Zaplecze bazy danych wpływa na aplikację, co może następnie wpłynąć na wydajność organizacji. Kiedy tak się dzieje, osoby odpowiedzialne zwykle chcą szybkiej naprawy. Istnieje wiele różnych sposobów poprawy wydajności w MySQL. Jako bardzo popularny wybór w wielu organizacjach, dość powszechne jest znalezienie instalacji MySQL z domyślną konfiguracją. Może to jednak nie być odpowiednie dla Twoich potrzeb związanych z obciążeniem pracą i konfiguracją.
W tym blogu pomożemy Ci lepiej zrozumieć obciążenie bazy danych i rzeczy, które mogą jej szkodzić. Wiedza o tym, jak korzystać z ograniczonych zasobów, jest niezbędna dla każdego, kto zarządza bazą danych, zwłaszcza jeśli uruchamiasz swój system produkcyjny na bazie danych MySQL.
Aby upewnić się, że baza danych działa zgodnie z oczekiwaniami, zaczniemy od darmowych narzędzi do monitorowania MySQL. Następnie przyjrzymy się powiązanym parametrom MySQL, które możesz dostosować, aby ulepszyć instancję bazy danych. Przyjrzymy się również indeksowaniu jako czynnikowi zarządzania wydajnością bazy danych.
