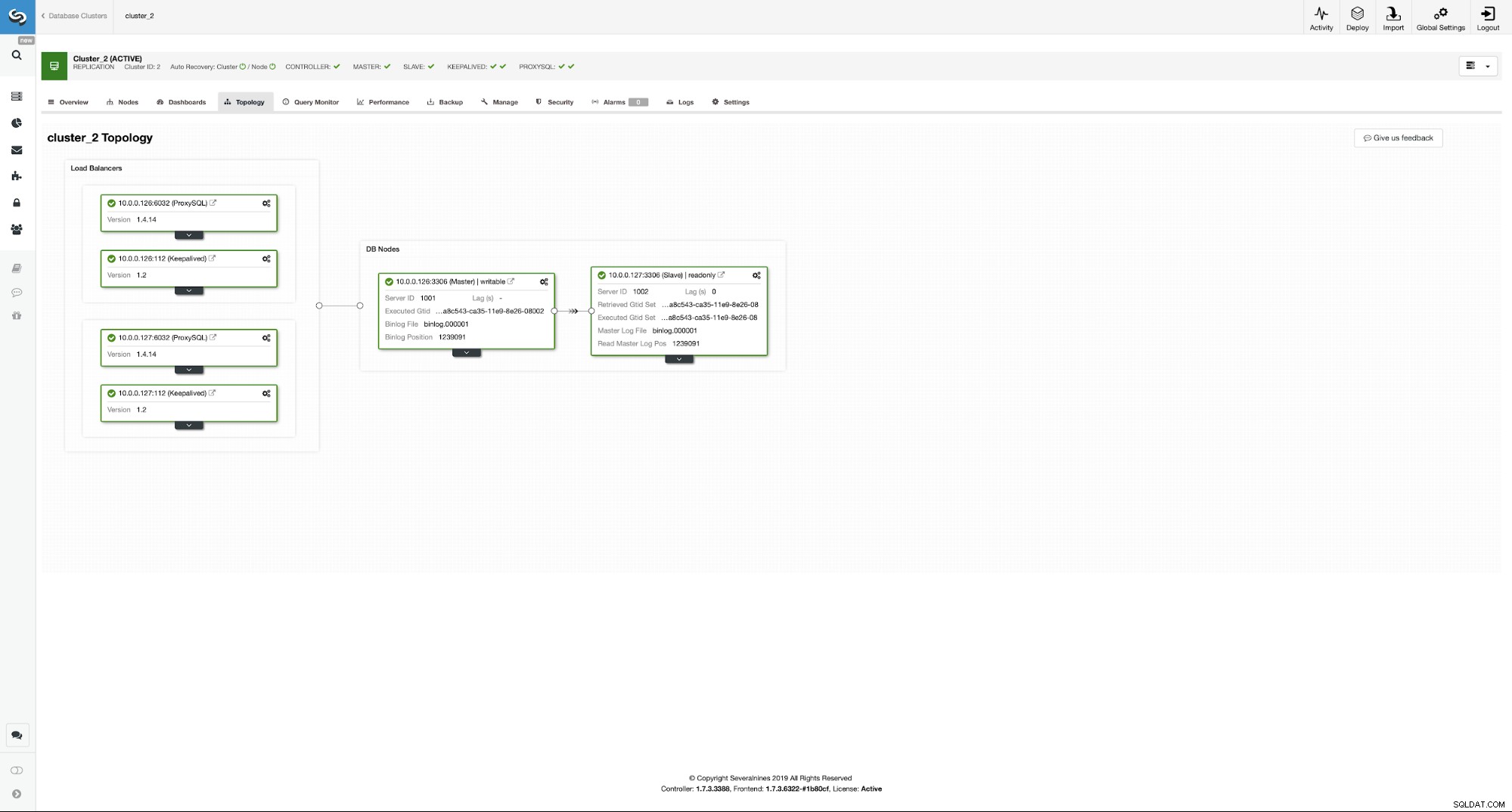
Jak widać, mamy już całą konfigurację. Mamy VIP 10.0.0.111, który jest przypisany do jednej z instancji ProxySQL. Instancje ProxySQL przekierują nasz ruch do właściwych węzłów backendu MySQL, a ClusterControl będzie obserwował środowisko, wykonując w razie potrzeby przełączanie awaryjne. Ostatnią czynnością, jaką musimy wykonać, jest rekonfiguracja Wordpress, aby używał wirtualnego adresu IP do łączenia się z bazą danych.
