Amazon Aurora Serverless zapewnia dostępną na żądanie, automatycznie skalowalną, wysoce dostępną relacyjną bazę danych, która pobiera opłaty tylko wtedy, gdy jest używana. Zapewnia stosunkowo prostą, opłacalną opcję dla nieczęstych, sporadycznych lub nieprzewidywalnych obciążeń. Umożliwia to automatyczne uruchamianie, skalowanie mocy obliczeniowej do poziomu wykorzystania aplikacji, a następnie wyłączanie, gdy nie jest już potrzebne.
Poniższy diagram przedstawia bezserwerową architekturę wysokiego poziomu Aurora.
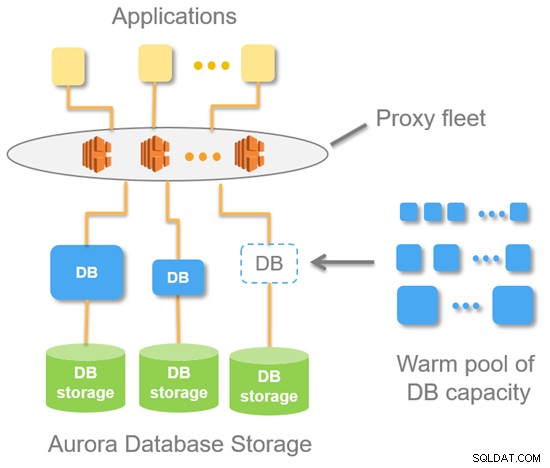
W przypadku Aurora Serverless otrzymujesz jeden punkt końcowy (w przeciwieństwie do dwóch punktów końcowych w przypadku standardowej bazy danych Aurora aprowizowanej). Jest to w zasadzie rekord DNS składający się z floty serwerów proxy, które znajdują się na górze instancji bazy danych. Z punktu serwera MySQL oznacza to, że połączenia zawsze pochodzą z floty proxy.
Bezserwerowe automatyczne skalowanie Aurora
Aurora Serverless jest obecnie dostępna tylko dla MySQL 5.6. Zasadniczo musisz ustawić minimalną i maksymalną jednostkę pojemności dla klastra DB. Każda jednostka pojemności odpowiada określonej konfiguracji obliczeń i pamięci. Aurora Serverless zmniejsza zasoby klastra DB, gdy jego obciążenie jest poniżej tych progów. Aurora Serverless może zmniejszyć pojemność do minimum lub zwiększyć pojemność do maksymalnej jednostki pojemności.
Klaster automatycznie skaluje się w górę, jeśli zostanie spełniony jeden z następujących warunków:
- Wykorzystanie procesora przekracza 70% LUB
- Ponad 90% połączeń jest używanych
Klaster zostanie automatycznie skalowany w dół, jeśli zostaną spełnione oba poniższe warunki:
- Wykorzystanie procesora spada poniżej 30% ORAZ
- Mniej niż 40% połączeń jest używanych.
Niektóre z ważnych rzeczy, które warto wiedzieć o automatycznym przepływie skalowania Aurora:
- Skaluje się tylko wtedy, gdy wykryje problemy z wydajnością, które można rozwiązać przez skalowanie w górę.
- Po skalowaniu czas odnowienia skalowania w dół wynosi 15 minut.
- Po zmniejszeniu, czas odnowienia następnego skalowania wynosi 310 sekund.
- Skaluje się do zera pojemności, gdy nie ma połączeń przez okres 5 minut.
Domyślnie Aurora Serverless wykonuje automatyczne skalowanie bezproblemowo, bez odcinania aktywnych połączeń bazy danych z serwerem. Jest w stanie określić punkt skalowania (punkt w czasie, w którym baza danych może bezpiecznie rozpocząć operację skalowania). Jednak w następujących warunkach Aurora Serverless może nie być w stanie znaleźć punktu skalowania:
- Trwają długotrwałe zapytania lub transakcje.
- W użyciu są tymczasowe tabele lub blokady tabel.
Jeśli zdarzy się którykolwiek z powyższych przypadków, Aurora Serverless nadal próbuje znaleźć punkt skalowania, aby móc zainicjować operację skalowania (chyba że włączona jest opcja „Force Scaling”). Robi to tak długo, jak określa, że klaster DB powinien być skalowany.