Aby móc osiągnąć optymalne wykorzystanie zasobów sprzętowych, przyjrzymy się optymalizacji jądra i innym kluczowym ustawieniom systemu operacyjnego. Na koniec przyjrzymy się modnym konfiguracjom opartym na replikacji MySQL i tym, jak można je zbadać pod kątem opóźnienia wydajności.
Identyfikowanie problemów z wydajnością MySQL
Ta analiza pomaga lepiej zrozumieć stan i wydajność bazy danych. Wymienione poniżej narzędzia mogą pomóc w uchwyceniu i zrozumieniu każdej transakcji, dzięki czemu będziesz na bieżąco z jej wydajnością i zużyciem zasobów.
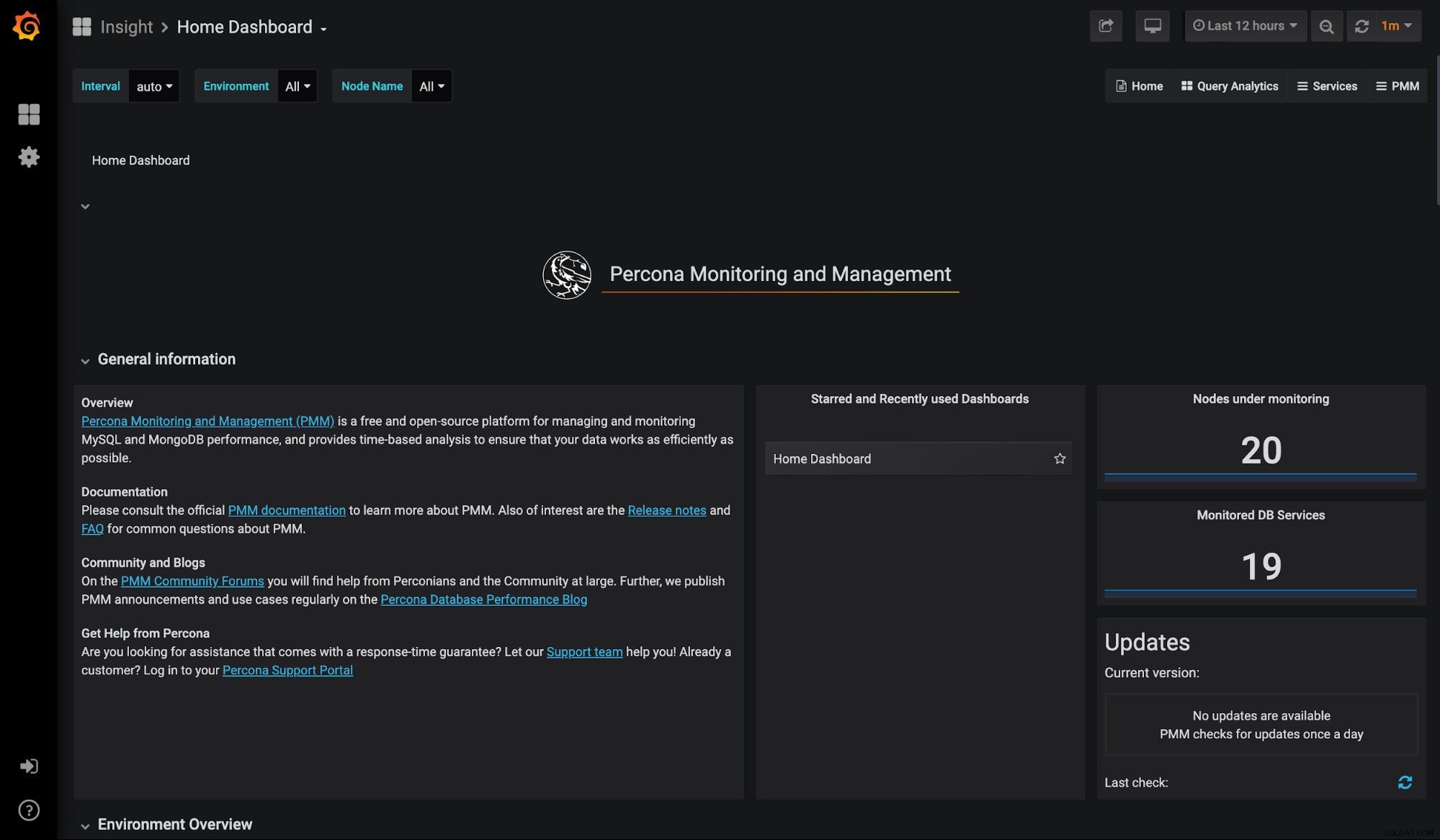
PMM (monitorowanie i zarządzanie Percona)
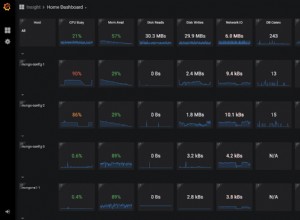
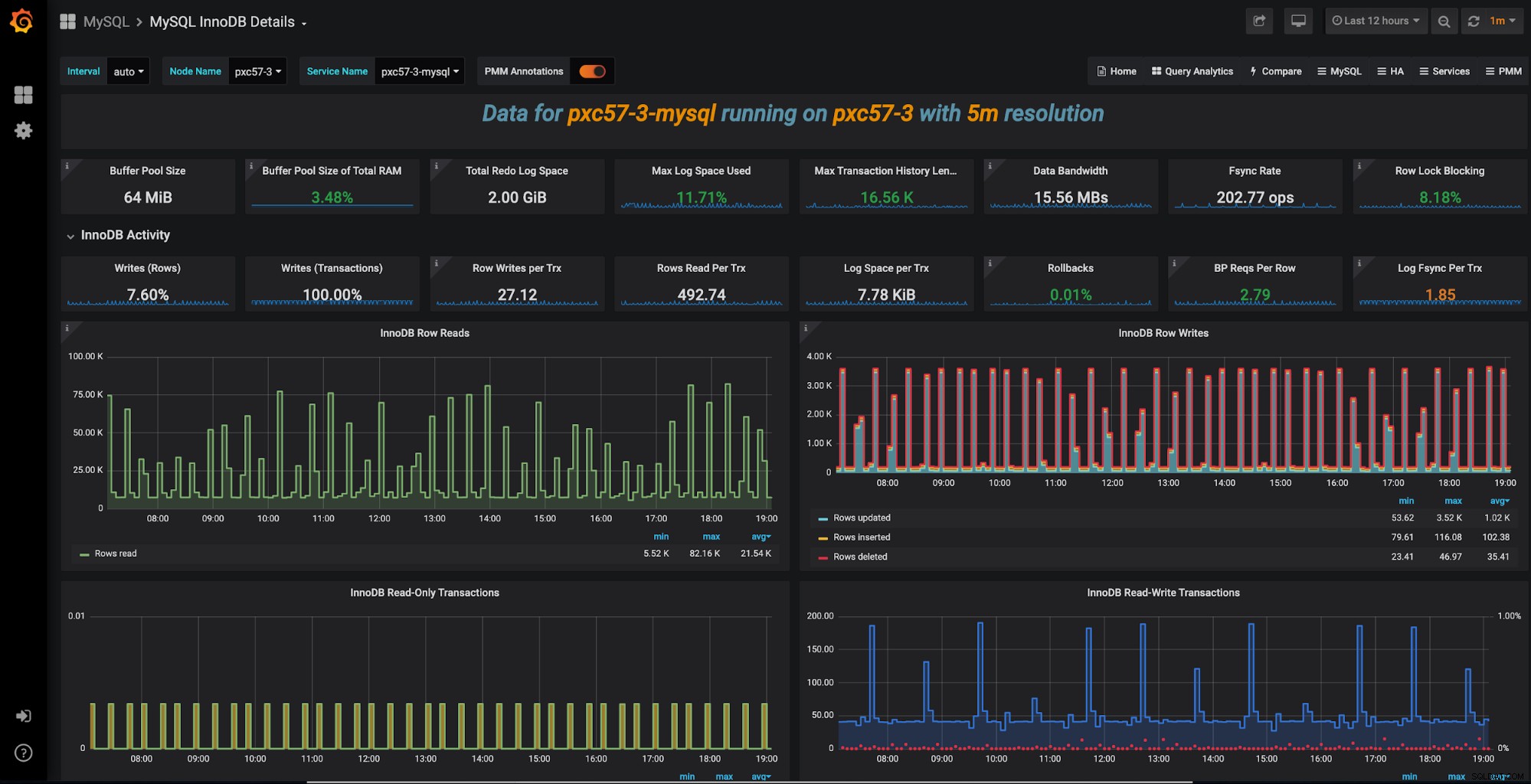
Narzędzie do monitorowania i zarządzania Percona to zbiór narzędzi typu open source dedykowany do baz danych MySQL, MongoDB i MariaDB (lokalnie lub w chmurze). PPM jest darmowy i jest oparty na dobrze znanej DB serii czasowej Grafana i Prometheus. Zapewnia dokładną, opartą na czasie analizę dla MySQL. Oferuje wstępnie skonfigurowane pulpity nawigacyjne, które pomagają zrozumieć obciążenie bazy danych.
PMM używa modelu klient/serwer. Będziesz musiał pobrać i zainstalować zarówno klienta, jak i serwer. Dla serwera możesz użyć kontenera Docker. To tak proste, jak pobranie obrazu dokera serwera PMM, utworzenie kontenera i uruchomienie PMM.
Wyciągnij obraz serwera PMM
docker pull percona/pmm-server:2
2: Pulling from percona/pmm-server
ab5ef0e58194: Downloading 2.141MB/75.78MB
cbbdeab9a179: Downloading 2.668MB/400.5MBUtwórz kontener PMM
docker create \
-v /srv \
--name pmm-data \
percona/pmm-server:2 /bin/trueUruchom kontener
docker run -d \
-p 80:80 \
-p 443:443 \
--volumes-from pmm-data \
--name pmm-server \
--restart always \
percona/pmm-server:2Możesz też sprawdzić jak to wygląda bez instalacji. Demo PMM jest dostępne tutaj.