W tym celu musimy edytować wp-config.php i zmienić zmienną DB_HOST na nasz wirtualny adres IP:
/** MySQL hostname */
define( 'DB_HOST', '10.0.0.111' );Wnioski
Od teraz Wordpress połączy się z bazą danych za pomocą VIP i ProxySQL. W przypadku awarii węzła głównego, ClusterControl wykona przełączenie awaryjne.
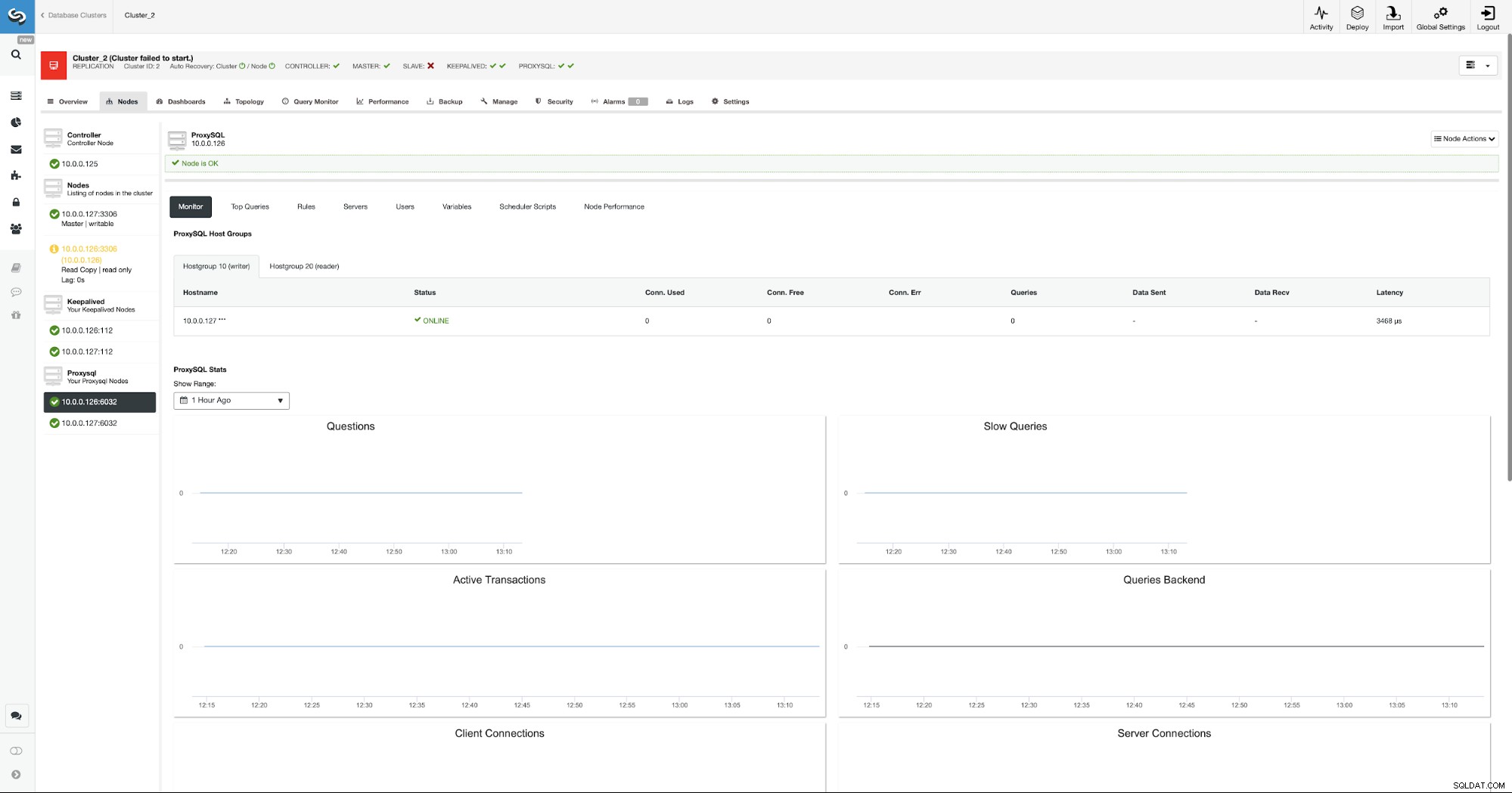
Jak widać, został wybrany nowy master, a ProxySQL również wskazuje na nowy master w grupie hostów 10.
Mamy nadzieję, że ten wpis na blogu da Ci pewne pojęcie o tym, jak zaprojektować wysoce dostępne środowisko bazy danych dla witryny Wordpress i jak można wykorzystać ClusterControl do wdrożenia wszystkich jego elementów.