Obserwowanie zachowania automatycznego skalowania Aurory
Zauważ, że w Aurora Serverless tylko niewielka liczba parametrów może być modyfikowana, a max_connections nie jest jednym z nich. W przypadku wszystkich innych parametrów konfiguracyjnych klastry Aurora MySQL Serverless używają wartości domyślnych. W przypadku max_connections jest ono dynamicznie kontrolowane przez Aurora Serverless przy użyciu następującej formuły:
max_connections =GREATEST({log(DBInstanceClassMemory/805306368)*45},{log(DBInstanceClassMemory/8187281408)*1000})
Gdzie log to log2 (log base-2) i „DBInstanceClassMemory” to liczba bajtów pamięci przydzielonych do klasy instancji DB skojarzonej z bieżącą instancją DB pomniejszoną o pamięć używaną przez procesy Amazon RDS, które zarządzają instancją. Dosyć trudno jest z góry określić wartość, której użyje Aurora, dlatego dobrze jest przeprowadzić kilka testów, aby zrozumieć, w jaki sposób ta wartość jest odpowiednio skalowana.
Oto nasze podsumowanie wdrożenia bezserwerowego Aurora dla tego testu:
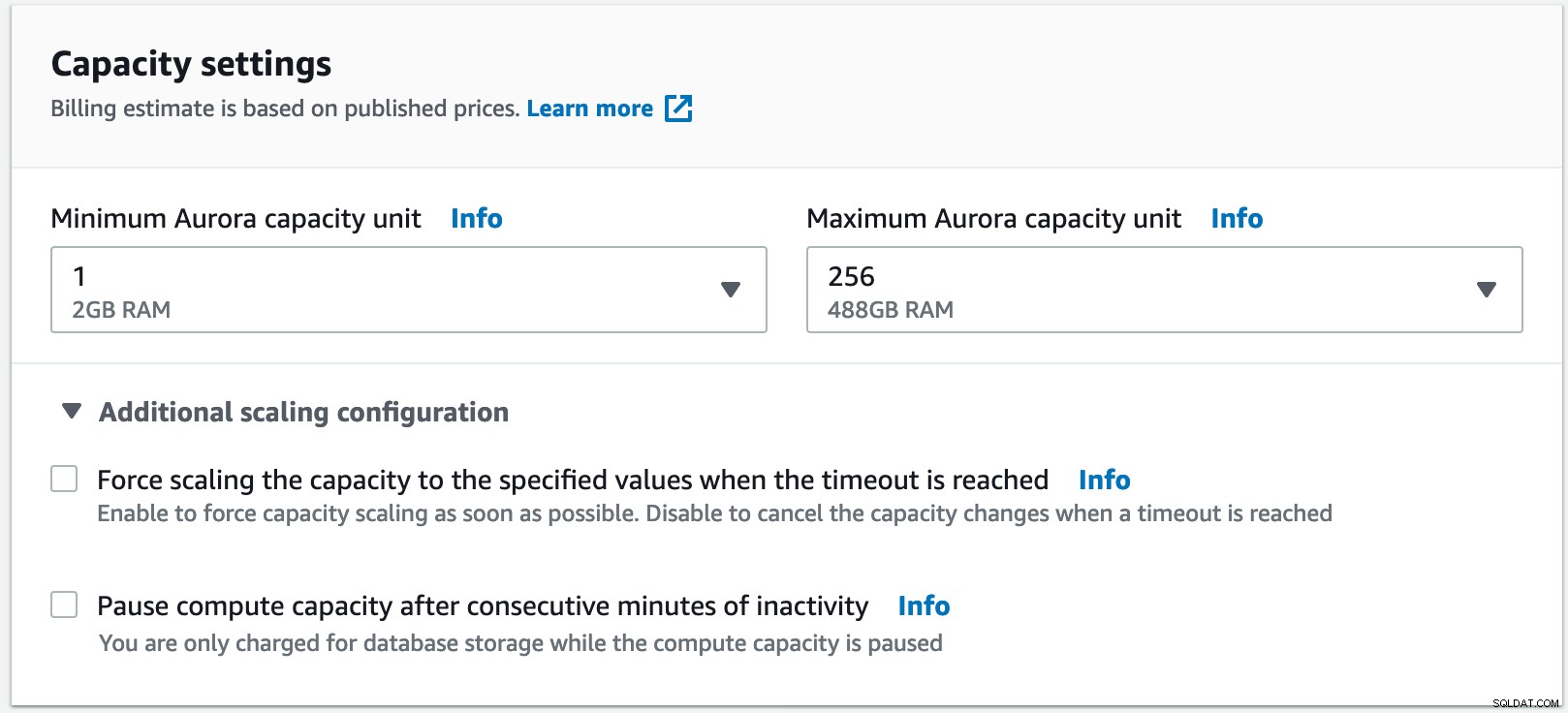
W tym przykładzie wybrałem co najmniej 1 jednostkę pojemności Aurora, co jest równe 2 GB pamięci RAM do maksymalnej jednostki pojemności 256 z 488 GB pamięci RAM.