Innym narzędziem wchodzącym w skład zestawu narzędzi PMM jest Query Analytics (QAN). Narzędzie QAN kontroluje czas wykonania zapytań. Możesz nawet uzyskać szczegółowe informacje o zapytaniach SQL. Daje również historyczny widok różnych parametrów, które są krytyczne dla optymalnej wydajności serwera bazy danych MySQL. To często pomaga zrozumieć, czy jakiekolwiek zmiany w kodzie mogą zaszkodzić wydajności. Na przykład nowy kod został wprowadzony bez Twojej wiedzy. Prostym zastosowaniem byłoby wyświetlenie bieżących zapytań SQL i podkreślenie problemów, które pomogą Ci poprawić wydajność bazy danych.
PMM zapewnia bieżącą i historyczną widoczność wydajności bazy danych MySQL. Pulpity nawigacyjne można dostosować do własnych wymagań. Możesz nawet rozwinąć konkretny panel, aby znaleźć potrzebne informacje o przeszłym wydarzeniu.
Bezpłatne monitorowanie baz danych za pomocą ClusterControl
ClusterControl zapewnia monitorowanie w czasie rzeczywistym całej infrastruktury bazy danych. Obsługuje różne systemy baz danych, począwszy od MySQL, MariaDB, PerconaDB, MySQL NDB Cluster, Galera Cluster (zarówno Percona, jak i MariaDB), MongoDB, PostgreSQL i TimescaleDB. Korzystanie z modułów monitorowania i wdrażania jest bezpłatne.
ClusterControl składa się z kilku modułów. W bezpłatnej wersji ClusterControl Community Edition możemy użyć:

Doradcy ds. wydajności oferują konkretne porady dotyczące rozwiązywania problemów z bazą danych i serwerami, takich jak jak wydajność, bezpieczeństwo, zarządzanie dziennikami, konfiguracja i planowanie pojemności. Raporty operacyjne mogą służyć do zapewnienia zgodności w setkach instancji. Jednak monitorowanie to nie zarządzanie. ClusterControl oferuje takie funkcje, jak zarządzanie kopiami zapasowymi, automatyczne przywracanie/przełączanie awaryjne, wdrażanie/skalowanie, aktualizacje kroczące, bezpieczeństwo/szyfrowanie, zarządzanie systemem równoważenia obciążenia i tak dalej.
Monitorowanie i doradcy
ClusterControl Community Edition oferuje bezpłatne monitorowanie bazy danych, które zapewnia ujednolicony widok wszystkich wdrożeń w centrach danych i umożliwia drążenie do poszczególnych węzłów. Podobnie jak w PMM możemy znaleźć dashboardy oparte na danych w czasie rzeczywistym. Trzeba wiedzieć, co się teraz dzieje, dzięki metrykom o wysokiej rozdzielczości dla lepszej dokładności, wstępnie skonfigurowanym pulpitom nawigacyjnym i szerokiej gamie usług powiadamiania innych firm do ostrzegania.