Testy przeprowadzono przy użyciu sysbench, po prostu wysyłając wiele wątków, aż do osiągnięcia limitu połączeń z bazą danych MySQL. Nasza pierwsza próba wysłania 128 jednoczesnych połączeń z bazą danych naraz zakończyła się niepowodzeniem:
$ sysbench \
/usr/share/sysbench/oltp_read_write.lua \
--report-interval=2 \
--threads=128 \
--delete_inserts=5 \
--time=360 \
--max-requests=0 \
--db-driver=mysql \
--db-ps-mode=disable \
--mysql-host=${_HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=20 \
--table-size=100000 \
runPowyższe polecenie natychmiast zwróciło błąd „Zbyt wiele połączeń”:
FATAL: unable to connect to MySQL server on host 'aurora-sysbench.cluster-cdw9q2wnb00s.ap-southeast-1.rds.amazonaws.com', port 3306, aborting...
FATAL: error 1040: Too many connectionsPatrząc na ustawienia max_connection, otrzymaliśmy następujące:
mysql> SELECT @@hostname, @@max_connections;
+----------------+-------------------+
| @@hostname | @@max_connections |
+----------------+-------------------+
| ip-10-2-56-105 | 90 |
+----------------+-------------------+Okazuje się, że początkowa wartość max_connections dla naszej instancji Aurora z pojemnością jednej bazy danych (2GB RAM) wynosi 90. W rzeczywistości jest to znacznie mniej niż nasza oczekiwana wartość, jeśli zostanie obliczona przy użyciu podanego wzoru do oszacowania wartość max_connections:
mysql> SELECT GREATEST({log2(2147483648/805306368)*45},{log2(2147483648/8187281408)*1000});
+------------------------------------------------------------------------------+
| GREATEST({log2(2147483648/805306368)*45},{log2(2147483648/8187281408)*1000}) |
+------------------------------------------------------------------------------+
| 262.2951 |
+------------------------------------------------------------------------------+Oznacza to po prostu, że DBInstanceClassMemory nie jest równa rzeczywistej pamięci dla instancji Aurora. Musi być o wiele niżej. Zgodnie z tym wątkiem dyskusji, wartość zmiennej jest dostosowywana, aby uwzględnić pamięć już używaną przez usługi systemu operacyjnego i demona zarządzania RDS.
Jednak zmiana domyślnej wartości max_connections na wyższą również nam nie pomoże, ponieważ ta wartość jest dynamicznie kontrolowana przez klaster Aurora Serverless. Dlatego musieliśmy zmniejszyć wartość wątków początkowych sysbench do 84, ponieważ wewnętrzne wątki Aurory zarezerwowały już około 4 do 5 połączeń za pośrednictwem 'rdsadmin'@'localhost'. Ponadto potrzebujemy również dodatkowego połączenia do celów zarządzania i monitorowania.
Więc zamiast tego wykonaliśmy następujące polecenie (z --threads=84):
$ sysbench \
/usr/share/sysbench/oltp_read_write.lua \
--report-interval=2 \
--threads=84 \
--delete_inserts=5 \
--time=600 \
--max-requests=0 \
--db-driver=mysql \
--db-ps-mode=disable \
--mysql-host=${_HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=20 \
--table-size=100000 \
runPo zakończeniu powyższego testu w ciągu 10 minut (--time=600), ponownie uruchomiliśmy to samo polecenie i w tym czasie niektóre ważne zmienne i status zmieniły się, jak pokazano poniżej:
mysql> SELECT @@hostname AS hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+--------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+--------------+-----------------+-------------------+--------+
| ip-10-2-34-7 | 180 | 179 | 157 |
+--------------+-----------------+-------------------+--------+Zauważ, że max_connections podwoiło się teraz do 180, z inną nazwą hosta i krótkim czasem działania, jakby serwer dopiero się zaczynał. Z punktu widzenia aplikacji wygląda na to, że inna „większa instancja bazy danych” przejęła punkt końcowy i została skonfigurowana z inną zmienną max_connections. Patrząc na wydarzenie Aurora, wydarzyło się co następuje:
Wed, 04 Sep 2019 08:50:56 GMT The DB cluster has scaled from 1 capacity unit to 2 capacity units.Następnie uruchomiliśmy to samo polecenie sysbench, tworząc kolejne 84 połączenia z punktem końcowym bazy danych. Po zakończeniu wygenerowanego testu warunków skrajnych serwer automatycznie skaluje pojemność do 4 DB, jak pokazano poniżej:
mysql> SELECT @@hostname AS hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+---------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+---------------+-----------------+-------------------+--------+
| ip-10-2-12-75 | 270 | 6 | 300 |