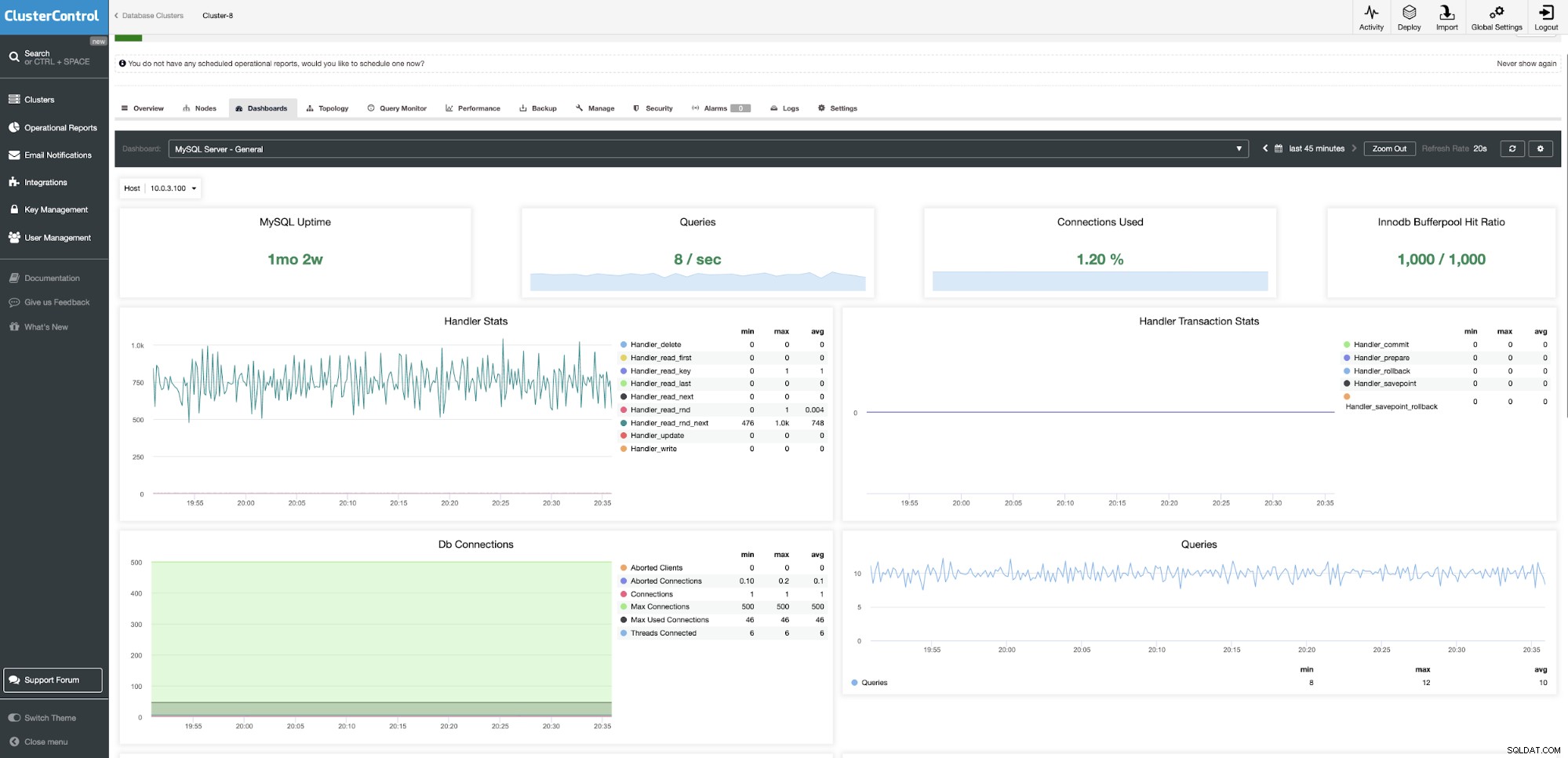
Systemy lokalne i w chmurze mogą być monitorowane i zarządzane z jednego punktu . Inteligentne kontrole kondycji są wdrażane dla rozproszonych topologii, na przykład wykrywanie partycjonowania sieci poprzez wykorzystanie widoku węzłów bazy danych systemu równoważenia obciążenia.
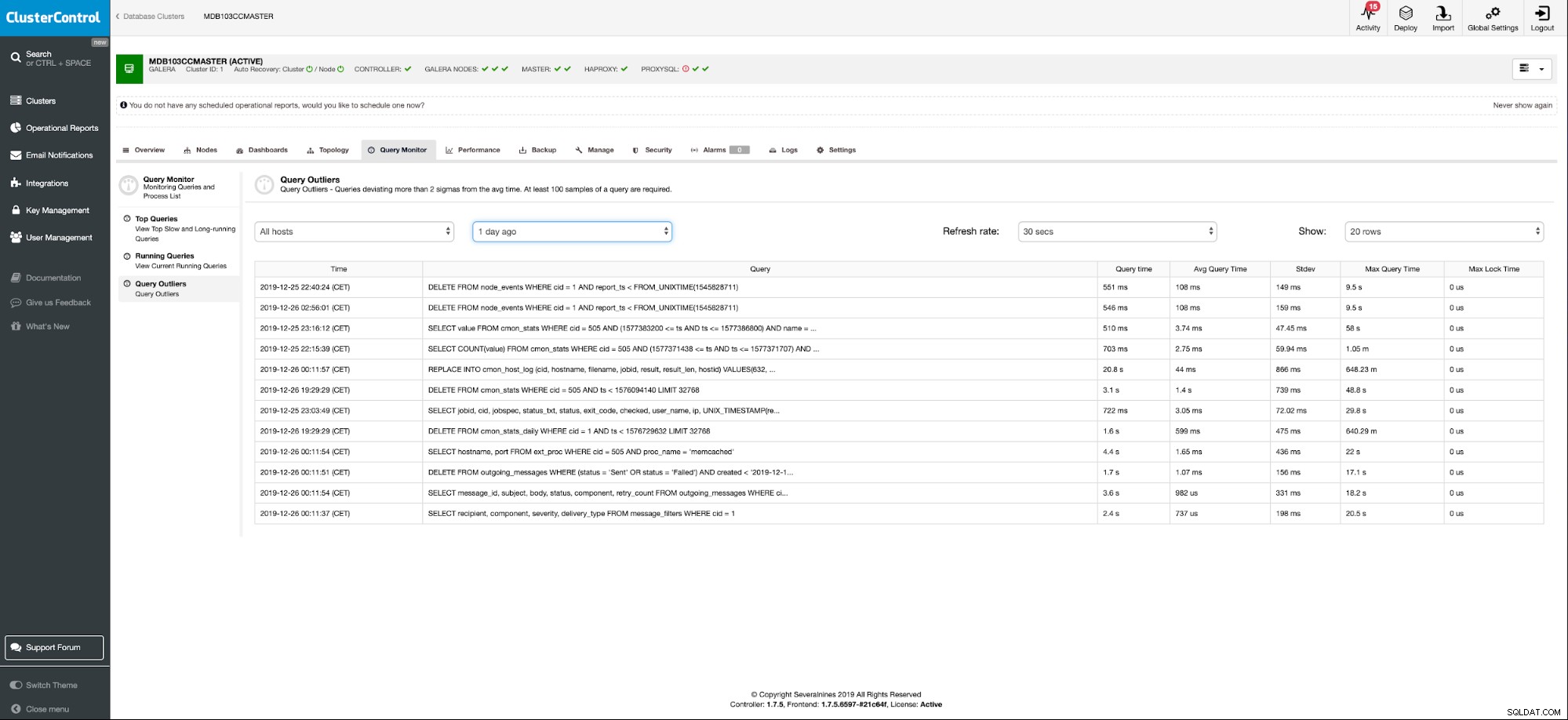
ClusterControl Workload Analytics w jednym z komponentów monitorowania, który może łatwo pomóc śledź swoje działania w bazie danych. Zapewnia przejrzystość transakcji/zapytań z aplikacji. Wyjątki wydajności nigdy nie są oczekiwane, ale zdarzają się i łatwo je przeoczyć w morzu danych. Wykrywanie wartości odstających spowoduje, że zapytania, które nagle zaczną być wykonywane znacznie wolniej niż zwykle. Śledzi średnią ruchomą i odchylenie standardowe dla czasów wykonania zapytania i wykrywa/alarmuje, gdy różnica między wartościami przekracza średnią o dwa odchylenia standardowe.
Jak widać na poniższym obrazku, udało nam się wyłapać kilka zapytań, które w ciągu jednego dnia mają tendencję do zmiany czasu wykonania w określonym czasie.
Aby zainstalować ClusterControl, kliknij tutaj i pobierz skrypt instalacyjny. Skrypt instalacyjny zajmie się niezbędnymi krokami instalacyjnymi.