+---------------+-----------------+-------------------+--------+Możesz to stwierdzić, patrząc na inną nazwę hosta, wartość max_connection i uptime w porównaniu z poprzednią. Kolejne większe instancje „przejęły” rolę od poprzedniej instancji, gdzie pojemność bazy danych była równa 2. Rzeczywisty punkt skalowania jest wtedy, gdy obciążenie serwera spadało i prawie spadało. W naszym teście, gdybyśmy utrzymali pełne połączenie i stale wysokie obciążenie bazy danych, automatyczne skalowanie nie miałoby miejsca.
Oglądając oba poniższe zrzuty ekranu, możemy stwierdzić, że skalowanie ma miejsce tylko wtedy, gdy nasz Sysbench zakończy test warunków skrajnych przez 600 sekund, ponieważ jest to najbezpieczniejszy punkt do przeprowadzenia automatycznego skalowania.
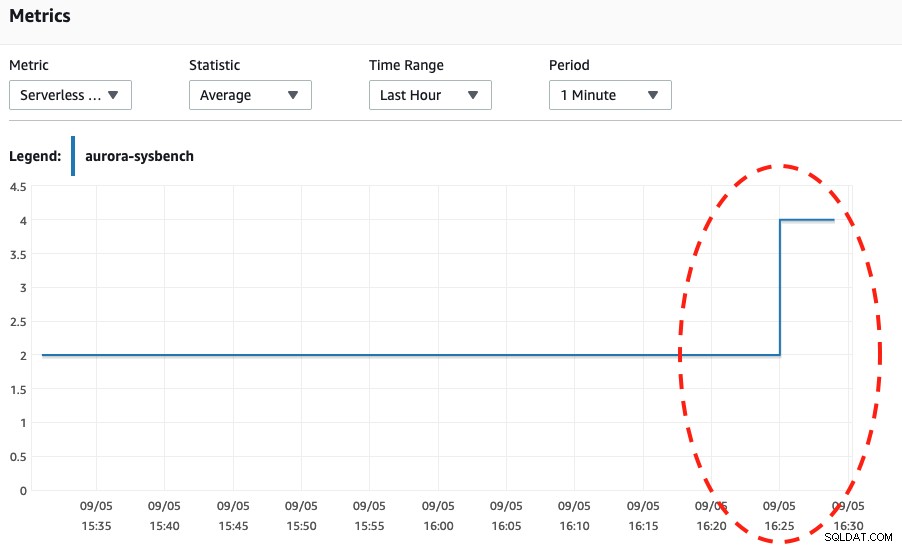 Pojemność bezserwerowej bazy danych Wykorzystanie procesora
Pojemność bezserwerowej bazy danych Wykorzystanie procesora 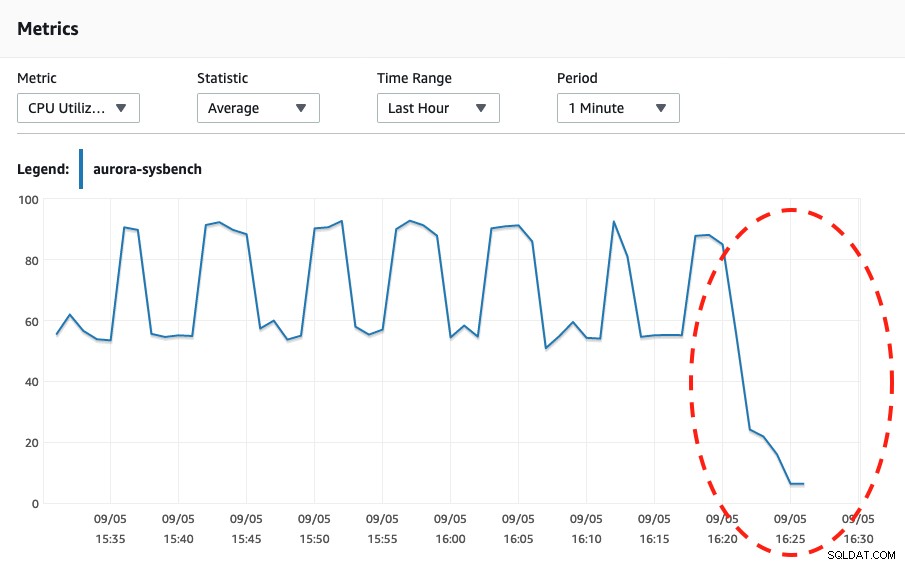 Wykorzystanie procesora
Wykorzystanie procesora Podczas oglądania wydarzeń z Aurory miały miejsce następujące wydarzenia:
Wed, 04 Sep 2019 16:25:00 GMT Scaling DB cluster from 4 capacity units to 2 capacity units for this reason: Autoscaling.
Wed, 04 Sep 2019 16:25:05 GMT The DB cluster has scaled from 4 capacity units to 2 capacity units.Wreszcie wygenerowaliśmy znacznie więcej połączeń, aż do prawie 270 i poczekaliśmy, aż się skończy, aby dostać się do pojemności 8 DB:
mysql> SELECT @@hostname as hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+---------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+---------------+-----------------+-------------------+--------+
| ip-10-2-72-12 | 1000 | 144 | 230 |
+---------------+-----------------+-------------------+--------+W instancji 8 jednostek pojemności MySQL max_connections wartość wynosi teraz 1000. Powtórzyliśmy podobne kroki, maksymalizując połączenia bazy danych i aż do limitu 256 jednostek pojemności. Poniższa tabela podsumowuje całkowitą jednostkę pojemności DB w porównaniu z wartością max_connections w naszych testach do maksymalnej pojemności DB:
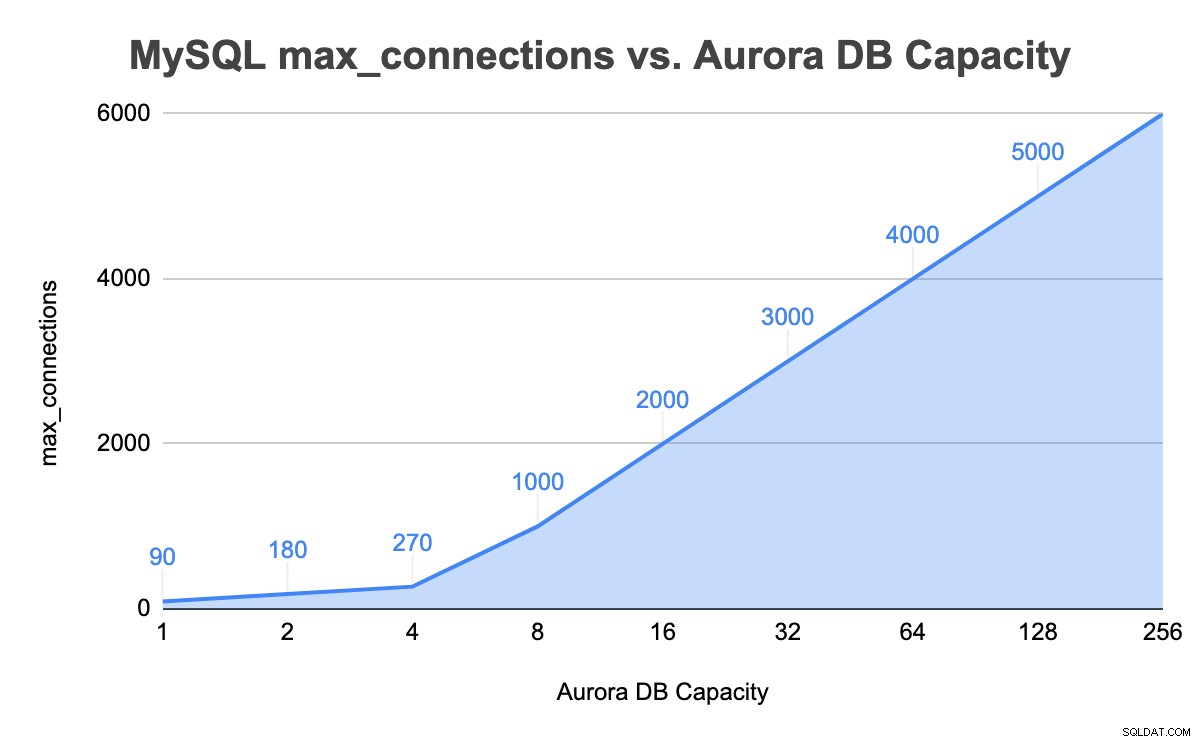
Skalowanie wymuszone