Powinieneś również sprawdzić demo ClusterControl, aby zobaczyć, jak działa.
Możesz również uzyskać obraz dokowany za pomocą ClusterControl.
$ docker pull severalnines/clustercontrolWięcej informacji na ten temat znajdziesz w tym artykule.
Indeksowanie bazy danych MySQL
Bez indeksu uruchomienie tego samego zapytania powoduje skanowanie każdego wiersza w poszukiwaniu potrzebnych danych. Utworzenie indeksu na polu w tabeli tworzy dodatkową strukturę danych, która jest wartością pola i wskaźnikiem do rekordu, do którego się odnosi. Innymi słowy, indeksowanie tworzy skrót, z dużo krótszymi czasami zapytań w rozbudowanych tabelach. Bez indeksu MySQL musi zaczynać się od pierwszego wiersza, a następnie czytać całą tabelę, aby znaleźć odpowiednie wiersze.
Ogólnie rzecz biorąc, indeksowanie działa najlepiej w tych kolumnach, które są przedmiotem klauzul WHERE w często wykonywanych zapytaniach.
Tabele mogą mieć wiele indeksów. Zarządzanie indeksami nieuchronnie będzie wymagało możliwości wylistowania istniejących indeksów w tabeli. Składnia do przeglądania indeksu znajduje się poniżej.
Aby sprawdzić indeksy w tabeli MySQL uruchom:
SHOW INDEX FROM table_name;Ponieważ indeksy są używane tylko do przyspieszenia wyszukiwania pasującego pola w rekordach, jest zrozumiałe, że indeksowanie pól używanych tylko do danych wyjściowych byłoby po prostu marnowaniem miejsca na dysku. Innym efektem ubocznym jest to, że indeksy mogą rozszerzać operacje wstawiania lub usuwania, dlatego należy ich unikać, gdy nie są potrzebne.
Podmiana bazy danych MySQL
Na serwerach, na których MySQL jest jedyną uruchomioną usługą, dobrą praktyką jest ustawienie vm.swapiness =1. Domyślne ustawienie to 60, co nie jest odpowiednie dla systemu baz danych.
vi /etc/sysctl.conf
vm.swappiness = 1Przezroczyste, duże strony
Jeśli używasz MySQL na RedHat, upewnij się, że Transparent Huge Pages jest wyłączony.
Można to sprawdzić za pomocą polecenia:
cat /proc/sys/vm/nr_hugepages
0(0 oznacza, że przezroczyste duże strony są wyłączone).
Harmonogram we/wy MySQL
W większości dystrybucji harmonogramy we/wy noop lub terminów powinny być domyślnie włączone. Aby to sprawdzić, uruchom
cat /sys/block/sdb/queue/scheduler Opcje systemu plików MySQL
Zaleca się używanie kronikowanych systemów plików, takich jak xfs, ext4 lub btrfs. MySQL działa dobrze z nimi wszystkimi, a różnice najprawdopodobniej pojawią się przy obsługiwanym maksymalnym rozmiarze pliku.
- XFS (maksymalny rozmiar systemu plików 8EB, maksymalny rozmiar pliku 8EB)
- XT4 (maksymalny rozmiar systemu plików 8 EB, maksymalny rozmiar pliku 16 TB)
- BTRFS (maksymalny rozmiar systemu plików 16EB, maksymalny rozmiar pliku 16EB)
Domyślne ustawienia systemu plików powinny obowiązywać w porządku.
Deamon NTP
Dobrą najlepszą praktyką jest zainstalowanie demona serwera czasu NTP na serwerach baz danych. Użyj jednego z następujących poleceń systemowych.
#Red Hat
yum install ntp
#Debian
sudo apt-get install ntpWnioski
To wszystko dla części pierwszej. W następnym artykule będziemy kontynuować z ustawieniami systemów operacyjnych zmiennych MySQL i przydatnymi zapytaniami do zbierania stanu wydajności bazy danych.