Jak wspomniano powyżej, Aurora Serverless wykona automatyczne skalowanie tylko wtedy, gdy jest to bezpieczne. Użytkownik ma jednak możliwość wymuszenia natychmiastowego skalowania pojemności bazy danych, zaznaczając pole wyboru Wymuś skalowanie w opcji „Dodatkowa konfiguracja skalowania”:
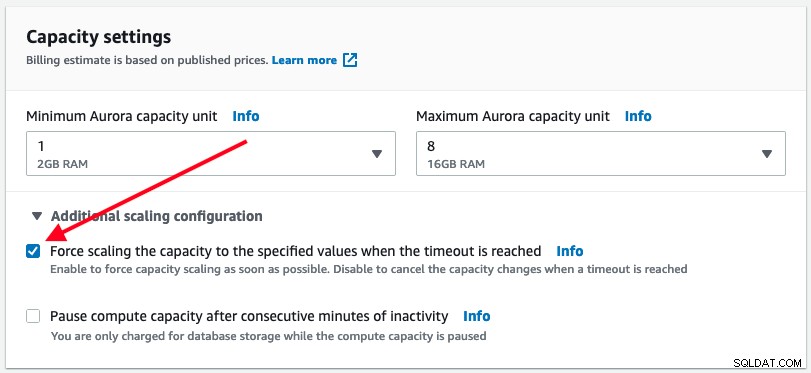
Gdy wymuszone skalowanie jest włączone, skalowanie następuje natychmiast po przekroczeniu limitu czasu osiągnięty, który wynosi 300 sekund. To zachowanie może powodować przerwy w działaniu bazy danych z aplikacji, w wyniku których aktywne połączenia z bazą danych mogą zostać zerwane. Zaobserwowaliśmy następujący błąd, gdy wymuszenie automatycznego skalowania nastąpiło po przekroczeniu limitu czasu:
FATAL: mysql_drv_query() returned error 1105 (The last transaction was aborted due to an unknown error. Please retry.) for query 'SELECT c FROM sbtest19 WHERE id=52824'
FATAL: `thread_run' function failed: /usr/share/sysbench/oltp_common.lua:419: SQL error, errno = 1105, state = 'HY000': The last transaction was aborted due to an unknown error. Please retry.Powyższe oznacza po prostu, że zamiast znaleźć odpowiedni czas na skalowanie, Aurora Serverless wymusza zastąpienie instancji natychmiast po przekroczeniu limitu czasu, co powoduje przerwanie transakcji i wycofanie. Ponowna próba przerwanego zapytania prawdopodobnie rozwiąże problem. Ta konfiguracja może być używana, jeśli Twoja aplikacja jest odporna na zrywanie połączeń.
Podsumowanie
Automatyczne skalowanie Amazon Aurora Serverless to rozwiązanie skalowania pionowego, w którym mocniejsza instancja przejmuje gorszą instancję, efektywnie wykorzystując podstawową technologię współdzielonej pamięci masowej Aurora. Domyślnie operacja automatycznego skalowania jest wykonywana płynnie, dzięki czemu Aurora znajduje bezpieczny punkt skalowania, aby wykonać przełączanie instancji. Istnieje możliwość wymuszenia automatycznego skalowania z ryzykiem utraty aktywnych połączeń z bazą danych.